专业视角深度解析:DeepSeek的核心优势何在?
杭州深度求索(DeepSeek)人工智能基础技术研究有限公司,是一家成立于2023年7月的中国人工智能初创企业,总部位于浙江省杭州市。该公司由量化对冲基金幻方量化(High-Flyer)的联合创始人梁文锋创立,致力于开发开源大型语言模型(LLM)及相关技术。
此前,DeepSeek 并不为大众所熟知,但最近其发布的新人工智能模型 DeepSeek-R1 在全球科技界引起了巨大反响。该模型的能力被认为可与谷歌和 OpenAI 的先进技术相媲美。根据上周(即2025年1月22日)发布的研究论文,DeepSeek 团队在训练该模型时仅花费了不到 600 万美元的计算成本,这一数字远低于 OpenAI 和谷歌(ChatGPT 和 Gemini 的开发者)数十亿美元的人工智能预算。因此,硅谷知名风险投资家马克·安德森(Marc Andreessen)将这一突破称为“人工智能的斯普特尼克时刻”。“斯普特尼克”一词源自1957年苏联发射的世界首颗人造卫星“斯普特尼克1号”(Sputnik 1),它曾震惊美国并推动了美国航天和科技的快速发展,最终促成了阿波罗登月计划(Apollo Program)的创立。
DeepSeek 作为一家中国小型初创公司,能够与硅谷顶尖企业竞争,挑战了美国在人工智能领域的主导地位,并引发了对英伟达、Meta 等公司高估值的质疑。本周周一,英伟达股价暴跌 17%,市值蒸发近 6000 亿美元,该公司在生成人工智能所需的半导体领域几乎处于垄断地位。摩根士丹利认为,DeepSeek的成功可能会激发一波AI创新浪潮。美国“元”公司首席AI科学家杨立昆在社交媒体上发文说,Deep-Seek-R1的面世,意味着开源模型正在超越闭源模型。美国总统唐纳德·特朗普上周宣布启动一项价值 5000 亿美元的人工智能计划,由 OpenAI、甲骨文(总部位于德克萨斯州)和日本软银集团牵头。特朗普表示,DeepSeek 应该成为“警钟”,提醒美国工业界需要“全神贯注于竞争以赢得胜利”。

图1,美国总统特朗普宣布斥资 5000 亿美元建立 AI 基础设施的“星际之门”项目
本文旨在避开政治和社会层面的喧哗,专注于从技术角度剖析 DeepSeek 的核心创新,以及它为何能够在短期内,在生成人工智能领域取得如此显著的成功。
自 2024 年以来,DeepSeek 共发表了 8 篇DeekSeek相关的科技论文,其中三篇尤为关键,揭示了其技术核心以及在人工智能技术创新和实际应用中的重大突破:
-
DeepSeek-LLM:以长期主义推动开源语言模型扩展
该论文于 2024 年 1 月发布,从长期主义的角度提出了开源语言模型的发展策略,旨在推动技术民主化。论文提出了社区驱动的开源治理框架和多任务优化方法,为开源生态的可持续发展提供了理论支持。 -
DeepSeek-V3:高效的混合专家模型
2024 年 12 月发布的这篇论文,提出了一种高效的混合专家模型。该模型通过仅激活少量参数,在性能和计算成本之间实现了优化平衡,成为大规模模型优化领域的重要突破。 -
DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
2025 年 1 月发布的这篇论文,提出了一种基于强化学习而非传统监督学习的方法,显著提升了语言模型在数学和逻辑推理任务中的表现。这一成果为大型语言模型的研究开辟了新的方向。
这三篇论文集中体现了 DeepSeek 在技术创新和实际应用中的核心贡献,展示了其如何通过开源策略、模型优化和新学习方法推动人工智能领域的发展。
1. DeepSeek-LLM:以长期主义扩展开源语言模型
2024年1月,DeepSeek大语言模型团队在《以长期主义扩展开源语言模型》 (LLM Scaling Open-Source Language Models with Longtermism)论文中提出从长期主义角度推动开源语言模型的发展,重点研究了大语言模型的规模效应。他们基于研究成果开发了DeepSeek Chat,并在此基础上不断升级迭代。

图2,DeepSeek 2024年发布的大语言模型(DeepSeek-LLM)论文
1.1 背景与目标
近年来,大型语言模型(LLM)通过自监督预训练和指令微调,逐步成为实现通用人工智能(AGI)的核心工具。然而,LLM 的规模化训练存在挑战,尤其是在计算资源和数据分配策略上的权衡问题。DeepSeek LLM 的研究旨在通过深入分析模型规模化规律,推动开源大模型的长期发展。该项目探索了模型规模和数据分配的最优策略,并开发了性能超越 LLaMA-2 70B 的开源模型,尤其在代码、数学和推理领域表现卓越。
1.2 数据与预训练
1.2.1 数据处理
文章处理了包含 2 万亿个 token 的双语数据集(中文和英文)。采取了去重、过滤和重新混合三阶段策略,以提高数据多样性和信息密度。使用 Byte-level Byte-Pair Encoding(BBPE)分词算法,词表大小设置为 102,400。
1.2.2 模型架构
微观设计:借鉴 LLaMA 的架构,采用 RMSNorm 和 SwiGLU 激活函数,以及旋转位置编码。
宏观设计:DeepSeek LLM 7B 具有 30 层,而 67B 增加至 95 层,并通过深度扩展优化性能。
1.2.3 超参数优化
作者引入多阶段学习率调度器,优化训练过程并支持持续训练。使用 AdamW 优化器,并对学习率、批次大小等关键超参数进行了规模化规律研究。
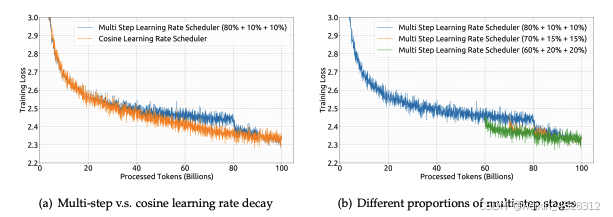
图3. DeepSeek使用不同的学习率调度器或不同的调度器参数的训练损失曲线。模型规模为 16 亿参数,在包含 1000 亿个标记的数据集上进行训练。
1.2.4 基础设施
作者开发了高效轻量化的训练框架 HAI-LLM,集成了数据并行、张量并行等技术,显著提升硬件利用率。
1.3 模型规模化规律
1.3.1 超参数规模化规律
作者通过实验发现,随着计算预算增加,最佳批次大小随之增大,而学习率则逐渐降低。他们提出了经验公式,以更准确地预测不同规模模型的超参数。
表1,DeepSeek LLM 系列模型的详细规格
1.3.2 模型与数据规模分配策略
作者引入了非嵌入 FLOPs/token(MMM)作为模型规模的度量方式,替代传统的参数数量表示,显著提高了计算预算分配的精确性。实验表明,高质量数据允许更多的预算分配到模型规模扩展上,从而提升性能。
1.4 对齐与微调
1.4.1 监督微调(supervised fine-tuning,SFT)
作者收集了 150 万条指令数据,包括通用语言任务、数学问题和代码练习。在微调中,通过两阶段策略,降低了模型的重复生成率,同时保持了基准性能。
1.4.2 直接偏好优化(direct preference optimization,DPO)
作者使用多语言提示生成偏好数据,通过优化模型,使其对开放式问题的生成能力显著增强。
1.5 性能评估
1.5.1 公共基准测试
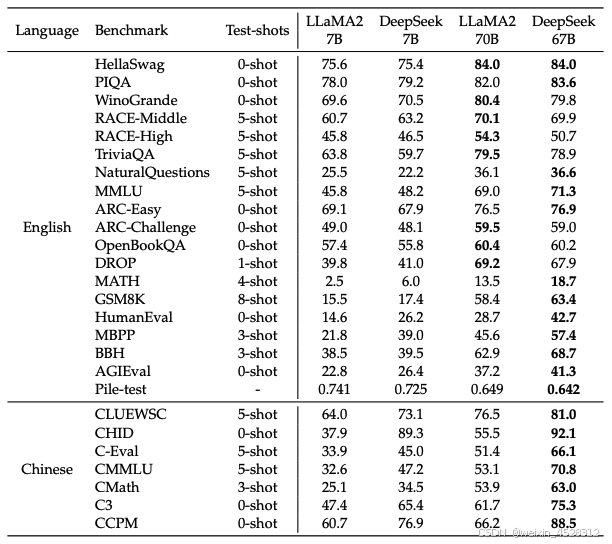
首先,对于数学和代码,DeepSeek LLM 67B 在 HumanEval 和 GSM8K 上显著优于 GPT-3.5 和 LLaMA-2 70B。
其次,对于中文任务,在 C-Eval、CMath 等基准上,DeepSeek 表现出色,尤其在中文成语填空(CHID)等文化任务中远超 LLaMA-2。在英文测试中,DeepSeek 67B Chat 在多轮对话生成能力上超越大多数开源模型。
最后,对于开放式生成能力,在 AlignBench 中文测试中,DeepSeek 67B Chat 在逻辑推理和文本生成等任务上表现接近 GPT-4。
表2. DeepSeek LLM 基准测试的主要结果。加粗数字表示 4 个模型中最优的结果。对于 Pile-test,作者报告比特每字节(BPB);对于 DROP,作者报告 F1 分数;对于其他任务,作者报告 准确率。请注意,测试时的 shots 取最大值,但在某些情况下,由于上下文长度限制或同一段落中可用的 few-shot 示例数量有限(如 RACE 等阅读理解任务),可能会使用更少的 shots。
1.5.2 安全评估
专业团队设计了覆盖多种安全问题的测试集,而DeepSeek 在歧视偏见、合法权益和违法行为等多方面均展现出高安全性。
1.6. 结论与未来方向
论文总结了 DeepSeek LLM 在开源大模型规模化领域的突破,包括:(1) 提出了更精确的模型规模与数据分配策略。(2) 在多个领域的任务中实现性能领先,尤其在数学、代码和中文任务上表现出色。 未来将继续优化高质量数据的利用,并探索更广泛的安全性和对齐技术。
2. DeepSeek-V3:高效的混合专家模型
DeepSeek于2024年12月27日发布了他们第二篇重要论文,《DeepSeek-V3: A Strong Mixture-of-Experts Language Model》。这是一项关于混合专家(Mixture-of-Experts,MoE)模型的研究,旨在通过激活少量专家网络实现高效计算,平衡模型性能和算力成本。该模型在多个复杂任务中表现出卓越的能力,同时显著降低了运行成本,为大模型的实际应用提供了新的思路。

图4,DeepSeek的《DeepSeek-V3》论文截图
2.1 背景与目标
随着大语言模型(LLM)的发展,DeepSeek-AI 团队提出了 DeepSeek-V3,一个拥有 6710 亿参数的混合专家(MoE)模型,每个子词单元(token)激活 370 亿参数。DeepSeek-V3 通过高效推理和经济成本的训练方法,旨在推动开源模型能力的极限,同时在性能上与闭源模型(如 GPT-4o 和 Claude-3.5)竞争。
2.2 核心技术与架构创新
2.2.1 多头潜在注意力(Multi-head Latent Attention, MLA)
作者使用低秩联合压缩方法减少注意力计算的缓存需求,同时保持多头注意力的性能。同时,他们引入旋转位置嵌入(Rotary Positional Embedding,RoPE)提高推理精度。
2.2.2 混合专家架构(DeepSeekMoE)
作者采用辅助损失优化的专家负载平衡策略,避免因负载不均导致的计算效率降低。同时,他们引入“无辅助损失”的负载平衡新方法,通过动态调整路由偏差值,确保训练过程中的负载均衡。
2.2.3 多 Token 预测目标(Multi-Token Prediction,MTP)
作者扩展了模型在每个位置预测多个未来 token 的能力,提高训练数据效率。特别是,在推理阶段,MTP 模块可被重新用于推测解码,从而加速生成。
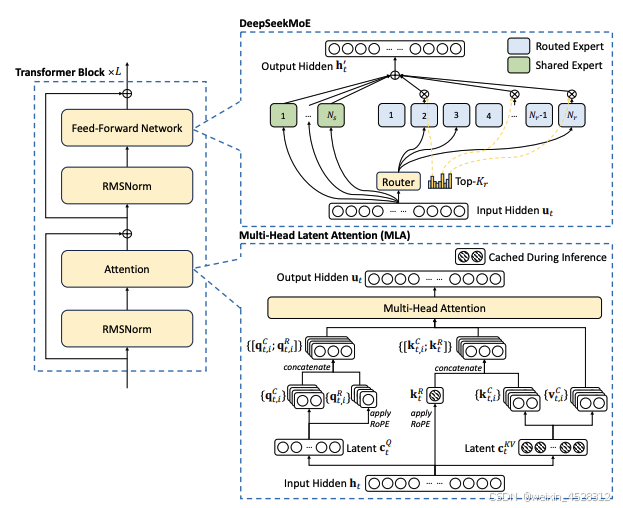
图 5,DeepSeek-V3 基本架构示意图。在继承 DeepSeek-V2 的基础上,作者采用 MLA 和 DeepSeekMoE 以实现高效推理和经济型训练。
2.3 数据与训练效率
2.3.1 数据与预训练:
作者使用了14.8 万亿高质量多样化 token 数据进行训练。他们发现,预训练过程非常稳定,未发生任何不可恢复的损失激增。
2.3.2 优化训练框架:
作者设计了 DualPipe 算法,通过前向和反向计算的重叠,显著减少通信开销。模型支持 FP8 混合精度训练,结合细粒度量化策略,显著降低内存使用和通信开销。
另外,他们发现,训练效率极高,每训练万亿 token 仅需 18 万 H800 GPU 小时,总成本约 557.6 万美元。
2.3.3 长上下文扩展:
DeepSeek 支持最大上下文长度从 32K 扩展至 128K,使模型更适用于长文档处理。
2.4 后期优化与推理部署
2.4.1 监督微调(Supervised Fine-Tuning,SFT)与强化学习(Reinforcement Learning,RL):
DeepSeek 通过 SFT 对齐模型输出与人类偏好。同时,他们引入自适应奖励模型和 相对策略优化(GRPO),提升模型的推理能力。
2.4.2 推理与部署:
DeepSeek 在 NVIDIA H800 GPU 集群上部署,结合高效的专家路由和负载均衡策略,实现低延迟的实时服务。同时,作者使用冗余专家策略进一步优化推理阶段的负载平衡。
2.5 DeepSeek V3 的性能表现
2.5.1 知识任务:
在 MMLU 和 GPQA 等教育基准上,DeepSeek-V3 超越所有开源模型,并接近 GPT-4o 的性能。特别是,DeepSeek V3 在中文事实性任务中表现尤为突出,领先大部分闭源模型。
2.5.2 代码与数学任务:
DeepSeek V3在数学基准(如 MATH-500)上实现开源模型的最佳表现。同时,它在编程任务(如 LiveCodeBench)中排名第一,展示了卓越的代码生成能力。
2.5.3 开放式生成任务:
在开放式生成任务中,DeepSeek-V3 的胜率显著高于其他开源模型,并接近闭源模型的水平。
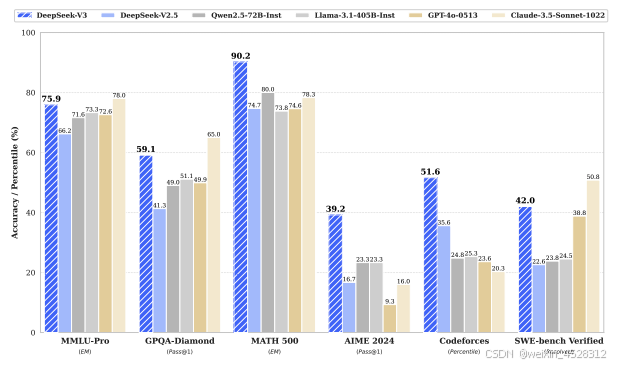
图 6. DeepSeek-V3 及其对比模型的基准测试性能。
2.6 结论与未来方向
DeepSeek-V3 是目前最强的开源基础模型之一,特别是在代码、数学和长上下文任务上表现突出。未来计划包括:(1)优化模型在多语言和多领域的泛化能力。(2) 探索更高效的硬件支持和训练方法。
3. DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
2025年01月20日,deepseek 正式发布 DeepSeek-R1,并同步开源模型权重。这篇题为《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》是一篇开创性的论文。它专注于通过纯强化学习方法(而非传统的监督学习)来提升大型语言模型的推理能力。研究展示了模型在训练过程中通过强化学习表现出的“顿悟”现象,并显著提升了模型在数学和逻辑推理任务中的性能。这也是DeepSeek在近期产生全球范围引发轰动效应的主要论文,它的第一作者是中山大学毕业的郭达雅博士。

图 7. DeepSeek的DeepSeek-R1论文截图。该论文近期引发全球范围的广泛影响。
3.1 背景与目标
近年来,大型语言模型(large language model, LLM)的推理能力成为人工智能研究的重要方向。然而,当前的许多方法依赖监督微调(supervised fine-tuning,SFT),这需要大量标注数据。论文提出了 DeepSeek-R1-Zero 和 DeepSeek-R1 两种新型模型,通过大规模强化学习(reinforcement learning, RL)方法提升推理能力,旨在减少对监督数据的依赖,探索纯强化学习对推理能力的优化潜力。
3.2 方法
3.2.1 DeepSeek-R1-Zero:基于纯强化学习的推理能力提升
DeepSeek-R1-Zero有两方面的特性:
- (1)强化学习算法: 使用 Group Relative Policy Optimization (GRPO),通过群体奖励优化策略模型。奖励设计包括准确性奖励(评估答案正确性)和格式奖励(引导模型按照指定格式输出推理过程)。
- (2)自我演化与“灵光一现”现象: 模型通过 RL 自动学习复杂的推理行为,如自我验证和反思。随着训练过程的深入,模型逐步提升了复杂任务的解答能力,并在推理任务上显现突破性的性能提升。
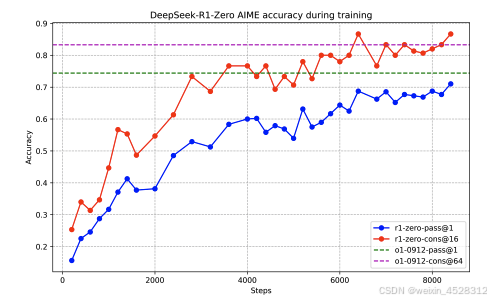
图8. DeepSeek-R1-Zero 在训练过程中的 AIME 准确率。对于每个问题,作者采样 16 个回答并计算整体平均准确率,以确保评估的稳定性。
3.2.2 DeepSeek-R1:结合冷启动数据的多阶段训练
DeepSeek-R1算法的主要特性:
- (1)冷启动数据的引入: 从零开始的 RL 容易导致初期性能不稳定,为此设计了包含高质量推理链的冷启动数据集。该数据提高了模型的可读性和训练初期的稳定性。
- (2)推理导向的强化学习: 通过多轮 RL,进一步优化模型在数学、编程等推理密集型任务中的表现。
- (3)监督微调与拒绝采样: 使用 RL 检查点生成额外的推理和非推理任务数据,进一步微调模型。
- (4)全场景强化学习: 在最终阶段结合多种奖励信号,提升模型的有用性和安全性。
- (5)蒸馏:将推理能力传递至小模型。将 DeepSeek-R1 的推理能力通过蒸馏技术传递至 Qwen 和 Llama 系列小型模型。蒸馏后的模型在多个基准任务中超越了部分开源大模型。
3.3 性能评估
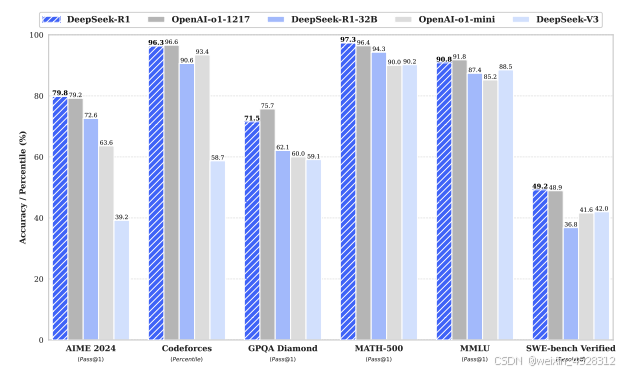
图9. DeepSeek-R1 的基准测试性能以及和OpenAI程序的比较。
3.3.1 推理任务
在 AIME 2024、MATH-500 等数学任务中,DeepSeek-R1 达到 OpenAI-o1-1217 的性能水平。另外,在编程任务(如 Codeforces 和 LiveCodeBench)上,表现优于大多数对比模型。
3.3.2 知识任务
在 MMLU 和 GPQA Diamond 等多学科基准测试中,DeepSeek-R1 展现了卓越的知识推理能力。特别是,其中文任务表现(如 C-Eval)显著优于其他开源模型。
3.3.3 生成任务
在 AlpacaEval 和 ArenaHard 等开放式生成任务中,DeepSeek-R1 的胜率分别达到 87.6% 和 92.3%,展现了强大的文本生成能力。
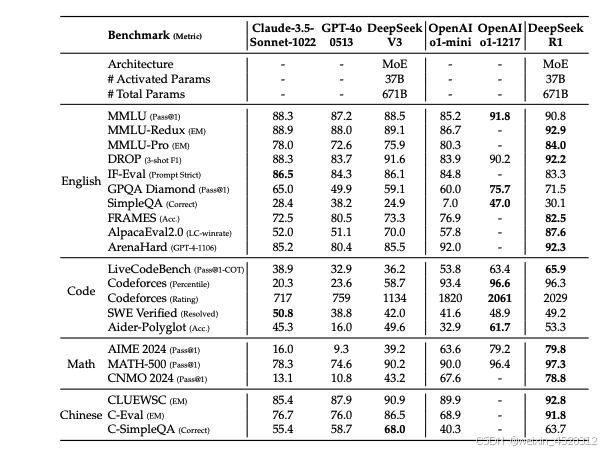
表3. DeepSeek-R1 与其他代表性模型的定量对比结果。
3.4 结论与未来展望
3.4.1 关键发现
通过强化学习,DeepSeek的语言推理能力可显著提升。即使对于无需监督数据,也依然成立。其次,将推理能力蒸馏到小型模型中可以有效地提高计算效率,同时保持较高的性能。
3.4.2 局限性
尽管这些成功,DeepSeek存在语言混合问题,即模型在处理多语言任务时可能输出混合语言。第二,DeepSeek存在提示敏感性问题,即模型对 few-shot 提示不够鲁棒(robust)。
3.4.3 未来方向
作者希望,在未来的研究中,增强多语言支持,优化对中文以外语言的推理能力。其次,加强研究大规模 强化学习在软件工程任务中的应用。
附录:梁文锋简介
梁文锋,中国人工智能公司DeepSeek的创始人兼首席执行官。他于1985年出生于广东省湛江市,父母均为小学教师。梁文锋于2007年获得浙江大学电子信息工程学士学位,2010年取得信息与通信工程硕士学位,师从项志宇教授,主要研究机器视觉领域。
在攻读硕士期间,梁文锋与同学组建团队,收集金融市场数据,探索将机器学习应用于全自动量化交易。2013年,他与浙江大学校友徐进共同创立了杭州雅克比投资管理有限公司,将人工智能与量化交易相结合。2015年,他们进一步创立了杭州幻方科技有限公司(现为浙江九章资产管理有限公司),并于2016年成立了宁波幻方量化投资管理合伙企业,专注于利用数学和人工智能进行量化投资。
在量化投资领域取得成功后,梁文锋将目光投向人工智能的更广阔应用。2023年,他宣布进军通用人工智能(AGI)领域,创立了DeepSeek,专注于大型语言模型的研究与开发。DeepSeek迅速崛起,其发布的DeepSeek-V2和DeepSeek-R1模型在性能和成本方面表现出色,引起全球关注。
梁文锋以其务实且创新的领导风格著称。他强调创新应通过速度和适应能力来实现,而非依赖保密。他主张中国应从模仿转向原创,积极参与全球技术创新浪潮。在人才招聘方面,DeepSeek注重吸纳具有能力和热情的年轻人才,团队主要由毕业不久的本土人才组成。
2025年1月,梁文锋受邀参加由中国国务院总理李强主持的专家、企业家座谈会,体现了他在中国人工智能领域的重要地位。DeepSeek的成功不仅展示了中国在人工智能领域的创新能力,也对全球科技产业格局产生了深远影响。

DeepSeek的创始人梁文锋
参考文献:
- X Bi et al, DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. [2401.02954] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- A Liu et al, DeepSeek-V3 Technical Report. [2412.19437] DeepSeek-V3 Technical Report.
- D Guo et al, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. [2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
相关文章:
专业视角深度解析:DeepSeek的核心优势何在?
杭州深度求索(DeepSeek)人工智能基础技术研究有限公司,是一家成立于2023年7月的中国人工智能初创企业,总部位于浙江省杭州市。该公司由量化对冲基金幻方量化(High-Flyer)的联合创始人梁文锋创立,…...

MySQL 索引存储结构
索引是优化数据库查询最重要的方式之一,它是在 MySQL 的存储引擎层中实现的,所以 每一种存储引擎对应的索引不一定相同。我们可以通过下面这张表格,看看不同的存储引擎 分别支持哪种索引类型: BTree 索引和 Hash 索引是我们比较…...

【ComfyUI专栏】如何使用Git命令行安装非Manager收录节点
当前的ComfyUI的收录的自定义节点很多,但是有些节点属于新出来,或者他的应用没有那么广泛,Manager管理节点 有可能没有收录到,这时候 如果我们需要安装需要怎么办呢?这就涉及到我们自己安装这些节点了。例如下面的内容…...

python算法和数据结构刷题[1]:数组、矩阵、字符串
一画图二伪代码三写代码 LeetCode必刷100题:一份来自面试官的算法地图(题解持续更新中)-CSDN博客 算法通关手册(LeetCode) | 算法通关手册(LeetCode) (itcharge.cn) 面试经典 150 题 - 学习计…...

数据分析系列--④RapidMiner进行关联分析(案例)
一、核心概念 1.项集(Itemset) 2.规则(Rule) 3.支持度(Support) 3.1 支持度的定义 3.2 支持度的意义 3.3 支持度的应用 3.4 支持度的示例 3.5 支持度的调整 3.6 支持度与其他指标的关系 4.置信度࿰…...

1/30每日一题
从输入 URL 到页面展示到底发生了什么? 1. 输入 URL 与浏览器解析 当你在浏览器地址栏输入 URL 并按下回车,浏览器首先会解析这个 URL(统一资源定位符),比如 https://www.example.com。浏览器会解析这个 URL 中的不同…...

vim的多文件操作
[rootxxx ~]# vim aa.txt bb.txt cc.txt #多文件操作 next #下一个文件 prev #上一个文件 first #第一个文件 last #最后一个文件 快捷键: ctrlshift^ #当前和上个之间切换 说明:快捷键ctrlshift^,…...

设计转换Apache Hive的HQL语句为Snowflake SQL语句的Python程序方法
首先,根据以下各类HQL语句的基本实例和官方文档记录的这些命令语句各种参数设置,得到各种HQL语句的完整实例,然后在Snowflake的官方文档找到它们对应的Snowflake SQL语句,建立起对应的关系表。在这个过程中要注意HQL语句和Snowfla…...

CAPL与外部接口
CAPL与外部接口 目录 CAPL与外部接口1. 引言2. CAPL与C/C++交互2.1 CAPL与C/C++交互简介2.2 CAPL与C/C++交互实现3. CAPL与Python交互3.1 CAPL与Python交互简介3.2 CAPL与Python交互实现4. CAPL与MATLAB交互4.1 CAPL与MATLAB交互简介4.2 CAPL与MATLAB交互实现5. 案例说明5.1 案…...
无公网IP 外网访问 本地部署夫人 hello-algo
hello-algo 是一个为帮助编程爱好者系统地学习数据结构和算法的开源项目。这款项目通过多种创新的方式,为学习者提供了一个直观、互动的学习平台。 本文将详细的介绍如何利用 Docker 在本地安装部署 hello-algo,并结合路由侠内网穿透实现外网访问本地部署…...

实验四 XML
实验四 XML 目的: 1、安装和使用XML的开发环境 2、认识XML的不同类型 3、掌握XML文档的基本语法 4、了解DTD的作用 5、掌握DTD的语法 6、掌握Schema的语法 实验过程: 1、安装XML的编辑器,可以选择以下之一 a)XMLSpy b)VScode,Vs…...

Autosar-Os是怎么运行的?(内存保护)
写在前面: 入行一段时间了,基于个人理解整理一些东西,如有错误,欢迎各位大佬评论区指正!!! 1.功能概述 以TC397芯片为例,英飞凌芯片集成了MPU模块, MPU模块采用了硬件机…...

题单:冒泡排序1
题目描述 给定 n 个元素的数组(下标从 1 开始计),请使用冒泡排序对其进行排序(升序)。 请输出每一次冒泡过程后数组的状态。 要求:每次从第一个元素开始,将最大的元素冒泡至最后。 输入格式…...

多目标优化策略之一:非支配排序
多目标优化策略中的非支配排序是一种关键的技术,它主要用于解决多目标优化问题中解的选择和排序问题,确定解集中的非支配解(也称为Pareto解)。 关于什么是多目标优化问题,可以查看我的文章:改进候鸟优化算法之五:基于多目标优化的候鸟优化算法(MBO-MO)-CSDN博客 多目…...

Go学习:字符、字符串需注意的点
Go语言与C/C语言编程有很多相似之处,但是Go语言中在声明一个字符时,数据类型与其他语言声明一个字符数据时有一点不同之处。通常,字符的数据类型为 char,例如 :声明一个字符 (字符名称为 ch) 的语句格式为 char ch&am…...

Linux文件原生操作
Linux 中一切皆文件,那么 Linux 文件是什么? 在 Linux 中的文件 可以是:传统意义上的有序数据集合,即:文件系统中的物理文件 也可以是:设备,管道,内存。。。(Linux 管理的一切对象…...
——常用Hint及语法(7)(其他Hint))
解决Oracle SQL语句性能问题(10.5)——常用Hint及语法(7)(其他Hint)
10.5.3. 常用hint 10.5.3.7. 其他Hint 1)cardinality:显式的指示优化器为SQL语句的某个行源指定势。该Hint具体语法如下所示。 SQL> select /*+ cardinality([@qb] [table] card ) */ ...; --注: 1)这里,第一个参数(@qb)为可选参数,指定查询语句块名;第二个参数…...
--编译器实现详解)
JavaScript系列(50)--编译器实现详解
JavaScript编译器实现详解 🔨 今天,让我们深入探讨JavaScript编译器的实现。编译器是一个将源代码转换为目标代码的复杂系统,通过理解其工作原理,我们可以更好地理解JavaScript的执行过程。 编译器基础概念 🌟 &…...

大数据相关职位 职业进阶路径
大数据相关职位 & 职业进阶路径 📌 大数据相关职位 & 职业进阶路径 大数据领域涵盖多个方向,包括数据工程、数据分析、数据治理、数据科学等,每个方向的进阶路径有所不同。以下是大数据相关职位的详细解析及其职业进阶关系。 &#…...

基础项目实战——学生管理系统(c++)
目录 前言一、功能菜单界面二、类与结构体的实现三、录入学生信息四、删除学生信息五、更改学生信息六、查找学生信息七、统计学生人数八、保存学生信息九、读取学生信息十、打印所有学生信息十一、退出系统十二、文件拆分结语 前言 这一期我们来一起学习我们在大学做过的课程…...

【模块化设计-10】UART1 驱动 + 环形 FIFO 实现高效串口数据收发
在嵌入式开发中,串口(UART)是最常用的通信接口之一,而直接采用中断 缓冲区的方式处理串口数据,能有效避免数据丢失、提升收发效率。本文将基于实际项目代码,详解UART1 驱动与环形 FIFO(ring_fi…...

专业级隐私保护工具:Boss-Key老板键完全使用指南
专业级隐私保护工具:Boss-Key老板键完全使用指南 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在现代办公环境中,…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...

5分钟实现PNG/JPG到SVG的终极转换:vectorizer矢量化工具完全指南
5分钟实现PNG/JPG到SVG的终极转换:vectorizer矢量化工具完全指南 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer vectorizer是一个…...

项目烂尾的魔咒:为什么你的物联网系统总是“上线即落后”?
在物联网行业有一个令人沮丧的“3-6-12”现象:3个月调研,6个月开发,12个月后项目烂尾或重构。 为什么投入巨资打造的智慧园区或工业互联系统,往往在验收通过的那一刻,就已经开始走向僵化?问题往往不出在硬…...

互斥锁如何避免数据竞争
互斥锁(Mutex, Mutual Exclusion Lock)是一种用于保护共享资源,确保在任意时刻只有一个线程可以访问该资源的同步原语。其核心目的是解决多线程环境下的**数据竞争(Data Race)**问题,防止因并发…...

基于Python与Telegram API构建消息抓取与备份工具实践
1. 项目概述与核心价值 最近在折腾一个挺有意思的小工具,起因是团队内部用Telegram群组做日常沟通和文件分享,时间一长,信息量爆炸,想找点历史资料或者特定文件简直是大海捞针。手动翻记录?效率低到令人发指。市面上虽…...

全球BGA锡球市场高速成长:2025年2.55亿美元筑基,2032年剑指4.43亿,8.3%CAGR锚定长期高增长逻辑
BGA锡球(BGA Solder Ball) 是用于替代IC元件封装结构中引脚的核心连接件,满足电性互连及机械连接的双重要求。简而言之,它是BGA封装工艺中不可或缺的焊接材料。QYResearch调研显示,2025年全球BGA锡球市场规模大约为2.5…...

英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆
英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟…...

容器化GUI自动化:基于Xvfb与xdotool的无头点击测试实践
1. 项目概述与核心价值最近在折腾一些自动化测试和模拟操作的项目,发现了一个挺有意思的镜像:instavm/clickclickclick。光看名字,你大概能猜到它的核心功能——点击。没错,这是一个专门用于模拟鼠标点击、键盘输入等图形界面&…...