【Ai】DeepSeek本地部署+Page Assist图形界面
准备工作
1、ollama,用于部署各种开源模型,并开放接口的程序
https://ollama.com/download
2、deepseek-r1:32b 模型
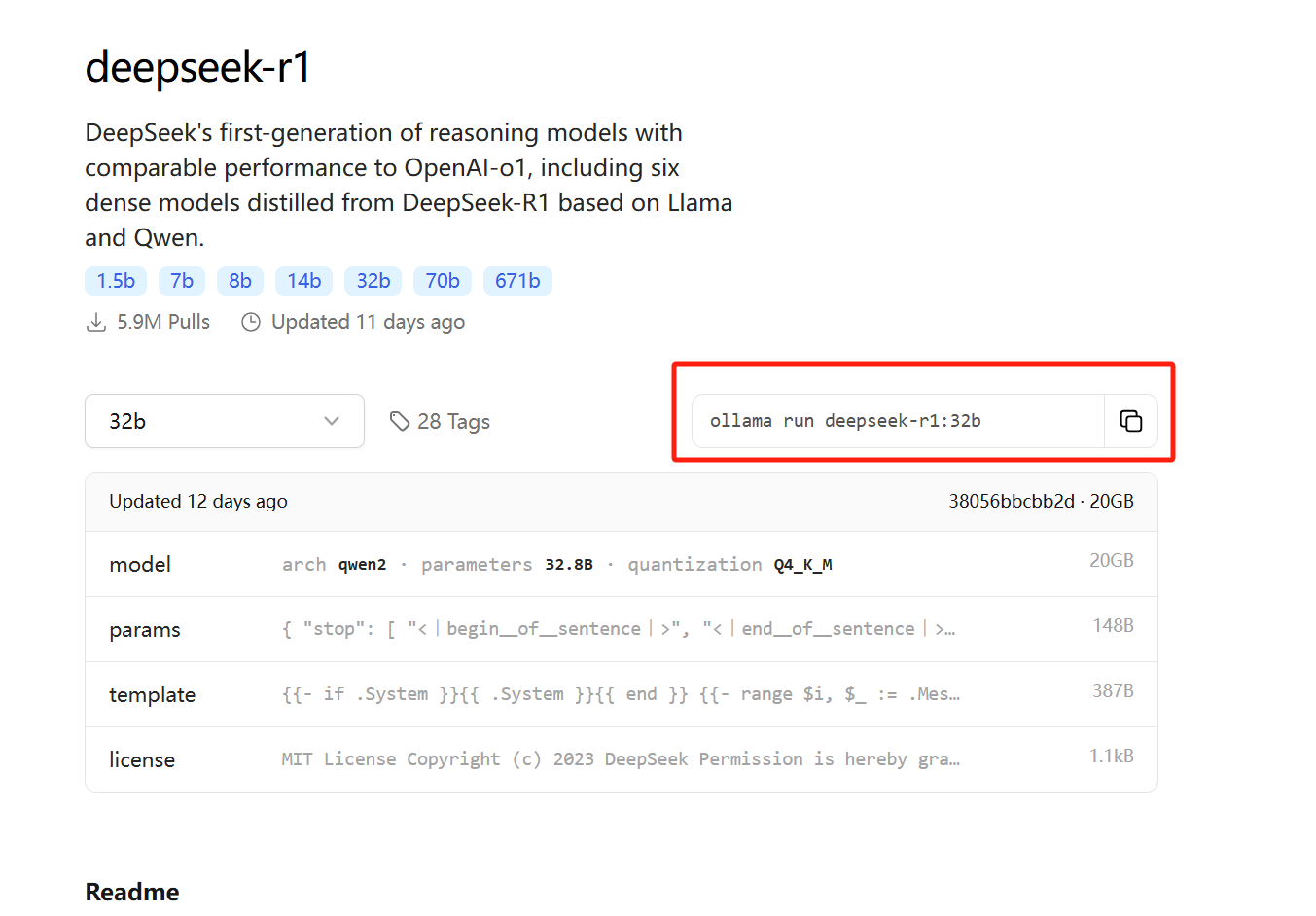
https://ollama.com/library/deepseek-r1:32b
不同的模型版本对计算机性能的要求不一样,版本越高对显卡和内存的要求越高,大致如下
- 7b:32GB内存,8GB显存
- 32b:128GB内存,24GB显存
3、Page Assist,浏览器插件,用于可视化的模型对话,特点是可接入联网搜索,并且很方便能配合嵌入模型
Firefox商店链接: Page Assist - Firefox Add-ons
安装完成后,可以通过以下方式打开Page Assist:
- 侧边栏:使用快捷键Ctrl+Shift+P
- Web UI:点击扩展图标,或使用快捷键Ctrl+Shift+L
首次使用需要配置本地AI模型,目前支持Ollama和Chrome AI (Gemini Nano)
下载安装
安装ollama
直接下载安装即可

配置环境变量
注意,配置完成后,要重启ollama
打开powershell命令窗口
1、模型存储目录
setx OLLAMA_MODELS D:\soft\ai\model
2、设置ollama服务启动配置
setx OLLAMA_HOST 0.0.0.0
setx OLLAMA_ORIGINS extension://*

安装DeepSeek模型
打开 https://ollama.com/search 第一个就是

复制执行命令,在powershell中运行即可,比如
ollama run deepseek-r1:32b
或
ollama run deepseek-r1:8b
安装模型需要等一段时间

经过数个小时的等待,终于完成了,使用命令提问试试

同时安装deepseek-r1:8b测试体验

GPU加速
模型启动默认使用CPU推理,速度较慢;可以配置使用GPU加速。
编辑文件(如果没有就创建一个)~/.ollama/config.json
{"gpu": true,"cuda": true
}
重启ollama服务,终止线程,然后使用命令启动ollama serve,可以看日志是否使用GPU
运行模型后,使用 nvidia-smi 命令查看 GPU 占用
接入 Page Assist
用Firefox打开 https://addons.mozilla.org/en-US/firefox/addon/page-assist/ 安装插件,安装完成后,打开设置,可以配置ollama地址,截图示例是默认地址,正常是直接连上的。

使用web页面提问,还可以联网搜索

使用deepseek-r1:8b测试体验,速度快很多

添加嵌入模型,ollama pull nomic-embed-text,然后在插件里RAG设置中选择嵌入模型即可

总结
我的电脑配置(12代i7cpu,40G内存,3060显卡6G显存)勉强能跑,不过提问回复很慢,效果很差。换8b的模型快了很多。
可能是模型级别太低的原因,本地模型使用效果一直不理想,问一些历史问题错误很多。
相关文章:
【Ai】DeepSeek本地部署+Page Assist图形界面
准备工作 1、ollama,用于部署各种开源模型,并开放接口的程序 https://ollama.com/download 2、deepseek-r1:32b 模型 https://ollama.com/library/deepseek-r1:32b 不同的模型版本对计算机性能的要求不一样,版本越高对显卡和内存的要求越高…...

【最长不下降子序列——树状数组、线段树、LIS】
题目 代码 #include <bits/stdc.h> using namespace std; const int N 1e510; int a[N], b[N], tr[N];//a保存权值,b保存索引,tr保存f,g前缀属性最大值 int f[N], g[N]; int n, m; bool cmp(int x, int y) {if(a[x] ! a[y]) return a[x] < a[…...

【实战篇章】深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据
文章目录 深入探讨:服务器如何响应前端请求及后端如何查看前端提交的数据一、服务器如何响应前端请求HTTP 请求生命周期全解析1.前端发起 HTTP 请求(关键细节强化版)2. 服务器接收请求(深度优化版) 二、后端如何查看前…...

Games104——引擎工具链基础
总览 工具链 用户到引擎架构图 工具链是衔接不同岗位、软件之间的桥梁,比如美术与技术,策划与美术,美术软件与引擎本身等,有Animation、UI、Mesh、Shader、Logical 、Level Editor等等。一般商业级引擎里的工具链代码量是超过…...

分层多维度应急管理系统的设计
一、系统总体架构设计 1. 六层体系架构 #mermaid-svg-QOXtM1MnbrwUopPb {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QOXtM1MnbrwUopPb .error-icon{fill:#552222;}#mermaid-svg-QOXtM1MnbrwUopPb .error-text{f…...

【漏斗图】——1
🌟 解锁数据可视化的魔法钥匙 —— pyecharts实战指南 🌟 在这个数据为王的时代,每一次点击、每一次交易、每一份报告背后都隐藏着无尽的故事与洞察。但你是否曾苦恼于如何将这些冰冷的数据转化为直观、吸引人的视觉盛宴? 🔥 欢迎来到《pyecharts图形绘制大师班》 �…...

(二)QT——按钮小程序
目录 前言 按钮小程序 1、步骤 2、代码示例 3、多个按钮 ①信号与槽的一对一 ②多对一(多个信号连接到同一个槽) ③一对多(一个信号连接到多个槽) 结论 前言 按钮小程序 Qt 按钮程序通常包含 三个核心文件: m…...

【Linux】从硬件到软件了解进程
个人主页~ 从硬件到软件了解进程 一、冯诺依曼体系结构二、操作系统三、操作系统进程管理1、概念2、PCB和task_struct3、查看进程4、通过系统调用fork创建进程(1)简述(2)系统调用生成子进程的过程〇提出问题①fork函数②父子进程关…...

HTB:Alert[WriteUP]
目录 连接至HTB服务器并启动靶机 信息收集 使用rustscan对靶机TCP端口进行开放扫描 使用nmap对靶机TCP开放端口进行脚本、服务扫描 使用nmap对靶机TCP开放端口进行漏洞、系统扫描 使用nmap对靶机常用UDP端口进行开放扫描 使用ffuf对alert.htb域名进行子域名FUZZ 使用go…...

ARM嵌入式学习--第十天(UART)
--UART介绍 UART(Universal Asynchonous Receiver and Transmitter)通用异步接收器,是一种通用串行数据总线,用于异步通信。该总线双向通信,可以实现全双工传输和接收。在嵌入式设计中,UART用来与PC进行通信,包括与监控…...

玉米苗和杂草识别分割数据集labelme格式1997张3类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):1997 标注数量(json文件个数):1997 标注类别数:3 标注类别名称:["corn","weed","Bean…...

哈夫曼树
哈夫曼树(Huffman Tree)是一种最优的二叉树,常用于数据压缩,如在 Huffman 编码中使用。它是根据字符出现的频率来构造的,频率越高的字符越靠近树的根,频率低的字符则在较深的节点上。其核心思想是通过构建一…...

wax到底是什么意思
在很久很久以前,人类还没有诞生文字之前,人类就产生了语言;在诞生文字之前,人类就已经使用了语言很久很久。 没有文字之前,人们的语言其实是相对比较简单的,因为人类的生产和生活水平非常低下,…...

笔记:使用ST-LINK烧录STM32程序怎么样最方便?
一般板子在插件上, 8脚 3.3V;9脚 CLK;10脚 DIO;4脚GND ST_Link 19脚 3.3V;9脚 CLK;7脚 DIO;20脚 GND 烧录软件:ST-LINK Utility,Keil_5; ST_Link 接口针脚定义: 按定义连接ST_Link与电路板; 打开STM32 ST-LINK Uti…...

数据分析系列--[11] RapidMiner,K-Means聚类分析(含数据集)
一、数据集 二、导入数据 三、K-Means聚类 数据说明:提供一组数据,含体重、胆固醇、性别。 分析目标:找到这组数据中需要治疗的群体供后续使用。 一、数据集 点击下载数据集 二、导入数据 三、K-Means聚类 Ending, congratulations, youre done....

Python在数据科学领域的深度应用:从数据处理到机器学习模型构建
Python在数据科学领域的深度应用:从数据处理到机器学习模型构建 在当今大数据与人工智能蓬勃发展的时代,Python凭借其简洁的语法、强大的库支持和活跃的社区,已成为数据科学家和工程师的首选编程语言。本文将深入探讨Python在数据科学领域的应用,从数据预处理、探索性分析…...

海外问卷调查渠道查,具体运营的秘密
相信只要持之以恒并逐渐掌握技巧,每一位调查人在踏上征徐之时都会非常顺利的。并在日后的职业生涯中拥有捉刀厮杀的基本技能!本文会告诉你如何做好一个优秀的海外问卷调查人。 在市场经济高速发展的今天,众多的企业为了自身的生存和发展而在…...

穷举vs暴搜vs深搜vs回溯vs剪枝系列一>单词搜索
题解如下 题目:解析决策树:代码设计: 代码: 题目: 解析 决策树: 代码设计: 代码: class Solution {private boolean[][] visit;//标记使用过的数据int m,n;//行,列char…...

万字长文深入浅出负载均衡器
前言 本篇博客主要分享Load Balancing(负载均衡),将从以下方面循序渐进地全面展开阐述: 介绍什么是负载均衡介绍常见的负载均衡算法 负载均衡简介 初识负载均衡 负载均衡是系统设计中的一个关键组成部分,它有助于…...

基于SpringBoot的青年公寓服务平台的设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

多智能体强化学习环境PettingZoo:从核心概念到工程实践
1. 项目概述:从零理解PettingZoo如果你正在寻找一个能让你快速上手、高效构建多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)实验环境的工具,那么Farama Foundation旗下的PettingZoo项目,绝对是你绕不开…...

基于WLED分段功能与激光切割的多层智能艺术灯板制作全攻略
1. 项目概述与核心价值如果你和我一样,对那种能随着音乐呼吸、或者能独立变换不同区域色彩的智能灯光装置着迷,那么你一定会喜欢这个项目。它远不止是把LED灯条粘在板子后面那么简单,而是将激光切割的精密工艺、分层的艺术设计,与…...

EmoLLM:大语言模型的情感增强训练与部署实践
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你大概能猜到,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large Lang…...

AI智能体开发实战:从Devin现象到代码辅助智能体构建
1. 项目概述:当开发者遇上AI智能体最近在GitHub上闲逛,发现一个叫“awesome-devins”的仓库热度飙升。点进去一看,好家伙,这简直是一个关于“AI智能体”的宝藏目录。这个由e2b-dev团队维护的项目,本质上是一个精心整理…...

AI赋能安全分析:hexstrike-ai项目实战与提示词工程详解
1. 项目概述:一个为安全研究而生的AI助手如果你是一名安全研究员、逆向工程师或者渗透测试人员,那么你肯定对“工具链”这个词深有体会。我们的工作台就像是一个复杂的车间,摆满了IDA Pro、Ghidra、x64dbg、Burp Suite、Wireshark……这些工具…...

AI驱动命令行工具:用自然语言生成Shell命令,提升开发运维效率
1. 项目概述:一个能“读懂”你意图的智能命令行工具如果你和我一样,每天有大量时间泡在终端里,那么对命令行工具的效率追求几乎是永无止境的。敲命令、查参数、记路径、处理错误……这些琐碎的操作虽然基础,却实实在在地消耗着我们…...

如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南
如何在Windows上高效使用酷安社区:UWP桌面客户端完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否经常在手机小屏幕上刷酷安,眼睛酸痛却停不下来&…...

Agent 的记忆也会被投毒:长期记忆安全的六阶段框架
过去,我们更习惯把大模型的风险理解为“这一轮输入有没有问题”“这一轮输出会不会越界”。但有了长期记忆之后,风险结构发生了变化。恶意内容不一定在当场触发,也不一定在同一轮任务里显现出来。它可以先悄悄进入记忆,在几天后、…...

基于CircuitPython与MagTag的电子墨水屏俳句显示器项目实践
1. 项目概述与核心价值如果你对嵌入式开发感兴趣,但又觉得传统的C/C开发环境配置繁琐、学习曲线陡峭,那么CircuitPython绝对是一个值得尝试的入口。它本质上是一个运行在微控制器上的Python 3解释器,由Adafruit主导开发,目标就是让…...

记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录
记一次在双 RTX 3090 工作站上部署 vLLM 与 Qwen3.6-35B-AWQ 的实战记录 1. 升级目的 最近需要本地部署大模型推理服务,目标是运行 Qwen3.6-35B 的 INT4 量化版本(AWQ 格式),并使用高性能推理引擎 vLLM 提供服务。由于模型采用 …...