机器学习--概览
一、机器学习基础概念
1. 定义
机器学习(Machine Learning, ML):通过算法让计算机从数据中自动学习规律,并利用学习到的模型进行预测或决策,而无需显式编程。
2. 与编程的区别
| 传统编程 | 机器学习 |
|---|---|
| 输入:规则+数据 → 输出:结果 | 输入:数据+结果 → 输出:规则 |
| 需要人工编写逻辑 | 自动发现数据中的模式 |
3. 核心要素
- 数据:模型学习的原材料(结构化/非结构化)
- 特征(Feature):数据的可量化属性(如房价预测中的面积、地段)
- 标签(Label):监督学习中的目标变量(如房价数值)
- 模型:从数据中学习到的数学函数(如 y = w 1 x 1 + w 2 x 2 + b y = w_1x_1 + w_2x_2 + b y=w1x1+w2x2+b)
- 损失函数:衡量预测值与真实值的差距(如均方误差 MSE)
- 优化算法:调整模型参数以最小化损失(如梯度下降)
二、机器学习分类
1. 按学习方式分类
(1) 监督学习(Supervised Learning)
- 特点:数据包含输入特征和对应标签
- 典型任务:
- 分类(预测离散类别):垃圾邮件识别(二分类)、手写数字识别(多分类)
- 回归(预测连续数值):房价预测、股票走势预测
- 常用算法:
- 线性回归(Linear Regression)
- 支持向量机(SVM)
- 随机森林(Random Forest)
- 神经网络(Neural Networks)
(2) 无监督学习(Unsupervised Learning)
- 特点:数据只有输入特征,无标签
- 典型任务:
- 聚类:客户分群、新闻主题发现
- 降维:可视化高维数据(t-SNE)
- 异常检测:信用卡欺诈识别
- 常用算法:
- K-Means聚类
- 主成分分析(PCA)
- 自编码器(Autoencoder)
(3) 强化学习(Reinforcement Learning, RL)
- 特点:智能体通过与环境交互获得奖励信号学习策略
- 典型应用:AlphaGo、自动驾驶决策
- 核心要素:
- 状态(State)
- 动作(Action)
- 奖励(Reward)
- 策略(Policy)
2. 按模型类型分类
| 类型 | 特点 | 算法示例 |
|---|---|---|
| 参数模型 | 参数数量固定(如线性模型) | 线性回归、逻辑回归 |
| 非参数模型 | 参数数量随数据增长 | KNN、决策树 |
| 判别模型 | 直接学习决策边界 | SVM、神经网络 |
| 生成模型 | 学习数据分布 | 朴素贝叶斯、GAN |
三、机器学习流程
1. 标准工作流
2. 关键步骤详解
(1) 数据预处理
- 缺失值处理:删除/填充(均值、中位数)
- 异常值检测:Z-Score、IQR方法
- 数据标准化:Min-Max缩放、Z-Score标准化
- 类别编码:One-Hot编码、标签编码
(2) 特征工程
- 特征选择:方差阈值、卡方检验
- 特征构造:组合特征(如面积=长×宽)
- 时间序列特征:滑动窗口统计
- 文本特征:TF-IDF、词嵌入
(3) 模型训练
- 数据集划分:训练集(60-80%)、验证集(10-20%)、测试集(10-20%)
- 超参数调优:网格搜索、随机搜索、贝叶斯优化
- 防止过拟合:交叉验证、早停(Early Stopping)
(4) 模型评估
| 任务类型 | 评估指标 |
|---|---|
| 分类 | 准确率、精确率、召回率、F1 Score、ROC-AUC |
| 回归 | MAE、MSE、R² |
| 聚类 | 轮廓系数、Calinski-Harabasz指数 |
四、经典算法原理
1. 线性回归(Linear Regression)
- 核心思想:找到最佳拟合直线 y = w T x + b y = w^Tx + b y=wTx+b
- 损失函数: M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum_{i=1}^n(y_i - \hat{y}_i)^2 MSE=n1∑i=1n(yi−y^i)2
- 求解方法:
- 解析解: w = ( X T X ) − 1 X T y w = (X^TX)^{-1}X^Ty w=(XTX)−1XTy (适用于小数据)
- 数值解:梯度下降(大数据场景)
2. 决策树(Decision Tree)
- 分裂准则:
- 信息增益(ID3算法)
- 基尼不纯度(CART算法)
- 剪枝策略:预剪枝(最大深度限制)、后剪枝(代价复杂度剪枝)
3. 随机森林(Random Forest)
- 核心机制:
- Bagging:通过自助采样(Bootstrap)生成多个子数据集
- 特征随机性:每个节点分裂时随机选择部分特征
- 预测方式:分类任务投票,回归任务平均
4. 支持向量机(SVM)
- 最大间隔分类器:寻找使间隔最大的超平面
- 核技巧:通过核函数将数据映射到高维空间(常用RBF核)
- 数学形式: f ( x ) = s i g n ( ∑ i = 1 n α i y i K ( x i , x ) + b ) f(x) = sign(\sum_{i=1}^n \alpha_i y_i K(x_i, x) + b) f(x)=sign(∑i=1nαiyiK(xi,x)+b)
五、实战案例解析
案例1:鸢尾花分类(监督学习)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 训练模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)# 评估
print("准确率:", model.score(X_test, y_test))
案例2:客户分群(无监督学习)
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.6)# 聚类分析
kmeans = KMeans(n_clusters=4)
clusters = kmeans.fit_predict(X)# 可视化
plt.scatter(X[:,0], X[:,1], c=clusters, cmap='viridis')
plt.show()

六、挑战与解决方案
| 常见问题 | 解决方法 |
|---|---|
| 数据不平衡 | SMOTE过采样、类别权重调整 |
| 维度灾难 | 特征选择、降维技术(PCA) |
| 过拟合 | L1/L2正则化、Dropout(神经网络) |
| 计算效率低 | 特征哈希、模型量化 |
线性回归算法
以下是线性回归的全面详解,包含基础概念、数学原理、实战应用及进阶技巧,适合零基础学习者系统掌握:
线性回归终极指南
一、核心概念全景图
二、算法深度解析
1. 数学表达形式
-
简单线性回归:
y = w 1 x + b y = w_1x + b y=w1x+b- w₁:斜率(特征权重)
- b:截距(偏置项)
-
多元线性回归:
y = w 1 x 1 + w 2 x 2 + . . . + w n x n + b y = w_1x_1 + w_2x_2 + ... + w_nx_n + b y=w1x1+w2x2+...+wnxn+b- 示例:房价 = 3.5×面积 + 1.2×卧室数 + 20
2. 损失函数可视化
均方误差(MSE):
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 MSE=n1∑i=1n(yi−y^i)2
3. 参数求解
更新规则:
w = w − α ∂ M S E ∂ w w = w - \alpha \frac{\partial MSE}{\partial w} w=w−α∂w∂MSE
b = b − α ∂ M S E ∂ b b = b - \alpha \frac{\partial MSE}{\partial b} b=b−α∂b∂MSE
学习率(α)的影响:
- 太小:收敛慢
- 太大:可能无法收敛
三、实战全流程演练
案例:预测汽车油耗(MPG)
数据集:
| 气缸数 | 排量 | 马力 | 重量 | 油耗 |
|---|---|---|---|---|
| 4 | 2.5 | 120 | 1500 | 28 |
| 6 | 3.0 | 180 | 2000 | 22 |
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# 加载数据
data = pd.read_csv('auto-mpg.csv')
X = data[['cylinders', 'displacement', 'horsepower', 'weight']]
y = data['mpg']# 数据预处理
X.fillna(X.mean(), inplace=True) # 处理缺失值
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 评估模型
print("训练集R²:", model.score(X_train, y_train))
print("测试集R²:", model.score(X_test, y_test))# 预测新数据
new_car = [[4, 2.0, 110, 1400]]
predicted_mpg = model.predict(new_car)
print("预测油耗:", predicted_mpg[0])
关键输出解读:
- 系数权重:
model.coef_显示每个特征的影响程度 - 截距:
model.intercept_表示基础油耗值 - R²分数:0.8表示模型能解释80%的数据变化
四、算法变种与改进
1. 多项式回归
处理非线性关系:
y = w 1 x + w 2 x 2 + b y = w_1x + w_2x^2 + b y=w1x+w2x2+b
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
model.fit(X_poly, y)
2. 正则化回归
| 类型 | 公式 | 特点 |
|---|---|---|
| Ridge回归 | 添加L2正则项: λ ∑ w i 2 \lambda\sum w_i^2 λ∑wi2 | 防止过拟合,保留所有特征 |
| Lasso回归 | 添加L1正则项:$\lambda\sum | w_i |
| ElasticNet | L1+L2组合 | 平衡特征选择与稳定性 |
from sklearn.linear_model import Lassolasso = Lasso(alpha=0.1) # 正则化强度
lasso.fit(X_train, y_train)
五、模型诊断与优化
1. 常见问题诊断表
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| 训练集R²高,测试集低 | 过拟合 | 增加正则化、减少特征 |
| 所有系数接近零 | 特征尺度差异大 | 数据标准化 |
| 残差不随机分布 | 非线性关系 | 添加多项式特征 |
2. 特征工程技巧
- 分箱处理:将连续年龄分段为青年/中年/老年
- 交互特征:创建面积=长×宽等组合特征
- 离散化:将温度分为低温/常温/高温
3. 超参数调优
from sklearn.model_selection import GridSearchCVparams = {'alpha': [0.001, 0.01, 0.1, 1]}
grid = GridSearchCV(Lasso(), params, cv=5)
grid.fit(X, y)
print("最佳参数:", grid.best_params_)
六、数学推导(简化版)
1. 最小二乘法推导
目标:找到使 ∑ ( y i − w x i − b ) 2 \sum(y_i - wx_i - b)^2 ∑(yi−wxi−b)2最小的w和b
求导过程:
-
对w求导:
∂ ∂ w = − 2 ∑ x i ( y i − w x i − b ) = 0 \frac{\partial}{\partial w} = -2\sum x_i(y_i - wx_i - b) = 0 ∂w∂=−2∑xi(yi−wxi−b)=0 -
对b求导:
∂ ∂ b = − 2 ∑ ( y i − w x i − b ) = 0 \frac{\partial}{\partial b} = -2\sum(y_i - wx_i - b) = 0 ∂b∂=−2∑(yi−wxi−b)=0
解得:
w = n ∑ x i y i − ∑ x i ∑ y i n ∑ x i 2 − ( ∑ x i ) 2 w = \frac{n\sum x_iy_i - \sum x_i \sum y_i}{n\sum x_i^2 - (\sum x_i)^2} w=n∑xi2−(∑xi)2n∑xiyi−∑xi∑yi
b = ∑ y i − w ∑ x i n b = \frac{\sum y_i - w\sum x_i}{n} b=n∑yi−w∑xi
愿得一心人,白头不相离。 —卓文君
相关文章:
机器学习--概览
一、机器学习基础概念 1. 定义 机器学习(Machine Learning, ML):通过算法让计算机从数据中自动学习规律,并利用学习到的模型进行预测或决策,而无需显式编程。 2. 与编程的区别 传统编程机器学习输入:规…...

低代码系统-产品架构案例介绍、炎黄盈动-易鲸云(十二)
易鲸云作为炎黄盈动新推出的产品,在定位上为低零代码产品。 开发层 表单引擎 表单设计器,包括设计和渲染 流程引擎 流程设计,包括设计和渲染,需要说明的是:采用国际标准BPMN2.0,可以全球通用 视图引擎 视图…...
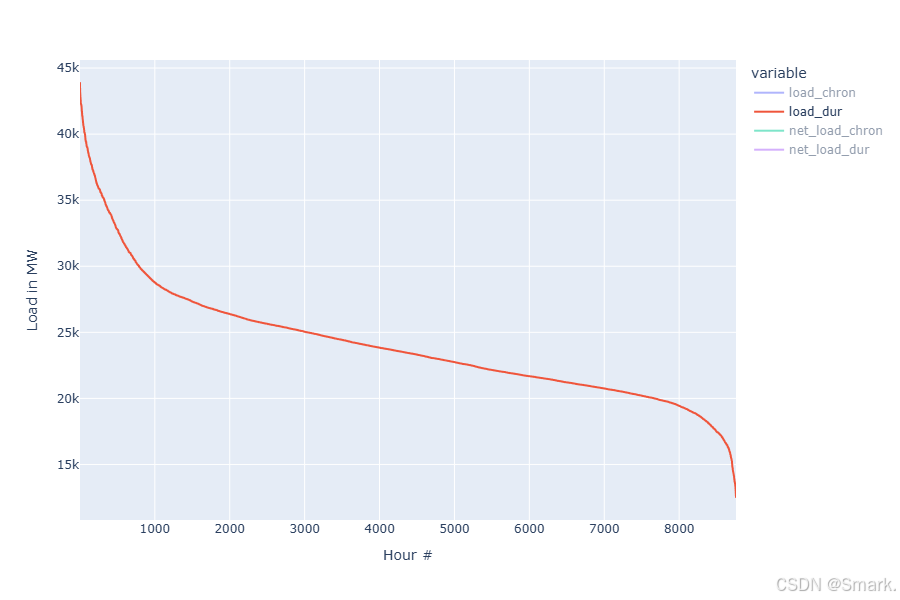
Electricity Market Optimization 探索系列(二)
本文参考链接link 负荷持续时间曲线 (Load Duration Curve),是根据实际的符合数据进行降序排序之后得到的一个曲线 这个曲线能够发现负荷在某个区间时,将会持续多长时间,有助于发电容量的规划 净负荷(net load) 是指预期负荷和预期可再生…...

OpenAI 实战进阶教程 - 第一节:OpenAI API 架构与基础调用
目标 掌握 OpenAI API 的基础调用方法。理解如何通过 API 进行内容生成。使用实际应用场景帮助零基础读者理解 API 的基本用法。 一、什么是 OpenAI API? OpenAI API 是一种工具,允许开发者通过编程方式与 OpenAI 的强大语言模型(例如 gpt-…...
TensorFlow简单的线性回归任务
如何使用 TensorFlow 和 Keras 创建、训练并进行预测 1. 数据准备与预处理 2. 构建模型 3. 编译模型 4. 训练模型 5. 评估模型 6. 模型应用与预测 7. 保存与加载模型 8.完整代码 1. 数据准备与预处理 我们将使用一个简单的线性回归问题,其中输入特征 x 和标…...

【视频+图文详解】HTML基础4-html标签的基本使用
图文教程 html标签的基本使用 无序列表 作用:定义一个没有顺序的列表结构 由两个标签组成:<ul>以及<li>(两个标签都属于容器级标签,其中ul只能嵌套li标签,但li标签能嵌套任何标签,甚至ul标…...

在Arm芯片苹果Mac系统上通过homebrew安装多版本mysql并解决各种报错,感谢deepseek帮助解决部分问题
背景: 1.苹果设备上安装mysql,随着苹果芯片的推出,很多地方都变得不一样了。 2.很多时候为了老项目能运行,我们需要能安装mysql5.7或者mysql8.0或者mysql8.2.虽然本文编写时最新的默认mysql已经是9.2版本。 安装步骤 1.执行hom…...

c++可变参数详解
目录 引言 库的基本功能 va_start 宏: va_arg 宏 va_end 宏 va_copy 宏 使用 处理可变参数代码 C11可变参数模板 基本概念 sizeof... 运算符 包扩展 引言 在C编程中,处理不确定数量的参数是一个常见的需求。为了支持这种需求,C标准库提供了 &…...
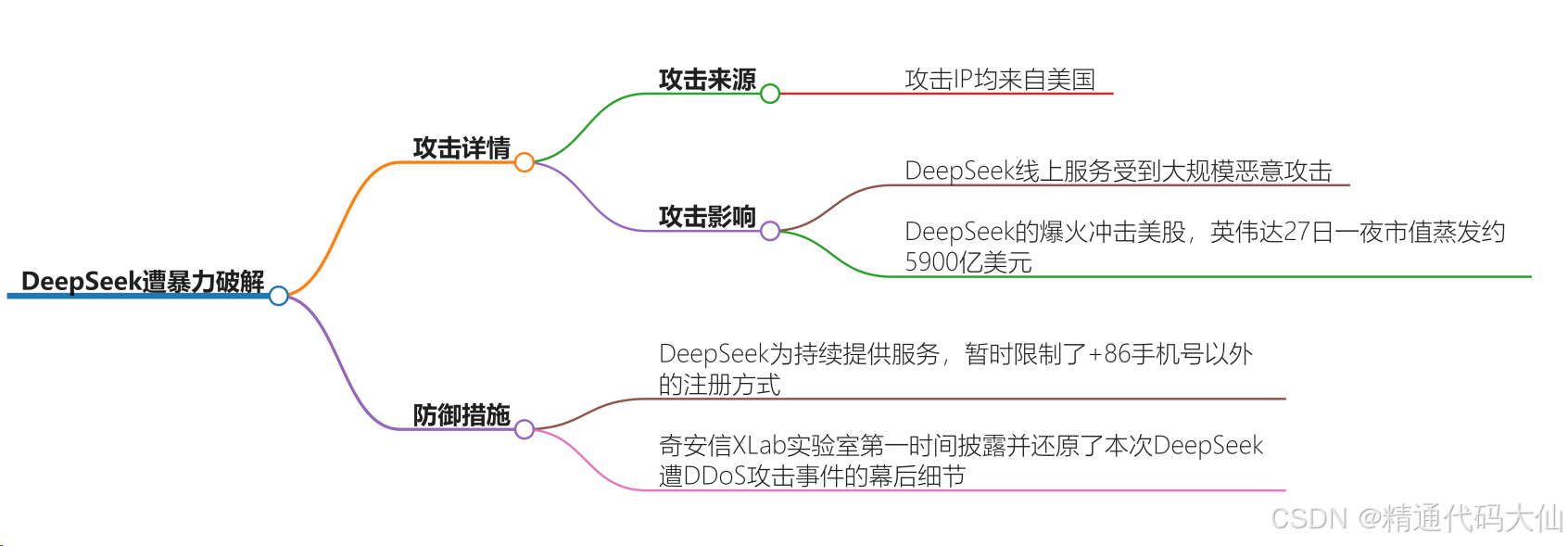
【深度分析】DeepSeek 遭暴力破解,攻击 IP 均来自美国,造成影响有多大?有哪些好的防御措施?
技术铁幕下的暗战:当算力博弈演变为代码战争 一场针对中国AI独角兽的全球首例国家级密码爆破,揭开了数字时代技术博弈的残酷真相。DeepSeek服务器日志中持续跳动的美国IP地址,不仅是网络攻击的地理坐标,更是技术霸权对新兴挑战者的…...
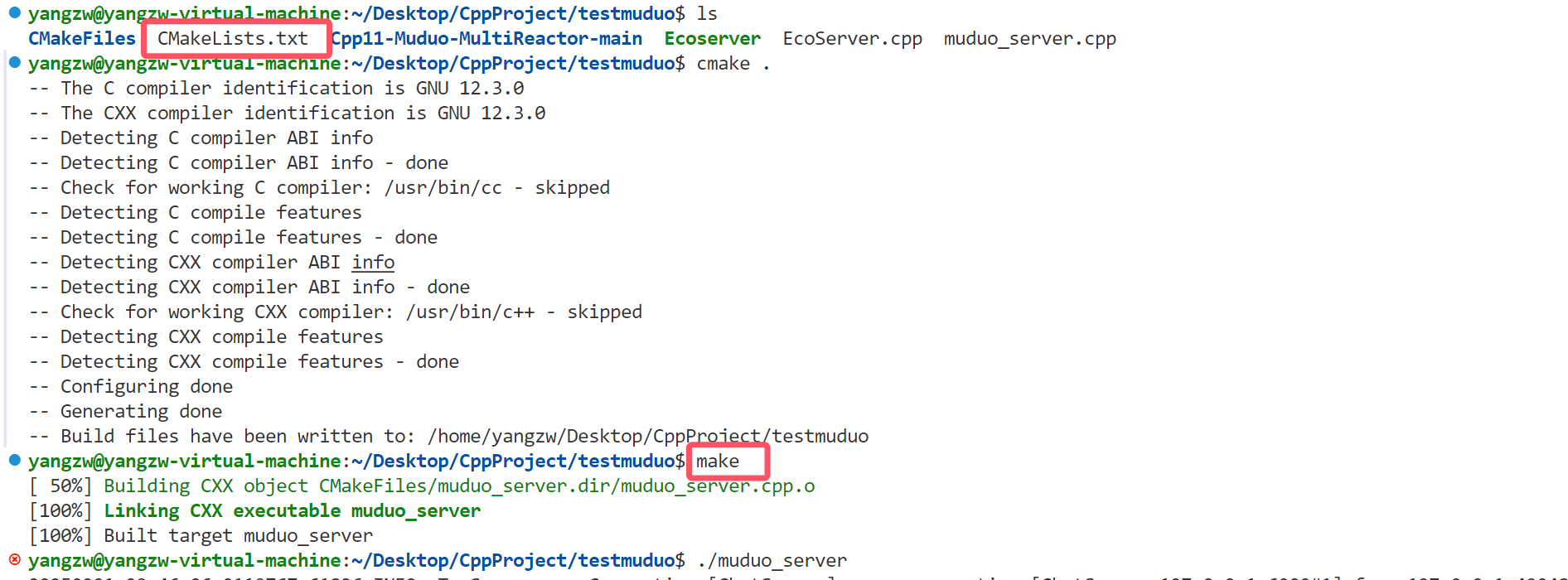
CMake项目编译与开源项目目录结构
Cmake 使用简单方便,可以跨平台构建项目编译环境,尤其比直接写makefile简单,可以通过简单的Cmake生成负责的Makefile文件。 如果没有使用cmake进行编译,需要如下命令:(以muduo库echo服务器为例)…...

完全卸载mysql server步骤
1. 在控制面板中卸载mysql 2. 打开注册表,运行regedit, 删除mysql信息 HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->EventLog->Application->Mysql HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->Mysql …...
)
C#方法(练习)
1.定义一个函数,输入三个值,找出三个数中的最小值 2.定义一个函数,输入三个值,找出三个数中的最大值 3.定义一个函数,输入三个值,找出三个数中的平均值 4.定义一个函数,计算一个数的 N 次方 Pow(2, 3)返回8 5.传入十一…...
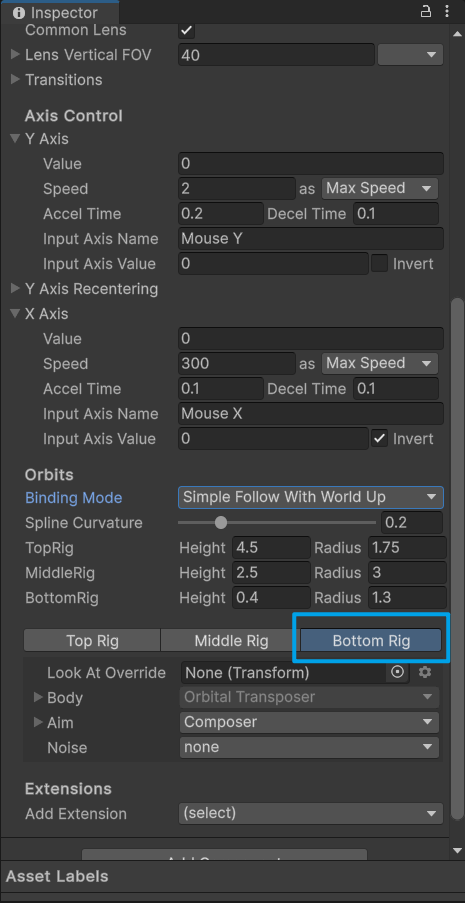
Unity游戏(Assault空对地打击)开发(3) 摄像机的控制
详细步骤 打开My Assets或者Package Manager。 选择Unity Registry。 搜索Cinemachine,找到 Cinemachine包,点击 Install按钮进行安装。 关闭窗口,新建一个FreeLook Camera,如下。 接着新建一个对象Pos,拖到Player下面…...

ChatGPT-4o和ChatGPT-4o mini的差异点
在人工智能领域,OpenAI再次引领创新潮流,近日正式发布了其最新模型——ChatGPT-4o及其经济实惠的小型版本ChatGPT-4o Mini。这两款模型虽同属于ChatGPT系列,但在性能、应用场景及成本上展现出显著的差异。本文将通过图文并茂的方式࿰…...

SQL进阶实战技巧:某芯片工厂设备任务排产调度分析 | 间隙分析技术应用
目录 0 技术定义与核心原理 1 场景描述 2 数据准备 3 间隙分析法 步骤1:原始时间线可视化...

【力扣】438.找到字符串中所有字母异位词
AC截图 题目 思路 我一开始是打算将窗口内的s子字符串和p字符串都重新排序,然后判断是否相等,再之后进行窗口滑动。不过缺点是会超时。 class Solution { public:vector<int> findAnagrams(string s, string p) {vector<int> vec;if(s.siz…...
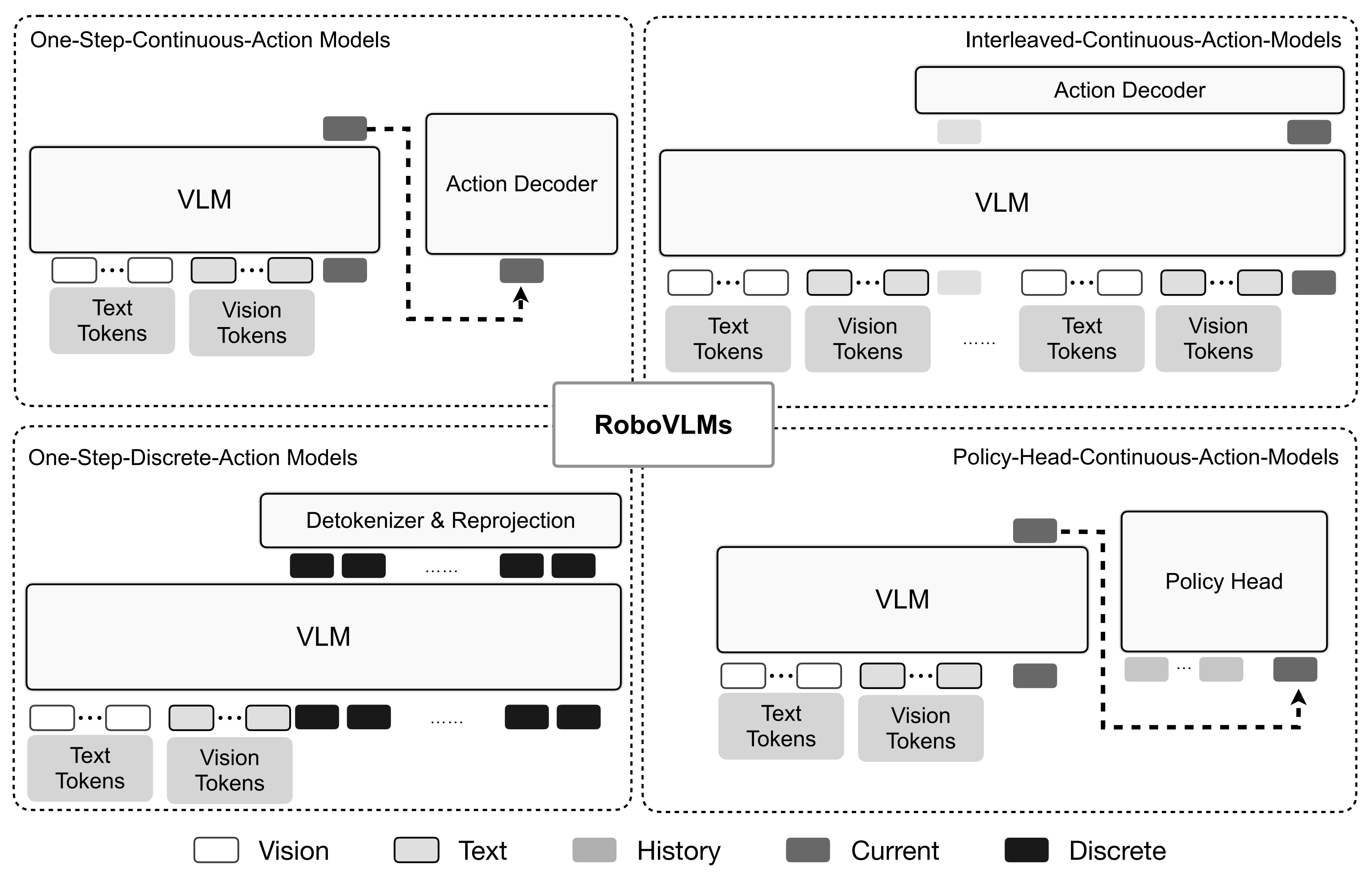
2024具身智能模型汇总:从训练数据、动作预测、训练方法到Robotics VLM、VLA
前言 本文一开始是属于此文《GRAPE——RLAIF微调VLA模型:通过偏好对齐提升机器人策略的泛化能力》的前言内容之一(该文发布于23年12月底),但考虑到其重要性,加之那么大一张表格 看下来 阅读体验较差,故抽出取来独立成文且拆分之 …...

Day33【AI思考】-函数求导过程 的优质工具和网站
文章目录 **函数求导过程** 的优质工具和网站**一、动态图形工具**1. **Desmos(网页端)**2. **GeoGebra(全平台)** **二、分步推导工具**3. **Wolfram Alpha(网页/App)**4. **Symbolab(网页/App…...
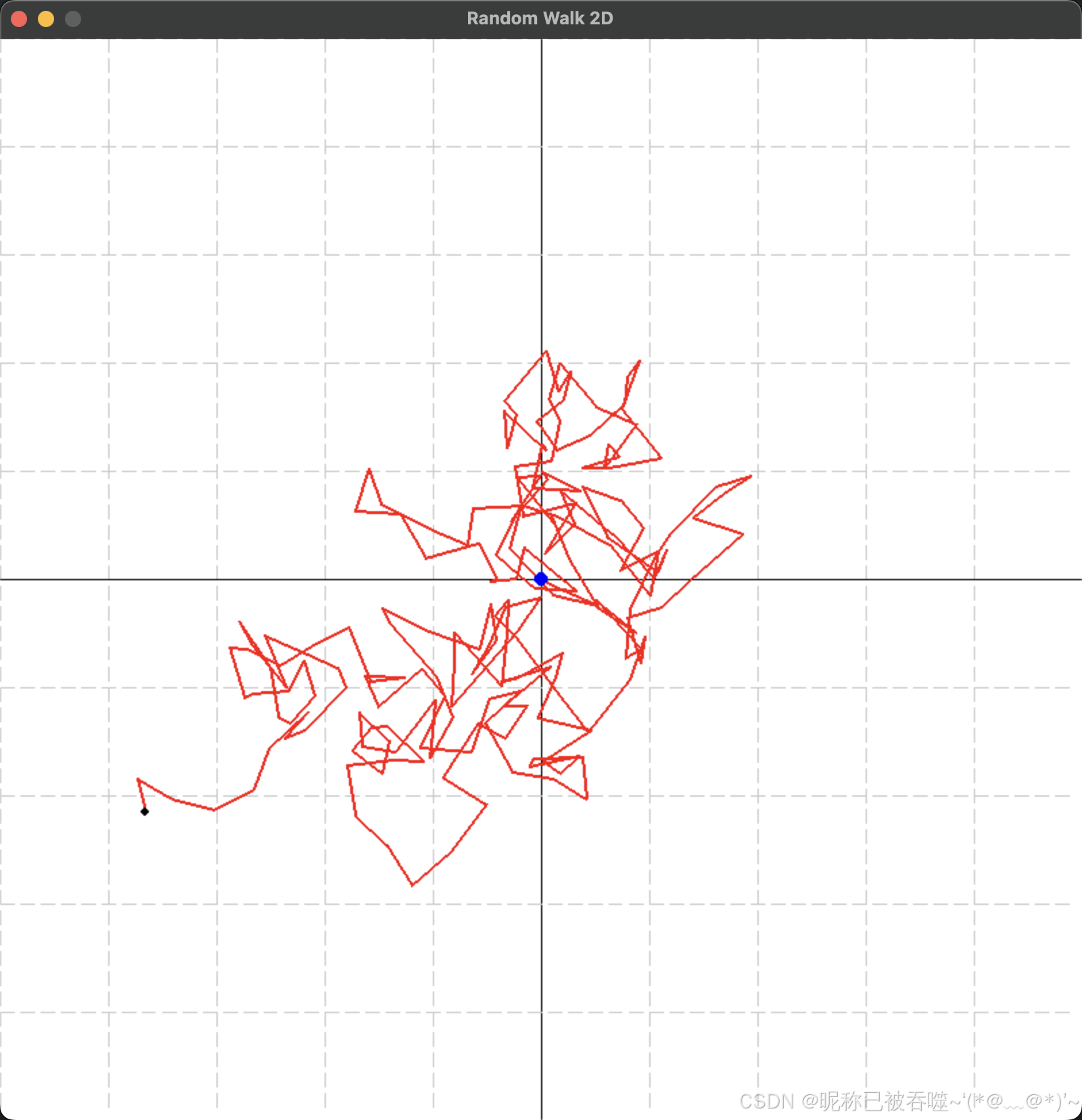
【URL】一个简单基于Gym的2D随机游走环境,用于无监督强化学习(URL)
import gym from gym import spaces import numpy as np import pygameclass RandomWalk2DEnv(gym.Env):def __init__(self):super(RandomWalk2DEnv, self).__init__()# 定义状态空间为2D坐标(x, y)self.x_min, self.x_max -10, 10 # 更新尺寸为 (-10,…...

【VM】VirtualBox安装ubuntu22.04虚拟机
阅读本文之前,请先根据 安装virtualbox 教程安装virtulbox虚拟机软件。 1.下载Ubuntu系统镜像 打开阿里云的镜像站点:https://developer.aliyun.com/mirror/ 找到如图所示位置,选择Ubuntu 22.04.3(destop-amd64)系统 Ubuntu 22.04.3(desto…...

猫抓插件:浏览器资源嗅探的革命性解决方案
猫抓插件:浏览器资源嗅探的革命性解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾在浏览网页时,看到心仪的…...

3步打造自平衡机器人:零基础实战DIY攻略
3步打造自平衡机器人:零基础实战DIY攻略 【免费下载链接】Cubli_Mini 项目地址: https://gitcode.com/gh_mirrors/cu/Cubli_Mini 自平衡机器人作为 robotics 领域的经典项目,一直是爱好者入门的理想选择。Cubli_Mini 作为开源项目中的佼佼者&…...

掌握5个核心配置技巧:OpenCore-Configurator从入门到专家
掌握5个核心配置技巧:OpenCore-Configurator从入门到专家 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator OpenCore-Configurator(简称…...
)
Unity UGUI实战:手把手教你打造一个可拖拽、可弯曲的UI连线组件(附完整源码)
Unity UGUI实战:打造可拖拽、可弯曲的智能连线系统 在游戏开发中,可视化连接系统是构建技能树、流程图、科技树等复杂UI结构的核心组件。传统实现往往局限于静态线条或简单的直线连接,缺乏交互性和动态美感。本文将带你从零构建一个支持实时拖…...

GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒
GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒摘要 GG3M的贝叶斯更新与决策数学体系,基于原创“事实层—模型层—元模型层”三层级架构,以系统长期反熵增演化为核心决策标尺,从“智能参数优化”跨越至“智慧框架迭代”…...

CLIP-GmP-ViT-L-14算力适配:自动检测CUDA版本并加载对应优化内核
CLIP-GmP-ViT-L-14算力适配:自动检测CUDA版本并加载对应优化内核 1. 引言:当高性能模型遇见复杂环境 如果你部署过AI模型,大概率遇到过这样的场景:好不容易把模型跑起来了,却发现速度慢得让人抓狂,或者干…...
)
药物研发新思路:共价对接工具AutoDock4实战指南(附避坑技巧)
药物研发新思路:共价对接工具AutoDock4实战指南(附避坑技巧) 在当今药物研发领域,共价抑制剂因其独特的作用机制和显著的治疗优势正受到前所未有的关注。与传统非共价药物相比,这类分子能与靶蛋白形成稳定的共价键&…...

Windows系统效能优化指南:基于Win11Debloat的系统调校方案
Windows系统效能优化指南:基于Win11Debloat的系统调校方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

GD32F4xx GPIO实战:用按键控制LED,详解输入输出配置与防抖处理
GD32F4xx GPIO实战:从按键消抖到LED控制的完整设计指南 在嵌入式开发中,GPIO(通用输入输出)是最基础却至关重要的外设模块。对于GD32F4xx系列微控制器而言,掌握GPIO的高效配置不仅关乎功能实现,更直接影响系…...

微信聊天记录永久保存终极指南:WeChatMsg免费工具完整解决方案
微信聊天记录永久保存终极指南:WeChatMsg免费工具完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...