Kafka分区策略实现
引言
Kafka 的分区策略决定了生产者发送的消息会被分配到哪个分区中,合理的分区策略有助于实现负载均衡、提高消息处理效率以及满足特定的业务需求。
轮询策略(默认)
- 轮询策略是 Kafka 默认的分区策略(当消息没有指定键时)。生产者会按照顺序依次将消息发送到各个分区中,确保每个分区都能均匀地接收到消息,从而实现负载均衡。简单高效,能使各个分区的消息量相对均衡,充分利用每个分区的存储和处理能力。
-
import org.apache.kafka.clients.producer.*; import java.util.Properties;public class RoundRobinProducer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("testTopic", "message-" + i);producer.send(record);}producer.close();} }随机策略
- 随机策略会随机地将消息分配到一个分区中。这种策略在某些情况下可以实现一定程度的负载均衡,但由于是随机分配,可能会导致分区之间的消息分布不够均匀。可以通过自定义分区器来实现随机策略。
-
import org.apache.kafka.clients.producer.*; import java.util.List; import java.util.Map; import java.util.Random;public class RandomPartitioner implements Partitioner {private final Random random = new Random();@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);return random.nextInt(partitions.size());}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {} }// 使用随机分区器的生产者示例 public class RandomProducer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("partitioner.class", "RandomPartitioner");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("testTopic", "message-" + i);producer.send(record);}producer.close();} }按键哈希策略
- 当消息指定了键时,Kafka 会根据键的哈希值将消息分配到特定的分区中。相同键的消息会被分配到同一个分区,这有助于保证具有相同业务逻辑的消息顺序性。可以保证消息的局部有序性,例如在处理用户相关的消息时,将同一个用户的消息发送到同一个分区,方便后续的处理和分析。
-
import org.apache.kafka.clients.producer.*; import java.util.Properties;public class KeyBasedProducer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("testTopic", "user-" + (i % 2), "message-" + i);producer.send(record);}producer.close();} }自定义分区策略(实现接口)
-
当上述默认策略无法满足业务需求时,可以自定义分区策略。通过实现
org.apache.kafka.clients.producer.Partitioner接口,重写partition方法来实现自定义的分区逻辑。例如,根据消息的某些特定字段(如时间、地理位置等)来进行分区,以满足特定的业务需求。 -
import org.apache.kafka.clients.producer.*; import java.util.List; import java.util.Map;public class CustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);// 自定义分区逻辑,这里简单示例根据消息值的长度分区String message = (String) value;return message.length() % partitions.size();}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {} }// 使用自定义分区器的生产者示例 public class CustomProducer {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("partitioner.class", "CustomPartitioner");Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("testTopic", "message-" + i);producer.send(record);}producer.close();} }
相关文章:

Kafka分区策略实现
引言 Kafka 的分区策略决定了生产者发送的消息会被分配到哪个分区中,合理的分区策略有助于实现负载均衡、提高消息处理效率以及满足特定的业务需求。 轮询策略(默认) 轮询策略是 Kafka 默认的分区策略(当消息没有指定键时&…...

【归属地】批量号码归属地查询按城市高速的分流,基于WPF的解决方案
在现代商业活动中,企业为了提高营销效果和资源利用效率,需要针对不同地区的市场特点开展精准营销。通过批量号码归属地查询并按城市分流,可以为企业的营销决策提供有力支持。 短信营销:一家连锁餐饮企业计划开展促销活动…...

为AI聊天工具添加一个知识系统 之78 详细设计之19 正则表达式 之6
本文要点 要点 本项目设计的正则表达式 是一个 动态正则匹配框架。它是一个谓词系统:谓词 是运动,主语是“维度”,表语是 语言处理。主语的一个 双动结构。 Reg三大功能 语法验证、语义检查和 语用检验,三者 :语义约…...

使用Java操作Redis数据类型的详解指南
SEO Meta Description: 详细介绍如何使用Java操作Redis的各种数据类型,包括字符串、哈希、列表、集合和有序集合,提供代码示例和最佳实践。 介绍 Redis是一种开源的内存数据结构存储,用作数据库、缓存和消息代理。它支持多种数据结构&#…...

一表总结 Java 的3种设计模式与6大设计原则
设计模式通常分为三大类:创建型、结构型和行为型。 创建型模式:主要用于解决对象创建问题结构型模式:主要用于解决对象组合问题行为型模式:主要用于解决对象之间的交互问题 创建型模式 创建型模式关注于对象的创建机制…...

Hive on Spark优化
文章目录 第1章集群环境概述1.1 集群配置概述1.2 集群规划概述 第2章 Yarn配置2.1 Yarn配置说明2.2 Yarn配置实操 第3章 Spark配置3.1 Executor配置说明3.1.1 Executor CPU核数配置3.1.2 Executor内存配置3.1.3 Executor个数配置 3.2 Driver配置说明3.3 Spark配置实操 第4章 Hi…...
)
Java集合面试总结(题目来源JavaGuide)
问题1:说说 List,Set,Map 三者的区别? 在 Java 中,List、Set 和 Map 是最常用的集合框架(Collection Framework)接口,它们的主要区别如下: 1. List(列表) 特点…...
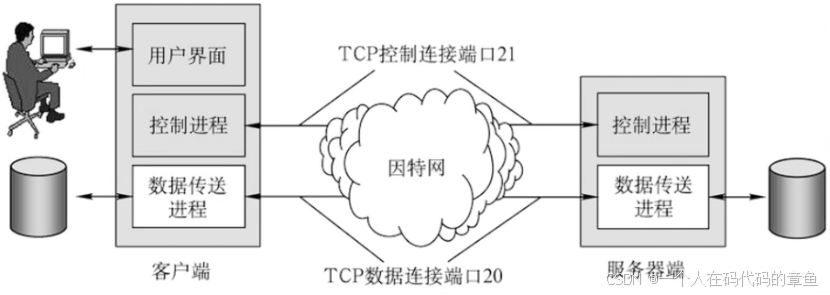
计算机网络 应用层 笔记1(C/S模型,P2P模型,FTP协议)
应用层概述: 功能: 常见协议 应用层与其他层的关系 网络应用模型 C/S模型: 优点 缺点 P2P模型: 优点 缺点 DNS系统: 基本功能 系统架构 域名空间: DNS 服务器 根服务器: 顶级域…...

ES6基础内容
ES 全称 EcmaScript ,是脚本语言的规范,而平时经常编写的 JavaScript 是 EcmaScript 的一种实现,所以 ES 新特性其实指的就是 JavaScript 的新特性。 一、 let变量声明和声明特性 1.1 变量声明 <!DOCTYPE html> <html lang"en">…...

DeepSeek本地部署的一些使用体会
春节期间我也尝试了一下Deepseek的本地部署,方案选用了Ollama Chatbox或AnythingLLM。Chatbox里有很多有意思的“助手”,而AnythingLLM支持本地知识库。 网上教程很多,总的来说还是很方便的,不需要费太多脑子。甚至可以这么说&a…...

鲸鱼算法 matlab pso
算法原理 鲸鱼优化算法的核心思想是通过模拟座头鲸的捕食过程来进行搜索和优化。座头鲸在捕猎时会围绕猎物游动并产生气泡网,迫使猎物聚集。这一行为被用来设计搜索策略,使算法能够有效地找到全局最优解。 算法步骤 初始化:随机生成一…...

013-51单片机红外遥控器模拟控制空调,自动制冷制热定时开关
主要功能是通过红外遥控器模拟控制空调,可以实现根据环境温度制冷和制热,能够通过遥控器设定温度,可以定时开关空调。 1.硬件介绍 硬件是我自己设计的一个通用的51单片机开发平台,可以根据需要自行焊接模块,这是用立创…...

在Vue3 + Vite 项目中使用 Tailwind CSS 4.0
文章目录 首先是我的package.json根据官网步骤VS Code安装插件验证是否引入成功参考资料 首先是我的package.json {"name": "aplumweb","private": true,"version": "0.0.0","type": "module","s…...

Leetcode—922. 按奇偶排序数组 II【简单】
2025每日刷题(207) Leetcode—922. 按奇偶排序数组 II 实现代码 class Solution { public:vector<int> sortArrayByParityII(vector<int>& nums) {for(int i 0, j 1; i < nums.size() - 1; i 2) {// 前奇后偶if(nums[i] % 2) {w…...

一个开源 GenBI AI 本地代理(确保本地数据安全),使数据驱动型团队能够与其数据进行互动,生成文本到 SQL、图表、电子表格、报告和 BI
一、GenBI AI 代理介绍(文末提供下载) github地址:https://github.com/Canner/WrenAI 本文信息图片均来源于github作者主页 在 Wren AI,我们的使命是通过生成式商业智能 (GenBI) 使组织能够无缝访问数据&…...

使用Posix共享内存区实现进程间通信
使用Posix共享内存区实现进程间通信 使用Posix共享内存区通常涉以下步骤: 进程A 调用shm_open 创建共享内存区进程A调用ftruncate修改共享内存区大小进程A 调用mmap将共享内存区映射到进程地址空间ptrA进程A 使用ptrA对共享内存区进程更改进程B 使用shm_open打开已有共享内存…...

家政预约小程序12服务详情
目录 1 修改数据源2 创建页面3 搭建轮播图4 搭建基本信息5 显示服务规格6 搭建服务描述7 设置过滤条件总结 我们已经在首页、分类页面显示了服务的列表信息,当点击服务的内容时候需要显示服务的详情信息,本篇介绍一下详情页功能的搭建。 1 修改数据源 在…...

【C语言】指针详细解读2
1.const 修饰指针 1.1 const修饰变量 变量是可以修改的,如果把变量的地址交给⼀个指针变量,通过指针变量的也可以修改这个变量。 但是如果我们希望⼀个变量加上⼀些限制,不能被修改,怎么做呢?这就是const的作⽤。 #in…...

MongoDB 聚合
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。 有点类似 SQL 语句中的 count(*)。 aggregate() 方法 MongoDB中聚合的方法使用aggregate()。 语法 aggregate() 方法的基本语法格式如下所示࿱…...

LabVIEW涡轮诊断系统
一、项目背景与行业痛点 涡轮机械是发电厂、航空发动机、石油化工等领域的核心动力设备,其运行状态直接关系到生产安全与经济效益。据统计,涡轮故障导致的非计划停机可造成每小时数十万元的经济损失,且突发故障可能引发严重安全事故。传统人…...

别再只靠EWSA了!聊聊WPA密码破解的几种姿势与效率对比
WPA密码破解工具全维度评测:从EWSA到Hashcat的实战指南 在无线安全评估领域,WPA/WPA2密码破解始终是绕不开的技术课题。当安全研究员获得合法授权的握手包后,如何高效完成密码恢复任务?市面上既有EWSA这样的老牌图形化工具&#x…...

BIOS里找不到SSD硬盘?Win10启动失败?可能是ESP引导分区‘隐身’了,手把手教你用PE盘和DiskGenius把它找回来
BIOS里找不到SSD硬盘?Win10启动失败?可能是ESP引导分区‘隐身’了 最近遇到一个奇怪的故障:明明SSD硬盘在PE系统里能正常识别,但BIOS启动项里却死活找不到它。系统反复提示"reboot and select proper boot device"&…...

Oracle数据库深度解析:从入门到精通的全面指南
在当今数据驱动的时代,数据库管理系统(DBMS)已成为企业信息化建设的核心。作为全球领先的商业数据库产品,Oracle数据库凭借其卓越的性能、高可用性和强大的扩展能力,长期占据市场主导地位。本文将为您带来一份从入门到…...

从理论到落地,一文读懂现代AI Agent的完整记忆流水线
来源:DeepHub IMBA 本文约6500字,建议阅读13分钟本文介绍 AI Agent 四大记忆分类与流水线,解析生产架构、选型方案及常见落地误区。每一次 LLM 调用都是无状态的。模型读上下文窗口,生成响应然后忘掉一切。这对单轮问答没问题。对…...

别再傻傻分不清了!VB、VBS、VBA到底该用哪个?从Excel自动化到网页脚本的实战选择指南
VB、VBS与VBA实战指南:从Excel自动化到系统脚本的精准选择 每次打开Excel准备处理数据时,你是否纠结过该用VBA还是VBS?当需要批量重命名文件时,是否犹豫过VB和VBS哪个更高效?这三种看似相似的"VB系"语言&am…...

FanControl深度解析:Windows上最强大的风扇控制软件终极指南
FanControl深度解析:Windows上最强大的风扇控制软件终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...

MyBatis 二级缓存脏读真实原因
很多同学熟悉 MyBatis 一级缓存、二级缓存基础用法,但多表联查、跨Mapper更新场景下的缓存脏读漏洞,90%的人都会踩坑。 本文结合完整实战案例,用大白话拆解:脏读如何产生、一级缓存二级缓存双重隐患、Namespace隔离缺陷࿰…...

如何快速导出API账单数据?New API 数据导出功能完整指南
如何快速导出API账单数据?New API 数据导出功能完整指南 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...

04 - 运行 rocrtst 第一个测试
本文档帮助你成功运行 rocrtst 的第一个测试,并掌握各种运行方式。 1. 运行前检查清单 在运行测试之前,确认以下条件: # ✅ 1. rocrtst64 已构建并安装 ls $ROCM_PREFIX/bin/rocrtst64# ✅ 2. GPU kernel 已编译(检查你的 GPU …...
PyVideoTrans:3步实现视频AI翻译配音,支持30+AI模型的完整解决方案
PyVideoTrans:3步实现视频AI翻译配音,支持30AI模型的完整解决方案 【免费下载链接】pyvideotrans Translate the video from one language to another and embed dubbing & subtitles. 项目地址: https://gitcode.com/gh_mirrors/py/pyvideotrans …...