javaEE-8.JVM(八股文系列)
目录
一.简介
二.JVM中的内存划分
JVM的内存划分图:
堆区:编辑
栈区:编辑
程序计数器:编辑
元数据区:编辑
经典笔试题:
三,JVM的类加载机制
1.加载:
2.验证:
3.准备:
4.解析:
5.初始化:
双亲委派模型
概念:
JVM的类加载器 默认有三种:
双亲委派模型的工作流程:
四.JVM的垃圾回收机制(GC)
垃圾回收步骤:
1.识别出垃圾
1)引用计数
2)可达性分析
2.把标记为垃圾的对象的内存空间进行释放
1)标记-清除:
2)复制算法
3)标记整理
分带回收
一.简介
JVM : java Virtual Machine 的简称,意为Java虚拟机。
虚拟机是指通过软件模拟的具有完整硬件功能的、运⾏在⼀个完全隔离的环境中的完整计算机系统。常⻅的虚拟机:JVM、VMwave、Virtual Box。
JVM 和其他两个虚拟机的区别:
1. VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统中会有很多的寄存器;
2. JVM则是通过软件模拟Java字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进⾏了裁剪。
JVM 是⼀台被定制过的现实当中不存在的计算机。

java的执行流程是:先通过javac 将.java文件转为.class(字节码文件)文件,之后在某个平台执行;然后 通过JVM 将.class文件转换为CPU能识别的机器指令。
因此,编写一个java程序,只需要发布.class文件就行了。JVM拿到.class文件,就知道该如何转换了.
二.JVM中的内存划分
JVM也相当于一个进程,在启动一个java程序后,需要个JVM分配资源空间.
JVM从系统中申请的内存,会根据java程序中不同的使用途径,为其分配空间.这就是内存划分.
JVM会将申请到的空间划分成几个区域,每个区域有不同的功能,
JVM的内存划分图:

堆区:
存放的是代码中new出来的对象,对象中的非静态成员也在堆区.
栈区:
包含了一些方法调用关系和局部变量.
由本地方法栈和虚拟机栈组成,本地方法栈是JVM内部,是由C++写的;虚拟机栈保存了一些java的方法调用和局部变量。
平时所说的栈区,指的是虚拟机栈,
程序计数器:
这个区域比较小,专门用来保存下一条要执行的java指令的地址。
元数据区:
包含了一些辅助性质的,描述性质的属性。元数据区也叫做方法区。
元数据是计算机中的一个常见术语(Meta data)。
对于硬盘来说,不仅要存储文件的数据本体,还要存储一些辅助信息,像文件的大小,文件的位置,文件的使用权限,文件的拥有者....这些都称为“元数据”。
一个程序中,有哪些类,有哪些方法,每个方法中有哪些指令,....这些信息都会保存在JVM的元数据区.

对于堆区和元数据区,整个进程中只有一份;而对于栈区和程序计数区,在内存中是有很多份的.
经典笔试题:
class Test {private int n;private static int m;
}
public static void main(String args[]){Test t = new Test();
}问: n,m,t 都在哪块JVM的哪个内存区域中?
n属于局部变量,在作用域中生效,出作用域就销毁了,存在栈区.
m:属于静态变量,存在元数据区。
t:是new出来了一个Test对象,t中保存的是Test的地址,属于局部变量,保存在栈区;而Test对象则保存在堆区.

区分变量在内存的哪个区域上,最重要的就是确定该变量的"形态",是 局部变量/成员变量/静态变量....
三,JVM的类加载机制
类加载指的是JVM把.class文件从硬盘读取到内存,进行一系列的校验解析的过程.转换成类对象的过程.
类加载过程大致分为五步:
1.加载:
把.class文件找到并打开,读取到文件中的内容.
2.验证:
需要确定当前读到的文件是合法的.class文件(字节码文件).否则若读到错误的文件,后面的工作就白费了.
具体的验证依据是在java的虚拟机规范中,有明确的格式说明:

左面这一列是类型,右面这一列是名字.
![]() :
:
也叫做:magic number 魔幻数字,用来标识二进制文件中的格式的类型.
![]() :
:
这两个都是版本号,u4 是主版本,u2 是次版本.属于JVM内部的版本,JVM会验证.class文件的版本号是否符合要求.
一般来说 高版本的JVM可以运行低版本的.class文件,反之不行.
3.准备:
为类对象申请内存空间.此时申请到的内存空间都为默认值 为全0的.
4.解析:
主要是针对类中的字符串常量进行处理.
将常量池中的 符号引用 替换为 直接引用 的过程,也就是初始化常量的过程.
我们知道,在.class文件中,是不存在地址的,而对于创建的字符串常量,变量中保存的是常量的地址,这又是怎样记录的呢?
class Test{private String s="hello";
}这个hello在.class文件中,是否会保存呢?
当然是要保存的,只不过s中保存的是一个字符串常亮的"偏移量".

在文件中,不存在地址这样的概念,地址是内存的地址,而文件是在硬盘中的.
为了保存字符串常来那个,可以存储一个"偏移量"的概念, 这里的偏移量就认为是符号引用.
之后,把.class文件加载到内存中,就有地址了,s中的值就能根据偏移量来转换为真正地址了,也就是直接引用.
5.初始化:
针对类对象,完成后续的初始化操作.
执行静态代码块,构造方法,还可能触发父类加载.....
双亲委派模型
在类加载过程的第一步:加载环节中使用 双亲委派模型 描述如何查找.class文件的策略.
JVM在进行类加载的时候,有一个专门的模块,称为"类加载器".(ClassLoader)
概念:
双亲委派模型: 如果一个类加载器收到一个类加载的请求,他首先不会自己加载该类,而是将这个类委派给父类加载器,让父类加载器去完成对类的加载.每层次的类加载器都是这样委派,最终所有的加载请求都会到达 最顶层的类加载器,直到当父类加载器反馈自己无法完成这个类加载请求时,子类加载器就会尝试自己完成加载.
JVM的类加载器 默认有三种:
BootstrapClassLoader: 负责查找标准库目录.
ExtensionClassLoader: 负责查找扩展库目录.
ApplicationClassLoader: 负责查找当前项目的代码目录,以及第三方库.
这三个类加载器存在父子类(二叉树关系)关系.
ApplicationClassLoader的父类是ExtensionClassLoader;
ExtensionClassLoader的父类是BootstrapClassLoader,BootstrapClassLoader属于顶层父类。
双亲委派模型的工作流程:
1.类加载任务先从ApplicationClassLoader为入口,开始工作;
2.ApplicationClassLoader自己不会立即搜索自己负责的目录,会将搜索的任务向上传递给父类;
3.代码进入ExtensionClassLoader的范畴,同样,ExtensionClassLoader 也不是立即搜索自己负责的目录,继续将搜索的任务向父类传递;
4.代码进入BootstrapClassLoader的范畴,由于BootstrapClassLoader是顶级父类了,就会真正进行负责搜索目录(标准库目录),尝试在标准库目录中找到符合要求的.Class文件;
5.若是找到了,就会进入打开文件,读文件流程了,此时类加载步骤就结束了;若是没有找到,就会返回到子类的类加载器中,继续尝试加载。
6.若是在ExtensionClassLoader类加载器中找到符合要求的.Class文件,此时类加载步骤就结束了;若还未找到,就会返回给子类加载器ApplicationClassLoader继续尝试加载.
7.若在ApplicationClassLoader类加载器中搜索到了,此时类加载就结束了,就会进入后续流程;若是没有找到,就会继续向子类寻找,由于ApplicationClassLoader是底层了,就表示类加载失败了.

这一系列的列加载机制,目的是为了保证这几个类加载器的优先级顺序.
这个类加载器是系统默认的类加载机制,也可以自己实现类加载机制,可以与默认机制不同.
四.JVM的垃圾回收机制(GC)
垃圾回收指的是让程序自动回收内存,JVM中的内存分为好几种,要回收的是堆区的内存;
元数据区和程序计数区的内存不需要回收,栈区中存放的都是局部变量申请的内存,在代码结束后,会自动销毁(属于栈区自己的特点,和垃圾回收没有关系)。

回收内存其实就是回收对象,垃圾回收时,将堆区上的若干个对象释放掉。
堆区内存根据垃圾回收,又分为三类区间:

垃圾回收步骤:
1.识别出垃圾
要判定哪些对象是垃圾,哪些对象不是垃圾。就是判断该对象是否还需要使用。
在java中,使用对象,一定是通过引用指向使用对象的方式使用,若该对象没有引用指向,则表示该对象不再被使用,就可以进行垃圾回收了。
class Test{
....
}
void func(){
Test t = new Test(); }这个代码中,执行结束后,t属于局部变量,存在于栈区,会被直接释放掉,Test对象在执行完后,由于没有对象指向了,也就属于垃圾了,就会被垃圾回收。
对于一些更复杂的代码,判定过程也就更加复杂。
Test t1 = new Test();
Test t2 = t1;
Test t3 = t2;
Test t4=t3;
....很多引用都指向了同一个对象Test,只有当所用的引用都结束了,才能释放Test对象,但每个引用的生命周期又不一样,就很难判断了。
于是又设计一些方法来记录对象的引用:
1)引用计数
给每个对象再分配一个额外的空间,保存当前对象引用个数,当有一个引用指向了该对象,引用计数就+1,一个引用结束后,引用计数就-1.
此时的垃圾回收机制就是:有一个专门的扫描线程,取获取每个对象的引用计数的情况,当引用计数为0时,就表示该对象没有引用指向了,不再使用了,也就可以释放了。
class Test {....
}
void func() {
Test t1 = new Test();
Test t2 = t1;
}这个代码的内存分配:

引用计数 存在的问题:
1)耗费额外的空间:
引用计数需要耗费一个额外的空间,若对象本身占用的内存就比较小,总的对象数目有很多,那么总的消耗空间就会非常多。
2)可能出现“循环引用问题”:
class Test{Test t;
}
Test t1 = new Test();
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
t1 = null;
t2 = null;当t1和t2还未被置为null的时候,此时的内存是这样的情况:

当t1和t2都被置为null后,t1,t2内存被释放,但Test对象中的t还未被释放:
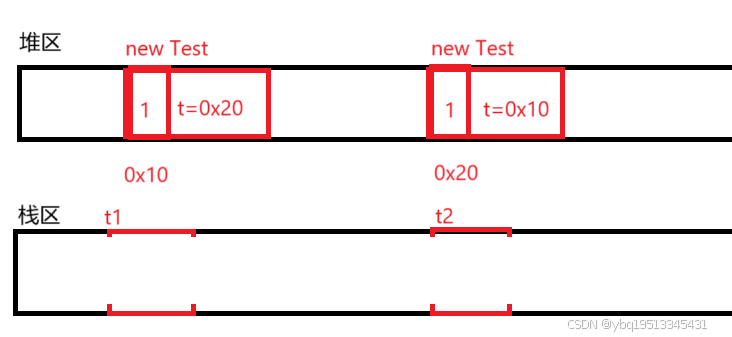
此时,Test是的引用计数还都不0,不能被GC回收,但又无法使用,就产生了循环引用问题,这种情况下的引用计数就无法被正常使用了。
引用计数 这种思想 并未在java中使用,在别的语言的垃圾回收机制中有使用到。
2)可达性分析
(JVM的垃圾回收机制 识别垃圾 采用的是这种思想)
可达性分析本质上是采用“时间”换“空间”的方法。
相较于 引用计数,可达性分析要消耗更多的时间去“遍历”,不会存在上面 引用计数 中的问题。
可达性分析:一个java代码中,会定义很多变量,从这些变量为起点,向下“遍历”:从这些变量中持有的引用类型的成员,再向下遍历,所有能被访问到的对象,一定不是垃圾了,而未被访问到的对象,就是垃圾了,要被就行回收。
JVM自身有扫描线程,会不停地扫描代码,看是否有对象无法被遍历到;JVM本身是知道一共有多少个对象的。
class Node{char root;Node left;Node right;
}
Node BuildNode{
Node a = new Node();
Node b = new Node();
Node c = new Node();
Node d = new Node();
Node e = new Node();
Node f = new Node();
Node g = new Node();
a.left = b;
a.right = c;
b.left = d;
b.right = e;
c.right = f;
e.left = g;
}
public static void main(String args[]){
Node root = BuildNode();
}代码中的树是这个样子,

在这个代码中,虽然只有一个root这样的引用,但实际上有7个对象都是可达的,
若代码中出现: c.right=null;此时f就是不可达的,f就属于垃圾了.要进行回收.
若a=null;那么整个二叉树都是不可达的了.都要进行垃圾回收.
2.把标记为垃圾的对象的内存空间进行释放
具体的释放方法有三种.
1)标记-清除:
把标记为垃圾的对象,直接进行释放。(最直接的方法)
这种做法可能会产生大量的“内存碎片”,会存在很多小的,离散的可用空间。
可能导致后续申请内存空间失败,申请内存空间都是一次申请一个连续的内存空间,此时可能内存中总得空间是够当前要申请的内存空间的,但内有连续的内存空间够分配,就可能申请失败。
2)复制算法
先把申请的内存分成两部分,对象申请内存时都在一半的内存中创建;进行释放时,把不是垃圾的对象的内存复制到另一半内存中,然后把带有垃圾的半个内存全部释放掉。

将不是垃圾的对象都复制到另半个内存中:

再把左半部分的内存中的对象都释放掉

这个方法也存在一些问题:
1、每次释放内存,要释放一半的内存,总的可用内存减少了很多。
2、若引用的对象很多,对对象的复制也要消费很大的开销。
3)标记整理
类似于顺序表中,删除元素的方法。
遍历整个内存,若有遍历到的对象标记为垃圾,不用管,后面遍历到不是垃圾的对象内存就覆盖垃圾的内存空间,这样既不会存在“内存碎片”,又不会一次释放很多的内存。

这个方法的缺点是搬运内存会有很大的开销。
上面的方法都有一定的缺点和问题,因此,JVM并没有直接使用上面的方法,而是对上面的方法思想,采用了一个·“综合性”方案:“分带回收”。
分带回收
依据不同种类的对象,采用不同的回收方式。
JVM引入了一个概念:年龄。
JVM的扫描线程会不断的扫描内存,若该对象是可达的,年龄就+1;
JVM根据对象年龄的不同,将内存分为两个区域:新生代 和 老年代。
新生代中又划分了三个大小不等的区域:其中一个大的区域叫伊甸区 和 两个小的等大的生存区(幸存区)。

回收过程:
1.当创建出一个对象后,该对象会先被创建到伊甸区,(伊甸区的对象大多都被第一轮GC扫描到了,就会被回收掉)
2.第一轮GC后,少数存活的对象通过复制算法被送到其中一个生存区,扫描还在继续,生存区中被标记的对象就会被清除掉,极少数的生存区的对象会再次通过复制算法,从一个生存区复制到另一个生存区,这样循环扫描复制,每经过一轮GC的扫描,年龄就会+1.
3.当这个对象在生存区经过了若干轮扫描,年龄已经很大了,说明这个对象的生命周期可能很长,就将这个对象拷贝到老年代,老年代中的对象经过GC扫描的频率要比新生代低很多。

4.当扫描老年代中的对象,也被标记为垃圾了,也会进行释放。
这个分带回收就类似于找工作一样:

相关文章:
javaEE-8.JVM(八股文系列)
目录 一.简介 二.JVM中的内存划分 JVM的内存划分图: 堆区:编辑 栈区:编辑 程序计数器:编辑 元数据区:编辑 经典笔试题: 三,JVM的类加载机制 1.加载: 2.验证: 3.准备: 4.解析: 5.初始化: 双亲委派模型 概念: JVM的类加…...

25.02.04 《CLR via C#》 笔记 13
核心机制 第二十章 异常和状态管理 什么是异常:异常指成员没有完成它的名称所宣称的行动;异常是程序运行过程中用来表示错误并处理的机制,错误可以是更广义的,包括程序中未捕获的问题或逻辑缺陷。异常处理机制(try-c…...

git 项目的更新
更新项目 当自己的本地项目与 远程的github 的仓库已经建立远程连接时, 则直接按照下面的步骤, 将本地的项目代码更新到远程仓库。 # Stage the resolved file git add README.md <file1> <file2># To stage all changes: git add .# Comm…...

【Rust自学】17.3. 实现面向对象的设计模式
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 17.3.1. 状态模式 状态模式(state pattern) 是一种面向对象设计模式,指的是一个值拥有的内部状态由数个状态对象(…...

51c视觉~CV~合集10
我自己的原文哦~ https://blog.51cto.com/whaosoft/13241694 一、CV创建自定义图像滤镜 热图滤镜 这组滤镜提供了各种不同的艺术和风格化光学图像捕捉方法。例如,热滤镜会将图像转换为“热图”,而卡通滤镜则提供生动的图像,这些图像看起来…...

如何安全地管理Spring Boot项目中的敏感配置信息
在开发Spring Boot应用时,我们经常需要处理一些敏感的配置信息,比如数据库密码、API密钥等。以下是一个最佳实践方案: 1. 创建配置文件 application.yml(版本控制) spring:datasource:url: ${MYSQL_URL:jdbc:mysql…...

Docker小游戏 | 使用Docker部署2048网页小游戏
Docker小游戏 | 使用Docker部署2048网页小游戏 前言项目介绍项目简介项目预览二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署2048网页小游戏下载镜像创建容器检查容器状态检查服务端口安全设置四、访问2048网页小游戏五、总结前言 在当今快速发展的技术世…...

RabbitMQ深度探索:消息幂等性问题
RabbitMQ 消息自动重试机制: 让我们消费者处理我们业务代码的时候,如果抛出异常的情况下,在这时候 MQ 会自动触发重试机制,默认的情况下 RabbitMQ 时无限次数的重试需要认为指定重试次数限制问题 在什么情况下消费者实现重试策略…...

Linux网络 | 进入数据链路层,学习相关协议与概念
前言:本节内容进入博主讲解的网络层级中的最后一层:数据链路层。 首先博主还是会线代友友们认识一下数据链路层的报文。 然后会带大家重新理解一些概念,比如局域网交换机等等。然后就是ARP协议。 讲完这些, 本节任务就算结束。 那…...
——flink-cdc监听mysql binlog并同步数据至elastic-search和更新redis缓存)
芝法酱学习笔记(2.6)——flink-cdc监听mysql binlog并同步数据至elastic-search和更新redis缓存
一、需求背景 在有的项目中,尤其是进销存类的saas软件,一开始为了快速把产品做出来,并没有考虑缓存问题。而这类软件,有着复杂的业务逻辑。如果想在原先的代码中,添加redis缓存,改动面将非常大,…...
--性能监控系统详解)
JavaScript系列(58)--性能监控系统详解
JavaScript性能监控系统详解 📊 今天,让我们深入探讨JavaScript的性能监控系统。性能监控对于保证应用的稳定性和用户体验至关重要。 性能监控基础概念 🌟 💡 小知识:JavaScript性能监控是指通过收集和分析各种性能指…...

GESP2023年12月认证C++六级( 第三部分编程题(1)闯关游戏)
参考程序代码: #include <cstdio> #include <cstdlib> #include <cstring> #include <algorithm> #include <string> #include <map> #include <iostream> #include <cmath> using namespace std;const int N 10…...

git 新项目
新项目git 新建的项目如何进行git 配置git git config --global user.name "cc" git config --global user.email ccexample.com配置远程仓库路径 // 添加 git remote add origin http://gogs/cc/mc.git //如果配错了,删除 git remote remove origin初…...
)
系统URL整合系列视频一(需求方案)
视频 系统URL整合系列视频一(需求方案) 视频介绍 (全国)某大型分布式系统Web资源URL整合需求实现方案讲解。当今社会各行各业对软件系统的web资源访问权限控制越来越严格,控制粒度也越来越细。安全级别提高的同时也增…...

Vue.js 使用组件库构建 UI
Vue.js 使用组件库构建 UI 在 Vue.js 项目中,构建漂亮又高效的用户界面(UI)是很重要的一环。组件库就是你开发 UI 的好帮手,它可以大大提高开发效率,减少重复工作,还能让你的项目更具一致性和专业感。今天…...

计算图 Compute Graph 和自动求导 Autograd | PyTorch 深度学习实战
前一篇文章,Tensor 基本操作5 device 管理,使用 GPU 设备 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started PyTorch 计算图和 Autograd 微积分之于机器学习Computational Graphs 计算图Autograd…...

51单片机入门_05_LED闪烁(常用的延时方法:软件延时、定时器延时;while循环;unsigned char 可以表示的数字是0~255)
本篇介绍编程实现LED灯闪烁,需要学到一些新的C语言知识。由于单片机执行的速度是非常快的,如果不进行延时的话,人眼是无法识别(停留时间要大于20ms)出LED灯是否在闪烁所以需要学习如何实现软件延时。另外IO口与一个字节位的数据对应关系。 文…...

如何获取sql数据中时间的月份、年份(类型为date)
可用自带的函数month来实现 如: 创建表及插入数据: create table test (id int,begindate datetime) insert into test values (1,2015-01-01) insert into test values (2,2015-02-01) 执行sql语句,获取月份: select MONTH(begindate)…...

【单层神经网络】softmax回归的从零开始实现(图像分类)
softmax回归 该回归分析为后续的多层感知机做铺垫 基本概念 softmax回归用于离散模型预测(分类问题,含标签) softmax运算本质上是对网络的多个输出进行了归一化,使结果有一个统一的判断标准,不必纠结为什么要这么算…...

使用开源项目:pdf2docx,让PDF转换为Word
目录 1.安装python 2.安装 pdf2docx 3.使用 pdf2docx 转换 PDF 到 Word pdf2docx:GitCode - 全球开发者的开源社区,开源代码托管平台 环境:windows电脑 1.安装python Download Python | Python.org 最好下载3.8以上的版本 安装时记得选择上&#…...

OpenRGB终极指南:一站式免费控制所有RGB设备的完整解决方案
OpenRGB终极指南:一站式免费控制所有RGB设备的完整解决方案 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. R…...

思源宋体CN:零成本打造专业中文排版的终极秘籍
思源宋体CN:零成本打造专业中文排版的终极秘籍 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为字体版权费用发愁?还在寻找既能商用又专业的中文字体&…...

基于Python与Telegram API构建消息抓取与备份工具实践
1. 项目概述与核心价值 最近在折腾一个挺有意思的小工具,起因是团队内部用Telegram群组做日常沟通和文件分享,时间一长,信息量爆炸,想找点历史资料或者特定文件简直是大海捞针。手动翻记录?效率低到令人发指。市面上虽…...

3PEAK思瑞浦 TPA1811-S5TR SOT23-5 精密运放
特性 供电电压:4伏至30伏 低功耗:在25C时为55A(典型值) 低偏置电压:8V在25C(最大值) 零漂:0.01V/C 轨到轨输出 增益带宽积:500kHz 斜率:0.3V/us...

Haystack框架实战:从零构建企业级智能问答系统
1. 项目概述:一个为构建智能搜索与问答系统而生的框架如果你正在为海量文档构建一个能“理解”问题并“找到”答案的智能系统,比如一个公司内部的知识库助手,或者一个能检索技术文档并给出精准回复的客服机器人,那么你很可能已经听…...

Postman数据迁移实战:如何用导入导出功能,在团队间高效同步你的接口集合和环境变量
Postman团队协作指南:接口资产迁移与标准化管理实践 在分布式团队和敏捷开发成为主流的今天,API开发工具的高效使用直接影响着协作效率。作为被全球超过2000万开发者使用的API工具,Postman的集合与环境变量功能已经成为团队间接口定义传递的事…...

基于OpenClaw构建AI智能体:从RAG到自动化工作流的实战指南
1. 项目概述:一个开源AI应用案例的“藏宝图”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫awesome-openclaw-usecases-zh。光看名字,就能拆解出几个关键信息:“awesome”系列(意味着是精选合集…...
)
不止于测温:用MAX31855和K型热电偶搭建一个低成本高精度温度监控系统(附STM32源码)
从热电偶到云端:基于MAX31855的高精度温度监测系统全栈开发指南 在工业自动化、实验室监测甚至家庭酿造等场景中,温度数据的精确采集与实时监控往往成为项目成败的关键。传统温度传感器虽然简单易用,但在高温、腐蚀性环境或需要极高精度的场合…...

如何用Mermaid CLI彻底改变技术文档工作流
如何用Mermaid CLI彻底改变技术文档工作流 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli 在技术文档编写过程中,图表创建往往是效率瓶颈。传统绘图工具需要手动拖拽、反…...

戴尔笔记本风扇控制神器:DellFanManagement让你的设备更安静更高效
戴尔笔记本风扇控制神器:DellFanManagement让你的设备更安静更高效 【免费下载链接】DellFanManagement A suite of tools for managing the fans in many Dell laptops. 项目地址: https://gitcode.com/gh_mirrors/de/DellFanManagement 你是否曾在深夜工作…...