pytorch实现变分自编码器
人工智能例子汇总:AI常见的算法和例子-CSDN博客
变分自编码器(Variational Autoencoder, VAE)是一种生成模型,属于深度学习中的无监督学习方法。它通过学习输入数据的潜在分布(Latent Distribution),生成与输入数据相似的新样本。VAE 可以用于数据生成、降维、异常检测等任务。
VAE 的关键思想是在传统的自编码器(Autoencoder)的基础上,引入了变分推断(Variational Inference)和概率模型,使得网络能够学习到数据的潜在分布,而不仅仅是数据的映射。
VAE 的结构:
- 编码器(Encoder):将输入数据映射到潜在空间的分布。不同于传统的自编码器直接将数据映射到一个固定的潜在向量,VAE 通过输出潜在变量的均值和方差来描述一个概率分布,这样潜在空间中的每个点都有一个概率分布。
- 潜在空间(Latent Space):表示数据的潜在特征。在 VAE 中,潜在空间的表示是一个分布而不是固定的值。通常,采用正态分布来作为潜在空间的先验分布。
- 解码器(Decoder):从潜在空间的样本中重构输入数据。解码器通过将潜在空间的点映射回数据空间来生成样本。
VAE 的目标函数:
VAE 的目标是最大化变分下界(Variational Lower Bound,简称 ELBO),即通过优化以下两部分的加权和:
- 重构误差(Reconstruction Loss):衡量生成的数据和输入数据之间的差异,通常使用均方误差(MSE)或交叉熵(Cross-Entropy)。
- KL 散度(KL Divergence):衡量潜在空间的分布与先验分布(通常是标准正态分布)之间的差异。
其最终的目标是使生成的数据尽可能接近真实数据,同时使潜在空间的分布接近先验分布。
优点:
- VAE 能够生成具有多样性的样本,尤其适用于图像、音频等数据的生成。
- 潜在空间通常具有良好的结构,可以进行插值、样本生成等操作。
应用:
- 生成任务:如图像生成、文本生成等。
- 数据重构:如去噪、自编码等。
- 半监督学习:VAE 可以结合有标签和无标签的数据进行训练,提升模型的泛化能力。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt# 生成圆形图像的函数(使用PyTorch)
def generate_circle_image(size=64):image = torch.zeros((1, size, size)) # 使用 PyTorch 创建空白图像center = size // 2radius = size // 4for y in range(size):for x in range(size):if (x - center) ** 2 + (y - center) ** 2 <= radius ** 2:image[0, y, x] = 1 # 在圆内的点设置为白色return image# 生成方形图像的函数(使用PyTorch)
def generate_square_image(size=64):image = torch.zeros((1, size, size)) # 使用 PyTorch 创建空白图像padding = size // 4image[0, padding:size - padding, padding:size - padding] = 1 # 设置方形区域为白色return image# 自定义数据集:圆形和方形图像
class ShapeDataset(Dataset):def __init__(self, num_samples=1000, size=64):self.num_samples = num_samplesself.size = sizeself.data = []# 生成数据:一半是圆形图像,一半是方形图像for i in range(num_samples // 2):self.data.append(generate_circle_image(size))self.data.append(generate_square_image(size))def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx].float() # 直接返回 PyTorch Tensor 格式的数据# VAE模型定义
class VAE(nn.Module):def __init__(self, latent_dim=2):super(VAE, self).__init__()self.latent_dim = latent_dim# 编码器self.fc1 = nn.Linear(64 * 64, 400)self.fc21 = nn.Linear(400, latent_dim) # 均值self.fc22 = nn.Linear(400, latent_dim) # 方差# 解码器self.fc3 = nn.Linear(latent_dim, 400)self.fc4 = nn.Linear(400, 64 * 64)def encode(self, x):h1 = torch.relu(self.fc1(x.view(-1, 64 * 64)))return self.fc21(h1), self.fc22(h1) # 返回均值和方差def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):h3 = torch.relu(self.fc3(z))return torch.sigmoid(self.fc4(h3)).view(-1, 1, 64, 64) # 重构图像def forward(self, x):mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar# 损失函数:重构误差 + KL 散度
def loss_function(recon_x, x, mu, logvar):BCE = nn.functional.binary_cross_entropy(recon_x.view(-1, 64 * 64), x.view(-1, 64 * 64), reduction='sum')# KL 散度return BCE + 0.5 * torch.sum(torch.exp(logvar) + mu ** 2 - 1 - logvar)# 设置超参数
batch_size = 128
epochs = 10
latent_dim = 2
learning_rate = 1e-3# 数据加载
train_loader = DataLoader(ShapeDataset(num_samples=2000), batch_size=batch_size, shuffle=True)# 创建模型和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VAE(latent_dim).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
def train(epoch):model.train()train_loss = 0for batch_idx, data in enumerate(train_loader):data = data.to(device)optimizer.zero_grad()recon_batch, mu, logvar = model(data)loss = loss_function(recon_batch, data, mu, logvar)loss.backward()train_loss += loss.item()optimizer.step()if batch_idx % 100 == 0:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item() / len(data):.6f}')print(f'Train Epoch: {epoch} Average loss: {train_loss / len(train_loader.dataset):.4f}')# 测试并显示一些真实图像和生成的图像
def test():model.eval()with torch.no_grad():# 获取一批真实的图像(原始图像)real_images = next(iter(train_loader))[:64] # 只取前64个图像real_images = real_images.cpu().numpy()# 从潜在空间随机生成一些样本sample = torch.randn(64, latent_dim).to(device)generated_images = model.decode(sample).cpu().numpy()# 显示真实图像和生成的图像,分别标明fig, axes = plt.subplots(8, 8, figsize=(8, 8))axes = axes.flatten()for i in range(64):if i < 32: # 前32个显示真实图像axes[i].imshow(real_images[i].squeeze(), cmap='gray')axes[i].set_title('Real', fontsize=8)else: # 后32个显示生成图像axes[i].imshow(generated_images[i - 32].squeeze(), cmap='gray')axes[i].set_title('Generated', fontsize=8)axes[i].axis('off')plt.tight_layout()plt.show()# 训练模型
for epoch in range(1, epochs + 1):train(epoch)# 训练完成后,显示生成的图像
test()
解释:
- 真实图像 (
real_images):我们通过next(iter(train_loader))获取一批真实图像,并将其转换为 NumPy 数组,以便matplotlib显示。 - 生成图像 (
generated_images):通过模型生成的图像,使用decode()方法生成潜在空间的样本。 - 图像展示:前 32 张图像展示真实图像,后 32 张图像展示生成的图像。每个图像上方都有
Real或Generated标注。
结果:
- 前32个图像:显示真实图像,并标注为
Real。 - 后32个图像:显示通过训练后的 VAE 生成的图像,并标注为
Generated。
相关文章:

pytorch实现变分自编码器
人工智能例子汇总:AI常见的算法和例子-CSDN博客 变分自编码器(Variational Autoencoder, VAE)是一种生成模型,属于深度学习中的无监督学习方法。它通过学习输入数据的潜在分布(Latent Distribution)&…...

Node.js与嵌入式开发:打破界限的创新结合
文章目录 一、Node.js的本质与核心优势1.1 什么是Node.js?1.2 嵌入式开发的范式转变二、Node.js与嵌入式结合的四大技术路径2.1 硬件交互层2.2 物联网协议栈2.3 边缘计算架构2.4 轻量化运行时方案三、实战案例:智能农业监测系统3.1 硬件配置3.2 软件架构3.3 核心代码片段四、…...

Noise Conditional Score Network
NCSN p σ ( x ~ ∣ x ) : N ( x ~ ; x , σ 2 I ) p_\sigma(\tilde{\mathrm{x}}|\mathrm{x}) : \mathcal{N}(\tilde{\mathrm{x}}; \mathrm{x}, \sigma^2\mathbf{I}) pσ(x~∣x):N(x~;x,σ2I) p σ ( x ~ ) : ∫ p d a t a ( x ) p σ ( x ~ ∣ x ) d x p_\sigma(\mathrm…...

低代码系统-产品架构案例介绍、蓝凌(十三)
蓝凌低代码系统,依旧是从下到上,从左至右的顺序。 技术平台h/iPaas 指低层使用了哪些技术,例如:微服务架构,MySql数据库。个人认为,如果是市场的主流,就没必要赘述了。 新一代门户 门户设计器&a…...

51单片机 02 独立按键
一、独立按键控制LED亮灭 轻触按键:相当于是一种电子开关,按下时开关接通,松开时开关断开,实现原理是通过轻触按键内部的金属弹片受力弹动来实现接通和断开。 #include <STC89C5xRC.H> void main() { // P20xFE;while(1){…...

2021.3.1的android studio版本就很好用
使用最新版的studio有个问题就是gradle版本也比较高,这样就容易出现之前项目不兼容问题,配置gradle可能会出现很多问题比较烦,所以干脆就用老版本的studio...

CSV数据分析智能工具(基于OpenAI API和streamlit)
utils.py: from langchain_openai import ChatOpenAI from langchain_experimental.agents.agent_toolkits import create_csv_agent import jsonPROMPT_TEMPLATE """你是一位数据分析助手,你的回应内容取决于用户的请求内容。1. 对于文…...
)
移除元素-双指针(下标)
题目 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。 假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:…...
)
蓝桥杯备赛题目练习(一)
目录 一. 口算练习题 代码如下 代码解读(简略重点): 代码解读(详细): 二. 小乐乐改数字 代码(1):当做整数读取 代码(2):当做字符…...
)
FortiOS 存在身份验证绕过导致命令执行漏洞(CVE-2024-55591)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

【多线程】线程池核心数到底如何配置?
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 前置回顾2. 动态线程池2.1 JMX 的介绍2.1.1 MBeans 介绍 2.2 使用 JMX jconsole 实现动态修改线程池2.2.…...
-QT-C/C++ - Qt Combo Box)
Windows图形界面(GUI)-QT-C/C++ - Qt Combo Box
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 一、概述 1.1 基本概念 1.2 应用场景对比 二、核心属性详解 2.1 行为控制 2.2 显示配置 三、数据操作与访问 3.1 基础数据管理 3.2 高级数据访问 四、用户交互处理 4.1 信号处…...

开源AI智能名片2 + 1链动模式S2B2C商城小程序:内容价值创造与传播新引擎
摘要:本文聚焦于信息爆炸时代下,内容价值的创造与传播。随着用户角色的转变,其在内容生产与传播中的价值日益凸显。同时,深入探讨开源AI智能名片2 1链动模式S2B2C商城小程序这一创新商业模式,如何借助用户创造内容并传…...

python读取excel工具:openpyxl | AI应用开发
python读取excel工具:openpyxl | AI应用开发 openpyxl 是一个 Python 库,专门用于读写 Excel 2010 xlsx/xlsm/xltx/xltm 文件。它是处理 Excel 文件的强大工具,可以让你在不需要安装 Excel 软件的情况下,对 Excel 文件进行创建、…...

堆的基本概念
1.1 堆的基本概念 虚拟机所在目录 E:\ctf\pwn-self 进入虚拟机的pwndocker环境 holyeyesubuntu:~$ pwd /home/holyeyes holyeyesubuntu:~$ sudo ./1run.sh IDA分析 int __fastcall main(int argc, const char **argv, const char **envp) { void *v4; // [rsp20h] [rbp-1…...
 NXP AutomotiveOS编译)
Android车机DIY开发之软件篇(九) NXP AutomotiveOS编译
Android车机DIY开发之软件篇(十一) NXP AutomotiveOS编译 Google 在汽车上也提供了用于汽车的 Google 汽车服务(GAS,Google Automotive Service),包含有 Google 地图、应用市场、Google 汽车助理等等。Google 汽车服务同样没有开…...

嵌入式工程师必学(143):模拟信号链基础
概述: 我们每天使用的许多电子设备,以及我们赖以生存的电子设备,如果不使用电子工程师设计的实际输入信号,就无法运行。 模拟信号链由四个主要元件组成:传感器、放大器、滤波器和模数转换器 (ADC)。这些传感器用于检测、调节模拟信号并将其转换为适合由微控制器或其他数…...

《LLM大语言模型深度探索与实践:构建智能应用的新范式,融合代理与数据库的高级整合》
文章目录 Langchain的定义Langchain的组成三个核心组件实现整个核心组成部分 为什么要使用LangchainLangchain的底层原理Langchain实战操作LangSmithLangChain调用LLM安装openAI库-国内镜像源代码运行结果小结 使用Langchain的提示模板部署Langchain程序安装langserve代码请求格…...
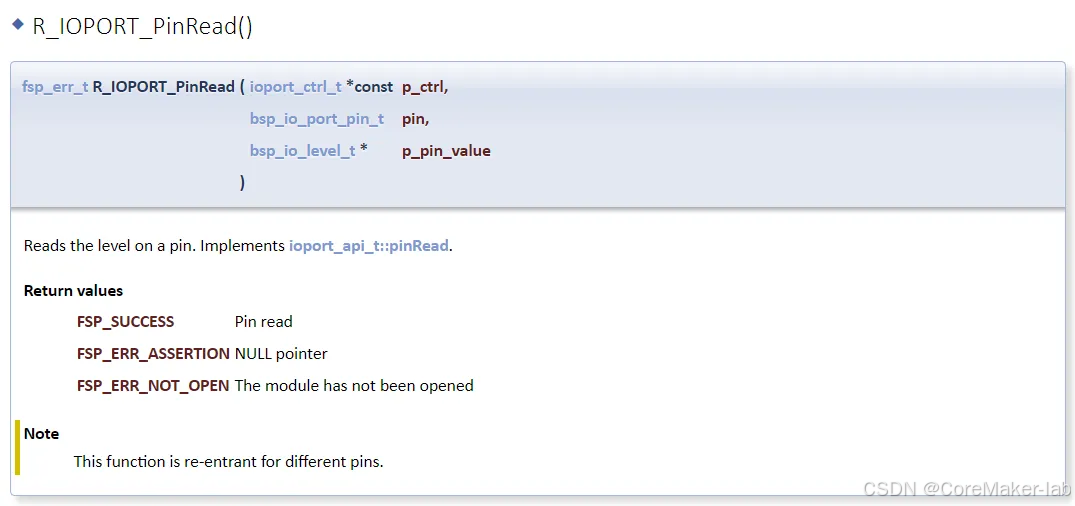
e2studio开发RA2E1(5)----GPIO输入检测
e2studio开发RA2E1.5--GPIO输入检测 概述视频教学样品申请硬件准备参考程序源码下载新建工程工程模板保存工程路径芯片配置工程模板选择时钟设置GPIO口配置按键口配置按键口&Led配置R_IOPORT_PortRead()函数原型R_IOPORT_PinRead()函数原型代码 概述 本篇文章主要介绍如何…...

Spring @Lazy:延迟初始化,为应用减负
在Spring框架中,Lazy注解的作用非常直观,它就是用来告诉Spring容器:“嘿,这个Bean嘛,先别急着创建和初始化,等到真正需要用到的时候再弄吧!” 默认情况下,Spring容器在启动时会立即创…...

AI智能体任务控制中心:构建可管理复杂项目的协作框架
1. 项目概述:为智能体装上“任务控制中心” 最近在折腾AI智能体(Agent)开发的朋友,可能都遇到过这样的场景:你精心设计了一个能联网搜索、处理文档、调用API的智能体,它单次任务的表现堪称完美。但当你试图…...

Otter多模态大模型实战:从Flamingo架构到指令调优与部署优化
1. 项目概述:一个能“看懂”世界的多模态大模型最近在折腾多模态大模型(Multimodal Large Language Models, MLLMs)的朋友,应该对 Otter 这个名字不陌生。它不是一个独立的产品,而是一个开源的研究项目,全称…...

大气层系统深度解析:构建Switch的六层数字防护体系
大气层系统深度解析:构建Switch的六层数字防护体系 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 在Nintendo Switch的定制固件生态中,Atmosphere(大气…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...

CC2530与ESP8266物联网网关:ZigBee转Wi-Fi通信协议转换实战
1. 项目概述:当ZigBee遇上Wi-Fi最近在折腾一个智能家居的传感器节点,核心是TI的CC2530 ZigBee芯片。这玩意儿功耗低、组网方便,是很多低功耗传感网络的绝佳选择。但问题来了,ZigBee网络的数据最终怎么方便地送到我们手机上去看呢&…...

基于视觉语言模型的智能体框架:让AI看懂界面并自动操作
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的领域时,我深度体验了landing-ai团队开源的vision-agent项目。这不仅仅是一个工具库,它更像是一个为大型语言模型(LLM)装上了“眼睛”和“手”的智能体框架…...

U64JSON编码技术解析与Iris框架性能优化
1. Iris框架与U64JSON编码技术解析 在嵌入式系统和高性能计算领域,数据交换效率直接影响整体系统性能。传统JSON虽然具有可读性好、跨平台等优势,但其文本特性带来的解析开销和带宽占用成为性能瓶颈。Arm Iris框架采用的U64JSON编码方案,通过…...
)
告别串口线!用STM32CubeMX给STM32F103C8T6做个USB DFU Bootloader(Keil工程+完整代码)
STM32F103C8T6 USB DFU Bootloader实战:从实验室到产品的完整方案 在嵌入式产品开发中,固件升级是一个绕不开的话题。想象一下,当你的设备已经部署在现场,却发现需要修复一个关键bug或增加新功能时,传统的JTAG/SWD调试…...

技能即代码:用自动化工具构建个人技能维护系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“skill-guardian”,作者是0xtresser。乍一看这个名字,可能有点摸不着头脑,但点进去研究了一下,发现这其实是一个关于“技能守护”或者说“技能管理”的…...

如何高效使用Diablo Edit2:暗黑破坏神II存档修改的全面解决方案
如何高效使用Diablo Edit2:暗黑破坏神II存档修改的全面解决方案 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 想要在暗黑破坏神II中打造理想角色,却苦于漫长的刷怪过程&a…...