【PostgreSQL内核学习 —— (WindowAgg(三))】
WindowAgg
- set_subquery_pathlist 部分函数解读
- check_and_push_window_quals 函数
- find_window_run_conditions 函数
- 执行案例
- 总结
- 计划器模块(set_plan_refs函数)
- set_windowagg_runcondition_references 函数
- 执行案例
- fix_windowagg_condition_expr 函数
- fix_windowagg_condition_expr_mutator 函数
- 执行案例
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-15.0 的开源代码和《PostgresSQL数据库内核分析》一书
在【PostgreSQL内核学习 —— (WindowAgg(一))】中,我们介绍了窗口函数以及窗口聚合的核心计算过程。其次,在【PostgreSQL内核学习 —— (WindowAgg(二))】一文中介绍了WindowAgg算子的具体实现逻辑。本文将进一步来学习一下WindowAgg中的条件下推的优化逻辑。
set_subquery_pathlist 部分函数解读
/** 如果子查询关系上有附加的限制条件,考虑将它们推送到子查询中,作为子查询的 WHERE 或 HAVING 过滤条件。* 这种转化很有用,因为它可能帮助我们为子查询生成更好的执行计划,避免首先评估所有子查询的输出行再过滤。** 有几种情况是不能推送限制条件的。涉及子查询的限制条件由 subquery_is_pushdown_safe() 检查。* 对单个条件的检查由 qual_is_pushdown_safe() 进行。此外,我们不希望推送伪常量(pseudoconstant)条件,* 这种情况下,最好将控制节点放在子查询上方。** 未被推送下去的条件会作为 SubqueryScan 节点的 qpquals 被评估。** XXX 是否有一些情况我们应该决定不推送可推送的条件,因为它可能导致更差的执行计划?*/
if (rel->baserestrictinfo != NIL && // 如果有限制条件并且可以安全推送subquery_is_pushdown_safe(subquery, subquery, &safetyInfo)) // 检查子查询是否支持限制条件的推送
{// 可以考虑推送单个条件List *upperrestrictlist = NIL; // 存储未推送的限制条件ListCell *l;// 遍历所有的限制条件foreach(l, rel->baserestrictinfo){RestrictInfo *rinfo = (RestrictInfo *) lfirst(l); // 当前限制条件Node *clause = (Node *) rinfo->clause; // 限制条件的表达式if (rinfo->pseudoconstant) // 如果是伪常量条件{upperrestrictlist = lappend(upperrestrictlist, rinfo); // 不推送,保留在父查询中continue;}// 检查当前条件是否可以推送到子查询中switch (qual_is_pushdown_safe(subquery, rti, rinfo, &safetyInfo)){case PUSHDOWN_SAFE:// 条件安全可以推送subquery_push_qual(subquery, rte, rti, clause); // 将条件推送到子查询break;case PUSHDOWN_WINDOWCLAUSE_RUNCOND:/** 如果条件涉及窗口函数,并且不能推送到子查询中,* 检查条件是否可以作为 WindowAgg 的运行条件。*/if (!subquery->hasWindowFuncs || // 子查询没有窗口函数,或者该条件不是合适的窗口运行条件check_and_push_window_quals(subquery, rte, rti, clause, &run_cond_attrs)){// 子查询没有窗口函数,或者条件不适合窗口运行条件,或者该条件是合适的窗口条件,但需要保留在上层查询upperrestrictlist = lappend(upperrestrictlist, rinfo);}break;case PUSHDOWN_UNSAFE:// 条件不安全,不能推送upperrestrictlist = lappend(upperrestrictlist, rinfo); // 保留在父查询中break;}}// 更新查询的限制条件rel->baserestrictinfo = upperrestrictlist;/* 不必重新计算 baserestrict_min_security */
}
代码逻辑总结:
这段代码的核心任务是评估是否能够将某些限制条件推送到子查询中,以便优化执行计划。推送的条件会直接成为子查询的过滤条件,从而避免父查询在处理子查询结果时进行重复过滤。具体流程如下:
-
判断是否可以推送条件:
- 先检查子查询是否允许推送限制条件(
subquery_is_pushdown_safe)。 - 如果子查询允许推送,则会遍历所有附加在外部查询的限制条件(
rel->baserestrictinfo)。
- 先检查子查询是否允许推送限制条件(
-
处理每个限制条件:
- 如果限制条件是伪常量,它就不能被推送下去,因为它不依赖于实际数据,可以直接在外层查询中处理。
- 对于其他条件,使用
qual_is_pushdown_safe来判断该条件是否可以安全地推送到子查询中。
-
推送限制条件:
- 如果条件安全推送,使用
subquery_push_qual将条件推送到子查询。 - 如果条件涉及窗口函数并且不能推送,它可能会被保留在外层查询中(例如作为窗口聚合的运行条件)。
- 对于无法推送的条件,它们将被保留在父查询中。
- 如果条件安全推送,使用
我们重点聚焦函数 check_and_push_window_quals,该函数在查询优化中起着至关重要的作用,特别是在涉及窗口函数的情况下。为了更好地理解这个函数的作用和它在整个查询优化中的地位,下面将从它的功能、参数、调用背景和优化目标等方面进行详细分析。
check_and_push_window_quals 函数
check_and_push_window_quals 函数的作用是在查询优化过程中判断某个过滤条件(clause)是否可以下推到窗口聚合节点(WindowAgg)的运行条件(runCondition)。如果条件可以下推,执行时可以跳过一些不必要的工作,进而优化查询的性能。
check_and_push_window_quals 函数检查给定的条件是否可以作为窗口函数的“运行条件”(runCondition)被下推至子查询中的窗口聚合节点。如果可以下推,那么这些条件会被推到窗口聚合的执行过程中,用来优化执行过程,避免不必要的计算。
具体来说,它首先确认条件是一个操作符表达式(OpExpr)且符合一定的条件,例如操作符必须是严格的(即在条件成立时可以安全地停止评估窗口函数)。然后,代码会检查操作符的左右两边是否涉及到子查询中的窗口函数,如果涉及到,就会尝试通过find_window_run_conditions函数检查该条件是否适合作为运行条件。最终,如果条件符合要求,它会将该条件下推并返回是否保留原始条件。如果条件不适合下推,或者无法找到合适的窗口函数,代码会保留原始条件,确保执行计划的正确性。函数源码如下所示:(路径:postgresql-15.10\src\backend\optimizer\path\allpaths.c)
参数作用总结
- subquery:提供关于子查询的详细信息,尤其是目标列信息,帮助解析窗口函数。
- rte:表示当前的表项,帮助确定条件是否可以与窗口函数关联。
- rti:用于标识rte在子查询中的位置,帮助定位表项。
- clause:是需要检查是否可以下推的过滤条件,通常是操作符表达式。
- run_cond_attrs:记录下推成功的窗口函数条件的目标列索引,优化窗口聚合操作。
static bool
check_and_push_window_quals(Query *subquery, RangeTblEntry *rte, Index rti,Node *clause, Bitmapset **run_cond_attrs)
{OpExpr *opexpr = (OpExpr *) clause; // 将输入的条件转换为操作符表达式 (OpExpr)bool keep_original = true; // 标记是否保留原始的过滤条件Var *var1; // 定义变量,用于存储操作符表达式左侧的变量Var *var2; // 定义变量,用于存储操作符表达式右侧的变量/* 我们只能处理有两个操作数的OpExpr */if (!IsA(opexpr, OpExpr)) // 检查输入条件是否为操作符表达式return true; // 如果不是操作符表达式,则返回true,无法下推该条件if (list_length(opexpr->args) != 2) // 确保操作符表达式有两个操作数return true; // 如果操作符的操作数不是两个,则返回true,无法下推/** 当前,这个优化仅限于严格的OpExpr。原因是,在执行时,一旦运行条件变为假,* 我们停止计算窗口函数。为了避免留下过时的窗口函数结果值,我们将它们设置为NULL。* 只有严格的OpExpr才能确保在WindowAgg节点中正确地过滤掉带有NULL值的元组。*/set_opfuncid(opexpr); // 设置操作符的函数IDif (!func_strict(opexpr->opfuncid)) // 检查操作符是否为严格运算符return true; // 如果操作符不是严格运算符,返回true,无法下推/** 检查是否有引用子查询中窗口函数的变量。* 如果找到,我们将调用find_window_run_conditions()来检查该'opexpr'是否可以* 作为运行条件的一部分。*//* 检查操作符表达式的左侧 */var1 = linitial(opexpr->args); // 获取操作符表达式的左侧操作数if (IsA(var1, Var) && var1->varattno > 0) // 检查左侧操作数是否是窗口函数引用的变量{TargetEntry *tle = list_nth(subquery->targetList, var1->varattno - 1); // 获取对应的目标列WindowFunc *wfunc = (WindowFunc *) tle->expr; // 获取窗口函数/* 使用find_window_run_conditions检查该条件是否可以作为窗口聚合的运行条件 */if (find_window_run_conditions(subquery, rte, rti, tle->resno, wfunc,opexpr, true, &keep_original,run_cond_attrs))return keep_original; // 如果可以作为运行条件,返回是否保留原始条件}/* 检查操作符表达式的右侧 */var2 = lsecond(opexpr->args); // 获取操作符表达式的右侧操作数if (IsA(var2, Var) && var2->varattno > 0) // 检查右侧操作数是否是窗口函数引用的变量{TargetEntry *tle = list_nth(subquery->targetList, var2->varattno - 1); // 获取对应的目标列WindowFunc *wfunc = (WindowFunc *) tle->expr; // 获取窗口函数/* 使用find_window_run_conditions检查该条件是否可以作为窗口聚合的运行条件 */if (find_window_run_conditions(subquery, rte, rti, tle->resno, wfunc,opexpr, false, &keep_original,run_cond_attrs))return keep_original; // 如果可以作为运行条件,返回是否保留原始条件}return true; // 如果没有条件可以下推,返回true,保留原始条件
}
具体案例说明
假设我们有以下SQL查询:
SELECT department,AVG(salary) OVER (PARTITION BY department)
FROM employees
WHERE salary > 50000;
这里,employees是一个包含多个字段的表,包括department和salary。该查询通过AVG(salary)计算每个department的平均薪资,并且只考虑salary > 50000的记录。我们现在要理解check_and_push_window_quals函数在此查询中的执行逻辑。
- 初始条件
我们需要将查询中的WHERE条件(即salary > 50000)尝试下推到窗口函数(AVG(salary) OVER (PARTITION BY department))中,来优化查询性能。如果条件可以下推,PostgreSQL将避免在窗口函数计算过程中返回不符合条件的行,从而减少不必要的计算。
- 函数执行逻辑
-
步骤1:检查clause类型
clause是salary > 50000,它是一个操作符表达式(OpExpr),因此check_and_push_window_quals会继续处理。
-
步骤2:确认操作符类型
- 该
clause会被解析为一个OpExpr,我们通过set_opfuncid和func_strict检查操作符是否严格(strict)。在此例中,>是一个严格操作符,因此可以进行进一步的优化。
- 该
-
步骤3:处理操作符的两侧(左侧和右侧)
clause是一个二元操作符表达式:salary > 50000。- 左侧操作数:
salary是一个Var类型的字段,它是一个表中的列。PostgreSQL通过subquery->targetList查找salary的目标列(Var)。 - 右侧操作数:常量
50000是一个常量,不需要进一步处理。
- 左侧操作数:
-
步骤4:检查是否有窗口函数
salary作为窗口函数的输入列之一,因此我们需要查看是否有窗口函数依赖于它。如果该列被窗口函数引用,check_and_push_window_quals会进一步检查是否可以将条件salary > 50000下推到窗口函数。- 在这种情况下,
AVG(salary) OVER (PARTITION BY department)正是一个窗口函数,salary列被窗口函数使用,因此我们调用find_window_run_conditions来检查是否可以将salary > 50000作为窗口函数的运行条件(run condition)。
-
步骤5:调用find_window_run_conditions
- 通过
find_window_run_conditions,我们检查该条件是否可以作为AVG(salary)窗口函数的运行条件(run condition)。如果可以,那么PostgreSQL将优化该查询,窗口函数只计算符合salary > 50000条件的行,而不必返回所有记录,再进行筛选。 - 如果该条件可以下推,
run_cond_attrs会被更新,标记出哪些目标列(如salary)需要作为窗口函数的运行条件。
- 通过
-
步骤6:返回结果
- 如果
salary > 50000条件被成功下推到窗口函数中,check_and_push_window_quals函数将返回false,表示可以忽略原始的WHERE条件,因为它已经被包含在窗口函数的运行条件中。 - 否则,
true会被返回,表示需要保留原始的WHERE条件,并且窗口函数的执行依然基于完整的查询结果。
- 如果
find_window_run_conditions 函数
find_window_run_conditions函数的作用是确定是否可以利用操作符表达式(OpExpr)来短路窗口函数的执行,以提高查询效率。具体来说,它检查窗口函数的单调性,如果窗口函数的输出是单调递增或递减的,则可以利用这个特性在外层查询中利用WHERE子句的过滤条件来提前停止窗口函数的计算。例如,如果一个ROW_NUMBER()窗口函数输出的值是递增的,并且外部查询要求只返回ROW_NUMBER() <= 10的结果,那么窗口函数的计算可以在ROW_NUMBER()达到11时停止,从而避免对后续行进行不必要的计算。函数源码如下所示:(路径:postgresql-15.10\src\backend\optimizer\path\allpaths.c)
/** find_window_run_conditions* 确定 'wfunc' 是否真的是一个窗口函数,并调用其支持函数来确定该函数的单调性属性。* 然后检查 'opexpr' 是否能用于短路执行。如果可以,它将帮助跳过不必要的计算。*/
static bool
find_window_run_conditions(Query *subquery, RangeTblEntry *rte, Index rti,AttrNumber attno, WindowFunc *wfunc, OpExpr *opexpr,bool wfunc_left, bool *keep_original,Bitmapset **run_cond_attrs)
{Oid prosupport; // 存储窗口函数的支持函数的 OIDExpr *otherexpr; // 存储操作符表达式中的另一个表达式SupportRequestWFuncMonotonic req; // 存储单调性请求SupportRequestWFuncMonotonic *res; // 存储单调性结果WindowClause *wclause; // 存储窗口子句List *opinfos; // 存储操作符的详细信息列表OpExpr *runopexpr; // 存储要用作运行条件的操作符表达式Oid runoperator; // 存储运行条件的操作符ListCell *lc; // 用于遍历操作符信息的列表单元*keep_original = true; // 默认为保留原始条件// 如果窗口函数是一个类型转换表达式(RelabelType),递归到窗口函数本身while (IsA(wfunc, RelabelType))wfunc = (WindowFunc *) ((RelabelType *) wfunc)->arg;// 如果不是窗口函数,则返回 falseif (!IsA(wfunc, WindowFunc))return false;// 如果窗口函数中包含子查询,则无法优化,返回 falseif (contain_subplans((Node *) wfunc))return false;// 获取窗口函数的支持函数 OIDprosupport = get_func_support(wfunc->winfnoid);// 如果窗口函数没有支持函数,返回 falseif (!OidIsValid(prosupport))return false;// 获取操作符表达式的另一侧的表达式(左侧或右侧)if (wfunc_left)otherexpr = lsecond(opexpr->args); // 获取右侧表达式elseotherexpr = linitial(opexpr->args); // 获取左侧表达式// 要比较的值在窗口分区的评估过程中必须保持不变if (!is_pseudo_constant_clause((Node *) otherexpr))return false;// 获取与窗口函数关联的窗口子句wclause = (WindowClause *) list_nth(subquery->windowClause, wfunc->winref - 1);// 设置单调性请求参数req.type = T_SupportRequestWFuncMonotonic;req.window_func = wfunc;req.window_clause = wclause;// 调用窗口函数的支持函数来获取单调性属性res = (SupportRequestWFuncMonotonic *) DatumGetPointer(OidFunctionCall1(prosupport, PointerGetDatum(&req)));// 如果窗口函数的单调性不是单调递增或单调递减,返回 falseif (res == NULL || res->monotonic == MONOTONICFUNC_NONE)return false;runopexpr = NULL; // 初始化运行条件表达式为空runoperator = InvalidOid; // 初始化运行条件操作符为空opinfos = get_op_btree_interpretation(opexpr->opno); // 获取操作符的详细信息// 遍历操作符信息foreach(lc, opinfos){OpBtreeInterpretation *opinfo = (OpBtreeInterpretation *) lfirst(lc);int strategy = opinfo->strategy; // 获取操作符策略// 处理 < / <= 操作符if (strategy == BTLessStrategyNumber || strategy == BTLessEqualStrategyNumber){// 如果是单调递增函数,支持 <wfunc> op <pseudoconst>// 如果是单调递减函数,支持 <pseudoconst> op <wfunc>if ((wfunc_left && (res->monotonic & MONOTONICFUNC_INCREASING)) ||(!wfunc_left && (res->monotonic & MONOTONICFUNC_DECREASING))){*keep_original = false; // 不再保留原始条件runopexpr = opexpr; // 设置运行条件表达式为当前的操作符表达式runoperator = opexpr->opno; // 设置运行条件操作符}break; // 结束遍历}// 处理 > / >= 操作符else if (strategy == BTGreaterStrategyNumber || strategy == BTGreaterEqualStrategyNumber){// 单调递减函数支持 <wfunc> op <pseudoconst>// 单调递增函数支持 <pseudoconst> op <wfunc>if ((wfunc_left && (res->monotonic & MONOTONICFUNC_DECREASING)) ||(!wfunc_left && (res->monotonic & MONOTONICFUNC_INCREASING))){*keep_original = false;runopexpr = opexpr;runoperator = opexpr->opno;}break;}// 处理 = 操作符else if (strategy == BTEqualStrategyNumber){int16 newstrategy;// 如果函数既是单调递增的又是单调递减的,窗口函数的返回值在每次计算时是相同的// 在这种情况下,直接使用原始的操作符表达式作为运行条件if ((res->monotonic & MONOTONICFUNC_BOTH) == MONOTONICFUNC_BOTH){*keep_original = false;runopexpr = opexpr;runoperator = opexpr->opno;break;}// 单调递增的情况下,创建 <wfunc> <= <value> 或 <value> >= <wfunc> 的条件// 单调递减的情况下,创建 <wfunc> >= <value> 或 <value> <= <wfunc> 的条件if (res->monotonic & MONOTONICFUNC_INCREASING)newstrategy = wfunc_left ? BTLessEqualStrategyNumber : BTGreaterEqualStrategyNumber;elsenewstrategy = wfunc_left ? BTGreaterEqualStrategyNumber : BTLessEqualStrategyNumber;// 保留原始的等号条件*keep_original = true;runopexpr = opexpr;// 确定用于运行条件的操作符runoperator = get_opfamily_member(opinfo->opfamily_id, opinfo->oplefttype,opinfo->oprighttype, newstrategy);break;}}// 如果找到了有效的运行条件表达式if (runopexpr != NULL){Expr *newexpr;// 构建运行条件表达式,保持窗口函数在原位置if (wfunc_left)newexpr = make_opclause(runoperator, runopexpr->opresulttype,runopexpr->opretset, (Expr *) wfunc,otherexpr, runopexpr->opcollid,runopexpr->inputcollid);elsenewexpr = make_opclause(runoperator, runopexpr->opresulttype,runopexpr->opretset, otherexpr, (Expr *) wfunc,runopexpr->opcollid, runopexpr->inputcollid);// 将新创建的运行条件添加到窗口子句的 runCondition 中wclause->runCondition = lappend(wclause->runCondition, newexpr);// 记录该属性已经用于运行条件*run_cond_attrs = bms_add_member(*run_cond_attrs, attno - FirstLowInvalidHeapAttributeNumber);return true;}// 如果没有找到支持的操作符,返回 falsereturn false;
}
该函数的主要执行步骤包括:
- 判断窗口函数的单调性属性(递增、递减等)。
- 根据单调性属性决定是否可以应用短路条件(比如
<或<=)。- 生成适当的条件表达式,将其添加到窗口子句的
runCondition中。- 更新已处理的属性集,以确保这些条件在查询执行时会被应用。
执行案例
为了详细解释 find_window_run_conditions 函数的作用,我们可以通过一个具体的例子来说明。假设有一个查询,其中包含一个窗口函数 row_number(),并且该窗口函数用于对行号进行排序。假设有一个窗口函数的查询结构如下:
SELECT row_number() OVER (ORDER BY salary DESC) AS rn, name, salary
FROM employees
WHERE row_number() <= 10;
在这个查询中,我们使用了 row_number() 作为窗口函数,并且在外部查询的 WHERE 子句中使用了 row_number() <= 10 来过滤结果。我们的目标是利用 find_window_run_conditions 函数来判断在什么情况下可以通过对窗口函数的运行条件进行优化,避免无谓的计算。
具体执行过程(逐行解释)
假设我们调用 find_window_run_conditions 函数时,传入的参数如下:
- subquery: 表示包含窗口函数的子查询,即
SELECT row_number() OVER (ORDER BY salary DESC) AS rn, ...。 - rte: 查询中的关系表条目(
employees表)。 - rti: 该表在查询范围表中的索引(例如,
employees表的索引)。 - attno: 表示我们感兴趣的属性(例如,
row_number()函数返回的列rn)。 - wfunc: 窗口函数结构体,包含了
row_number()函数的信息(例如,函数ID、窗口参考、分区、排序等)。 - opexpr: 表示操作符表达式,
row_number() <= 10中的<=操作符。 - wfunc_left: 指示窗口函数
row_number()在操作符的左侧。 - keep_original: 用于指示是否保留原始的操作符条件。
- run_cond_attrs: 用于记录哪些属性(列)将用于优化条件。
逐行解释代码执行过程
- 初始化
*keep_original = true
*keep_original = true;
这行代码初始化了 keep_original 标志为 true。这是因为默认情况下我们保留原始的操作符条件(row_number() <= 10)。
- 处理窗口函数的类型
while (IsA(wfunc, RelabelType))wfunc = (WindowFunc *) ((RelabelType *) wfunc)->arg;
如果 wfunc 是 RelabelType 类型(这通常发生在类型转换的情况下),我们将递归地访问它的实际参数。假设这里 wfunc 是 WindowFunc 类型,因此这段代码不会执行。
- 检查
wfunc是否是窗口函数
if (!IsA(wfunc, WindowFunc))return false;
这行代码检查 wfunc 是否是窗口函数类型。如果不是窗口函数,直接返回 false。在我们的例子中,row_number() 窗口函数符合条件,因此继续执行。
- 检查窗口函数中是否包含子查询
if (contain_subplans((Node *) wfunc))return false;
窗口函数中如果包含子查询(例如嵌套查询),则无法优化。因此,检查 wfunc 中是否包含子查询。如果包含子查询,返回 false。在本例中,row_number() 不包含子查询,所以继续执行。
- 获取窗口函数的支持函数
prosupport = get_func_support(wfunc->winfnoid);
这行代码获取窗口函数的支持函数。每个窗口函数可能有一个“支持函数”,用来检查该函数的单调性(即是否是递增或递减的)。对于 row_number() 函数,它应该是递增的。
注:以
row_number()窗口函数为例,通常这个函数会在分区内生成递增的行号。因此,窗口函数的支持函数可能会返回一个标志,表示该窗口函数的结果是递增的(单调递增)。
- 检查是否存在有效的支持函数
if (!OidIsValid(prosupport))return false;
如果窗口函数没有有效的支持函数,返回 false。如果 row_number() 的支持函数有效,继续执行。
- 获取操作符表达式的另一边的表达式
if (wfunc_left)otherexpr = lsecond(opexpr->args);
elseotherexpr = linitial(opexpr->args);
这行代码根据 wfunc_left 标志来确定操作符表达式 opexpr 的另一边的表达式。如果 wfunc_left 为 true,则窗口函数在操作符的左边,otherexpr 是操作符的右边。如果 wfunc_left 为 false,则窗口函数在右边,otherexpr 是操作符的左边。假设 wfunc_left 为 true,otherexpr 将是常数 10,因为 opexpr 中是 row_number() <= 10。
- 检查
otherexpr是否是伪常量
if (!is_pseudo_constant_clause((Node *) otherexpr))return false;
这行代码检查 otherexpr 是否是伪常量,即它的值在窗口分区的评估过程中不会发生变化。对于 row_number() <= 10 中的 10,它是一个常量,因此通过此检查。
- 获取窗口函数的窗口子句
wclause = (WindowClause *) list_nth(subquery->windowClause, wfunc->winref - 1);
通过 wfunc->winref 获取与窗口函数 row_number() 相关联的窗口子句。这一行确保我们访问到包含窗口函数定义的正确窗口子句。
- 构建支持请求并调用支持函数
req.type = T_SupportRequestWFuncMonotonic;
req.window_func = wfunc;
req.window_clause = wclause;
创建支持请求结构体,指定窗口函数和窗口子句,准备调用支持函数。
res = (SupportRequestWFuncMonotonic *)DatumGetPointer(OidFunctionCall1(prosupport, PointerGetDatum(&req)));
调用支持函数来检查窗口函数的单调性。如果 row_number() 是递增的,则返回 MONOTONICFUNC_INCREASING。
- 检查是否支持单调性
if (res == NULL || res->monotonic == MONOTONICFUNC_NONE)return false;
如果支持函数返回为空或窗口函数不具有单调性,则返回 false。对于 row_number(),它是递增的,因此通过此检查。
- 分析操作符的策略
runopexpr = NULL;
runoperator = InvalidOid;
opinfos = get_op_btree_interpretation(opexpr->opno);
获取操作符表达式的相关操作符信息,准备分析操作符策略。
foreach(lc, opinfos)
{OpBtreeInterpretation *opinfo = (OpBtreeInterpretation *) lfirst(lc);int strategy = opinfo->strategy;
遍历操作符的 B-tree 解释,检查操作符的策略类型(例如 <, <=, = 等)。
- 检查并处理操作符
<和<=
if (strategy == BTLessStrategyNumber || strategy == BTLessEqualStrategyNumber)
{if ((wfunc_left && (res->monotonic & MONOTONICFUNC_INCREASING)) ||(!wfunc_left && (res->monotonic & MONOTONICFUNC_DECREASING))){*keep_original = false;runopexpr = opexpr;runoperator = opexpr->opno;}break;
}
对于 <= 操作符,如果窗口函数是递增的,且窗口函数位于操作符的左侧,则可以利用该条件来优化计算,避免不必要的处理。此时,keep_original 被设置为 false,并且 runopexpr 和 runoperator 被设置为当前的操作符表达式。
-
其他操作符处理
处理>, >=, =等操作符的逻辑与上述类似。针对不同的操作符策略,检查是否可以根据窗口函数的单调性来优化。 -
构建新的运行条件表达式并添加到窗口子句
if (runopexpr != NULL)
{Expr *newexpr;if (wfunc_left)newexpr = make_opclause(runoperator, runopexpr->opresulttype, runopexpr->opretset, (Expr *) wfunc, otherexpr, runopexpr->opcollid);elsenewexpr = make_opclause(runoperator, runopexpr->opresulttype, runopexpr->opretset, otherexpr, (Expr *) wfunc, runopexpr->opcollid);
}
最后,基于优化后的条件构建新的表达式并将其加入到窗口子句中,供查询执行时使用。
总结
通过上述详细的例子和逐行分析,find_window_run_conditions 函数的作用是基于窗口函数的单调性和操作符表达式(如 <=)来决定是否可以优化窗口函数的计算,从而避免不必要的计算。通过合理的优化,查询的执行效率得到提升。
计划器模块(set_plan_refs函数)
这段代码是 PostgreSQL 计划器(Planner)中的 WindowAgg 处理逻辑,负责调整窗口函数执行节点的运行条件,确保 WindowFuncs(窗口函数)在 runCondition 计算时,能够正确引用已经计算出的值,而不是重复计算。同时,它还修正了窗口帧的偏移量表达式 (startOffset 和 endOffset),以及 runCondition 和 runConditionOrig 的变量索引,使其适应优化后的执行计划,确保查询执行效率和正确性。
case T_WindowAgg: // 处理 WindowAgg 类型的计划节点
{WindowAgg *wplan = (WindowAgg *) plan; // 将 plan 转换为 WindowAgg 类型,以便访问其成员变量/** 调整 WindowAgg 的运行条件 (`runCondition`):* 1. 原始 `runCondition` 可能包含对 WindowFuncs(窗口函数)的直接引用,* 但在执行时,WindowFunc 的计算结果会存储在 scan slot(扫描槽)中。* 2. 这个调整确保 `runCondition` 直接引用 scan slot 中的结果,而不是重新计算 WindowFunc。*/wplan->runCondition = set_windowagg_runcondition_references(root,wplan->runCondition,(Plan *) wplan);// 处理 WindowAgg 节点的变量引用,确保其与上层查询计划兼容set_upper_references(root, plan, rtoffset);/** 处理窗口帧的起始 (`startOffset`) 和结束 (`endOffset`) 偏移量:* 1. `startOffset` 和 `endOffset` 可能是表达式,如 `RANGE BETWEEN INTERVAL '1 day' PRECEDING AND CURRENT ROW`。* 2. 由于它们不会引用子计划中的变量,因此可以直接使用 `fix_scan_expr` 进行调整,确保正确引用优化后的执行计划。*/wplan->startOffset = fix_scan_expr(root, wplan->startOffset, rtoffset, 1);wplan->endOffset = fix_scan_expr(root, wplan->endOffset, rtoffset, 1);/** 修正 `runCondition` 运行条件中的变量索引:* 1. `runCondition` 可能包含对查询目标列表 (target list) 的引用。* 2. `fix_scan_list` 通过 `rtoffset` 修正这些引用,以适应优化后的计划。*/wplan->runCondition = fix_scan_list(root,wplan->runCondition,rtoffset,NUM_EXEC_TLIST(plan));/** 修正 `runConditionOrig`(原始运行条件)的变量索引:* 1. `runConditionOrig` 是未优化前的 `runCondition` 版本,通常用于调试或执行回退。* 2. 这里同样调用 `fix_scan_list` 进行调整,使其适应优化后的计划。*/wplan->runConditionOrig = fix_scan_list(root,wplan->runConditionOrig,rtoffset,NUM_EXEC_TLIST(plan));
}
功能描述
-
调整
runCondition引用- 确保
runCondition运行时引用的是scan slot中存储的WindowFunc计算结果,而不是重新计算WindowFunc,提高执行效率。
- 确保
-
修正
startOffset和endOffsetWindowAgg可能包含窗口帧偏移量 (frame offset expressions),例如RANGE BETWEEN语句中的时间偏移值。- 由于这些表达式不会包含子计划中的变量,因此使用
fix_scan_expr进行修正。
-
处理
runCondition和runConditionOrig变量索引fix_scan_list确保runCondition和runConditionOrig中的变量索引与优化后的查询计划一致,避免执行时变量解析错误。
set_windowagg_runcondition_references 函数
set_windowagg_runcondition_references 主要用于调整 WindowAgg 计划节点中的 runCondition,确保 runCondition 内部的 WindowFunc(窗口函数)不会被重复计算,而是转换为指向 plan->targetlist(计划目标列表)中相应 WindowFunc 计算结果的 Var(变量引用)。
这样做的目的是优化执行效率,避免 WindowFunc 在 runCondition 评估时重复计算,改为直接引用 plan->targetlist 中已经计算出的结果。函数源码如下所示:(路径:postgresql-15.10\src\backend\optimizer\plan\setrefs.c)
/** set_windowagg_runcondition_references* 将 'runcondition' 运行条件中的 WindowFunc 引用替换为 Var,* 使其指向 'plan' 目标列表 (targetlist) 中的相应 WindowFunc 计算结果。** 这样可以避免 WindowFunc 在 'runCondition' 评估时重复计算,* 改为直接引用 'plan->targetlist',从而优化执行效率。*/
static List *
set_windowagg_runcondition_references(PlannerInfo *root,List *runcondition,Plan *plan)
{List *newlist; // 存储转换后的 runCondition 列表indexed_tlist *itlist; // 存储 'plan->targetlist' 的索引信息// 构建目标列表索引,方便后续查找 targetlist 中的变量itlist = build_tlist_index(plan->targetlist);// 处理 runCondition,将 WindowFunc 引用替换为指向 targetlist 变量的 Varnewlist = fix_windowagg_condition_expr(root, runcondition, itlist);// 释放目标列表索引内存pfree(itlist);// 返回转换后的 runConditionreturn newlist;
}
执行案例
我们通过一个具体的 SQL 查询,详细展示 set_windowagg_runcondition_references 的作用,并结合执行计划分析它如何优化 WindowAgg 节点中的 runCondition 计算方式。
- SQL 查询示例
假设我们有一个sales表,记录了销售数据:
CREATE TABLE sales (id SERIAL PRIMARY KEY,region TEXT,amount NUMERIC
);
假设表中有如下数据:
| id | region | amount |
|---|---|---|
| 1 | East | 100 |
| 2 | West | 200 |
| 3 | East | 150 |
| 4 | West | 250 |
| 5 | East | 300 |
现在我们执行以下查询,计算每个区域内的 row_number,并过滤掉 row_number <= 2 的记录:
SELECT id, region, amount, row_number() OVER (PARTITION BY region ORDER BY amount DESC) AS rn
FROM sales
HAVING row_number() > 2;
- PostgreSQL 查询执行计划
在HAVING子句中,我们直接使用row_number(),这可能导致PostgreSQL在执行时多次计算row_number(),引发性能问题。
初始执行计划(未优化)
WindowAgg (cost=XX..XX rows=XX width=XX)-> Sort (cost=XX..XX)Sort Key: region, amount DESC-> Seq Scan on sales (cost=XX..XX)
在此情况下:
row_number()作为WindowFunc需要在HAVING过滤时重新计算,增加了计算成本。
set_windowagg_runcondition_references作用
在set_windowagg_runcondition_references运行后,PostgreSQL会优化WindowAgg节点:
- 原始的
runCondition:
HAVING row_number() > 2- 转换后的
runCondition:
HAVING rn > 2rn直接引用targetlist(plan->targetlist)中row_number()的结果,避免重复计算。
优化后的执行计划
WindowAgg (cost=XX..XX rows=XX width=XX)-> Sort (cost=XX..XX)Sort Key: region, amount DESC-> Seq Scan on sales (cost=XX..XX)Filter: (rn > 2)
WindowAgg只计算row_number()一次,结果存入targetlist。HAVING直接引用rn(Var),避免row_number()重新执行。
- 代码执行流程解析
当 set_windowagg_runcondition_references 执行时:
-
构建
targetlist索引
build_tlist_index(plan->targetlist)解析plan->targetlist,构建一个映射,使row_number()结果可以通过Var引用。 -
转换
runCondition
fix_windowagg_condition_expr(root, runcondition, itlist)遍历HAVING row_number() > 2,将row_number()引用替换为Var。 -
释放
itlist索引
pfree(itlist)释放内存。 -
返回优化后的
runCondition
返回HAVING rn > 2,避免row_number()额外计算。
- 结论
在未优化的情况下,HAVING row_number() > 2 可能导致 row_number() 在 WindowAgg 计算后再次被评估。
通过 set_windowagg_runcondition_references,PostgreSQL 只计算 row_number() 一次,然后在 HAVING 过滤时直接引用 targetlist 结果,提高查询效率。
fix_windowagg_condition_expr 函数
该函数 fix_windowagg_condition_expr 主要用于优化 WindowAgg 运行条件 (runCondition),避免 WindowFunc 重复计算。
它将 runcondition 中的 WindowFunc 替换为 Var,以便引用 subplan_itlist(即 plan->targetlist),减少计算开销。
在 HAVING 或其他涉及 WindowFunc 计算的表达式中,这种优化能够避免重复计算窗口函数,提高查询执行效率。
🔹函数参数
| 参数名 | 类型 | 说明 |
|---|---|---|
root | PlannerInfo * | 查询优化器的全局上下文信息 |
runcondition | List * | 需要优化的 runCondition(即 HAVING 条件等) |
subplan_itlist | indexed_tlist * | targetlist(plan->targetlist)的索引表 |
📌 目的
该函数的目标是优化 WindowAgg 运行条件,使 runCondition 直接引用 plan->targetlist,避免 WindowFunc 重新计算。
/** fix_windowagg_condition_expr* 转换 `runcondition` 中的 `WindowFunc` 引用,* 将其替换为指向 `subplan_itlist` 中对应 `WindowFunc` 结果的 `Var`。* 这样可以避免 `WindowFunc` 在 `HAVING` 等条件中被重复计算,提高查询执行效率。*/
static List *
fix_windowagg_condition_expr(PlannerInfo *root,List *runcondition,indexed_tlist *subplan_itlist)
{/* 定义 `fix_windowagg_cond_context` 结构体变量 `context`,用于存储转换过程中的上下文信息 */fix_windowagg_cond_context context;/* 将 `PlannerInfo` 指针 `root` 传递给 `context`,确保在转换过程中能够访问查询优化器的上下文信息 */context.root = root;/* 存储 `subplan_itlist`(即 `plan->targetlist` 的索引列表),用于查找 `WindowFunc` 对应的 `Var` */context.subplan_itlist = subplan_itlist;/* 初始化 `newvarno` 为 `0`(该字段目前未使用,可能用于扩展功能) */context.newvarno = 0;/* 调用 `fix_windowagg_condition_expr_mutator` 进行转换 *//* 该函数会递归遍历 `runCondition`,查找 `WindowFunc`,并替换为 `Var` */return (List *) fix_windowagg_condition_expr_mutator((Node *) runcondition,&context);
}
fix_windowagg_condition_expr_mutator 函数
该函数的作用是递归遍历并替换查询树中的 WindowFunc 节点,将其替换为 targetlist 中相应的 Var,以便在 runCondition 中高效引用而不必重新计算 WindowFunc。具体功能如下:
- 遍历树结构:递归遍历整个表达式树。
- 替换
WindowFunc:当遇到WindowFunc节点时,将其替换为指向targetlist中对应位置的Var,避免重新计算WindowFunc。 - 查找目标列表中的 Var:通过
search_indexed_tlist_for_non_var函数,找到对应的Var。 - 报错处理:如果没有找到相应的
Var,会抛出错误,说明WindowFunc无法在目标列表中找到。
/** fix_windowagg_condition_expr_mutator* 变换器函数,用于将 `WindowFunc` 替换为对应的 `Var`,该 `Var` 引用在 `targetlist` 中的 `WindowFunc`。* 此操作帮助优化查询,避免在条件中重复计算窗口函数。*/
static Node *
fix_windowagg_condition_expr_mutator(Node *node,fix_windowagg_cond_context *context)
{/* 如果当前节点为 NULL,直接返回 NULL */if (node == NULL)return NULL;/* 如果当前节点是 WindowFunc 类型的节点 */if (IsA(node, WindowFunc)){/* 定义一个 Var 类型的指针 `newvar`,用于存储替换后的变量 */Var *newvar;/* 从 `subplan_itlist` 中搜索与 `WindowFunc` 对应的 `Var` */newvar = search_indexed_tlist_for_non_var((Expr *) node,context->subplan_itlist,context->newvarno);/* 如果找到了对应的 Var,则返回这个 Var */if (newvar)return (Node *) newvar;/* 如果没有找到对应的 Var,则抛出错误,表示未能在目标列表中找到 WindowFunc */elog(ERROR, "WindowFunc not found in subplan target lists");}/* 对当前节点的子树进行递归处理,遍历树结构 */return expression_tree_mutator(node,fix_windowagg_condition_expr_mutator,(void *) context);
}
执行案例
假设我们有如下 SQL 查询:
SELECT id, region, amount, row_number() OVER (PARTITION BY region ORDER BY amount DESC) AS rn
FROM sales
HAVING row_number() > 2;
在查询优化过程中,WindowFunc(如 row_number())会出现在 HAVING 子句中。为了避免在 HAVING 子句中重复计算窗口函数,fix_windowagg_condition_expr_mutator 函数会将 WindowFunc 替换为 Var,并使得 HAVING 子句直接引用 targetlist 中已经计算好的结果。
关键函数解释
search_indexed_tlist_for_non_var:此函数用于从subplan_itlist中查找WindowFunc对应的Var。它通过对比表达式的结构和目标列表,找到对应的变量引用。expression_tree_mutator:这是PostgreSQL中常用的树遍历函数,用于递归处理表达式树的每个节点,并应用特定的变换操作。
相关文章:
)】)
【PostgreSQL内核学习 —— (WindowAgg(三))】
WindowAgg set_subquery_pathlist 部分函数解读check_and_push_window_quals 函数find_window_run_conditions 函数执行案例总结 计划器模块(set_plan_refs函数)set_windowagg_runcondition_references 函数执行案例 fix_windowagg_condition_expr 函数f…...

redis教程
Redis 教程 Redis 是一个开源的内存数据结构存储系统,用作数据库、缓存和消息代理。以下是一些基础知识和常用操作。 一、简介 Redis 支持多种数据结构,如字符串、哈希、列表、集合、有序集合等。它具有高性能、高可用性和数据持久化的特性。 二、安…...

Python aiortc API
本研究的主要目的是基于Python aiortc api实现抓取本地设备媒体流(摄像机、麦克风)并与Web端实现P2P通话。本文章仅仅描述实现思路,索要源码请私信我。 1 demo-server解耦 1.1 原始代码解析 1.1.1 http服务器端 import argparse import …...

Transaction rolled back because it has been marked as rollback-only问题解决
1、背景 在我们的日常开发中,经常会存在在一个Service层中调用另外一个Service层的方法。比如:我们有一个TaskService,里面有一个execTask方法,且这个方法存在事物,这个方法在执行完之后,需要调用LogServi…...

深入浅出 DeepSeek V2 高效的MoE语言模型
今天,我们来聊聊 DeepSeek V2 高效的 MoE 语言模型,带大家一起深入理解这篇论文的精髓,同时,告诉大家如何将这些概念应用到实际中。 🌟 什么是 MoE?——Mixture of Experts(专家混合模型&#x…...
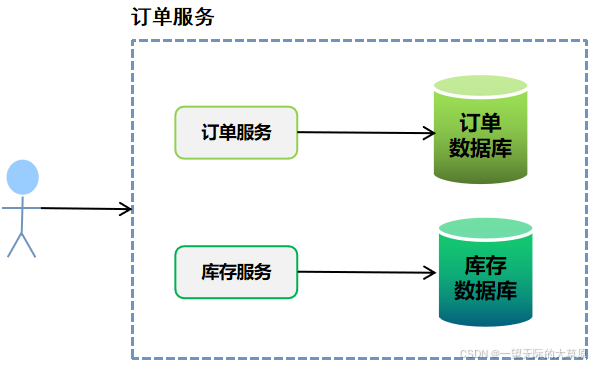
读书笔记--分布式架构的异步化和缓存技术原理及应用场景
本篇是在上一篇的基础上,主要对分布式应用架构下的异步化机制和缓存技术进行学习,主要记录和思考如下,供大家学习参考。大家知道原来传统的单一WAR应用中,由于所有数据都在同一个数据库中,因此事务问题一般借助数据库事…...

售后板子HDMI无输出分析
问题: 某产品售后有1例HDMI无输出。 分析: 1、测试HDMI的HPD脚(HDMI座子的19pin),测试电压4.5V,属于正常。 2、用万用表直流电压档,测试HDMI的3对数据脚和1对时钟脚(板子通过HDM…...

python3处理表格常用操作
使用pandas库读取excel文件 import pandas as pd data pd.read_excel(D:\\飞书\\近一年用量.xlsx)指定工作表 import pandas as pd data pd.read_excel(D:\\飞书\\近一年用量.xlsx, sheet_nameSheet1)读取日期格式 data pd.read_excel(example.xlsx, parse_dates[Date])添…...
)
AUX接口(Auxiliary Port)
AUX接口(Auxiliary Port)是网络设备(如路由器、交换机等)上的一个辅助端口,主要用于设备的配置、管理和维护。以下是关于AUX接口的一些关键点: ### 1. **功能** - **设备配置**:通过AUX接口连接…...

计算机毕业设计Python+Vue.js游戏推荐系统 Steam游戏推荐系统 Django Flask 游 戏可视化 游戏数据分析 游戏大数据 爬虫
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【梦想终会实现】Linux驱动学习5
加油加油坚持住! 1、 Linux驱动模型:驱动模型即将各模型中共有的部分抽象成C结构体。Linux2.4版本前无驱动模型的概念,每个驱动写的代码因人而异,随后为规范书写方式,发明了驱动模型,即提取公共信息组成一…...

Spring 核心技术解析【纯干货版】-Spring 数据访问模块 Spring-Jdbc
在 Spring 框架中,有一个重要的子项目叫做 spring-jdbc。这个模块提供了一种方 便的编程方式来访问基于 JDBC(Java数据库连接)的数据源。本篇博客将详细解析 Spring JDBC 的主要组件和用法,以帮助你更好地理解并使用这个强大的工具…...
Docker 安装详细教程(适用于CentOS 7 系统)
目录 步骤如下: 1. 卸载旧版 Docker 2. 配置 Docker 的 YUM 仓库 3. 安装 Docker 4. 启动 Docker 并验证安装 5. 配置 Docker 镜像加速 总结 前言 Docker 分为 CE 和 EE 两大版本。CE即社区版(免费,支持周期7个月)…...

Mac本地部署DeekSeek-R1下载太慢怎么办?
Ubuntu 24 本地安装DeekSeek-R1 在命令行先安装ollama curl -fsSL https://ollama.com/install.sh | sh 下载太慢,使用讯雷,mac版下载链接 https://ollama.com/download/Ollama-darwin.zip 进入网站 deepseek-r1:8b,看内存大小4G就8B模型 …...

《Angular之image loading 404》
前言: 千锤万凿出深山,烈火焚烧若等闲。 正文: 一。问题描述 页面加载图片,报错404 二。问题定位 页面需要加载图片,本地开发写成硬编码的形式请求图片资源: 然而部署到服务器上报错404 三。解决方案 正确…...

JavaScript前后端交互-AJAX/fetch
摘自千峰教育kerwin的js教程 AJAX 1、AJAX 的优势 不需要插件的支持,原生 js 就可以使用用户体验好(不需要刷新页面就可以更新数据)减轻服务端和带宽的负担缺点: 搜索引擎的支持度不够,因为数据都不在页面上…...

ZooKeeper单节点详细部署流程
ZooKeeper单节点详细部署流程 文章目录 ZooKeeper单节点详细部署流程 一.下载稳定版本**ZooKeeper**二进制安装包二.安装并启动**ZooKeeper**1.安装**ZooKeeper**2.配置并启动**ZooKeeper** ZooKeeper 版本与 JDK 兼容性3.检查启动状态4.配置环境变量 三.可视化工具管理**Zooke…...

流浪地球发动机启动问题解析与实现
目录 引言问题分析 2.1 发动机启动状态管理 2.2 手动启动与关联启动逻辑 2.3 最晚启动发动机的确定Python 实现 3.1 代码实现 3.2 <...

Java 注解使用教程
简介 Java 1.5 引入了注解,现在它在 Java EE 框架(如 Hibernate、Jersey 和 Spring )中被大量使用。Java 注释是该语言的一个强大特性,用于向 Java 代码中添加元数据。它们不直接影响程序逻辑,但可以由工具、库或框架…...

网络安全学习
博客目录 1.Ddos 攻击2.SYN Flood3.如何应对 Ddos 攻击4.Xss 漏洞5.越权访问漏洞6.水平越权与垂直越权7.水平越权8.垂直越权 1.Ddos 攻击 DDos 全名 Distributed Denial of Service,翻译成中文就是分布式拒绝服务。指的是处于不同位置的多个攻击者同时向一个或数个…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

Kubernetes原生自动化部署工具Keel:实现容器镜像自动更新的最后一公里
1. 项目概述:什么是Keel,以及它解决了什么问题如果你和我一样,在团队里负责过一段时间的应用部署和更新,那你一定对“发布日”的紧张感深有体会。开发那边代码一提交,这边就得开始手动拉取镜像、更新Kubernetes的Deplo…...

Agent 一接分布式缓存就开始数据不一致:从 Cache Coherence 到 Write-Through Guard 的工程实战
一、缓存不一致的生产陷阱 在生产环境中部署 Agent 系统时,一个常见的诡异现象是:Agent 从 Redis 缓存读取的业务状态与数据库实际值不一致,导致后续决策出现偏差。这个问题在缓存 TTL 到期前难以察觉,高并发下却反复出现。⚠️ 某…...

智能合约赋能AI代理:构建可验证、可审计的自动化工作流
1. 项目概述:当技能遇上智能合约最近在探索AI代理(AI Agent)的落地应用时,我遇到了一个非常有意思的项目:saralobo/skill-ai-execution-contract。这个项目名字乍一看有点长,但拆解开来,核心是“…...

Linux系统下Vue开发环境搭建:从Node.js到Vite的完整指南
1. 项目概述:为什么要在Linux上搭建Vue环境?对于前端开发者而言,Vue.js 早已不是陌生的名字。它凭借其渐进式的设计理念、灵活的组件化系统和相对平缓的学习曲线,成为了构建现代Web应用的主流框架之一。然而,很多开发者…...
)
【负荷预测】基于LSTM-KAN的负荷预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

使用taotoken聚合api后模型响应延迟的实际体感观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken聚合api后模型响应延迟的实际体感观察 作为一名日常需要调用多种大模型API的开发者,将多个供应商的API接入…...

【BK3633】从规格书到实战:解锁蓝牙5.2双模芯片的十大核心应用场景
1. BK3633芯片核心特性解析 第一次拿到BK3633规格书时,我被它的参数惊艳到了——这简直是为物联网设备量身定制的瑞士军刀。作为博通集成推出的蓝牙5.2双模芯片,它完美兼顾了高性能与低功耗这对"冤家"。实测下来,全速运行电流仅5mA…...