七大排序思想
目录
七大排序的时间复杂度和稳定性
排序
插入排序
简单插入排序
希尔排序
选择排序
简单选择排序
堆排序
交换排序
冒泡排序
快速排序
快排的递归实现
hoare版本的快排
挖坑法的快排
双指针法的快排
快排的非递归
归并排序
归并的递归实现
归并的非递归实现
补充
快排的三路划分
七大排序的时间复杂度和稳定性
排序时间的复杂度和稳定性-CSDN博客关于七大排序的时间复杂度和稳定性的总结,帮助读者迅速掌握各各排序的优劣,在不同情况下如何选择。https://blog.csdn.net/2401_87944878/article/details/145404375
排序
排序就是将一组数据按照递增或递减的方式将其排列。
排序包含两种;
内部排序:数据元素全部放在内存中的排序。
外部排序:数据太多不能同时放在内存中,根据排序的过程不能在内外存之间移动的排序。外部排序要对文件进行操作。
排序包含有四大实现:插入排序,选择排序,交换排序,归并排序。根据这四个实现又可以分支出一共7个排序思想:简单插入排序,希尔排序;选择排序,堆排序;冒泡排序,快速排序;归并排序。下面我们对这七种排序进行讲解。

插入排序
插入排序包含两种:简单插入排序,希尔排序。
简单插入排序

如图,简单插入怕排序就是遍历原数组,将每一个元素放在其指定位置。先拿出一个元素,向前找看,比它大的先后移,直到找到比它小的。
//简单插入排序
void InsertSort(int* a, int n)
{//插入排序,向前找到元素的指定位置for (int i = 1; i < n; i++){int end = i;int cur = a[end];while(end>0){if (a[end - 1] > cur){a[end] = a[end - 1];end--;}elsebreak;}a[end] = cur;}
}希尔排序
希尔排序实际上是对简单插入排序的一种优化。简单插入排序每次与其相邻的元素进行比较,而希尔排序是将一个数组分成多个组,将每个组进行简单插入排序,这样可以让大的数迅速到前面去,小的数迅速到后面去。

可以看到第一次gap是5时,将下标0和5比较,1和6比较,2和7比较....这样可以迅速将大的数移到前面去,将小的数移到后面去,这样就使的数组更加趋于有序的状态。
通过gap从大到小的变化,使得当gap较小的时候可以快速向前找到它的位置,更快的让每次循环break掉,让效率更快。
//希尔排序
void ShellSort(int* a, int n)
{//希尔排序与插入排序的区别在于,其先进行预排序int gap = n;while (gap > 1){gap /= 2;for (int i = 0; i < gap; i++){for (int m = i + gap; m < n; m += gap){int end = m;int cur = a[end];while (end > 0){if (a[end - 1] > cur){a[end] = a[end - 1];end--;}elsebreak;}a[end] = cur;}}}
}选择排序
选择排序包含两种简单选择排序和堆排序;
简单选择排序
简单选择排序就是遍历原数组,直接找到最大值或最小值将其放在尾和首,可以一次只找出一个最值,也可以将最大值和最小值同时找到。

以上是遍历未排序的数组每次找出最下的元素交换,下面演示遍历未排序的数组每次找打最小和最大的元素。
//交换函数
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//简单选择排序
void SelectSort(int* a, int n)
{//一次遍历,选出最大值和最小值int left = 0;int right = n - 1;while (left < right){int min = left;int max = left;for (int i = left; i <= right; i++){if (a[min] > a[i])min = i;if (a[max] < a[i])max = i;}//交换Swap(&a[left], &a[min]);//注意此处,如果left对应的值就是最大值的时候,//将min和left交换后,max就在min的位置了if (left == max)Swap(&a[right], &a[min]);elseSwap(&a[right], &a[max]);left++, right--;}
}堆排序
堆排序就是利用二叉树的性质,通过建大堆或小堆,将最大的数据或最小的数据放在指定位置。在二叉树中已经详细讲过堆了,这里就直接贴代码。
二叉树(C语言)-CSDN博客文章浏览阅读1.3k次,点赞19次,收藏18次。帮助读者快速掌握树这一数据结构,了解堆的功能,能够实现堆排序,以及如何再大量数据中快速找到前K个最大元素,如何处理普通二叉树,普通二叉树的遍历等知识。https://blog.csdn.net/2401_87944878/article/details/145262931https://blog.csdn.net/2401_87944878/article/details/145262931https://blog.csdn.net/2401_87944878/article/details/145262931https://blog.csdn.net/2401_87944878/article/details/145262931https://blog.csdn.net/2401_87944878/article/details/145262931![]() https://blog.csdn.net/2401_87944878/article/details/145262931
https://blog.csdn.net/2401_87944878/article/details/145262931
//向下调整
void AdjustDown(int* a, int n, int parent)
{int child = 2 * parent + 1;while (child < n){if (child+1<n&&a[child] < a[child + 1])child++;if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}elsebreak;}
}//堆排序
void HeapSort(int* a, int n)
{//先建大堆for (int i = (n - 2) / 2; i >= 0; i--){//向下调整AdjustDown(a, n, i);}//将堆顶的最大值和堆低交换int sz = n - 1;Swap(&a[0], &a[sz]);sz--;while (sz > 0){AdjustDown(a, sz + 1, 0);Swap(&a[0], &a[sz]);sz--;}
}交换排序
交换排序分为冒泡排序和快速排序。
冒泡排序
冒泡排序简单,没有实际作用,这里直接贴代码。

//冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){for (int m = 0; m < n - 1 - i; m++){if (a[m] > a[m + 1])Swap(&a[m], &a[m + 1]);}}
}快速排序
快速排序是将一个元素key作为基准,先找到这个key的准确位置,将小于key的放在key的左边,将大于key的放在右边。
快排的递归实现
hoare版本的快排

如图:将数组首元素作为key,通过左右指针,让R指针先走找到小于key的值停,L指针再走大于key的时候停,将L位置和R位置交换,直到L和R相遇时停止,这个位置就是key排序后的位置。
思考:为什么要让R指针想走?能否让L指针想走?
关于key的选择有三种方法:选择最左边的,随机选择,比较数组左右中间这三个值,选出次小的值。此处选择三数取中最好,可以尽量避免只出现一个递归函数。
//快排:Hoare版本
void QuickSort(int* a, int begin,int end)
{if (begin >= end)return;//快排就是将key放在正确位置上去。//三数取中int mid = Mid(begin, end);Swap(&a[begin], &a[mid]);int keyi = begin;int left = begin;int right = end;while (left < right){while (left < right && a[right] >= a[keyi])right--;while (left < right && a[left] <= a[keyi])left++;Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);keyi = left;QuickSort(a, begin, keyi - 1);QuickSort(a, keyi+1, end);
}挖坑法的快排
利用挖坑法可以直接不用思考数组那一边的指针先走的问题。

挖坑法就是将keyi的位置值保留,R指针找比key小的将其填在keyi的位置,R指针处变为坑,直到L指针和R指针相遇,将其位置的key填入坑。
//快排:挖坑法
void HoleSort(int* a, int begin, int end)
{if (begin >= end)return;int mid = Mid(begin, end);Swap(&a[mid], &a[begin]);int hole = begin;int left = begin;int right = end;int key = a[hole];while (left < right){while (left < right && a[right] >= key)right--;a[hole] = a[right];hole = right;while (left < right && a[left] <= key)left++;a[hole] = a[left];hole = left;}a[hole] = key;int keyi = hole;HoleSort(a, 0, keyi - 1);HoleSort(a, keyi+1, end);
}双指针法的快排

分别利用两个指针,一个向前面走如果cur对用的值比key小就交换,两个指针都向前移动;如果cur对应的值大就不交换,cur向前移动。
//快排:双指针法
void DPoint(int* a, int begin, int end)
{if (begin >= end)return;int mid = Mid(begin, end);Swap(&a[begin], &a[mid]);int keyi = begin;int cur = begin;int pre = begin;while (cur <= end){if (a[cur] <= a[keyi]){if (cur != pre)Swap(&a[cur], &a[pre]);cur++;pre++;}else{cur++;}}Swap(&a[keyi], &a[pre - 1]);keyi = pre - 1;DPoint(a, begin, keyi - 1);DPoint(a, keyi+1, end);
}快排的非递归
快排的非递归就是利用栈将其begin和end的值储存起来,再利用栈的“后入先出”的性质,每一次拿出一个范围再放入子范围,直到栈的空间为空时停止。
此处以Hoare的非递归为例。
typedef struct Stack
{int* a;int size;int capacity;
}Stack;//栈的初始化
void StackInit(Stack* sp)
{sp->capacity = 4;sp->a = (int*)malloc(sizeof(int) * (sp->capacity));if (sp->a == NULL)perror("malloc failed");sp->size = 0;
}//入栈
void StackPush(Stack* sp, int x)
{//检查空间够不够if (sp->size == sp->capacity){sp->capacity *= 2;int* tmp = (int*)realloc(sp->a, sizeof(int) * (sp->capacity));if (tmp == NULL)perror("realloc failed");sp->a = tmp;}sp->a[sp->size] = x;sp->size++;
}//出栈
void StackPop(Stack* sp)
{sp->size--;
}//返回栈顶元素
int StackTop(Stack* sp)
{return sp->a[sp->size - 1];
}//检查栈空间是否为空
bool IsStackEmpty(Stack* sp)
{if (sp->size == 0)return true;elsereturn false;
}//快排:非递归
void QuickNon(int* a, int begin, int end)
{//快排的非递归就是将快排的左右间距存储在栈中Stack s;StackInit(&s);StackPush(&s, end);StackPush(&s, begin);while (!IsStackEmpty(&s)){int begin = StackTop(&s);StackPop(&s);int end = StackTop(&s);StackPop(&s);int left = begin;int keyi = left;int right = end;while (left < right){while (left < right && a[right] >= a[keyi])right--;while (left < right && a[left] <= a[keyi])left++;Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;if (begin < keyi - 1){StackPush(&s, keyi - 1);StackPush(&s, begin);}if (keyi + 1 < end){StackPush(&s, end);StackPush(&s, keyi + 1);}}
}归并排序

归并排序的实现就是:先对小范围排序,再对大范围排序。如图:相对两个元素进行排序,再对4个元素进行排序,依次依次*2向后排序。
归并的递归实现
//归并排序
void Merge(int* a, int begin, int end)
{if (begin >= end)return;int mid = (begin + end) / 2;Merge(a, begin, mid);Merge(a, mid + 1, end);int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int* tmp = (int*)malloc(sizeof(int) * (end - begin + 1));int j = 0;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];memcpy(a + begin, tmp, sizeof(int) * (end - begin + 1));free(tmp);
}归并的非递归实现
归并的非递归实现就不能用栈来存储18首尾的范围了,可以直接从2个元素排序开始,依次*2直到排完为止。
//归并的非递归实现
void MergeNon(int* a, int begin, int end)
{int gap = 1;while (gap < end){for (int i = 0; i <= end; i += 2 * gap){int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;if (begin2 > end){break;}if (end2 > end)end2 = end;int* tmp = (int*)malloc(sizeof(int) * (end2 - begin1 + 1));int j = 0;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];memcpy(a + i, tmp, sizeof(int) * (end2-i+1));free(tmp);}gap *= 2;}
}补充
关于快排,当有大量重复的数据出现的时候,快排的key的位置可能就是最左边,导致向下递归后还是只有一组,当大量出现这种情况的时候就会导致快排变成简单选择排序,时间复杂度大大增加,导致效率降低。此处可以采用三路划分的快排解决。
快排的三路划分
三路划分与普通快排的区别:普通快排将数组分成两个部分,大于key和小于key的;而三路划分将快排分成三个部分,大于key,小于key和等于key的。
分为左右两个指针以及一个遍历数组的指针,将大于key的调到右边,将小于key的调到左边,将等于key的放在中间。
//快排的三路划分
void TQuickSort(int* a, int begin, int end)
{if (begin >= end)return;int mid = Mid(begin, end);Swap(&a[begin], &a[mid]);int keyi = begin;int key = a[begin];int left = begin;int cur = begin;int right = end;while (cur <= right){if (a[cur] < key){if (cur != left)Swap(&a[left], &a[cur]);left++, cur++;}else if (a[cur] > key){Swap(&a[cur], &a[right]);right--;}elsecur++;}keyi = left;TQuickSort(a, begin, keyi - 1);TQuickSort(a, keyi + 1, end);
}相关文章:
七大排序思想
目录 七大排序的时间复杂度和稳定性 排序 插入排序 简单插入排序 希尔排序 选择排序 简单选择排序 堆排序 交换排序 冒泡排序 快速排序 快排的递归实现 hoare版本的快排 挖坑法的快排 双指针法的快排 快排的非递归 归并排序 归并的递归实现 归并的非递归实现…...

intra-mart实现简易登录页面笔记
一、前言 最近在学习intra-mart框架,在此总结下笔记。 intra-mart是一个前后端不分离的框架,开发时主要用的就是xml、html、js这几个文件; xml文件当做配置文件,html当做前端页面文件,js当做后端文件(js里…...

SpringBoot整合RocketMQ
前言 在当今快速发展的软件开发领域,构建高效、稳定的应用系统是每个开发者的追求。Spring Boot 作为一款极具影响力的开发框架,凭借其强大的自动化配置和便捷的开发特性,极大地简化了项目搭建过程。使用 Spring Boot,我们无需再…...

深入理解 YUV Planar 和色度二次采样 —— 视频处理的核心技术
深入理解 YUV Planar 和色度二次采样 —— 视频处理的核心技术 在现代视频处理和编码中,YUV 颜色空间和**色度二次采样(Chroma Subsampling)**是两个非常重要的概念。它们的结合不仅能够显著减少视频数据量,还能在保持较高视觉质量的同时优化存储和传输效率。而 YUV Plana…...

项目顺利交付,几个关键阶段
年前离放假还有10天的时候,来了一个应急项目, 需要在放假前一天完成一个演示版本的项目,过年期间给甲方领导看。 本想的最后几天摸摸鱼,这么一来,非但摸鱼不了,还得加班。 还在虽然累,但也是…...

第七天 开始学习ArkTS基础,理解声明式UI编程思想
学习 ArkTS 的声明式 UI 编程思想是掌握 HarmonyOS 应用开发的核心基础。以下是一份简洁高效的学习指南,帮助你快速入门: 一、ArkTS 声明式 UI 核心思想 数据驱动 UI f(state):UI 是应用状态的函数,状态变化自动触发 UI 更新。单…...
)
windows C++ Fiber (协程)
协程,也叫微线程,多个协程在逻辑上是并发的,实际并发由用户控件。 在windows上引入了纤程(fiber)。 WinBase.h 中函数原型 #if(_WIN32_WINNT > 0x0400)// // Fiber begin //#pragma region Application Family or OneCore Family or Game…...

游戏引擎学习第89天
回顾 由于一直没有渲染器,终于决定开始动手做一个渲染器,虽然开始时并不确定该如何进行,但一旦开始做,发现这其实是正确的决定。因此,接下来可能会花一到两周的时间来编写渲染器,甚至可能更长时间…...

2025新鲜出炉--前端面试题(一)
文章目录 1. vue3有用过吗, 和vue2之间有哪些区别2. vue-router有几种路由, 分别怎么实现3. webpack和rollup这两个什么区别, 你会怎么选择4. 你能简单介绍一下webpack项目的构建流程吗5. webpack平时有手写过loader和plugin吗6. webpack这块你平时做过哪些优化吗?7…...

教程 | i.MX RT1180 ECAT_digital_io DEMO 搭建(一)
本文介绍 i.MX RT1180 EtherCAT digital io DEMO 搭建,Master 使用 TwinCAT ,由于步骤较多,分为上下两篇,本文为第一篇,主要介绍使用 TwinCAT 控制前的一些准备。 原厂 SDK 提供了 evkmimxrt1180_ecat_examples_digit…...
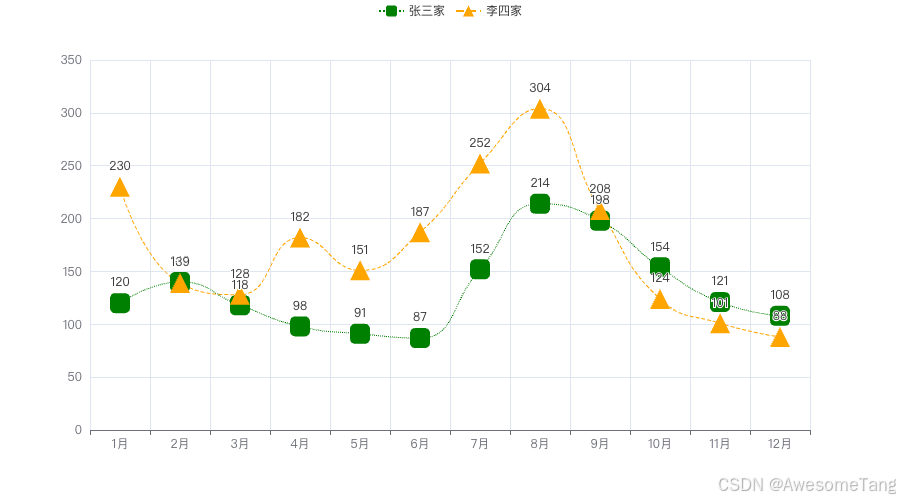
Pyecharts系列课程04——折线图/面积图(Line)
本章我们学习在Pyecharts中折线图(Line)的使用。折线图通用应用于数据的趋势分析。 折线图 我们现在有两组数据,x_data是2024年的月份,y_data为对应张三甲每个月的用电量。 # 家庭每月用电量趋势 x_data ["1月", &q…...

变压器-000000
最近一个项目是木田12V的充电器,要设计变压器,输出是12V,电压大于1.5A12.6*1.518.9W. 也就是可以将变压器当成初级输入的一个负载。输入端18.9W. 那么功率UI 。因为变压器的输入是线性上升的,所以电压为二份之一,也就是1/2*功率…...

凝思60重置密码
凝思系统重置密码 - 赛博狗尾草 - 博客园 问题描述 凝思系统进入单用户模式,在此模式下,用户可以访问修复错误配置的文件。也可以在此模式下安装显卡驱动,解决和已加载驱动的冲突问题。 适用范围 linx-6.0.60 linx-6.0.80 linx-6.0.100…...

linux——网络计算机{序列化及反序列化(JSON)(ifdef的用法)}
linux——网络(服务器的永久不挂——守护进程)-CSDN博客 目录 一、序列化与反序列化 1. 推荐 JSON 库 2. 使用 nlohmann/json 示例 安装方法 基础用法 输出结果 3. 常见操作 4. 其他库对比 5. 选择建议 二、ifdef宏的用法 基本语法 核心用途…...

【教程】docker升级镜像
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 自动升级 手动升级 无论哪种方式,最重要的是一定要通过-v参数做数据的持久化! 自动升级 使用watchtower,可…...

迅为RK3568开发板篇OpenHarmony实操HDF驱动控制LED-编写应用APP
在应用代码中我们实现如下功能: 当应用程序启动后会获取命令行参数。如果命令行没有参数,LED 灯将循环闪烁;如果命令行带有参数,则根据传输的参数控制 LED 灯的开启或关闭。通过 HdfIoServiceBind 绑定 LED灯的 HDF 服务ÿ…...

python代码
python\main_script.py from multiprocessing import Process import subprocessdef call_script(args):# 创建一个新的进程来运行script_to_call.pyprocess Process(targetrun_script, args(args[0], args[1]))process.start()process2 Process(targetrun_script, args(arg…...

React 打印插件 -- react-to-print
一、安装依赖 npm install react-to-print 二、使用 import { useReactToPrint } from "react-to-print"; import React, { useRef, forwardRef } from react;const Content () > {const contentRef useRef(null);const reactToPrintFn useReactToPrint({ c…...

探索C语言简易计算器程序的实现与优化
在C语言编程学习中,实现一个简易计算器是一个常见且有趣的练习项目。它不仅能帮助我们巩固基本的语法知识,如函数、循环、分支结构,还能让我们深入理解程序设计的逻辑。接下来,我们将分析三段实现简易计算器功能的C语言代码&#…...

深入了解 MySQL:从基础到高级特性
引言 在当今数字化时代,数据的存储和管理至关重要。MySQL 作为一款广泛使用的开源关系型数据库管理系统(RDBMS),凭借其高性能、可靠性和易用性,成为众多开发者和企业的首选。本文将详细介绍 MySQL 的基础概念、安装启…...

基于Claude API构建可编程AI智能体:从对话到自动化生产单元
1. 项目概述:从Claude中“招聘”一个AI伙伴最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。初看这个标题,你可能会有点摸不着头脑:Claude不是Anthropic公司开发的那个AI助手吗?怎么还能从它那里“招聘…...

Chrome 扩展 uMatrix 被弃用,MV3 环境下 matrix³ 原型尝试实现其功能
Chrome 扩展 uMatrix 被弃用,MV3 环境下如何实现其功能?matrix 原型来尝试 曾经有一款很棒的 Chrome 扩展程序叫 uMatrix,它由 uBlock Origin 的开发者 Raymond Hill 编写,是一种直观控制网站权限和子资源请求的工具。 它看上去是…...

【仿真学习框架】MultiModalWBC 完全指南:从入门到精通的多模态全身控制框架
版本: v1.0 | 日期: 2026-05-15 目标读者: 具身智能研究者、机器人学习工程师、人形机器人开发者 前置知识: 基础强化学习(PPO)、PyTorch、刚体动力学概念 📑 目录 1. 初见 MultiModalWBC:我们到底在解决什么问题? 1.1 人形机器人控制的"碎片化"困境 1.2 多模态…...

RP2350微控制器模拟Macintosh 128K:嵌入式复古计算实践
1. 项目概述:在RP2350上复活Macintosh 128K拿到一块Adafruit Fruit Jam开发板,看着上面那颗RP2350双核微控制器,我就在想,除了跑跑MicroPython、控制几个LED,这玩意儿还能干点啥更“出格”的事?答案是把一台…...

基于规则引擎与AI Agent的Google Ads自动化营销系统设计与实践
1. 项目概述:当AI遇上Google Ads,一个自动化营销引擎的诞生最近在折腾一个挺有意思的项目,起因是发现很多团队在管理Google Ads广告时,依然在重复着大量手动、低效的操作。无论是关键词的日常拓词、否定关键词的筛选,还…...

FeFET时间域内存计算宏:突破AI边缘计算能效瓶颈
1. 项目概述:FeFET时间域内存计算宏的创新实现在人工智能和边缘计算蓬勃发展的当下,传统冯诺依曼架构面临着一个根本性挑战:数据在处理器和存储器之间的频繁搬运导致的高能耗和延迟瓶颈。这个问题在需要大量并行乘累加(MAC)运算的神经网络应用…...

边缘计算赋能工业智能化:重大危险源监测+产线控制+视觉分析一体化解决方案
在工业 4.0 与智能制造深度融合的今天,工业现场产生的数据量呈指数级增长。传统的 "云端集中式" 数据处理架构在面对毫秒级实时控制、海量视觉数据传输、高危场景 724 小时不间断监测等需求时,逐渐暴露出延迟高、带宽成本大、网络依赖强、数据…...

Figma设计稿自动化生成Markdown文档:从API调用到CI/CD集成
1. 项目概述:从设计稿到结构化文档的自动化桥梁如果你是一名前端开发者、产品经理或是UI设计师,一定经历过这样的场景:Figma里精心打磨的设计稿终于定稿,接下来需要将其转化为开发文档、产品需求文档或者设计规范文档。这个过程&a…...

【ElevenLabs卡纳达文语音实战指南】:2024年唯一经生产环境验证的7步本地化部署方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs卡纳达文语音技术概览与生产价值定位 ElevenLabs 作为全球领先的文本转语音(TTS)平台,自2023年Q4起正式支持卡纳达语(Kannada)&…...

从零到一:在MissionPlanner中配置与可视化RC接收器RSSI
1. 什么是RSSI?为什么需要监控它? 如果你玩过无人机或者遥控模型,肯定遇到过信号突然中断的情况。那种眼睁睁看着爱机失控坠落的无力感,我深有体会。RSSI(Received Signal Strength Indicator)就是帮助我们…...