RabbitMQ 从入门到精通:从工作模式到集群部署实战(五)
#作者:闫乾苓
系列前几篇:
《RabbitMQ 从入门到精通:从工作模式到集群部署实战(一)》:link
《RabbitMQ 从入门到精通:从工作模式到集群部署实战(二)》: link
《RabbitMQ 从入门到精通:从工作模式到集群部署实战(三)》:link
《RabbitMQ 从入门到精通:从工作模式到集群部署实战(四)》:link
文章目录
- 日志检查
- 日志相关时间关键字
- 常见错误日志及处理方法
- 内存不足 memory alarm
- 磁盘空间不足 disk alarm
- 连接错误 connection error
- 队列阻塞 queue blocked
- 消息丢失警告 message dropped
- 权限错误 access refused
- 节点通信错误 cluster_node_down
- 插件启动失败 plugin startup error
- 深度巡检
- 监控指标
- 集群指标
- 节点指标
- 单个队列
- 备份恢复
- 拓补(元数据)数据备份恢复
- 消息数据备份和恢复
- 在web页面模拟数据被删除
- 消息数据恢复
- 数据迁移
- 元数据迁移
- 消息数据迁移
- 开启shovel插件
- 数据持久化
- 容器
日志检查
可以使用命令查看日志
rabbitmq-diagnostics consume_event_stream
日志相关时间关键字
队列、交换和绑定事件
queue.deleted
queue.created
exchange.created
exchange.deleted
binding.created
binding.deleted
连接和通道事件
connection.created
connection.closed
channel.created
channel.closed
消费者事件
consumer.created
consumer.deleted
策略和参数事件
policy.set
policy.cleared
parameter.set
parameter.cleared
虚拟机活动
vhost.created
vhost.deleted
vhost.limits.set
vhost.limits.cleared
用户管理事件
user.authentication.success
user.authentication.failure
user.created
user.deleted
user.password.changed
user.password.cleared
user.tags.set
权限事件
permission.created
permission.deleted
topic.permission.created
topic.permission.deleted
报警事件
alarm.set
alarm.cleared
Shovel事件
shovel.worker.status
shovel.worker.removed
联邦事件
federation.link.status
federation.link.removed
如何将日志写入rabbitmq队列
RabbitMQ 可以将日志条目转发到系统exchange,该exchange将在默认虚拟主机amq.rabbitmq.log中声明。
默认情况下,此功能已停用。要激活此日志记录,请将配置log.exchange键设置为true
log.exchange.level可用于控制此日志记录目标将使用的日志级别:
log.exchange = true
log.exchange.level = warning
amq.rabbitmq.log是topic ex,可以按此使用。日志条目以消息形式发布。消息正文包含已记录的消息,路由密钥设置为日志级别。
常见错误日志及处理方法
关注这些 RabbitMQ 错误和警告日志,可以有效地预防和诊断潜在的系统问题,保证 RabbitMQ 集群的正常运行。
内存不足 memory alarm
=WARNING REPORT====
rabbit@hostname === memory resource limit alarm set on node rabbit@hostname
原因:
RabbitMQ 使用内存来缓存消息,如果节点内存使用量超过限制(默认是物理内存的 40%),会触发内存报警,停止接收新的消息。
解决方法:
- 检查内存使用情况,关闭不必要的应用进程。
- 调整
vm_memory_high_watermark参数,增加允许的内存占用比例。 - 增加服务器的物理内存或调整消息持久化策略,将消息写入磁盘,减小内存消耗。
磁盘空间不足 disk alarm
=WARNING REPORT====
rabbit@hostname === disk free space alarm set on node rabbit@hostname
原因:
当可用磁盘空间低于阈值(默认是 50MB)时,RabbitMQ 会停止接受新的消息发布,以防止因磁盘空间不足导致的系统崩溃。
解决方法:
- 清理磁盘空间,例如删除旧日志文件和不必要的数据。
- 调整磁盘报警阈值
disk_free_limit。 - 增加服务器的磁盘空间。
连接错误 connection error
=ERROR REPORT====
connection <0.2001.0> closing due to an error: missed heartbeats from client, timeout
原因:
此错误通常由于 RabbitMQ 客户端没有在指定时间内发送心跳信号,可能是网络连接不稳定或客户端发生异常。
解决方法:
- 检查网络连接,确保客户端和 RabbitMQ 服务器之间的网络稳定。
- 增加心跳超时设置(在客户端和服务器端都需要配置)。
- 检查客户端是否有性能瓶颈,是否超时未能发送心跳。
队列阻塞 queue blocked
=WARNING REPORT====
rabbit@hostname === queue 'queue_name' in vhost '/' is blocked
原因:
当队列的消息数超过允许限制时,RabbitMQ 会阻止该队列接收新的消息,以防止因队列过大而导致系统崩溃。
解决方法:
- 增加队列的最大长度限制,配置
max-length或max-length-bytes参数。 - 优化消费者速度,确保及时处理队列中的消息。
- 设置消息的 TTL(生存时间),自动清理队列中过期的消息。
消息丢失警告 message dropped
=WARNING REPORT====
rabbit@hostname === messages are being dropped due to high load or resource constraints
原因:
在高负载或资源受限的情况下,RabbitMQ 可能会丢弃某些非持久化消息,以保持系统的稳定性。
解决方法:
优化生产者速率,减轻 RabbitMQ 的负载。
将重要的消息标记为持久化,减少被丢弃的风险。
扩展 RabbitMQ 集群,分担消息负载。
权限错误 access refused
=ERROR REPORT====
access to vhost 'vhost_name' refused for user 'username': vhost not found or permissions denied
原因:
用户没有访问某个 vhost 的权限,可能是配置错误或没有正确分配权限。
解决方法:
检查 RabbitMQ 用户权限,确保用户有正确的访问权限。
使用 rabbitmqctl 设置权限:
rabbitmqctl set_permissions -p vhost_name username ".*" ".*" ".*"
节点通信错误 cluster_node_down
=ERROR REPORT====
cluster_node_down, 'rabbit@other_node'
原因:
集群中的一个节点无法与其他节点通信,可能是网络问题或该节点发生了故障。
解决方法:
- 检查网络连接和各节点的状态,确保网络畅通。
- 检查该节点的资源使用情况,确保内存和磁盘空间充足。
- 如果节点无法恢复,可能需要重新启动或重新加入集群。
插件启动失败 plugin startup error
=ERROR REPORT====
plugin error: "some_plugin" failed to start due to missing dependencies or configuration issues
原因:
RabbitMQ 插件无法启动,可能是依赖关系错误或插件配置不正确。
解决方法:
- 确认所需的依赖插件已安装并启用。
- 检查插件的配置,确保配置项无误。
- 查看 RabbitMQ 文档中该插件的安装和配置指南,检查是否有遗漏步骤。
深度巡检
关键配置参数说明
total_memory_available_override_value = 3GiB
vm_memory_high_watermark.relative = 0.6
vm_memory_high_watermark.absolute = 2GiB
vm_memory_high_watermark_paging_ratio = 0.5
#disk_free_limit.absolute = 500MB
disk_free_limit.relative = 0.05
vm_memory_calculation_strategy = rss
cluster_partition_handling = autoheal
vm_memory_high_watermark
- 定义了 RabbitMQ 在何时会因为内存使用过高而发出警告,并可能阻塞发布者的连接。它是一个内存阈值,用于控制 RabbitMQ 的流控机制。当 RabbitMQ 的内存使用超过这个阈值时,它会触发流控机制,如阻塞发布者的连接,以防止内存耗尽导致的服务崩溃。
- 可以使用命令动态调整(使用此方式配置的参数,服务重启后,配置会恢复默认值),可以通过设置内存的绝对值或者比例设置参数值,最大值为total_memory_available_override_value 参数所指定的值。所以不管使用那种方式,设置完成的值都不会超过此值。
命令行动态设置
# 设置绝对值
rabbitmqctl set_vm_memory_high_watermark absolute 2GB# 也可以通过设置比例调整
rabbitmqctl set_vm_memory_high_watermark 0.6
动态设置完成后,可以使用下面的命令查看:
# rabbitmqctl status |grep 'Memory high watermark setting'
Memory high watermark setting: 0.4 of available memory, computed to: 1.4286 gb
- rabbitmq 官方文档中在k8s中部署rabbitmq 节点集群中此参数的值为:1717986919,单位为字节。约为1.6G
- 在rabbitmq.conf 配置文件中需要如下配置:
vm_memory_high_watermark.relative = 0.6
# 或者
vm_memory_high_watermark.absolute = 1Gib
vm_memory_high_watermark_paging_ratio
- 在实际应用中,vm_memory_high_watermark_paging_ratio 与 vm_memory_high_watermark 一起构成了 RabbitMQ 的内存管理策略。通过合理配 置这两个参数,可以在确保系统稳定运行的同时,最大化地利用内存资源来处理消息。
- 在某个 Broker 节点触及vm_memory_high_watermark 设置的内存阈值并阻塞生产者之前,它会尝试将队列中的消息从内存换页到磁盘以释放内存空间。持久化和非持久化的消息都会被转储到磁盘中,其中持久化的消息本身就在磁盘中有一份副本,这里会将持久化的消息从内存中清除掉。例如,如果 vm_memory_high_watermark 设置为 0.4(即物理内存的 40%),(官方建议设置此值区间为:0.4~0.66 ,不建议取值超过 0.7)vm_memory_high_watermark_paging_ratio 设置为 0.75(即 vm_memory_high_watermark 的 75%),则当内存使用量达到物理内存的 30%(即 0.4 * 0.75)时,RabbitMQ 将开始分页操作。这有助于在内存使用量较高时释放部分内存空间,并防止内存溢出。
命令行动态设置:
rabbitmqctl set_vm_memory_high_watermark paging_ratio 0.6
rabbitmq.conf中配置:
#当内存使用量达到高水位的 50% 时,RabbitMQ 开始将消息移到磁盘
vm_memory_high_watermark_paging_ratio = 0.5
total_memory_available_override_value
- 它影响 RabbitMQ 对内存使用的整体评估,从而影响内存相关的决策,如消息分页、内存警告等
- total_memory_available_override_value 设置的内存总量是 RabbitMQ 进行内存管理和决策的基础,而 vm_memory_high_watermark 则是在这个基础上设定的一个内存使用阈值。因此,vm_memory_high_watermark 的设置应该考虑到 total_memory_available_override_value 所设定的内存总量。
- 这个参数允许管理员手动设置 RabbitMQ 节点可用的总内存量。在容器化部署中特别有用,因为容器通常会有自己的内存限制。
# rabbitmq.conf
total_memory_available_override_value = 4GB不支持命令行动态修改
disk_free_limit.absolute
- RabbitMQ 在触发磁盘空间警报之前,磁盘上必须保留的最小可用空间量。
- 当剩余磁盘空间低于配置的阈值时,rabbitmq也会阻塞生产者,通过设置此参数可以避免因非持久化的消息持续换页,从而耗尽磁盘空间导致服务崩溃。
- 默认情况下,磁盘阈值为 50MB,表示当磁盘剩余空间低于50MB时,会阻塞生产者并停止内存中消息的换页动作
- 所需的最低磁盘可用空间量,确保 RabbitMQ 在有足够的磁盘空间来支持其操作的同时,避免因磁盘空间不足而导致性能下降或崩溃的问题
# rabbitmq.conf
# 设置绝对磁盘空间限制
disk_free_limit.absolute = 500MBrabbitmqctl set_disk_free_limit 500MB
disk_free_limit.relative
- 根据服务器上安装的内存容量来动态设置磁盘可用空间的相对阈值,例如,要将磁盘可用空间阈值设置为服务器内存容量的 50%,你可以这样配置: disk_free_limit.relative = 0.5
- 命令行动态调整,比如rabbitmq 官方文档中在k8s中部署rabbitmq 3节点集群中此参数的值为 disk_free_limit.absolute = 2GB
pod中的配置文件路径:/etc/rabbitmq/conf.d/10-operatorDefaults.conf
# rabbitmq.conf
disk_free_limit.relative = 0.05rabbitmqctl set_disk_free_limit mem_relative 0.05
vm_memory_calculation_strategy
Erlang虚拟机内存消耗计算策略,默认为rss策略,可选策略有:allocated 、 rss 、 legacy
rss 使用操作系统特定的方式查询内核来查找节点操作系统进程的 RSS(驻留集大小)值。此策略最为精确,并且默认在 Linux、MacOS、BSD 和 Solaris 系统上使用。使用此策略时,RabbitMQ 每秒运行一次短暂的子进程。
allocate 是一种查询运行时内存分配器信息的策略。它通常非常接近 rss 策略报告的值。 Windows 上默认使用此策略。
egacy使用遗留内存报告。这是RabbitMQ早期版本的内存报告方式,可能在某些情况下不够准确。为了向后兼容,RabbitMQ仍然保留了这种策略,但不建议在新版本中使用。
# rabbitmq.conf
vm_memory_calculation_strategy = rss
不支持动态设置
cluster_partition_handling
# rabbitmq.conf
cluster_partition_handling = autoheal
不支持动态设置
配置文件(如果没有配置)默认是 ignore 模式,即不自动处理网络分区,所以在这种模式下,当网络分区的时候需要人工介入
3种方法自动地处理网络分区 pause_minority 模式、pause_if_all_down 模式和 autoheal 模式,可以更加不同业务场景进行选择。
pause_minority
- 发生分区后,会自动关闭处于少数分区的节点,并在网络恢复后自动重新加入
- 适用于跨机架或可用区群集时,在单个区域中丢失大多数节点(区域)的概率被认为是非常低的情况。此模式会牺牲一些可用性,但具有自动恢复的能力。
- 在这种模式下,RabbitMQ的节点数量应为奇数(如3个或5个),以确保在分区时能够明确区分多数派和少数派。
autoheal
- 发生分区后,各分区下的节点正常工作,网络恢复后,会选出一个连接数最多、分区内节点数最多的节点为winner节点,并重启其他节点,其他节点从winner节点同步数据。
- 当更关注服务的连续性而不是跨节点的数据一致性时,可以采用此策略。
- 在网络恢复后,需要确保选出的winner节点具有最新的数据,以避免数据不一致的问题。
pause-if-all-down
- 在关注的节点全部下线后会关闭自己,在关注的节点上线后,可以选择忽略或通过autoheal机制来恢复。
- 此策略可以根据具体的业务需求进行灵活配置,适用于对节点状态有特定关注的情况。
- 需要配置关注的节点列表,并根据业务需求选择合适的恢复策略(ignore或autoheal)。
ignore
- 在网络可靠性达到最高实际可能的情况下使用,节点可用性是最重要的。此时,RabbitMQ会忽略网络分区事件,不做任何处理。
- 所有集群节点都可以位于同一机架或等效机架中,与交换机连接,该交换机也是路由对外界时,可以采用此策略。
- 采用此策略时,需要确保网络具有高可靠性,以避免因网络故障导致的消息丢失或系统不可用问题。
监控指标
集群指标
集群范围的指标提供了集群状态的高级视图。其中一些指标描述了节点之间的交互。此类指标的示例包括集群链接流量和检测到的网络分区。其他指标结合了所有集群成员的指标。所有节点的完整连接列表就是一个例子。这两种类型都是对基础设施和节点指标的补充。
GET /api/overview是返回集群范围指标

节点指标
有两个 HTTP API端点可以提供对节点特定指标的访问:
GET /api/nodes/{node}返回单个节点的统计信息
GET /api/nodes返回所有集群成员的统计数据
后一个端点返回一个对象数组。支持(或可以支持)该端点作为输入的监控工具应该优先选择该端点,因为它可以减少请求数量。如果不是这种情况,请使用前一个端点依次检索每个集群成员的统计信息。这意味着监控系统知道集群成员列表。
大多数指标都表示某个时间点的绝对值。有些指标表示最近一段时间内的活动(例如,GC 运行和回收的字节数)。后者指标在与之前的值和历史平均值/百分位值进行比较时最有用。

单个队列
各个队列指标可通过端点的HTTP API获得GET /api/queues/{vhost}/{qname}。
需要注意vhost / 在URL中需要使用URL编码 “%2F”替代。
比如: http://192.168.18.11:15672/api/queues/%2F/queue-quorum-01

下表列出了一些可用于监控队列状态的关键指标。其他一些指标(如队列状态和“空闲时间”)应被视为 RabbitMQ 贡献者使用的内部指标。

开启rabbitmq_prometheus 插件
[root@rbt01 ~]# rabbitmq-plugins enable rabbitmq_prometheus
Enabling plugins on node rabbit@rbt01:
rabbitmq_prometheus
The following plugins have been configured:rabbitmq_federationrabbitmq_managementrabbitmq_management_agentrabbitmq_prometheusrabbitmq_web_dispatch
Applying plugin configuration to rabbit@rbt01...
The following plugins have been enabled:rabbitmq_federationrabbitmq_prometheus
查看prometheus端口15692是否开启监听
[root@rbt01 ~]# netstat -ntlp |grep 15692
tcp 0 0 0.0.0.0:15692 0.0.0.0:* LISTEN 1797/beam.smp
http://192.168.18.11:15692/metrics

备份恢复
拓补(元数据)数据备份恢复
节点和集群存储的信息可以被认为是模式、元数据或拓扑。用户、虚拟主机、队列、交换、绑定、运行时参数都属于这一类。在 RabbitMQ 术语中,这些元数据称为定义。
可以将定义导出到文件,然后导入到另一个集群或用于架构备份。
定义文件可以在节点启动期间或之后导入。在多节点集群中,启动时导入实际上会导致节点在启动时执行重复工作。对于较小的定义文件,这无关紧要;但对于较大的文件,建议在集群部署(形成)后,在节点启动后导入定义
rabbitmqctl export_definitions
导出(备份)到文件:
[root@rbt01 ~]# rabbitmqctl export_definitions export01.json
Exporting definitions in JSON to a file at "export01.json" ...
从(备份)文件导入集群:
[root@rbt01 ~]# rabbitmqctl import_definitions export02.json
Importing definitions in JSON from a file at "export02.json" ...
Successfully started definition import. This process is asynchronous and can take some time. Watch target node logs for completion.

API /api/definitions
通过API /api/definitions接口导出
[root@rbt01 ~]# curl -o export_by_api_01.json -u admin:Admin.123 -X GET http://127.0.0.1:15672/api/definitions% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed
100 2149 100 2149 0 0 699k 0 --:--:-- --:--:-- --:--:-- 699k
通过API /api/definitions接口导入备份的数据
curl -u {username}:{password} -H “Content-Type: application/json” -X POST -T /path/to/definitions.file.json http://{hostname}:15672/api/definitions
curl -u admin:Admin.123 -H "Content-Type: application/json" -X POST -T export_by_api_01.json http://127.0.0.1:15672/api/definitions
消息数据备份和恢复
使用 durable=true 选项声明队列时,这确保了队列的元数据(比如队列的名称和属性)在 RabbitMQ 服务器重启后仍然存在。
要达到消息持久化的目的,在发布消息时,需要将消息的 delivery_mode 设置为 2(持久化消息)。这通常是在发送消息时通过 AMQP 客户端库的相应方法设置的。
如果只durable=true,而在发布消息是没有将delivery_mode 设置为 2,服务器重启后,元数据任然存在,消息数据会丢失。
消息数据备份
RabbitMQ官方文档描述子3.7.0 版本开始,所有消息数据全部存储在msg_stores/vhosts,所以只需备份此目录下的数据即可。
但经过实际测试,classic类型的队列(没开启镜像复制)使用下面的备份步骤,可以恢复数据,quorum类型的队列数据会全部丢失,所以quorum类型的队列不适合此方法备份恢复数据。
rabbitmqctl eval ‘rabbit_mnesia:dir().’

rabbitmq-diagnostics status | grep -A 2 -B 2 "Node data directory"
Data directoryNode data directory: /opt/rabbitmq_server-3.13.7/var/lib/rabbitmq/mnesia/rabbit@rbt01
Raft data directory: /opt/rabbitmq_server-3.13.7/var/lib/rabbitmq/mnesia/rabbit@rbt01/quorum/rabbit@rbt01
备份消息数据前,需要先停止app
[root@rbt01 ~]# rabbitmqctl start_app
Starting node rabbit@rbt01 ...
备份数据目录:
cd /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@rbt01/msg_stores/vhosts
cp -r 628WB79CIFDYO9LJI6DKMI09L/ /databak/rabbit_bak01/
在web页面模拟数据被删除



消息数据恢复
恢复数据前关闭rabbitmq服务
rabbitmqctl shutdown
将备份目录恢复
/opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@rbt01/msg_stores/vhosts
scp -r /databak/rabbit_bak01/628WB79CIFDYO9LJI6DKMI09L/* 628WB79CIFDYO9LJI6DKMI09L/
启动rabbitmq服务
rabbitmq-server -detached
查看数据已经恢复

数据迁移
元数据迁移
可以参考“数据备份恢复”章节,元数据(拓补数据)可以使用“导出,导入”的方式,classia类型的队列中的消息数据可以通过备份数据目录的方式,将数据同步到新环境。quorum类型的队列数据迁移因为不支持备份数据目录的方式,建议自行开发或者使用第三方工具,将消息数据导出,被同步到新环境的方式进行。
消息数据迁移
Rabbitmq shovel插件允许在不同的RabbitMQ实例或集群之间复制消息,实现数据迁移。
开启shovel插件
在k8s使用RabbitMQ Cluster Kubernetes Operator部署的Rabbitmq集群,需要源和目的集群都启用shovel插件,在yaml资源清单增加如下配置:
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmq-cluster02namespace: rabbitmq-shovel
spec:replicas: 3image: rabbitmq:3.13.7-managementrabbitmq:additionalPlugins:- rabbitmq_shovel- rabbitmq_shovel_management
将资源清单文件apply到k8s后,插件启用,通过web UI是否启用成功:

在web UI 界面配置shove 迁移(动态)
在shovel managenment中增加shove
下面示例是在k8s中部署的2个Rabbitmq集群配置队列数据迁移的shove配置
rabbitmq-cluster01
namespace:rabbitmq-test
k8s svc: rabbitmq-cluster01.rabbitmq-test.svc.cluster.localvhost: / (默认/ 虚拟主机在amqp中需要使用“%2F”转义 )queue: queue_quorum_01
账号密码:admin/Admin.123rabbitmq-cluster02
namespace:rabbitmq-shovel
queue: queue-quorum-02
k8s svc: rabbitmq-cluster02.rabbitmq-shovel.svc.cluster.localvhost: / (默认/ 虚拟主机在amqp中需要使用“%2F”转义 )queue: queue-quorum-02
账号密码:admin/Admin.123



配置完成后rabbitmq-cluster01中queue_quorum_01队列中的消息数据就被迁移到 rabbitmq-cluster02中的queue-quorum-02队列中了。


数据迁移完成后,如果不需要后期继续使用,可以进行删除。

使用API配置创建shove
192.168.123.240:64790 为Rabbitmq的webUI管理界面的IP和端口,本例为k8s中Rabbitmq svc的nodeport.
curl -v -u admin:Admin.123 -X PUT http://192.168.123.240:64790/api/parameters/shovel/%2f/my-shovel-01 \-H "content-type: application/json" \-d @- <<EOF
{"value": {"src-protocol": "amqp091","src-uri": "amqp://admin:Admin.123@rabbitmq-cluster01.rabbitmq-test.svc.cluster.local:5672/%2F","src-queue": "queue_quorum_01","dest-protocol": "amqp091","dest-uri": "amqp://admin:Admin.123@rabbitmq-cluster02.rabbitmq-shovel.svc.cluster.local:5672/%2F","dest-queue": "queue-quorum-02"}
}
EOF

查看已经创建shovel
curl -v -u admin:Admin.123 -X GET http://192.168.123.240:64790/api/shovels/
删除不需要的shovel
curl -v -u admin:Admin.123 -X DELETE http://192.168.123.240:64790/api/shovels/vhost/%2f/my-shovel-01
数据持久化
容器
组件数据
在k8s中使用RabbitMQ Cluster Kubernetes Operator 部署的Rabbitmq集群的持久化方案是在k8s集群中需要已经有部署好的storageClass,通过指定k8s storageClass的名字(本例为nfs)和需要的磁盘容量(本例为20G)来创建pv, storageClass会自动创建pvc,并与pv进行动态绑定。pv 挂在到rabbitmq pod中指定的目录,实现将pod中的数据写入storageClass 底层的存储服务器中。
下面是yaml配置
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmq-cluster01namespace: rabbitmq-testspec:replicas: 3image: rabbitmq:3.13.7-managementrabbitmq:persistence:storageClassName: nfsstorage: "20Gi"日志数据
在k8s中使用RabbitMQ Cluster Kubernetes Operator 部署的Rabbitmq集群中,Rabbitmq pod中的日志默认输出到stdout,如果需要持久存储,需要在yaml文件中增加日志写入文件的配置。
具体参考一下yaml:
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmq-cluster01namespace: rabbitmq-test
spec:replicas: 3tls:secretName: tls-secret-01image: rabbitmq:3.13.7-managementrabbitmq:additionalConfig: |log.file = /var/log/rabbitmq/rabbit.log相关文章:
RabbitMQ 从入门到精通:从工作模式到集群部署实战(五)
#作者:闫乾苓 系列前几篇: 《RabbitMQ 从入门到精通:从工作模式到集群部署实战(一)》:link 《RabbitMQ 从入门到精通:从工作模式到集群部署实战(二)》: lin…...
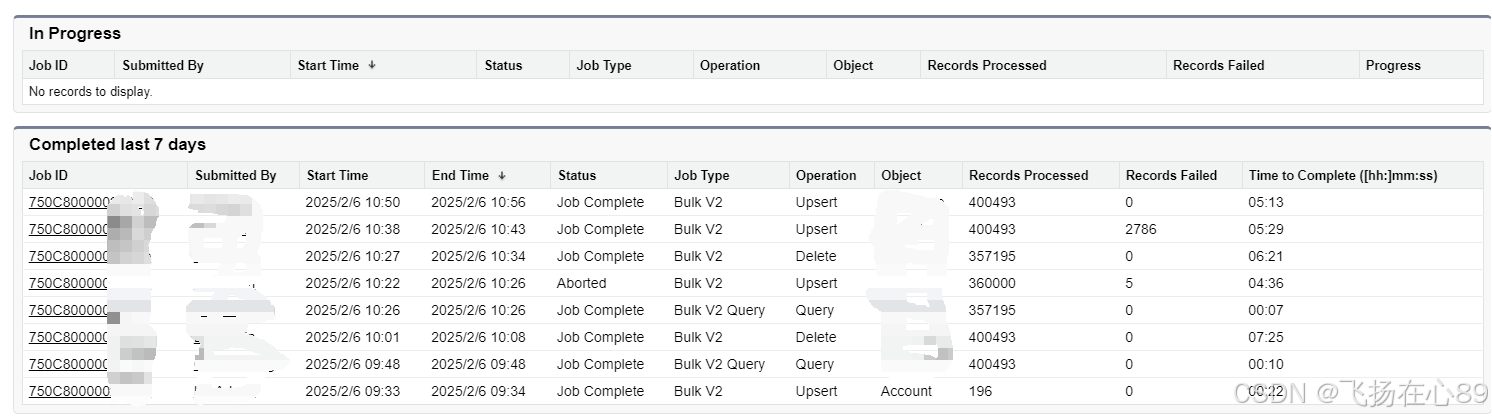
salesforce SF CLI 数据运维经验分享
SF CLI data默认使用bulk api v2, 数据操作效率有了极大的提高。 Bulk api v2的优点: 执行结果可以很直观的从Bulk Data Load Jobs中看到。相较于bulk api v1,只能看到job执行in progress,或者closed的状态,有了很大的改善。执行…...

5.2Internet及其作用
5.2.1Internet概述 Internet称为互联网,又称英特网,始于1969年的美国ARPANET(阿帕网),是全球性的网络。 互连网指的是两个或多个不同类型的网络通过路由器等网络设备连接起来,形成一个更大的网络结构。互连…...

【蓝桥杯—单片机】第十一届省赛真题代码题解题笔记 | 省赛 | 真题 | 代码题 | 刷题 | 笔记
第十一届省赛真题代码部分 前言赛题代码思路笔记竞赛板配置内部振荡器频率设定键盘工作模式跳线扩展方式跳线 建立模板明确设计要求和初始状态显示功能部分数据界面第一部分第二部分第三部分调试时发现的问题 参数设置界面第一部分第二部分和第四部分第三部分和第五部分 按键功…...

数据分析:企业数字化转型的金钥匙
引言:数字化浪潮下的数据金矿 在数字化浪潮席卷全球的背景下,有研究表明,只有不到30%的企业能够充分利用手中掌握的数据,这是否让人深思?数据已然成为企业最为宝贵的资产之一。然而,企业是否真正准备好从数…...

网络工程师 (23)OSI模型层次结构
前言 OSI(Open System Interconnect)模型,即开放式系统互联模型,是一个完整的、完善的宏观模型,它将计算机网络体系结构划分为7层。 OSI七层模型 1. 物理层(Physical Layer) 功能:负…...
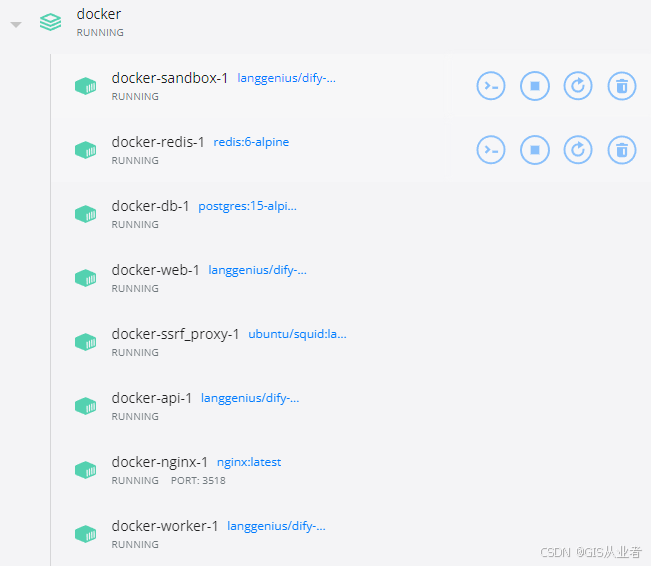
DeepSeek添加知识库
1、下载dify 项目地址:https://github.com/langgenius/dify 2、通过docker安装 端口报错 修改端口 .env文件下所有80端口替换成了其它端口 执行正常了 查看 docker容器 <...

2、k8s的cni网络插件和基本操作命令
kube-prxoy属于节点组件,网络代理,实现服务的自动发现和负载均衡。 k8s的内部网络模式 1、pod内的容器于容器之间的通信。 2、一个节点上的pod之间的通信,docker0网桥直接通信。 3、不同节点上的pod之间的通信: 通过物理网卡的…...
)
Next.js简介:现代 Web 开发的强大框架(ChatGPT-4o回答)
prompt: 你是一位专业的技术博客撰稿人,你将写一篇关于介绍next.js这个开发框架的技术博文,语言是中文,风格专业严谨,用词自然、引人入胜且饶有趣味 在现代 Web 开发的世界中,选择合适的框架可以显著提升开发效率和应用…...

【DeepSeek:国产大模型的崛起与ChatGPT的全面对比】
DeepSeek:国产大模型的崛起与ChatGPT的全面对比 目录 引言DeepSeek的技术架构 2.1 混合专家(MoE)架构2.2 动态路由机制2.3 训练数据与成本 ChatGPT的技术架构 3.1 Transformer架构3.2 训练数据与成本 性能对比 4.1 推理能力4.2 语言处理4.3…...

input 超出maxlength限制后,输入框变红
一、前言 最近收到产品的一个需求:输入框限制了maxlength“11”,需要在输入第12位时,输入框变红;当然,第12位是不能真正输入到输入框中的。 二、实现难点 其实,单纯的要监听 字母和数字以及字符 还是比较容…...

Docker 构建镜像并搭建私人镜像仓库教程
构建镜像教程 步骤 1:安装 Docker #在安装 Docker 之前,建议先更新系统软件包。 sudo yum update -y # 移除旧的Docker版本和Podman、runc软件包及其相关依赖。 yum remove -y docker docker-client docker-client-latest docker-ce-cli docker-commo…...

doris:MySQL Dump
Doris 在 0.15 之后的版本已经支持通过 mysqldump 工具导出数据或者表结构 使用示例 导出 导出 test 数据库中的 table1 表:mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test --tables table1 导出 test 数据库中的 table1 表结构&am…...

OpenBMC:通过qemu-system-arm运行编译好的image
OpenBMC:编译_openbmc meson.build file-CSDN博客 讲述了如何编译生成openbmc的image 完成编译后可以通过qemu-system-arm进行模拟加载,以便在没有BMC硬件的情况下进行调试 1.下载qemu-system-arm 在openbmc的上级目录上执行 wget https://jenkins.op…...

STM32的HAL库开发---通用定时器(TIMER)---定时器脉冲计数
一、脉冲计数实验原理 1、 外部时钟模式1:核心为蓝色部分的时基单元,时基单元的时钟源可以来自四种,分别是内部时钟PCLK、外部时钟模式1,外部时钟模式2、内部定时器触发(级联)。而脉冲计数就是使用外部时钟…...

动态规划LeetCode-121.买卖股票的最佳时机1
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易中获取的最大利润。…...

网安三剑客:DNS、CDN、VPN
DNS(网络地址转换系统)的技术原理与安全应用 1. 网络地址转换系统的基本原理 DNS通过解析用户的访问URL(超链接),将其映射到服务器上存储的信息。具体来说: 解析URL:DNS从URL中提取出 hostna…...

Linux在x86环境下制作ARM镜像包
在x86环境下制作ARM镜像包(如qemu.docker),可以通过QEMU和Docker的结合来实现。以下是详细的步骤: 安装QEMU-user-static QEMU-user-static是一个静态编译的QEMU二进制文件,用于在非目标架构上运行目标架构的二进制文…...

Vue3+codemirror6实现公式(规则)编辑器
实现截图 实现/带实现功能 插入标签 插入公式 提示补全 公式验证 公式计算 需要的依赖 "codemirror/autocomplete": "^6.18.4","codemirror/lang-javascript": "^6.2.2","codemirror/state": "^6.5.2","cod…...

Lua中文语言编程源码-第十一节,其它小改动汉化过程
__tostring 汉化过程 liolib.c metameth[] {"__转换为字符串", f_tostring}, lauxlib.c luaL_callmeta(L, idx, "__转换为字符串") lua.c luaL_callmeta(L, 1, "__转换为字符串") __len 汉化过程 ltm.c luaT_eventname[] ltablib.c c…...

你知道AI时代的我们如何用好AI吗?
如何用AI写文案看起来更像真人写的呢?给AI这个指令:1. “翻译”术语,换成“人话”:把那些抽象的、正确的套话,“翻译”成生活中能摸得着的场景。比如“优化流程”不如说“省下喝咖啡的时间”。多用这种场景感强的表达&…...

互联网产品创新:基于Qwen3-ASR-0.6B的在线教育实时字幕解决方案
互联网产品创新:基于Qwen3-ASR-0.6B的在线教育实时字幕解决方案 1. 引言 想象一下,你正在上一节重要的在线直播课,老师讲得飞快,有些专业术语没听清,或者因为网络波动声音断断续续。又或者,你身处一个嘈杂…...

导师严选!盘点2026年最强的的降AI率网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AI率网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...
)
QT事件过滤器实战:如何用eventFilter拦截鼠标移动事件(附完整代码)
QT事件过滤器实战:如何精准拦截鼠标移动事件 在QT开发中,事件处理机制是GUI编程的核心。当我们需要对特定控件的事件流进行精细化控制时,事件过滤器(eventFilter)提供了一种优雅的解决方案。不同于直接重写事件处理函数,事件过滤器…...

SHA-3:从海绵结构到抗量子密码学的基石
1. SHA-3的诞生背景与核心价值 2004年,密码学界发现SHA-1存在理论漏洞,这直接推动了NIST启动新一代哈希算法竞赛。经过5年激烈角逐,Keccak团队提出的海绵结构方案最终胜出。与传统哈希算法不同,SHA-3不是对SHA-2的简单升级&#x…...

TypeScript——tsconfig.json
tsconfig.json1、使用配置文件1.1、自动搜索配置文件1.2、指定配置文件2、编译选项列表3、编译文件列表3.1、--listFiles编译选项3.2、 默认编译文件列表3.3、files属性3.4、include属性3.5、 exclude属性4、声明文件列表4.1、--typeRoots编译选项4.2、--types编译选项5、继承…...

终极免费方案:3分钟掌握英雄联盟身份伪装完整指南
终极免费方案:3分钟掌握英雄联盟身份伪装完整指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款基于官方LCUAPI开发的英雄联盟个性化展示工具,通过安全合规的方式实现游戏身份伪装、…...

BiliTools:跨平台B站资源管理工具的全方位应用指南
BiliTools:跨平台B站资源管理工具的全方位应用指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliToo…...

Cobalt视频下载工具:创作者必备的素材管理与备份完整指南
Cobalt视频下载工具:创作者必备的素材管理与备份完整指南 【免费下载链接】cobalt save what you love 项目地址: https://gitcode.com/GitHub_Trending/cob/cobalt 在数字内容创作的世界里,素材管理是每个创作者都面临的挑战。Cobalt视频下载工具…...

AI专著生成速达秘籍:高性价比工具剖析,助力快速创作
创新是学术专著所需的核心元素,也是写作的一道高门槛。一部合格的学术专著,不能仅仅是对已有研究成果的机械拼凑,而应当展示贯穿全书的独特见解、理论模型或研究方法。在浩如烟海的学术文献中,识别尚未探索的研究空白并不是一件容…...