【Flink快速入门-1.Flink 简介与环境配置】
Flink 简介与环境配置
实验介绍
在学习一门新的技术之前,我们首先要了解它的历史渊源,也就是说它为什么会出现,它能够解决什么业务痛点。所以本节我们的学习目的是了解 Flink 的背景,并运行第一个 Flink 程序,对它有一个初步的印象。
知识点
- 流处理概述
- Flink 简介
- Flink 批处理 WordCount
- Flink 流处理 WordCount
流处理简介
流处理并不是一个新概念,但是要做好并不是一件容易的事情。提到流处理,我们最先想到的可能是金融交易、信号检测以及地图导航等领域的应用。但是近年来随着信息技术的发展,除了前面提到的三个领域,其它方向对数据时效性的要求也越来越高。随着 Hadoop 生态的崛起,Storm、Spark Streaming、Samza、MillWheel 等一众流处理技术开始走入大众视野,但是我们最熟悉的应该还是 Storm 和 Spark Streaming。
我们知道,“高吞吐”、“低延迟”和”exactly-once“是衡量一个流处理框架的重要指标。 Storm 虽然提供了低延迟的流处理,但是在高吞吐方面的表现并不算佳,可以说基本满足不了日益暴涨的数据量,而且也没办法保证精准一次消费。Spark Streaming 中通过微批次的批处理来模拟流处理,只要将批处理的批次分的足够小,那么从宏观上来看就是流处理,这也是 Spark Streaming 的核心思想。通过微观批处理的方式,Spark Streaming 也实现了高吞吐和 exactly-once 语义,时效性也有了大幅提升,在很长一段时间里占据流处理榜首。但是受限于其实现方式,依然存在几秒的延迟,对于那些实时性要求较高的领域来说依然不够完美。
在这样的背景下,Flink 应运而生,接下来我们正式进入 Flink 的学习。
Flink 简介
Apache Flink 是为分布式、高性能、随时可用以及准确 的流处理应用程序打造的开源流处理框架,用于对无界和有界数据流进行有状态计算。Flink 最早起源于在 2010 ~ 2014 年,由 3 所地处柏林的大学和欧洲的一些其它大学共同进行研究的名为 Stratosphere 的项目。2014 年 4 月 Stratosphere 将其捐赠给 Apache 软件基 金会, 初始成员是 Stratosphere 系统的核心开发人员,2014 年 12 月,Flink 一跃成为 Apache 软件基金会的顶级项目。在 2015 年,阿里也加入到了 Flink 的开发工作中,并贡献了至少 150 万行代码。
Flink 一词在德语中有着“灵巧”、“快速”的意思,它的 logo 原型也是柏林常见的一种松鼠,以身材娇小、灵活著称,为该项目取这样的名字和选定这样的 logo 也正好符合 Flink 的特点和愿景。

注意,虽然我们说 Flink 是一个流处理框架,但是它同样可以进行批处理。因为在 Flink 的世界观里,批处理是流处理的一种特殊形式,这和 Spark 不同,在 Spark 中,流处理是通过大批量的微批处理实现的。
运行第一个 Flink 程序
接下来我们运行第一个 Flink 程序,感受一下它的魅力,从而对它有一个初步的印象。
搭建开发环境
本课程使用的是本地环境。后续实验不再提示。
首先我们需要在环境中搭建 Flink 运行环境,总共可以分为下面这几步:
- 安装 jdk 并配置环境变量 【jdk 1.8】
- 安装 scala 并配置环境变量 【Scala 2.11.12】
- 安装 maven 并修改中心仓库为阿里云地址
- 安装 IDEA 开发工具 【IDEA 2022.2.1或更新版】
我们的实验环境已经为大家安装了 jdk、scala、maven 和 IDEA,只需要在 IDEA 里配置使用即可。
双击桌面的 IDEA 程序,启动之后,点击 File -> New -> Project 创建一个新的 Maven 工程 FlinkLearning:
【或者New Project->Maven Archetype】

创建好之后点击左上角 File > Settings 中,将 Maven 的配置文件修改为 D:\programs\apahe-maven-3.6.3\conf\settings.xml,配置之后的 Maven 中心仓库为阿里云,加载依赖会快很多:

项目中点击File-》Project Structure -> Libraries-》加号-》添加Scala SDK-》选择所需要的scala版本-》ok进行下载

在工程 src/main 目录中创建 scala 文件夹,然后右键,选择 Mark Directory as,并将其标记为 Sources Root。

在 scala 目录里创建 com.vlab.wc 包,并分别创建 BatchWordCount 和 StreamWordCount 两个 Scala Object,分别代表 Flink 批处理和 Flink 流处理。

至此,我们的准备工作已经完成,接下来正式进入编码阶段。
Flink 批处理 WordCount
修改 pom.xml 文件中的代码为如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>pblh123.lh</groupId><artifactId>FlinkLearning</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><!-- 配置国内 Maven 依赖库的镜像源镜--><repositories><repository><id>aliyun</id><url>https://maven.aliyun.com/repository/public</url></repository></repositories>
<!--配置插件的镜像源--><pluginRepositories><pluginRepository><id>aliyun</id><url>https://maven.aliyun.com/repository/public</url></pluginRepository></pluginRepositories><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>1.17.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>1.17.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.2</version></dependency></dependencies><build><plugins><!-- 该插件用于将 Scala 代码编译成 class 文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><archive><manifest><mainClass></mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>
修改完成后注意点击加载图标重新 Load。

BatchWordCount.scala 中的代码如下:
package com.vlab.wcimport org.apache.flink.api.scala._/*** @projectName FlinkLearning* @package com.vlab.wc* @className com.vlab.wc.BatchWordCount* @description Flink Batch Word Count Example* @author pblh123* @date 2025/2/7 14:41* @version 1.17.2*/
object BatchWordCount {def main(args: Array[String]): Unit = {// 判断输入参数数量是否正确if (args.length != 1) {System.err.println("Usage: BatchWordCount <input path>")System.exit(5)}// 获取输入路径val inputPath = args(0)// 创建执行环境val env = ExecutionEnvironment.getExecutionEnvironment// 读取输入数据val inputDS: DataSet[String] = env.readTextFile(inputPath)// 计算词频val wordCountDS: DataSet[(String, Int)] = inputDS.flatMap(_.split("\\s+")) // 扁平化,并且处理多个空格作为分隔符.map((_, 1)) // 转换为 (word, 1).groupBy(0) // 按第一个字段(word)进行分组.sum(1) // 对第二个字段(计数)求和// 打印输出wordCountDS.print()}
}
在 datas/words.txt 路径下创建 words.txt 文件并在其中加入如下内容(注意每个单词之间使用空格分隔):

hello world
hello flink
hello spark
hello java
右键选中 BatchWordCount.scala,点击 Run 运行,将会看到如下输出:
如果出现一些其他的报错和警告可以忽略。
(java,1)
(world,1)
(flink,1)
(hello,4)
(spark,1)
Flink 流处理 WordCount
在 StreamWordCount.scala 中加入如下代码:
package com.vlab.wcimport org.apache.flink.streaming.api.scala._/*** @projectName FlinkLearning * @package com.vlab.wc * @className com.vlab.wc.StreamWordCount * @description ${description} * @author pblh123* @date 2025/2/7 14:41* @version 1.0**/object StreamWordCount {def main(args: Array[String]): Unit = {// 创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 监控Socket数据val textDstream: DataStream[String] = env.socketTextStream("localhost", 9999)// 导入隐式转换import org.apache.flink.api.scala._// 计算逻辑val dataStream: DataStream[(String, Int)] = textDstream.flatMap(_.split(" ")).filter(_.nonEmpty).map((_, 1)).keyBy(0).sum(1)// 设置并行度dataStream.print().setParallelism(1)// 执行env.execute("Socket stream word count")}
}
打开终端,并输入 nc -l -p 9999,然后输入以下内容:
hello world
hello flink
hello spark
hello java
运行 StreamWordCount.scala 将会看到如下输出:
(hello,1)
(flink,1)
(hello,2)
(spark,1)
(java,1)
(hello,3)
...
至此,我们的第一个 Flink 实验就已经完成了。
实验总结
本节实验中,我们介绍了 Flink 出现的背景,并和 Storm、Spark Streaming 做了简单对比,然后在实验环境下安装了 idea 开发工具并运行了第一个 Flink 程序。至此,相信大家已经对 Flink 已经有了一个初步的认识。
相关文章:
【Flink快速入门-1.Flink 简介与环境配置】
Flink 简介与环境配置 实验介绍 在学习一门新的技术之前,我们首先要了解它的历史渊源,也就是说它为什么会出现,它能够解决什么业务痛点。所以本节我们的学习目的是了解 Flink 的背景,并运行第一个 Flink 程序,对它有…...

硬盘修复后,文件隐身之谜
在数字时代,硬盘作为数据存储的重要载体,承载着无数珍贵的信息与回忆。然而,当硬盘遭遇故障并经过修复后,有时我们会遇到这样一个棘手问题:硬盘修复后,文件却神秘地“隐身”,无法正常显示。这一…...

如何处理网络连接错误导致的fetch失败?
处理由于网络连接错误导致的 fetch 失败通常涉及捕获网络错误并提供适当的用户反馈。以下是如何在 Vue 3 中实现这一点的步骤和示例。 一、更新 useFetch 函数 在 useFetch 函数中,需要捕获网络错误,并设置相应的错误信息。网络错误通常会抛出一个 TypeError,可以根据这个…...

Qt之设置QToolBar上的按钮样式
通常给QAction设置icon后,菜单栏的菜单项和工具栏(QToolBar)上对应的按钮会同时显示该icon。工具栏还可以使用setToolButtonStyle函数设置按钮样式,其参数为枚举值: enum ToolButtonStyle {ToolButtonIconOnly,ToolButtonTextOnly,ToolButtonTextBesideIcon,ToolButtonTe…...
)
责任链模式(Chain Responsibility)
一、定义:属于行为型设计模式,包含传递的数据、创建处理的抽象和实现、创建链条、将数据传递给顶端节点; 二、UML图 三、实现 1、需要传递处理的数据类 import java.util.Date;/*** 需要处理的数据信息*/ public class RequestData {priva…...

docker安装 mongodb
1、拉取镜像 docker run -dit --name mongo \ -p 17017:27017 \ -e MONGO_INITDB_ROOT_USERNAMEadmin \ -e MONGO_INITDB_ROOT_PASSWORD2018 \ --restartalways \ mongo2、进入容器 docker exec -it mongo bash 3、进入mongo ./bin/mongosh -u admin -p 2018 --authenticat…...

RabbitMQ 从入门到精通:从工作模式到集群部署实战(五)
#作者:闫乾苓 系列前几篇: 《RabbitMQ 从入门到精通:从工作模式到集群部署实战(一)》:link 《RabbitMQ 从入门到精通:从工作模式到集群部署实战(二)》: lin…...
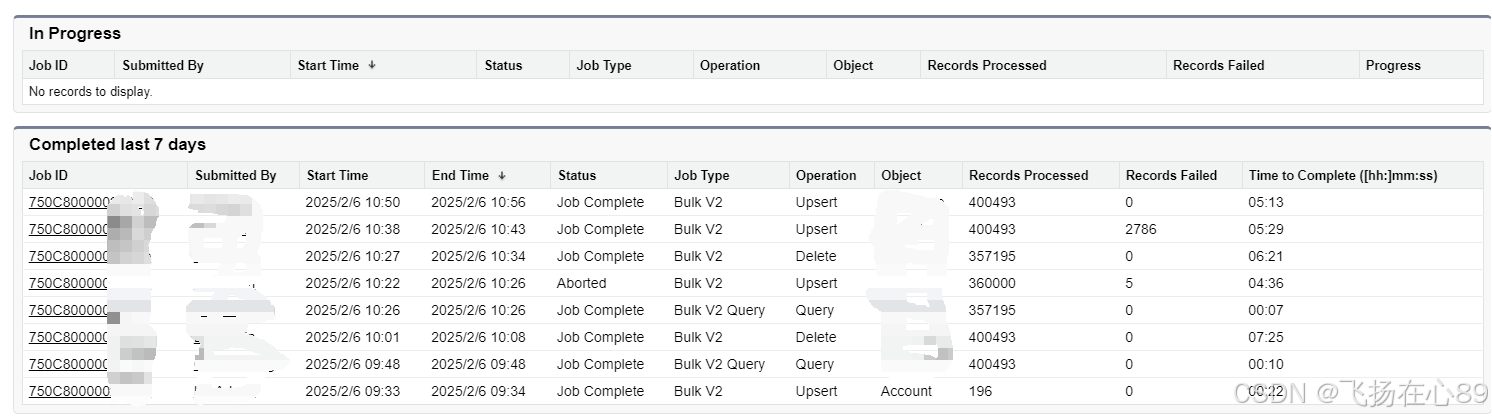
salesforce SF CLI 数据运维经验分享
SF CLI data默认使用bulk api v2, 数据操作效率有了极大的提高。 Bulk api v2的优点: 执行结果可以很直观的从Bulk Data Load Jobs中看到。相较于bulk api v1,只能看到job执行in progress,或者closed的状态,有了很大的改善。执行…...

5.2Internet及其作用
5.2.1Internet概述 Internet称为互联网,又称英特网,始于1969年的美国ARPANET(阿帕网),是全球性的网络。 互连网指的是两个或多个不同类型的网络通过路由器等网络设备连接起来,形成一个更大的网络结构。互连…...

【蓝桥杯—单片机】第十一届省赛真题代码题解题笔记 | 省赛 | 真题 | 代码题 | 刷题 | 笔记
第十一届省赛真题代码部分 前言赛题代码思路笔记竞赛板配置内部振荡器频率设定键盘工作模式跳线扩展方式跳线 建立模板明确设计要求和初始状态显示功能部分数据界面第一部分第二部分第三部分调试时发现的问题 参数设置界面第一部分第二部分和第四部分第三部分和第五部分 按键功…...

数据分析:企业数字化转型的金钥匙
引言:数字化浪潮下的数据金矿 在数字化浪潮席卷全球的背景下,有研究表明,只有不到30%的企业能够充分利用手中掌握的数据,这是否让人深思?数据已然成为企业最为宝贵的资产之一。然而,企业是否真正准备好从数…...

网络工程师 (23)OSI模型层次结构
前言 OSI(Open System Interconnect)模型,即开放式系统互联模型,是一个完整的、完善的宏观模型,它将计算机网络体系结构划分为7层。 OSI七层模型 1. 物理层(Physical Layer) 功能:负…...
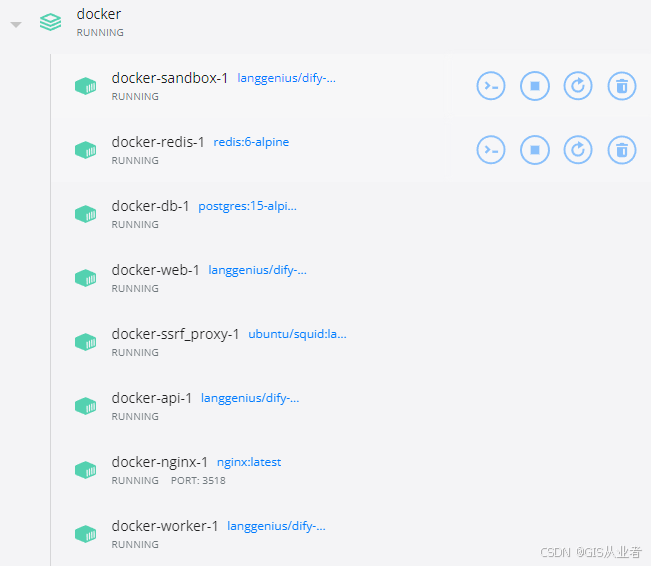
DeepSeek添加知识库
1、下载dify 项目地址:https://github.com/langgenius/dify 2、通过docker安装 端口报错 修改端口 .env文件下所有80端口替换成了其它端口 执行正常了 查看 docker容器 <...

2、k8s的cni网络插件和基本操作命令
kube-prxoy属于节点组件,网络代理,实现服务的自动发现和负载均衡。 k8s的内部网络模式 1、pod内的容器于容器之间的通信。 2、一个节点上的pod之间的通信,docker0网桥直接通信。 3、不同节点上的pod之间的通信: 通过物理网卡的…...
)
Next.js简介:现代 Web 开发的强大框架(ChatGPT-4o回答)
prompt: 你是一位专业的技术博客撰稿人,你将写一篇关于介绍next.js这个开发框架的技术博文,语言是中文,风格专业严谨,用词自然、引人入胜且饶有趣味 在现代 Web 开发的世界中,选择合适的框架可以显著提升开发效率和应用…...

【DeepSeek:国产大模型的崛起与ChatGPT的全面对比】
DeepSeek:国产大模型的崛起与ChatGPT的全面对比 目录 引言DeepSeek的技术架构 2.1 混合专家(MoE)架构2.2 动态路由机制2.3 训练数据与成本 ChatGPT的技术架构 3.1 Transformer架构3.2 训练数据与成本 性能对比 4.1 推理能力4.2 语言处理4.3…...

input 超出maxlength限制后,输入框变红
一、前言 最近收到产品的一个需求:输入框限制了maxlength“11”,需要在输入第12位时,输入框变红;当然,第12位是不能真正输入到输入框中的。 二、实现难点 其实,单纯的要监听 字母和数字以及字符 还是比较容…...

Docker 构建镜像并搭建私人镜像仓库教程
构建镜像教程 步骤 1:安装 Docker #在安装 Docker 之前,建议先更新系统软件包。 sudo yum update -y # 移除旧的Docker版本和Podman、runc软件包及其相关依赖。 yum remove -y docker docker-client docker-client-latest docker-ce-cli docker-commo…...

doris:MySQL Dump
Doris 在 0.15 之后的版本已经支持通过 mysqldump 工具导出数据或者表结构 使用示例 导出 导出 test 数据库中的 table1 表:mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test --tables table1 导出 test 数据库中的 table1 表结构&am…...

OpenBMC:通过qemu-system-arm运行编译好的image
OpenBMC:编译_openbmc meson.build file-CSDN博客 讲述了如何编译生成openbmc的image 完成编译后可以通过qemu-system-arm进行模拟加载,以便在没有BMC硬件的情况下进行调试 1.下载qemu-system-arm 在openbmc的上级目录上执行 wget https://jenkins.op…...

从压测到瓶颈定位:一次完整的性能分析思路
很多人刚接触压测时,会产生一种错觉:“压测不就是看 QPS 吗?”但压测的本质,从来不是“跑数字”,而是:找到系统的性能极限,以及限制系统性能的真正瓶颈。 本文会围绕下面几个核心问题࿰…...

4.【Python】Python3 注释
第一步:分析与整理 注释1. 注释的作用 不影响程序执行,只提高可读性。帮助理解代码逻辑,方便团队协作。2. 单行注释 以 # 开头,直到行末的所有内容均为注释。 # 这是一个注释 print("Hello, World!") # 这也是注释3. 多…...

LZ4与ZSTD压缩算法在LLM内存优化中的硬件实现对比
1. 项目概述:压缩算法在LLM内存优化中的关键作用 在大型语言模型(LLM)推理过程中,内存带宽和容量一直是制约性能的关键瓶颈。特别是随着模型规模的不断扩大,KV缓存(Key-Value Cache)所占用的内存…...

开源创富的三大支柱:技术、流量与商业化的完美结合
开源创富的三大支柱:技术、流量与商业化的完美结合 关键词:开源项目、技术壁垒、流量运营、商业化闭环、社区生态、价值变现、开源经济学 摘要:很多人对“开源”的理解停留在“免费送代码”,但实际上,开源是一套用技术…...

从棋盘格到精准感知:ROS camera_calibration实战单目与双目相机标定
1. 为什么相机标定是机器人视觉的"体检报告"? 想象一下你新配了一副眼镜,但镜片度数不准——看东西要么变形要么模糊。相机标定就是给机器人的"眼睛"做验光,确保它看到的图像能真实反映物理世界。我在做视觉SLAM项目时&a…...

BilibiliDown完整使用教程:三步搞定B站视频批量下载
BilibiliDown完整使用教程:三步搞定B站视频批量下载 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...

避开这些坑!STC8H8K64U IAP升级中FLASH分区与Keil定位的保姆级教程
STC8H8K64U IAP升级实战:FLASH分区设计与Keil定位全解析 第一次接触STC8H8K64U的IAP功能时,我花了整整三天时间才搞明白为什么程序总是莫名其妙地崩溃。直到发现是FLASH分区地址计算错误导致用户程序覆盖了ISP引导区,才恍然大悟。本文将分享从…...
利用CTranslate2与INT8量化,实现Whisper语音识别7倍加速
1. 项目概述:当Whisper遇上CTranslate2,语音转文字的“涡轮增压”如果你尝试过OpenAI的Whisper模型来做语音识别,大概率会被它的准确性所折服,但同时也可能被其缓慢的推理速度所困扰。尤其是在处理长音频文件或需要批量处理时&…...

【NotebookLM海洋学研究辅助实战指南】:20年海洋数据科学家亲授AI笔记法,3步构建专属科研知识图谱
更多请点击: https://intelliparadigm.com 第一章:NotebookLM海洋学研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度语义理解与推理的 AI 工具,特别适用于海洋学这类多源异构、长周期、高专业性的科研场景。研究人员可将 PDF…...

2026年南京本地实测整理,值得入手的高性价比全屋定制品牌推荐
讲真,南京准备装房子、换柜子的姊妹们、老少爷们,谁没为全屋定制头大过?刚收了江北核心区的新房,还是鼓楼老破小准备翻新,跑了三五家门店就会发现:水太深了!低价套餐勾你进去,签约后…...