mysql自连接 处理层次结构数据
MySQL 的自连接(Self Join)是一种特殊的连接方式,它允许一个表与自身进行连接。自连接通常用于处理具有层次结构或递归关系的数据,或者当同一张表中的数据需要相互关联时。以下是几种常见的场景,说明何时应该使用自连接。
mysql自连接 处理层次结构数据
- 1. 处理层次结构数据
- 示例:员工-经理关系
- 2. 查找相邻时间点的数据
- 示例:比较相邻月份的销售数据
- 3. 查找重复或相似的记录
- 示例:查找具有相同电话号码的用户
- 4. 查找连续的记录
- 示例:查找连续登录的用户
- 在指定日期范围内查找连续7天登录的用户
- 方案 1:使用窗口函数(推荐)
- SQL 查询
- 解释
- 示例数据
- 方案 2:使用递归 CTE
- SQL 查询
- 解释
- 总结
- login_date - INTERVAL rn DAY详解
- 1. 背景:识别连续日期
- 2. 窗口函数 `ROW_NUMBER()`
- 3. 关键操作:`login_date - INTERVAL rn DAY`
- 为什么需要 `login_date - INTERVAL rn DAY`?
- 示例:
- 非连续日期的情况:
- 4. 分组和计数
- 5. 总结
- 5. 查找递归关系
- 示例:查找所有子类别
- 6. 查找最近的历史记录
- 示例:查找产品的最新价格
- 表结构设计
- 表名:`product_prices`
- SQL 创建表语句
- 查找每个产品的最新价格
- 方法 1:使用自连接
- 方法 2:使用窗口函数(推荐)
- 方法 3:使用子查询
- 总结
- 总结
1. 处理层次结构数据
当表中存储了具有父子关系或层级结构的数据时,自连接可以用来查询这些层次关系。例如,员工表中可能包含员工及其直接上级的信息,这时可以使用自连接来查询某个员工的所有下属,或者查找某位经理的所有直接下属。
示例:员工-经理关系
假设有一个 employees 表,其中每个员工都有一个 manager_id 字段,表示该员工的直接上级(经理)。你可以使用自连接来查询某个员工的所有下属。
SELECT e1.employee_id, e1.name AS employee_name, e2.name AS manager_name
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.employee_id
WHERE e2.employee_id = ?; -- 替换为你要查询的经理ID
- 解释:
e1表示员工表中的员工记录。e2表示员工表中的经理记录。LEFT JOIN用于将每个员工与其对应的经理关联起来。WHERE e2.employee_id = ?用于筛选出特定经理的所有下属。
2. 查找相邻时间点的数据
在某些情况下,你可能需要比较同一张表中不同时间点的数据。例如,你想比较某个月份的销售数据与前一个月的销售数据,或者计算某个指标的变化率。这时可以使用自连接来将当前月份的数据与前一个月的数据进行对比。
示例:比较相邻月份的销售数据
假设有一个 sales 表,记录了每个月的销售数据。你可以使用自连接来比较相邻两个月的销售情况。
WITH CurrentMonth AS (SELECT * FROM sales WHERE DATE_FORMAT(sale_date, '%Y-%m') = '2024-10' -- 当前月份
),
PreviousMonth AS (SELECT * FROM sales WHERE DATE_FORMAT(sale_date, '%Y-%m') = '2024-09' -- 前一个月
)
SELECT c.month AS current_month,c.sales_amount AS current_sales,p.sales_amount AS previous_sales,(c.sales_amount - p.sales_amount) / p.sales_amount * 100 AS sales_change_percent
FROM CurrentMonth c
JOIN PreviousMonth p ON c.product_id = p.product_id;
- 解释:
CurrentMonth和PreviousMonth是两个 CTE(Common Table Expressions),分别获取当前月份和前一个月的销售数据。JOIN用于将当前月份和前一个月的数据按产品 ID 进行关联。- 最后,计算销售增长百分比。
3. 查找重复或相似的记录
当你需要查找同一张表中存在重复或相似的记录时,自连接可以帮助你将每条记录与其他记录进行比较。例如,查找具有相同电话号码的不同用户,或者查找具有相同地址的多个客户。
示例:查找具有相同电话号码的用户
假设有一个 users 表,记录了用户的姓名和电话号码。你可以使用自连接来查找具有相同电话号码的不同用户。
SELECT u1.user_id, u1.name AS user1_name, u1.phone_number,u2.user_id, u2.name AS user2_name
FROM users u1
JOIN users u2 ON u1.phone_number = u2.phone_number
WHERE u1.user_id < u2.user_id; -- 避免重复配对
- 解释:
u1和u2是同一个users表的两个别名。JOIN用于将具有相同电话号码的用户进行关联。WHERE u1.user_id < u2.user_id用于避免重复配对(即避免(u1, u2)和(u2, u1)同时出现)。
4. 查找连续的记录
有时你需要查找连续的记录,例如查找连续登录的用户,或者查找连续几天内有活动的用户。自连接可以帮助你将当前记录与前后记录进行关联,从而判断是否存在连续性。
示例:查找连续登录的用户
假设有一个 user_logins 表,记录了用户的登录时间和用户 ID。你可以使用自连接来查找连续两天都登录的用户。
SELECT DISTINCT l1.user_id
FROM user_logins l1
JOIN user_logins l2 ON l1.user_id = l2.user_idAND l2.login_date = DATE_ADD(l1.login_date, INTERVAL 1 DAY);
- 解释:
l1和l2是同一个user_logins表的两个别名。JOIN用于将同一个用户在相邻两天的登录记录进行关联。DATE_ADD(l1.login_date, INTERVAL 1 DAY)用于确保l2的登录日期是l1登录日期的下一天。DISTINCT用于去重,避免同一个用户多次出现在结果中。
在指定日期范围内查找连续7天登录的用户
要在指定日期范围内查找连续 7 天登录的用户,我们可以在查询中添加日期范围的过滤条件。具体来说,我们可以通过以下步骤来实现:
- 限制查询的日期范围:在
user_logins表中只选择指定日期范围内的登录记录。 - 识别连续 7 天的登录:使用窗口函数或递归 CTE 来识别每个用户的连续登录天数。
- 确保连续 7 天在指定日期范围内:确保用户的连续 7 天登录完全包含在指定的日期范围内。
方案 1:使用窗口函数(推荐)
有关窗口函数的,可以参考我的另一篇文章
mysql窗口函数(Window Functions)详解
我们将基于你之前的窗口函数方法,并添加日期范围的过滤条件。假设你要查找在 2023-01-01 到 2023-01-31 之间连续 7 天登录的用户。
SQL 查询
WITH login_gaps AS (-- 1. 选择指定日期范围内的登录记录,并为每个用户的登录记录分配行号SELECT user_id, login_date,ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) AS rn,login_date - INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY AS grpFROM user_loginsWHERE login_date BETWEEN '2023-01-01' AND '2023-01-31'
),
consecutive_logins AS (-- 2. 按用户和分组进行分组,计算每个分组中的连续登录天数SELECT user_id, MIN(login_date) AS start_date, -- 连续登录的起始日期COUNT(*) AS consecutive_daysFROM login_gapsGROUP BY user_id, grpHAVING COUNT(*) >= 7
),
valid_consecutive_logins AS (-- 3. 确保连续 7 天完全包含在指定日期范围内SELECT *FROM consecutive_loginsWHERE start_date + INTERVAL 6 DAY <= '2023-01-31'
)
SELECT DISTINCT user_id
FROM valid_consecutive_logins;
解释
-
login_gapsCTE:- 我们首先从
user_logins表中选择指定日期范围内的登录记录(WHERE login_date BETWEEN '2023-01-01' AND '2023-01-31')。 - 然后,我们为每个用户的登录记录分配行号
rn,并使用login_date - INTERVAL rn DAY创建grp列,标识连续的登录日期。
- 我们首先从
-
consecutive_loginsCTE:- 我们按
user_id和grp分组,并计算每个分组中的连续登录天数。 - 使用
HAVING COUNT(*) >= 7筛选出连续登录天数大于等于 7 的用户。 - 同时,我们还计算了每个连续登录序列的起始日期
start_date,即该序列中最早的登录日期。
- 我们按
-
valid_consecutive_loginsCTE:- 我们进一步筛选出那些连续 7 天完全包含在指定日期范围内的用户。具体来说,确保
start_date + INTERVAL 6 DAY(即连续 7 天的最后一天)不超过指定的结束日期2023-01-31。
- 我们进一步筛选出那些连续 7 天完全包含在指定日期范围内的用户。具体来说,确保
-
最终查询:
- 最后,我们选择符合条件的
user_id,即在指定日期范围内连续 7 天登录的用户。
- 最后,我们选择符合条件的
示例数据
假设我们有以下用户登录记录:
user_id | login_date |
|---|---|
| 1 | 2023-01-01 |
| 1 | 2023-01-02 |
| 1 | 2023-01-03 |
| 1 | 2023-01-04 |
| 1 | 2023-01-05 |
| 1 | 2023-01-06 |
| 1 | 2023-01-07 |
| 2 | 2023-01-25 |
| 2 | 2023-01-26 |
| 2 | 2023-01-27 |
| 2 | 2023-01-28 |
| 2 | 2023-01-29 |
| 2 | 2023-01-30 |
| 2 | 2023-01-31 |
| 3 | 2023-01-01 |
| 3 | 2023-01-02 |
| 3 | 2023-01-03 |
| 3 | 2023-01-04 |
| 3 | 2023-01-05 |
| 3 | 2023-01-06 |
执行上述查询后,结果将返回用户 1 和用户 2,因为他们在指定日期范围内(2023-01-01 到 2023-01-31)都有连续 7 天的登录记录。
方案 2:使用递归 CTE
如果你更喜欢使用递归 CTE,也可以通过类似的方式实现。我们只需要在递归部分添加日期范围的过滤条件,并确保连续 7 天完全包含在指定的日期范围内。
SQL 查询
WITH RECURSIVE login_sequence AS (-- 基础情况:找到每个用户在指定日期范围内的第一次登录SELECT user_id, login_date, 1 AS day_countFROM user_loginsWHERE login_date BETWEEN '2023-01-01' AND '2023-01-31'AND (user_id, login_date) IN (SELECT user_id, MIN(login_date)FROM user_loginsWHERE login_date BETWEEN '2023-01-01' AND '2023-01-31'GROUP BY user_id)UNION ALL-- 递归部分:查找连续登录的下一天SELECT l.user_id, l.login_date, ls.day_count + 1 AS day_countFROM user_logins lJOIN login_sequence ls ON l.user_id = ls.user_idAND l.login_date = DATE_ADD(ls.login_date, INTERVAL 1 DAY)WHERE l.login_date BETWEEN '2023-01-01' AND '2023-01-31'
)
SELECT DISTINCT user_id
FROM login_sequence
WHERE day_count >= 7
AND login_date + INTERVAL 6 DAY <= '2023-01-31';
解释
-
基础情况:
- 我们从每个用户在指定日期范围内的第一次登录开始,选择每个用户的最早登录日期,并将其
day_count设为 1。
- 我们从每个用户在指定日期范围内的第一次登录开始,选择每个用户的最早登录日期,并将其
-
递归部分:
- 对于每个用户的每次登录,我们检查是否存在下一天的登录记录。如果存在,则将
day_count加 1,并继续递归。 - 我们还添加了
WHERE l.login_date BETWEEN '2023-01-01' AND '2023-01-31'来确保递归过程中只考虑指定日期范围内的登录记录。
- 对于每个用户的每次登录,我们检查是否存在下一天的登录记录。如果存在,则将
-
最终查询:
- 最后,我们选择
day_count大于等于 7 的用户,并确保连续 7 天的最后一天不超过指定的结束日期2023-01-31。
- 最后,我们选择
总结
- 窗口函数:适用于 MySQL 8.0 及以上版本,提供了一种简洁且高效的解决方案。通过窗口函数
ROW_NUMBER()和分组,可以轻松识别连续的登录天数,并确保这些天数完全包含在指定的日期范围内。 - 递归 CTE:适用于需要逐步构建连续性的情况,尤其适合处理复杂的连续性问题。你可以通过递归逐步查找每个用户的连续登录记录,并确保它们在指定的日期范围内。
根据你的 MySQL 版本和具体需求,选择合适的方法来查找在指定日期范围内连续 7 天登录的用户。如果你使用的是 MySQL 8.0 或更高版本,推荐使用窗口函数,因为它不仅代码更简洁,而且性能也更好。
login_date - INTERVAL rn DAY详解
login_date - INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY AS grp 是什么意思,为什么需要这么写?
你提到的这行代码 login_date - INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY AS grp 是窗口函数查询中非常巧妙的一部分,用于识别连续的日期序列。让我们详细解释一下它的含义和作用。
1. 背景:识别连续日期
假设我们有一个 user_logins 表,记录了用户的登录日期。我们想要查找每个用户是否有连续 7 天登录的情况。为了做到这一点,我们需要一种方法来识别哪些日期是连续的。
2. 窗口函数 ROW_NUMBER()
ROW_NUMBER() 是一个窗口函数,它为每一行分配一个唯一的行号,行号的分配基于你指定的排序规则。在我们的例子中,我们按 user_id 分区(即每个用户作为一个独立的组),并按 login_date 排序,这样可以为每个用户的每次登录分配一个递增的行号。
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) AS rn
PARTITION BY user_id:将数据按user_id分区,确保每个用户的行号是独立计算的。ORDER BY login_date:按login_date排序,确保行号按照登录日期的顺序递增。
例如,对于用户 1 的登录记录:
user_id | login_date | rn |
|---|---|---|
| 1 | 2023-01-01 | 1 |
| 1 | 2023-01-02 | 2 |
| 1 | 2023-01-03 | 3 |
| 1 | 2023-01-04 | 4 |
| 1 | 2023-01-05 | 5 |
| 1 | 2023-01-06 | 6 |
| 1 | 2023-01-07 | 7 |
3. 关键操作:login_date - INTERVAL rn DAY
现在,我们有了每个用户的行号 rn,接下来的关键操作是通过 login_date - INTERVAL rn DAY 来创建一个新的列 grp,这个列用于标识连续的日期。
为什么需要 login_date - INTERVAL rn DAY?
login_date:表示用户的实际登录日期。INTERVAL rn DAY:表示从login_date中减去rn天。rn是行号,随着每次登录递增。
通过减去行号 rn,我们可以将连续的日期转换为相同的值。具体来说:
- 如果用户的登录日期是连续的,那么
login_date - INTERVAL rn DAY的结果将是相同的日期。 - 如果用户的登录日期不连续,那么
login_date - INTERVAL rn DAY的结果将不同。
示例:
假设用户 1 的登录记录如下:
user_id | login_date | rn | login_date - INTERVAL rn DAY |
|---|---|---|---|
| 1 | 2023-01-01 | 1 | 2023-01-01 - 1 = 2022-12-31 |
| 1 | 2023-01-02 | 2 | 2023-01-02 - 2 = 2022-12-31 |
| 1 | 2023-01-03 | 3 | 2023-01-03 - 3 = 2022-12-31 |
| 1 | 2023-01-04 | 4 | 2023-01-04 - 4 = 2022-12-31 |
| 1 | 2023-01-05 | 5 | 2023-01-05 - 5 = 2022-12-31 |
| 1 | 2023-01-06 | 6 | 2023-01-06 - 6 = 2022-12-31 |
| 1 | 2023-01-07 | 7 | 2023-01-07 - 7 = 2022-12-31 |
可以看到,所有连续的登录日期在 login_date - INTERVAL rn DAY 列中的值都是相同的(2022-12-31)。这意味着这些登录记录是连续的。
非连续日期的情况:
假设用户 2 的登录记录如下:
user_id | login_date | rn | login_date - INTERVAL rn DAY |
|---|---|---|---|
| 2 | 2023-01-01 | 1 | 2023-01-01 - 1 = 2022-12-31 |
| 2 | 2023-01-02 | 2 | 2023-01-02 - 2 = 2022-12-31 |
| 2 | 2023-01-03 | 3 | 2023-01-03 - 3 = 2022-12-31 |
| 2 | 2023-01-05 | 4 | 2023-01-05 - 4 = 2023-01-01 |
| 2 | 2023-01-06 | 5 | 2023-01-06 - 5 = 2023-01-01 |
| 2 | 2023-01-07 | 6 | 2023-01-07 - 6 = 2023-01-01 |
在这个例子中,用户 2 在 2023-01-04 没有登录,因此 login_date - INTERVAL rn DAY 的结果不再是连续的。前 3 天的值是 2022-12-31,而后面的 3 天的值是 2023-01-01。这表明用户的登录记录在这两天之间出现了中断。
4. 分组和计数
通过 login_date - INTERVAL rn DAY 创建的 grp 列,我们可以将连续的登录记录分组。然后,我们可以对每个分组进行计数,找出连续登录天数大于等于 7 的用户。
WITH login_gaps AS (SELECT user_id, login_date,ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) AS rn,login_date - INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY AS grpFROM user_logins
),
consecutive_logins AS (SELECT user_id, COUNT(*) AS consecutive_daysFROM login_gapsGROUP BY user_id, grpHAVING COUNT(*) >= 7
)
SELECT DISTINCT user_id
FROM consecutive_logins;
login_gapsCTE:为每个用户的登录记录分配行号rn,并通过login_date - INTERVAL rn DAY创建grp列,标识连续的登录日期。consecutive_loginsCTE:按user_id和grp分组,并计算每个分组中的连续登录天数。使用HAVING COUNT(*) >= 7筛选出连续登录天数大于等于 7 的用户。
5. 总结
login_date - INTERVAL rn DAY:通过将login_date减去行号rn,我们可以将连续的日期转换为相同的值。如果日期是连续的,grp列的值将是相同的;如果日期不连续,grp列的值将不同。- 分组和计数:通过
grp列进行分组,我们可以轻松识别出每个用户的连续登录天数,并筛选出连续登录 7 天或更长时间的用户。
这种方法不仅简洁,而且非常高效,特别适用于处理大量数据时的连续性问题。
5. 查找递归关系
自连接还可以用于处理递归关系,例如组织结构图、分类树等。虽然 MySQL 8.0 引入了递归公用表表达式(CTE),但在某些情况下,自连接仍然是处理递归关系的有效方法。
示例:查找所有子类别
假设有一个 categories 表,记录了类别的 ID 和父类别 ID。你可以使用自连接来查找某个类别的所有子类别。
WITH RECURSIVE CategoryHierarchy AS (SELECT id, parent_id, nameFROM categoriesWHERE id = ? -- 替换为你要查询的类别IDUNION ALLSELECT c.id, c.parent_id, c.nameFROM categories cJOIN CategoryHierarchy ch ON c.parent_id = ch.id
)
SELECT * FROM CategoryHierarchy;
- 解释:
WITH RECURSIVE用于定义递归查询。CategoryHierarchy是递归 CTE,首先选择指定类别的信息,然后通过自连接递归地查找其所有子类别。JOIN CategoryHierarchy ch ON c.parent_id = ch.id用于将子类别与父类别关联起来。
6. 查找最近的历史记录
有时你需要查找某个实体的最近历史记录,例如查找某个产品的最新价格变化,或者查找某个用户的最近一次登录。自连接可以帮助你将当前记录与历史记录进行关联,并找到最新的那一条。
示例:查找产品的最新价格
假设有一个 product_prices 表,记录了产品的价格变化历史。你可以使用自连接来查找每个产品的最新价格。
SELECT p1.product_id, p1.price, p1.change_date
FROM product_prices p1
LEFT JOIN product_prices p2 ON p1.product_id = p2.product_idAND p1.change_date < p2.change_date
WHERE p2.product_id IS NULL;
- 解释:
p1和p2是同一个product_prices表的两个别名。LEFT JOIN用于将每个价格记录与后续的价格记录进行关联。WHERE p2.product_id IS NULL用于筛选出没有后续价格记录的记录,即最新的价格记录。
好的!为了帮助你设计 product_prices 表的结构,并实现查找每个产品的最新价格的功能,我们首先需要明确表中应该包含哪些字段。通常,记录产品价格变化的历史表会包含以下信息:
product_id:产品的唯一标识符,用于区分不同的产品。price:产品的价格。change_date:价格变更的日期和时间,用于记录价格变化的时间点。id(可选):主键,用于唯一标识每一条价格记录,通常是自增的整数。created_at(可选):记录创建的时间戳,用于审计或调试。updated_at(可选):记录更新的时间戳,用于审计或调试。
表结构设计
表名:product_prices
| 列名 | 数据类型 | 说明 |
|---|---|---|
id | INT AUTO_INCREMENT | 主键,唯一标识每条价格记录 |
product_id | INT | 产品的唯一标识符 |
price | DECIMAL(10, 2) | 产品的价格,使用 DECIMAL 类型以确保精度 |
change_date | DATETIME | 价格变更的日期和时间 |
created_at | TIMESTAMP | 记录创建的时间戳,默认为当前时间 |
updated_at | TIMESTAMP | 记录更新的时间戳,默认为当前时间 |
SQL 创建表语句
CREATE TABLE product_prices (id INT AUTO_INCREMENT PRIMARY KEY,product_id INT NOT NULL,price DECIMAL(10, 2) NOT NULL,change_date DATETIME NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,INDEX idx_product_change_date (product_id, change_date)
);-- 产品 1 的价格变化历史
INSERT INTO product_prices (product_id, price, change_date) VALUES
(1, 10.99, '2023-01-01 10:00:00'),
(1, 12.49, '2023-02-15 14:30:00'),
(1, 11.75, '2023-03-10 09:15:00'),
(1, 13.50, '2023-04-05 16:45:00');-- 产品 2 的价格变化历史
INSERT INTO product_prices (product_id, price, change_date) VALUES
(2, 5.99, '2023-01-10 11:00:00'),
(2, 6.49, '2023-03-01 13:20:00');-- 产品 3 的价格变化历史(只有一个记录)
INSERT INTO product_prices (product_id, price, change_date) VALUES
(3, 19.99, '2023-02-28 15:30:00');
id:主键,自动递增,用于唯一标识每条记录。product_id:外键,关联到产品表(假设有一个products表),表示哪个产品的价格发生了变化。price:使用DECIMAL(10, 2)类型来存储价格,确保小数点后两位的精度。change_date:记录价格变化的时间,使用DATETIME类型。created_at和updated_at:用于记录创建和更新的时间戳,方便审计。INDEX idx_product_change_date:为product_id和change_date创建索引,加速查询性能,特别是在查找某个产品的最新价格时。
查找每个产品的最新价格
现在我们已经设计好了表结构,接下来可以编写 SQL 查询来查找每个产品的最新价格。你可以使用自连接或者窗口函数来实现这个需求。
方法 1:使用自连接
SELECT p1.product_id, p1.price, p1.change_date
FROM product_prices p1
LEFT JOIN product_prices p2 ON p1.product_id = p2.product_idAND p1.change_date < p2.change_date
WHERE p2.product_id IS NULL;
解释:
- 这个查询通过自连接将
product_prices表与自身进行关联。 p1表示当前的价格记录,p2表示比p1更新的价格记录。p1.change_date < p2.change_date确保我们只匹配比p1更新的价格记录。WHERE p2.product_id IS NULL表示没有比p1更新的价格记录,因此p1就是该产品的最新价格。
方法 2:使用窗口函数(推荐)
从 MySQL 8.0 开始,窗口函数(如 ROW_NUMBER())提供了更简洁和高效的解决方案。你可以使用窗口函数来为每个产品的价格记录分配一个行号,然后选择行号为 1 的记录作为最新价格。
WITH ranked_prices AS (SELECT product_id, price, change_date,ROW_NUMBER() OVER (PARTITION BY product_id ORDER BY change_date DESC) AS rnFROM product_prices
)
SELECT product_id, price, change_date
FROM ranked_prices
WHERE rn = 1;
解释:
ROW_NUMBER() OVER (PARTITION BY product_id ORDER BY change_date DESC):为每个product_id分区,并按change_date降序排列,分配行号。rn = 1:选择每个分区中行号为 1 的记录,即每个产品的最新价格。
方法 3:使用子查询
如果你使用的是较早版本的 MySQL(不支持窗口函数),还可以使用子查询来实现相同的效果:
SELECT p.product_id, p.price, p.change_date
FROM product_prices p
JOIN (SELECT product_id, MAX(change_date) AS max_change_dateFROM product_pricesGROUP BY product_id
) latest ON p.product_id = latest.product_id AND p.change_date = latest.max_change_date;
解释:
- 内部子查询
latest找出每个product_id的最大change_date,即最新的价格变更日期。 - 外部查询通过
JOIN将product_prices表与子查询结果进行连接,返回每个产品的最新价格。
总结
- 表结构设计:
product_prices表包含id、product_id、price、change_date等字段,确保能够记录产品的价格变化历史。 - 查找最新价格:可以通过自连接、窗口函数或子查询来实现。推荐使用窗口函数(MySQL 8.0+),因为它更简洁且性能更好。
根据你的需求和 MySQL 版本,选择合适的方法来查找每个产品的最新价格。如果你使用的是 MySQL 8.0 或更高版本,建议使用窗口函数,因为它不仅代码更简洁,而且在处理大量数据时性能也更好。
总结
自连接是一种强大的工具,适用于处理具有层次结构、递归关系、重复记录、连续记录等场景。它的主要优点是可以简化复杂的查询逻辑,避免创建额外的表或视图。然而,自连接也会增加查询的复杂性和执行时间,因此在使用时需要注意性能优化,尤其是在处理大数据集时。
如果你有更多具体的需求或遇到其他问题,欢迎继续讨论!
相关文章:

mysql自连接 处理层次结构数据
MySQL 的自连接(Self Join)是一种特殊的连接方式,它允许一个表与自身进行连接。自连接通常用于处理具有层次结构或递归关系的数据,或者当同一张表中的数据需要相互关联时。以下是几种常见的场景,说明何时应该使用自连接…...

##__VA_ARGS__有什么作用
##__VA_ARGS__ 是 C/C 中宏定义(Macro)的一种特殊用法,主要用于可变参数宏(Variadic Macros)的场景,解决当可变参数为空时可能导致的语法错误问题。以下是详细解释: 核心作用 消除空参数时的多余…...
返回不到上个页面)
鸿蒙 router.back()返回不到上个页面
1. 检查页面栈(Page Stack) 鸿蒙的路由基于页面栈管理,确保上一个页面存在且未被销毁。 使用 router.getLength() 检查当前页面栈长度: console.log(当前页面栈长度: ${router.getLength()}); 如果结果为 1,说明没有上…...

深度学习模型蒸馏技术的发展与应用
随着人工智能技术的快速发展,大型语言模型和深度学习模型在各个领域展现出惊人的能力。然而,这些模型的规模和复杂度也带来了显著的部署挑战。模型蒸馏技术作为一种优化解决方案,正在成为连接学术研究和产业应用的重要桥梁。本文将深入探讨模…...

STM32G0B1 ADC DMA normal
目标 ADC 5个通道,希望每1秒采集一遍; CUBEMX 配置 添加代码 #define ADC1_CHANNEL_CNT 5 //采样通道数 #define ADC1_CHANNEL_FRE 3 //单个通道采样次数,用来取平均值 uint16_t adc1_val_buf[ADC1_CHANNEL_CNT*ADC1_CHANNEL_FRE]; //传递…...

<tauri><rust><GUI>基于rust和tauri,在已有的前端框架上手动集成tauri示例
前言 本文是基于rust和tauri,由于tauri是前、后端结合的GUI框架,既可以直接生成包含前端代码的文件,也可以在已有的前端项目上集成tauri框架,将前端页面化为桌面GUI。 环境配置 系统:windows 10 平台:visu…...
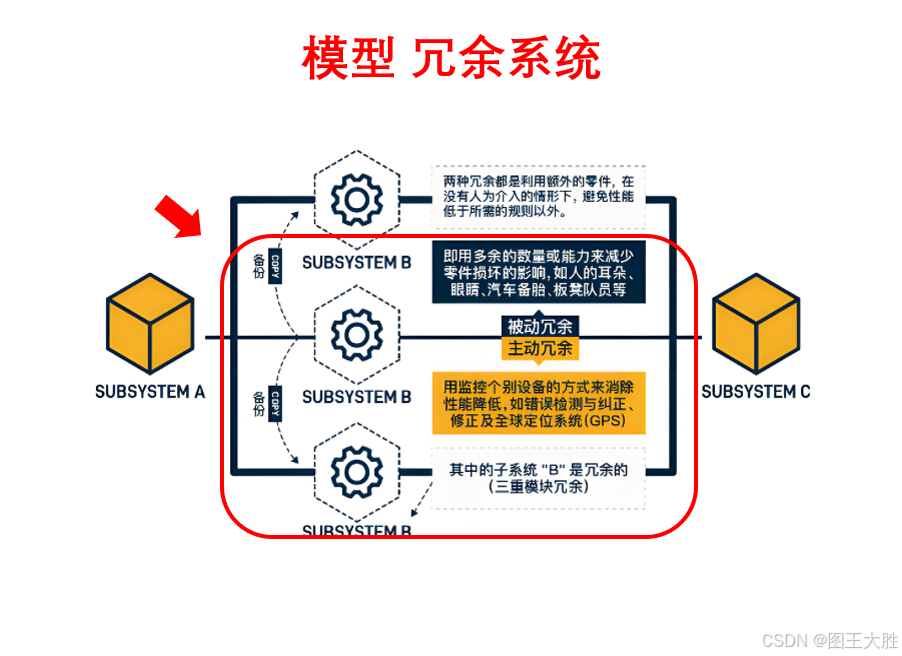
模型 冗余系统(系统科学)
系列文章分享模型,了解更多👉 模型_思维模型目录。为防故障、保运行的备份机制。 1 冗余系统的应用 1.1 冗余系统在企业管理中的应用-金融行业信息安全的二倍冗余技术 在金融行业,信息安全是保障业务连续性和客户资产安全的关键。随着数字化…...

Deepseek部署的模型参数要求
DeepSeek 模型部署硬件要求 模型名称参数量显存需求(推理)显存需求(微调)CPU 配置内存要求硬盘空间适用场景DeepSeek-R1-1.5B1.5B4GB8GB最低 4 核(推荐多核)8GB3GB低资源设备部署,如树莓派、旧…...

AI-学习路线图-PyTorch-我是土堆
1 需求 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili PyTorch 深度学习快速入门教程 配套资源 链接 视频教程 https://www.bilibili.com/video/BV1hE411t7RN/ 文字教程 https://blog.csdn.net/xiaotudui…...

[LeetCode]day17 349.两个数组的交集
https://leetcode.cn/problems/intersection-of-two-arrays/description/ 题目描述 给定两个数组 nums1 和 nums2 ,返回它们的交集。 输出结果中的每个元素一定是唯一的。 我们可以不考虑输出结果的顺序 。 示例 1: 输入:nums1 [1,2,2,1…...

axios 发起 post请求 json 需要传入数据格式
• 1. axios 发起 post请求 json 传入数据格式 • 2. axios get请求 1. axios 发起 post请求 json 传入数据格式 使用 axios 发起 POST 请求并以 JSON 格式传递数据是前端开发中常见的操作。 下面是一个简单的示例,展示如何使用 axios 向服务器发送包含 JSON 数…...

linux交叉编译paho-mqtt-c
下载源代码: https://github.com/eclipse-paho/paho.mqtt.c.git 编译: 如果mqtt不需要SSL安全认证,可以直接执行(注意把编译工具链路径改成自己的) cd paho.mqtt.c-1.3.13/ mkdir install # 创建安装目录 mkdir…...
)
feign Api接口中注解问题:not annotated with HTTP method type (ex. GET, POST)
Bug Description 在调用Feign api时,出现如下异常: java.lang.IllegalStateException: Method PayFeignSentinelApi#getPayByOrderNo(String) not annotated with HTTPReproduciton Steps 1.启动nacos-pay-provider服务,并启动nacos-pay-c…...

安装指定版本的pnpm
要安装指定版本的 pnpm,可以使用以下方法: 方法 1: 使用 pnpm 安装指定版本 你可以通过 pnpm 的 add 命令来安装指定版本: pnpm add -g pnpm<版本号>例如,安装 pnpm 的 7.0.0 版本: pnpm add -g pnpm7.0.0方法…...

【系统设计】Spring、SpringMVC 与 Spring Boot 技术选型指南:人群、场景与实战建议
在 Java 开发领域,Spring 生态的技术选型直接影响项目的开发效率、维护成本和长期扩展性。然而,面对 Spring、SpringMVC 和 Spring Boot 这三个紧密关联的框架,开发者常常陷入纠结:该从何入手?如何根据团队能力和业务需…...

常用数据结构之String字符串
字符串 在Java编程语言中,字符可以使用基本数据类型char来保存,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。 操作字符串常用的有三种类:String、StringBuilder、StringBuffer 接下来看看这三类常见用…...

深入Linux系列之进程地址空间
深入Linux系列之进程地址空间 1.引入 那么在之前的学习中,我们知道我们创建一个子进程的话,我们可以在代码层面调用fork函数来创建我们的子进程,那么fork函数的返回值根据我们当前所处进程的上下文是返回不同的值,它在父进程中返…...
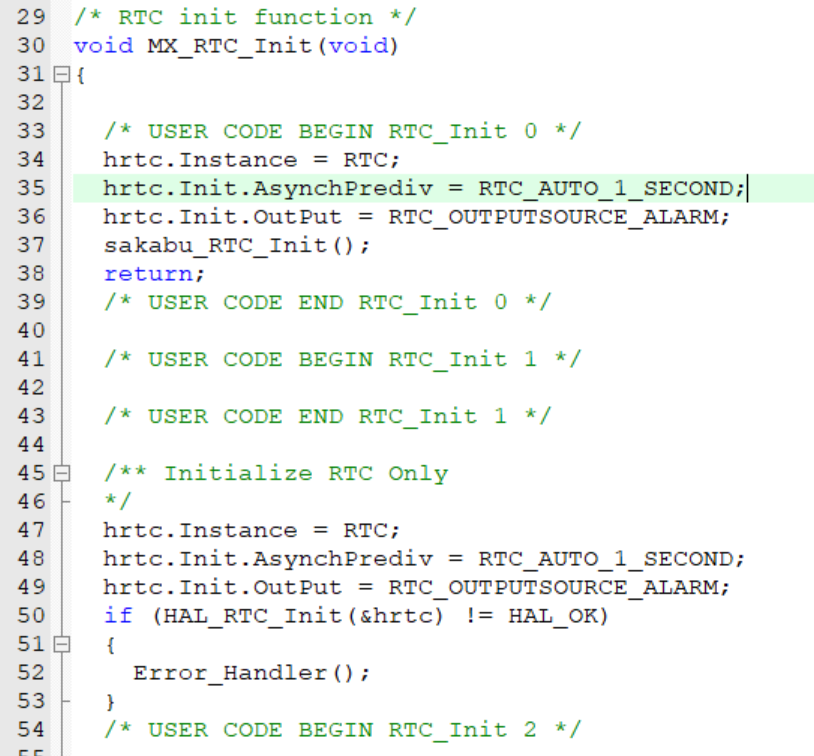
HAL库外设宝典:基于CubeMX的STM32开发手册(持续更新)
目录 前言 GPIO(通用输入输出引脚) 推挽输出模式 浮空输入和上拉输入模式 GPIO其他模式以及内部电路原理 输出驱动器 输入驱动器 中断 外部中断(EXTI) 深入中断(内部机制及原理) 外部中断/事件控…...

网络安全-HSTS
什么是HSTS? HTTP严格传输安全协议(HTTP Strict Transport Security,简称:HSTS) 是互联网安全策略机制。网站可以选择使用HSTS策略,来让浏览器强制使用HTTPS与网站进行通信,以减少会话劫持风险。…...

全程Kali linux---CTFshow misc入门(38-50)
第三十八题: ctfshow{48b722b570c603ef58cc0b83bbf7680d} 第三十九题: 37换成1,36换成0,就得到长度为287的二进制字符串,因为不能被8整除所以,考虑每7位转换一个字符,得到flag。 ctfshow{5281…...

百度首页网页图片更多当AI开始写测试用例,手工测试工程师的护城河在哪里?
一、 第一道护城河:从“用例执行者”到“策略设计者”AI可以基于需求文档和历史数据,瞬间生成海量测试用例。但它无法回答一个根本性的问题:我们究竟应该测试什么?测试策略的设计,是在有限的时间和资源下,对…...

Java反编译终极指南:JD-GUI从入门到精通完整教程
Java反编译终极指南:JD-GUI从入门到精通完整教程 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui Java反编译是每个Java开发者必备的核心技能,而JD-GUI正是这一领域的终极利器。作…...

Hermes-Agent 智能体核心能力与实战效能深度评测
在构建自动化工作流或智能客服系统时,开发者最常遇到的痛点往往不是模型本身不够聪明,而是“记不住”和“乱执行”。很多时候,一个智能体在前几轮对话中还逻辑清晰,一旦上下文拉长,就开始遗忘关键约束,或者…...

SoC设计中虚拟原型技术与TLM建模实践
1. 虚拟原型技术概述在SoC设计领域,虚拟原型技术(Virtual Prototyping)已经成为现代芯片开发流程中不可或缺的关键环节。这项技术的核心价值在于,它能够在RTL级硬件设计完成之前,就为软件团队提供一个可执行的硬件抽象模型。作为一名经历过多…...
)
避开这3个坑,你的MAX30102心率数据才更准(Arduino实测经验分享)
避开这3个坑,你的MAX30102心率数据才更准(Arduino实测经验分享) 当你在健康监测或可穿戴设备项目中使用MAX30102传感器时,是否遇到过心率数据忽高忽低、稳定性差的问题?这很可能不是传感器本身的问题,而是你…...

Android Studio中文界面:从英文困扰到母语开发的完整解决方案
Android Studio中文界面:从英文困扰到母语开发的完整解决方案 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾…...
)
别再瞎调了!OpenCV手动曝光参数CAP_PROP_EXPOSURE与快门时间换算表(附Python/C++代码)
OpenCV曝光参数与快门时间实战指南:从原理到精准控制 在计算机视觉项目中,摄像头曝光控制往往是影响图像质量的关键因素之一。许多开发者在使用OpenCV的CAP_PROP_EXPOSURE参数时,都会遇到一个共同的困惑:为什么设置的值是-13而不…...

如何用Python操控Photoshop?3步实现自动化图像处理的终极指南
如何用Python操控Photoshop?3步实现自动化图像处理的终极指南 【免费下载链接】photoshop-python-api Python API for Photoshop. 项目地址: https://gitcode.com/gh_mirrors/ph/photoshop-python-api Photoshop Python API是一个革命性的工具,让…...

iVentoy(增强版PXE服务器
链接:https://pan.quark.cn/s/d2ca56327274iVentoy是一个增强版的PXE服务器。你可以通过网络同时为多台机器启动和安装操作系统。软件的使用非常简单,无需复杂的配置。只需要直接将ISO文件放在指定的位置,然后在启动时,客户机可以…...

【谷歌内部培训材料流出】:Gemini与Workspace Admin Console深度绑定的5类企业级策略配置
更多请点击: https://intelliparadigm.com 第一章:Gemini与Workspace Admin Console深度集成的底层架构解析 Gemini 与 Workspace Admin Console 的深度集成并非简单的 API 调用叠加,而是基于统一身份上下文、双向实时状态同步和策略驱动控制…...