LIMO:上海交大的工作 “少即是多” LLM 推理
25年2月来自上海交大、SII 和 GAIR 的论文“LIMO: Less is More for Reasoning”。
一个挑战是在大语言模型(LLM)中的复杂推理。虽然传统观点认为复杂的推理任务需要大量的训练数据(通常超过 100,000 个示例),但本文展示只需很少的示例就可以有效地引发复杂的数学推理能力。这个不仅挑战对海量数据要求的假设,也挑战监督微调(SFT)主要造成记忆而不是泛化的普遍看法。"少即是多"推理假说(LIMO 假说):在预训练期间已全面编码域知识的基础模型中,复杂的推理能力可以通过最少但精确协调的认知过程演示显现出来。该假设认为,复杂推理的引出阈值,本质上不受目标推理任务复杂性的限制,而是由两个关键因素从根本上决定的:(1)预训练期间模型编码知识基础的完整性,以及(2)后训练示例的有效性,它们作为“认知模板”,向模型展示如何有效利用现有知识库来解决复杂的推理任务。
如图所示:LIMO 使用更少的样本实现比 NuminaMath 显著的改进,同时在各种数学和多学科基准测试中表现出色。

长期以来,复杂推理一直被认为是大语言模型 (LLM) 中最难培养的能力之一。尽管最近的研究表明,LLM 可以通过相对较少的指令数据有效地与用户偏好保持一致(Zhou,2024a),但人们普遍认为,教师模型进行推理(尤其是在数学和编程方面)需要更多的训练示例(Paster,2023;Yue,2024)。
这种传统观点源于推理任务固有的复杂性,它需要多步骤的逻辑推理、域知识应用和结构化的解决方案路径。由此产生的范式通常涉及对数万或数十万个示例进行训练(Yu,2024;Li,2024b),基于两个基本假设:首先,掌握如此复杂的认知过程需要大量监督演示;其次,监督微调主要造成记忆而不是真正的泛化(Zhang,2024;Xu,2024;Chu,2025)。
虽然这种方法已取得成功,但它带来了巨大的计算成本和数据收集负担。更重要的是,这种数据密集型范式可能不再是必要的。最近的进展从根本上改变 LLM 获取、组织和利用推理知识的方式,表明有可能采用一种更有效的方法。特别是两个关键发展从根本上为重新构想 LLM 中的推理方法创造了条件:
- 知识基础革命:现代基础模型现在在预训练期间纳入前所未有的大量数学内容(Qwen,2025;Yang,2024;Wang,2024)。例如:Llama 2 在所有域的总训练数据为 1.8T 个 token(Touvron,2023 年),而 Llama 3 仅在数学推理中就使用 3.7T 个 token(Grattafiori,2024 年)。这表明当代 LLM 可能已经在其参数空间中拥有丰富的数学知识,将挑战从知识获取转变为知识引出。
- 推理-时间计算规模化革命:规模化更长推理链技术的出现表明,有效的推理在论断过程中需要大量的计算空间。最近的研究(OpenAI,2024;Qin,2024;Huang,2024)表明,允许模型生成规模化推理链,可显著提高其推理能力。本质上,推理-时间计算提供了至关重要的认知工作空间,模型可以在其中系统地解开和应用其预先训练的知识。
LLM 中数学推理的演变。大规模训练数据一直是 LLM 推理能力发展的驱动力。在预训练阶段,相关语料库可以增强 LLM 的推理能力(Wang,2024;Azerbayev,2024;Paster,2023;Shao,2024)。这些精选语料库可以由多种来源组成,例如教科书、科学论文和数学代码,它们捕捉用于解决问题的各种人类认知模式。在后训练阶段,一系列研究专注于策划大规模指令数据以教授 LLM 推理(Yue,2023、2024;Li,2024a)。这包括规模化问题及其相应解决方案的数量。规模化方法很有前景,并且已经取得显着的性能提升。然而,通过这种方法获得的推理能力,因依赖于固定模式的记忆而不是实现真正的泛化而受到批评(Mirzadeh,2024;Zhang,2024)。例如,Mirzadeh(2024)发现,LLM 在回答同一问题的不同实例时表现出明显的差异,并且当仅改变问题中的数值时,其性能会下降。这引发人们对 SFT 方法泛化能力的怀疑(Chu,2025),以及 LLM 是否可以成为真正的推理者而不是单纯的知识检索者(Kambhampati,2024)。
测试-时间规模化和长链推理。最近的研究不再关注规模化模型参数和训练数据(Kaplan,2020),而是转向探索测试-时间规模化(OpenAI,2024;Snell,2024),即增加 token 数量以提高性能。这可以通过使用并行采样(Brown,2024;Wang,2022;Li,2022)或符号树搜索(Hao,2023;Chen,2024;Yao,2023)等方法增强 LLM 来实现,以增强推理能力。此外,OpenAI(2024);Guo(2025) 探索使用强化学习训练 LLM 以生成长 CoT,这通常包括自我反思、验证和回溯——人类在解决复杂问题时常用的过程。这种方法不仅创新 LLM 的训练范式,而且还提供一种新形式的训练数据来增强其推理能力。这种长 CoT 在引出 LLM 固有的推理能力方面表现出高质量的特征。
语言模型中的数据效率。Zhou (2024a) 证明,仅需 1,000 个策划的提示和响应,模型就可以学会遵循特定的格式并很好地推广到未见过的任务。研究结果强调在对齐过程中质量重于数量的重要性。然而,考虑到此类任务的潜在高计算复杂性,这一教训是否可以应用于推理任务仍不确定(Merrill & Sabharwal,2024;Xiang,2025)。虽然一些关于推理的研究强调在整理训练数据时质量的重要性(Zhou,2024b),但此类数据的数量与 LIMA 相比仍然大得多。
LIMO 假设
将“少即是多”推理 (LIMO) 假设形式化如下:在基础模型中,域知识在预训练期间已被全面编码,复杂的推理能力可以在最少但精确编排的认知过程演示中出现。
这一假设基于两个基本前提:(I)在模型参数空间中,先决条件知识的潜在存在(II)推理链的质量,这些推理链将复杂问题精确分解为详细的逻辑步骤,使认知过程明确且可追溯。
为了验证这一假设,本文提出一种系统的方法来构建一个高质量、最小的数据集,可以有效地抽出模型固有的推理能力。
问题定义
本文专注于具有可验证答案的推理任务。给定推理问题空间中的问题 q,目标是生成答案 a 和推理链 r。将推理链 r 定义为一系列中间步骤 {s_1, s_2, …, s_n},其中每个步骤 s_i 代表一个逻辑推理,它弥补问题和最终答案之间的差距。
正式地,可以将推理过程表示为函数 f: Q→R×A。因此,生成数据集 D 的质量,由两个基本但多方面的组成部分决定:(1) 问题 q 的质量,其中包括问题解决方法的多样性、挑战模型能力的适当难度级别、以及涵盖的知识领域广度等因素;(2) 解决方案的质量 (r, a),其中包括教学价值、逻辑连贯性和方法严谨性等方面。问题的设计应鼓励复杂的推理模式和知识整合,而解决方案应展示清晰的逻辑进展并作为有效的学习示例。
高质量数据管理
数据管理过程侧重于构建高质量数据集 D = {(q_i, r_i, a_i)},并且数据量 N 故意保持较小以验证 LIMO 假设。
问题选择。假设高质量问题 q 应该自然地引发扩展的推理过程。选择标准包括以下内容:
• 难度级别。优先考虑那些能够促进复杂推理链、多样化思维过程和知识整合的具有挑战性问题,使 LLM 能够有效地利用预训练的知识进行高质量推理。
• 泛化性。与模型的训练分布偏差更大的问题,可以更好地挑战其固定的思维模式,鼓励探索新的推理方法,从而扩大其推理搜索空间。
• 知识多样性。所选问题应涵盖各种数学领域和概念,要求模型在解决问题时整合和连接远端的知识。
为了有效地实施这些标准,首先从各种既定数据集中收集一个全面的候选问题池:NuminaMath-CoT,包含从高中到高级竞赛水平的标注问题;AIME 历史考试问题,以其极具挑战性和综合性的问题而闻名,涵盖多个数学领域;MATH(Hendrycks,2021),涵盖来自著名竞赛的各种竞争性数学问题;以及其他几个数学问题来源。
从这个丰富的初始集合中,采用系统的多阶段过滤过程。
- 从数千万个问题的初始池开始,首先使用 Qwen2.5-Math-7B-Instruct(Yang,2024)应用基线难度过滤器,消除该模型可以在几次尝试中正确解决的问题。这个过程有助于建立初步的难度阈值。
- 随后,使用最先进的推理模型,包括 R1、DeepSeek-R1-Distill-Qwen-32B(Guo,2025)和 Huang(2024)的模型,对剩余的问题进行更严格的评估,仅保留即使是这些最强大的模型在多次采样迭代后成功率也低于某个阈值的问题。
- 最后,为保持语料库的多样性,采用战略采样技术,在数学领域和复杂度级别之间平衡表示,同时避免概念冗余。这一细致的选择过程,最终从数千万个候选问题的初始池中产生817 个挑选的问题,所选问题共同满足严格的质量标准,同时涵盖丰富的数学推理挑战。
推理链构建。除了高质量的问题之外,解决方案的质量在大语言模型的训练阶段也起着关键作用。为了挑选高质量的解决方案,采用全面的选择策略。首先收集问题的官方解决方案(如果可用),并辅以人类专家和 AI 专家编写的解决方案。此外,利用最先进的推理模型,包括 DeepSeek R1、DeepSeek-R1-Distill-Qwen-32B(Guo,2025)和 Qwen2.5-32b-Instruct,来生成不同的解决方案。此外,按照 O1-Journey-Part2(Huang,2024)中提出的方法,利用基于 Qwen2.5-32b-Instruct 的自我蒸馏技术来创建其他模型变型,然后使用这些变型生成补充问题响应。然后根据答案的正确性筛选这些响应,以建立有效解决方案的基线集合。随后,通过协作检查对这些筛选的解决方案进行全面分析。通过仔细观察和系统审查,确定区分高质量推理链的几个关键特征:
• 最佳结构组织:解决方案表现出清晰且组织良好的结构格式,步骤分解具有自适应粒度。特别是,它在关键的推理节点分配更多token和详细阐述,同时保持简单步骤的简洁表达。这种自适应步骤粒度方法,可确保复杂的转换得到适当的关注,同时避免在较简单的推理中出现不必要的冗长。
• 有效的认知支架:高质量的解决方案,通过精心构建的解释逐步建立理解,从而提供战略教育支持。这包括渐进的概念介绍、在关键点清晰表达关键见解以及深思熟虑地弥合概念差距,使复杂的推理过程更易于理解和学习。
• 严格的验证:高质量的解决方案,在整个推理过程中包含极其频繁的验证步骤。这包括验证中间结果、交叉检查假设以及确认每个推论的逻辑一致性,从而确保最终答案的可靠性。
基于这些确定的特征,开发一种结合基于规则的过滤和 LLM 辅助策划的混合方法,以针对上述每个问题选择高质量的解决方案。这个系统化的过程,确保每个选定的解决方案都符合既定的质量标准,同时保持整个数据集的一致性。通过专注于一组最小策划的推理链,体现“少即是多”的核心原则:高质量的演示,而不是纯粹的数据量,是解锁复杂推理能力的关键。
生成的数据集 D 由精心策划的三元组 (q, r, a) 组成,其中每个推理链 r 都满足质量标准。在限制数据集大小 |D| 的同时保持这些严格的标准,旨在证明高质量的演示,而不是大量的训练数据,对于解锁复杂的推理能力至关重要。
方法论
基于“少即是多”原则,一个模型如果在预训练中积累大量的推理知识,并且在测试-时能够执行长链推理,那么它就可以发展出强大的推理能力。在仅对几百个 SFT 数据实例进行训练后,该模型就会学会将元推理任务整合成一个有凝聚力的推理链。
训练协议
在 LIMO 数据集上使用监督微调对 Qwen2.5-32B-Instruct 进行微调。训练过程采用全参数微调,使用 DeepSpeed ZeRO-3 优化(Rajbhandari,2020)和 FlashAttention- 2(Dao,2023),序列长度限制为 16,384 个 tokens。
评估框架
域内评估。为了全面评估模型在各种推理能力方面的表现,建立了一个涵盖传统和新型基准的多样化评估框架。我们的主要评估套件包括几个成熟的数学竞赛和基准:美国数学邀请赛 (AIME24)、MATH500 (Hendrycks,2021) 和美国数学竞赛 (AMC23)。
分布外(OOD)评估。为了严格评估模型在分布外任务上的表现,选择与训练数据在各个方面不同的一些基准。这些基准可以分为三个不同的类别:
• 多样化的数学竞赛:进一步选择 OlympiadBench(He,2024),它代表数学挑战的独特分布,用于测试模型的 OOD 性能。
• 新的多语言基准:为了最大限度地减少数据污染,用最新的考试问题构建几个基准:2024 年中国高中数学联赛竞赛 CHMath、2024 年中国高考 GAOKAO、中国研究生入学考试 KAOYAN,以及新开发的用于初等数学推理 GradeSchool。值得注意的是,这些基准中的所有问题都是用中文编写的,而训练数据不包含中文问题。这引入一个额外的 OOD 维度,不仅评估模型在问题分布中泛化的能力,还评估其在面对未见过语言时的跨语言推理能力。
• 多学科基准:为了评估数学(训练领域)以外更广泛的泛化能力,结合 Miverva(Lewkowycz,2022)(其中包括本科水平的 STEM 问题)和 GPQA(Rein,2023)。这些基准评估跨多个学科和认知水平的推理能力,深入了解模型将数学推理技能转移到更广泛环境的能力。
性能指标。用 pass@1 指标评估整个基准套件的性能。所有评估均在零样本思维链 (CoT) 设置下进行,以更好地评估模型的推理能力。对于包括 MATH500、OlympiadBench、Gaokao、Kaoyan、GradeSchool、MinervaMath 和 GPQA 在内的基准,采用一种简单的方法,使用贪婪解码和一个单样本来评估正确性。但是,对于每个包含少于 50 个问题的较小基准(特别是 AIME24、AMC23 和 CHMATH),实施更全面的评估协议,生成 16 个样本,温度设置为 0.7,并计算无偏 pass@1 指标,如 Chen (2021) 中所述。对于答案是结构良好的数值问题,直接应用基于规则的评估来检查数学等价性。对于更复杂的答案格式(例如表达式、方程式或结构化解决方案),利用基于 LLM 的评估器,已经验证它的高可靠性。
在所有评估过程中,将最大输出长度保持在 32,768 个 tokens,以最大限度地减少输出截断的可能性,确保评估能够捕获完整的问题解决尝试。此外,在评估 LIMO 时,观察到推理-时间规模化偶尔会导致冗长输出末尾出现重复模式。在这种情况下,从模型的响应中提取最可能的最终答案进行评估,以确保准确评估其解决问题的能力。
现象再思考:“少即是多”和强化学习规模化
LIMO 的出现,代表在大语言模型中概念化和激活复杂推理能力的范式转变。首先,将 LIMO 与 LIMA 进行对比,了解“少即是多”原则如何从一般对齐扩展到复杂推理;其次,将 LIMO 与强化学习 (RL) 规模化方法进行比较,以突出开发推理能力的不同哲学观点。通过这些分析,旨在更深入地了解语言模型中复杂认知能力的出现方式以及有效激活的条件。
LIMO 与 LIMA
LLM 中“少即是多”现象的出现,代表对如何用最少的数据引出复杂能力的理解发生了根本性转变。虽然 LIMA(Zhou,2024a)首先在一般对齐的背景下展示了这种现象,但将这一原则扩展到复杂的数学推理提出了独特的挑战和要求。
知识基础革命。过去两年见证语言模型获取和组织数学知识的方式转变。虽然 LIMA 可以依靠一般文本语料库进行对齐,但 LIMO 的成功建立在通过专门的预训练嵌入现代基础模型的丰富数学内容之上(Wang,2024)。这种专门的知识基础是有效激活推理能力的先决条件。
计算能力革命。LIMA 和 LIMO 之间的一个关键区别在于它们的计算要求。虽然 LIMA 的对齐任务可以通过固定长度生成和单次处理来完成,但 LIMO 的推理任务需要大量的计算空间来进行多步审议。推理-时间规模化技术的出现(OpenAI,2024;Qin,2024)提供了必要的“认知工作空间”,模型可以在其中系统地解开并应用其预训练的知识。
协同合流。LIMO 的发现时间,反映了这两场革命的必要合流。 LIMA 和 LIMO 之间两年的差距,不仅代表更好的预训练模型所需时间,还代表等待推理-时间计算突破的必要时间。这种合流促成一种称为“推理抽出阈值”的现象:当模型同时拥有丰富的域知识和足够的计算空间时,可以通过最少但精确的演示激活复杂的推理能力。
对未来研究的启示。这种比较分析表明,“少即是多”不仅仅是一种使用更少数据的提倡,而且是支配模型能力有效抽出的一条基本原则。 LIMO 的成功表明,当满足基本先决条件(知识基础和计算框架)时,复杂的能力可以以显著的数据效率抽出。这一见解表明一个新的研究方向:系统地识别不同能力的先决条件和最佳激活条件。未来的工作应该探索其他高级能力(例如,规划、创造性解决问题)在建立相应的知识和计算基础后是否能达到类似的效率。因此,“少即是多”原则既是理解能力出现的理论框架,也是在各个领域追求数据高效能力发展的实用指南。
如下表比较复杂推理 LIMO 和通用对齐 LIMA:

LIMO 与 RL 规模化
在大语言模型中开发推理能力两种不同方法的出现——RL 规模化和 LIMO——代表了理解和增强模型智能的根本分歧。RL 规模化以 o1(OpenAI,2024)、DeepSeek-R1(Guo,2025)等为例,从工程优化的角度应对挑战。它假设推理能力需要通过大规模强化学习进行广泛的模型训练。虽然这种方法有效,但它本质上将 RL 视为一种广泛的搜索机制,通过大量计算资源发现有效的推理模式。
相比之下,LIMO 引入一个更基础的视角:推理能力已经潜伏在预训练模型中,嵌入在预训练阶段。关键挑战从“训练”转向“抽出”——找到能够引出这些天生能力的精确认知模板。
从这个角度来看,像 DeepSeek-R1 这样的 RL 规模化方法可以看作是这一原则的具体实现,使用强化学习作为寻找此类轨迹的机制。虽然这两种方法最终都寻求高质量的推理解决方案,但 LIMO 通过明确的轨迹设计提供一条更有原则、更直接的路径,而 RL 规模化则通过广泛的计算探索发现这些轨迹。这种重新构建表明,包括 RL、专家设计或混合方法在内的各种方法,都可以在 LIMO 的框架内被理解和评估为发现最佳推理轨迹的不同策略。
如下表比较 LIMO 和 RL 规模化:

相关文章:
LIMO:上海交大的工作 “少即是多” LLM 推理
25年2月来自上海交大、SII 和 GAIR 的论文“LIMO: Less is More for Reasoning”。 一个挑战是在大语言模型(LLM)中的复杂推理。虽然传统观点认为复杂的推理任务需要大量的训练数据(通常超过 100,000 个示例),但本文展…...

Android studio怎么创建assets目录
在Android Studio中创建assets文件夹是一个简单的步骤,通常用于存储不需要编译的资源文件,如文本文件、图片、音频等 main文件夹,邮件new->folder-assets folder...

常见的前端框架和库有哪些
1. React 描述:由 Facebook 开发的一个 JavaScript 库,用于构建用户界面,尤其是单页面应用(SPA)。特点: 基于组件的架构,便于重用 UI 组件。使用虚拟 DOM 提升性能。容易与其他库和框架集成。 …...

【批量获取图片信息】批量获取图片尺寸、海拔、分辨率、GPS经纬度、面积、位深度、等图片属性里的详细信息,提取出来后导出表格,基于WPF的详细解决方案
摄影工作室通常会有大量的图片素材,在进行图片整理和分类时,需要知道每张图片的尺寸、分辨率、GPS 经纬度(如果拍摄时记录了)等信息,以便更好地管理图片资源,比如根据图片尺寸和分辨率决定哪些图片适合用于…...

数据结构与算法(test3)
七、查找 1. 看图填空 查找表是由同一类型的数据元素(或记录)构成的集合。例如上图就是一个查找表。 期中(1)是______________. (2)是______________(3)是_____关键字_______。 2. 查找(Searching) 就是根据给定的某个值, 在查…...

基于Python的人工智能驱动基因组变异算法:设计与应用(下)
3.3.2 数据清洗与预处理 在基因组变异分析中,原始数据往往包含各种噪声和不完整信息,数据清洗与预处理是确保分析结果准确性和可靠性的关键步骤。通过 Python 的相关库和工具,可以有效地去除噪声、填补缺失值、标准化数据等,为后续的分析提供高质量的数据基础。 在基因组…...

C++ 顺序表
顺序表的操作有以下: 1 顺序表的元素插入 给定一个索引和元素,这个位置往后的元素位置都要往后移动一次,元素插入的步骤有以下几步 (1)判断插入的位置是否合法,如果不合法则抛出异常 (2&…...

Mac(m1)本地部署deepseek-R1模型
1. 下载安装ollama 直接下载软件,下载完成之后,安装即可,安装完成之后,命令行中可出现ollama命令 2. 在ollama官网查看需要下载的模型下载命令 1. 在官网查看deepseek对应的模型 2. 选择使用电脑配置的模型 3. copy 对应模型的安…...

Docker 部署 redis | 国内阿里镜像
一、简易单机版 1、镜像拉取 # docker hub 镜像 docker pull redis:7.0.4-bullseye # 阿里云镜像 docker pull alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/redis_optimized:20240221-6.2.7-2.3.0 2、运行镜像 docker run -itd --name redis \n …...

48V电气架构全面科普和解析:下一代智能电动汽车核心驱动
48V电气架构:下一代智能电动汽车核心驱动 随着全球汽车产业迈入电动化、智能化的新时代,传统12V电气系统逐渐暴露出其无法满足现代高功率需求的不足。在此背景下,48V电气架构应运而生,成为现代电动汽车(EV)…...

滤波器截止频率的计算
1、RC低通滤波器 图1.1 RC低通滤波器 RC低通滤波器如图1.1所示,电阻R串联电容C,输入电压记为Ui ,输出电压记为Uo。 电容容抗记为,其中ω 2πf。 根据串联分压,列出传递函数。 将①式最右侧的分子与分母各乘以1-jω…...

服务器绑定 127.0.0.1 和 0.0.0.0 的区别
前言 IP 地址实际上并不是分配给计算机的,而是分配给网卡的,因此当计算机上存在多块网卡时,每一块网卡都会有自己的 IP 地址。 绑定 127.0.0.1 是绑定到 lookback 这个虚拟的本地回环接口,该接口只处理本机上的数据,…...

DeepSeek提示词手册
一、核心原则:基于DeepSeek的推理特性 自然语言优先undefinedDeepSeek擅长理解自然表达,无需复杂模板。例如: ❌旧模板:"你是专业分析师,需分三步回答,第一步…" ✅高效提问:"…...

校园网规划方案
个人博客站—运维鹿: http://www.kervin24.top CSDN博客—做个超努力的小奚: https://blog.csdn.net/qq_52914969?typeblog 本课程设计参考学习计算机网络 思科Cisco Packet Tracer仿真实验_哔哩哔哩_bilibili, 文章和pkg详见个人博客站: http://www.kervin24.to…...

python怎么求 一个数是否包含3
python求一个数包含3的方法: 1、使用“for i in 列表名”循环遍历列表中的每一个元素并将每个元素用str()函数转换成字符串格式 2、用“if str(3) in i”判断该元素中是否含有3 完整代码如下: 执行结果如下:...

ARM RFEIA指令作用
FreeRTOS第一个任务如何run起来的 在给ARM cortex R5适配FreeRTOS的过程中,在执行第一个task时,都是使用vTaskStartScheduler()函数,把第一个task运行起来的,其中比较关键在port.c实现的xPortStartScheduler()函数中,…...

【Kubernetes】常用命令全解析:从入门到实战(上)
🐇明明跟你说过:个人主页 🏅个人专栏:《Kubernetes航线图:从船长到K8s掌舵者》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、Kubernetes简介 2、安装Kubernetes …...
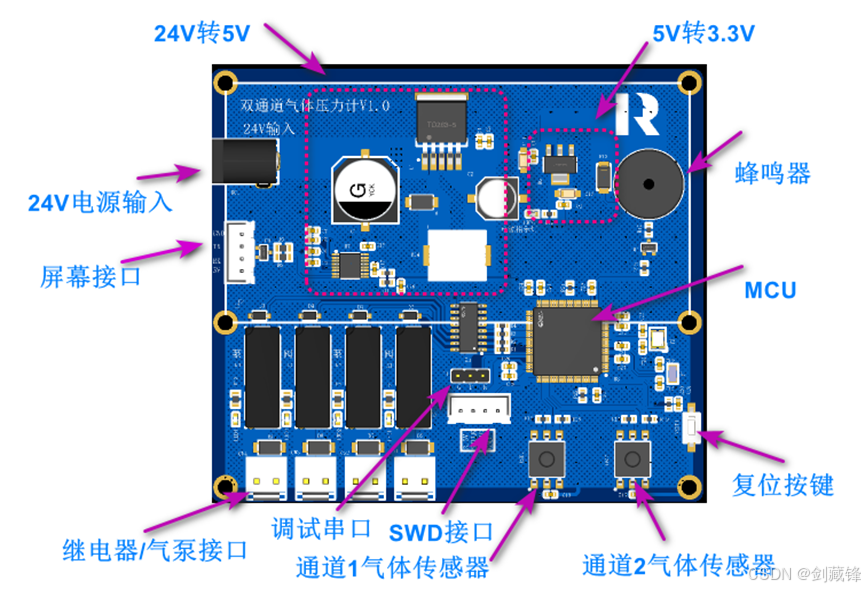
项目实战(11)-双通道气体压力计V1.0
一. 产品简介: 1、项目背景是在实际应用中需要监控通道内气体的压力,压力计分为两个通道;通道一时实时监控;通道二是保压,设定保压值得上下限后通道内得气体压力值会一直保持在这个范围内。 二. 应用场景:…...

Node.js怎么调用到打包的python文件呢
在 Node.js 中调用打包后的 Python 可执行文件(如 PyInstaller 生成的 .exe 或二进制文件),可以通过以下步骤实现: 一、Python 打包准备 假设已有打包好的 Python 文件 your_script.exe(以 Windows 为例)&…...

Transformer 详解:了解 GPT、BERT 和 T5 背后的模型
目录 什么是 Transformer? Transformer如何工作? Transformer 为何有用? 常见问题解答:机器学习中的 Transformer 在技术领域,突破通常来自于修复损坏的东西。制造第一架飞机的人研究过鸟类。莱特兄弟观察了秃鹫如何在气流中保持平衡,意识到稳定性比动力更重要。…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组
WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在GOG或Epic Games Store购买了游戏࿰…...