UP-VLA:具身智体的统一理解与预测模型
25年1月来自清华大学和上海姚期智研究院的论文“UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent”。
视觉-语言-动作 (VLA) 模型的最新进展,利用预训练的视觉语言模型 (VLM) 来提高泛化能力。VLM 通常经过视觉语言理解任务的预训练,提供丰富的语义知识和推理能力。然而,先前的研究表明,VLM 通常专注于高级语义内容而忽略低级特征,从而限制了它们捕获详细空间信息和理解物理动态的能力。这些方面对于机器人控制任务至关重要,但在现有的预训练范式中仍未得到充分探索。本文研究 VLA 的训练范式,并介绍 UP-VLA,一种统一的 VLA 模型训练,具有多模态理解和未来预测目标,可增强高级语义理解和低级空间理解。
构建能够在开放环境中解决多项任务的视觉-语言-动作 (VLA) 模型 (Brohan,2023;Li,2023b) 已成为机器人研究的重点。VLA 模型的一种有前途的方法,涉及在机器人动作数据集上微调大规模预训练的视觉语言模型 (VLM) (Li,2023a;Wang,2022;Dai,2024;Driess,2023),并结合适当的动作建模组件 (Jang,2022;Li,2023b;Wu,2023;Zhang,2024;Kim,2024;Zheng,2024b)。这种方法使 VLA 模型能够继承强大的 VLM 中编码的语义知识和推理能力,从而增强未知环境中的决策能力。
然而,之前的研究已经发现 VLM 的某些弱点,特别是在捕获低级信息和理解物理动态方面(Zheng,2024a;Chen,2024a)。Zheng(2024a)强调,如果没有额外的训练,VLM 在低级视觉任务中表现较弱。Chen(2024a);Wen(2024)指出,预训练的 VLM 缺乏空间理解,无法捕捉距离和大小差异等低级细节。此外,研究(Balazadeh,2024;Ghaffari & Krishnaswamy;Li,2024)揭示 VLM 在理解物理动态方面的能力面临着重大挑战。这些限制主要归因于 VLM 的预训练范式(Wen,2024;Chen,2024a),该范式优先考虑多模态理解任务,例如视觉问答 (VQA),这些任务可以增强语义推理,但可能会忽略对具体决策任务至关重要的低级细节。虽然当前预训练方法提供的泛化优势是可取的,但它们提出一个重要的问题:是否可以开发出更好的训练流程来结合两全其美的优势,既保留语义理解,又强调对控制至关重要的低级特征?
用于通用机器人策略的 VLA 模型。最近的研究探索 VLM(Li,2023a;Wang,2022;Dai,2024;Driess,2023;Wang,2023)在机器人技术中的应用,利用其对语言指令和视觉场景的强大理解。一个值得注意的例子是 RT-2(Brohan,2023),它直接利用 VLM 自回归生成离散动作token,展示 VLA 方法的语义基础能力。最近的研究旨在增强 VLA 模型,使其具有更好的泛化性能 (Kim et al., 2024; O’Neill et al., 2023)、跨实体控制能力 (Black et al., 2024) 和更高的推理效率 (Zhang et al., 2024)。之前的研究 3D-VLA (Zhen et al., 2024) 也探索用于多模态理解和生成的协同训练,但侧重于引入 3d 信息,并使用单独的扩散模型进行生成。
机器人的视觉预训练方法。利用预训练的视觉模型进行机器人感知,已成为机器人控制的一个重要研究领域。早期的研究(Brohan,2022;Jang,2022)采用预训练的视觉编码器,如 ViT(Dosovitskiy,2020)和 EfficientNet(Tan & Le,2019)来编码视觉观察。最近,许多研究结合生成模型(Ho,2020;Blattmann,2023),通过未来帧预测(Guo,2024)和视频生成(Du,2024)来训练策略。例如,SuSIE(Black,2023)通过预测关键帧来学习机器人动作,而 GR-1(Wu,2023)则通过视频生成直接预训练策略。 PAD(Guo,2024)采用扩散模型同时预测未来图像和多步骤动作。IGOR(Chen,2024b)使用压缩视觉变化的潜动作作为低级动作的中间目标。这些研究强调,视觉预测任务可以有利于模型对未见过的场景的视觉泛化。
本文提出一个 UP-VLA 模型,如图所示:其通过多模态理解目标和未来预测目标进行预训练,更好地捕捉高级语义信息和低级空间细节,增强具身决策任务。

语言条件下的操作问题,被认为是在由指定特定任务的自由形式语言指令 l 和初始观察 o_1 建模环境下的决策序列。为了演示 D = {τ_1,τ_2,···,τ_n},其中每帧 τ_i = {(o_t,a_t)} 包含视觉观察 o 和动作 a。视觉-语言-动作 (VLA) 模型通常通过最小化 aˆ ∼ π_θ (o, l) 之间的误差,来训练 VLM π_θ 作为机器人动作策略。利用 VLM 的多模态理解能力,VLA 在任务之间具有更好的泛化能力,尤其是增强了对未见过目标的语义理解,并提高了理解或推理复杂自然语言指令的能力。
按照 SeeD-X(Ge,2024)和 Showo(Xie,2024)等方法,用离散图像编码器来处理图像生成任务的编码和解码,同时使用连续视觉编码器来处理多模态理解和推理任务。在训练期间,LLM 输入会根据任务类型给出提示。
这里目标是为 VLA 开发更好的训练方案。如图所示:UP-VLA、基于 VLM 的 VLA 模型和基于预测模型之间的比较。注:右下角的图表展示模拟和现实环境中多个任务的性能,从每种方法中选择最佳的模型。

主干
如图所示,用 Phi-1.5 (Li et al., 2023c) 作为底层大语言模型。对于多模态理解任务,遵循标准 VLM 编码方法,通过 CLIP-ViT (Radford et al., 2021) 编码器将图像投射到语言嵌入空间中。然后将这些投影的图像特征与语言嵌入连接起来并输入到大语言模型中。对于图像预测任务,用 VQ-GAN (Esser et al., 2021) 将当前观察的图像编码为离散tokens。不使用噪声预测或掩码重建,而是直接预测在输出token相应位置上的未来图像 token,这鼓励模型关注当前帧中的视觉信息并预测以语言为条件的未来变化。

连接视觉预测和多模态理解
为了使 LLM 同时具备视觉预测和多模态理解能力,在训练过程中结合来自机器人数据和图像文本对的未来预测任务。这两类任务可以编码成统一的格式,以便通过 LLM 主干网混合和并行处理。因此,扩展一下多任务方法。
多模态理解。给定一个成对的图像文本问答集 (I,L),通过连续编码器和连接层 E_1 将图像编码到语言嵌入空间中,得到 u = {u_i} = E_1(I)。这些嵌入与文本嵌入 l = {l_i} 连接起来形成多模态输入。为了生成一个可以在理解语言的同时关注图像的文本序列,修改因果注意机制,以便图像token可以互相关注,如图(a)所示。最后,用自回归的方式预测下一个语言token。这个任务可以简要描述为 Lˆ = π_θ^MMU (I, L)。
未来视觉预测。对于图像预测,给定时间 t 的图像和指令对 (O_t , L),用离散编码器 E_2 对当前的视觉观察进行编码:v_t = {v_i } = E_2 (O_t )。与多模态理解任务不同,视觉预测的目标,是通过关注指令提示来编码未来的视觉观察。因此,如图(b)所示,将图像token放在语言token之后,使图像能够关注所有输入信息。同时,引入一个特殊 token PRE 来表示这个新任务。我们不使用下一个 token 预测,而是在图像 token 的相同位置对未来的图像 token 进行建模,这样任务描述为ˆO_t+∆t = π_θ^PRE(O_t, L)。

通过联合的预测和理解,增强动作学习
虽然先前的 VLA 方法利用预训练 VLM 的多模态理解知识,但它未能利用丰富的视觉信息和物理动态。
为了解决这一限制,提出一种联合预测和理解行动学习机制。将动作输出与图像预测任务相结合。给定当前的观察-指令对 (O_t, L),模型预测未来的观察和每个时间步的动作序列:(Oˆ_t+∆t, Aˆ_t:t+∆t)=π_θ^PRE(O_t, L),其中 Aˆ对应于动作token位置的最后一层特征。
此外,如上图© 所示,用模型本身生成的场景描述扩展语言指令输入。观测 Ot′ 经过连续视觉编码器 E_1 = MLP(VIT) 处理后,被映射到语言嵌入空间 E_1(O_t′) 中,可直接用作语言token。最后一个组件 π_θ^MMU (O_t, L_prompt) 是当前场景的生成描述,其中 L_prompt 是特定提示,例如“描述此图像”。
最后,通过联合预测生成动作: ( Oˆ_t+∆t, Aˆ_t:t+∆t ) = π_θ^PRE (O_t, L′ )。用一个小型策略头来输出低级动作,其由一个 MAP 模块(单层注意模块)和一个线性层组成:aˆ_t:t+∆t = MLP(MAP(Aˆ_t:t+∆t))。
训练策略
用 Show-o (Xie et al., 2024) 初始化 UP-VLA 的主干。在训练期间,对 LLM 的参数进行全面微调并冻结所有编码器。训练过程可分为两个阶段。在第一阶段,目标是赋予 VLM 视觉预测和多模态理解能力。在第二阶段,专注于使用机器人数据学习动作。对不同的任务应用不同的采样率。
预测和理解预训练阶段。将两个域的训练数据混合在一起:一部分来自 BridgeData(Walke,2023),其中包括 25k 个机械臂演示。这些数据用于未来预测。另一部分来自 LLava-tuning-665k(Liu,2024),其中包括 665k 个图像-文本对,用于增强高级理解能力。
使用动作调整阶段进行预测。该模型在下游具体化任务上进行微调。用联合预测-和-理解的动作学习方法训练 UP-VLA。继续与图像-文本对一起训练,以保持多模态理解能力。
UP-VLA 方法涉及三个建模目标:用于多模态理解的语言建模、用于视觉预测的图像建模和用于具身任务的动作建模。
用于多模态理解的语言建模。给定 M 个视觉token u = {u_i} 和 N 个文本token l = {l_i},用交叉熵损失最大化下一个token似然。
用于视觉预测的图像建模。对于未来的图像预测任务,给定 M 个当前图像tokens v_t = {v_i} 和指令tokens l = {l_i},用交叉熵来预测未来的图像token。
具身任务的动作建模。最小化预测相对位置 aˆ_pos 与真实动作 a_pos 之间的均方误差 (MSE)。末端执行器的离散状态 a_end 通过二元交叉熵损失 (BCE) 进行优化。
最后将这三个损失项组合在一起为最终损失。
对模拟评估,用 CALVIN(Mees,2022),一个开源基准,用于学习长时间语言条件任务。如图(a)所示,CALVIN 环境包含 4 个不同的场景,表示为 ABCD。在 ABCD-D 和 ABC-D 设置上评估 UP-VLA。
现实世界实验涉及 Franka-Emika Panda 机器人上的多个桌面操作任务,包括拾取和放置、布线、按下按钮和打开抽屉。具体来说,收集 6 项技能的 2000 多个演示。如图(b)所示,在简单场景中训练 UP-VLA,同时在更复杂的设置上对其进行测试。在桌子上放置几个见过和未见过的目标来引入干扰,并测试模型是否可以抓住全新的目标,以验证其语义基础能力。同时,评估模型执行更细粒度任务的能力,例如布线、抓取较小的未见过的块或拿起笔。

相关文章:
UP-VLA:具身智体的统一理解与预测模型
25年1月来自清华大学和上海姚期智研究院的论文“UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent”。 视觉-语言-动作 (VLA) 模型的最新进展,利用预训练的视觉语言模型 (VLM) 来提高泛化能力。VLM 通常经过视觉语言理解任务的预训练&…...

Unity 基于状态机的逻辑控制详解
状态机是游戏开发中常用的逻辑控制方法,它可以将复杂的逻辑分解成多个独立的状态,并通过状态转移来控制逻辑的执行流程。本文将详细介绍如何在 Unity 中基于状态机实现逻辑控制,并提供技术详解和代码实现。 一、状态机简介 1.1 基本概念 状…...

傅里叶单像素成像技术研究进展
摘要:计算光学成像,通过光学系统和信号处理的有机结合与联合优化实现特定成像特性的成像系统,摆脱了传统成像系统的限制,为光学成像技术添加了浓墨重彩的一笔,并逐步向简单化与智能化的方向发展。单像素成像(Single-Pi…...

IDEA接入DeepSeek
IDEA 目前有多个途径可以接入deepseek,比如CodeGPT或者Continue,这里借助CodeGPT插件接入,CodeGPT目前用的人最多,相对更稳定 一、安装 1.安装CodeGPT idea插件市场找到CodeGPT并安装 2.创建API Key 进入deepseek官网…...

前端如何判断浏览器 AdBlock/AdBlock Plus(最新版)广告屏蔽插件已开启拦截
2个月前AdBlock/AdBlock Plus疑似升级了一次 因为自己主要负责面对海外的用户项目,发现以前的检测AdBlock/AdBlock Plus开启状态方法已失效了,于是专门研究了一下。并尝试了很多方法。 已失效的老方法 // 定义一个检测 AdBlock 的函数 function chec…...

macOS 上部署 RAGFlow
在 macOS 上从源码部署 RAGFlow-0.14.1:详细指南 一、引言 RAGFlow 作为一款强大的工具,在人工智能领域应用广泛。本文将详细介绍如何在 macOS 系统上从源码部署 RAGFlow 0.14.1 版本,无论是开发人员进行项目实践,还是技术爱好者…...

如何在Kickstart自动化安装完成后ISO内拷贝文件到新系统或者执行命令
如何在Kickstart自动化安装完成后ISO内拷贝文件到新系统或者执行命令 需求 在自动化安装操作系统完成后,需要对操作系统进行配置需要拷贝一些文件到新的操作系统中需要运行一些脚本 问题分析 Linux安装操作系统时,实际上是将ISO镜像文件中的操作系统…...

在服务器部署JVM后,如何评估JVM的工作能力,比如吞吐量
在服务器部署JVM后,评估其工作能力(如吞吐量)可以通过以下步骤进行: 1. 选择合适的基准测试工具 JMH (Java Microbenchmark Harness):适合微基准测试,测量特定代码片段的性能。Apache JMeter:…...

攻防世界32 very_easy_sql【SSRF/SQL时间盲注】
不太会,以后慢慢看 被骗了,看见very_easy就点进来了,结果所有sql能试的全试了一点用都没有 打开源代码发现有个use.php 好家伙,这是真的在考sql吗...... 制作gopher协议的脚本: import urllib.parsehost "12…...

STM32G474--Whetstone程序移植(双精度)笔记
1 获取Whetstone程序 Whetstone程序,我用github被墙了,所以用了KK的方式。 获取的程序目录如上所示。 2 新建STM32工程 配置如上,生成工程即可。 3 在生成的工程中添加并修改Whetstone程序 3.1 实现串口打印功能 在生成的usart.c文件中…...

【DeepSeek × Postman】请求回复
新建一个集合 在 Postman 中创建一个测试集合 DeepSeek API Test,并创建一个关联的测试环境 DeepSeek API Env,同时定义两个变量 base_url 和 api_key 的步骤如下: 1. 创建测试集合 DeepSeek API Test 打开 Postman。点击左侧导航栏中的 Co…...

开源身份和访问管理方案之keycloak(一)快速入门
文章目录 什么是IAM什么是keycloakKeycloak 的功能 核心概念client管理 OpenID Connect 客户端 Client Scoperealm roleAssigning role mappings分配角色映射Using default roles使用默认角色Role scope mappings角色范围映射 UsersGroupssessionsEventsKeycloak Policy创建策略…...

基于PaddleOCR的图像文字识别与程序打包方法
目录 一、基本介绍 二、程序实现 1)环境配置 2)代码实现 3)程序运行结果 三、程序打包 1)使用pyinstaller打包程序 2)添加依赖和模型数据 四、需要注意的问题 五、总结 一、基本介绍 本文主要介绍利用现有开源…...

单片机上SPI和IIC的区别
SPI(Serial Peripheral Interface)和IC(Inter-Integrated Circuit)是两种常用的嵌入式外设通信协议,它们各有优缺点,适用于不同的场景。以下是它们的详细对比: — 1. 基本概念 SPI࿰…...
)
Python 字典(一个简单的字典)
在本章中,你将学习能够将相关信息关联起来的Python字典。你将学习如何访问和修改字典中的信息。鉴于字典可存储的信息量几乎不受限制,因此我们会演示如何遍 历字典中的数据。另外,你还将学习存储字典的列表、存储列表的字典和存储字典的字典。…...

一个简单的Windows TCP服务器实现
初始化 WSADATA wsaData; SOCKET serverSocket, clientSocket; struct sockaddr_in serverAddr { 0x00 }; struct sockaddr_in clientAddr { 0x00 }; int clientAddrLen sizeof(clientAddr);if (WSAStartup(MAKEWORD(2, 2), &wsaData) ! 0) {printf("WSAStartup f…...

Node.js笔记入门篇
黑马程序员视频地址: Node.js与Webpack-01.Node.js入门 基本认识 概念 定义:Node.js 是一个免费、开源、跨平台的 JavaScript 运行时环境, 它让开发人员能够创建服务器 Web 应用、命令行工具和脚本 作用:使用Node.js 编写服务器端程序 ✓ …...

EX_25/2/10
epoll实现多路客户端之间的登录注册及消息和文件传输 服务器部分 #include <stdio.h> #include <string.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include…...

python视频爬虫
文章目录 爬虫的基本步骤一些工具模拟浏览器并监听文件视频爬取易错点一个代码示例参考 爬虫的基本步骤 1.抓包分析,利用浏览器的开发者工具 2.发送请求 3.获取数据 4.解析数据 5.保存数据 一些工具 requests, 用于发送请求,可以通过get,p…...
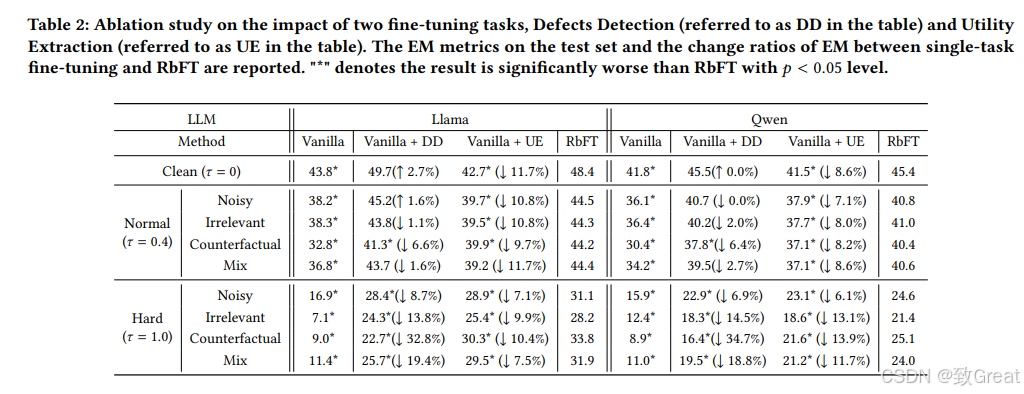
RbFT:针对RAG中检索缺陷的鲁棒性微调
今天给大家分享一篇最新的RAG论文: 论文题目:Enhancing Retrieval-Augmented Generation: A Study of Best Practices 论文链接:https://arxiv.org/pdf/2501.18365 论文代码:https://github.com/StibiumT16/Robust-Fine-tuning 研…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

Windows 11终极优化指南:一键清理系统,释放51%性能潜力
Windows 11终极优化指南:一键清理系统,释放51%性能潜力 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to decl…...

对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异 在将应用从直接调用单一厂商的模型API迁移到Taotoken平台后,…...

音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧
音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://g…...