深度学习R4周:LSTM-火灾温度预测
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
任务:
数据集中提供了火灾温度(Tem1)、一氧化碳浓度(CO 1)烟雾浓度(Soot 1)。随着时间变化数据,需要根据这些数据对未来某一时刻的火灾温度做出预测。
要求:
1.了解LSTM是什么,并使用其构建一个完整的程序
2.R2达到0.83
拔高:
使用第1-8个时刻的数据预测第9-10个时刻的温度数据
一、理论知识基础
1.LSTM原理
LSTM---RNN进阶版
如果RNN的最大限度是理解一句话,则LSTM的最大限度是理解一段话。
具体:
LSTM,长短期记忆网络(Long Short Term Memory networks),一种特有的RNN,能够学习到长期依赖关系。
所有的循环神经网络都有着重复的神经网络模块形成链的形式。在普通的RNN中、重复模块结构非常简单,其结构如下:
 LSTM避免了长期以来的问题、可以记住长期信息! LSTM内部有较为复杂的结构,能通过门控状态来选择调整传输的信息,需要长时间记忆的信息,忘记不重要的信息。
LSTM避免了长期以来的问题、可以记住长期信息! LSTM内部有较为复杂的结构,能通过门控状态来选择调整传输的信息,需要长时间记忆的信息,忘记不重要的信息。

2.LSTM的数据处理流程
将时序数据(LSTM输入数据)以可视化形式呈现。



根据输入的数据结构、预测输出、程序可以分为以下六类:

3.代码实现
1.前期准备
1.1导入数据
import torch.nn.functional as F
import numpy as np
import pandas as pd
import torch
from torch import nn
数据:训练营提供
data = pd.read_csv('/PythonProject/woodpine2.csv')print(data)结果输出:

因为过年,台式机不在身边,尝试在线代码平台。
问题:Module Not FoundError:No module named ‘torch’
这个在线平台与平常学习环境很类似,比较好上手,但还没有找到如何安装torch的正确方法。

显示已经装好torch,但实际上没有办法继续使用,还在寻找更合适的方法。
1.2数据集可视化
import matplotlib.pyplot as plt
import seaborn as snsplt.rcParams['savefig.dpi'] = 500 #图片像素
plt.rcParams['figure.dpi'] = 500 #分辨率fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(14, 3))sns.lineplot(data=data["Tem1"], ax=ax[0])
sns.lineplot(data=data["CO 1"], ax=ax[1])
sns.lineplot(data=data["Soot 1"], ax=ax[2])
plt.show()
结果输出:

dataFrame = data.iloc[:,1:]
print(dataFrame)
2.构建数据集
2.1数据集预处理
from sklearn.preprocessing import MinMaxScaler dataFrame = data.iloc[:,1:].copy()
sc = MinMaxScaler(feature_range=(0, 1)) #将数据归一化,范围是0到1for i in ['CO 1', 'Soot 1', 'Tem1']:dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1, 1))print(dataFrame.shape)
2.2设置x、y
width_X = 8
width_y = 1X = []
y = []in_start = 0for _, _ in data.iterrows():in_end = in_start + width_Xout_end = in_end + width_yif out_end < len(dataFrame):X_ = np.array(dataFrame.iloc[in_start:in_end , ])y_ = np.array(dataFrame.iloc[in_end :out_end, 0])X.append(X_)y.append(y_)in_start += 1X = np.array(X)
y = np.array(y).reshape(-1,1,1)print(X.shape, y.shape)
结果输出:
2.3划分数据集
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch.float32)X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch.float32)print(X_train.shape, y_train.shape)
结果输出:
from torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=64, shuffle=False)test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=64, shuffle=False)
3.模型训练
3.1构建LSTM模型
# 构建模型
class model_lstm(nn.Module): classmodel_lstm(classmodel_lstm): def __init__(self): super(model_lstm, self).__init__() self.lstm0 = nn.LSTM(input_size=3 ,hidden_size=320, num_layers=1, batch_first=True) self.lstm1 = nn.LSTM(input_size=320 ,hidden_size=320,num_layers=1, batch_first=True) self.fc0 = nn.Linear(320, 1) def forward(self, x): Defforward(self,x): out, hidden1 = self.lstm0(x) out, _ = self.lstm1(out, hidden1) out = self.fc0(out) return out[:, -1:, :] #取2个预测值,否则经过lstm会得到8*2个预测 model = model_lstm()
print(model model模型)
修改后得到
model(torch.rand(30,8,3)).shape
3.2定义训练/测试函数
# 定义训练函数
import copy
def train(train_dl, model, loss_fn, opt, lr_scheduler=None):size = len(train_dl.dataset) num_batches = len(train_dl) train_loss = 0 # 初始化训练损失和正确率for x, y in train_dl: x, y = x.to(device), y.to(device)# 计算预测误差pred = model(x) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距# 反向传播opt.zero_grad() # grad属性归零loss.backward() # 反向传播opt.step() # 每一步自动更新# 记录losstrain_loss += loss.item()if lr_scheduler is not None:lr_scheduler.step()print("learning rate = {:.5f}".format(opt.param_groups[0]['lr']), end=" ")train_loss /= num_batchesreturn train_loss
# 定义测试函数
def test (dataloader, model, loss_fn): size = len(dataloader.dataset) # 测试集的大小 num_batches = len(dataloader) # 批次数目 test_loss = 0 # 当不进行训练时,停止梯度更新,节省计算内存消耗 with torch.no_grad(): for x, y in dataloader: x, y = x.to(device), y.to(device) # 计算loss y_pred = model(x) loss = loss_fn(y_pred, y) test_loss += loss.item() test_loss /= num_batches return test_loss
3.3正式训练
#设置GPU训练
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
deviceX_test = X_test.to(device)#训练模型
model = model_lstm()
model = model.to(device)
loss_fn = nn.MSELoss() # 创建损失函数
learn_rate = 1e-1 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)
epochs = 50
train_loss = []
test_loss = []
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs, last_epoch=-1) for epoch in range(epochs):model.train()epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)model.eval()epoch_test_loss = test(test_dl, model, loss_fn)train_loss.append(epoch_train_loss)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_loss:{:.5f}, Test_loss:{:.5f}')print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))print("="*20, 'Done', "="*20)
让同学帮忙跑了代码,得到部分结果

4.模型评估
4.1 LOSS图
import matplotlib.pyplot as plt importmatplotlib.pyplotaspltplt.figure(figsize=(5, 3),dpi=120) 图(图大小=(5.3),dpi=120) plt.plot(train_loss , label='LSTM Training Loss') plt.plot(train_loss,Label ='LSTM训练损失')
plt.plot(test_loss, label='LSTM Validation Loss') plt.plot(test_loss,tag ="LSTM验证丢失") plt.title('Training and Validation Loss') plt.title(“培训和验证损失”)
plt.legend() legend()
plt.show() plt.show)搜索结果
4.2调用模型进行预测
# 测试集输入模型进行预测
# predicted_y_lstm = sc.inverse_transform(model(X_test).detach().numpy().reshape(-1,1))
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().cpu().numpy().reshape(-1,1))
y_test_1 = sc.inverse_transform(y_test.reshape(-1,1))
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]plt.figure(figsize=(5, 3),dpi=120)
# 画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000], color='red', label='real_temp')
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction')plt.title('Title')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
4.3R2值评估
from sklearn import metrics
"""
RMSE :均方根误差 -----> 对均方误差开方
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
"""
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1)**0.5
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)
二、总结
这周真的很混乱,身边没有台式机,在线平台也没有想象中好用,可能是我没有找到方式。LSTM学习掌握的很一般,明天就能有台式机。重新修改学习记录。文字知识已大致掌握,还需要代码加强。
LSTM的优点:
1.解决梯度消失问题:传统的RNN在处理长序列时容易出现梯度消失的问题,导致难以训练。
2.捕捉长期依赖关系:相比传统的RNN,LSTM有更好的记忆性能,可以在处理序列数据时保留较远的上下文信息。
3.可以学习到时序特征:LSTM具有对时间的敏感性,能够学习到时序数据中的模式和特征。这使得LSTM在时间序列预测、信号处理等任务中具有优势。
LSTM的缺点:
1.计算优化
2.模型简化
3.数据增强和迁移学习
这周真是失败的一次学习打卡。。。困难多多
相关文章:
深度学习R4周:LSTM-火灾温度预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 任务: 数据集中提供了火灾温度(Tem1)、一氧化碳浓度(CO 1)烟雾浓度(Soot 1)…...

探索Java中的集合类_特性与使用场景
1. 引言 1.1 Java集合框架概述 Java集合框架(Java Collections Framework, JCF)是Java中用于存储和操作一组对象的类和接口的统称。它提供了多种数据结构来满足不同的需求,如列表、集合、映射等。JCF的核心接口包括Collection、List、Set、Queue和Map,以及它们的各种实现…...

自动化遇到的问题记录(遇到问题就更)
总结回归下自己这边遇到的一些问题 “EOF错误”,获取不到csv里面的内容 跑多csv文件里的场景,部分场景的请求值为 1、检查csv文件里不能直接是[]开头的参数,把[]改到ms平台的请求参数里 2、有时可能是某个参数值缺了双引号的其中一边 met…...

【云安全】云原生- K8S kubeconfig 文件泄露
什么是 kubeconfig 文件? kubeconfig 文件是 Kubernetes 的配置文件,用于存储集群的访问凭证、API Server 的地址和认证信息,允许用户和 kubectl 等工具与 Kubernetes 集群进行交互。它通常包含多个集群的配置,支持通过上下文&am…...

【愚公系列】《Python网络爬虫从入门到精通》008-正则表达式基础
标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度…...
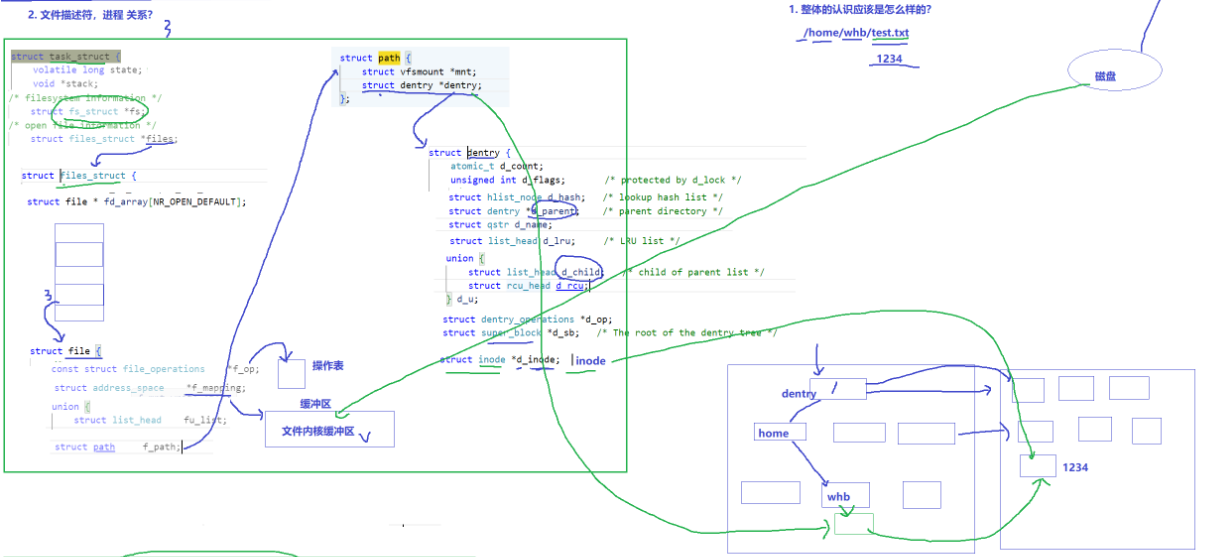
【Linux】Ext2文件系统、软硬链接
Ext2文件系统 一.理解硬件1.磁盘、服务器、机柜、机房2.磁盘的物理结构3.磁盘的存储结构4.磁盘的逻辑结构1.理解过程2.真实过程 5.CHS地址、LBA地址转换 二.引入文件系统1.引入"块"概念2.引入"分区"概念3.引入"inode"概念 三.Ext2文件系统1.宏观…...

ATF系统安全从入门到精通
CSDN学院课程连接:https://edu.csdn.net/course/detail/39573...

【算法专场】哈希表
目录 前言 哈希表 1. 两数之和 - 力扣(LeetCode) 算法分析 算法代码 面试题 01.02. 判定是否互为字符重排 编辑算法分析 算法代码 217. 存在重复元素 算法分析 算法代码 219. 存在重复元素 II 算法分析 算法代码 解法二 算法代码 算法…...

Beszel监控Docker安装
一、Beszel Hub安装 #Beszel Hub安装 mkdir -p ./beszel_data && \ docker run -d \--name beszel \--restartunless-stopped \-v ./beszel_data:/beszel_data \-p 8090:8090 \henrygd/beszel#创建账号 账号/密码:adminadmin.com/adminadmin.com 二、Besz…...
:从入门到精通的完整指南)
如何学习Elasticsearch(ES):从入门到精通的完整指南
如何学习Elasticsearch(ES):从入门到精通的完整指南 嘿,小伙伴们!如果你对大数据搜索和分析感兴趣,并且想要掌握Elasticsearch这一强大的分布式搜索引擎,那么你来对地方了!本文将为…...

【mybatis】基本操作:详解Spring通过注解和XML的方式来操作mybatis
mybatis 的常用配置 配置数据库连接 #驱动类名称 spring.datasource.driver-class-namecom.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.urljdbc:mysql://127.0.0.1:3306/mybatis_test characterEncodingutf8&useSSLfalse #连接数据库的名 spring.datasourc…...

CSV格式和普通EXCEL格式文件的区别
CSV 文件(.csv) 普通的 Excel 文件(.xlsx 或 .xls) 主要体现在 文件格式、数据存储、功能支持 等方面: 文件格式 比较项CSV 文件 (.csv)Excel 文件 (.xlsx/.xls)文件类型纯文本文件二进制或 XML 格式数据分隔逗号(,)…...

使用 Vite + React 19 集成 Tailwind CSS 与 shadcn/ui 组件库完整指南
使用 Vite React 19 集成 Tailwind CSS 与 shadcn/ui 组件库完整指南 🌟 前言一、创建 React 19 项目二、集成 Tailwind CSS1️⃣ 安装依赖2️⃣ 配置 Vite 插件3️⃣ 引入 Tailwind4️⃣ 启动项目 三、配置路径别名1️⃣ 修改 TypeScript 配置2️⃣ 安装类型声明3…...

【java】基本数据类型和引用数据类型
在 Java 中,数据类型分为 基本数据类型 和 引用数据类型。它们的本质区别在于存储方式和操作方式。下面我会详细解释这两种数据类型,并用通俗易懂的语言帮助你理解。 1. 基本数据类型(Primitive Data Types) 基本数据类型是 Java…...

mybatis-lombok工具包介绍
Lombok是一个实用的]ava类库,能通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率。 使用前要加入Lombok依赖...

2. grafana插件安装并接入zabbix
一、在线安装 如果不指定安装位置,则默认安装位置为/var/lib/grafana/plugins 插件安装完成之后需要重启grafana 命令在上一篇讲到过 //查看相关帮助 [rootlocalhost ~]# grafana-cli plugins --help //从列举中的插件过滤zabbix插件 [rootlocalhost ~]# grafana…...

零基础学CocosCreator·第九季-网络游戏同步策略与ESC架构
课程里的版本好像是1.9,目前使用版本为3.8.3 开始~ 目录 状态同步帧同步帧同步客户端帧同步服务端ECS框架概念ECS的解释ECS的特点EntityComponentSystemWorld ECS实现逻辑帧&渲染帧 ECS框架使用帧同步&ECS 状态同步 一般游戏的同步策略有两种:…...

为什么配置Redis时候要序列化配置呢
序列化和反序列化?: 序列化:将对象转换为二进制数据,以便存储到Redis中。 反序列化:将Redis中的二进制数据转换回对象,以便在应用程序中使用。 1. 默认序列化器的问题 如果不配置序列化器,Re…...

使用爬虫获取1688商品分类:实战案例指南
在电商领域,获取商品分类信息对于市场分析、选品决策和竞争情报收集至关重要。1688作为国内领先的B2B电商平台,提供了丰富的商品分类数据。通过爬虫技术,我们可以高效地获取这些分类信息,为商业决策提供有力支持。 一、为什么选择…...

C#打印设计器
C# 打印设计器,功能强大却操作简单,小白也能快速上手! 主要功能: 支持多种设计元素: 文字、图片、图形、二维码、条形码等,满足您多样化的设计需求。 灵活排版,精准定位: 支持拖拽…...

桌面图标太多找不到文件?NoFences让你5分钟拥有整洁高效的工作空间
桌面图标太多找不到文件?NoFences让你5分钟拥有整洁高效的工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否经历过这样的场景:电脑桌面堆…...

3分钟掌握树状书签管理:Neat Bookmarks终极整理指南
3分钟掌握树状书签管理:Neat Bookmarks终极整理指南 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为浏览器中杂乱无章的书签而烦恼吗…...

如何高效配置ComfyUI-Manager:3个专业技巧让你事半功倍
如何高效配置ComfyUI-Manager:3个专业技巧让你事半功倍 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

使用Taotoken为Claude Code配置稳定API通道避免封号与Token不足
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken为Claude Code配置稳定API通道避免封号与Token不足 对于依赖Claude Code进行日常开发的工程师而言,一个稳…...

snip CLI代理:为AI编程助手智能过滤终端输出,节省90%以上令牌成本
1. 项目概述:snip,一个为AI编程助手节省60-90%上下文令牌的CLI代理 如果你和我一样,每天都在用Claude Code、Cursor或者GitHub Copilot这类AI编程助手,那你肯定也遇到过这个让人头疼的问题:每次让AI运行一个简单的 g…...

Verilog仿真验证入门:用HDLbits的Finding bugs练习巩固你的代码审查能力
Verilog仿真验证实战:用HDLbits代码审查训练验证工程师思维 在数字IC设计领域,写出能综合的RTL代码只是第一步,真正的挑战在于确保代码在各种边界条件下都能正确工作。许多初学者往往把注意力集中在功能实现上,却忽略了同样重要的…...

MindSpore分布式并行原理与实战
随着深度学习模型参数量与数据集规模呈指数级增长,单卡训练已无法满足效率与内存需求,分布式并行训练成为突破性能瓶颈的核心方案。MindSpore作为华为自研的全场景AI框架,内置完善的分布式并行能力,支持数据并行、半自动并行、自动…...

QKeyMapper:5个技巧让你在Windows上实现零重启的按键映射
QKeyMapper:5个技巧让你在Windows上实现零重启的按键映射 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠…...

3分钟搞定!让Windows拥有macOS同款优雅鼠标指针的完整指南 [特殊字符]️✨
3分钟搞定!让Windows拥有macOS同款优雅鼠标指针的完整指南 🖱️✨ 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.…...

EVOKORE-MCP:为AI助手打造开箱即用的200+技能聚合平台
1. 项目概述:一个为AI助手赋能的“技能超市”如果你最近在折腾Claude、Cursor这类AI助手,想让它们帮你写代码、分析数据或者处理文档时更“聪明”一点,那你可能已经听说过MCP(Model Context Protocol)了。简单来说&…...