如何设置Python爬虫的User-Agent?
在Python爬虫中设置User-Agent是模拟浏览器行为、避免被目标网站识别为爬虫的重要手段。User-Agent是一个HTTP请求头,用于标识客户端软件(通常是浏览器)的类型和版本信息。通过设置合适的User-Agent,可以提高爬虫的稳定性和成功率。
以下是几种常见的方法来设置Python爬虫中的User-Agent:
1. 使用requests库设置User-Agent
requests库是Python中最常用的HTTP请求库之一,它允许在发送请求时通过headers参数设置请求头,包括User-Agent。
示例代码:
import requests# 目标URL
url = "https://example.com"# 设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}# 发送GET请求
response = requests.get(url, headers=headers)# 检查响应状态
if response.status_code == 200:print("请求成功")print(response.text)
else:print(f"请求失败,状态码: {response.status_code}")2. 使用BeautifulSoup和requests设置User-Agent
如果你使用BeautifulSoup来解析HTML内容,同样需要通过requests库发送请求,并设置User-Agent。
示例代码:
import requests
from bs4 import BeautifulSoup# 目标URL
url = "https://example.com"# 设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}# 发送GET请求
response = requests.get(url, headers=headers)# 检查响应状态
if response.status_code == 200:# 解析HTML内容soup = BeautifulSoup(response.text, 'html.parser')print(soup.prettify())
else:print(f"请求失败,状态码: {response.status_code}")3. 使用Scrapy框架设置User-Agent
如果你使用Scrapy框架来构建爬虫,可以在settings.py文件中全局设置User-Agent,或者在每个请求中动态设置。
全局设置User-Agent(在settings.py中):
# settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'动态设置User-Agent(在爬虫中):
import scrapyclass ExampleSpider(scrapy.Spider):name = "example"start_urls = ["https://example.com"]def start_requests(self):for url in self.start_urls:yield scrapy.Request(url=url, callback=self.parse, headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"})def parse(self, response):# 解析响应内容self.logger.info("成功获取页面")4. 使用随机User-Agent
为了避免被目标网站识别出规律性请求,可以使用随机的User-Agent。可以通过fake_useragent库生成随机的User-Agent。
安装fake_useragent库:
pip install fake_useragent示例代码:
from fake_useragent import UserAgent
import requests# 创建UserAgent对象
ua = UserAgent()# 目标URL
url = "https://example.com"# 设置随机User-Agent
headers = {"User-Agent": ua.random
}# 发送GET请求
response = requests.get(url, headers=headers)# 检查响应状态
if response.status_code == 200:print("请求成功")print(response.text)
else:print(f"请求失败,状态码: {response.status_code}")5. 注意事项
-
遵守法律法规:在进行爬虫操作时,必须严格遵守相关法律法规,尊重网站的
robots.txt文件规定。 -
合理设置请求频率:避免过高的请求频率导致对方服务器压力过大,甚至被封禁IP。
-
应对反爬机制:目标网站可能会采取一些反爬措施,如限制IP访问频率、识别爬虫特征等。可以通过使用动态代理、模拟正常用户行为等方式应对。
通过以上方法,你可以在Python爬虫中灵活地设置User-Agent,从而更好地模拟浏览器行为,避免被目标网站识别为爬虫。希望这些信息对你有所帮助!
相关文章:

如何设置Python爬虫的User-Agent?
在Python爬虫中设置User-Agent是模拟浏览器行为、避免被目标网站识别为爬虫的重要手段。User-Agent是一个HTTP请求头,用于标识客户端软件(通常是浏览器)的类型和版本信息。通过设置合适的User-Agent,可以提高爬虫的稳定性和成功率…...

深度学习框架探秘|TensorFlow:AI 世界的万能钥匙
在人工智能(AI)蓬勃发展的时代,各种强大的工具和框架如雨后春笋般涌现,而 TensorFlow 无疑是其中最耀眼的明星之一。它不仅被广泛应用于学术界的前沿研究,更是工业界实现 AI 落地的关键技术。今天,就让我们…...

C++:高度平衡二叉搜索树(AVLTree) [数据结构]
目录 一、AVL树 二、AVL树的理解 1.AVL树节点的定义 2.AVL树的插入 2.1更新平衡因子 3.AVL树的旋转 三、AVL的检查 四、完整代码实现 一、AVL树 AVL树是什么?我们对 map / multimap / set / multiset 进行了简单的介绍,可以发现,这几…...

建筑兔零基础自学python记录18|实战人脸识别项目——视频检测07
本次要学视频检测,我们先回顾一下图片的人脸检测建筑兔零基础自学python记录16|实战人脸识别项目——人脸检测05-CSDN博客 我们先把上文中代码复制出来,保留红框的部分。 然后我们来看一下源代码: import cv2 as cvdef face_detect_demo(…...

【MySQL数据库】Ubuntu下的mysql
目录 1,安装mysql数据库 2,mysql默认安装路径 3,my.cnf配置文件? 4,mysql运用的相关指令及说明 5,数据库、表的备份和恢复 mysql是一套给我们提供数据存取的,更加有利于管理数据的服务的网络程序。下…...
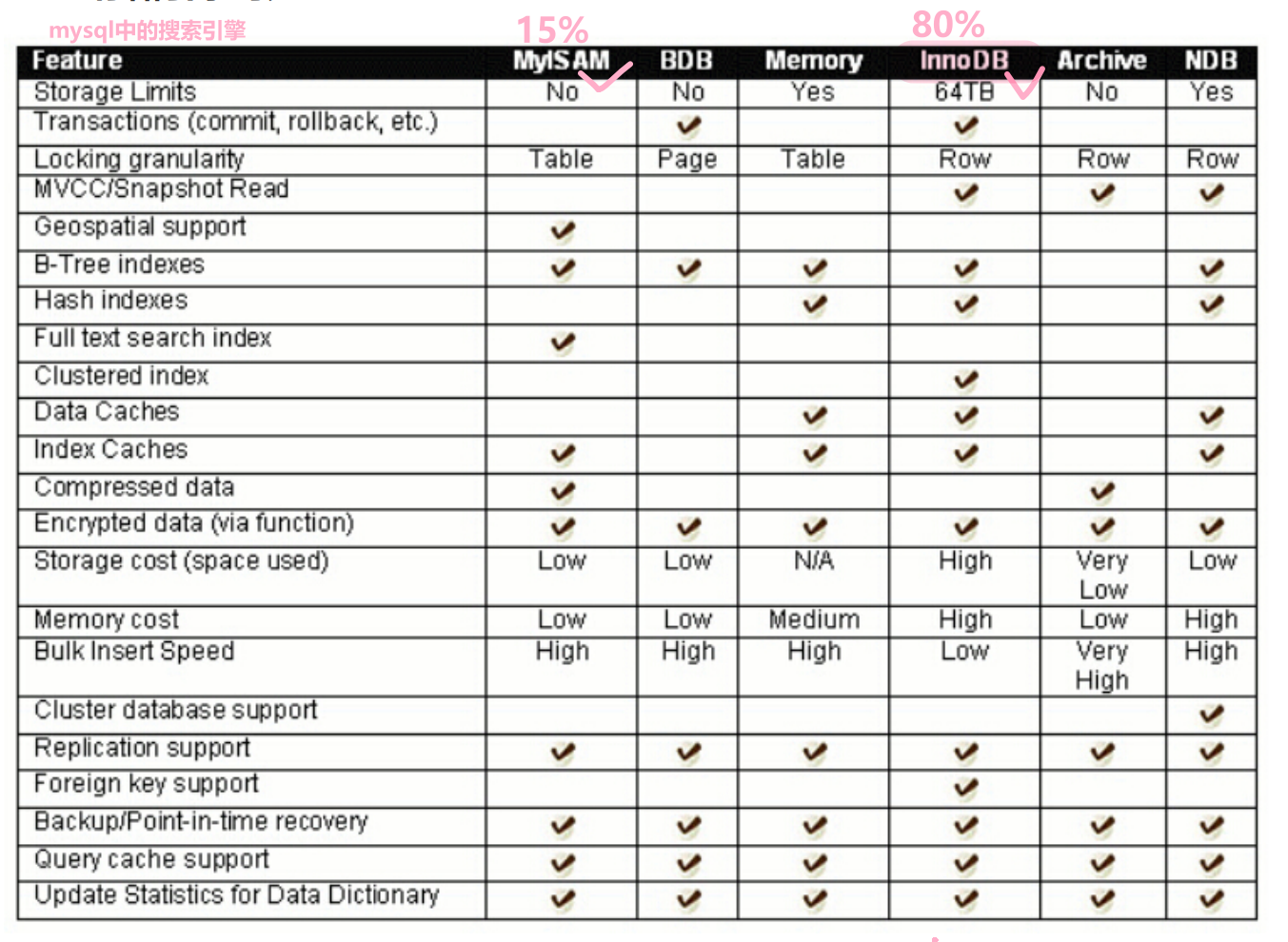
[MySQL#1] database概述 常见的操作指令 MySQL架构 存储引擎
#1024程序员节|征文# 目录 一. 数据库概念 0.连接服务器 1. 什么是数据库 口语中的数据库 为什么数据不直接以文件形式存储,而需要使用数据库呢? 总结 二. ??基础操作 三. 主流数据库 四. 基础知识 服务器,数据库&…...

1.从零开始学会Vue--{{基础指令}}
全新专栏带你快速掌握Vue2Vue3 1.插值表达式{{}} 插值表达式是一种Vue的模板语法 我们可以用插值表达式渲染出Vue提供的数据 1.作用:利用表达式进行插值,渲染到页面中 表达式:是可以被求值的代码,JS引擎会将其计算出一个结果 …...

VS2022中.Net Api + Vue 从创建到发布到IIS
VS2022中.Net Api Vue 从创建到发布到IIS 前言一、先决条件二、创建项目三、运行项目四、增加API五、发布到IIS六、设置Vue的发布 前言 最近从VS2019 升级到了VS2022,终于可以使用官方的.Net Vue 组合了,但是使用过程中还是有很多问题,这里记录一下. 一、先决条件 Visual …...

RFID技术在制造环节的应用与价值
在现代制造业中,信息化和智能化已经成为企业提升竞争力的重要手段。RFID技术因其非接触式、远距离和高效识别的特点,广泛应用于生产的多个环节。本文将详细解读生产过程中RFID的关键应用场景,并结合实际案例,展示其为制造业带来的…...

(前端基础)HTML(一)
前提 W3C:World Wide Web Consortium(万维网联盟) Web技术领域最权威和具有影响力的国际中立性技术标准机构 其中标准包括:机构化标准语言(HTML、XML) 表现标准语言(CSS) 行为标准…...

Linux文件管理:硬链接与软链接
文章目录 1. 硬链接的设计目的(1)节省存储空间(2)提高文件管理效率(3)数据持久性(4)文件系统的自然特性 2. 软链接的设计目的**(1)跨文件系统引用****&#x…...

pnpm, eslint, vue-router4, element-plus, pinia
利用 pnpm 创建 vue3 项目 pnpm 包管理器 - 创建项目 Eslint 配置代码风格(Eslint用于规范纠错,prettier用于美观) 在 设置 中配置保存时自动修复 提交前做代码检查 husky是一个 git hooks工具(git的钩子工具,可以在特定实际执行特…...

在软件产品从开发到上线过程中,不同阶段可能出现哪些问题,导致软件最终出现线上bug
在软件产品从开发到上线的全生命周期中,不同阶段都可能因流程漏洞、技术疏忽或人为因素导致线上问题。以下是各阶段常见问题及典型案例: 1. 需求分析与设计阶段 问题根源:业务逻辑不清晰或设计缺陷 典型问题: 需求文档模糊&#…...

Spring Boot中如何自定义Starter
文章目录 Spring Boot中如何自定义Starter概念和作用1. 概念介绍2. 作用和优势2.1 简化依赖管理2.2 提供开箱即用的自动配置2.3 标准化和模块化开发2.4 提高开发效率2.5 提供灵活的配置覆盖3. 应用场景创建核心依赖1. 确定核心依赖的作用2. 创建 starter-core 模块2.1 依赖管理…...

制作Ubuntu根文件
系列文章目录 Linux内核学习 Linux 知识(1) Linux 知识(2) WSL Ubuntu QEMU 虚拟机 Linux 调试视频 PCIe 与 USB 的补充知识 vscode 使用说明 树莓派 4B 指南 设备驱动畅想 Linux内核子系统 Linux 文件系统挂载 QEMU 通过网络实现…...

SpringBoot快速接入OpenAI大模型(JDK8)
使用AI4J快速接入OpenAI大模型 本博文给大家介绍一下如何使用AI4J快速接入OpenAI大模型,并且如何实现流式与非流式的输出,以及对函数调用的使用。 介绍 由于SpringAI需要使用JDK17和Spring Boot3,但是目前很多应用依旧使用的JDK8版本&…...
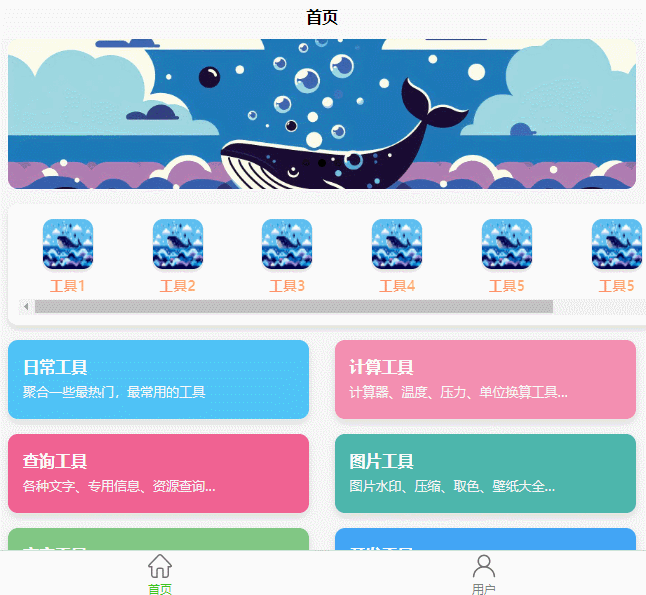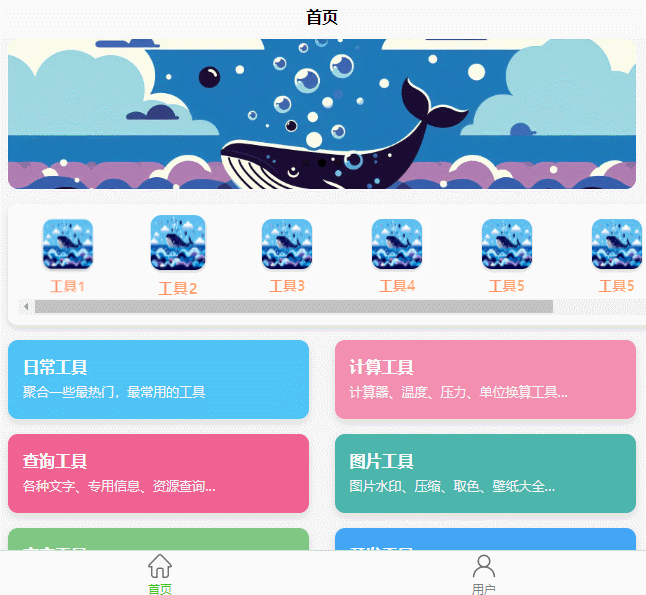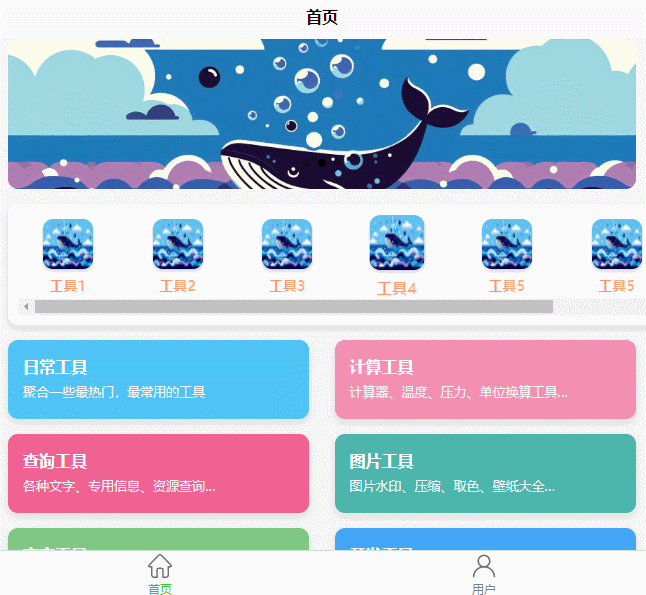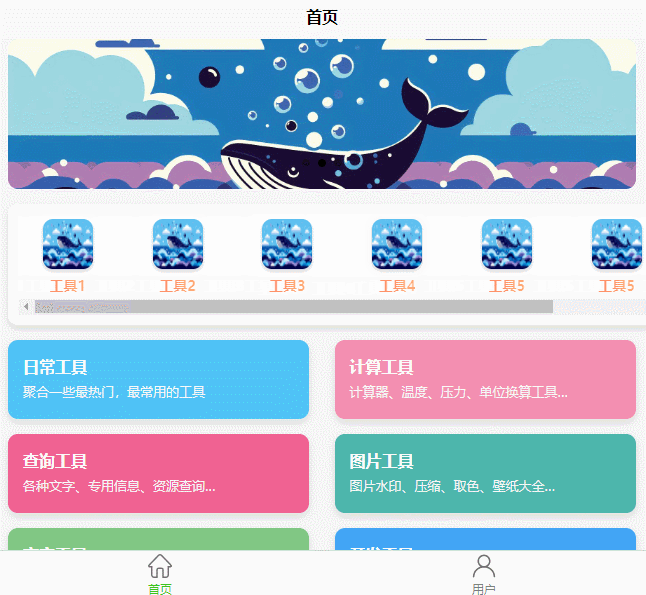
UniApp 中制作一个横向滚动工具栏
前言 最近在用 UniApp 开发项目时,需要一个横向滑动的工具栏。常见的工具栏一般都是竖着的,但横向滑动的工具栏不仅能展示更多内容,还能让界面看起来更加丰富。不过很多朋友可能会发现,如何让内容“横着”展示又不变形、能流畅滚…...

react中如何获取真实的dom
在 React 中,获取真实的 DOM 元素通常通过 ref 来实现。ref 是一个特殊的属性,用于引用组件或 DOM 元素的实例。你可以通过 ref 获取到组件的真实 DOM 元素或组件实例。 1. 函数组件中的 useRef 在函数组件中,获取 DOM 元素的引用需要使用 …...

5G与物联网的协同发展:打造智能城市的未来
引言 随着科技的不断进步,智能城市的概念已经不再是科幻小说中的幻想,它正在逐步走进我们的生活。而这背后的两大驱动力无疑是 5G和 物联网(IoT)。5G网络以其高速率、低延迟、大容量的优势,与物联网的强大连接能力相结…...

【Qt】实现定期清理程序日志
在现有Qt程序中实现可配置日志保存天数的代码示例,分为界面修改、配置存储和核心逻辑三部分: // 1. 在配置文件(如settings.h)中添加保存天数的配置项 class Settings { public:int logRetentionDays() const {return m_settings…...

AI驱动的认知行为疗法实践:用cbt-llm-kit构建结构化情绪管理工具
1. 项目概述:当AI助手成为你的认知行为疗法伙伴如果你和我一样,对AI助手的印象还停留在写代码、改文档或者生成一些营销文案,那么cbt-llm-kit这个项目可能会彻底改变你的看法。它本质上是一个“认知行为疗法工具包”,但别被这个专…...

Class D放大器原理与高效音频设计实践
1. Class D放大器基础:从原理到优势解析Class D放大器作为现代音频系统的核心组件,其工作原理与传统线性放大器有着本质区别。我第一次拆解汽车音响功放时,就被Class D那小巧的散热片震惊了——同样的输出功率下,AB类放大器需要巴…...

Universal x86 Tuning Utility技术架构深度解析:跨平台硬件调优实现原理与工程实践
Universal x86 Tuning Utility技术架构深度解析:跨平台硬件调优实现原理与工程实践 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuni…...

蓝桥杯单片机决赛避坑指南:从“高位熄灭”到“双键长按”的实战代码优化
蓝桥杯单片机决赛代码优化实战:从数码管显示到双键检测的进阶技巧 参加蓝桥杯单片机竞赛的同学们都知道,决赛环节往往会在基础功能上设置诸多"陷阱",考验选手对细节的掌控能力。本文将针对数码管高位熄灭、温度传感器小数处理、双键…...

视觉语言模型幻觉问题解析与优化实践
1. 视觉语言模型中的幻觉现象解析第一次在测试集上看到视觉语言模型把图片中的"黄色校车"描述成"红色消防车"时,我以为是标注错误。直到连续发现模型将"办公室场景"解读为"图书馆"、把"金毛犬"识别成"狮子&…...

Qwen3.5-4B-Claude-Opus部署教程:基于llama.cpp的GPU加速Web服务搭建详解
Qwen3.5-4B-Claude-Opus部署教程:基于llama.cpp的GPU加速Web服务搭建详解 1. 模型介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版…...

自动驾驶占据网络OCC精细化平衡之道 | 全网深度解析,体素优化+TPV降维+稀疏推理篇 | ICCV 2025 | 引入三维优化策略,兼顾精度、速度与算力,助力高阶自动驾驶量产落地,附工程代码
目录 一、技术背景:OCC占据网络的行业困境与精细化平衡刚需 二、OCC精细化平衡核心技术定义与设计理念 三、三大核心技术深度拆解(含工程化实现细节) 3.1 核心技术一:体素优化——动态分辨率+优先级排序,平衡精度与算力 3.1.1 动态分辨率体素划分(核心创新点) 3.1…...
共现网络图)
025年-2026年AI智能体学术论文发表国家(地区)共现网络图
✓中国、美国的节点大小显著大于其他国家,说明两国在 AI智能体领域的论文发表量、研究活跃度处于全球顶尖水平,是该领域的核心创新主体。 ✓中国的节点略大于美国,反映出 2025-2026年中国在该领域的研究产出规模已处于全球领先地位。 ✓两国均…...

产销严重脱节,生产过剩与缺货问题反复出现怎么办?——2026年基于实在Agent的智慧供应链深度重构方案
站在2026年的时间节点回看,制造业的数字化转型已从简单的“信息化”跃迁至“智能体化”。 然而,即便在AI技术高度普及的今天,许多企业依然深陷于产销严重脱节的泥潭: 一边是仓库中堆积如山的过期库存,导致资金链极度紧…...

抖音图片怎么无水印保存?2026 保存工具和方法实测对比指南
每当我们在抖音上看到喜欢的图片,总会想保存下来。但抖音默认保存的图片往往带着明显的水印,影响美观度。对于想要收藏素材、做内容创意参考,或者只是想干净地保存喜欢图片的人来说,无水印保存抖音图片就成了一个实际需求。2026 年…...