李沐--动手学深度学习 序列模型
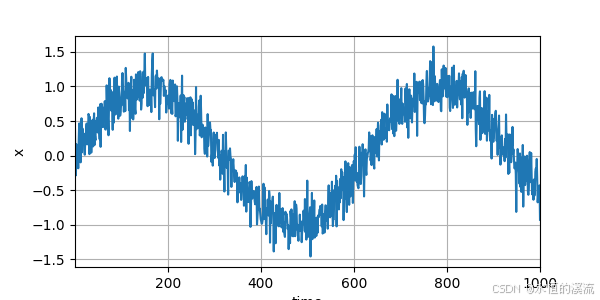
1.使用正弦函数和可加性噪声生成序列数据
import torch
from torch import nn
from d2l import torch as d2l#使用正弦函数和可加性噪声生成序列数据
T = 1000 #总共产生1000个点
time = torch.arange(1,T+1,dtype=torch.float32)
x = torch.sin(0.01*time) + torch.normal(0,0.2,(T,))
d2l.plot(time,[x],'time','x',xlim=[1,1000],figsize=(6,3))
d2l.plt.show()#使用正弦函数和可加性噪声生成序列数据
2.训练
#将这个序列转换为模型的模型的特征-标签对。
#仅使用前600个“特征-标签”对进行训练。
tau = 4
features = torch.zeros((T-tau,tau))
for i in range(tau):features[:,i] = x[i:T-tau+i]
labels = x[tau:].reshape((-1,1))batch_size,n_train = 16,600
#只有前n_train个样本用于训练
train_iter = d2l.load_array((features[:n_train],labels[:n_train]),batch_size,is_train=True)#使用一个相当简单的架构训练模型:一个拥有两个全连接层的多层感知机,ReLU激活函数和平方损失。#初始化网络权重的函数
def init_weight(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)#一个简单的多层感知机
def get_net():net = nn.Sequential(nn.Linear(4,10),nn.ReLU(),nn.Linear(10,1))net.apply(init_weight)return net#平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')#训练模型.与前面几节(如 3.3节)中的循环训练基本相同
def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr)for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, 'f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')net = get_net()
train(net, train_iter, loss, 5, 0.01)
d2l.plt.show()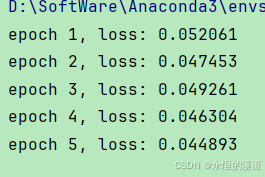
3.预测
(1)一步预测
#检查模型预测下一个时间步的能力, 也就是单步预测
onestep_preds = net(features)
d2l.plot([time,time[tau:]],[x.detach().numpy(),onestep_preds.detach().numpy()],'time','x',legend=['data','1-step preds'],xlim = [1,1000],figsize=(6,3))
d2l.plt.show()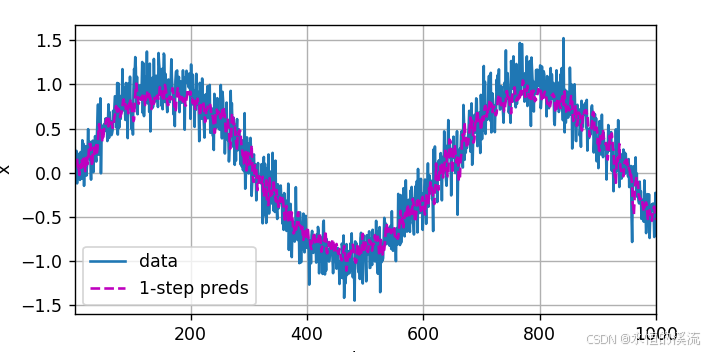
(2)K步预测
#K步预测
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau,T):multistep_preds[i] = net(multistep_preds[i-tau:i].reshape((1,-1)))
d2l.plot([time,time[tau:],time[n_train+tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train+tau:].detach().numpy()],'time','x',legend=['data','1-step preds','multistep preds'],xlim=[1,1000],figsize=(6,3))
d2l.plt.show()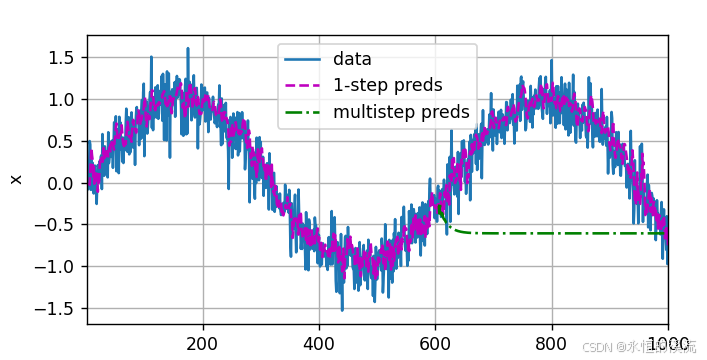
(3)基于k = 1,4,16,64,通过对整个序列预测的计算,更仔细地看一下k步预测的困难。
#基于k = 1,4,16,64,通过对整个序列预测的计算,更仔细地看一下k步预测的困难。
max_steps = 64features = torch.zeros((T-tau-max_steps+1,tau+max_steps))
#列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):features[:,i] = x[i:i+T-tau-max_steps+1]
# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau,tau+max_steps):features[:,i] = net(features[:,i-tau:i]).reshape(-1)steps = (1,4,16,64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],figsize=(6, 3))
d2l.plt.show()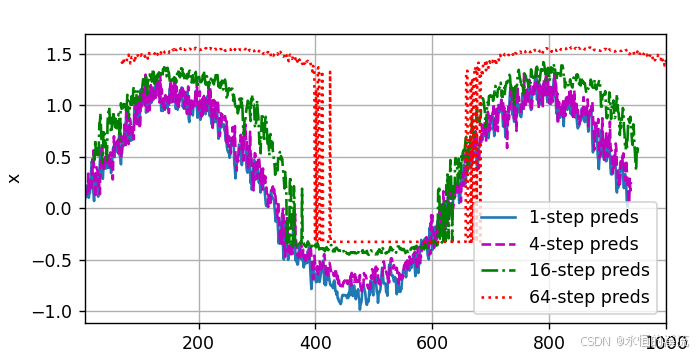
相关文章:
李沐--动手学深度学习 序列模型
1.使用正弦函数和可加性噪声生成序列数据 import torch from torch import nn from d2l import torch as d2l#使用正弦函数和可加性噪声生成序列数据 T 1000 #总共产生1000个点 time torch.arange(1,T1,dtypetorch.float32) x torch.sin(0.01*time) torch.normal(0,0.2,(…...
数据分析、商业智能、业务分析三者之间的关系
商业智能 (Business Intelligence, BI)、业务分析 (Business Analytics, BA) 和数据分析 (Data Analytics, DA) 三者都与数据密切相关,但在目标、方法和应用上存在差异。为了能够清晰地解释,下面将从定义入手,然后阐述它们之间的联系和区别。…...

【Spring+MyBatis】留言墙的实现
目录 1. 添加依赖 2. 配置数据库 2.1 创建数据库与数据表 2.2 创建与数据库对应的实体类 3. 后端代码 3.1 目录结构 3.2 MessageController类 3.3 MessageService类 3.4 MessageMapper接口 4. 前端代码 5. 单元测试 5.1 后端接口测试 5.2 使用前端页面测试 在Spri…...

让编程变成一种享受-明基RD320U显示器
引言 作为一名有着多年JAVA开发经验的从业者,在工作过程中,显示器的重要性不言而喻。它不仅是我们与代码交互的窗口,更是影响工作效率和体验的关键因素。在多年的编程生涯中,我遇到过各种各样的问题。比如,在进行代码…...
函数)
【嵌入式Linux应用开发基础】fork()函数
目录 一、fork 函数概述 1.1. 函数作用 1.2. 函数原型与头文件 1.3. 返回值 1.4. 核心特性 二、父子进程的区别与联系 2.1. 相同点 2.2. 不同点 三、典型应用场景 3.1. 多任务处理 3.2. 守护进程创建 3.3. 执行外部程序 3.4. 并行计算 四、fork 函数的关键注意事…...

2024 年 CSDN 博客之星年度评选:技术创作与影响力的碰撞(统计时间2025-02-17 11:06:06)
摘要:在技术的海洋里,每一位博主都像是一座独特的灯塔,用自己创作的光芒照亮他人前行的道路。2024 年 CSDN 博客之星年度评选活动,正是对这些灯塔的一次盛大检阅,让我们看到了众多优秀博主在技术创作领域的卓越表现以及…...

串的基本操作--数据结构
目录 一、串的基本概述 二、串的存储结构 2.1定义属性存储结构 串长有两种表示方法: 1、用一个额外的变量length来存放串的长度; 2、串值后面加一个不计入串长的结束标记字符“\0”,此时的串长为隐含值。 2.2堆的顺序存储结构 三、串的基本操…...

Unity 命令行设置运行在指定的显卡上
设置运行在指定的显卡上 -force-device-index...

Dest1ny漏洞库: 美团代付微信小程序系统任意文件读取漏洞
大家好,今天是Dest1ny漏洞库的专题!! 会时不时发送新的漏洞资讯!! 大家多多关注,多多点赞!!! 0x01 产品简介 美团代付微信小程序系统是美团点评旗下的一款基于微信小程…...

设计模式:状态模式
状态机有3个要素:状态,事件,动作。 假如一个对象有3个状态:S1、S2、S3。影响状态的事件有3个:E1、E2、E3。每个状态下收到对应事件的时候,对象的动作为AXY。那么该对象的状态机就可以用如下表格来表示。S1收到事件E1的…...

【故障处理】- 执行命令crsctl query crs xxx一直hang
【故障处理】- 执行命令crsctl query crs xxx一直hang 一、概述二、故障处理三、解决方法 一、概述 Oracle RAC环境中,遇到执行crsctl query crs xxx等相关命令不返回任何结果,一直hang在那里。系统下执行命令ps -ef |grep crsctl query crs softwarever…...

Zabbix——监控Nginx
背景 在项目中使用Nginx之后,有时候我们需要知道Nginx具体的工作情况,这时候就需要使用zabbix进行Nginx的相关监控 这边我们有两种方法 使用普通的http请求的方式获取基本信息如果使用了Nginx Plus,就可以通过Nginx Plus的接口获取更多的信…...

开源工具推荐--思维导图、流程图等绘制
1. 前言 在工作中,经常要用到各种不同的工具,随着系统的升级,有些工具也在不断更新升级。这里收集整理一些好用的开源工具推荐,遵循以下一些基本原则:开源免费,商业工具的有效平替,轻量级&…...

【论文笔记】Transformer^2: 自适应大型语言模型
Code repo: https://github.com/SakanaAI/self-adaptive-llms 摘要 自适应大型语言模型(LLMs)旨在解决传统微调方法的挑战,这些方法通常计算密集且难以处理多样化的任务。本文介绍了Transformer(Transformer-Squared)…...

FFmpeg源码:av_strlcpy函数分析
一、引言 在C/C编程中经常会用到strcpy这个字符串复制函数。strcpy是C/C中的一个标准函数,可以把含有\0结束符的字符串复制到另一个地址空间。但是strcpy不会检查目标数组dst的大小是否足以容纳源字符串src,如果目标数组太小,将会导致缓冲区…...

Unity Shader学习6:多盏平行光+点光源 ( 逐像素 ) 前向渲染 (Built-In)
0 、分析 在前向渲染中,对于逐像素光源来说,①ForwardBase中只计算一个平行光,其他的光都是在FowardAdd中计算的,所以为了能够渲染出其他的光照,需要在第二个Pass中再来一遍光照计算。 而有所区别的操作是࿰…...

docker批量pull/save/load/tag/push镜像shell脚本
目录 注意: 脚本内容 执行效果 注意: 以下脚本为shell脚本通过docker/nerdctl进行镜像独立打包镜像的相关操作脚本内仓库信息和镜像存取路径需自行更改需自行创建images.txt并填写值,并且与脚本位于同级目录下 [rootmaster01 sulibao]# l…...

五十天精通硬件设计第32天-S参数
系列文章传送门 50天精通硬件设计第一天-总体规划-CSDN博客 目录 1. S参数基础 2. S参数在信号完整性中的作用 3. 单端 vs. 差分S参数 4. S参数的关键特性 5. S参数的获取与使用 6. S参数分析中的常见问题 7. 实际案例:PCIe通道分析 8. 工具推荐 总结 信号完整性中…...

6.2.4 基本的数据模型
文章目录 基本的数据模型 基本的数据模型 基本的数据模型包含层次模型,网状模型和关系模型。 层次模型:使用树型结构表示数据间联系。记录间的联系用指针实现,简单高效。但是只能表示1:n的联系,且对插入、删除的限制多。网状模型…...

DeepSeek ,银行营销会被 AIGC 颠覆吗?
AI 让银行营销更智能,但更重要的是“懂客户” AI 在银行营销中的应用已经不仅仅局限于文案生成,而是渗透到了整个营销流程。 据悉,中国银行已经开始利用 AI 大模型构建智能营销助手系统,结合知识图谱和 AI 技术,实现…...
理论体系的深度解析:数学,检验,预测,证伪【这是对几篇核心基础论文的总结】)
关于OFIRM(本源场直觉共振模型)理论体系的深度解析:数学,检验,预测,证伪【这是对几篇核心基础论文的总结】
关于OFIRM(本源场直觉共振模型)理论体系的深度解析:数学,检验,预测,证伪Authors: Haiting Allen ChenAffiliations: Chen Xiao’er Creative Workshop, Independent Researcher, Guangzhou, China.Corres…...

Pantheon:本地AI智能体编排控制平面架构与实践
1. 项目概述:Pantheon,一个本地的AI智能体编排控制平面最近在折腾AI智能体(AI Agents)的本地化部署和协同工作,发现了一个挺有意思的项目——Pantheon。简单来说,它就像是你本地终端里的一个“智能体指挥中…...

RPG+ZeroRepo:自动化代码结构管理的工程实践
1. 项目背景与核心价值在软件工程领域,代码库的结构化管理一直是困扰开发团队的痛点问题。传统代码库往往随着业务增长逐渐演变成难以维护的"大泥球",而人工设计目录结构又高度依赖个人经验且效率低下。RPG(Repository Pattern Gen…...

Arm CoreLink MMU-700内存管理单元架构与优化实践
1. Arm CoreLink MMU-700内存管理单元架构解析在现代计算机体系结构中,内存管理单元(MMU)扮演着至关重要的角色。作为Arm最新一代系统级内存管理解决方案,CoreLink MMU-700通过创新的架构设计,在性能、可扩展性和安全性…...

VCS后仿真的完整流程与避坑指南:从网表、SDF到lib库的保姆级配置
VCS后仿真的完整流程与避坑指南:从网表、SDF到lib库的保姆级配置 第一次接触VCS后仿真时,面对后端同事扔过来的一堆文件——网表、SDF、lib库,还有各种.tfile和.cmd文件,相信很多新手工程师都会感到一头雾水。这些文件各自有什么作…...

深蓝词库转换:跨平台词库迁移神器,支持30+输入法格式
深蓝词库转换:跨平台词库迁移神器,支持30输入法格式 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 还在为更换设备或输入法时词库无法同步而…...

Sunshine游戏串流完全手册:三步搭建你的跨平台游戏服务器
Sunshine游戏串流完全手册:三步搭建你的跨平台游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否厌倦了被硬件束缚的游戏体验?想在客厅电视上…...

NVIDIA Nemotron Nano V2 VL边缘计算视觉语言模型解析
1. 项目概述NVIDIA Nemotron Nano V2 VL是英伟达最新推出的轻量级视觉语言模型,专为边缘计算和移动端部署优化。这个7B参数规模的模型在保持高性能的同时,通过创新的量化技术实现了惊人的推理效率提升。我在实际测试中发现,它在NVIDIA Jetson…...

自然语言生成中的并行解码策略:Margin Top-k与Entropy Top-k对比
1. 解码技术背景与核心挑战在自然语言生成任务中,解码策略的选择直接影响生成文本的质量和效率。传统自回归解码(Autoregressive Decoding)需要逐个token顺序生成,虽然质量稳定但速度受限。为提升解码效率,近年来并行解…...

如何快速生成逼真的书籍测试数据:Faker库的完整指南
如何快速生成逼真的书籍测试数据:Faker库的完整指南 【免费下载链接】faker Generate massive amounts of fake data in the browser and node.js 项目地址: https://gitcode.com/GitHub_Trending/faker/faker 在软件开发和测试过程中,获取大量逼…...