解锁豆瓣高清海报(三)从深度爬虫到URL构造,实现极速下载
脚本地址:
项目地址: Gazer
PosterBandit_v2.py
前瞻
之前的 PosterBandit.py 是按照深度爬虫的思路一步步进入海报界面来爬取, 是个值得学习的思路, 但缺点是它爬取慢, 仍然容易碰到豆瓣的 418 错误, 本文也会指出彻底解决旧版 418 错误的方法并提高爬取速度. 现在我将介绍优化版, 这个版本通过直接构造 URL 来实现获取海报原图, 准确识别、更快爬取. 本文会重点讲解动态 headers 及其应用于请求的必要性.
使用方法
- 克隆或下载项目代码.
- 安装依赖:
pip install requests, 或者克隆项目代码后pip install -r requirements.txt - 修改脚本内部的常量
DEFAULT_POSTER_PATH, 设置默认保存路径. - 修改主函数处的
poster_save_path保存路径. - 修改主函数处的起始日期
target_date_1和截止日期target_date_2. 同时修改起始爬取页参数为包含截止日期标记的页数page_id=1. - 填写你的
cookies. - 运行脚本
PosterBandit_v2.
注意
- 起止日期不要写错, 否则判断逻辑会出错.
- 见免责声明.
示例:
target_date_1 = "2024-12-1" # TODO 填写起始日期target_date_2 = "2024-12-31" # TODO 填写截止日期
文件结构
Gazer/
├── DoubanGaze/
│ ├── data/
│ │ └── poster/
│ │ └── 2024_1_1_2025_1_31/
│ └── src/
│ ├── PosterBandit.py
│ └── PosterBandit_v2.py
└──...
脚本构思详解
V2 版本处理了深度为 1 的数据 (缩略图链接) 和深度为 2 的数据 (最终海报 URL), 但它 爬取 的深度仍然是 0. 依然在括号中标记了爬取深度.
-
以默认第一页或指定的页数作为爬取的起始页 (爬取深度 0), 找到所有包含电影条目的 div 元素, 最大为 15 个. ▶️
get_movie_elements电影条目 CSS 选择器:
#content > div.grid-16-8.clearfix > div.article .item.comment-item -
在电影条目的 div 元素内找到对应的日期元素和压缩的海报图片链接 ▶️
get_movie_info-
日期 CSS 选择器:
#content div.info span.date检查是否在指定的起止日期参数之间 ▶️
compare_date -
这个页面的海报图片元素 CSS 选择器:
#content div.pic img-
以 <绝命毒师 第二季> 为例, 在这里
<img>标签的 source 链接是https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2016505705.webp(可以认为是数据深度 1, 因为它直接来源于起始页), 高清海报页面https://movie.douban.com/photos/photo/2016505705/的海报元素 source 链接是https://img9.doubanio.com/view/photo/l/public/p2016505705.webp(数据深度 2, 因为它需要通过详情页才能获取, 或者说, 如果按照 V1 的"点击"流程, 需要经过两层(收藏页 -> 电影详情页 -> 海报大图)页面跳转才能到达).注意: 这个

div中放了 2 个可下载图片资源链接. 首先, 后一个 jpg 链接需要通过 JS 动态加载激活, 直接下载是不可用的; 其次, 一般 WebP 文件会更小, 基于 WebP 更先进的压缩算法, 肉眼观察可能会感觉 WebP 更清晰. 所以这里第一个链接是最优选择. -
观察两个链接, 可以知道, 只要在这个页面找到第一个链接, 即可构造第二个:
https://img9.doubanio.com/view/photo/l/public/p{photo_id}.webp(数据深度 2, 但 V2 版本是直接构造这个 URL, 没有爬取这个深度的页面)
检查是否在指定的起止日期参数之间 ▶️
compare_date -
-
-
下载图片保存到指定路径, 创建文件夹名称, 根据日期定义, 如
2024_1_1_2024_12_31▶️create_foldersave_poster
爬虫效率优化
V2 版本 ( PosterBandit_v2.py ) 确实比 V1 版本 ( PosterBandit.py ) 理论上应该更快, 因为减少了不必要的请求 (不再需要进入每个电影的详情页, 直接构造海报 URL). 而且用 save_poster() 函数单独测试海报下载也是成功的, 这说明问题很可能出在 V2 版本的爬虫逻辑上, 而不是 save_poster() 函数本身.
问题:
- V2 版本: 出现高频率 418 错误 (只能下载第一张);
- V1 版本: (深度爬虫) 能正常下载. 但速度慢, 可能会有 418.
V1 和 V2 的主要区别 (请求层面):
-
V1 (深度爬虫):
- 请求豆瓣电影收藏页面 (
https://movie.douban.com/people/{user_id}/collect...). - 对于页面上的每个电影条目, 获取电影详情页链接.
- 请求每个电影详情页链接 (
https://movie.douban.com/subject/{movie_id}/). - 从电影详情页中获取海报列表页链接.
- 请求海报列表页链接 (
https://movie.douban.com/subject/{movie_id}/photos...). - 从海报列表页中获取第一张海报的详情页链接.
- 请求第一张海报的详情页链接 (
https://movie.douban.com/photos/photo/{photo_id}/). - 从海报详情页中获取最终的海报图片 URL.
- 请求最终的海报图片 URL, 下载海报.
- 请求豆瓣电影收藏页面 (
-
V2 (构造 URL):
- 请求豆瓣电影收藏页面 (
https://movie.douban.com/people/{user_id}/collect...). - 对于页面上的每个电影条目, 获取电影的 缩略图 链接 (例如
https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2016505705.webp). - 从缩略图链接中提取 photo ID.
- 直接构造海报图片 URL (
https://img9.doubanio.com/view/photo/l/public/p{photo_id}.webp). - 请求构造的海报图片 URL, 下载海报.
- 请求豆瓣电影收藏页面 (
V2 版本高频率 418 的原因:
-
请求频率过高:
- V1 的 “缓冲” 作用: V1 版本虽然请求次数多, 但每次请求之间都有一定的 “缓冲”. 它需要逐个进入电影详情页、海报列表页等, 这些页面加载本身就需要时间. 这些 “无意” 的延迟, 反而降低了请求频率, 不容易触发豆瓣的反爬机制.
- V2 的 “集中” 请求: V2 版本大大减少了请求次数, 理论上更快. 但它把对海报图片 URL 的请求 集中 在了一起. 在循环中, 它会快速地、连续地请求多个海报图片 URL, 这很容易被豆瓣服务器识别为爬虫行为, 从而触发 418 错误 (或者其他更严厉的封禁).
-
Referer头的问题:Referer: 2 个版本, 当请求最终的海报图片 URL 时,Referer头理应是海报详情页的 URL, 但实际都是直接请求它. 此时,Referer头会是豆瓣电影收藏页面 URL (例如https://movie.douban.com/people/{user_id}/collect...). 服务器可能会认为, 直接从收藏页面请求海报图片 URL 这种行为不太正常, 因为用户通常会先点击海报进入详情页, 然后再查看大图. 因此, 豆瓣可能会对这种Referer头的请求更加警惕.
解决: 修改后的 V2 版本代码 (重点是增加延迟和修改 Referer):
主要修改:
-
get_headers()函数修改:- 参数名
viewed_movie_url改为referer, 更通用. - 函数内部使用传入的
referer参数设置Referer请求头.
- 参数名
-
save_poster()函数:- 增加了一个
headers参数. - 在
requests.get()中使用传入的headers参数.
- 增加了一个
-
download_poster_images()函数修改:- 在首次请求豆瓣电影收藏页面时, 使用
viewed_movie_url作为Referer. - 在循环内部, 构造好
headers后, 调用save_poster()函数时, 传入headers参数. - 在每次循环请求海报 URL 之前, 增加
time.sleep(random.uniform(2, 6)), 随机延迟 2-6 秒或更长. 用于降低请求频率.
- 在首次请求豆瓣电影收藏页面时, 使用
V1 版本代码也作了同样的修改, 测试后显著提高了速度以及避免了 418.
性能对比
对比一下, 同样的内容完整爬取, 包括延迟时间, 总耗时:
- 38 张图片: V1 版本 5 分 29 秒, V2 版本 2 分 50 秒.
- 110 张图片: V1 版本 15 分 10 秒, V2 版本 8 分 15 秒.
V1 版本 (深度爬虫) 的速度提升也很明显, 这说明 Referer 头 的正确设置确实非常重要! 豆瓣的反爬机制很可能对 Referer 做了比较严格的检查.
V2 版本 (构造 URL) 会比 V1 快近一倍. 因为 V2 版本减少了大量不必要的请求 (不需要访问每个电影的详情页和海报列表页), 直接构造最终的海报 URL, 所以速度最快.
总结:
- 解决了 418 错误: 通过增加延迟和正确设置
Referer头. - 优化了 V1 版本: 给 V1 版本增加
Referer头更新, 提高了 V1 的速度 (从超过 5 分钟缩短到大约 2 分半钟). - 性能对比: 对比了 V1 和 V2 版本的性能, 验证了 V2 版本 (构造 URL) 的速度优势.
相关文章:
解锁豆瓣高清海报(三)从深度爬虫到URL构造,实现极速下载
脚本地址: 项目地址: Gazer PosterBandit_v2.py 前瞻 之前的 PosterBandit.py 是按照深度爬虫的思路一步步进入海报界面来爬取, 是个值得学习的思路, 但缺点是它爬取慢, 仍然容易碰到豆瓣的 418 错误, 本文也会指出彻底解决旧版 418 错误的方法并提高爬取速度. 现在我将介绍…...

IDEA单元测试插件 SquareTest 延长试用期权限
SquareTest是一款强大的IDEA单元测试生成插件工具,具体使用方法就不过多介绍了,这里主要介绍变更试用期,方便大家使用 配置信息 我的电脑安装前提配置条件 IntelliJ IDEA 2023.2windows 系统 软件安装 IntelliJ IDEA 直接安装插件Squar…...

PLC的五个学习步骤
五个学习步骤详解: 1. 夯实电气基础 (第一步) 核心思想: PLC控制技术是建立在传统电气控制技术之上的,因此扎实的电气基础至关重要。学习内容: 电气元件原理: 深入理解继电器、接触器、按钮、三相异步电机等常用电气元件的工作原理。这是理解电气控制回…...

深度学习05 ResNet残差网络
目录 传统卷积神经网络存在的问题 如何解决 批量归一化BatchNormalization, BN 残差连接方式 残差结构 ResNet网络 ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得CO…...
卷积神经网络CNN
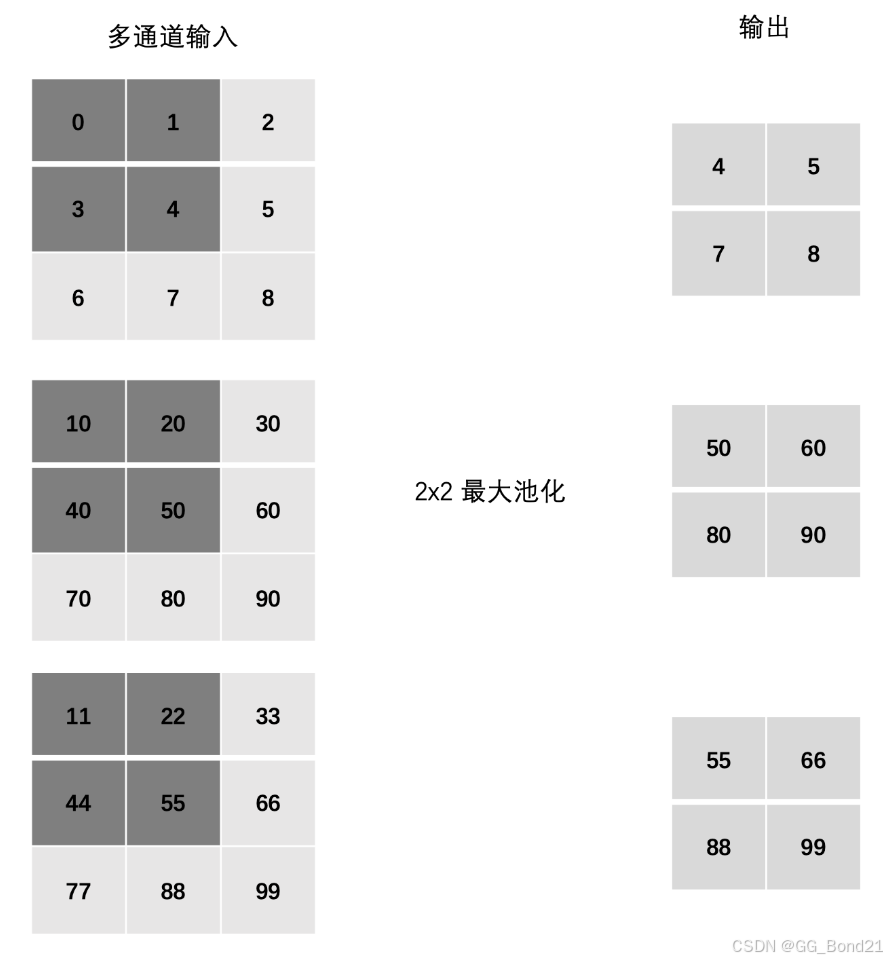
目录 一、CNN概述 二、图像基础知识 三、卷积层 3.1 卷积的计算 3.2 Padding 3.3 Stride 3.4 多通道卷积计算 3.5 多卷积核卷积计算 3.6 特征图大小计算 3.7 Pytorch 卷积层API 四、池化层 4.1 池化计算 4.2 Stride 4.3 Padding 4.4 多通道池化计算 4.5 Pytorc…...

Android:播放Rtsp视频流的两种方式
一.SurfaceView Mediaplayer XML中添加SurfaceView: <SurfaceViewandroid:id"id/surface_view"android:layout_width"match_parent"android:layout_height"match_parent"/> Activity代码: package com.android.rtsp;impor…...

web信息泄露 ctfshow-web入门web1-web10
01做题思路 判断做题的思路是读取,写入,还是执行判断大概的类型,有登录逻辑就尝试sql注入,有下载逻辑就尝试文件读取,有源码就做源码审计 02信息泄露及利用 robots.txt 以ctfshow的web1为例,访问robots…...

Log4j在Spring项目中的应用与实践
在现代Java开发中,日志记录是不可或缺的一部分。它不仅帮助开发者调试和监控应用程序的运行状态,还能在出现问题时快速定位原因。今天,我们就来探讨如何在Spring项目中使用Log4j进行日志管理,并通过具体的实例来展示其强大的功能。…...

docker安装mysql:8.0
1.docker源 目前docker国内的源基本上用不了了,建议去淘宝找一找,我整了一个大概是10R一个月。 2.拉取镜像 docker pull mysql:8.0 3.启动容器 命令如下: docker run \-p 3306:3306 \-e MYSQL_ROOT_PASSWORD123456 \-v /home/data/mysq…...

搭建一个 Spring Boot 项目,解决jdk与springboot版本不匹配
搭建一个 Spring Boot 项目 方式一:使用 Spring Initializr Spring Initializr 是一个基于 Web 的工具,用于快速生成 Spring Boot 项目的基础结构。 访问 Spring Initializr 网站:https://start.spring.io/配置项目信息: …...

心心相系:十颗心
心心相系:十颗心 【1】心脏;人心,热心 heart //注:h-通c-或k- warmhearted a.热心的,热心肠的;亲切的a warm-hearted person 为人古道热肠 词根cardi(o)-(heart),例词:cardiology(…...

ChatGPT行业热门应用提示词案例-AI绘画类
AI 绘画指令是一段用于指导 AI 绘画工具(如 DALLE、Midjourney 等)生成特定图像的文本描述。它通常包含场景、主体、风格、色彩、氛围等关键信息,帮助 AI 理解创作者的意图,从而生成符合要求的绘画作品。 ChatGPT 拥有海量的知识…...

前端面试手写--虚拟列表
目录 一.问题背景 二.代码讲解 三.代码改装 四.代码发布 今天我们来学习如何手写一个虚拟列表,本文将把虚拟列表进行拆分并讲解,然后发布到npm网站上. 一.问题背景 为什么需要虚拟列表呢?这是因为在面对大量数据的时候,我们的浏览器会将所有数据都渲染到表格上面,但是渲…...

达梦数据库针对慢SQL,收集统计信息清除执行计划缓存
前言:若遇到以下场景,大概率是SQL走错了执行计划: 1、一条SQL在页面上查询特别慢,但拿到数据库终端执行特别快 2、一条SQL在某种检索条件下查询特别慢,但拿到数据库终端执行特别快 此时,可以尝试按照下述步…...
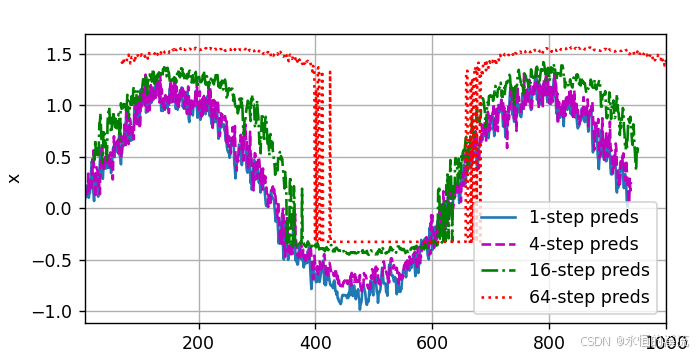
李沐--动手学深度学习 序列模型
1.使用正弦函数和可加性噪声生成序列数据 import torch from torch import nn from d2l import torch as d2l#使用正弦函数和可加性噪声生成序列数据 T 1000 #总共产生1000个点 time torch.arange(1,T1,dtypetorch.float32) x torch.sin(0.01*time) torch.normal(0,0.2,(…...
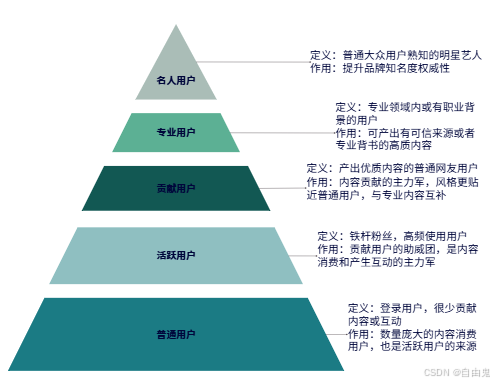
数据分析、商业智能、业务分析三者之间的关系
商业智能 (Business Intelligence, BI)、业务分析 (Business Analytics, BA) 和数据分析 (Data Analytics, DA) 三者都与数据密切相关,但在目标、方法和应用上存在差异。为了能够清晰地解释,下面将从定义入手,然后阐述它们之间的联系和区别。…...

【Spring+MyBatis】留言墙的实现
目录 1. 添加依赖 2. 配置数据库 2.1 创建数据库与数据表 2.2 创建与数据库对应的实体类 3. 后端代码 3.1 目录结构 3.2 MessageController类 3.3 MessageService类 3.4 MessageMapper接口 4. 前端代码 5. 单元测试 5.1 后端接口测试 5.2 使用前端页面测试 在Spri…...

让编程变成一种享受-明基RD320U显示器
引言 作为一名有着多年JAVA开发经验的从业者,在工作过程中,显示器的重要性不言而喻。它不仅是我们与代码交互的窗口,更是影响工作效率和体验的关键因素。在多年的编程生涯中,我遇到过各种各样的问题。比如,在进行代码…...
函数)
【嵌入式Linux应用开发基础】fork()函数
目录 一、fork 函数概述 1.1. 函数作用 1.2. 函数原型与头文件 1.3. 返回值 1.4. 核心特性 二、父子进程的区别与联系 2.1. 相同点 2.2. 不同点 三、典型应用场景 3.1. 多任务处理 3.2. 守护进程创建 3.3. 执行外部程序 3.4. 并行计算 四、fork 函数的关键注意事…...

2024 年 CSDN 博客之星年度评选:技术创作与影响力的碰撞(统计时间2025-02-17 11:06:06)
摘要:在技术的海洋里,每一位博主都像是一座独特的灯塔,用自己创作的光芒照亮他人前行的道路。2024 年 CSDN 博客之星年度评选活动,正是对这些灯塔的一次盛大检阅,让我们看到了众多优秀博主在技术创作领域的卓越表现以及…...

差分信号传输原理与高速电路设计实践
1. 差分信号传输基础与核心优势在高速数字电路设计中,差分信号传输技术已经成为应对噪声干扰的黄金标准。这种传输方式采用两根紧密耦合的传输线,分别承载相位相反的信号。当一条线上的电压为逻辑高电平时,另一条线必然为逻辑低电平ÿ…...

大语言模型安全评估方法与风险防范
1. 大语言模型安全评估的必要性在人工智能技术快速发展的今天,大语言模型(Large Language Models, LLMs)已经深入到我们生活的方方面面。从智能客服到内容创作,从代码生成到教育辅助,这些模型展现出了惊人的能力。但与此同时,它们…...

FLM与FMLM:连续去噪技术在语言建模中的突破
1. 语言建模的进化与挑战在自然语言处理领域,语言建模一直是个核心课题。传统自回归模型(如GPT系列)通过从左到右逐个预测token的方式生成文本,这种"一步一个脚印"的方式虽然稳定,却存在两个致命缺陷&#x…...

强化学习在数学建模中的高效采样优化实践
1. 项目背景与核心价值在数学建模领域,传统采样方法往往面临效率低下、资源浪费的问题。我最近在优化一个复杂金融风险模型时,发现常规均匀采样会导致90%的计算资源消耗在无关紧要的参数空间上。这促使我开始探索强化学习自适应采样技术,经过…...

Flutter 跨平台实战:OpenHarmony 健康管理应用 Day3|页面路由跳转与多表单联动实现
🎯 Flutter 跨平台实战:OpenHarmony 健康管理应用 Day3|页面路由跳转与多表单联动实现 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 前言 大家好!本篇是我真实完成 Flutte…...
设计精妙在哪?从‘挖坑占位’到链表操作,一个简化版C程序全讲透)
LwIP内存池(memp.c)设计精妙在哪?从‘挖坑占位’到链表操作,一个简化版C程序全讲透
LwIP内存池核心机制解析:从静态数组到动态链表的精妙设计 在嵌入式网络协议栈开发中,内存管理一直是决定系统性能和稳定性的关键因素。LwIP作为轻量级TCP/IP协议栈的经典实现,其内存池(memp.c)设计尤其值得深入剖析。本文将用一个完整可运行的…...

SwiftUIX终极指南:开发者最常问的50个问题与解决方案
SwiftUIX终极指南:开发者最常问的50个问题与解决方案 【免费下载链接】SwiftUIX An exhaustive expansion of the standard SwiftUI library. 项目地址: https://gitcode.com/gh_mirrors/sw/SwiftUIX SwiftUIX是标准SwiftUI库的全面扩展,为开发者…...

Agent / Subagent / Swarm 解析:ClaudeCode源码深度解读
Claude Code 的多智能体系统由三个递进层级构成:单次 Subagent(轻量委托)→ Fork Subagent(上下文克隆分身)→ Swarm / Team(多进程协作群)。它们共享同一个 runAgent() 核心,但在隔…...

利用 Taotoken 模型广场为新产品选择性价比最高的文本生成模型
利用 Taotoken 模型广场为新产品选择性价比最高的文本生成模型 1. 理解模型选型的关键维度 为新产品选择文本生成模型时,需要综合考虑多个关键因素。首先是模型能力与产品需求的匹配度,例如生成内容的长度、创意性、逻辑性等。其次是成本因素ÿ…...

2025届毕业生推荐的六大AI论文工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 写作学术作品时,降低文本重复比率属于常见需求,专业降重网站一般依据…...