企业级RAG开源项目分享:Quivr、MaxKB、Dify、FastGPT、RagFlow
企业级 RAG GitHub 开源项目深度分享:Quivr、MaxKB、Dify、FastGPT、RagFlow 及私有化 LLM 部署建议
随着生成式 AI 技术的成熟,检索增强生成(RAG)已成为企业构建智能应用的关键技术。RAG 技术能够有效地将大型语言模型(LLM)与企业私域知识库连接,在保证数据安全和模型可控性的前提下,释放 LLM 的强大能力。本文将深入探讨 GitHub 上五个备受瞩目的开源企业级 RAG 项目:Quivr、MaxKB、Dify、FastGPT 和 RagFlow。我们将结合互联网信息、项目特点以及本地私有化 LLM 部署的考量,为您呈现一篇有深度的技术选型指南。
 Quivr
Quivr
1. Quivr:你的大脑第二皮层,强大的知识管理与 RAG 工具
Quivr 不仅仅是一个 RAG 框架,更是一个强大的“大脑第二皮层”工具,旨在帮助用户管理和利用海量知识。Quivr 的核心理念是将用户的各种知识源整合到一个统一的平台,并通过先进的 RAG 技术,让用户能够像与自己的大脑对话一样,与知识库进行交互。Quivr 强调知识的组织、探索和生成,并提供了丰富的功能和灵活的配置选项,使其在企业级 RAG 应用中展现出巨大的潜力。
深度解析:
- 多模态知识库: Quivr 不仅支持文本数据,还支持图像、音频等多种模态数据,这使得企业可以构建更加全面的知识库,应对更广泛的应用场景。
- 先进的 RAG 流程: Quivr 内置了高度可定制的 RAG 流程,用户可以根据自身需求调整检索策略、提示词工程等关键环节,以优化问答效果。其 "Brain" 的概念,允许用户创建多个独立的知识库,并进行灵活组合和管理。
- 强大的知识管理能力: Quivr 提供了标签、分类、搜索等多种知识管理工具,方便用户组织和查找信息。其 "Prompt Chaining" 功能,允许用户构建复杂的多步骤问答流程,实现更高级的知识应用。
- 用户友好的界面: Quivr 拥有简洁直观的用户界面,即使是非技术人员也能快速上手,进行知识库的构建和管理。
- 插件生态系统: Quivr 正在积极构建插件生态系统,未来将支持更多的数据源、模型和功能扩展,进一步提升平台的灵活性和可扩展性。
GitHub 链接: StanGirard/quivr
 MaxKB
MaxKB
2. MaxKB:企业级知识库平台,专注稳定与效率
MaxKB 是一款企业级知识库平台,其设计目标是为企业提供稳定、高效、易用的知识管理和 RAG 解决方案。MaxKB 强调开箱即用,提供了完善的功能和企业级特性,帮助企业快速构建和部署知识库应用,并提升知识管理的效率。
深度解析:
- 企业级架构设计: MaxKB 从一开始就以企业级应用为目标进行设计,注重系统的稳定性、性能和安全性。其架构支持高并发、高可用,能够满足企业大规模知识库的需求。
- 全面的知识库功能: MaxKB 提供了文档管理、知识分类、权限控制、版本管理等全面的知识库功能,方便企业进行知识的沉淀、管理和维护。
- 高效的 RAG 引擎: MaxKB 内置了高效的 RAG 引擎,支持多种向量数据库和检索算法,能够快速准确地从知识库中检索信息。其 "Hybrid Search" 功能,结合了向量检索和关键词检索的优势,提升了检索的准确性和召回率。
- 强大的管理后台: MaxKB 提供了功能强大的管理后台,方便管理员进行系统配置、用户管理、知识库管理等操作。
- 灵活的部署方式: MaxKB 支持多种部署方式,包括本地部署、云部署等,满足企业不同的部署需求。
GitHub 链接: WayneGongCN/MaxKB (请注意,该项目 GitHub 链接可能需要进一步核实,建议访问其官网获取最新信息)
 Dify
Dify
3. Dify:开箱即用的 LLM 应用开发平台 (再次强调,因其重要性)
Dify 作为一款 LLM 应用开发平台,其 RAG 能力同样不容忽视。Dify 的优势在于其平台化的设计理念,将 RAG 引擎作为核心组件,并集成了模型管理、工作流编排、可观测性等企业级特性,使得开发者可以更专注于业务逻辑的实现。
深度解析 (RAG 角度):
- 平台化 RAG 引擎: Dify 的 RAG 引擎与平台深度集成,用户可以轻松地在平台中配置和使用 RAG 功能,无需进行复杂的代码编写。
- 多 Agent 协同: Dify 支持多 Agent 协同工作,用户可以将 RAG Agent 与其他类型的 Agent 组合,构建更复杂的智能应用,例如 RAG + 知识图谱 Agent、RAG + 自动化 Agent 等。
- 可观测性与监控: Dify 提供了完善的可观测性功能,用户可以监控 RAG 引擎的运行状态、性能指标等,及时发现和解决问题。
- 持续迭代与优化: Dify 团队持续迭代和优化 RAG 引擎,不断引入新的技术和功能,例如最新的 Parent-child Retrieval 功能,提升了 RAG 的性能和效果。
- 商业化支持: Dify 背后有商业公司支持,提供了专业的企业级服务和技术支持,降低了企业使用开源 RAG 项目的风险。
GitHub 链接: langgenius/dify
 FastGPT
FastGPT
4. FastGPT:轻量级知识库问答平台,快速落地业务场景
FastGPT 以其轻量级、易用性而著称,旨在帮助用户快速构建和部署知识库问答系统。FastGPT 降低了 RAG 技术的门槛,让更多的企业和开发者能够快速落地 RAG 应用,解决实际业务问题。
深度解析:
- 极简的设计理念: FastGPT 的设计理念是极简主义,力求在保证功能性的前提下,最大程度地简化操作和配置,降低用户的学习成本和使用门槛。
- 快速部署能力: FastGPT 提供了多种部署方式,包括 Docker 部署、一键部署脚本等,用户可以快速搭建起可用的知识库问答系统。
- 可视化 AI 工作流: FastGPT 提供了可视化的 AI 工作流编排功能,用户可以通过拖拽和配置,自定义问答流程,满足不同的业务需求。
- 插件化扩展: FastGPT 支持插件化扩展,用户可以根据自身需求开发和集成插件,扩展平台的功能。
- 活跃的社区支持: FastGPT 拥有活跃的社区,用户可以在社区中获取帮助、交流经验,并参与项目共建。
GitHub 链接: labring/FastGPT

RagFlow
5. RagFlow:深度文档理解 RAG 引擎 (再次强调,因其独特价值)
RagFlow 专注于深度文档理解,在处理复杂文档和结构化数据方面具有独特优势。RagFlow 致力于提供精准且可信的答案,尤其适合需要从海量文档中提取深层信息的应用场景。
深度解析 (文档理解角度):
- 深度文档解析: RagFlow 采用了先进的文档解析技术,能够深入理解文档的结构和语义信息,并将其转化为结构化数据,方便后续的检索和问答。
- 多格式文档支持: RagFlow 支持多种复杂文档格式,例如 PDF、Word、Excel、PPT 等,以及网页、数据库等多种数据源,能够应对企业知识库中常见的复杂数据类型。
- 结构化信息提取: RagFlow 不仅能够提取文本信息,还能够提取文档中的表格、图片、列表等结构化信息,并将其用于 RAG 流程中,提升问答的准确性和完整性。
- 引用溯源能力: RagFlow 能够提供答案的引用来源,用户可以追溯答案的来源文档和段落,验证答案的可信度。
- 本地 LLM 优化: RagFlow 特别针对本地 LLM 进行了优化,可以与 Intel GPU 上的 IPEX-LLM 等本地模型高效集成,实现高性能的本地 RAG 方案。
GitHub 链接: infiniflow/ragflow
项目对比与选型深度建议
| 功能特性 | Quivr | MaxKB | Dify | FastGPT | RagFlow |
| 核心定位 | 大脑第二皮层,知识管理与 RAG 工具 | 企业级知识库平台,稳定高效 | LLM 应用开发平台,平台化 RAG 引擎 | 轻量级知识库问答平台,快速落地 | 深度文档理解 RAG 引擎,复杂文档处理 |
| 易用性 | 用户友好界面,操作相对简单 | 开箱即用,管理后台强大 | 可视化界面,平台化操作简便 | 极简设计,快速部署,低代码 | 模块化架构,部署相对简单,配置灵活 |
| RAG 能力 | 高度可定制 RAG 流程,多模态支持 | 高效 RAG 引擎,Hybrid Search | 平台化 RAG 引擎,多 Agent 协同 | RAG 检索与重排序,可视化工作流 | 深度文档解析,结构化信息提取,引用溯源 |
| 企业级特性 | 插件生态,知识管理工具丰富 | 企业级架构,全面知识库功能,管理后台强大 | SSO、访问控制,可观测性,商业化支持 | 插件化扩展,社区活跃 | 可扩展架构,本地 LLM 优化,引用支持 |
| 私有化 LLM 适配性 | 需进一步评估,插件化机制可能支持 | 需进一步评估,企业级架构或有考虑 | 支持多种 LLM,包括开源模型,本地部署 | 支持多种 LLM,轻量级易于适配 | 本地 LLM 优化,与 Intel IPEX-LLM 集成 |
| 适用场景 | 个人知识管理、企业知识库、多模态知识应用 | 企业级知识库、文档管理、内部知识共享 | 多种 LLM 应用场景、AI 工作流、平台化 RAG 服务 | 企业内部问答、客服机器人、快速原型验证 | 复杂文档问答、金融研报分析、法律文档处理、深度信息挖掘 |
| 深度与特色 | 知识组织与探索,Prompt Chaining,多模态 | 企业级稳定高效,Hybrid Search,管理后台 | 平台化能力,多 Agent 协同,可观测性,商业支持 | 极简易用,可视化工作流,快速部署,插件化 | 深度文档理解,结构化信息提取,引用溯源,本地优化 |
导出到 Google 表格
企业级 RAG 项目选型深度建议:
- 全能型平台之选 - Dify: 如果您需要一个功能全面、平台化的 RAG 解决方案,并希望构建各种复杂的 LLM 应用,Dify 是首选。其平台化的设计、完善的企业级特性和商业化支持,能够为企业提供更可靠的保障。
- 企业级稳定之选 - MaxKB: 如果您更看重系统的稳定性、效率和企业级知识库的完整功能,MaxKB 可能更符合您的需求。其企业级架构和全面的知识库管理功能,能够满足企业大规模知识管理的需求。
- 轻量快速落地之选 - FastGPT: 如果您希望快速构建一个可用的知识库问答系统,并快速验证 RAG 技术在业务场景中的价值,FastGPT 的轻量级和易用性将是您的优势。
- 深度文档理解之选 - RagFlow: 如果您需要处理大量复杂文档,并对文档的深度理解和答案的准确性有极高要求,RagFlow 的深度文档理解能力将是您的不二之选。尤其在金融、法律、研究等领域,RagFlow 能够发挥其独特价值。
- 个人知识管理与创新探索之选 - Quivr: 如果您希望构建一个面向未来的、更智能化的知识管理系统,并希望在 RAG 技术上进行更深入的探索和创新,Quivr 的灵活性和多模态支持将为您提供更大的空间。
本地私有化 LLM 部署建议
在企业级 RAG 应用中,本地私有化 LLM 部署变得越来越重要。本地 LLM 部署可以带来以下优势:
- 数据安全与隐私保护: 企业数据无需上传到云端,降低数据泄露的风险,符合企业对于数据安全和隐私保护的要求。
- 模型可控性与定制化: 企业可以完全掌控 LLM 模型,并根据自身需求进行定制和优化,提升模型在特定领域的性能。
- 降低成本: 长期来看,本地部署可以降低模型 API 调用成本,尤其是在高并发、高频次的应用场景下。
- 离线运行能力: 本地部署的 RAG 系统可以在离线环境下运行,保证业务的连续性和可靠性。
本地私有化 LLM 选型与集成建议:
- 模型选型:
- 开源模型优先: 优先考虑 Llama 2、Mistral、ChatGLM 等优秀的开源 LLM 模型,这些模型在性能和社区支持方面都表现出色。
- 领域模型微调: 针对特定领域,可以对开源模型进行微调,提升模型在特定领域的专业性和准确性。
- 硬件适配性: 选择与企业现有硬件环境(例如 GPU、CPU)适配性良好的模型,充分利用硬件资源,提升模型推理效率。 RagFlow 在与 Intel GPU 上的 IPEX-LLM 集成方面做了优化,可以作为参考。
- 硬件配置:
- GPU 加速: 对于计算密集型的 LLM 推理任务,GPU 是必不可少的硬件加速设备。根据模型大小和并发量需求,选择合适的 GPU 型号和数量。
- 内存需求: LLM 模型通常需要较大的内存空间,确保服务器内存能够满足模型运行的需求。
- 存储空间: 本地部署需要足够的存储空间来存放模型文件、知识库数据等。
- 集成方案:
- API 封装: 将本地 LLM 封装成 API 接口,方便 RAG 框架调用。可以使用 FastAPI、Flask 等框架快速构建 API 服务。
- 框架原生支持: 关注 RAG 框架是否原生支持本地 LLM 集成。例如,Dify、FastGPT 等平台都支持自定义模型接入,RagFlow 也对本地 LLM 做了优化。
- 向量数据库本地化: RAG 系统通常需要向量数据库来存储和检索向量数据。可以选择本地部署的向量数据库,例如 Milvus、Weaviate 等,确保数据安全和访问效率。
- 安全与监控:
- 访问控制: 对本地 LLM 服务进行严格的访问控制,防止未经授权的访问和使用。
- 安全审计: 建立完善的安全审计机制,记录和监控模型的使用情况,及时发现和处理安全风险。
- 性能监控: 对本地 LLM 服务的性能进行监控,例如推理延迟、吞吐量等,及时优化系统性能。
总结
企业级 RAG 开源项目为企业构建智能应用提供了强大的工具和平台。Quivr、MaxKB、Dify、FastGPT 和 RagFlow 各有特色,企业可以根据自身需求和场景进行选择。在追求 RAG 应用的深度和广度的同时,本地私有化 LLM 部署也成为企业需要重点考虑的方向。通过合理的模型选型、硬件配置和集成方案,企业可以构建安全、高效、可控的企业级 RAG 系统,释放 AI 的真正价值。
希望这篇深度博客文章能够帮助您更好地理解企业级 RAG 开源项目,并为您的技术选型和私有化 LLM 部署提供有价值的参考。如果您有任何疑问或需要进一步的交流,欢迎随时提出。
相关文章:
企业级RAG开源项目分享:Quivr、MaxKB、Dify、FastGPT、RagFlow
企业级 RAG GitHub 开源项目深度分享:Quivr、MaxKB、Dify、FastGPT、RagFlow 及私有化 LLM 部署建议 随着生成式 AI 技术的成熟,检索增强生成(RAG)已成为企业构建智能应用的关键技术。RAG 技术能够有效地将大型语言模型ÿ…...
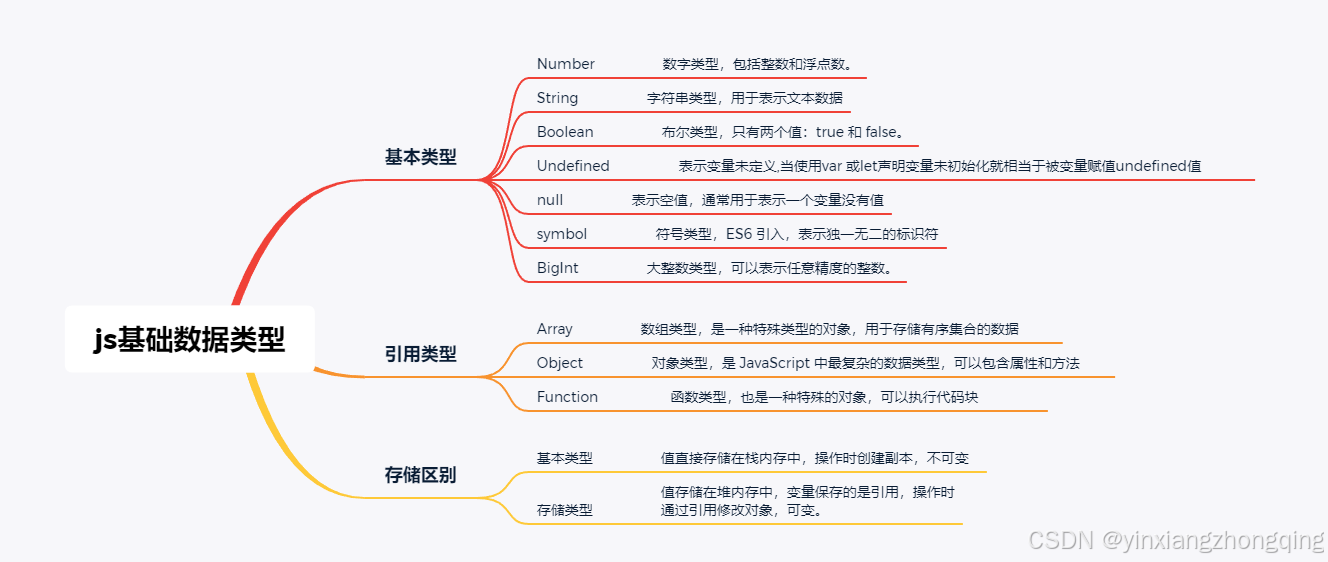
js基础知识总结
1、js数据类型有哪些?存储区别 js基础类型及引用类型存储区别代码示例如下: // 基本数据类型 let a 10; let b a; // b 是 a 的一个副本 b 20; // 修改 b 不会影响 …...

LearnOpenGL——高级OpenGL(下)
教程地址:简介 - LearnOpenGL CN 高级数据 原文链接:高级数据 - LearnOpenGL CN 在OpenGL中,我们长期以来一直依赖缓冲来存储数据。本节将深入探讨一些操作缓冲的高级方法。 OpenGL中的缓冲本质上是一个管理特定内存块的对象,它…...

vue脚手架开发打地鼠游戏
游戏设计: 规划游戏的核心功能,如场景、随机出现的地鼠、计分系统、游戏时间限制等。简单设计游戏流程,包括开始界面、游戏进行中、关卡设置(如不同关卡地鼠出现数量、游戏时间等)、关卡闯关成功|失败、游戏结束闯关成…...

uniapp 连接mqtt
1:下载插件 npm install mqtt 2:创建 mqtt.js /* main.js 项目主入口注入实例 */ // import mqttTool from ./lib/mqttTool.js // Vue.prototype.$mqttTool mqttTool/* 使用范例见 /pages/index/index.vue */ // mqtt协议:H5使用ws/wss APP-…...

EX_25/2/19
1. 封装一个 File 类,用有私有成员 File* fp 实现以下功能 File f "文件名" 要求打开该文件 f.write(string str) 要求将str数据写入文件中 string str f.read(int size) 从文件中读取最多size个字节,并将读取到的数据返回 析构函数 …...

Breakout Tool
思科 CML 使用起来还是很麻烦的,很多操作对于习惯了 secure crt 或者 putty 等工具的网络工程师都不友好。 Breakout Tool 提供对远程实验室中虚拟机控制台与图形界面的本地化接入能力,其核心特性如下: Console 访问:基于 Telnet…...

【大模型】DeepSeek:AI浪潮中的破局者
【大模型】DeepSeek:AI浪潮中的破局者 引言:AI 新时代的弄潮儿DeepSeek:横空出世展锋芒(一)诞生背景与发展历程(二)全球影响力初显 探秘 DeepSeek 的技术内核(一)独特的模…...

Kafka 简介
Kafka 简介 Apache Kafka 是一个开源的分布式流处理平台,广泛应用于实时数据流处理、日志管理、消息传递等场景。Kafka 最初由 LinkedIn 开发,并于 2011 年捐献给 Apache 软件基金会。 Kafka 的设计目标是高吞吐量、低延迟和高可用性,它能够…...
?——金融衍生品的关键工具(中英双语))
什么是掉期(Swap)?——金融衍生品的关键工具(中英双语)
什么是掉期(Swap)?——金融衍生品的关键工具 引言 掉期(Swap) 是金融市场中最重要的衍生品之一,它允许两方交换未来的现金流,以优化融资成本、规避利率或汇率风险,甚至进行投机交易…...

深入解析 Vue 项目中的缓存刷新机制:原理与实战
目录 前言1. Demo2. 知识拓展 前言 在 Vue 项目中,缓存通常用于存储用户信息、角色权限、系统设置等,以提高页面加载速度并减少 API 请求 这里使用 web-storage-cache 作为封装的本地存储工具,支持 localStorage 和 sessionStorage 方式存储…...

【C++】 Flow of Control
《C程序设计基础教程》——刘厚泉,李政伟,二零一三年九月版,学习笔记 文章目录 1、选择结构1.1、if 语句1.2、嵌套的 if 语句1.3、条件运算符 ?:1.4、switch 语句 2、循环结构2.1、while 语句2.2、do-while 语句2.3、 for 循环2.4、循环嵌套…...

【异常错误】pycharm debug view变量的时候显示不全,中间会以...显示
异常问题: 这个是在新版的pycharm中出现的,出现的问题,点击view后不全部显示,而是以...折叠显示 在setting中这么设置一下就好了: 解决办法: https://youtrack.jetbrains.com/issue/PY-75568/Large-stri…...

2.19c++练习
1.封装一个mystring类 拥有私有成员: char* p int len 需要让以下代码编译通过,并实现对应功能 mystring str "hello" mystring ptr; ptr.copy(str) ptr.append(str) ptr.show() 输出ptr代表的字符串 ptr.compare(str) 比较ptr和…...

【为什么使用`new DOMParser`可以保持SVG命名空间】
为什么使用new DOMParser可以保持SVG命名空间: 一、命名空间基础概念 1. XML命名空间定义 <svg xmlns"http://www.w3.org/2000/svg"><!-- 此元素及其子元素属于SVG命名空间 --><rect x"10" y"20"/> </svg>…...

【DL】浅谈深度学习中的知识蒸馏 | 输出层知识蒸馏
目录 一 核心概念与背景 二 输出层知识蒸馏 1 教师模型训练 2 软标签生成(Soft Targets) 3 学生模型训练 三 扩展 1 有效性分析 2 关键影响因素 3 变体 一 核心概念与背景 知识蒸馏(Knowledge Distillation, KD)是一种模…...

应急响应(linux 篇,以centos 7为例)
一、基础命令 1.查看已经登录的用户w 2.查看所有用户最近一次登录:lastlog 3.查看历史上登录的用户还有登录失败的用户 历史上所有登录成功的记录 last /var/log/wtmp 历史上所有登录失败的记录 Lastb /var/log/btmp 4.SSH登录日志 查看所有日志:…...

EasyRTC:智能硬件适配,实现多端音视频互动新突破
一、智能硬件全面支持,轻松跨越平台障碍 EasyRTC 采用前沿的智能硬件适配技术,无缝对接 Windows、macOS、Linux、Android、iOS 等主流操作系统,并全面拥抱 WebRTC 标准。这一特性确保了“一次开发,多端运行”的便捷性,…...

堆和栈的区别
堆和栈 不同点: 内存分配方式不同: 栈:栈上的内存是自动分配和释放的,通常用于存储函数调用过程中的局部变量、调用参数和使用的寄存器状态等信息。堆:堆上的内存是动态分配的,程序在运行时可以根据需要分…...

【信息系统项目管理师】专业英语重点词汇大汇总
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 一、信息和信息系统重要词汇汇总1.Computer(计算机)重要词汇2.Information system(信息系统)重要词汇3.Software Engineering(软件工程)重要词汇4.Network(网络)相关重要词汇5.信息安全重要词汇6.Electronic Co…...

题解:洛谷 P5688 [CSP-S 2019 江西] 散步
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...
)
Android16进阶之Virtualizer.canVirtualize调用流程与实战(三百零九)
简介: CSDN博客专家、《Android系统多媒体进阶实战》作者 博主新书推荐:《Android系统多媒体进阶实战》🚀 Android Audio工程师专栏地址: Audio工程师进阶系列【原创干货持续更新中……】🚀 Android多媒体专栏地址&a…...

DisplayPort 1.2协议分析工具FS4438/FS4439详解
1. DisplayPort 1.2协议分析工具的技术背景在数字显示接口领域,DisplayPort标准自2006年由VESA发布以来,已成为计算机和高清视频设备的主流接口之一。2010年推出的DisplayPort 1.2版本将单通道带宽提升至5.4Gbps,并引入了多流传输(MST)等关键…...

BetterJoy完整指南:轻松解决Switch控制器PC连接问题
BetterJoy完整指南:轻松解决Switch控制器PC连接问题 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.com/gh…...

2.4 静态链表
#include <stdio.h> #include <malloc.h>// 默认链表容量 #define DEFAULT_SIZE 5typedef struct StaticLinkedNode{char data;int next; } *NodePtr;typedef struct StaticLinkedList{NodePtr nodes;int* used; } *ListPtr;/*** 初始化静态链表(带头节…...

商品结构需要重排跨境卖家如何选择先优化哪一类
破局与深耕:跨境卖家商品结构的战略优化之道在跨境电商的竞技场上,卖家时常会面临一个核心挑战:当店铺商品结构逐渐庞杂,流量分散,利润增长乏力时,如何从琳琅满目的商品库中,精准定位出需要优先…...

vben-admin-thin-next完整指南:10个核心功能深度解析
vben-admin-thin-next完整指南:10个核心功能深度解析 【免费下载链接】vben-admin-thin-next vue-vben-admin-2.0 mini template.vue3,vite,typescript 项目地址: https://gitcode.com/gh_mirrors/vb/vben-admin-thin-next vben-admin-thin-next是一个免费开…...

特征学习电力机车辅助供电接地故障诊断【附代码】
✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。 ✅ 如需沟通交流,扫描文章底部二维码。(1)故障机理驱动的时序波形特征建模:针对电力机车辅…...

从数据展示到场景叙事:用ECharts 3D地图贴图打造沉浸式业务大屏
从数据展示到场景叙事:用ECharts 3D地图贴图打造沉浸式业务大屏 当数据可视化从平面图表跃入三维空间时,地理信息便不再是简单的坐标集合。想象一下:物流热力在星空背景下流转,城市交通脉络在卫星影像上跳动,这种将业务…...

Qwen3模型网络故障诊断辅助:图解常见错误与解决方案
Qwen3模型网络故障诊断辅助:图解常见错误与解决方案 网络一断,业务瘫痪。对于运维工程师来说,这可能是最让人心跳加速的时刻。面对屏幕上跳出的错误代码,从海量的日志和复杂的拓扑图中快速定位问题根源,无异于大海捞针…...