DeepSeek与ChatGPT:会取代搜索引擎和人工客服的人工智能革命
云边有个稻草人-CSDN博客
在众多创新技术中,DeepSeek和ChatGPT无疑是最为引人注目的。它们通过强大的搜索和对话生成能力,能够改变我们与计算机交互的方式,帮助我们高效地获取信息,增强智能服务。本文将深入探讨这两项技术如何结合使用,为用户提供更精准、更流畅的对话和搜索体验。
目录
一、介绍
1.1 什么是DeepSeek?
1.2 什么是ChatGPT?
1.3 DeepSeek与ChatGPT的结合:技术优势
二、应用场景:广泛的行业应用
2.1 智能客服与客户支持
2.2 内容创作与新闻生成
2.3 教育与学习辅导
三、应用场景:智能问答系统
3.1 流程
3.2 代码实现
结果输出
解释
一、介绍
1.1 什么是DeepSeek?
DeepSeek 是一种智能搜索引擎,采用了深度学习技术来提高搜索的精准度。传统的搜索引擎主要依靠基于关键词的匹配算法来为用户提供相关信息。然而,DeepSeek不仅关注关键词匹配,还能够深度理解查询的语境与用户意图,提供更加精准的答案。
DeepSeek能够分析查询中的上下文,理解其中的潜在需求,从而从海量的数据中快速筛选出最相关的内容。其背后的核心技术包括自然语言理解(NLU)、深度语义匹配和信息抽取模型,帮助系统超越传统搜索引擎的局限,生成更符合用户需求的结果。
1.2 什么是ChatGPT?
ChatGPT 是由OpenAI开发的基于GPT(Generative Pre-trained Transformer)架构的大规模预训练语言模型。它经过数以亿计文本数据的训练,具备了强大的生成能力,能够理解上下文并生成连贯、有逻辑的自然语言文本。
ChatGPT不仅能完成日常对话,还能够进行问答、文本生成、情感分析等任务。通过对大量数据的预训练,ChatGPT具有丰富的知识库,能够解决用户在多个领域的提问,甚至在较为复杂的语境下进行推理与分析。
1.3 DeepSeek与ChatGPT的结合:技术优势
DeepSeek和ChatGPT结合的核心优势在于它们能够结合各自的技术特长,弥补对方的不足。具体来说:
-
精准的搜索引擎与深度语义理解: DeepSeek能够通过深度学习对用户查询的背景、意图和上下文进行深刻分析。这一优势使得它能够精确地匹配相关的内容并提取出关键信息。然而,DeepSeek的输出通常是原始的文档或片段,缺少人类自然语言的流畅性和可读性。在这种情况下,ChatGPT的生成能力就显得尤为重要。它可以将DeepSeek返回的原始信息转化为更加连贯、易于理解的答案。
-
多轮对话与个性化体验: ChatGPT的多轮对话能力使得系统能够更好地理解上下文,并根据前述对话进行推理。在和DeepSeek结合后,用户不仅能得到相关信息,还能得到更加符合其实际需求的个性化回答。
-
动态反馈与智能推荐: 结合了深度学习搜索引擎和自然语言生成技术的DeepSeek和ChatGPT,能够提供更加智能化和实时的推荐服务。基于用户的查询和行为,系统可以动态优化推荐内容,并通过自然语言与用户互动,以获取更多上下文信息,从而进一步改进推荐的准确性。
二、应用场景:广泛的行业应用
DeepSeek和ChatGPT结合后的应用场景几乎无所不在。以下是一些典型的应用案例:
2.1 智能客服与客户支持
智能客服系统是目前DeepSeek与ChatGPT结合最广泛的应用场景之一。用户通过提问,DeepSeek会从知识库、FAQ或其他在线文档中查找相关的信息。然后,ChatGPT根据这些信息生成自然流畅的答案,并且能够根据用户进一步的提问进行多轮对话,优化服务质量。
例如,当用户询问“如何修改账户信息”时,DeepSeek会搜索到相关的帮助文档,而ChatGPT则将这些信息整理并生成一个简洁的说明,帮助用户完成操作。
2.2 内容创作与新闻生成
在新闻行业,记者和编辑可以利用DeepSeek快速获取与某个话题相关的各种新闻报道、文献和数据,而ChatGPT则可以将这些信息结合起来,生成一篇新的新闻文章。这不仅提高了信息获取和内容创作的效率,还能大幅降低人工编辑的工作量。
例如,在紧急报道突发事件时,DeepSeek能够实时从网络上抓取最新的报道和研究成果,ChatGPT则会基于这些数据生成一篇清晰且有逻辑的新闻报道,提供给读者。
2.3 教育与学习辅导
在教育领域,DeepSeek和ChatGPT的结合可以为学生提供个性化的学习支持。DeepSeek从全球范围内检索并筛选出优质的教育资源、教材和研究资料,而ChatGPT则能够根据这些资源为学生解答问题、提供辅导并解释复杂的概念。
例如,当学生查询“相对论是什么?”时,DeepSeek会返回相关的学术文章和解释,ChatGPT则用通俗易懂的语言为学生解释相对论的基本原理。
例如,企业领导想了解某个市场趋势时,DeepSeek会检索到相关的行业报告,ChatGPT会根据报告内容生成一份易懂的市场趋势分析报告,供决策者参考。
示例代码:多种应用场景
下面的代码示例展示了如何将DeepSeek与ChatGPT结合,构建一个多功能的智能问答系统。
安装必要的库
pip install openai requests
代码实现
import openai
import requests# 设置OpenAI API密钥
openai.api_key = 'your-openai-api-key'# 模拟DeepSeek查询(API模拟)
def deepseek_query(query):# 模拟从DeepSeek获取相关文档search_results = [{"title": "如何提高工作效率", "content": "1. 制定明确目标 2. 优化工作流程..."},{"title": "时间管理技巧", "content": "时间管理的重要性,如何合理规划日程..."}]return search_results# 使用ChatGPT生成自然语言回答
def generate_answer_from_chatgpt(context):prompt = f"根据以下内容生成简洁明了的答案:\n\n{context}"response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=150)return response.choices[0].text.strip()# 模拟多轮对话
def multi_round_conversation(query):# Step 1: DeepSeek返回相关文档documents = deepseek_query(query)# Step 2: 将多个文档内容组合成上下文context = "\n".join([doc['content'] for doc in documents])# Step 3: 通过ChatGPT生成自然语言答案answer = generate_answer_from_chatgpt(context)return answer# 主函数:模拟查询
def main():query_1 = "如何提高工作效率?"answer_1 = multi_round_conversation(query_1)print(f"查询:{query_1}\n回答:{answer_1}\n")query_2 = "时间管理的关键技巧是什么?"answer_2 = multi_round_conversation(query_2)print(f"查询:{query_2}\n回答:{answer_2}\n")query_3 = "如何克服拖延症?"answer_3 = multi_round_conversation(query_3)print(f"查询:{query_3}\n回答:{answer_3}\n")# 执行示例
main()
代码解释:
- DeepSeek查询:
deepseek_query函数模拟从DeepSeek获取与用户查询相关的文档。实际使用中,DeepSeek会通过深度语义理解返回相关文档的内容。 - 生成自然语言回答:
generate_answer_from_chatgpt通过OpenAI的API使用ChatGPT生成简洁明了的答案,整合从DeepSeek返回的文档内容。 - 多轮对话支持:代码通过多轮对话,模拟用户提出不同的问题,DeepSeek和ChatGPT的结合为每个查询提供精准的回答。
三、应用场景:智能问答系统
假设DeepSeekR1是一个基于深度学习的搜索引擎模型,结合了自然语言处理(NLP)和深度神经网络(DNN)来处理和检索文本信息。我们将以一个实际的应用场景:智能问答系统为例,来展示如何实现。
3.1 流程
- 查询输入:用户提出查询问题。
- 文档检索:DeepSeekR1从数据库或文档库中检索相关文档。
- 自然语言理解:DeepSeekR1利用深度学习和自然语言处理技术分析文档内容。
- 答案生成:系统生成与查询最相关的答案,返回给用户。
假设DeepSeekR1是一个基于BERT的搜索引擎,采用文本嵌入(embeddings)与向量空间模型进行高效检索和匹配。
3.2 代码实现
(1) 安装所需依赖
pip install transformers faiss-cpu torch
(2)导入所需库和加载模型
from transformers import BertTokenizer, BertForMaskedLM
import torch
import faiss
import numpy as np
(3)拟文档库与用户查询
# 假设这是从DeepSeekR1数据库中获取的文档
documents = ["The capital of France is Paris.","Deep learning is a subset of machine learning.","The Eiffel Tower is located in Paris, France.","Machine learning is the study of algorithms that improve automatically through experience."
]# 用户查询问题
query = "Where is the Eiffel Tower?"(4)生成文档的文本嵌入(Embeddings)
我们将使用BERT模型生成每个文档的文本嵌入。嵌入是一个固定长度的向量,表示文本的语义内容。通过比较文本之间的嵌入,我们可以有效地衡量它们的相似度。
# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 生成文档的嵌入向量
def generate_embeddings(texts):embeddings = []for text in texts:inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = model(**inputs)# 使用BERT模型的输出作为文本嵌入(可以取平均值)embeddings.append(outputs.last_hidden_state.mean(dim=1).squeeze().numpy())return np.array(embeddings)# 生成文档的嵌入
doc_embeddings = generate_embeddings(documents)(5)创建FAISS索引
为了加速搜索,我们使用FAISS(Facebook AI Similarity Search)库来构建文档嵌入的索引,并快速检索与查询问题最相似的文档。
# 创建FAISS索引,使用L2距离进行相似度匹配
def create_faiss_index(embeddings):index = faiss.IndexFlatL2(embeddings.shape[1]) # L2距离度量index.add(embeddings) # 添加嵌入到索引中return index# 创建索引
index = create_faiss_index(doc_embeddings)
(6)执行查询并返回最相关的文档
用户输入查询后,我们会将查询转化为嵌入,并使用FAISS索引查找与查询最相似的文档。
# 将查询转化为嵌入并使用FAISS搜索最相关的文档
def search(query, index, documents):query_embedding = generate_embeddings([query])D, I = index.search(query_embedding, k=1) # 返回与查询最相关的文档return documents[I[0][0]] # 返回最相关的文档# 执行查询并输出结果
answer = search(query, index, documents)
print(f"User query: {query}")
print(f"Most relevant document: {answer}")(7)完整代码实现
from transformers import BertTokenizer, BertForMaskedLM
import torch
import faiss
import numpy as np# 假设这是从DeepSeekR1数据库中获取的文档
documents = ["The capital of France is Paris.","Deep learning is a subset of machine learning.","The Eiffel Tower is located in Paris, France.","Machine learning is the study of algorithms that improve automatically through experience."
]# 用户查询问题
query = "Where is the Eiffel Tower?"# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 生成文档的嵌入向量
def generate_embeddings(texts):embeddings = []for text in texts:inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = model(**inputs)# 使用BERT模型的输出作为文本嵌入(可以取平均值)embeddings.append(outputs.last_hidden_state.mean(dim=1).squeeze().numpy())return np.array(embeddings)# 生成文档的嵌入
doc_embeddings = generate_embeddings(documents)# 创建FAISS索引,使用L2距离进行相似度匹配
def create_faiss_index(embeddings):index = faiss.IndexFlatL2(embeddings.shape[1]) # L2距离度量index.add(embeddings) # 添加嵌入到索引中return index# 创建索引
index = create_faiss_index(doc_embeddings)# 将查询转化为嵌入并使用FAISS搜索最相关的文档
def search(query, index, documents):query_embedding = generate_embeddings([query])D, I = index.search(query_embedding, k=1) # 返回与查询最相关的文档return documents[I[0][0]] # 返回最相关的文档# 执行查询并输出结果
answer = search(query, index, documents)
print(f"User query: {query}")
print(f"Most relevant document: {answer}")
结果输出
执行代码后,系统会根据用户查询 "Where is the Eiffel Tower?" 从文档库中找出最相关的文档,并返回:
User query: Where is the Eiffel Tower?
Most relevant document: The Eiffel Tower is located in Paris, France.
解释
- 文档嵌入:通过BERT模型将每个文档转换为一个高维向量,捕捉到文本的语义信息。
- FAISS索引:FAISS库用于存储和搜索文档嵌入,利用L2距离快速找到与查询最相似的文档。
- 查询与匹配:用户输入查询后,系统将查询转化为嵌入,使用FAISS索引进行搜索,返回最相关的文档。
完——
相关文章:

DeepSeek与ChatGPT:会取代搜索引擎和人工客服的人工智能革命
云边有个稻草人-CSDN博客 在众多创新技术中,DeepSeek和ChatGPT无疑是最为引人注目的。它们通过强大的搜索和对话生成能力,能够改变我们与计算机交互的方式,帮助我们高效地获取信息,增强智能服务。本文将深入探讨这两项技术如何结合…...

企业级RAG开源项目分享:Quivr、MaxKB、Dify、FastGPT、RagFlow
企业级 RAG GitHub 开源项目深度分享:Quivr、MaxKB、Dify、FastGPT、RagFlow 及私有化 LLM 部署建议 随着生成式 AI 技术的成熟,检索增强生成(RAG)已成为企业构建智能应用的关键技术。RAG 技术能够有效地将大型语言模型ÿ…...
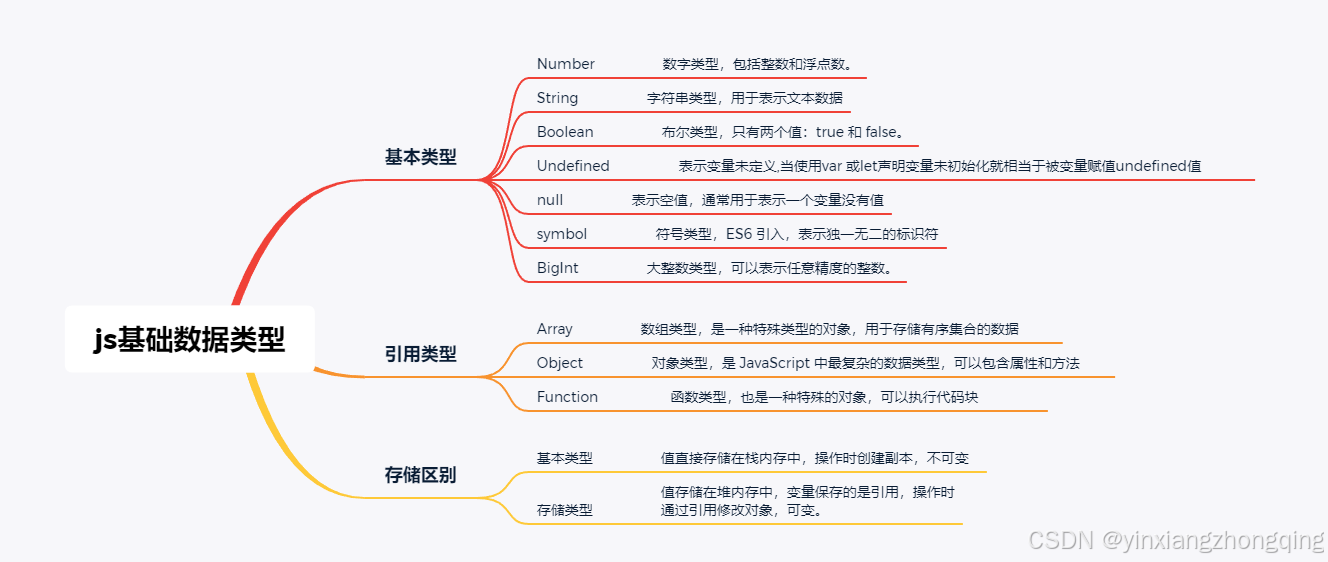
js基础知识总结
1、js数据类型有哪些?存储区别 js基础类型及引用类型存储区别代码示例如下: // 基本数据类型 let a 10; let b a; // b 是 a 的一个副本 b 20; // 修改 b 不会影响 …...

LearnOpenGL——高级OpenGL(下)
教程地址:简介 - LearnOpenGL CN 高级数据 原文链接:高级数据 - LearnOpenGL CN 在OpenGL中,我们长期以来一直依赖缓冲来存储数据。本节将深入探讨一些操作缓冲的高级方法。 OpenGL中的缓冲本质上是一个管理特定内存块的对象,它…...

vue脚手架开发打地鼠游戏
游戏设计: 规划游戏的核心功能,如场景、随机出现的地鼠、计分系统、游戏时间限制等。简单设计游戏流程,包括开始界面、游戏进行中、关卡设置(如不同关卡地鼠出现数量、游戏时间等)、关卡闯关成功|失败、游戏结束闯关成…...

uniapp 连接mqtt
1:下载插件 npm install mqtt 2:创建 mqtt.js /* main.js 项目主入口注入实例 */ // import mqttTool from ./lib/mqttTool.js // Vue.prototype.$mqttTool mqttTool/* 使用范例见 /pages/index/index.vue */ // mqtt协议:H5使用ws/wss APP-…...

EX_25/2/19
1. 封装一个 File 类,用有私有成员 File* fp 实现以下功能 File f "文件名" 要求打开该文件 f.write(string str) 要求将str数据写入文件中 string str f.read(int size) 从文件中读取最多size个字节,并将读取到的数据返回 析构函数 …...

Breakout Tool
思科 CML 使用起来还是很麻烦的,很多操作对于习惯了 secure crt 或者 putty 等工具的网络工程师都不友好。 Breakout Tool 提供对远程实验室中虚拟机控制台与图形界面的本地化接入能力,其核心特性如下: Console 访问:基于 Telnet…...

【大模型】DeepSeek:AI浪潮中的破局者
【大模型】DeepSeek:AI浪潮中的破局者 引言:AI 新时代的弄潮儿DeepSeek:横空出世展锋芒(一)诞生背景与发展历程(二)全球影响力初显 探秘 DeepSeek 的技术内核(一)独特的模…...

Kafka 简介
Kafka 简介 Apache Kafka 是一个开源的分布式流处理平台,广泛应用于实时数据流处理、日志管理、消息传递等场景。Kafka 最初由 LinkedIn 开发,并于 2011 年捐献给 Apache 软件基金会。 Kafka 的设计目标是高吞吐量、低延迟和高可用性,它能够…...
?——金融衍生品的关键工具(中英双语))
什么是掉期(Swap)?——金融衍生品的关键工具(中英双语)
什么是掉期(Swap)?——金融衍生品的关键工具 引言 掉期(Swap) 是金融市场中最重要的衍生品之一,它允许两方交换未来的现金流,以优化融资成本、规避利率或汇率风险,甚至进行投机交易…...

深入解析 Vue 项目中的缓存刷新机制:原理与实战
目录 前言1. Demo2. 知识拓展 前言 在 Vue 项目中,缓存通常用于存储用户信息、角色权限、系统设置等,以提高页面加载速度并减少 API 请求 这里使用 web-storage-cache 作为封装的本地存储工具,支持 localStorage 和 sessionStorage 方式存储…...

【C++】 Flow of Control
《C程序设计基础教程》——刘厚泉,李政伟,二零一三年九月版,学习笔记 文章目录 1、选择结构1.1、if 语句1.2、嵌套的 if 语句1.3、条件运算符 ?:1.4、switch 语句 2、循环结构2.1、while 语句2.2、do-while 语句2.3、 for 循环2.4、循环嵌套…...

【异常错误】pycharm debug view变量的时候显示不全,中间会以...显示
异常问题: 这个是在新版的pycharm中出现的,出现的问题,点击view后不全部显示,而是以...折叠显示 在setting中这么设置一下就好了: 解决办法: https://youtrack.jetbrains.com/issue/PY-75568/Large-stri…...

2.19c++练习
1.封装一个mystring类 拥有私有成员: char* p int len 需要让以下代码编译通过,并实现对应功能 mystring str "hello" mystring ptr; ptr.copy(str) ptr.append(str) ptr.show() 输出ptr代表的字符串 ptr.compare(str) 比较ptr和…...

【为什么使用`new DOMParser`可以保持SVG命名空间】
为什么使用new DOMParser可以保持SVG命名空间: 一、命名空间基础概念 1. XML命名空间定义 <svg xmlns"http://www.w3.org/2000/svg"><!-- 此元素及其子元素属于SVG命名空间 --><rect x"10" y"20"/> </svg>…...

【DL】浅谈深度学习中的知识蒸馏 | 输出层知识蒸馏
目录 一 核心概念与背景 二 输出层知识蒸馏 1 教师模型训练 2 软标签生成(Soft Targets) 3 学生模型训练 三 扩展 1 有效性分析 2 关键影响因素 3 变体 一 核心概念与背景 知识蒸馏(Knowledge Distillation, KD)是一种模…...

应急响应(linux 篇,以centos 7为例)
一、基础命令 1.查看已经登录的用户w 2.查看所有用户最近一次登录:lastlog 3.查看历史上登录的用户还有登录失败的用户 历史上所有登录成功的记录 last /var/log/wtmp 历史上所有登录失败的记录 Lastb /var/log/btmp 4.SSH登录日志 查看所有日志:…...

EasyRTC:智能硬件适配,实现多端音视频互动新突破
一、智能硬件全面支持,轻松跨越平台障碍 EasyRTC 采用前沿的智能硬件适配技术,无缝对接 Windows、macOS、Linux、Android、iOS 等主流操作系统,并全面拥抱 WebRTC 标准。这一特性确保了“一次开发,多端运行”的便捷性,…...

堆和栈的区别
堆和栈 不同点: 内存分配方式不同: 栈:栈上的内存是自动分配和释放的,通常用于存储函数调用过程中的局部变量、调用参数和使用的寄存器状态等信息。堆:堆上的内存是动态分配的,程序在运行时可以根据需要分…...

深度学习模型优化与实时推理技术解析
1. 深度学习模型优化基础解析 1.1 模型压缩技术原理与实践 模型压缩是深度学习优化领域的核心技术路线,其核心目标是在保持模型精度的前提下,显著减少计算量和内存占用。当前主流方法可分为四大类: 量化压缩 :将32位浮点参数转…...

从不及格到优秀论文,全靠这几个口碑炸裂的 AI 论文写作工具
还在为论文选题迷茫、初稿逻辑混乱、查重率爆表而焦虑?眼看截止日期逼近,熬夜几周写出的稿子仍被导师打回,评语满是 “结构松散、论据不足、AI 痕迹重”?别慌!2026 年6 款口碑炸裂的 AI 论文写作神器,从选题…...

Smithbox终极指南:5分钟掌握FromSoftware游戏修改的完整解决方案
Smithbox终极指南:5分钟掌握FromSoftware游戏修改的完整解决方案 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gi…...

SAP FI实操笔记:中日会计科目对照表,手把手教你配置GL主数据
SAP FI中日会计科目智能配置实战:从对照表到系统落地的全流程解析 当东京证券交易所的上市公司需要合并其在华子公司报表时,财务团队总会在会计科目转换环节遭遇"术语迷阵"。某日企财务总监曾向我展示过他们手工维护的Excel对照表——超过2000…...

终极指南:如何在Blender中无缝导入Rhino 3D文件
终极指南:如何在Blender中无缝导入Rhino 3D文件 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否曾经在Rhino中创建了精美的3D模型,却无法直接在Bl…...

2026年最新B站视频下载教程:3分钟掌握BiliTools跨平台下载神器
2026年最新B站视频下载教程:3分钟掌握BiliTools跨平台下载神器 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTool…...

重新定义Windows桌面美学:RoundedTB技术深度解析与实战应用
重新定义Windows桌面美学:RoundedTB技术深度解析与实战应用 【免费下载链接】RoundedTB Add margins, rounded corners and segments to your taskbars! 项目地址: https://gitcode.com/gh_mirrors/ro/RoundedTB 你是否曾对Windows任务栏的千篇一律感到厌倦&…...

网易云音乐油猴脚本:三分钟解锁周杰伦完整曲库与云盘快传的专业方案
网易云音乐油猴脚本:三分钟解锁周杰伦完整曲库与云盘快传的专业方案 【免费下载链接】myuserscripts 网易云音乐油猴脚本:歌曲下载、转存云盘、云盘歌曲快传、云盘匹配纠正... 项目地址: https://gitcode.com/gh_mirrors/my/myuserscripts 还在为网易云音乐中…...

Qwen3.5-4B-AWQ-4bit开源模型部署:腾讯云TI-ONE平台适配指南
Qwen3.5-4B-AWQ-4bit开源模型部署:腾讯云TI-ONE平台适配指南 1. 模型概述 Qwen3.5-4B-AWQ-4bit是阿里云通义千问团队推出的轻量级开源模型,采用4bit AWQ量化技术,在保持高性能的同时大幅降低资源需求。 1.1 核心优势 极致低资源ÿ…...

N_m3u8DL-RE:破解流媒体下载的三大技术难题
N_m3u8DL-RE:破解流媒体下载的三大技术难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 在当今流…...