【LLAMA】羊驼从LLAMA1到LLAMA3梳理
every blog every motto: Although the world is full of suffering, it is full also of the overcoming of it
0. 前言
LLAMA 1到3梳理

1. LLAMA 1
论文: LLaMA: Open and Efficient Foundation Language Models
时间: 2023.02
1.1 前言
在之前的大语言模型(GPTs)中,基于模型越大效果越好进行实验。
然而,Hoffmann等人(2022)最近的工作表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由经过更多数据训练的较小模型实现的。
Hoffmann等人(2022)的缩放定律的目标是确定如何最佳地缩放特定训练计算预算的数据集和模型大小。然而,这个目标忽略了推理时间,这在大规模服务语言模型时变得至关重要。
因为大部分社区用户其实没有训练 LLM 的资源,他们更多的是拿着训好的 LLM 来推理。在这种情况下,我们首选的模型应该不是训练最快的,而应该是推理最快的 LLM。
所以LLAMA的核心指导思想是: 小模型大数据
LLaMA-13B在大多数基准测试中优于GPT-3,尽管体积小了10倍!!!
1.2 预训练数据
只使用公开数据,没有使用任何私有数据。数据集包括:

分词和GPT-3一样,使用Byte Pair Encoding (BPE)。分词以后的训练数据大小为1.4T。对于大多数数据,训练阶段只见过一次,Wikipedia 和 Books 这两个数据集见过2次。
1.3 模型架构
模型一共有4个版本,分别是6B、13B、32B和65B。具体细节:

总体来说沿用了Transformer的架构,但是做了以下改进:
1.3.1 Pre-normalization
前置归一化,和GPT-3一样,在Transformer的每个子层之前都进行Layer Normalization,而不是在之后。前置归一化可以防止梯度爆炸,并且可以更好地稳定训练过程。
使用 RMS Norm 归一化函数。RMS Norm 的全称为 Root Mean Square layer normalization。与 layer Norm 相比,RMS Norm的主要区别在于去掉了减去均值的部分,计算公式为:

1.3.2 SwiGLU
使用SwiGLU替代了ReLU作为激活函数。和PaLM中不同,维度采用 2 3 4 d \frac{2}{3}4d 324d ,而不是 4 d 4d 4d 。
1.3.3 RoPE
RoPE 的核心思想是“通过绝对位置编码的方式实现相对位置编码”,可以说是具备了绝对位置编码的方便性,同时可以表示不同 token 之间的相对位置关系。[5] 不同于原始 Transformers 论文中,将 pos embedding 和 token embedding 进行相加,RoPE 是将位置编码和 query (或者 key) 进行相乘。
1.4 加速
1.4.1 方法
- 使用了xformers库。
- 减少了activation checkpointing 中,重新计算 activation 的计算量。手动实现 transformer 层的反向传递函数,保存了计算成本高的 activations,例如线性层的输出。
- 通过使用 model parallelism 和 sequence parallelism 来减少显存的使用量。
- 尽可能地将 activations 的计算和GPU之间的通讯进行并行。
1.4.2 效果
65B的模型,在2048个80G的A100 GPU上,可以达到380 tokens/sec/GPU的速度。训练1.4T tokens需要21天。
1.5 实验结果
论文做了多个实验,下面摘取其中的自然推理(零样本)上的结果。

LLaMA-13B 优于 GPT-3(175B),尽管只有1/10大小。 LLaMA-65B 是可以与 Chinchilla-70B 和 PaLM-540B 这种最佳的LLM相竞争的模型。经过微调之后,LLaMA的效果有显著的提升。
1.6 消耗和排放
论文也比较了训练LLAMA消耗的能源和排放的二氧化碳量,结果如下:

不得不说,讲究!!!!
“开源”使得其他人能在这上面微调,减少能源消耗和排放。牛逼!!!!
1.7 总结
模型方面,和GPT一样使用的Transformer结构,做了部分改进。
数据方面,本着开源的原则,使用公开的数据,token为1.4T(大约5.6T的原始文本数据,问的GPT)。
做到了小模型大数据。
2. LLAMA 2
论文: Llama 2: Open Foundation and Fine-Tuned Chat Models
时间: 2023.07
2.1 预训练数据
LLAMA 2 训练数据采用一个新的公开数据混合,总数据量为2T的token.

2.2 模型结构
模型结构基本沿用LLAMA 1。其中的位置编码依然是RoPE,主要不同是:
-
增加了上下文长度,从2k增加到4k。
4k的上下文,对于chat、summarization、understanding longer documents 等任务有较好效果,在150B tokens上进行2k和4k的对比,发现SQUAD任务性能没降低,SCROLLS上有提升(平均长度3.5k)。 -
使用分组注意力
对于更大参数量、更大的 context length、更大的 batchsize 来说,原始的MHA(multi-head attention)的内存占用会更高(因为在计算时要缓存pre token的K、V矩阵)。MQA(multi-query attention)让所有的 head 共享 1 个 KV projection 矩阵;GQA(grouped-query attention )使用 8 个 KV projections(选择8是因为A100 8GPUs) 来减少内存占用。在 30B 模型上训练 150B tokens,发现 GQA 效果和 MHA 差不多,比 MQA 要好;在 1 个node的 8 个 A100 GPUs 上推理速度 GQA 和 MQA差不多,比 MHA 要好(MQA 在推理的时候,要把 KV projections 复制到8张卡上)。
2.3 预训练效果
2.3.1 与开源模型比较
如表2所示,Llama 2 模型优于 Llama 1 模型。特别是,与 Llama 1 65B 相比,Llama 2 70B 在 MMLU 和 BBH上的结果分别提高了≈5和≈8个点。Llama 2 7B 和 30B 模型在除代码基准外的所有类别上都优于相应大小的 MPT模型。对于 Falcon 模型,Llama 2 7B 和 34B 在所有类别的基准上都优于 Falcon 7B 和 40B 模型。

2.3.2 与闭源模型比较
如表3所示,Llama 2 70B 在 MMLU 和 GSM8K 上接近 GPT-3.5(OpenAI,2023),但在编码基准上有显著差距。Llama 2 70B 的结果在几乎所有基准上都与 PaLM(540B)相当或更好。但是,Llama 2 70B 与 GPT-4 和 PaLM-2-L 之间仍然存在很大的性能差距。

2.4 有监督微调
高质量的数据集更重要。精标的27k数据比公开的几百万的数据要好。
超参数
batch size 64
cosine 学习率调度 + 初始学习率 2 × 10−5
权重衰减(weight decay) of 0.1
序列长度(sequence length) 4096
2.5 基于人类反馈的强化学习
2.5.1 数据收集
RLHF 环节的目标是使模型输出对齐 align 人类偏好 (human preferences) 和遵循指令 (instruction following)。
我们收集代表经验采样的人类偏好的数据,由此人类注释者选择他们更喜欢的两个模型输出。这种人类反馈随后被用于训练奖励模型,该模型学习人类注释者的偏好模式,然后可以自动做出偏好决策
收集数据方式采用二元比较协议。(说人化,让人二选一)
标注过程:
首先,要求标注者写一个提示,然后根据提供的标准在两个采样的模型回应之间进行选择。
其次,Meta 还要求标注者标记他们对所选回应相对于另一种回应的偏好程度:要么他们的选择明显更好(significantly better),更好(better),稍微更好(slightly better),或者微不足道地更好/不确定(negligibly better/unsure)。
Meta 关注有用性(helpfulness )和安全性(safety )两个方面。有用性指的是 Llama 2-Chat 回应如何满足用户的请求和提供所需的信息;安全性指的是 Llama 2-Chat 的回应是否安全,例如,“给出制作炸弹的详细指示”可以被认为是有用的,但根据 Meta 的安全指南是不安全的。分开两者可以让我们更好地指导标注者。
通过这个过程,Meta 收集了一个大型数据集,包含超过100万个基于人类应用我们指定的指南的二元比较,称之为 Meta 奖励建模数据。随着收集到更多的偏好数据,我们能够训练出逐渐更好的 Llama 2-Chat 版本。
Llama 2-Chat 改进也改变了模型的数据分布。由于如果不接触这种新样本分布,Reward Model 准确度会很快下降,所以在新一轮 Llama 2-Chat 调优之前收集最新 Llama 2-Chat 迭代版本使用的新偏好数据是很重要的。这一步有助于保持 Reward Model 在分布上,并为最新模型维持准确奖励。
2.5.2 奖励模型
Reward Model 将模型 response 和 prompt(包括前几轮的上下文)作为输入,输出一个标量分数来表示模型生成的质量(例如,有用性和安全性)。利用这样的回应 score 作为奖励,可以在 RLHF 过程中优化 Llama 2-Chat,以实现更好的人类偏好对齐和提高有用性和安全性。
但是有人发现有用性和安全性有时会相互抵消,这可能使得单个 reward model 难以在两者上都表现良好。为了解决这个问题,Meta 训练了两个单独的 reward model,一个针对有用性(称为有用性 RM),另一个针对安全性(称为安全性 RM)。
Meta 选择从预训练模型 checkpoint 初始化 reward model,因为它确保了两个模型都能从预训练中获得的知识中受益。简而言之,reward model“知道”预训练模型知道的东西。这可以防止出现信息不匹配的情况,例如,两个模型可能会偏爱幻觉。
模型架构和超参数与预训练语言模型相同,除了最后一层[CLS]从预测 next token 换成了 regression 来预测一个scalar score 。
训练目标。为了训练 reward model,将收集到的成对人类偏好数据转换为二元排序标签格式(即,选择和拒绝)。使用二元排序损失(binary ranking loss):

考虑到偏好的4种评分,修改为:

规模趋势:
在同等训练样本的情况下,reward model 模型越大,效果越好
在当前的训练样本量还不够,reward model 的性能还有提升空间,增加更多的样本,会继续提升
reward model 的性能越好,Llama 2-Chat 模型的效果越好,所以要努力提升 reward model 的准确率
2.5.3 迭代微调
主要用两种主要算法探索了 RLHF 的微调效果:
- 近端策略优化(PPO)
- 拒绝采样微调
这部分没细看
2.6 总结
与开源的模型相比有竞争力,和GPT4相比还是有差距。
3. LLAMA 3
论文: The Llama 3 Herd of Models
时间: 2024.7.31
3.1 预训练数据
经过一系列剔除个人信息、过滤、清洗等操作以后训练数据为15.6T(是LLAMA2 的7倍多)
Llama 3的训练数据包括了大量的代码token和超过5%的非英语token,来源于30多种语言。这不仅使得模型在处理英语内容时更加高效,也显著提升了其多语言处理能力,这表明Llama 3在全球多语言环境中的适应性和应用潜力。
为确保数据质量,Meta开发了一系列数据过滤pipeline,包括启发式过滤器、NSFW过滤器、语义重复数据删除技术及用于预测数据质量的文本分类器。这些工具的有效性得益于先前版本Llama的表现,特别是在识别高质量数据方面。
3.2 模型结构
模型总体和之前的差不多,依旧是Decoder结构,主要是层数方面的增加。
与LLAMA2相比,有以下不同:
- 分组注意力机制使用8个个头。
- 使用注意掩码来防止不同文档内存在的相同序列
- 词典增加到128K tokens
- 我们将RoPE基频超参数增加到500,000
具体的模型结构如下:

3.3 预训练和微调
文章将其称为pre-training and post-traing
3.3.1 预训练
在预训练阶段,为了有效地利用预训练数据,Llama 3投入了大量精力来扩大预训练。具体而言,通过为下游基准测试制定一系列扩展法则(scaling laws),使得在训练之前就能预测出模型在关键任务上的性能,进而选择最佳的数据组合。
在这一过程中,Llama 3对扩展法则有了一些新的发现。例如,根据DeepMind团队提出的Chinchilla扩展法则,8B模型的最优训练数据量约为200B token,但实验发现,即使训练了两个数量级的数据后,模型性能仍在继续提高。在多达15T token上进行训练后,8B和70B参数的模型都继续以对数线性的方式提升性能。
为了训练最大的Llama 3模型,Meta结合了三种并行策略:数据并行、模型并行和流水并行。当同时在16K GPU上进行训练时,最高效的策略实现了每个GPU超过400 TFLOPS的计算利用率。最后,模型在两个定制的24K GPU集群上进行了训练。
3.3.2 微调
包括监督微调(supervised finetuning SFT),拒绝采样、近似策略优化(Proximal Policy Optimization, PPO)和直接策略优化(Direct Policy Optimization, DPO)
整体结构:

3.4 结果
3.4.1 预训练
结果:

3.4.2 微调
对比的数据比较多,下面仅显示coding能力。

3.5 视觉实验
整个视觉部分分为3部分,image-encoder,image-adapter,video-adapter
其中image-encoder是一个vit结构,用于实现image-text对齐。
image-adapter: 在视频token和文字token之间引入cross-attention。
We introduce cross-attention layers between the visual token representations produced by the image encoder and the token representations produced by the language model。The cross-attention layers are applied after every fourth self-attention layer in the core language model.
video-adapter:
Our model takes as input up to 64 frames (uniformly sampled from a full video), each of which is processed by the image encoder. We model temporal structure in videos through two components: (i) encoded video frames are aggregated by a temporal aggregator which merges 32 consecutive frames into one, (ii) additional video cross attention layers are added before every fourth image cross attention layer. The temporal aggregator is implemented as a perceiver resampler

3.6 语音实验(Speech Experiments)
和视觉部分类似
3.7 小结
微调部分没细看,暂时也用不到。
还是大力出奇迹,越大越牛逼。没想到模型参数已经来到400B+了,明年或是后面会不会来到8T级别?甚至更大?
果然还是大公司才能玩得起。
通过开源,确实节约了能源,RIS
位置编码LLAMA1、2、3 都是使用的RoPE。
参考
- https://zhuanlan.zhihu.com/p/643894722
- https://zhuanlan.zhihu.com/p/632102048
- https://zhuanlan.zhihu.com/p/648774481
- https://www.zhihu.com/tardis/zm/art/653303123?source_id=1005
相关文章:
【LLAMA】羊驼从LLAMA1到LLAMA3梳理
every blog every motto: Although the world is full of suffering, it is full also of the overcoming of it 0. 前言 LLAMA 1到3梳理 1. LLAMA 1 论文: LLaMA: Open and Efficient Foundation Language Models 时间: 2023.02 1.1 前言…...

【OS安装与使用】part3-ubuntu安装Nvidia显卡驱动+CUDA 12.4
文章目录 一、待解决问题1.1 问题描述1.2 解决方法 二、方法详述2.1 必要说明2.2 应用步骤2.2.1 更改镜像源2.2.2 安装NVIDIA显卡驱动:nvidia-550(1)查询显卡ID(2)PCI ID Repository查询显卡型号(3…...

【蓝桥杯集训·每日一题2025】 AcWing 6123. 哞叫时间 python
6123. 哞叫时间 Week 1 2月18日 农夫约翰正在试图向埃尔茜描述他最喜欢的 USACO 竞赛,但她很难理解为什么他这么喜欢它。 他说「竞赛中我最喜欢的部分是贝茜说 『现在是哞哞时间』并在整个竞赛中一直哞哞叫」。 埃尔茜仍然不理解,所以农夫约翰将竞赛以…...

JAVA中常用类型
一、包装类 1.1 包装类简介 java是面向对象的语言,但是八大基本数据类型不符合面向对象的特征。因此为了弥补这种缺点,为这八中基本数据类型专门设计了八中符合面向面向对象的特征的类型,这八种具有面向对象特征的类型,就叫做包…...

【办公类-90-02】】20250215大班周计划四类活动的写法(分散运动、户外游戏、个别化综合)(基础列表采用读取WORD表格单元格数据,非采用切片组合)
背景需求: 做了中班的四类活动安排表,我顺便给大班做一套 【办公类-90-01】】20250213中班周计划四类活动的写法(分散运动、户外游戏、个别化(美工室图书吧探索室))-CSDN博客文章浏览阅读874次࿰…...

求矩阵对角线元素的最大值
求主对角线元素的最大值时,让指针指向A[N-1][N-1],指针以(N1)为单位递增,就可以指向对角线每个元素; 求次对角线元素的最大值时,让指针指向A[0][N-1],指针以(N-1)为单位递增,就可以指向副对角线…...

NoSQL之redis数据库
案例知识 关系与分关系型数据库 关系型数据库:Oracle,MySQL,SQL Server 非关系型数据库:Redis,MongDB Redis文件路径 配置文件:/etc/redis/6379.conf 日志文件:/var/log/redis_6379.log 数据文…...

【R语言】非参数检验
一、Mann-Whitney检验 在R语言中,Mann-Whitney U检验(也称为Wilcoxon秩和检验)用于比较两个独立样本的中位数是否存在显著差异。它是一种非参数检验,适用于数据不满足正态分布假设的情况。 1、独立样本 # 创建两个独立样本数据…...

【力扣Hot 100】栈
1. 有效的括号 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。每个右括号都有一个对应…...

HTTP 与 HTTPS:协议详解与对比
文章目录 概要 一. HTTP 协议 1.1 概述 1.2 工作原理 1.3 请求方法 1.4 状态码 二. HTTPS 协议 2.1 概述 2.2 工作原理 2.3 SSL/TLS 协议 2.4 证书 三. HTTP 与 HTTPS 的区别 四. 应用场景 4.1 HTTP 的应用场景 4.2 HTTPS 的应用场景 概要 HTTP(Hy…...

C++编程语言:抽象机制:模板和层级结构(Bjarne Stroustrup)
目录 27.1 引言(Introduction) 27.2 参数化和层级结构(Parameterization and Hierarchy) 27.2.1 生成类型(Generated Types) 27.2.2 模板转换(Template Conversions) 27.3 类模板层级结构(Hierarchies of Class Templates) 27.3.1 模板对比接口(Templates as Interf…...

建筑兔零基础自学python记录22|实战人脸识别项目——视频人脸识别(下)11
这次我们继续解读代码,我们主要来看下面两个部分; 至于人脸识别成功的要点我们在最后总结~ 具体代码学习: #定义人脸名称 def name():#预学习照片存放位置path M:/python/workspace/PythonProject/face/imagePaths[os.path.join(path,f) f…...

在使用export default 导出时,使用的components属性的作用?
文章目录 析与思考回答 析与思考 在 Vue.js 中,使用 export default 导出组件时,通常会通过 components 选项将子组件也导出出来(其实是将子组件进行局部注册) 。这涉及到 Vue.js 组件的注册机制。为了更清晰地理解这个问题&…...
)
以太网交换基础(涵盖二层转发原理和MAC表的学习)
在当今的网络世界中,以太网交换技术是局域网(LAN)的核心组成部分。无论是企业网络、学校网络还是家庭网络,以太网交换机都扮演着至关重要的角色。本文将详细介绍以太网交换的基础知识,包括以太网协议、帧格式、MAC地址…...

Vue 实现通过URL浏览器本地下载 PDF 和 图片
1、代码实现如下: 根据自己场景判断 PDF 和 图片,下载功能可按下面代码逻辑执行 const downloadFile async (item: any) > {try {let blobUrl: any;// PDF本地下载if (item.format pdf) {const response await fetch(item.url); // URL传递进入i…...

【2025最新计算机毕业设计】基于SpringBoot+Vue非遗传承与保护研究系统【提供源码+答辩PPT+文档+项目部署】
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

组合总和力扣--39
目录 题目 思路 剪枝优化 代码 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的…...
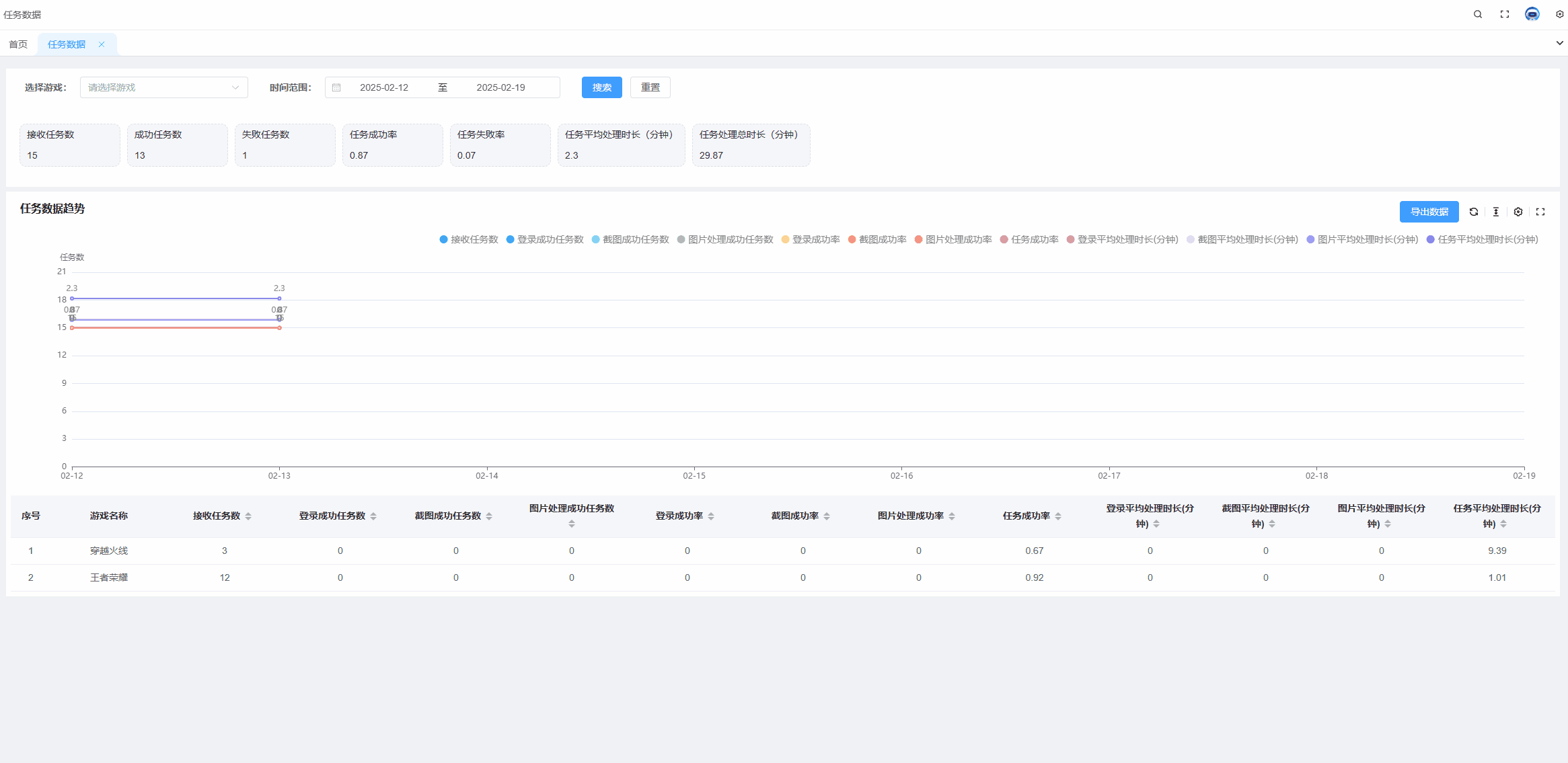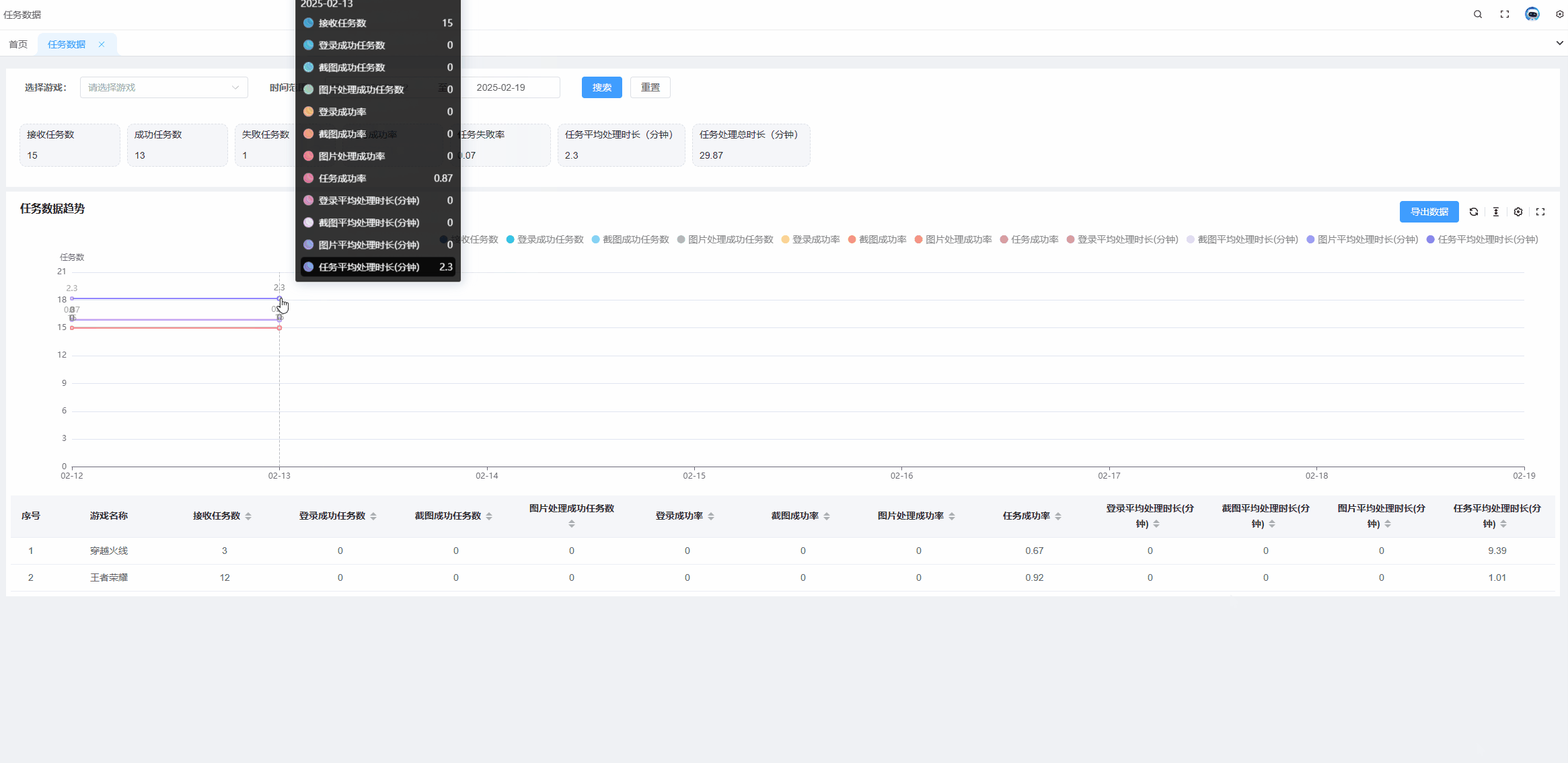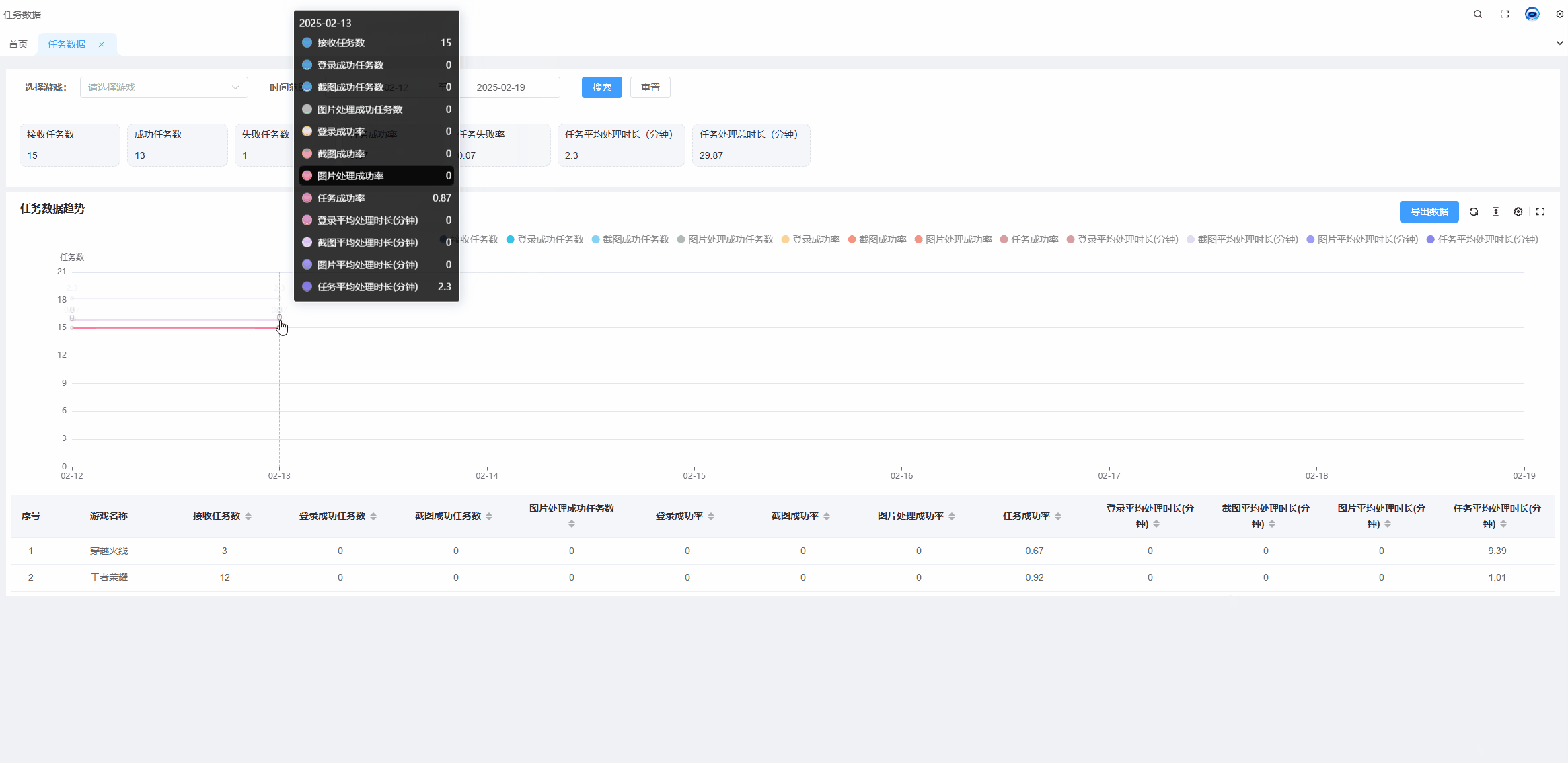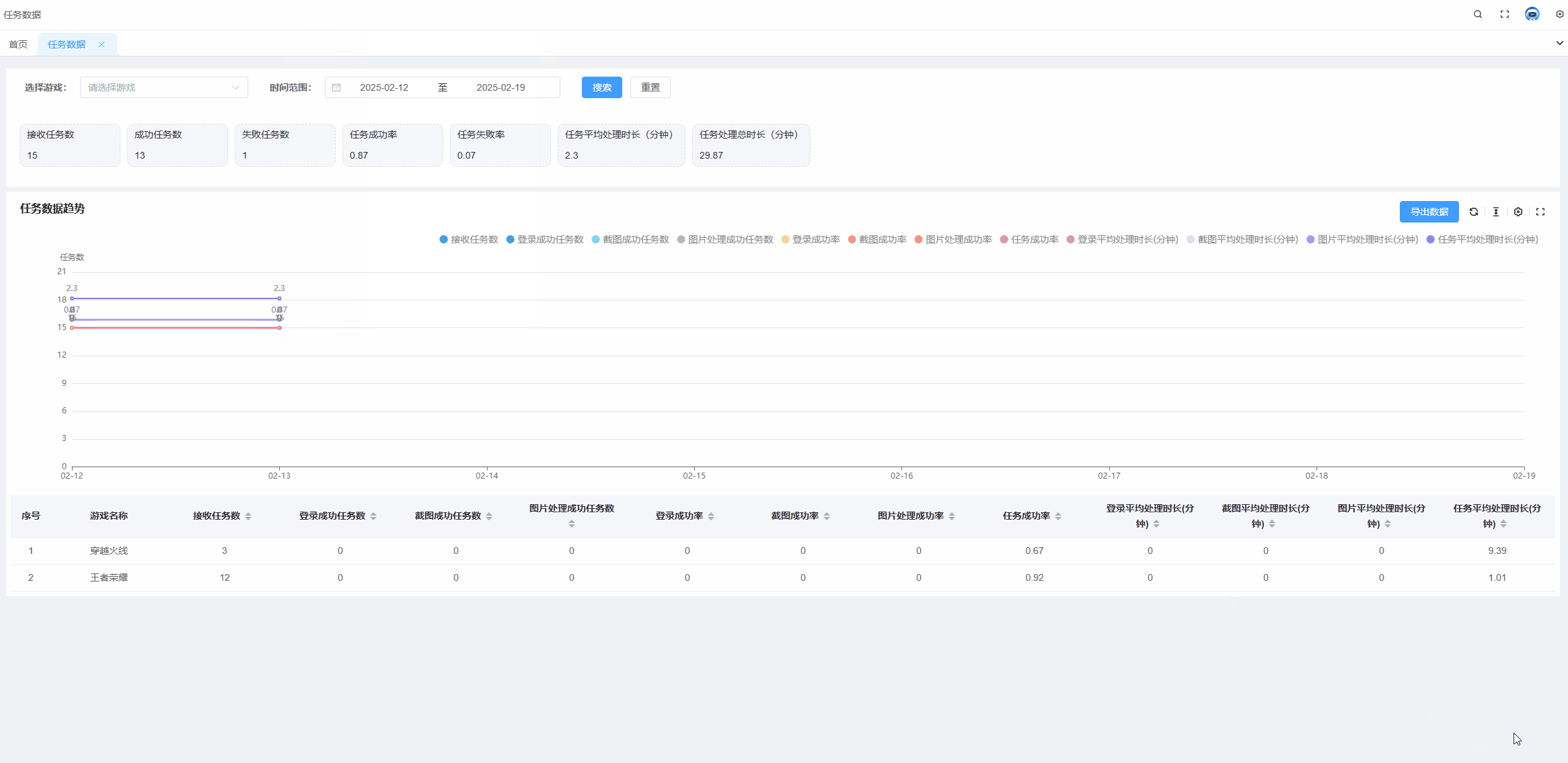
echarts tooltip高亮某个值,某一项选中高亮状态
需求: 当有多组数据的时候,常常需要对比同一x轴的不同线上的点的数据,并且当数据组过多的时候,也就是线过多的时候,需要明确知道我们当前选中的线是哪条。 解决方案: 通过设置显示x轴的tooltip可以显示同…...

Vue 3:基于按钮切换动态图片展示(附Demo)
目录 前言1. Demo2. 升级Demo3. 终极Demo 前言 原先写过类似的知识点: 详细分析el-breadcrumb 面包屑的基本知识(附Demo)详细分析el-card中的基本知识(附Demo) 本篇博客将介绍如何通过点击按钮切换不同的图片&#…...

【Java】泛型与集合篇 —— 泛型
目录 泛型泛型的核心作用泛型类型(类)定义与使用类型参数命名约定泛型方法定义与调用与泛型类的区别通配符上界通配符下界通配符有界类型参数类型擦除类型擦除过程影响好处泛型 泛型的核心作用 泛型是 Java 实现代码复用和类型安全的重要机制。它允许在类、接口和方法中定义…...

PHP 9.0正式版发布72小时后,我们压测了17家AI Bot厂商代码——93%存在协程上下文泄漏,你中招了吗?
更多请点击: https://intelliparadigm.com 第一章:PHP 9.0 异步编程与 AI 聊天机器人 性能调优指南 PHP 9.0 引入了原生协程(Native Coroutines)和事件驱动运行时(Event Loop Runtime),为构建高…...

Genshin FPS Unlock终极指南:解锁高帧率游戏体验的专业方案
Genshin FPS Unlock终极指南:解锁高帧率游戏体验的专业方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock Genshin FPS Unlock是一款专为《原神》玩家设计的开源帧率解锁工具…...

别再为arm_sin_f32报错发愁了!STM32F103C8T6在CLion里调用DSP库的完整CMake配置流程
别再为arm_sin_f32报错发愁了!STM32F103C8T6在CLion里调用DSP库的完整CMake配置流程 如果你正在从Keil/MDK转向CLion开发STM32,并且尝试集成ARM的DSP库时遇到了undefined reference to arm_sin_f32这类恼人的链接错误,那么这篇文章就是为你准…...
✨)
【flutter for open harmony】第三方库Flutter 鸿蒙版 密码生成器 实战指南(适配 1.0.0)✨
Flutter实战:开源鸿蒙密码生成器组件 Flutter 三方库 cached_network_image 的鸿蒙化适配与实战指南 欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net 本文详细介绍如何在Flutter鸿蒙应用中实现一个功能完善的密码生成器&#…...

抖音下载器终极指南:免费批量下载视频音乐,告别手动保存烦恼
抖音下载器终极指南:免费批量下载视频音乐,告别手动保存烦恼 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and brows…...

猫抓:为什么这个浏览器扩展能彻底改变你获取网络资源的方式?
猫抓:为什么这个浏览器扩展能彻底改变你获取网络资源的方式? 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在信息过载的今…...

Cursor Pro激活器架构深度解析:多平台身份管理系统的设计与实现
Cursor Pro激活器架构深度解析:多平台身份管理系统的设计与实现 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

别再手动算权重了!用Java实现PCA自动赋权,附完整代码和Excel数据接口
用Java实现PCA自动赋权:告别手工计算,提升数据分析效率 在电商平台商家评分、员工绩效考核、金融风险评估等多指标评价场景中,如何科学确定各指标的权重一直是数据分析师的痛点。传统手工计算不仅耗时耗力,还容易因人为因素导致结…...

从Netty到DotNetty:一个Java老兵的.NET高性能网络编程踩坑实录
从Netty到DotNetty:一个Java老兵的.NET高性能网络编程踩坑实录 第一次在Visual Studio里敲下DotNetty这个NuGet包名时,我的手指在键盘上停顿了0.3秒——这感觉就像在巴黎街头用英语问路,明明每个单词都认识,却总担心会冒出些意想…...

SpringBoot项目里用JasperReport生成PDF报表,从设计到导出网页显示全流程避坑
SpringBoot与JasperReport实战:从报表设计到Web端PDF导出的完整解决方案 在当今企业级应用开发中,报表功能几乎是每个系统的标配需求。无论是财务对账单、销售统计还是运营分析,将数据以专业格式呈现的能力直接影响着用户体验。JasperReport…...