第1章大型互联网公司的基础架构——1.11 消息中间件技术
消息队列(Message Queue)是分布式系统中最重要的中间件之一,在服务架构设计中被广泛使用。
1.11.1 通信模式与用途
消息中间件构建了这样的通信模式:
- 一条消息由生产者创建,并被投递到存放消息的队列中;
- 消费者从队列中读取这条消息,于是生产者与消费者完成了一次通信。
这种通信模式在现实生活中很常见,典型的例子是E-mail通信:
住在北京的张三想把一个重要但不紧急的消息告诉住在上海的李四,张三给李四打电话,但是李四正在忙其他的事情而未接电话,张三为了把消息传达给李四,只能不停地拨打电话直到李四接听,这无疑浪费了张三大量的时间。于是,张三选择将消息使用E-mail的方式发送,他只需要把邮件投递到李四的收件箱中就可以去忙其他的事情了,而不用去管李四是否繁忙,E-mail系统保证只要李四空闲下来查看收件箱,就必然会收到张三的消息。对于消息中间件而言,张三和李四分别是生产者和消费者,E-mail系统就是消息队列。
消息队列的通信模式为生产者和消费者带来了便捷性,如下所述。
- 生产者将消息投递到消息队列中就单方面完成了消息通信,比如张三只需要发送邮件,而不用等待李四阅读邮件。
- 消费者在自身有能力消费消息时才从消息队列中拉取新消息,比如李四今天非常忙碌,那么他可以明天再登录E-mail系统阅读邮件。
正是因为消息队列为生产者和消费者提供了便利,所以它被广泛应用于分布式系统。下面介绍消息队列的几个核心用途。
- 异步处理
- 流量削峰
- 服务解耦
(1)异步处理
在未使用消息队列的系统中,一些非必要的业务逻辑以同步方式运行,导致请求处理耗时较大。比如图1-48所示的业务场景,一个用户请求需要串行地经过A、B、C、D四个服务处理,其中:
- A服务是此业务场景的核心服务,请求处理仅需10ms;
- B、C、D服务是非核心服务,请求处理时间分别是200ms、300ms、100ms。

所以一个用户请求需要耗时610ms才能得到响应。
使用消息队列后,A服务可以将请求相关消息写入消息队列,然后直接返回响应消息, 而不用关心B、C、D服务是否已经处理请求,以及是否遇到故障;B、C、D服务异步地从消息队列中拉取消息进行相应的业务逻辑处理。这样一来,用户请求的响应时间被大幅降低到10ms,如图1-49所示。

(2)流量削峰
通过E-mail系统,李四可以根据自己是否有空来选择阅读或者不阅读收件箱中的邮件,以及阅读几封邮件。对于消息队列的消费者来说也是一样的,消费者服务完全可以根据自己的消息处理能力灵活地读取消息,这样的灵活度能有效提高服务的稳定性。消息队列使得消费者服务拥有处理请求的主动权,再也不用担心自己会被击垮了。
举一个例子,A服务使用数据库作为处理请求的核心,当A服务面临流量高峰时,全部请求都会直接访问数据库,导致数据库宕机,进而A服务崩溃。如果请求并不要求立即执行,则可以先将请求写入消息队列,A服务根据自己的处理能力从消息队列中慢慢拉取消息进行相应的请求处理。
如图1-50所示,假设A服务1s仅可以处理100个请求,流量高峰时10000 QPS会直接击垮A服务,而通过消息队列的形式,A服务可以根据自己的请求处理速度来拉取消息,在整个链路上原来的请求量10000 QPS被平滑为100 QPS,这就是流量削峰。

(3)服务解耦
在未使用消息队列时,服务之间的耦合性太强,如果B服务想加入A服务的请求处理流程,则需要在A服务中实现对B服务的RPC逻辑。假设在系统中有3个服务,如下所述。
- 点赞服务:负责处理用户对文章的点赞请求,主要业务逻辑是为用户和文章建立已点赞的关系记录。
- 热点服务:根据每篇文章的被点赞次数,给出当前最热门的文章列表。
- 策略服务:分析每个用户的点赞文章类型,以便可以将同类型的文章推荐给该用户。
热点服务和策略服务都想实时获取用户点赞行为,为此,我们只能在点赞服务对用户点赞请求的处理逻辑中增加对这两个服务的RPC。如果将来有服务也想要收集用户点赞行为,或者策略服务下线,则需要改造点赞服务,于是所有依赖用户点赞行为的服务都与点赞服务形成了耦合,如图1-51所示。

在系统中引入消息队列后,这种耦合关系得到完全解耦:点赞服务将在处理用户点赞请求时顺便将点赞事件发送到消息队列,任何希望收集用户点赞行为的服务只需要被配置成这个消息队列的消费者,而不会对点赞服务有任何影响。
如图1-52所示,通过引入消息队列,点赞服务与其他服务彻底解耦,每个服务的负责人只需要专注于自己的服务,这样也解决了一个大规模后台中多部门或多人协作的职责分离问题,减少了事故的发生。

1.11.2 Kafka的重要概念和原理
Kafka是一个分布式、高性能、高可扩展性的消息队列系统,最初由LinkedIn开发,在2010年成为Apache基金会旗下的开源项目。Kafka的主要应用场景是日志收集系统和消息中间件,其整体架构如图1-53所示。

我们结合图1-53所示的Kafka整体架构来介绍Kafka的重要概念和原理。
- Producer(生产者)和Consumer(消费者):它们很好理解,前者生产消息,后者消费消息。
- Topic(主题):每个发送到Kafka的消息都有自己的Topic,可以将其理解为消息的类型,比如上一节提到的用户点赞事件就是一个Topic。生产者发送某Topic的消息,消费者订阅该Topic的消息。
- Partition(分区):一个Topic将消息数据分布式地存储在多个Partition中。这个Partition与存储系统的数据分片概念相同,都是将全量数据拆分为多个分区存储,以便实现负载均衡。每个Partition存储的消息都是基于Key有序的,不同Partition之间的消息不保证有序。Partition由Broker管理。
- Broker:Broker是Kafka的核心,负责接收消息、将消息存储到Partition,以及处理消费者的消费消息逻辑。多个Broker组成Kafka Cluster( Kafka集群)。Kafka使用全局唯一的Broker ID为每个Broker编号。
- Consumer Group(消费者组):多个消费者实例组成一个Consumer Group, 一个 Topic对应的消费对象是Consumer Group。
- ZooKeeper:负责Kafka集群元信息的管理工作,将包括Kafka的生产者、消费者和Broker在内的所有组件在无状态的情况下建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
ZooKeeper具体负责的内容包括但不限于如下内容。
- Broker注册:每个Broker实例都需要把自己的Broker ID、IP地址和端口号注册到ZooKeeper中。如果某Broker实例宕机,则ZooKeeper会删除其地址信息。ZooKeeper实现了 Kafka集群的服务发现功能。
- Topic元信息管理:一个Topic会创建多个Partition并分布在多个Broker上,每个Topic的Partition与Broker的关联关系也由ZooKeeper维护。
- 生产者负载均衡:每个生产者都需要决定它生产的消息应该被写入哪个Partition。由于ZooKeeper中保存了Broker地址信息与Topic元信息,因此生产者可以根据ZooKeeper实现消息写入的负载均衡。
- 消费者负载均衡:Kafka规定一个Partition消息只能被Consumer Group中的一个消费者实例消费,ZooKeeper负责记录“哪个消费者实例消费哪个Partition消息”这样的消费关系。另外,当某个消费者实例宕机后,ZooKeeper可以对相应的Consumer Group做Rebalance,以便保证每个Partition消息一直都在被消费。比如Consumer i消费Partition 1消息时宕机,ZooKeeper将对相应的Consumer Group进行Rebalance,然后可以选择让Consumer j继续消费Partition 1。
- 消费进度Offset记录:消费者实例在消费Partition消息的过程中,ZooKeeper定时记录消息的消费进度Offset,以便消费者实例重启或Consumer Group发生Rebalance后,可以从之前的Partition Offset位置继续消费消息。不过,这个功能的写性能不佳,Kafka 0.9版本不再将消费进度Offset保存到ZooKeeper,而是保存到Broker本地磁盘。
当生产者向某Topic发送消息时,首先要决定将消息存储到哪个Partition:
- 如果消息指定了 Partition,则直接使用它;
- 如果消息未指定Partition,但是消息设置了 Key,则对Key做哈希运算后选出一个Partition ;
- 如果消息既未指定Partition也未指定Key,则轮询选择一个Partition。
然后,生产者将消息发送到所选出的Partition对应的Broker节点,Broker收到消息后将其顺序写入磁盘,消息写入完成,如图1-54所示。

消费者以Consumer Group方式工作,一个Consumer Group可以消费多个Topic,,— 个Topic也可以被多个Consumer Group消费。当某Topic被一个Consumer Group消费时,每个Partition消息只能被一个消费者实例消费,但是一个消费者实例可以消费多个Partition消息,如图1-55所示。

这个限制表明,如果Topic有10个Partition,而Consumer Group有20个消费者实例,那么就有10个实例处于空闲状态。
消费者采用拉取(pull)的方式消费Partition消息,这样才能由消费者自己控制消费消息的速度,以便实现消息队列的削峰能力。
1.11.3 Kafka的高可用
为了实现高可用性,Kafka允许一个Partition拥有多个消息副本(Replica),每个Partition的副本由1个Leader和若干Follower组成。生产者发送消息实际上写入的是Partition的Leader,而Follower则会周期性地向Leader请求消息复制,以保证Leader与 Follower之间的数据一致性。不只是生产者发送消息到Leader,消费者消费的也是Leader中的消息,Follower的用途是作为Leader的数据备份,用于在Leader所在的Broker宕机后接管Partition的读/写,尽可能保证消息不丢失。
需要强调的是,如果一个Partition的所有副本都被存储到同一个Broker上,那么Broker宕机后会造成这个Partition完全不可用,达不到高可用性的效果。所以,Kafka会尽可能将一个Partition的每个副本都存储到不同的Broker上。
那么,将一条消息写入Partition,是写入Leader就算成功,还是所有Follower都已同步这条消息才算成功?这要看Leader和Follower的数据复制需要哪种机制。
- 同步复制:所有的Follower都已复制此消息才认为消息写入成功。在这种机制下,Leader与Follower数据一致性高,但是一旦某个Follower复制速度太慢或者宕机,就会直接劣化消息写入的性能和可用性。
- 异步复制:只要Leader收到消息就认为消息写入成功,并不关心Follower是否已复制此消息。在这种机制下,消息写入的性能高、可用性高,但是数据一致性得不到保证。
Kafka采用的数据复制机制既不是完全的同步复制,也不是完全的异步复制,而是ISR机制:
- 每个Partition的Leader都会维护与其保持数据一致的Follower列表,该列表被称为ISR(In-Sync Replica)。
- 如果一个Follower长时间未发起数据复制,或者其数据落后于Leader太多,那么Leader会将这个Follower从ISR中移除;
- 在Partition写入消息时,只有ISR中所有的Follower都已确认收到此消息,Leader才认为消息写入成功。
- Leader会根据Follower状态动态地变更ISR,并将变更结果同步到ZooKeeper中。
ISR机制其实是同步复制和异步复制的折中,它可以很好地避免某Follower宕机对消息队列的可用性、性能的影响,也在一定程度上保证了多副本间数据的一致性。
多副本能够保证当Broker发生故障时相关的Partition依然有数据备份,那么Kafka如何使用数据备份进行故障恢复呢?
Kafka 0.8版本引入了Partition Leader选举与故障恢复机制。
- 首先,需要在Kafka集群的所有Broker中选举一个Controller角色,用于负责Partition Leader选举和副本重分配工作。
- 当Leader发生故障时,Controller会将Partition的最新Leader、Follower变动通知到相关Broker。
- Broker选举Controller借助了ZooKeeper的分布式锁能力,哪个Broker先抢到锁,它就是Controller。
Controller帮助Broker进行故障恢复的详细过程如图1-56所示。

- 某Broker发生故障,与ZooKeeper断开连接。
- ZooKeeper认为此Broker已下线,于是删除该Broker节点。
- ZooKeeper通知Controller这个Broker已下线。
- Controller向ZooKeeper查询哪些Topic Partition的Leader副本由这个Broker负责,得到的结果是受影响的、需要重新选举Leader的Partition。
- Controller从每个Partition Leader ISR中选择一个Follower,准备将其提升为Leader。
- Controller将选举结果通知到各相关Broker。
- 被选举出的Follower变为Leader,其他Follower转而向新的Leader复制数据。
至此,我们已经对互联网应用后台机房架构的主要组件做了较为完整的介绍,不过目前仅局限于一个机房内部。接下来从更为宏观的视角来探讨多机房架构的建设。
总结
消息队列的作用?
- 异步处理
- 流量削峰
- 服务解耦
介绍以下Kafka的整体结构?
- Producer(生产者)和Consumer(消费者):它们很好理解,前者生产消息,后者消费消息。
- Topic(主题):每个发送到Kafka的消息都有自己的Topic,可以将其理解为消息的类型,比如上一节提到的用户点赞事件就是一个Topic。生产者发送某Topic的消息,消费者订阅该Topic的消息。
- Partition(分区):一个Topic将消息数据分布式地存储在多个Partition中。这个Partition与存储系统的数据分片概念相同,都是将全量数据拆分为多个分区存储,以便实现负载均衡。每个Partition存储的消息都是基于Key有序的,不同Partition之间的消息不保证有序。Partition由Broker管理。
- Broker:Broker是Kafka的核心,负责接收消息、将消息存储到Partition,以及处理消费者的消费消息逻辑。多个Broker组成Kafka Cluster( Kafka集群)。Kafka使用全局唯一的Broker ID为每个Broker编号。
- Consumer Group(消费者组):多个消费者实例组成一个Consumer Group, 一个 Topic对应的消费对象是Consumer Group。
- ZooKeeper:负责Kafka集群元信息的管理工作,将包括Kafka的生产者、消费者和Broker在内的所有组件在无状态的情况下建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
ZooKeeper具体负责的内容大体包括哪些?
- Broker注册:每个Broker实例都需要把自己的Broker ID、IP地址和端口号注册到ZooKeeper中。如果某Broker实例宕机,则ZooKeeper会删除其地址信息。ZooKeeper实现了 Kafka集群的服务发现功能。
- Topic元信息管理:一个Topic会创建多个Partition并分布在多个Broker上,每个Topic的Partition与Broker的关联关系也由ZooKeeper维护。
- 生产者负载均衡:每个生产者都需要决定它生产的消息应该被写入哪个Partition。由于ZooKeeper中保存了Broker地址信息与Topic元信息,因此生产者可以根据ZooKeeper实现消息写入的负载均衡。
- 消费者负载均衡:Kafka规定一个Partition消息只能被Consumer Group中的一个消费者实例消费,ZooKeeper负责记录“哪个消费者实例消费哪个Partition消息”这样的消费关系。另外,当某个消费者实例宕机后,ZooKeeper可以对相应的Consumer Group做Rebalance,以便保证每个Partition消息一直都在被消费。比如Consumer i消费Partition 1消息时宕机,ZooKeeper将对相应的Consumer Group进行Rebalance,然后可以选择让Consumer j继续消费Partition 1。
- 消费进度Offset记录:消费者实例在消费Partition消息的过程中,ZooKeeper定时记录消息的消费进度Offset,以便消费者实例重启或Consumer Group发生Rebalance后,可以从之前的Partition Offset位置继续消费消息。不过,这个功能的写性能不佳,Kafka 0.9版本不再将消费进度Offset保存到ZooKeeper,而是保存到Broker本地磁盘。
Kafka如何保证高可用?
- 为了实现高可用性,Kafka允许一个Partition拥有多个消息副本(Replica),每个Partition的副本由1个Leader和若干Follower组成。
- 生产者发送消息实际上写入的是Partition的Leader,而Follower则会周期性地向Leader请求消息复制,以保证Leader与 Follower之间的数据一致性。
- 不只是生产者发送消息到Leader,消费者消费的也是Leader中的消息,Follower的用途是作为Leader的数据备份,用于在Leader所在的Broker宕机后接管Partition的读/写,尽可能保证消息不丢失。
Leader和Follower的数据复制有哪些?
- 同步复制:所有的Follower都已复制此消息才认为消息写入成功。在这种机制下,Leader与Follower数据一致性高,但是一旦某个Follower复制速度太慢或者宕机,就会直接劣化消息写入的性能和可用性。
- 异步复制:只要Leader收到消息就认为消息写入成功,并不关心Follower是否已复制此消息。在这种机制下,消息写入的性能高、可用性高,但是数据一致性得不到保证。
Kafka采用的数据复制机制?
- Kafka采用的数据复制机制既不是完全的同步复制,也不是完全的异步复制,而是ISR机制。
ISR机制的原理?
- 每个Partition的Leader都会维护与其保持数据一致的Follower列表,该列表被称为ISR(In-Sync Replica)。
- 如果一个Follower长时间未发起数据复制,或者其数据落后于Leader太多,那么Leader会将这个Follower从ISR中移除;
- 在Partition写入消息时,只有ISR中所有的Follower都已确认收到此消息,Leader才认为消息写入成功。
- Leader会根据Follower状态动态地变更ISR,并将变更结果同步到ZooKeeper中。
Kafka如何使用数据备份进行故障恢复?
- Kafka 0.8版本引入了Partition Leader选举与故障恢复机制。
Partition Leader选举与故障恢复机制的流程?
- 首先,需要在Kafka集群的所有Broker中选举一个Controller角色,用于负责Partition Leader选举和副本重分配工作。
- 当Leader发生故障时,Controller会将Partition的最新Leader、Follower变动通知到相关Broker。
- Broker选举Controller借助了ZooKeeper的分布式锁能力,哪个Broker先抢到锁,它就是Controller。
Controller帮助Broker进行故障恢复的详细过程?
- 某Broker发生故障,与ZooKeeper断开连接。
- ZooKeeper认为此Broker已下线,于是删除该Broker节点。
- ZooKeeper通知Controller这个Broker已下线。
- Controller向ZooKeeper查询哪些Topic Partition的Leader副本由这个Broker负责,得到的结果是受影响的、需要重新选举Leader的Partition。
- Controller从每个Partition Leader ISR中选择一个Follower,准备将其提升为Leader。
- Controller将选举结果通知到各相关Broker。
- 被选举出的Follower变为Leader,其他Follower转而向新的Leader复制数据。
相关文章:
第1章大型互联网公司的基础架构——1.11 消息中间件技术
消息队列(Message Queue)是分布式系统中最重要的中间件之一,在服务架构设计中被广泛使用。 1.11.1 通信模式与用途 消息中间件构建了这样的通信模式: 一条消息由生产者创建,并被投递到存放消息的队列中;…...

FlutterAssetsGenerator插件的使用
在Plugins中找到FlutterAssetsGenerator插件,点击安装。 更改生成的资源索引类可以修改名字。 在根目录下创建assets/images文件夹,用于存储图片。 点击images文件夹,鼠标右键点击Flutter:Configuring Paths,pub…...

EasyExcel 自定义头信息导出
需求:需要在导出 excel时,合并单元格自定义头信息(动态生成),然后才是字段列表头即导出数据。 EasyExcel - 使用table去写入:https://easyexcel.opensource.alibaba.com/docs/current/quickstart/write#%E4%BD%BF%E7%94%A8table%E…...

网络运维学习笔记 012网工初级(HCIA-Datacom与CCNA-EI)某机构新增:GRE隧道与EBGP实施
文章目录 GRE隧道(通用路由封装,Generic Routing Encapsulation)协议号47实验:思科:开始实施: 华为:开始实施: eBGP实施思科:华为: GRE隧道(通用路…...

【系列专栏】银行IT的云原生架构-存储架构-数据库部署 10
银行 IT 的云原生架构:存储架构(数据库部署) 一、引言 在银行 IT 云原生架构的构建中,存储架构作为关键支撑,其性能、可靠性和扩展性直接影响着银行各类业务系统的运行效率与数据安全。而数据库作为数据存储与管理的…...

Python 爬虫selenium
1.selenium自动化 selenium可以操作浏览器,在浏览器页面上实现:点击、输入、滑动 等操作。 不同于selenium自动化,逆向本质是: 分析请求,例如:请求方法、请求参数、加密方式等。用代码模拟请求去实现同等…...

为啥vue3设计不直接用toRefs,而是reactive+toRefs
Vue 3 设计中将 reactive 和 toRefs 结合使用而非直接使用 toRefs,主要基于以下设计考量: 1. 响应式粒度的不同需求 reactive 适用于对象整体响应式 reactive 会为整个对象创建响应式代理,自动追踪对象内部所有属性的变化。这种设计适用于需要…...

深入解析 vLLM:高性能 LLM 服务框架的架构之美(二)调度管理
深入解析 vLLM:高性能 LLM 服务框架的架构之美(一)原理与解析 深入解析 vLLM:高性能 LLM 服务框架的架构之美(二)调度管理 1. vLLM 调度器结构与主要组件 在 vLLM 中,调度器的结构设计围绕任务…...

VMware安装教程
一、安装VMware软件 1. 安装前准备 系统要求: 操作系统:Windows 10/11 或 Linux(如Ubuntu、CentOS)。硬件要求: CPU:支持虚拟化技术(Intel VT-x 或 AMD-V),需在BIOS中启…...

iOS事件传递和响应
背景 对于身处中小公司且业务不怎么复杂的程序员来说,很多技术不常用,你可能看过很多遍也都大致了解,但是实际让你讲,不一定讲的清楚。你可能说,我以独当一面,应对自如了,但是技术的知识甚多&a…...

TensorFlow 实现任意风格的快速风格转换
一、什么是风格迁移? 风格迁移(Style Transfer)是一种利用深度学习技术,将一幅图像的内容与另一幅图像的艺术风格相结合,生成新图像的技术。其核心思想是将图像的“内容”和“风格”分离,再重新组合&#…...

火绒终端安全管理系统V2.0【系统防御功能】
火绒企业版V2.0系统防御功能包含系统加固、应用加固、软件安装拦截、摄像头保护和浏览器保护。火绒终端安全管理软件V2.0守护企业用户终端安全。 系统防御 1. 系统加固 系统加固功能根据火绒提供的安全加固策略,当程序对特定系统资源操作时提醒用户可能存在的安…...

全志A133 android10 适配SLM770A 4G模块
一,模块基本信息 1.官方介绍 SLM770A是美格智能最新推出的一款LTE Cat.4无线通讯模组,最大支持下行速率150Mbps及上行速率50Mbps。同时向下兼容现有的3G和2G网络,以确保即使在偏远地区也可以进行网络通信。 SLM770A模组支持分集接收和MIMO技…...

第3章 3.2 配置系统 .NET Core配置系统
3.2.1 配置系统的基本使用 .NET Core中的配置系统支持非常丰富的配置源,包括文件(JSON、XML、INI等)、注册表、环境变量、命令行、Azure Key Vault等,配置系统还支持自定义配置源。 用配置系统开发包Microsoft.Extensions.Confi…...

装修流程图: 装修前准备 → 设计阶段 → 施工阶段 → 安装阶段 → 收尾阶段 → 入住
文章目录 引言I 毛坯房装修的全流程**1. 装修前准备****1.1 确定装修预算****1.2 选择装修方式****1.3 选择装修公司****1.4 办理装修手续****2. 设计阶段****2.1 量房****2.2 设计方案****2.3 确认方案****3. 施工阶段****3.1 主体拆改****3.2 水电改造****3.3 防水工程****3.…...

Python----数据结构(单链表:节点,是否为空,长度,遍历,添加,删除,查找)
一、链表 链表是一种线性数据结构,由一系列按特定顺序排列的节点组成,这些节点通过指针相互连接。每个节点包含两部分:元素和指向下一个节点的指针。其中,最简单的形式是单向链表,每个节点含有一个信息域和一个指针域&…...

NLP-RNN-LSTM浅析
双向 LSTM(Bi - LSTM) 结构原理:从图片中可以看到,双向 LSTM 由两个方向相反的 LSTM 组成,一个是正向 LSTM(forward),一个是反向 LSTM(backward)。正向 LSTM …...
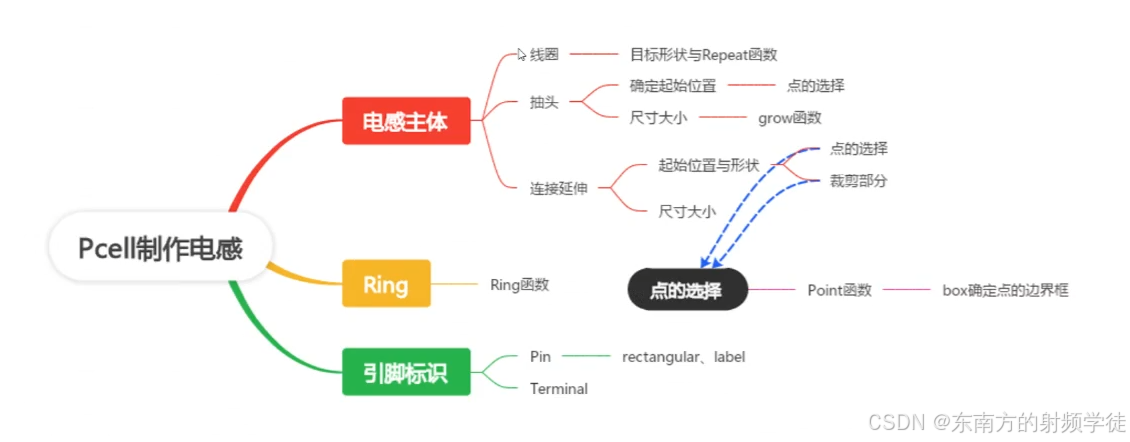
【Cadence射频仿真学习笔记】Pcell Designer设计电感学习笔记
Cadence的Pcell designer官方入门教程 一、下载Pcell Designer 首先,前往Cadence网站下载Pcell Designer软件 (具体安装过程就不记录了,大家自己去看视频吧) 二、创建新的P-cell 然后打开Virtuoso,点击Tools->…...

臻识相机,华夏相机,芊熠车牌识别相机加密解密
臻识,华夏,芊熠这三种车牌识别相机解密我都试过了,可以正常解密成功,其它品牌我暂时没有测试。超级简单,免费的,白嫖无敌! 流程: ①:先导出配置文件,例如我以…...

一个前端,如何同时联调多个后端
文章目录 场景解决方案思路实现步骤创建项目目标前端配置安装cross-env配置vue.config.js配置package.json 测试 场景 一个前端,需要同时和N个后端联调 一个需求里有若干个模块,分别给不同的后端开发,前端需要和N个后端联调 本地开启一个端…...

Win11Debloat:一键清理Windows臃肿的终极免费工具
Win11Debloat:一键清理Windows臃肿的终极免费工具 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

如何通过DJI Cloud API Demo快速构建无人机云端管理系统
如何通过DJI Cloud API Demo快速构建无人机云端管理系统 【免费下载链接】DJI-Cloud-API-Demo 项目地址: https://gitcode.com/gh_mirrors/dj/DJI-Cloud-API-Demo 在无人机应用开发领域,企业开发者常常面临一个核心挑战:如何在保障功能完整性的同…...

OpenDAN个人AI操作系统:构建本地化、可协作的AI智能体平台
1. 项目概述:个人AI操作系统的野望最近在AI圈子里,一个名为OpenDAN-Personal-AI-OS的项目引起了我的注意。简单来说,它试图构建一个完全属于你个人的、可深度定制的AI操作系统。这听起来有点科幻,但仔细研究其架构和理念ÿ…...

智能筛选企业高风险账务,提前规避税务稽查自查实操。
一、实际应用场景描述在中小企业财务日常工作中,会计人员常面临以下场景:- 每月大量凭证、发票、科目余额数据- 税务稽查指标逐年细化(如进销项匹配、费用异常波动)- 人工筛查效率低,容易漏判高风险点本程序的目标是在…...

从Robinson到Chernozhukov:Double ML的‘正交化’思想如何革新了经济学与生物统计?
从Robinson到Chernozhukov:Double ML如何重塑高维因果推断 1988年,计量经济学家Peter Robinson在《Econometrica》发表了一篇看似普通的半参数回归论文,却无意间埋下了一颗改变机器学习因果推断范式的种子。三十年后,当MIT的Cher…...

围棋AI分析工具LizzieYzy:从入门到精通的智能复盘神器
围棋AI分析工具LizzieYzy:从入门到精通的智能复盘神器 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为围棋复盘找不到问题所在而烦恼吗?LizzieYzy可能是你正在寻找的终…...

每天节省30分钟!淘宝自动化脚本让你的淘金币、蚂蚁森林、芭芭农场全自动运行
每天节省30分钟!淘宝自动化脚本让你的淘金币、蚂蚁森林、芭芭农场全自动运行 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/…...

VLC皮肤美化终极指南:5款VeLoCity主题打造个性化播放体验
VLC皮肤美化终极指南:5款VeLoCity主题打造个性化播放体验 【免费下载链接】VeLoCity-Skin-for-VLC Castom skin for VLC Player 项目地址: https://gitcode.com/gh_mirrors/ve/VeLoCity-Skin-for-VLC 还在使用VLC播放器那个单调乏味的默认界面吗?…...

WarcraftHelper:魔兽争霸3免费增强插件终极使用指南
WarcraftHelper:魔兽争霸3免费增强插件终极使用指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上运行不畅…...

终极指南:3分钟学会用ncmdumpGUI解密网易云音乐NCM格式文件
终极指南:3分钟学会用ncmdumpGUI解密网易云音乐NCM格式文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM加密格式文件无法…...