大数据技术之HBase操作归纳
HBase基本命令总结表(实际操作方式)
进入Hbase:hbase shell
方式一:命令行窗口来操作HBase
1.通用性命令
version 版本信息
status 查看集群当前状态
whoami 查看登入者身份
help 帮助
2.HBase DDL操作(对象级操作)
2.1、namespace命名空间(相当于库)
# 1.【查看】已创建的【所有】命名空间列表
list_namespace
---------------------------
NAMESPACE
default
hbase
hbase_test
【test_hbase】
4 row(s)
Took 0.0631 seconds
---------------------------# 2.【创建】命名空间
create_namespace "test_hbase"# 3.【查看】【指定】命名空间(库)中的表
list_namespace_tables "test_hbase"
---------------------------
TABLE
0 row(s)
Took 0.0301 seconds
=> []
---------------------------# 4.【描述】命名空间的定义
describe_namespace "test_hbase"
---------------------------
DESCRIPTION
{NAME => 'test_hbase'}
Quota is disabled
---------------------------# 5.【删除】命名空间
drop_namespace "test_hbase"2.2、Table表
# 1.查看所有表
list
---------------------------
TABLE
hbase_test:student_info
1 row(s)
Took 0.0202 seconds
=> ["hbase_test:student_info"]
---------------------------# 2.表是否存在
exists "test_hbase:test_table"
---------------------------
Table test_hbase:test_table does exist
Took 0.0114 seconds
=> true
---------------------------# 3.创建表
1.完整写法:
create "test_hbase:test_table",{NAME => 'base', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'TRUE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'},{NAME => 'sources', BLOOMFILTER => 'ROWCOL', IN_MEMORY => 'false', VERSIONS => '3', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '655360', REPLICATION_SCOPE => '0'}
说明文字:BLOOMFILTER布隆过滤器有三个参数=>ROW,ROWCOL,NONEROW:只对行键进行BLOOMFILTER检测 => 分裂策略ROWCOL:行健和列键进行BLOOMFILTER检测NONE:不使用BLOOMFILTER,默认值为ROWTTL:TTL的值以秒为单位2.简单写法:✔
create "test_hbase:test_table","base","sources"# 4.查看表的定义
desc "test_hbase:test_table"
---------------------------
Table test_hbase:test_table is ENABLED
test_hbase:test_table
COLUMN FAMILIES DESCRIPTION
{NAME => 'base', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DE
LETED_CELLS => 'TRUE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => '
FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATIO
N_SCOPE => '0'}
{NAME => 'sources', BLOOMFILTER => 'ROWCOL', IN_MEMORY => 'false', VERSIONS => '3', K
EEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', T
TL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '655360', RE
PLICATION_SCOPE => '0'}
---------------------------# 5.查看表的状态
is_enabled "test_hbase:test_table" # 是否已启用
is_disabled "test_hbase:test_table" # 是否已禁用
enable "test_hbase:test_table" # 启用表
disable "test_hbase:test_table" # 禁用表# 6.删除表【禁用状态的表才可以删除】
disable "test_hbase:test_table"
drop "test_hbase:test_table"
3.HBase DML操作(数据级操作)
# 1.添加数据=>列插入【一个put只能插入一列】
语法:put "表名","行键","列族:新增的信息","内容"
案例:【单】插入put "test_hbase:test_table","1","base:name","胡桃"put "test_hbase:test_table","1","base:age",17put "test_hbase:test_table","1","base:gender","女"put "test_hbase:test_table","1","sources:English",82put "test_hbase:test_table","1","sources:Math",90# 2.查看全表数据【全表扫描】
scan "test_hbase:test_table"
---------------------------
ROW COLUMN+CELL1 column=base:age, timestamp=2024-03-07T15:07:10.339, value=171 column=base:gender, timestamp=2024-03-07T15:07:14.510, value=\xE5\xA5\xB31 column=base:name, timestamp=2024-03-07T15:07:06.009, value=\xE8\x83\xA1\xE6\xA1\x831 column=sources:English, timestamp=2024-03-07T15:07:17.987, value=861 column=sources:Math, timestamp=2024-03-07T15:07:21.874, value=97
---------------------------# 3.查看表中记录数【行数】
count "test_hbase:test_table"
---------------------------
1 row(s)
Took 0.0194 seconds
=> 1
---------------------------# 4.查看某列值
4.1、查一行get "test_hbase:test_table","1"
---------------------------
COLUMN CELLbase:age timestamp=2024-03-07T15:36:03.061, value=17base:gender timestamp=2024-03-07T15:36:03.115, value=\xE5\xA5\xB3base:name timestamp=2024-03-07T15:36:03.001, value=\xE8\x83\xA1\xE6\xA1\x83sources:English timestamp=2024-03-07T15:36:03.156, value=82sources:Math timestamp=2024-03-07T15:36:03.192, value=90
---------------------------4.2、查一行一个列族get "test_hbase:test_table","1","sources"
---------------------------
COLUMN CELLsources:English timestamp=2024-03-07T15:36:03.156, value=82sources:Math timestamp=2024-03-07T15:36:03.192, value=90
---------------------------4.3、查一行一个列族某个列get "test_hbase:test_table","1","sources:English"
---------------------------
COLUMN CELLsources:English timestamp=2024-03-07T15:36:03.156, value=82
---------------------------# 5.删除数据
5.1、删除【一个单元格】
deleteall | delete "test_hbase:test_table","1","base:name"5.2、删除【整行】
deleteall "test_hbase:test_table","2"5.3、ROEPREFIXFILTEB:支持行键前缀批量删除,CACHE:修改批量的值
deleteall "test_hbase:test_table",{ROEPREFIXFILTEB="时间戳TS|字符串STR",CACHE=>100}5.4、删除表中【所有数据】
disable "test_hbase:test_table"
truncate "test_hbase:test_table"# 6.自增
-- 首次针对不存在的列操作,针对存在的列会报错:Field is not a log,it‘s 10 bytes wide
-- 此后操作可针对【新添列名】进行
6.1、基本语法自增:incr "[命名空间:]表名","行键","列族名:新添列名",增加数N查询:get_counter "[命名空间:]表名","行键","列族名:新添列名"
6.2、案例展示scan "test_hbase:test_table"
---------------------------
ROW COLUMN+CELL1 column=base:age, timestamp=2024-03-07T15:36:03.061, value=171 column=base:gender, timestamp=2024-03-07T15:36:03.115, value=\xE5\xA5\xB31 column=base:name, timestamp=2024-03-07T15:36:03.001, value=\xE8\x83\xA1\xE6\xA1\x831 column=sources:English, timestamp=2024-03-07T15:36:03.156, value=821 column=sources:Math, timestamp=2024-03-07T15:36:03.192, value=90
---------------------------incr "test_hbase:test_table","1","sources:count",2
---------------------------
ROW COLUMN+CELL1 column=base:age, timestamp=2024-03-07T15:36:03.061, value=171 column=base:gender, timestamp=2024-03-07T15:36:03.115, value=\xE5\xA5\xB31 column=base:name, timestamp=2024-03-07T15:36:03.001, value=\xE8\x83\xA1\xE6\xA1\x831 column=sources:English, timestamp=2024-03-07T15:36:03.156, value=821 column=sources:Math, timestamp=2024-03-07T15:36:03.192, value=901 column=sources:count, timestamp=2024-03-11T20:01:16.651, value=\x00\x00\x00\x00\x00\x00\x00\x02
---------------------------# 7.预分区(hbase优化)
7.1、预分区
策略一:【NUMREGIONS:分区数量;SPLITALGO:分裂所采用的算法】create "test_hbase:test_split","t1","t2",{NUMREGIONS=>3,SPLITALGO=>"UniformSplit"}
策略二:【SPLITS:行键取值范围(字母或数字)】###取值范围:0~100,101~200,201~300,301以上create "test_hbase:test_rowkey_split","cf1","cf2",SPLITS=>["100","200","300"]7.2、查看分区
scan "hbase:meta",{STARTROW=>"test_hbase:test_rowkey_split",LIMIT=>10}
---------------------------
#hdfs存储信息
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B .tabledesc
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B .tmp
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B 28c38ce5ff401333122c00c05e521ae3
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B 4493f765702cc8979678f14cbcff17ff
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B 540c8c1f386356cab11f824e74d33fad
#drwxr-xr-x root supergroup 0 B Mar 11 20:31 0 0 B 867157c4f6ab39ba52ac6b3b58e6cbf4
---------------------------
4.TOOLS
## 2个小文件合并为一个大文件
1.compact "[命名空间:]表名"## 所有小的文件合并为一个大文件
2.major_compact "[命名空间:]表名"
方式二:Hive来操作HBase(HBase数据映射至Hive中进行操作)
1.向HBase导入数据
## 基本格式
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator="分隔符" \
-Dimporttsv.columns="HBASE_ROW_KEY,列族:列名..." \
"命名空间:表名" \
文件路径## 案例(在shell命令窗下进行,不在hbase中进行)
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator="|" \
-Dimporttsv.columns=HBASE_ROW_KEY,base:name,base:age,sources:English,sources:Math \
test_hbase:test_table \
file:///root/file/hbase_file/students_for_import_2.csv
2.hive 表映射 hbase表(在hive中进行)
# hive中建表并导入数据【hbase数据映射到hive中】
create external table yb12211.student_from_hbase(
stu_id int,
stu_name string,
stu_age int,
score_English int,
score_Math int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,base:name,base:age,sources:English,sources:Math")
tblproperties("hbase.table.name"="test_hbase:test_table");
方式三:Java来操作HBase——数据迁移
1、应用场景的讲解
Java借助于HBase的API接口来操作HBase。
其核心功能主要是数据迁移。
1.借助于原生的HBase的API接口和Java jdbc的API接口,将传统的关系型数据库(mysql)中的数据导入到HBase中。
2.借助于文件流将普通的文件中的数据导入到HBase中。
2、初步准备工作
2.1:Maven创建
选择quick start,进行Maven创建
2.2:初步配置
一、删除url
二、properties配置
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target>
</properties>
三、基本检查,确保版本一致=>都为1.8|8版本
四、依赖(覆盖)
<!-- MySql 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency><!-- HBase 驱动 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency><!-- Hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.3</version>
</dependency><!-- zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency><!-- log4j 系统日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency><!--json tool-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.47</version>
</dependency>
3、最终的传参操作(验证操作)
运行配置的设置——传参
步骤一:先点击绿色的小锤子,然后再点击Edit Configurations的选项

步骤二:进行信息的配置

相关文章:
大数据技术之HBase操作归纳
HBase基本命令总结表(实际操作方式) 进入Hbase:hbase shell 方式一:命令行窗口来操作HBase 1.通用性命令 version 版本信息 status 查看集群当前状态 whoami 查看登入者身份 help 帮助2.HBase DDL操作(对象级操作) 2.1、namespace命名空间(相当…...

后端Java Stream数据流的使用=>代替for循环
API讲解 对比 示例代码对比 for循环遍历 package cn.ryanfan.platformback.service.impl;import cn.ryanfan.platformback.entity.Algorithm; import cn.ryanfan.platformback.entity.AlgorithmCategory; import cn.ryanfan.platformback.entity.DTO.AlgorithmInfoDTO; im…...

遗传算法与深度学习实战系列,自动调优深度神经网络和机器学习的超参数
遗传算法与深度学习实战系列文章 目录 进化深度学习生命模拟及其应用生命模拟与进化论遗传算法中常用遗传算子遗传算法框架DEAPDEAP框架初体验使用遗传算法解决N皇后问题使用遗传算法解决旅行商问题使用遗传算法重建图像遗传编程详解与实现粒子群优化详解与实现协同进化详解与…...

体验用ai做了个python小游戏
体验用ai做了个python小游戏 写在前面使用的工具2.增加功能1.要求增加视频作为背景。2.我让增加了一个欢迎页面。3.我发现中文显示有问题。4.我提出了背景修改意见,欢迎页面和结束页面背景是视频,游戏页面背景是静态图片。5.提出增加更多游戏元素。 总结…...

谷粒商城—分布式高级②.md
认证服务 1. 环境搭建 创建gulimall-auth-server模块,导依赖,引入login.html和reg.html,并把静态资源放到nginx的static目录下 2. 注册功能 (1) 验证码倒计时 //点击发送验证码按钮触发下面函数 $("#sendCode").click(function () {//如果有disabled,说明最近…...

阿里云ECS命名规则解析与规格选型实战指南
阿里云ECS实例的命名规则通常采用 “ecs.{实例族}.{规格大小}” 的结构,各部分含义如下: 命名字段说明ecs代表“弹性计算服务”(Elastic Compute Service)。{实例族}标识实例的用途和代次(如 g7、c7、r7),由字母+数字组成。{规格大小}表示实例的资源配置(如 large、2xl…...

Spring MVC 的核心以及执行流程
Spring MVC的核心 Spring MVC是Spring框架中的一个重要模块,它采用了经典的MVC(Model-View-Controller)设计模式。 MVC是一种软件架构的思想,它将软件按照模型(Model)、视图(View)…...

ai json处理提示词
在解析JSON数据时,提示词的设计需要明确任务目标、输入格式以及期望的输出格式。以下是一些常用的提示词示例,适用于不同的JSON解析场景: 1. 提取特定字段 用于从JSON中提取特定字段的值。 示例: 从以下JSON数据中提…...
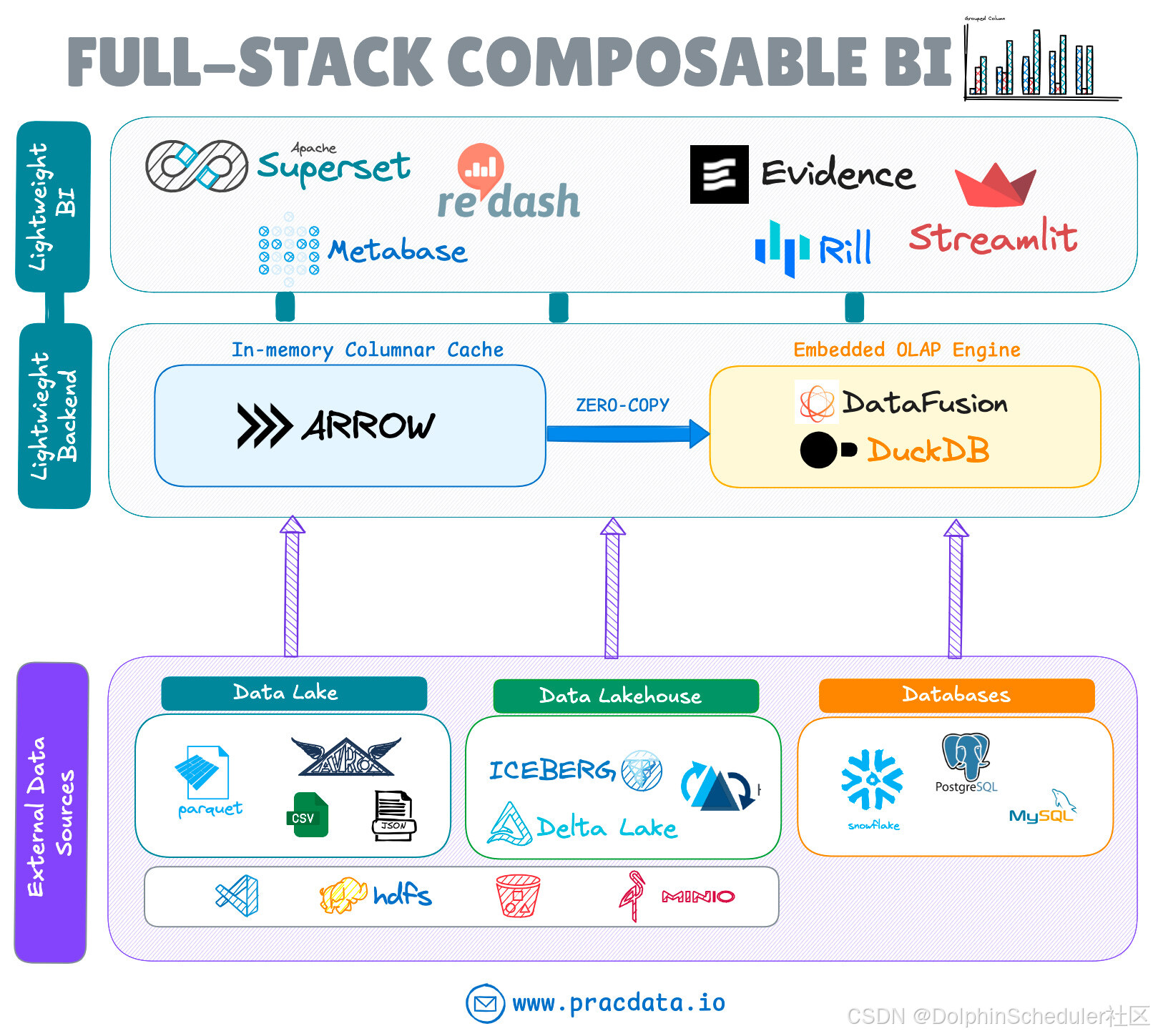
2025开源数据工程全景图
作者 | Alireza Sadeghi 译自Practical Data Engineering 2025年开源数据工程领域呈现蓬勃创新与生态重构的双重态势,九大技术赛道在实时化、轻量化与云原生架构驱动下加速演进。一份来自外网的2025年开源数据工程全景图全面地展示了这一领域的发展态势与走向&…...
)
438. 找到字符串中所有字母异位词(LeetCode 热题 100)
题目来源: 438. 找到字符串中所有字母异位词 - 力扣(LeetCode) 题目内容: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 示例 1: 输入: s &…...

c++标准io与线程,互斥锁
封装一个 File 类, 用有私有成员 File* fp 实现以下功能 File f "文件名" 要求打开该文件 f.write(string str) 要求将str数据写入文件中 string str f.read(int size) 从文件中读取最多size个字节, 并将读取到的数据返回 析构函数 #…...

java简单实现请求deepseek
1.deepseek的api创建 deepseek官网链接 点击右上API开放平台后找到API keys 创建APIkey: 注意:创建好的apikey只能在创建时可以复制,要保存好 2.java实现请求deepseek 使用springbootmaven 2.1 pom文件: <?xml version&…...

Ext系列文件系统 -- 磁盘结构,磁盘分区,inode,ext文件系统,软硬链接
目录 1.理解硬盘 1.1 磁盘、服务器、机柜、机房 1.2 磁盘物理结构 1.3 磁盘的存储结构 1.4 磁盘的逻辑结构 1.4.1 理解逻辑结构 1.4.2 真实过程 1.5 CHS地址和LBA地址的相互转换 2.引入文件系统 2.1 “块”概念 2.2 “分区”概念 2.3 “inode”概念 3.ext2文件系…...

PyTorch Tensor 形状变化操作详解
PyTorch Tensor 形状变化操作详解 在深度学习中,Tensor 的形状变换是非常常见的操作。PyTorch 提供了丰富的 API 来帮助我们调整 Tensor 的形状,以满足模型输入、计算或数据处理的需求。本文将详细介绍 PyTorch 中常见的 Tensor 形状变换操作࿰…...

文字识别软件cnocr学习笔记
• 安装 pip install cnocr • 基础的使用方法 首次运行会下载安装模型,如果没有梯子,会报错: 在网络上查找cnocr的模型资源,并下载到本地。https://download.csdn.net/download/qq_33464428/89514689?ops_request_misc%257B%2…...

本地部署DeepSeek R1 + 界面可视化open-webui【ollama容器+open-webui容器】
本地部署DeepSeek R1 界面可视化open-webui 本文主要讲述如何用ollama镜像和open-webui镜像部署DeepSeek R1, 镜像比较方便我们在各个机器之间快速部署。 显卡推荐 模型版本CPU内存GPU显卡推荐1.5B4核8GB非必需4GBRTX1650、RTX20607B、8B8核16GB8GBRTX3070、RTX…...

macOS部署DeepSeek-r1
好奇,跟着网友们的操作试了一下 网上方案很多,主要参考的是这篇 DeepSeek 接入 PyCharm,轻松助力编程_pycharm deepseek-CSDN博客 方案是:PyCharm CodeGPT插件 DeepSeek-r1:1.5b 假设已经安装好了PyCharm PyCharm: the Pyth…...

基于STM32与BD623x的电机控制实战——从零搭建无人机/机器人驱动系统
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 一、为什么选择这两个芯片?1.1 STM32微控制器1.2 ROHM BD623x电机驱动 二、核心控制原理详解2.1 H桥驱动奥…...
)
基于ffmpeg+openGL ES实现的视频编辑工具-字幕添加(六)
在视频编辑领域,字幕的添加是一项极为重要的功能,它能够极大地丰富视频内容,提升观众的观看体验。当我们深入探究如何实现这一功能时,FreeType 开源库成为了强大助力。本文将详细阐述借助 FreeType 库生成字幕数据的过程,以及如何实现字幕的缩放、移动、旋转、颜色修改、对…...

C++中const T为什么少见?它有什么用途?
在C中,右值引用(T&&)是移动语义和完美转发的核心特性之一,但你是否注意到,const T&&(const右值引用)却很少被使用?它到底有什么用途? 今天我们就来深入…...

从零到精通:AI大模型学习路线图,助你月薪30K+!2026年AI大模型学习路线终极指南
本文提供了一套系统的AI大模型学习路线,涵盖数学与编程基础、机器学习入门、深度学习深入、大模型探索以及进阶应用。文章详细介绍了各阶段的理论学习资源(如书籍、在线课程)和实践项目(如Kaggle竞赛、Hugging Face库应用…...

【工业级MCP网关开发白皮书】:基于C++20/Boost.Asio/FlatBuffers构建延迟<50μs的金融级网关
更多请点击: https://intelliparadigm.com 第一章:工业级MCP网关的设计目标与性能边界 工业级MCP(Modbus Control Protocol)网关并非普通协议转换桥接器,而是面向严苛生产环境构建的实时数据中枢。其核心使命是在毫秒…...

轻松解锁网易云NCM音乐文件:ncmdumpGUI图形化转换工具完全攻略
轻松解锁网易云NCM音乐文件:ncmdumpGUI图形化转换工具完全攻略 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM格式文件无法…...

终极指南:30天无限续杯!简单三步重置JetBrains IDE试用期
终极指南:30天无限续杯!简单三步重置JetBrains IDE试用期 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾因JetBrains IDE试用期到期而中断开发工作?ide-eval-resetter…...

WinUtil终极指南:5分钟掌握Windows系统一键优化与批量安装
WinUtil终极指南:5分钟掌握Windows系统一键优化与批量安装 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统卡顿…...

GoFr框架:加速微服务开发的Go语言利器
目录 一、核心特性:简化微服务开发的五大支柱 1.1 零配置启动与约定优于配置 1.2 全栈可观测性:日志、追踪、指标一体化 1.3 多数据源支持与弹性扩展 二、技术架构:分层设计与模块化组件 三、未来展望:持续演进的云原生生态…...

保姆级教程:将你的PyTorch/ONNX模型转换为NCNN格式并完成C++推理
从PyTorch/ONNX到NCNN:移动端模型部署全流程实战指南 在移动端和嵌入式设备上部署深度学习模型一直是开发者面临的挑战之一。不同于云端服务器,这些设备通常受限于计算资源、内存容量和功耗要求。NCNN作为腾讯开源的高性能神经网络推理框架,凭…...

4.【会话管理系统】如何实现多轮对话不丢上下文?
【会话管理系统设计】如何实现多轮对话不丢上下文?(完整落地方案) 一、问题场景 用户问:“帮我写一个Python函数”然后又问:“加上异常处理”👉 AI直接懵了 原因:没有上下文二、问题分析 AI本身…...

5分钟掌握WinUtil:Windows终极系统优化与软件批量安装工具
5分钟掌握WinUtil:Windows终极系统优化与软件批量安装工具 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统卡顿…...

企业无线网反复弹认证页面?排查这3个AC配置项和2个手机设置就够了
企业无线网络认证弹窗故障排查指南:从AC配置到终端优化的全流程解决方案 当企业员工频繁抱怨"明明已经认证过,为什么又弹出登录页面"时,作为网络管理员的你该如何快速定位并解决问题?这种反复弹窗的认证故障不仅影响工作…...