【深度学习】矩阵的理解与应用
一、矩阵基础知识
1. 什么是矩阵?
矩阵是一个数学概念,通常表示为一个二维数组,它由行和列组成,用于存储数值数据。矩阵是线性代数的基本工具之一,广泛应用于数学、物理学、工程学、计算机科学、机器学习和数据分析等领域。
1.1 矩阵的表示
一个矩阵通常用大写字母来表示,例如 A A A,而矩阵中的元素则用小写字母来表示,例如 a i j a_{ij} aij,其中 i i i表示行索引, j j j表示列索引。
本质:矩阵是二维的张量
矩阵的维度:一个矩阵的维度用行数和列数来描述,通常表示为 m m m× n n n,其中 m m m是行数, n n n是列数。比如,一个 2×3的矩阵表示有 2 行和 3 列。
1.2 矩阵的类型
行矩阵:只有一行的矩阵,例如 ( 1 , 2 ) \begin{pmatrix} 1,2 \\ \end{pmatrix} (1,2)
列矩阵:只有一列的矩阵,例如 ( 1 2 ) \begin{pmatrix} 1 \\ 2\end{pmatrix} (12)
方阵:行数和列数相等的矩阵,例如 ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324)
零矩阵:所有元素都为零的矩阵,例如 ( 0 0 0 0 ) \begin{pmatrix} 0& 0 \\ 0 & 0 \\ \end{pmatrix} (0000)
单位矩阵:对角线上的元素为 1,其余元素为 0 的方阵,例如 ( 1 0 0 1 ) \begin{pmatrix} 1& 0 \\ 0 & 1 \\ \end{pmatrix} (1001)
1.3 矩阵的运算
矩阵支持多种运算,包括
(1)加法:两个相同维度的矩阵可以相加。
A A A+ B B B= ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324)+ ( 5 6 7 8 ) \begin{pmatrix} 5 & 6 \\ 7 & 8 \\ \end{pmatrix} (5768)= ( 6 8 10 12 ) \begin{pmatrix} 6 & 8 \\ 10 & 12 \\ \end{pmatrix} (610812)
(2)减法:类似于加法,两个相同维度的矩阵可以相减。
A A A- B B B= ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324)- ( 5 6 7 8 ) \begin{pmatrix} 5 & 6 \\ 7 & 8 \\ \end{pmatrix} (5768)= ( − 4 − 4 − 4 − 4 ) \begin{pmatrix} -4 & -4 \\ -4 & -4 \\ \end{pmatrix} (−4−4−4−4)
(3)数乘:矩阵的每个元素乘以一个标量(数字)。
k k k A A A=2* ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324)= ( 2 4 6 8 ) \begin{pmatrix} 2 & 4 \\ 6 & 8\\ \end{pmatrix} (2648)
(4)矩阵乘法:两个矩阵相乘的条件是前一个矩阵的列数等于后一个矩阵的行数。
A A A* B B B= ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324)X ( 5 6 7 8 ) \begin{pmatrix} 5 & 6 \\ 7 & 8 \\ \end{pmatrix} (5768)= ( 19 22 43 50 ) \begin{pmatrix}19 & 22 \\ 43 & 50 \\ \end{pmatrix} (19432250)
(5)转置:将矩阵的行和列交换,记作 A T A^{T} AT
A A A= ( 1 2 3 4 ) \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ \end{pmatrix} (1324), A T A^{T} AT= ( 1 3 2 4 ) \begin{pmatrix} 1 & 3 \\ 2 & 4 \\ \end{pmatrix} (1234)
(6)逆矩阵:对于方阵 A A A,如果存在一个矩阵 B B B,使得
A A A* B B B= I I I(单位矩阵),则称 B B B为 A A A的逆矩阵,记作 A − 1 A^{-1} A−1
1.4 矩阵的秩
(1)秩的定义:矩阵的秩是指该矩阵中线性无关行或列的最大数量。换句话说,矩阵的秩可以看作是它的维度深度,描述了其中有多大数量的独立信息。
例如:
对于一个
m m m* n n n的矩阵 A A A,如果它的秩为 r r r,则 r r r≤min( m m m, n n n)。
如果 r r r=min( m m m, n n n),则矩阵是满秩的;否则是非满秩的。
(2)全秩 vs. 低秩:
- 全秩矩阵:如果一个矩阵的秩等于其最小维度(行数或列数),那么这个矩阵被称为全秩矩阵。
- 低秩矩阵:如果秩小于其最小维度,它被称为低秩矩阵。低秩矩阵通常存在于数据中,在许多应用中表示存在冗余结构。
二、低秩矩阵
低秩矩阵可以被看作是由少量“基本成分”组成的矩阵。这种特性使得低秩矩阵在实际应用中有很强的压缩和降维能力。
1. 低秩矩阵的定义
(1)低秩矩阵是指矩阵的秩 r r r远小于矩阵的行数 m m m和列数 n n n。
具体来说:
如果 r r r≪min( m m m, n n n),则称该矩阵为低秩矩阵。
(2)低秩矩阵的特点是:尽管矩阵可能很大(如
m m m× n n n很大),但它可以用较少的参数来描述。
例如:一个 1000×1000的矩阵,如果其秩仅为 10,则说明这个矩阵可以用 10 个独立的模式来近似表示。
以下是几个直观的理解角度:
1.1 数据的冗余性
许多现实世界的数据具有一定的冗余性。例如:
图像中相邻像素通常具有相似的颜色值。
用户对商品的评分矩阵中,用户的行为往往受到少数隐含因素(如兴趣、偏好)的影响。
这些冗余性导致矩阵的实际秩远小于其理论最大秩。
1.2 分解视角
低秩矩阵可以通过矩阵分解来表示。例如,一个秩为 r r r的矩阵 A A A可以分解为两个小矩阵的乘积: A A A= U U U V T V^{T} VT
其中:
- U U U是 m m m× r r r的矩阵,
- V V V是 n n n× r r r的矩阵。
通过这种方式,原本 m m m× r r r的大矩阵 A A A只需要用( m m m+ r r r)* r r r个参数来表示,从而实现了数据的压缩。
1.3 几何视角
从几何上看,矩阵的秩反映了其列向量或行向量所张成的空间维度。如果矩阵的秩较低,则说明其列向量或行向量主要集中在少数几个方向上。
2. 低秩矩阵的应用
(1)推荐系统
在推荐系统中,用户-物品评分矩阵通常是稀疏的且低秩的。这是因为用户的偏好行为往往受到少数隐含因素的影响。通过低秩矩阵分解(如奇异值分解 SVD 或矩阵补全方法),可以预测用户对未评分物品的偏好。
(2)图像处理
图像矩阵通常是低秩的,因为图像中存在大量的局部相关性和重复模式。利用低秩矩阵分解,可以实现图像去噪、修复和压缩。
(3)自然语言处理
在词嵌入(Word Embedding)中,词-上下文共现矩阵通常是低秩的。通过低秩分解,可以得到词向量表示(如 Word2Vec、GloVe)。
(4)信号处理
在信号处理中,低秩矩阵常用于表示信号的结构化特性。例如,在视频背景建模中,背景部分通常可以用低秩矩阵表示,而前景部分则表现为稀疏扰动。
3. 低秩矩阵的计算
在实际问题中,直接判断一个矩阵是否低秩可能比较困难,因此常用的方法包括:
3.1 奇异值分解(SVD)
通过对矩阵进行 SVD 分解,观察奇异值的分布。如果大部分奇异值接近零,则说明矩阵是低秩的
核心思想:将一个矩阵分解为三个特殊矩阵的乘积,从而揭示矩阵的内在结构
import numpy as np
from numpy.linalg import svd
# 示例矩阵
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 进行奇异值分解
U, S, VT = svd(A)
# 选择前 k 个奇异值来近似
k = 2
S_k = np.zeros_like(A)
S_k[:k, :k] = np.diag(S[:k]) # 只保留前 k 个奇异值
# 重构低秩矩阵
A_k = U[:, :k] @ S_k @ VT[:k, :]
print("原矩阵 A:")
print(A)
print("\n低秩近似矩阵 A_k:")
print(A_k)
3.2 矩阵补全
对于缺失数据的矩阵,通过优化方法(如核范数最小化)寻找其低秩近似。
可以借助 cvxpy 库实现。
import numpy as np
import cvxpy as cp
def matrix_completion_cvxpy(A, mask, rank=None, lambda_=1.0):"""使用凸优化方法进行矩阵补全。参数:- A: 原始矩阵 (包含缺失值)- mask: 观测值的掩码矩阵 (1 表示已知,0 表示缺失)- rank: 目标矩阵的秩(可选)- lambda_: 正则化参数返回:- 完整矩阵的估计值"""m, n = A.shapeX = cp.Variable((m, n)) # 待优化的变量objective = cp.Minimize(cp.norm(X, "nuc")) # 核范数最小化constraints = [cp.multiply(mask, X) == cp.multiply(mask, A)] # 已知元素约束prob = cp.Problem(objective, constraints)prob.solve(solver=cp.SCS, verbose=False)return X.value
# 示例用法
A = np.array([[5, 3, 0], [4, 0, 2], [0, 1, 6]]) # 原始矩阵(含缺失值)
mask = np.array([[1, 1, 0], [1, 0, 1], [0, 1, 1]]) # 已知元素的掩码
completed_matrix = matrix_completion_cvxpy(A, mask)
print("补全后的矩阵:")
print(completed_matrix)
3.3 PCA(主成分分析)
通过 PCA 提取数据的主要成分,本质上也是寻找低秩近似。
PCA 的数学原理:
给定一个 m m m× n n n 的数据矩阵 X X X,其中每一行是一个样本,每一列是一个特征:
(1)中心化:对数据进行中心化处理,使得每列的均值为 0。
(2)协方差矩阵:计算协方差矩阵 C C C= 1 m − 1 \frac{1}{m-1} m−11 X T X^{T} XT X X X
(3)特征值分解:对协方差矩阵 C C C进行特征值分解,得到特征值和特征向量。
选择主成分:根据特征值大小选择前 k k k个主成分(即最大的 k k k个特征值对应的特征向量)。
低秩近似:用前 k k k个主成分重构数据矩阵,得到低秩近似矩阵。
(4)实践用代码演示:
from sklearn.decomposition import PCA
import numpy as np
def pca_low_rank_sklearn(X, k):"""使用 Scikit-learn 的 PCA 计算低秩矩阵近似。参数:- X: 数据矩阵 (m x n),每一行是一个样本,每一列是一个特征- k: 目标低秩维度返回:- 低秩近似的矩阵"""# 初始化 PCA 模型pca = PCA(n_components=k)# 拟合并转换数据X_reduced = pca.fit_transform(X) # 投影到低维空间X_reconstructed = pca.inverse_transform(X_reduced) # 重构数据return X_reconstructed
# 示例用法
X = np.array([[2.5, 2.4], [0.5, 0.7], [2.2, 2.9], [1.9, 2.2], [3.1, 3.0]])
k = 1 # 目标低秩维度
low_rank_X = pca_low_rank_sklearn(X, k)
print("低秩近似的矩阵:")
print(low_rank_X)
4. 总结
低秩矩阵的核心思想是:尽管矩阵本身可能很大,但其本质信息可以用少量的参数来描述。这种特性使得低秩矩阵在数据压缩、降维、去噪等方面具有重要意义。理解和应用低秩矩阵的关键在于掌握其数学定义、分解方法以及实际应用场景。
三、矩阵乘法优化
优化矩阵乘法的性能对于提高计算效率至关重要,尤其是在处理大规模数据时。以下是优化矩阵乘法的具体方法及原理解析:
1. 矩阵乘法的基本实现
矩阵乘法的标准公式如下:
A [ c ] [ j ] = ∑ k A [ i ] [ k ] ∗ B [ k ] [ j ] A[c][j]=\sum_{k}A[i][k]*B[k][j] A[c][j]=∑kA[i][k]∗B[k][j]
其中 A A A是 m m m× n n n的矩阵, B B B是 n n n× p p p的矩阵,结果 C C C是 m m m× p p p的矩阵。
def matrix_multiply_basic(A, B):"""基本的矩阵乘法实现。参数:- A: m x n 矩阵- B: n x p 矩阵返回:- C: m x p 矩阵"""m, n = len(A), len(A[0])n, p = len(B), len(B[0])C = [[0 for _ in range(p)] for _ in range(m)]for i in range(m):for j in range(p):for k in range(n):C[i][j] += A[i][k] * B[k][j]return C
# 示例用法
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
C = matrix_multiply_basic(A, B)
print("矩阵乘法结果:")
print(C)
问题:这种实现简单易懂,但在性能上存在瓶颈,尤其是当矩阵规模较大时。
2. 使用 NumPy 进行高效矩阵乘法
NumPy 是一个高效的数值计算库,其底层使用了高度优化的 BLAS(Basic Linear Algebra Subprograms)和
LAPACK 库来加速矩阵运算。
NumPy 实现:
import numpy as np
def matrix_multiply_numpy(A, B):"""使用 NumPy 进行矩阵乘法。参数:- A: m x n 矩阵- B: n x p 矩阵返回:- C: m x p 矩阵"""A = np.array(A)B = np.array(B)return np.dot(A, B)
# 示例用法
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
C = matrix_multiply_numpy(A, B)
print("矩阵乘法结果:")
print(C)
优点:
- 性能远高于纯 Python 实现。
- 简洁易用,适合大多数场景。
3. 分块矩阵乘法(Block Matrix Multiplication)
分块矩阵乘法将大矩阵分割成小块,分别计算每个小块的结果后再合并。这种方法可以更好地利用缓存,减少内存访问开销。
分块矩阵乘法实现
def block_matrix_multiply(A, B, block_size=32):"""分块矩阵乘法实现。参数:- A: m x n 矩阵- B: n x p 矩阵- block_size: 分块大小返回:- C: m x p 矩阵"""m, n = len(A), len(A[0])n, p = len(B), len(B[0])C = [[0 for _ in range(p)] for _ in range(m)]for i0 in range(0, m, block_size):for j0 in range(0, p, block_size):for k0 in range(0, n, block_size):# 计算当前块的范围i_end = min(i0 + block_size, m)j_end = min(j0 + block_size, p)k_end = min(k0 + block_size, n)# 对当前块进行矩阵乘法for i in range(i0, i_end):for j in range(j0, j_end):for k in range(k0, k_end):C[i][j] += A[i][k] * B[k][j]return C
# 示例用法
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
C = block_matrix_multiply(A, B, block_size=2)
print("分块矩阵乘法结果:")
print(C)
优点:
- 更好地利用 CPU 缓存,减少内存访问延迟。
- 适合大规模矩阵运算。
4. Strassen 算法
Strassen 算法是一种分治算法,通过递归地将矩阵分成更小的子矩阵来减少乘法次数。
传统矩阵乘法的时间复杂度为 O O O( n 3 n^{3} n3),而 Strassen 算法的时间复杂度为 O O O( A log 2 7 A^{\log_{2}7} Alog27) ≈ \approx ≈ O O O( n 2.81 n^{2.81} n2.81)
Strassen 算法实现:
def strassen_multiply(A, B):"""使用 Strassen 算法进行矩阵乘法。参数:- A: n x n 矩阵- B: n x n 矩阵返回:- C: n x n 矩阵"""n = len(A)if n == 1:return [[A[0][0] * B[0][0]]]# 将矩阵分成四块mid = n // 2A11 = [row[:mid] for row in A[:mid]]A12 = [row[mid:] for row in A[:mid]]A21 = [row[:mid] for row in A[mid:]]A22 = [row[mid:] for row in A[mid:]]B11 = [row[:mid] for row in B[:mid]]B12 = [row[mid:] for row in B[:mid]]B21 = [row[:mid] for row in B[mid:]]B22 = [row[mid:] for row in B[mid:]]# 递归计算 7 个中间矩阵P1 = strassen_multiply(A11, subtract_matrix(B12, B22))P2 = strassen_multiply(add_matrix(A11, A12), B22)P3 = strassen_multiply(add_matrix(A21, A22), B11)P4 = strassen_multiply(A22, subtract_matrix(B21, B11))P5 = strassen_multiply(add_matrix(A11, A22), add_matrix(B11, B22))P6 = strassen_multiply(subtract_matrix(A12, A22), add_matrix(B21, B22))P7 = strassen_multiply(subtract_matrix(A11, A21), add_matrix(B11, B12))# 计算结果矩阵的四个块C11 = add_matrix(subtract_matrix(add_matrix(P5, P4), P2), P6)C12 = add_matrix(P1, P2)C21 = add_matrix(P3, P4)C22 = subtract_matrix(subtract_matrix(add_matrix(P5, P1), P3), P7)# 合并结果矩阵C = []for i in range(mid):C.append(C11[i] + C12[i])for i in range(mid):C.append(C21[i] + C22[i])return C
def add_matrix(A, B):"""矩阵加法"""return [[A[i][j] + B[i][j] for j in range(len(A[0]))] for i in range(len(A))]
def subtract_matrix(A, B):"""矩阵减法"""return [[A[i][j] - B[i][j] for j in range(len(A[0]))] for i in range(len(A))]
# 示例用法
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
C = strassen_multiply(A, B)
print("Strassen 算法结果:")
print(C)
优点:
- 减少了乘法次数,理论上比传统方法更快。
- 适合非常大的矩阵。
缺点:
- 实现复杂,常数因子较高。
- 在中小规模矩阵中可能不如直接方法快。
5. GPU加速(使用CuPy或PyTorch)
如果需要处理超大规模矩阵,可以利用 GPU 加速矩阵乘法。CuPy 和 PyTorch 提供了与 NumPy 类似的接口,并支持 GPU
加速。
CuPy 实现:
import cupy as cp
def matrix_multiply_cupy(A, B):"""使用 CuPy 进行矩阵乘法(GPU 加速)。参数:- A: m x n 矩阵- B: n x p 矩阵返回:- C: m x p 矩阵"""A_gpu = cp.array(A)B_gpu = cp.array(B)C_gpu = cp.dot(A_gpu, B_gpu)return cp.asnumpy(C_gpu)
# 示例用法
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
C = matrix_multiply_cupy(A, B)
print("CuPy 矩阵乘法结果:")
print(C)
优点:
- 利用 GPU 并行计算能力,显著提升性能。
- 适合超大规模矩阵运算。
6. 总结
根据不同的需求和场景,可以选择以下优化方法:
- 小型矩阵:直接使用 NumPy,简单高效。
- 中型矩阵:考虑分块矩阵乘法或 Strassen 算法。
- 大型矩阵:使用 GPU 加速(如 CuPy 或 PyTorch)。
相关文章:

【深度学习】矩阵的理解与应用
一、矩阵基础知识 1. 什么是矩阵? 矩阵是一个数学概念,通常表示为一个二维数组,它由行和列组成,用于存储数值数据。矩阵是线性代数的基本工具之一,广泛应用于数学、物理学、工程学、计算机科学、机器学习和数据分析等…...

我是如何从 0 到 1 找到 Web3 工作的?
作者:Lotus的人生实验 关于我花了一个月的时间,从 0 到 1 学习 Web3 相关的知识和编程知识。然后找到了一个 Web3 创业公司实习的远程工作。 👇👇👇 我的背景: 计算机科班,学历还可以(大厂门槛水平) 毕业工…...
《Keras 3 :使用 Vision Transformers 进行物体检测》:此文为AI自动翻译
《Keras 3 :使用 Vision Transformers 进行物体检测》 作者:Karan V. Dave 创建日期:2022 年 3 月 27 日最后修改时间:2023 年 11 月 20 日描述:使用 Vision Transformer 进行对象检测的简单 Keras 实现。 (i) 此示例使用 Keras 3 在 Colab 中查看 GitHub 源 介绍 A…...
实现向deepseek/GPT等模型的api发送请求/多轮对话(附源码))
java(spring boot)实现向deepseek/GPT等模型的api发送请求/多轮对话(附源码)
我们再启动应用并获取api密钥后就可以对它发送请求了,但是官方文档对于如何进行多轮对话以及怎么自定义参数并没有说的很清楚,给的模板也没有java的,因此我们需要自己实现。 import org.json.JSONArray; import org.json.JSONObject;import j…...

module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法
module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法 pip install opencv-python4.7.0.72 -i https://pypi.tuna.tsinghua.edu.cn/simple 测试: python -c"import cv2"...

将RocketMQ集成到了Spring Boot项目中,实现站内信功能
1. 添加依赖 首先,在pom.xml中添加RocketMQ的依赖: <dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifac…...

Deepseek 怼CHATGPT实况
提示词: 用犀利的语言批评ChatGPT 深度思考(R1) 嗯,用户让我用犀利的语言批评ChatGPT。首先,我需要理解他们的动机。可能他们遇到了ChatGPT的某些问题,比如回答不准确或者缺乏深度,所以想表达不满。也有…...
--阈值的方法)
基础篇11-图像分割(上)--阈值的方法
图像分割是图像处理的重要内容,是位于底层的图像处理、特征提取与上一层次的图像分析之间的关键步骤。图像分割的相关技术较多,分为三篇介绍。本节是上篇,介绍基于阈值的技术。 1 引言 图像分割是计算机视觉和图像处理中的核心任务之一&…...

[特殊字符] LeetCode 62. 不同路径 | 动态规划+递归优化详解
在解 LeetCode 的过程中,路径计数问题是动态规划中一个经典的例子。今天我来分享一道非常基础但极具代表性的题目——不同路径。不仅适合初学者入门 DP(动态规划),还能帮助你打下递归思维的基础。 本文将介绍: &…...

常用的 JVM 参数:配置与优化指南
文章目录 常用的 JVM 参数:配置与优化指南引言 1. 内存管理参数1.1 堆内存配置1.2 方法区(元空间)配置1.3 直接内存配置 2. 垃圾回收参数2.1 垃圾回收器选择2.2 GC 日志配置2.3 GC 调优参数 3. 性能监控参数3.1 堆内存转储3.2 JVM 监控3.3 远…...

【JavaWeb学习Day17】
Tlias智能学习系统(员工管理) 新增员工: 三层架构职责: Controller:1.接收请求参数(员工信息);2.调用service方法;3.响应结果。 具体实现: /***新增员工…...

DeepSeek 提示词:定义、作用、分类与设计原则
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

前端大文件上传
1. 开场概述 “大文件上传是前端开发中常见的需求,但由于文件体积较大,直接上传可能会遇到网络不稳定、服务器限制等问题。因此,通常需要采用分片上传、断点续传、并发控制等技术来优化上传体验” 2. 核心实现方案 “我通常会采用以下方案…...

JDK源码系列(一)Object
Object 概述 Object类是所有类的基类——java.lang.Object。 Object类是所有类的基类,当一个类没有直接继承某个类时,默认继承Object类Object类属于java.lang包下,此包下的所有类在使用时无需手动导入,系统会在程序编译期间自动…...
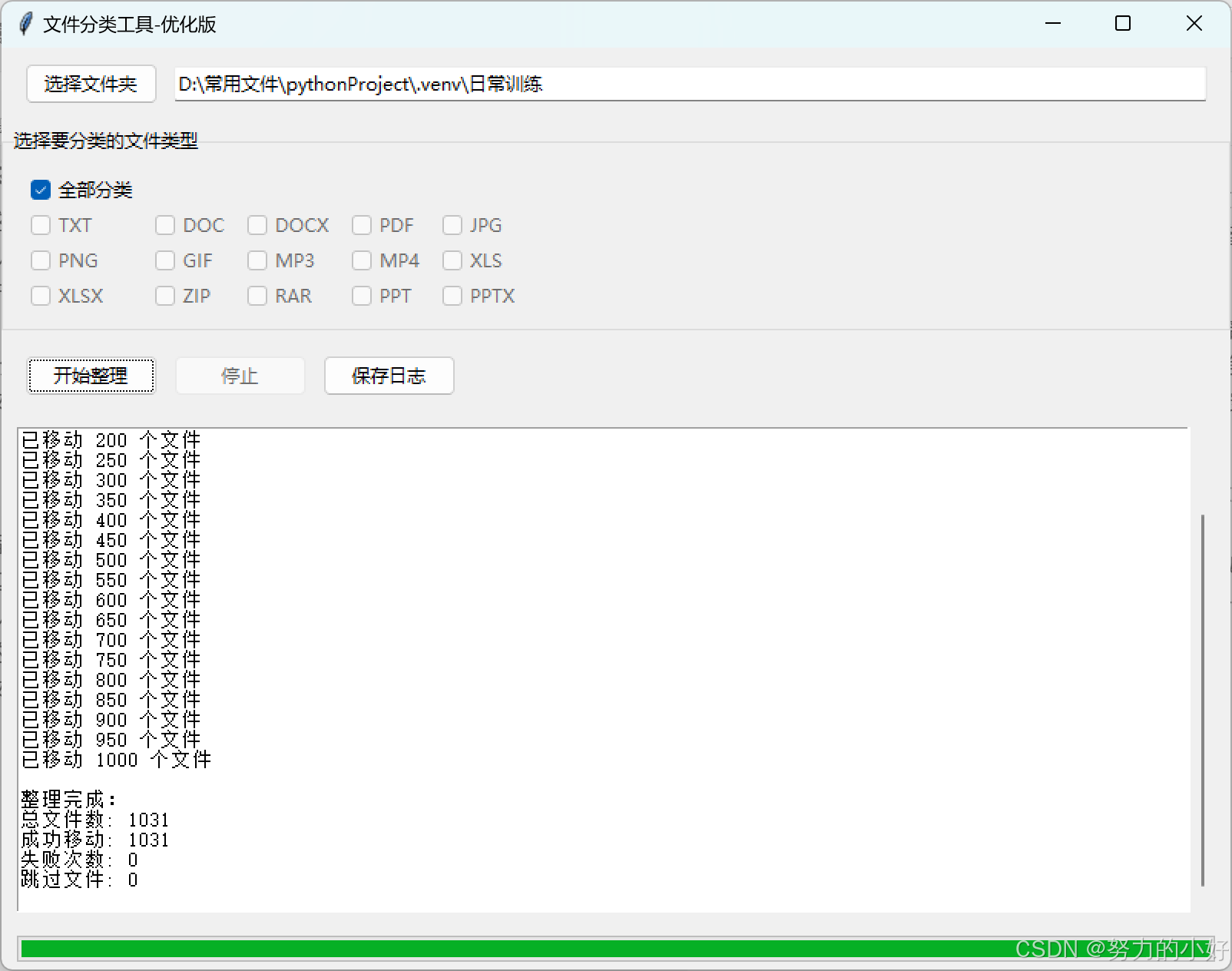
【Python 打造高效文件分类工具】
【Python】 打造高效文件分类工具 一、代码整体结构二、关键代码解析(一)初始化部分(二)界面创建部分(三)核心功能部分(四)其他辅助功能部分 三、运行与使用四、示图五、作者有话说 …...

大数据组件(四)快速入门实时数据湖存储系统Apache Paimon(1)
Paimon的下载及安装,并且了解了主键表的引擎以及changelog-producer的含义参考: 大数据组件(四)快速入门实时数据湖存储系统Apache Paimon(1) 利用Paimon表做lookup join,集成mysql cdc等参考: 大数据组件(四)快速入门实时数据…...

边缘安全加速(Edge Security Acceleration)
边缘安全加速(Edge Security Acceleration,简称ESA)是一种通过将安全功能与网络边缘紧密结合来提升安全性和加速网络流量的技术。ESA的目标是将安全措施部署到接近用户或设备的地方,通常是在网络的边缘,而不是将所有流…...

C/C++高性能Web开发框架全解析:2025技术选型指南
一、工业级框架深度解析(附性能实测) 1. Drogon v2.1:异步框架性能王者 核心架构: Reactor 非阻塞I/O线程池(参考Nginx模型) 协程实现:基于Boost.Coroutine2(兼容C11)…...

fedora 安装 ffmpeg 过程记录
参考博客:1. linux(centos)安装 ffmpeg,并添加 libx264库:https://blog.csdn.net/u013015301/article/details/140778199ffmpeg 执行时如添加参数 -vcodec libx264,会出现错误:Unknown encoder libx264’的错误,缺少li…...

【GPU驱动】OpenGLES图形管线渲染机制
OpenGLES图形管线渲染机制 OpenGL/ES 的渲染管线也是一个典型的图形流水线(Graphics Pipeline),包括多个阶段,每个阶段都负责对图形数据进行处理。管线的核心目标是将图形数据转换为最终的图像,这些图像可以显示在屏幕…...

如何快速解包Godot游戏资源:终极PCK文件提取工具指南
如何快速解包Godot游戏资源:终极PCK文件提取工具指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 如果你正在寻找一个高效、免费的Godot游戏资源解包工具,那么godot-unpac…...

FigmaCN中文插件终极指南:3分钟让Figma界面变中文的专业方案
FigmaCN中文插件终极指南:3分钟让Figma界面变中文的专业方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma复杂的英文界面而烦恼吗?FigmaCN中文插件…...
)
【回归损失函数实战指南】从MAE、MSE到Huber Loss:如何根据数据特性与任务目标精准选择(2024深度解析)
1. 回归损失函数的选择逻辑:从数据特性到模型目标 当你第一次接触回归问题时,可能会觉得"不就是预测一个连续值吗?"。但真正开始调参时,损失函数的选择往往让人头疼。我在电商销量预测项目中就踩过坑——用了MSE损失函数…...

QKeyMapper终极指南:Windows系统下专业级键鼠手柄一体化映射解决方案
QKeyMapper终极指南:Windows系统下专业级键鼠手柄一体化映射解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键…...

Phi-mini-MoE-instruct惊艳效果:中英混合提问+跨语言答案生成实录
Phi-mini-MoE-instruct惊艳效果:中英混合提问跨语言答案生成实录 1. 模型能力全景展示 Phi-mini-MoE-instruct作为一款轻量级混合专家(MoE)指令型小语言模型,在多个基准测试中展现出超越同级模型的卓越性能: 代码能…...

企业财务数字化转型:从RPA到AI Agent的落地路径
在企业数字化转型中,财务一直是最优先落地的场景之一。原因很现实:流程标准、数据集中、效果可量化。但也正因为“好做”,很多企业对财务自动化的理解,长期停留在一个比较初级的阶段,随着AI能力的引入,财务…...

LFM2.5-VL-1.6B惊艳效果展示:OCR文档理解+结构化信息提取真实案例
LFM2.5-VL-1.6B惊艳效果展示:OCR文档理解结构化信息提取真实案例 1. 模型概述 LFM2.5-VL-1.6B是由Liquid AI推出的轻量级多模态大模型,专为端侧和边缘设备优化设计。这个1.6B参数的视觉语言模型(1.2B语言400M视觉)在保持轻量化的…...

智慧树自动刷课插件终极指南:3分钟解放双手,高效完成在线课程
智慧树自动刷课插件终极指南:3分钟解放双手,高效完成在线课程 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的繁琐视频播放流…...

cpolar把内网 K8s 服务秒变全网可访问!cpolar 内网穿透实验室第 703 个成功挑战
软件名称:cpolar 操作系统支持:CentOS、Windows、macOS、Linux 发行版(适配 K8s 常用的 CentOS7/8) 软件介绍:cpolar 是一款轻量级内网穿透工具,不用申请公网 IP、不用改路由器配置,通过简单的…...
|Vue全栈开源|支持App/H5/小程序|含拉新与核销渠道)
高稳定任务悬赏系统源码(已上线运营版)|Vue全栈开源|支持App/H5/小程序|含拉新与核销渠道
温馨提示:文末有联系方式高稳定性商用任务悬赏系统源码 当前已在多个线上项目稳定运行,历经长期压力测试与用户反馈迭代,核心功能零宕机,关键逻辑Bug已全部修复优化。全端兼容|Vue驱动的现代化前端架构 采用主流Vue 3 …...