【JAVA】io流之缓冲流
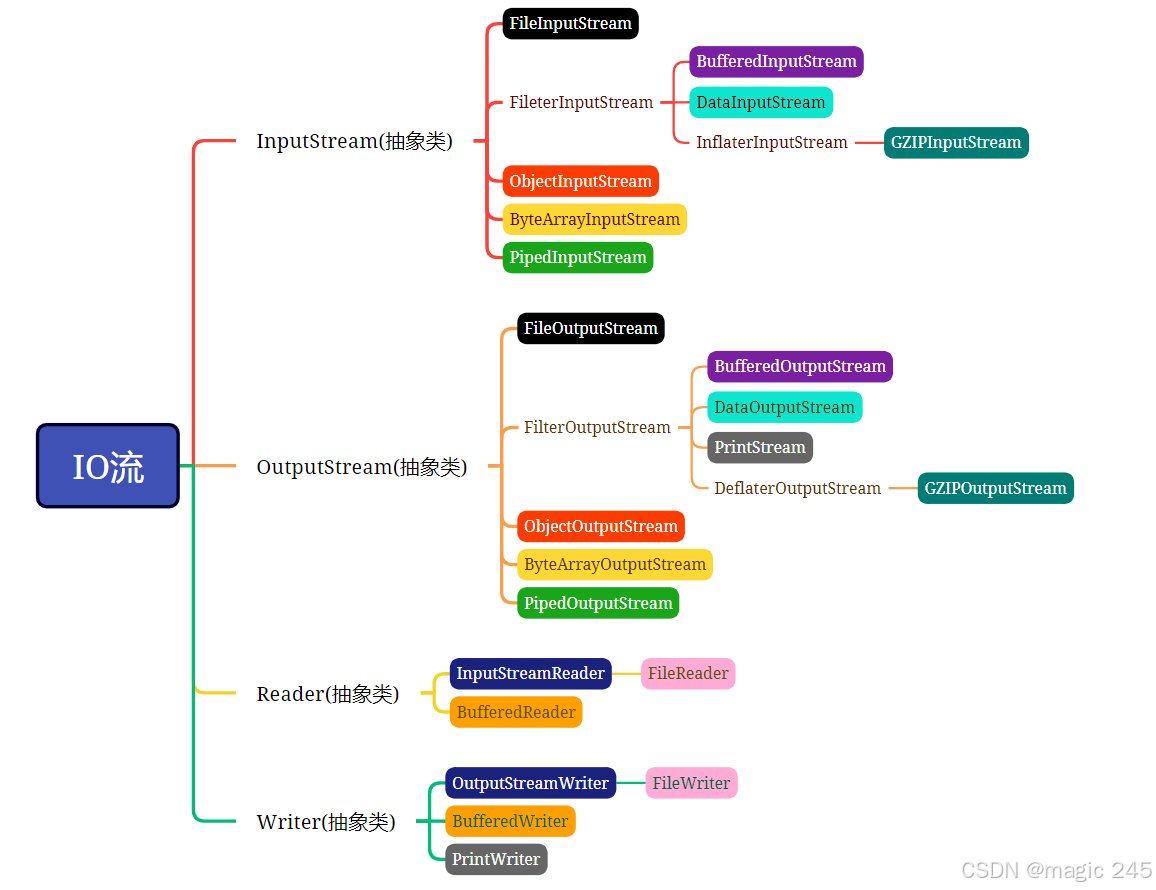
①BufferedInputStream、BufferedOutputStream(适合读写非普通文本文件)
②BufferedReader、BufferedWriter(适合读写普通文本文件。)
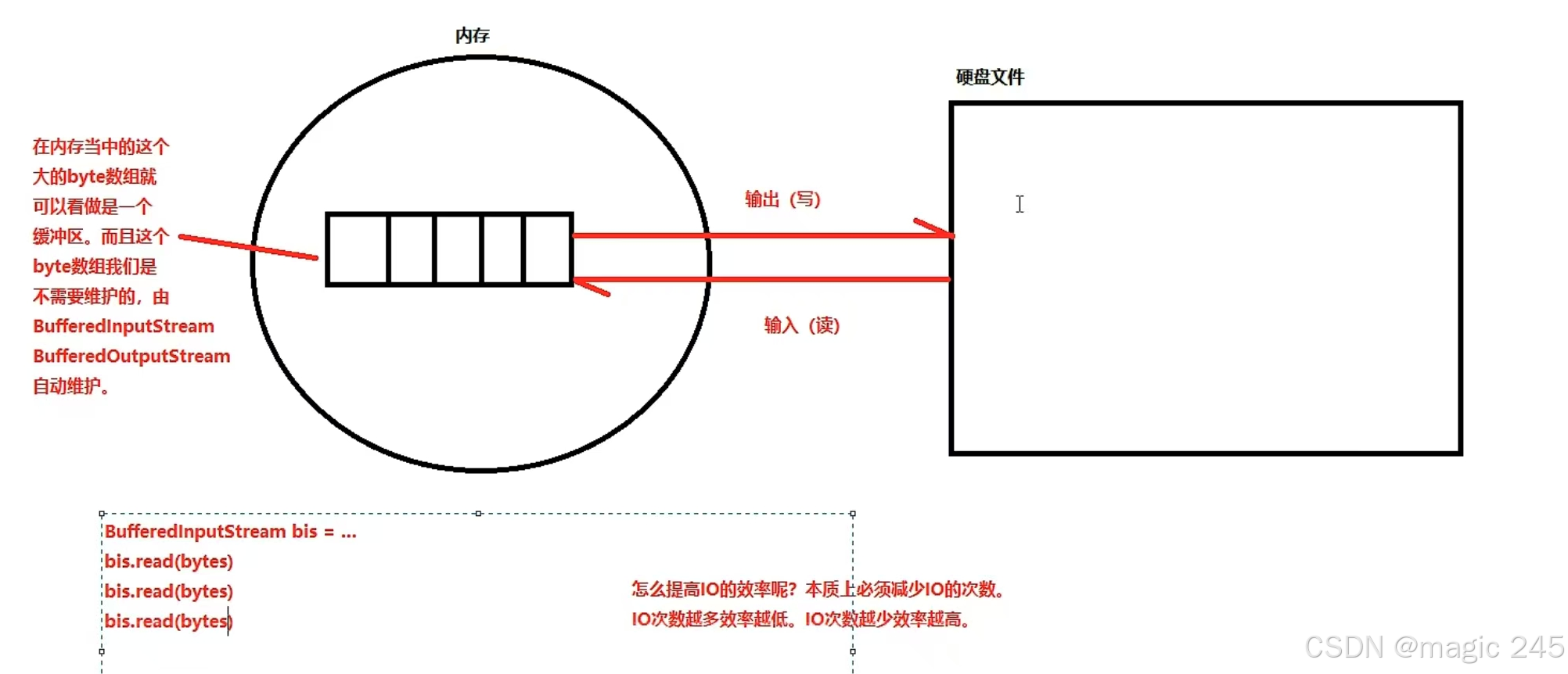
缓冲流的读写速度快,原理是:在内存中准备了一个缓存。读的时候从缓存中读。写的时候将缓存中的数据一次写出。都是在减少和磁盘的交互次数。
一、如何理解缓冲区?
家里盖房子,有一堆砖头要搬在工地100米外,单字节的读取就好比你一个人每次搬一块砖头,从堆砖头的地方搬到工地,这样肯定效率低下。
然而聪明的人类会用小推车,每次先搬砖头搬到小车上,再利用小推车运到工地上去,这样你再从小推车上取砖头是不是方便多了呀!这样效率就会大大提高,缓冲流就好比我们的小推车,给数据暂时提供一个可存放的空间。
二·、BufferedInputStream
FileInputStream/FileOutputStream是节点流
BufferedInputStream是缓冲流(包装流/处理流)。这个流的效率高。自带缓冲区。并且自己维护这个缓冲区。读大文件的时候建议采用这个缓冲流来读取。
关闭流只需要关闭最外层的处理流即可,通过源码就可以看到,当关闭处理流时,底层节点流也会关闭。
1.概述
BufferedInputStream为另一个输入流添加了缓冲功能,它内部维护了一个缓冲区,当从流中读取数据时,会尽可能多地将数据读入缓冲区,这样后续的读取操作就可以直接从缓冲区中获取数据,而不必每次都从底层输入流中读取,从而减少了实际的 I/O 操作次数,提高了读取效率。
2.常用构造方法
BufferedInputStream(InputStream in):创建一个BufferedInputStream,并使用默认大小的缓冲区。参数in是要被缓冲的底层输入流。例如
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;/*** 1. java.io.BufferedInputStream的用法和FileInputStream用法相同。** 2. 他们的不同点是:* FileInputStream是节点流。* BufferedInputStream是缓冲流(包装流/处理流)。这个流的效率高。自带缓冲区。并且自己维护这个缓冲区。读大文件的时候建议采用这个缓冲流来读取。** 3. BufferedInputStream对 FileInputStream 进行了功能增强。增加了一个缓冲区的功能。** 4. 怎么创建一个BufferedInputStream对象呢?构造方法:* BufferedInputStream(InputStream in)**/
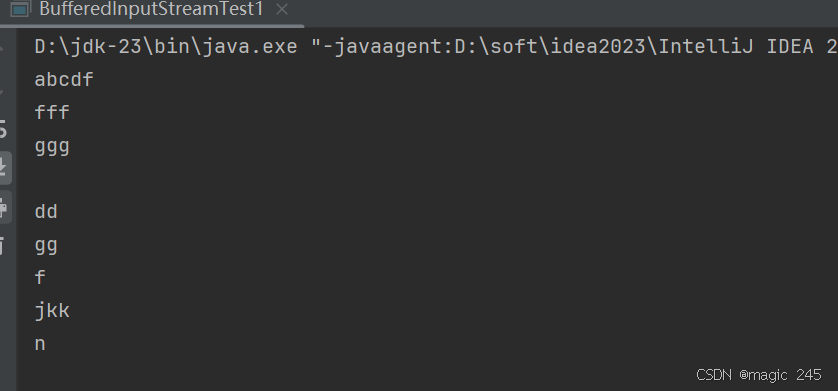
public class BufferedInputStreamTest1 {public static void main(String[] args) {BufferedInputStream bis = null;try {// 创建节点流//FileInputStream in = new FileInputStream("file.txt");// 创建包装流//bis = new BufferedInputStream(in);// 组合起来写bis = new BufferedInputStream(new FileInputStream("file.txt"));// 读,和FileInputStream用法完全相同byte[] bytes = new byte[1024];int readCount = 0;while((readCount = bis.read(bytes)) != -1){System.out.print(new String(bytes, 0, readCount));}} catch (Exception e) {e.printStackTrace();} finally {// 包装流以及节点流,你只需要关闭最外层的那个包装流即可。节点流不需要手动关闭。if (bis != null) {try {bis.close();} catch (IOException e) {e.printStackTrace();}}}}
}在根路径下创建file.txt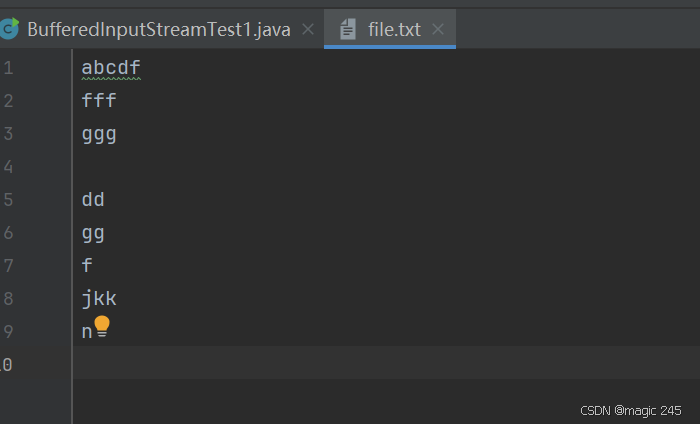
运行结果:
⑵.BufferedInputStream(InputStream in, int size):
创建一个BufferedInputStream,并指定缓冲区的大小为size字节。例如:
FileInputStream fis = new FileInputStream("test.txt");
BufferedInputStream bis = new BufferedInputStream(fis, 8192);read方法主要功能是通过预加载数据到内存缓冲区,减少底层 I/O 操作的次数
三、BufferedOutputStream
常用构造方法 BufferedOutputStream(OutputStream out):创建一个BufferedOutputStream,并使用默认大小的缓冲区。参数out是要被缓冲的底层输出流。例如:
FileOutputStream fos = new FileOutputStream("test.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);BufferedOutputStream(OutputStream out, int size):创建一个BufferedOutputStream,并指定缓冲区的大小为size字节。例如:
FileOutputStream fos = new FileOutputStream("test.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos, 8192);import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** 1. java.io.BufferedOutputStream也是一个缓冲流。属于输出流。* 2. 怎么创建BufferedOutputStream对象?* BufferedOutputStream(OutputStream out)* 3. FileOutputStream是节点流。 BufferedOutputStream是包装流。*/
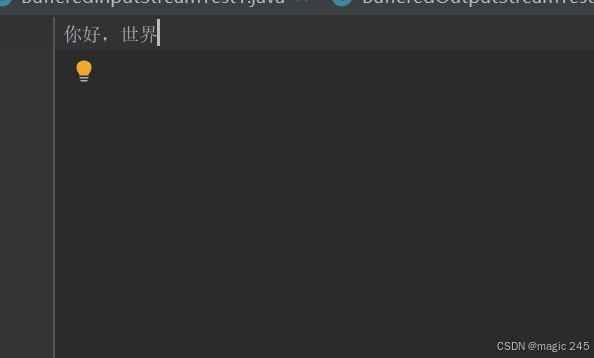
public class BufferedOutputStreamTest01 {public static void main(String[] args) {BufferedOutputStream bos = null;try {bos = new BufferedOutputStream(new FileOutputStream("file.txt"));bos.write("你好,世界".getBytes());// 缓冲流需要手动刷新。bos.flush();} catch (Exception e) {e.printStackTrace();} finally {if (bos != null) {try {// 只需要关闭最外层的包装流即可。bos.close();} catch (IOException e) {e.printStackTrace();}}}}
}运行结果:
四、使用BufferedInputStream 和BufferedOutputStream完成文件的复制
/*** 使用BufferedInputStream BufferedOutputStream完成文件的复制。*/
public class BufferedInputOutputStreamCopy {public static void main(String[] args) {long begin = System.currentTimeMillis();try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\Users\\86178\\Desktop\\2024\\test3.txt"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("C:\\Users\\86178\\Desktop\\2024\\testwriter.txt"))){// 一边读一边写byte[] bytes = new byte[1024];int readCount = 0;while((readCount = bis.read(bytes)) != -1){bos.write(bytes, 0, readCount);}// 手动刷新bos.flush();} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}long end = System.currentTimeMillis();System.out.println("带有缓冲区的拷贝耗时"+(end - begin)+"毫秒"); // 671}
}五、缓存流的mark与reset
输入流中的 mark 和 reset(以 BufferedInputStream 为例)
1. 方法说明
void mark(int readlimit):在流的当前位置设置一个标记。readlimit参数指定了在标记位置失效之前可以读取的最大字节数。也就是说,在读取了readlimit个字节之后,标记可能会失效,此时调用reset方法可能会抛出IOException。void reset():将流的位置重置到之前通过mark方法设置的标记位置。如果标记已经失效(例如,已经读取超过readlimit个字节),则会抛出IOException。
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;public class BufferedInputStreamMarkResetExample {public static void main(String[] args) {try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.txt"))) {// 读取前 3 个字节int data;for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}// 设置标记,允许在读取 10 个字节内重置到该位置bis.mark(10);// 继续读取 3 个字节for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}// 重置到标记位置bis.reset();// 再次从标记位置读取 3 个字节for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}} catch (IOException e) {e.printStackTrace();}}
}运行结果: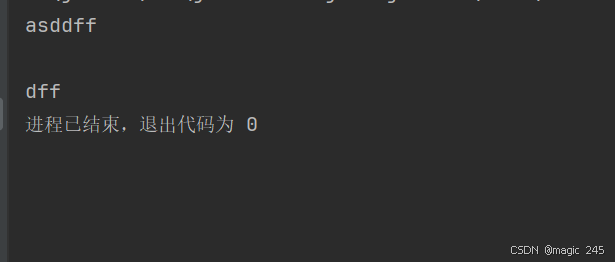
输出流中的 mark 和 reset
在 BufferedOutputStream 中,并没有直接提供 mark 和 reset 方法。这是因为输出流的主要目的是将数据写入目标,而不是像输入流那样可以灵活地回退读取。一旦数据被写入输出流,通常是不可逆的操作。
不过,如果你需要实现类似的功能,可以考虑使用一些辅助的数据结构(如 ByteArrayOutputStream)来缓存数据,然后根据需要重新写入。
相关文章:
【JAVA】io流之缓冲流
①BufferedInputStream、BufferedOutputStream(适合读写非普通文本文件) ②BufferedReader、BufferedWriter(适合读写普通文本文件。) 缓冲流的读写速度快,原理是:在内存中准备了一个缓存。读的时候从缓存中…...
这么用?)
from flask_session import Session 为什么是Session(app)这么用?
在 Flask 中,from flask_session import Session 和 Session(app) 的用法是为了配置和使用 Flask-Session 扩展,将用户的会话(Session)数据存储到服务器端(如 Redis、数据库或文件系统),而不是默…...

AI赋能的未来城市:如何用智能化提升生活质量?
这会是我们憧憬的未来城市吗? 随着技术的不断进步和城市化进程的加速,现代城市面临着诸多挑战——交通拥堵、环境污染、能源消耗、人口老龄化等问题愈发突出。为了应对这些挑战,建设智慧城市已成为全球发展的重要趋势。在这一进程中…...

【Go】Go wire 依赖注入
1. wire 简介 wire 是一个 Golang 的依赖注入框架(类比 Spring 框架提供的依赖注入功能) ⭐ 官方文档:https://github.com/google/wire 这里关乎到编程世界当中一条好用的设计原则:A用到了B,那么B一定是通过依赖注入的…...

深度集成DeepSeek与Java开发:智能编码新纪元全攻略 [特殊字符]
一、DeepSeek:Java开发者的第二大脑 🧠 1.1 传统开发痛点VS智能开发体验 传统开发DeepSeek智能辅助效率提升对比手动编写重复代码一键生成模板代码代码量减少70%↑调试全靠断点日志智能定位缺陷根源问题排查时间缩短60%↓文档维护耗时费力自动生成更新…...

WEB前端将指定DOM生成图片并下载最佳实践(html2canvas)
前言: html2canvas 是一个 JavaScript 库,其主要作用是将 HTML 元素或其部分内容渲染为 Canvas 图像。通过它,开发者可以将网页中的任意 DOM 元素(包括文本、图片、样式等)转换为图片格式(如 PNG 或 JPEG&…...

掌握.NET Core后端发布流程,如何部署后端应用?
无论你是刚接触.NET Core的新手还是已有经验的开发者,在这篇文章中你将会学习到一系列实用的发布技巧与最佳实践,帮助你高效顺利地将.NET Core后端应用部署到生产环境中 目录 程序发布操作 Docker容器注册表 文件夹发布 导入配置文件 网站运行操作 …...

深度学习学习笔记(34周)
目录 摘要 Abstracts 简介 Hourglass Module(Hourglass 模块) 网络结构 Intermediate Supervision(中间监督) 训练过程细节 评测结果 摘要 本周阅读了《Stacked Hourglass Networks for Human Pose Estimation》…...

C++ 设计模式-备忘录模式
游戏存档实现,包括撤销/重做、持久化存储、版本控制和内存管理 #include <iostream> #include <memory> #include <deque> #include <stack> #include <chrono> #include <fstream> #include <sstream> #include <ct…...

TOGAF之架构标准规范-信息系统架构 | 应用架构
TOGAF是工业级的企业架构标准规范,信息系统架构阶段是由数据架构阶段以及应用架构阶段构成,本文主要描述信息系统架构阶段中的应用架构阶段。 如上所示,信息系统架构(Information Systems Architectures)在TOGAF标准规…...

第一届网谷杯
统计四场的所有题目(共计12题,四场比赛一共上了21题【包括换题】) 随便记记,以免老题复用(已经复用了) Web 文件包含 1 伪协议 http://120.202.175.143:8011/?cphp://filter/convert.base64-encode/reso…...

Linux(ubuntu) GPU CUDA 构建Docker镜像
一、创建Dockerfile FROM ubuntu:20.04#非交互式,以快速运行自动化任务或脚本,无需图形界面 ENV DEBIAN_FRONTENDnoninteractive# 安装基础工具 RUN apt-get update && apt-get install -y \curl \wget \git \build-essential \software-proper…...

mysql -DQL语句和DCL语句
DQL 数据查询语言(Data Query Language,DQL)是数据库操作语言的重要组成部分,主要用于从数据库中检索数据,核心关键字为SELECT。以下从语法结构、常见操作及示例等方面详细介绍: 语法结构 DQL 的标准语法…...

掌握 ElasticSearch 组合查询:Bool Query 详解与实践
掌握 ElasticSearch 组合查询:Bool Query 详解与实践 一、引言 (Introduction)二、Bool 查询基础2.1 什么是 Bool 查询?2.2 Bool 查询的四种子句2.3 语法结构 三、Bool 查询的四种子句详解与示例3.1 must 子句3.2 filter 子句3.3 should 子句3.4 must_no…...

C++ 类和对象(友元、内部类、匿名对像)
目录 一、前言 二、正文 1.友元 1.1友元函数的使用 1.1.1外部友元函数可访问类的私有成员,友员函数仅仅是一种声明,他不是类的成员函数。 1.1.2一个函数可以是多个类的友元函数 2.友元类的使用 2.1什么是友元类 2.2 友元类的关系是单向的&#x…...

PostgreSQL 常用函数
PostgreSQL 常用函数 在数据库管理系统中,函数是执行特定任务的基本构建块。PostgreSQL 是一个功能强大的开源关系数据库管理系统,提供了丰富的内置函数,这些函数极大地增强了数据库操作的能力。以下是一些在 PostgreSQL 中常用的函数&#…...

掌握 ElasticSearch 四种match查询的原理与应用
文章目录 一、引言 (Introduction)二、准备工作:创建索引和添加示例数据三、match 查询四、match_all 查询五、multi_match 查询六、match_phrase 查询七、总结 (Conclusion) 一、引言 (Introduction) 在信息爆炸的时代,快速准确地找到所需信息至关重要…...

解决:Conda虚拟环境中未设置CUDA_HOME的问题
背景:我是Ubuntu22.04系统,最近在复现FoundationPose算法,按照README构建部署环境时,有一步一直卡住,看了下是未找到CUDA_HOME这个环境变量。 网上搜了下这个错误,需要设置CUDA_HOME的环境变量路径&#x…...

easyexcel和poi同时存在版本问题,使用easyexcel导出excel设置日期格式
这两天在使用easyexcel导出excel的时候日期格式全都是字符串导致导出的excel列无法筛选 后来调整了一下终于弄好了,看一下最终效果 这里涉及到easyexcel和poi版本冲突的问题,一直没搞定,最后狠下心来把所有的都升级到了最新版,然…...

HarmonyOS 开发套件 介绍——下篇
HarmonyOS 开发套件 介绍——下篇 在HarmonyOS的生态中,开发套件作为支撑整个系统发展的基石,为开发者提供了丰富而强大的工具和服务。本文将深入继续介绍HarmonyOS SDK、ArkCompiler、DevEco Testing、AppGallery等核心组件,帮助开发者全面掌…...
)
Linux系统崩溃别慌!手把手教你用Timeshift在Deepin/UOS上快速恢复桌面(含命令行救急指南)
Linux系统崩溃急救手册:Timeshift在Deepin/UOS上的全场景恢复指南 那天下午,我正在赶一份重要文档,Deepin系统突然弹出一个更新提示。像往常一样点击"立即更新"后,屏幕却陷入了黑屏循环重启的噩梦。作为深度系统三年老用…...

关于在vs2022中使用清单模式遇到的问题
问题1: 1>"D:\vcpkg\vcpkg.exe" install --x-wait-for-lock --triplet "x86-windows" --vcpkg-root "D:\vcpkg\\" "--x-manifest-root=D:\Projects\Test\\" "--x-install-root=D:\Projects\Test\vcpkg_installed\x86-windo…...

春秋云境CVE-2021-42013
1.阅读靶场介绍 这里主要是得到路径穿越和命令执行 这两个关键字眼 这里说点博主打靶场的心得 就是首先是根据靶场介绍我们会得到大致方向 如果打不出来的话我们可以去找度娘 再然后就是去把介绍的文字喂给ai看看ai给到什么建议 最后就是找github看看有没有了 如果都没有…...

Gin:自定义日志、验证器与中间件全指南
前言在使用 Gin 开发 Web 服务时,默认的功能已经能覆盖大部分场景,但在生产环境中我们往往需要更精细的控制——比如定制日志格式以便于 ELK 采集、增加业务专属的参数校验规则、或者编写通用的请求拦截中间件。Gin 本身提供了非常优雅的扩展机制&#x…...

Windows Cleaner:如何通过3个简单步骤解决C盘空间不足和系统卡顿问题
Windows Cleaner:如何通过3个简单步骤解决C盘空间不足和系统卡顿问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windo…...
)
从VGA到8K:一文读懂HDMI协议进化史与关键版本差异(1.4/2.0/2.1对比)
从VGA到8K:HDMI协议进化史与关键版本差异全解析 2002年12月,当索尼、松下、东芝等七家电子巨头联合发布HDMI 1.0标准时,很少有人能预料到这个接口会在未来二十年彻底改变视听产业的格局。如今,从家庭影院到电竞显示器,…...

如何用BabelDOC轻松解决PDF翻译难题:5步完整指南
如何用BabelDOC轻松解决PDF翻译难题:5步完整指南 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 你是否曾为翻译PDF文档而烦恼?格式错乱、公式丢失、表格变形——这些问…...

不只是安装:用Docker在Ubuntu 20.04上快速部署可复现的UHD 3.15 + GNU Radio 3.8开发环境
容器化SDR开发环境:基于Docker的UHD 3.15与GNU Radio 3.8高效部署指南 当你在三台不同配置的工作站上第五次重装系统依赖时,时钟已指向凌晨三点。libboost版本冲突导致编译失败的红字在屏幕上闪烁,隔壁工位的咖啡机发出嘲讽般的嗡鸣——这可能…...

Spring Boot AOP 拦截链执行顺序
Spring Boot AOP 拦截链执行顺序解析 在Spring Boot开发中,AOP(面向切面编程)是实现横切关注点的重要技术。通过拦截链(Interceptor Chain),开发者可以在方法执行前后插入自定义逻辑。当多个切面同时作用于…...

从‘老王分遗产’到智能指针:用生活例子彻底搞懂C++的dynamic_cast和std::dynamic_pointer_cast
从‘老王分遗产’到智能指针:用生活例子彻底搞懂C的dynamic_cast和std::dynamic_pointer_cast 想象一下,你正在处理一个复杂的家族遗产分配问题。老王有一对儿女——小明和小红,他们各自有不同的财产继承方式。在C的世界里,这种家…...