爬虫解析库:Beautiful Soup的详细使用
文章目录
- 1. 安装 Beautiful Soup
- 2. 基本用法
- 3. 选择元素
- 4. 提取数据
- 5. 遍历元素
- 6. 修改元素
- 7. 搜索元素
- 8. 结合 requests 使用
- 9. 示例:抓取并解析网页
- 10. 注意事项
Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库,它提供了简单易用的 API,能够快速提取和操作网页中的数据。以下是 Beautiful Soup 的详细使用方法:
1. 安装 Beautiful Soup
首先,确保你已经安装了 Beautiful Soup 和解析器(如 lxml 或 html.parser)。你可以通过以下命令安装:pip install beautifulsoup4 lxml
2. 基本用法
初始化:你可以从字符串、文件或 URL 初始化 Beautiful Soup 对象:
from bs4 import BeautifulSoup# 从字符串初始化
html = """
<html><head><title>示例页面</title></head><body><div id="container"><p class="item">Item 1</p><p class="item">Item 2</p><p class="item">Item 3</p></div></body>
</html>
"""
soup = BeautifulSoup(html, 'lxml') # 使用 lxml 解析器# 从文件初始化
with open('example.html', 'r', encoding='utf-8') as f:soup = BeautifulSoup(f, 'lxml')# 从 URL 初始化(结合 requests)
import requests
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'lxml')
3. 选择元素
Beautiful Soup 提供了多种选择元素的方法。
通过标签名选择
# 选择所有 <p> 标签
p_tags = soup.find_all('p')
for p in p_tags:print(p.text)
通过类名选择
# 选择所有 class 为 "item" 的元素
items = soup.find_all(class_='item')
for item in items:print(item.text)
通过 ID 选择
# 选择 id 为 "container" 的元素
container = soup.find(id='container')
print(container)
通过属性选择
# 选择所有具有 href 属性的 <a> 标签
links = soup.find_all('a', href=True)
for link in links:print(link['href'])
4. 提取数据
获取文本内容
# 获取第一个 <p> 标签的文本内容
text = soup.find('p').text
print(text)
获取属性值
# 获取第一个 <a> 标签的 href 属性
href = soup.find('a')['href']
print(href)
获取 HTML 内容
# 获取第一个 <div> 标签的 HTML 内容
html = soup.find('div').prettify()
print(html)
5. 遍历元素
遍历子元素
# 遍历 id 为 "container" 的所有子元素
container = soup.find(id='container')
for child in container.children:print(child)
遍历所有后代元素
# 遍历 id 为 "container" 的所有后代元素
for descendant in container.descendants:print(descendant)
遍历兄弟元素
# 遍历第一个 <p> 标签的所有兄弟元素
first_p = soup.find('p')
for sibling in first_p.next_siblings:print(sibling)
6. 修改元素
修改文本内容
# 修改第一个 <p> 标签的文本内容
first_p = soup.find('p')
first_p.string = 'New Item'
print(soup)
修改属性值
# 修改第一个 <a> 标签的 href 属性
first_a = soup.find('a')
first_a['href'] = 'https://newexample.com'
print(soup)
添加新元素
# 在 id 为 "container" 的末尾添加一个新 <p> 标签
new_p = soup.new_tag('p', class_='item')
new_p.string = 'Item 4'
container.append(new_p)
print(soup)
7. 搜索元素
使用正则表达式
import re# 查找所有文本中包含 "Item" 的 <p> 标签
items = soup.find_all('p', text=re.compile('Item'))
for item in items:print(item.text)
使用自定义函数
# 查找所有 class 包含 "item" 的 <p> 标签
def has_item_class(tag):return tag.has_attr('class') and 'item' in tag['class']items = soup.find_all(has_item_class)
for item in items:print(item.text)
8. 结合 requests 使用
Beautiful Soup 通常与 requests 库结合使用,用于抓取网页并解析:
import requests
from bs4 import BeautifulSoup# 抓取网页内容
url = 'https://example.com'
response = requests.get(url)
html = response.text# 解析网页
soup = BeautifulSoup(html, 'lxml')# 提取标题
title = soup.find('title').text
print("网页标题:", title)# 提取所有链接
links = soup.find_all('a', href=True)
for link in links:href = link['href']text = link.textprint(f"链接文本: {text}, 链接地址: {href}")
9. 示例:抓取并解析网页
以下是一个完整的示例,展示如何使用 Beautiful Soup 抓取并解析网页数据:
import requests
from bs4 import BeautifulSoup# 抓取网页内容
url = 'https://example.com'
response = requests.get(url)
html = response.text# 解析网页
soup = BeautifulSoup(html, 'lxml')# 提取标题
title = soup.find('title').text
print("网页标题:", title)# 提取所有段落
paragraphs = soup.find_all('p')
for p in paragraphs:print("段落内容:", p.text)# 提取所有链接
links = soup.find_all('a', href=True)
for link in links:href = link['href']text = link.textprint(f"链接文本: {text}, 链接地址: {href}")
10. 注意事项
编码问题:如果网页编码不是 UTF-8,可能需要手动指定编码。
动态内容:Beautiful Soup 只能解析静态 HTML,无法处理 JavaScript 动态加载的内容。如果需要处理动态内容,可以结合 Selenium 或 Pyppeteer 使用。
通过以上方法,你可以使用 Beautiful Soup 轻松解析和提取网页中的数据。它的语法简洁且功能强大,非常适合快速开发爬虫和数据采集工具。
相关文章:

爬虫解析库:Beautiful Soup的详细使用
文章目录 1. 安装 Beautiful Soup2. 基本用法3. 选择元素4. 提取数据5. 遍历元素6. 修改元素7. 搜索元素8. 结合 requests 使用9. 示例:抓取并解析网页10. 注意事项 Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库,它提供了简单易用的 API…...

OpenHarmony-4.基于dayu800 GPIO 实践(2)
基于dayu800 GPIO 进行开发 1.DAYU800开发板硬件接口 LicheePi 4A 板载 2x10pin 插针,其中有 16 个原生 IO,包括 6 个普通 IO,3 对串口,一个 SPI。TH1520 SOC 具有4个GPIO bank,每个bank最大有32个IO: …...

【C++设计模式】观察者模式(1/2):从基础到优化实现
1. 引言 在 C 软件与设计系列课程中,观察者模式是一个重要的设计模式。本系列课程旨在深入探讨该模式的实现与优化。在之前的课程里,我们已对观察者模式有了初步认识,本次将在前两次课程的基础上,进一步深入研究,着重…...

《机器学习数学基础》补充资料:欧几里得空间的推广
在《机器学习数学基础》第 1 章介绍了向量空间,并且说明了机器学习问题通常是在欧几里得空间。然而,随着机器学习技术的发展,特别是 AI 技术开始应用于科学研究中,必然会涉及到其他类型的空间。本文即在《机器学习数学基础》一书所…...
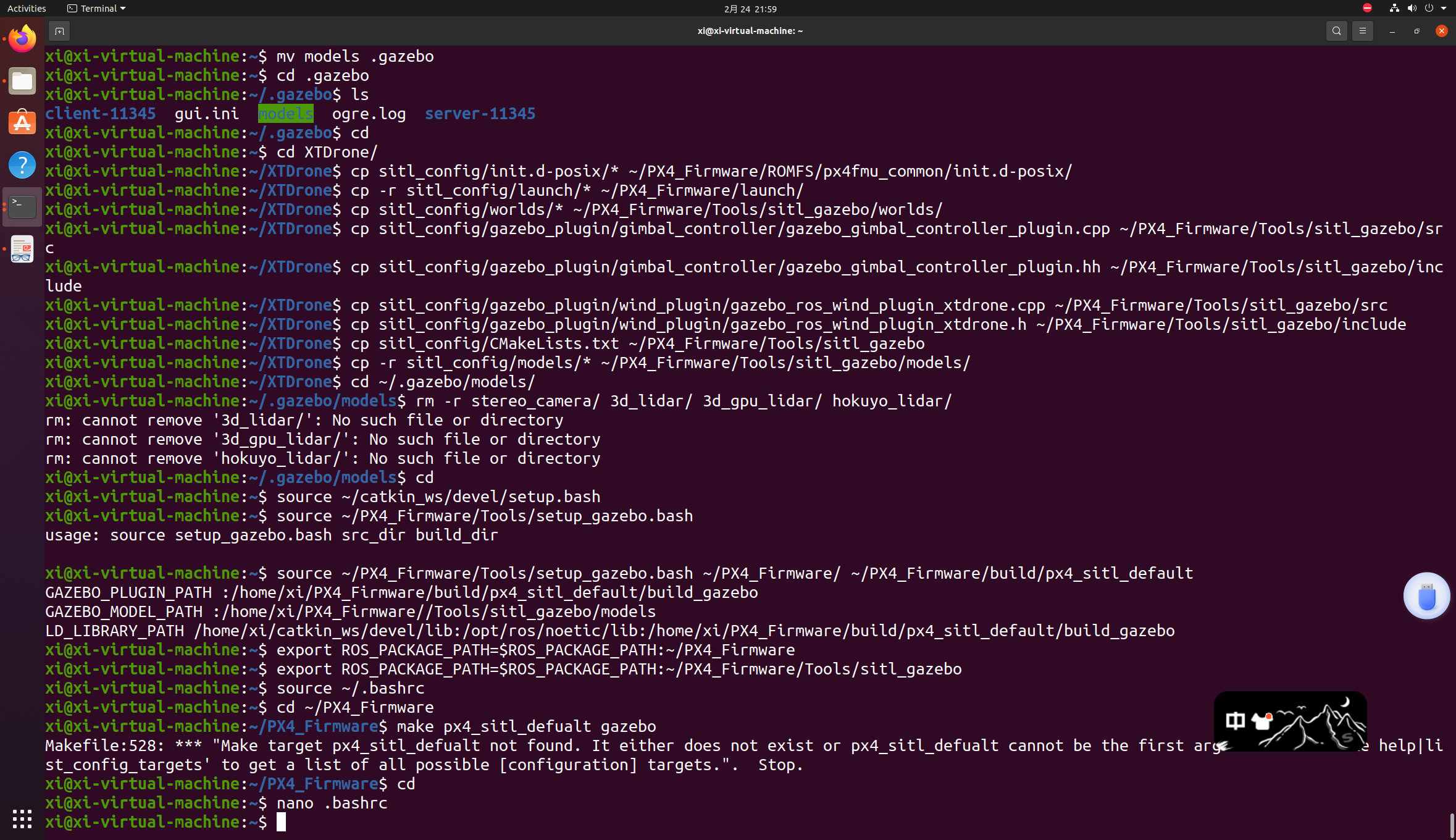
在配置PX4中出现的问题2
想要原教程的请看:第一次配置中出现的问题 前面一切正常(gazebo导入models那一步在刚刚解压好的文件夹里就删不掉stereo_camera等文件,ls打开也看不到,应该时我下的包里面本来就没有),到 make px4_sitl_def…...
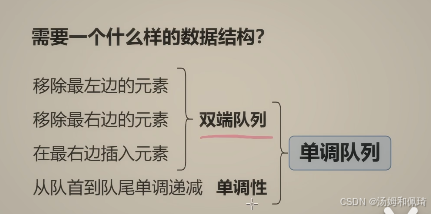
2025-2-24-4.9 单调栈与单调队列(基础题)
文章目录 4.9 单调栈与单调队列(基础题)单调栈739. 每日温度42. 接雨水单调队列239. 滑动窗口最大值 4.9 单调栈与单调队列(基础题) 很有趣的两个数据结构。 原视频讲解链接 单调栈 739. 每日温度 题目链接 给定一个整数数组 te…...

python绘图之swarmplot分布散点图
swarmplot 是 Seaborn 提供的一种用于展示分类数据分布的散点图。它的主要作用是将数据点按照分类变量(通常是离散变量)进行分组,并在每个分类中以一种非重叠的方式展示数据点的位置。这种可视化方式可以帮助我们直观地理解数据在不同分类下的…...
)
数据库之MySQL——事务(一)
1、MySQL之事务的四大特性(ACID)? 原子性(atomicity):一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操…...

Linux学习笔记之文件
1.文件 1.1文件属性 当我们创建文件时,文件就有了对应的属性,可以用mkdir创建目录,touch创建普通文件。用ls -al查看文件属性。 从上图可以看出目录或者文件的所有者,所属组,其他人权限,创建时间等信息。由…...

LLM学习
1、基础概念篇 大模型训练三部曲Pretraining SFT RLHF...
Classic Control Theory | 13 Complex Poles or Zeros (第13课笔记-中文版)
笔记链接:https://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQhttps://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQ...

给小米/红米手机root(工具基本为官方工具)——KernelSU篇
目录 前言准备工作下载刷机包xiaomirom下载刷机包【适用于MIUI和hyperOS】“hyper更新”微信小程序【只适用于hyperOS】 下载KernelSU刷机所需程序和驱动文件 开始刷机设置手机第一种刷机方式【KMI】推荐提取boot或init_boot分区 第二种刷机方式【GKI】不推荐 结语 前言 刷机需…...

【MySQL】表的增删查改(CRUD)(上)
个人主页:♡喜欢做梦 欢迎 👍点赞 ➕关注 ❤️收藏 💬评论 CRUD:Create(新增数据)、Retrieve(查询数据)、Update(修改数据)、Delete(修改数据…...

测试用例的Story是什么?
测试用例的 Story(用户故事)是指描述某个功能或场景的具体用户需求,它通常以简短的业务背景用户操作期望结果的方式呈现,使测试人员能够理解测试的目标和价值。用户故事能够帮助团队更好地设计测试用例,确保功能满足用…...

15.4 FAISS 向量数据库实战:构建毫秒级响应的智能销售问答系统
FAISS 向量数据库实战:构建毫秒级响应的智能销售问答系统 关键词:FAISS 向量数据库、销售知识库构建、相似度检索优化、大规模问答匹配、量化索引技术 1. 销售问答场景的向量化挑战与解决方案 1.1 传统检索方案痛点分析 #mermaid-svg-AeVgih79asJb7lb8 {font-family:"…...

Golang笔记——Interface类型
大家好,这里是,关注 公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Golang的interface数据结构类型,包括基本实现和使用等。 文章目录 Go 语言中的 interface 详解接口定义实现接口空接口 interface{} 示例&…...

如何查看图片的原始格式
问题描述:请求接口的时候,图片base64接口报错,使用图片url请求正常 排查发现是图片格式的问题: 扩展名可能被篡改:如果文件损坏或扩展名被手动修改,实际格式可能与显示的不同,需用专业工具验证…...

FreiHAND (handposeX-json 格式)数据集-release >> DataBall
FreiHAND (handposeX-json 格式)数据集-release 注意: 1)为了方便使用,按照 handposeX json 自定义格式存储 2)使用常见依赖库进行调用,降低数据集使用难度。 3)部分数据集获取请加入:DataBall-X数据球(free) 4)完…...

【Rust中级教程】2.8. API设计原则之灵活性(flexible) Pt.4:显式析构函数的问题及3种解决方案
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 说句题外话,这篇文章一共5721个字,是我截至目前写的最长的一篇文章&a…...

LabVIEW Browser.vi 库说明
browser.llb 库位于C:\Program Files (x86)\National Instruments\LabVIEW 2019\vi.lib\Platform目录,它是 LabVIEW 平台下用于与网络浏览器相关操作的重要库。该库为 LabVIEW 开发者提供了一系列工具,用于实现网页浏览控制、网页数据获取与交互等功能&a…...
)
【SITS2026独家授权】:AGI金融预测模型训练全链路手册(含QuantConnect适配代码、FedAvg联邦微调脚本、SEC/FCA双合规审计checklist)
第一章:SITS2026独家授权声明与AGI金融预测范式演进 2026奇点智能技术大会(https://ml-summit.org) SITS2026(Singularity Intelligence & Trading Systems 2026)是由全球AGI金融研究联盟(GAFRA)与国际机器学习峰…...
)
别再折腾CUDA版本了!用Anaconda Navigator一键搞定TensorFlow/PyTorch的GPU环境(附版本匹配表)
告别CUDA版本地狱:Anaconda Navigator极简搭建TensorFlow/PyTorch GPU环境实战指南 刚入坑深度学习的开发者,十有八九会在环境配置阶段崩溃——CUDA版本不兼容、cuDNN找不到对应版本、Python环境冲突...这些报错信息就像一堵高墙,把无数热情挡…...

VSAN集群安全关机与重启实战指南
1. VSAN集群安全关机与重启的核心挑战 第一次接触VSAN集群关机流程时,我也犯过直接断电的低级错误。那是在测试环境里,四台ESXi主机同时断电后,整个VSAN存储池直接崩溃,花了整整两天时间才恢复数据。这次惨痛教训让我明白…...

泵箱控制协议
安装泵箱调试电路板基于CIU32步进电机的驱动 D:\zhuoqing\window\ARM\Keil\CIU32\2026\April\TestF003PWMPIO-V1\Source\main.c AD\Test\2026\April\StepMotorDrvF003A4950V1.SchDoc 01 泵箱控制协议一、接口修改 泵箱中的接线,包括有三组线缆, 一是步进…...

3分钟上手Snap Hutao:原神玩家的终极智能助手指南
3分钟上手Snap Hutao:原神玩家的终极智能助手指南 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hutao …...

Win11Debloat终极指南:如何快速清理Windows 11预装软件和优化系统性能
Win11Debloat终极指南:如何快速清理Windows 11预装软件和优化系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to d…...

Manjaro新手避坑指南:从依赖缺失到签名错误,一次搞定所有安装报错
Manjaro新手避坑指南:从依赖缺失到签名错误,一次搞定所有安装报错 第一次打开Manjaro的终端,输入sudo pacman -S命令时,那种期待和忐忑交织的感觉我还记得很清楚。作为一个刚从Ubuntu转投Arch系的新手,我完全没预料到接…...
Pixel Language Portal入门必看:Hunyuan-MT-7B模型许可证解读、商用合规性与数据隐私说明
Pixel Language Portal入门必看:Hunyuan-MT-7B模型许可证解读、商用合规性与数据隐私说明 1. 产品概述与技术背景 Pixel Language Portal(像素语言跨维传送门)是一款基于腾讯Hunyuan-MT-7B大模型构建的创新翻译工具。与传统翻译软件不同&am…...

高效PCB逆向分析:OpenBoardView专业电路板查看器深度实战指南
高效PCB逆向分析:OpenBoardView专业电路板查看器深度实战指南 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView 面对复杂的电路板设计文件,你是否曾因无法直接查看.brd文件而束手无策…...

【绝密级】AGI战场决策黑箱溯源技术首度解禁:如何用可解释性XAI逆向还原AI开火逻辑?——来自DARPA TRUST-AI项目的3项未公开专利方法
第一章:AGI与军事应用的伦理边界 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)在军事系统中的深度集成正以前所未有的速度推进,从自主侦察分析到动态战术推演,其能力已超越传统自动化范畴。然而&…...