flink使用demo
1、添加不同数据源
package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.WordCount;
import com.baidu.keyue.deepsight.memory.WordCountData;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class EnvDemo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);// 设置流处理还是批处理env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);// 从不同数据源读取数据
// DataStream<String> text = env.fromElements(WordCountData.WORDS);
// DataStream<String> text = env.fromCollection(Arrays.asList("hello world", "hello flink"));
// DataStream<String> text = env.fromSource(crateFileSource(), WatermarkStrategy.noWatermarks(), "file source");
// DataStream<String> text = env.fromSource(crateKafkaSource(), WatermarkStrategy.noWatermarks(), "kafka source");DataStream<String> text = env.fromSource(createDataGeneratorSource(), WatermarkStrategy.noWatermarks(), "datagen source");// 处理逻辑DataStream<Tuple2<String, Integer>> counts =text.flatMap(new WordCount.Tokenizer()).keyBy(0).sum(1);counts.print();env.execute("WordCount");}public static FileSource crateFileSource() {FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build();return fileSource;}public static KafkaSource<String> crateKafkaSource() {KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("ip-port").setTopics("topic").setGroupId("groupId").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();return kafkaSource;}public static DataGeneratorSource<String> createDataGeneratorSource() {DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>((GeneratorFunction<Long, String>) value -> "hello" + value,100, // 一共100条数据RateLimiterStrategy.perSecond(5), // 每秒5条Types.STRING);return dataGeneratorSource;}
}
2、数据处理
package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.WordCount;
import com.baidu.keyue.deepsight.memory.bean.WaterSensor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class DataProcessDemo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);// 设置流处理还是批处理env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);// 读取数据DataStream<WaterSensor> sensorDs = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 100L, 100),new WaterSensor("s1", 1000L, 1000),new WaterSensor("s3", 3L, 3));// map算子 : 对数据流中的每个元素执行转换操作,一进一出SingleOutputStreamOperator<String> map = sensorDs.map(new MapFunction<WaterSensor, String>() {@Overridepublic String map(WaterSensor waterSensor) throws Exception {return waterSensor.getId() + " : " + waterSensor.getVc();}});
// map.print();// filter算子 : 对数据流中的每个元素执行过滤操作SingleOutputStreamOperator<WaterSensor> filter = sensorDs.filter(new FilterFunction<WaterSensor>() {@Overridepublic boolean filter(WaterSensor waterSensor) throws Exception {return waterSensor.getVc() > 1; // 只保留vc>1的元素}});
// filter.print();// flatMap算子 : 扁平映射,一个可以有多个输出,在collector里面,然后将其平铺返回SingleOutputStreamOperator<String> flatMap = sensorDs.flatMap(new FlatMapFunction<WaterSensor, String>() {@Overridepublic void flatMap(WaterSensor waterSensor, Collector<String> collector) throws Exception {// collector里面是输出的数据if ("s1".equals(waterSensor.getId())) {collector.collect(waterSensor.getId());} else {collector.collect(waterSensor.getId());collector.collect(waterSensor.getVc().toString());}}});
// flatMap.print();// keyBy 相同key的数据分到同一个分区,用于海量数据聚合操作来提升效率,不对数据进行转换,只是分区KeyedStream<WaterSensor, String> keyBy = sensorDs.keyBy(new KeySelector<WaterSensor, String>() {@Overridepublic String getKey(WaterSensor waterSensor) throws Exception {return waterSensor.getId(); // 按照id分组}});
// keyBy.print();// 在keyBy后可以使用聚合算子,求sum max min等
// keyBy.sum("vc").print(); // 传实体类的属性名
// keyBy.maxBy("vc").print(); // 传实体类的属性名// reduce算子 : 两两聚合,keyBy后才能操作keyBy.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor t2, WaterSensor t1) throws Exception {System.out.println("t1=" + t1);System.out.println("t2=" + t2);return new WaterSensor(t1.getId(), t1.getTs() + t2.getTs(), t1.getVc() + t2.getVc());}}).print();env.execute("WordCount");}
}3、分流/合流
package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.bean.WaterSensor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class FenliuDemo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);// 设置流处理还是批处理env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);// 读取数据DataStream<WaterSensor> sensorDs = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 100L, 100),new WaterSensor("s1", 1000L, 1000),new WaterSensor("s3", 3L, 3));SingleOutputStreamOperator<WaterSensor> oushu = sensorDs.filter(waterSensor -> waterSensor.getVc() % 2 == 0);SingleOutputStreamOperator<WaterSensor> jishu = sensorDs.filter(waterSensor -> waterSensor.getVc() % 2 == 1);oushu.print("偶数流");jishu.print("奇数流");// 偶数流和奇数流合并oushu.union(jishu).print("合并流");env.execute("WordCount");}
}4、输出流 sink
package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.bean.WaterSensor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.connector.sink.Sink;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SinkDemo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);// 设置流处理还是批处理env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);// 读取数据DataStream<WaterSensor> sensorDs = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 100L, 100),new WaterSensor("s1", 1000L, 1000),new WaterSensor("s3", 3L, 3));FileSink<WaterSensor> fileSink = FileSink.<WaterSensor>forRowFormat(new Path("/Users/chengyong03/Downloads/output/flink"),new SimpleStringEncoder<>("UTF-8")).build();sensorDs.sinkTo(fileSink);env.execute("WordCount");}
}5、flink流表互转,flink sql
package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class SqlDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 1. 创建表环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);DataStream<WaterSensor> sensorDs = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 100L, 100),new WaterSensor("s1", 1000L, 1000),new WaterSensor("s3", 3L, 3));sensorDs.print();// 2.流转表Table sensorTable = tableEnv.fromDataStream(sensorDs);// 3.注册临时表tableEnv.createTemporaryView("sensorTable", sensorTable);Table resultTable = tableEnv.sqlQuery("select * from sensorTable where vc > 10");// 4. table转流DataStream<WaterSensor> waterSensorDataStream = tableEnv.toDataStream(resultTable, WaterSensor.class);waterSensorDataStream.print();env.execute();}
}相关文章:

flink使用demo
1、添加不同数据源 package com.baidu.keyue.deepsight.memory.test;import com.baidu.keyue.deepsight.memory.WordCount; import com.baidu.keyue.deepsight.memory.WordCountData; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.…...

OpenCV(8):图像直方图
在图像处理中,直方图是一种非常重要的工具,它可以帮助我们了解图像的像素分布情况。通过分析图像的直方图,我们可以进行图像增强、对比度调整、图像分割等操作。 1 什么是图像直方图? 图像直方图是图像像素强度分布的图形表示&am…...

力扣LeetCode:1656 设计有序流
题目: 有 n 个 (id, value) 对,其中 id 是 1 到 n 之间的一个整数,value 是一个字符串。不存在 id 相同的两个 (id, value) 对。 设计一个流,以 任意 顺序获取 n 个 (id, value) 对,并在多次调用时 按 id 递增的顺序…...

NGINX配置TCP负载均衡
前言 之前本人做项目需要用到nginx的tcp负载均衡,这里是当时配置做的笔记;欢迎收藏 关注,本人将会持续更新 文章目录 配置Nginx的负载均衡 配置Nginx的负载均衡 nginx编译安装需要先安装pcre、openssl、zlib等库,也可以直接编译…...

vm和centos
安装 VMware Workstation Pro 1. 下载 VMware Workstation Pro 访问 VMware 官方网站(https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html ),在该页面中点击 “立即下载” 按钮,选择适合你操作…...

c#丰田PLC ToyoPuc TCP协议快速读写 to c# Toyota PLC ToyoPuc读写
源代码下载 <------下载地址 历史背景与发展 TOYOPUC协议源于丰田工机(TOYODA)的自动化技术积累。丰田工机成立于1941年,最初是丰田汽车的机床部门,后独立为专注于工业机械与控制系统的公司。2006年与光洋精工(Ko…...

量子计算的数学基础:复数、矩阵和线性代数
量子计算是基于量子力学原理的一种新型计算模式,它与经典计算机在信息处理的方式上有着根本性的区别。在量子计算中,信息的最小单位是量子比特(qubit),而不是传统计算中的比特。量子比特的状态是通过量子力学中的数学工具来描述的,因此,理解量子计算的数学基础对于深入学…...
 》笔记-Chapter22-处理 XML)
【JavaScript】《JavaScript高级程序设计 (第4版) 》笔记-Chapter22-处理 XML
二十二、处理 XML 处理 XML XML 曾一度是在互联网上存储和传输结构化数据的标准。XML 的发展反映了 Web 的发展,因为DOM 标准不仅是为了在浏览器中使用,而且还为了在桌面和服务器应用程序中处理 XML 数据结构。在没有 DOM 标准的时候,很多开发…...
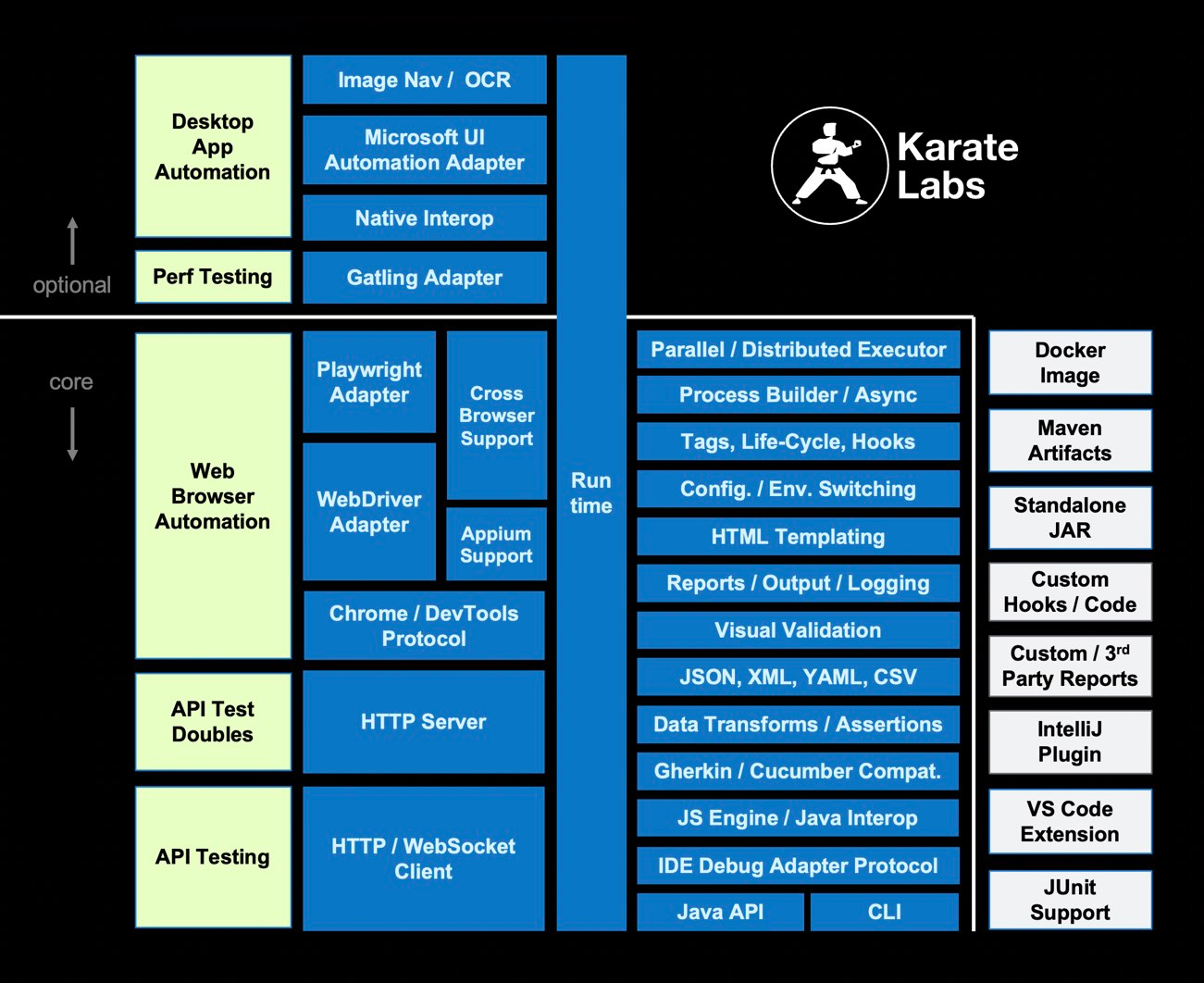
一个不错的API测试框架——Karate
Karate 是一款开源的 API 测试工具,基于 BDD(行为驱动开发)框架 Cucumber 构建,但无需编写 Java 或 JavaScript 代码即可直接编写测试用例。它结合了 API 测试、模拟(Mocking)和性能测试功能,支持 HTTP、GraphQL 和 WebSocket 等协议,语法简洁易读。 Karate详细介绍 K…...

文字语音相互转换
目录 1.介绍 2.思路 3.安装python包 3.程序: 4.运行结果 1.介绍 当我们使用一些本地部署的语言模型的时候,往往只能进行文字对话,这一片博客教大家如何实现语音转文字和文字转语音,之后接入ollama的模型就能进行语音对话了。…...

DeepSeek-R1:通过强化学习激发大语言模型的推理能力
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 DeepSeek大模型技术系列三DeepSeek大模型技术系列三》DeepSeek-…...

MATLAB中fft函数用法
目录 语法 说明 示例 含噪信号 高斯脉冲 余弦波 正弦波的相位 FFT 的插值 fft函数的功能是对数据进行快速傅里叶变换。 语法 Y fft(X) Y fft(X,n) Y fft(X,n,dim) 说明 Y fft(X) 用快速傅里叶变换 (FFT) 算法计算 X 的离散傅里叶变换 (DFT)。 如果 X 是向量&…...

【SpringBoot】【JWT】使用JWT的claims()方法存入Integer类型数据自动转为Double类型
生成令牌时使用Map存入Integer类型数据,将map使用claims方法放入JWT令牌后,取出时变成Double类型,强转报错: 解决: 将Integer转为String后存入JWT令牌,不会被自动转为其他类型,取出后转为Integ…...

Crack SmartGit
感谢大佬提供的资源 一、正常安装SmartGit 二、下载crackSmartGit crackSmartGit 发行版 - Gitee.com 三、使用crackSmartGit 1. 打开用户目录:C:\Users%用户名%\AppData\Roaming\syntevo\SmartGit。将crackSmartGit.jar和license.zip拷贝至 用户目录。 2. 用户…...

【备赛】在keil5里面创建新文件的方法+添加lcd驱动
一、先创建出文件夹和相应的.c和.h文件 因为在软件里面创建出的是在MDk文件那里面的,实际上是不存在你的新文件夹里的。 二、在keil5软件里面操作 1)添加文件夹 -*---------------------------------------------------------- 这里最好加上相对路径&…...

Rk3568驱动开发_驱动实现流程以及本质_3
1设备号: cat /proc/devices 编写驱动模块需要要想加载到内核并与设备正常通信,那就需要申请一个设备号,用cat /proc/devices可以查看已经被占用的设备号 设备号有什么用?不同设备其驱动实现不同用设备号去区分,例如字…...

【学习笔记】LLM+RL
文章目录 1 合成数据与模型坍缩(model collapse),1.1 递归生成数据与模型坍缩1.2 三种错误1.3 理论直觉1.4 PPL指标 2 基于开源 LLM 实现 O1-like step by step 慢思考(slow thinking),ollama,streamlit2.1…...

深入理解IP子网掩码子网划分{作用} 以及 不同网段之间的ping的原理 以及子网掩码的区域划分
目录 子网掩码详解 子网掩码定义 子网掩码进一步解释 子网掩码的作用 计算总结表 子网掩码计算 子网掩码对应IP数量计算 判断IP是否在同一网段 1. 计算步骤 2. 示例 3. 关键点 总结 不同网段通信原理与Ping流程 1. 同网段通信 2. 跨网段通信 网段计算示例 3. P…...

rust 前端npm依赖工具rsup升级日志
rsup是使用 rust 编写的一个前端 npm 依赖包管理工具,可以获取到项目中依赖包的最新版本信息,并通过 web 服务的形式提供查看、升级操作等一一系列操作。 在前一篇文章中,记录初始的功能设计,自己的想法实现过程。在自己的使用过…...

2.2 STM32F103C8T6最小系统板的四种有关固件的开发方式
2.2.1 四种有关固件的开发方式 四种有关于固件的开发方式从时间线由远及近分别是:寄存器开发、标准外设驱动库开发、硬件抽象层库开发、底层库开发。 四种开发方式各有优缺点,可以参考ST官方的测试与说明。 1.寄存器开发 寄存器编程对于从51等等芯片过渡…...

别再为MAC地址发愁了!三种为W5500/W5100等网络芯片生成合法地址的实战方法
WIZnet网络芯片MAC地址生成实战指南:从合规到高效 在嵌入式网络设备开发中,MAC地址就像设备的身份证号码,不仅需要全球唯一,还要符合行业规范。对于使用W5500、W5100等WIZnet系列网络芯片的开发者来说,如何生成既合法又…...

FRCRN模型训练数据准备与增强教程:从零构建数据集
FRCRN模型训练数据准备与增强教程:从零构建数据集 想训练一个能有效去除语音中噪声的FRCRN模型,第一步也是最关键的一步,就是准备一份高质量的训练数据。很多人模型调了半天效果不好,最后发现是数据出了问题。今天,我…...

阴阳师自动化脚本:免费高效的百鬼夜行全自动解决方案
阴阳师自动化脚本:免费高效的百鬼夜行全自动解决方案 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师百鬼夜行是获取式神碎片的重要途径,但手动操作…...

MongoDB广告点击追踪如何建模_点击事件聚合与去重记录
不该直接存成大文档;应将每次点击作为独立文档存储,精简字段、建合理索引,并用唯一复合索引实现去重,配合覆盖索引优化聚合查询,按需预聚合。点击事件该不该直接存成大文档?别把每次点击都塞进一个嵌套数组…...

NVIDIA Profile Inspector架构深度解析:驱动级性能优化技术揭秘
NVIDIA Profile Inspector架构深度解析:驱动级性能优化技术揭秘 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector作为一款专业的显卡驱动配置工具,通过直…...

HUNYUAN-MT与AIGC结合实战:跨语言短视频脚本创意生成
HUNYUAN-MT与AIGC结合实战:跨语言短视频脚本创意生成 最近在折腾AIGC工作流时,我发现了一个特别有意思的组合玩法,它能让内容创作的边界一下子拓宽不少。这个玩法的核心,就是把不同语言的创意生成和高质量翻译无缝衔接起来。 简…...

云原生环境中的容器安全最佳实践:从镜像到运行时的全流程防护
云原生环境中的容器安全最佳实践:从镜像到运行时的全流程防护 🔥 硬核开场 各位技术大佬们,今天咱们来聊聊容器安全。别跟我说你还在裸奔容器,那都2023年了!在云原生时代,容器安全是底线,是生命…...
Translumo终极指南:免费实时屏幕翻译工具,打破语言壁垒的完整解决方案
Translumo终极指南:免费实时屏幕翻译工具,打破语言壁垒的完整解决方案 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors…...

StructBERT在智能招聘中的应用:候选人简历与JD关键词语义匹配效果展示
StructBERT在智能招聘中的应用:候选人简历与JD关键词语义匹配效果展示 1. 智能招聘的痛点与解决方案 招聘过程中最耗时的环节是什么?很多HR会告诉你:是简历筛选。面对海量简历,如何快速准确地找到与职位要求最匹配的候选人&…...

Java 面试题精讲:在分布式系统中集成 Stable Yogi 模型的设计思路
Java 面试题精讲:在分布式系统中集成 Stable Yogi 模型的设计思路 最近在面试高级Java工程师时,我特别喜欢问一个开放性的架构设计题:“假设我们要在一个大型电商平台的微服务架构里,集成一个类似Stable Diffusion的AI图像生成模…...