如何用JAVA实现布隆过滤器?
目录
引言
布隆过滤器的原理
1. 核心思想
2. 优缺点
布隆过滤器的使用场景
Java 实现布隆过滤器
1. 实现步骤
2. 代码实现
3. 代码说明
4. 测试结果
布隆过滤器的优化
总结
引言
布隆过滤器(Bloom Filter)是一种高效的概率数据结构,用于判断一个元素是否属于某个集合。它的特点是空间效率高、查询速度快,但有一定的误判率(False Positive)。布隆过滤器常用于缓存系统、垃圾邮件过滤、数据库查询优化等场景。
1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列的随机映射函数(哈希函数)两部分组成的数据结构。
背景:为预防大量黑客故意发起非法的时间查询请求,造成缓存击穿,建议采用布隆过滤器的方法解决。布隆过滤器通过一个很长的二进制向量和一系列随机映射函数(哈希函数)来记录与识别某个数据是否在一个集合中。如果数据不在集合中,能被识别出来,不需要到数据库中进行查询,所以能将数据库查询返回值为空的查询过滤掉。
缓存穿透: 缓存穿透是查询一个根本不存在的数据,由于缓存是不命中时需要从数据库查询,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
布隆过滤器的原理
1. 核心思想
布隆过滤器的核心思想是使用多个哈希函数将元素映射到一个位数组中。具体步骤如下:
-
初始化位数组:创建一个长度为
m的位数组,所有位初始化为 0。 -
添加元素:
-
对元素使用
k个哈希函数计算哈希值。 -
将位数组中对应哈希值的位置置为 1。
-
-
查询元素:
-
对元素使用相同的
k个哈希函数计算哈希值。 -
检查位数组中对应哈希值的位置是否都为 1。
-
-
如果都为 1,则元素可能存在(可能有误判)。
-
如果有任何一个位置为 0,则元素一定不存在。
2. 优缺点
-
优点:
-
空间效率高:使用位数组存储数据。
-
查询速度快:时间复杂度为 O(k),其中 k 是哈希函数的数量。
-
-
缺点:
-
有误判率:可能将不存在的元素误判为存在。
-
不支持删除操作:删除元素会影响其他元素的判断。
-
简单来说
当一个元素加入布隆过滤器中的时候,会进行如下操作:
使用布隆过滤器中的哈希函数对元素进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
根据得到的哈希值,在位数组中把对应下标的值置为1。
当我们需要判断一个元素是否位于布隆过滤器的时候,会进行如下操作:
对给定元素再次进行相同的哈希计算;
得到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
例子:
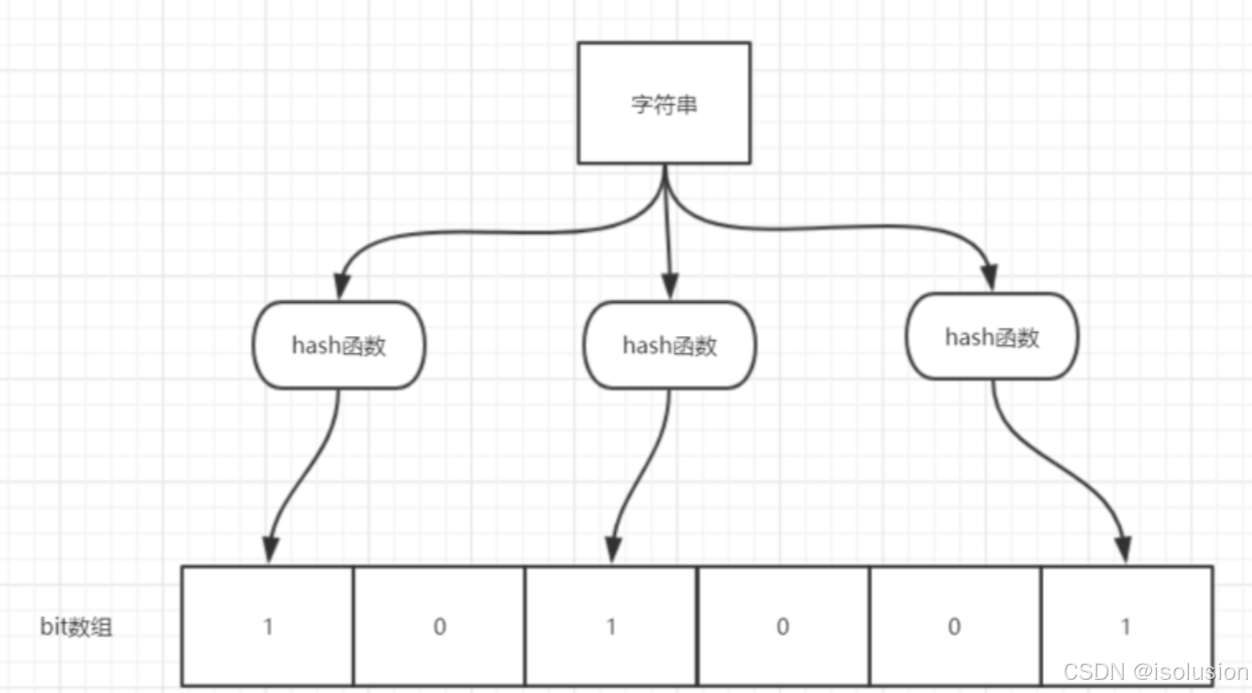
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1 (当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便);
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的某个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不存在,那么这个元素一定不在。
布隆过滤器的使用场景
判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上)、防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)、邮箱的垃圾邮件过滤、黑名单功能等。去重:爬给定网址的时候对已经爬取过的URL去重。
Java 实现布隆过滤器
1. 实现步骤
-
定义位数组和哈希函数。
-
实现添加元素的方法。
-
实现查询元素的方法。
2. 代码实现
import java.util.BitSet;
import java.util.Random;public class BloomFilter {private BitSet bitSet; // 位数组private int size; // 位数组大小private int[] seeds; // 哈希函数的种子private SimpleHash[] hashFunctions; // 哈希函数数组/*** 构造函数** @param size 位数组大小* @param hashCount 哈希函数数量*/public BloomFilter(int size, int hashCount) {this.size = size;this.bitSet = new BitSet(size);this.seeds = new int[hashCount];this.hashFunctions = new SimpleHash[hashCount];// 初始化哈希函数Random random = new Random();for (int i = 0; i < hashCount; i++) {seeds[i] = random.nextInt();hashFunctions[i] = new SimpleHash(size, seeds[i]);}}/*** 添加元素** @param value 要添加的元素*/public void add(String value) {for (SimpleHash hashFunction : hashFunctions) {int hash = hashFunction.hash(value);bitSet.set(hash, true);}}/*** 查询元素是否存在** @param value 要查询的元素* @return 如果可能存在返回 true,否则返回 false*/public boolean contains(String value) {for (SimpleHash hashFunction : hashFunctions) {int hash = hashFunction.hash(value);if (!bitSet.get(hash)) {return false;}}return true;}/*** 内部类:简单哈希函数*/private static class SimpleHash {private int capacity;private int seed;public SimpleHash(int capacity, int seed) {this.capacity = capacity;this.seed = seed;}/*** 计算哈希值** @param value 输入值* @return 哈希值*/public int hash(String value) {int result = 0;int len = value.length();for (int i = 0; i < len; i++) {result = seed * result + value.charAt(i);}return (capacity - 1) & result; // 取模运算}}public static void main(String[] args) {// 创建布隆过滤器BloomFilter bloomFilter = new BloomFilter(1000, 3);// 添加元素bloomFilter.add("Alice");bloomFilter.add("Bob");bloomFilter.add("Charlie");// 查询元素System.out.println("Contains Alice: " + bloomFilter.contains("Alice")); // trueSystem.out.println("Contains Dave: " + bloomFilter.contains("Dave")); // false}
}3. 代码说明
-
BitSet:
-
使用
BitSet作为位数组,节省空间。
-
-
哈希函数:
-
使用多个简单的哈希函数(
SimpleHash)来计算哈希值。 -
哈希函数通过种子生成不同的哈希值。
-
-
添加元素:
-
对元素使用所有哈希函数计算哈希值,并将位数组中对应位置置为 1。
-
-
查询元素:
-
对元素使用所有哈希函数计算哈希值,检查位数组中对应位置是否都为 1。
-
4. 测试结果
运行上述代码,输出如下:
Contains Alice: true
Contains Dave: false
布隆过滤器的优化
-
选择合适的位数组大小和哈希函数数量:
-
位数组越大,误判率越低,但占用空间越多。
-
哈希函数越多,误判率越低,但计算开销越大。
-
可以通过公式计算最优的位数组大小和哈希函数数量。
-
-
使用更复杂的哈希函数:
-
例如 MurmurHash、MD5 等,减少哈希冲突。
-
-
支持删除操作:
-
使用计数布隆过滤器(Counting Bloom Filter),通过计数器记录每个位的使用次数。
-
总结
布隆过滤器是一种高效的概率数据结构,适用于需要快速判断元素是否存在的场景。本文通过 Java 实现了一个简单的布隆过滤器,并介绍了其原理和优化方法。希望这篇文章能帮助你理解布隆过滤器,并在实际项目中应用它!
相关文章:
如何用JAVA实现布隆过滤器?
目录 引言 布隆过滤器的原理 1. 核心思想 2. 优缺点 布隆过滤器的使用场景 Java 实现布隆过滤器 1. 实现步骤 2. 代码实现 3. 代码说明 4. 测试结果 布隆过滤器的优化 总结 引言 布隆过滤器(Bloom Filter)是一种高效的概率数据结构࿰…...

游戏开发 游戏开始界面
目录 前言 一 游戏初始化界面的分析 二 游戏的大概框架 三 显示界面的开发 四 完整代码 总结 我们可以来看看游戏初始界面是什么样的 勇士游戏样例 前言 这里是开发游戏的初始界面 一 游戏初始化界面的分析 我们需要一个背景图,开始游戏图标࿰…...

Python解析 Flink Job 依赖的checkpoint 路径
引言 Apache Flink 是一个强大的分布式处理框架,广泛用于批处理和流处理任务。其 checkpoint 机制是确保容错的关键功能,允许在计算过程中保存状态,以便在故障时从最近的 checkpoint 恢复。本文详细探讨了一个 Python 脚本,该脚本…...

Javascript网页设计案例:通过PDFLib实现一款PDF分割工具,分割方式自定义-完整源代码,开箱即用
功能预览 一、工具简介 PDF 分割工具支持以下核心功能: 拖放或上传 PDF 文件:用户可以通过拖放或点击上传 PDF 文件。两种分割模式: 指定范围:用户可以指定起始页和结束页,提取特定范围的内容。固定间距:用户可以设置间隔页数(例如每 5 页分割一次),工具会自动完成分…...

计算机视觉算法实战——产品分拣(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 领域简介✨✨ 产品分拣是工业自动化和物流领域的核心技术,旨在通过机器视觉系统对传送带上的物品进行快速识别、定位和分类&a…...

汽车软件︱AUTO TECH China 2025 广州国际汽车软件与安全技术展览会:开启汽车科技新时代
在汽车产业智能化与网联化飞速发展的当下,汽车软件与安全技术已然成为行业变革的核心驱动力。2025年11月20 - 22日,AUTO TECH China 2025 广州国际汽车软件与安全技术展览会将在广州保利世贸博览馆盛大开幕,这场展会将汇聚行业前沿成果&#…...

Visual Studio打开文件后,中文变乱码的解决方案
文件加载 使用Unicode(UTF-8)编码加载文件 C:\WorkSpace\Assets\Scripts\UI\View\ExecuteComplateView.cs时,有些字节已用Unicode替换字符替换。保存该文件将不会保留原始文件内容。...

Python爬虫selenium验证-中文识别点选+图片验证码案例
1.获取图片 import re import time import ddddocr import requests from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from selenium.webdriver.support.wait import WebDriverWait from …...
)
MySQL后端返回给前端的时间变了(时区问题)
问题:MySQL里的时间例如为2025-01-10 21:19:30,但是返回到前端就变成了2025-01-10 13:19:30,会出现小时不一样或日期变成隔日的问题 一般来说设计字段时会使用datetime字段类型,这是一种用于时间的字段类型,而这个类型…...

计算机毕业设计Hadoop+Spark+DeepSeek-R1大模型民宿推荐系统 hive民宿可视化 民宿爬虫 大数据毕业设计(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

前端性能优化面试题及参考答案
目录 如何通过合并文件减少 HTTP 请求次数? 列举 CDN 加速的适用场景与实现原理。 如何利用 HTTP/2 的多路复用特性优化资源加载? 描述 DNS 预解析的实现方式及其对性能的影响。 异步加载脚本时,async 与 defer 属性的区别是什么? 如何优化 AJAX 请求的并发数与优先级…...

【NLP 37、激活函数 ③ relu激活函数】
—— 25.2.23 ReLU广泛应用于卷积神经网络(CNN)和全连接网络,尤其在图像分类(如ImageNet)、语音识别等领域表现优异。其高效性和非线性特性使其成为深度学习默认激活函数的首选 一、定义与数学表达式 ReLU࿰…...

量子计算的威胁,以及企业可以采取的措施
当谷歌、IBM、Honeywell和微软等科技巨头纷纷投身量子计算领域时,一场技术军备竞赛已然拉开帷幕。 量子计算虽能为全球数字经济带来巨大价值,但也有可能对相互关联的系统、设备和数据造成损害。这一潜在影响在全球网络安全领域引起了强烈关注。也正因如…...
——解锁 C# 变量的更多奥秘:从基础到进阶的深度指南)
C#初级教程(5)——解锁 C# 变量的更多奥秘:从基础到进阶的深度指南
一、变量类型转换:隐式与显式的门道 (一)隐式转换:编译器的 “贴心小助手” 隐式转换是编译器自动进行的类型转换,无需开发者手动干预。这种转换通常发生在将取值范围小的数据类型赋值给取值范围大的数据类型时&#…...
训练自己的数据集)
Pytorch实现之GIEGAN(生成器信息增强GAN)训练自己的数据集
简介 简介:在训练数据样本之前首先利用VAE来推断潜在空间中不同类的分布,用于后续的训练,并使用它来初始化GAN。与ACGAN和BAGAN不同的是,提出的GIEGAN有一个分类器结构,这个分类器主要判断生成的图像或者样本图像属于哪个类,而鉴别器仅判断图像是来自于生成器还是真实样…...

使用PHP接入纯真IP库:实现IP地址地理位置查询
引言 在日常开发中,我们经常需要根据用户的IP地址获取其地理位置信息,例如国家、省份、城市等。纯真IP库(QQWry)是一个常用的IP地址数据库,提供了丰富的IP地址与地理位置的映射关系。本文将介绍如何使用PHP接入纯真IP库,并通过一个完整的案例演示如何实现IP地址的地理位…...
计算机毕业设计SpringBoot+Vue.jst0甘肃非物质文化网站(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

无人机实战系列(三)本地摄像头+远程GPU转换深度图
这篇文章将结合之前写的两篇文章 无人机实战系列(一)在局域网内传输数据 和 无人机实战系列(二)本地摄像头 Depth-Anything V2 实现了以下功能: 本地笔记本摄像头发布图像 远程GPU实时处理(无回传&#…...

七.智慧城市数据治理平台架构
一、整体架构概览 智慧城市数据治理平台架构描绘了一个全面的智慧城市数据治理平台,旨在实现城市数据的统一管理、共享和应用,为城市运行、管理和决策提供数据支撑。整体架构呈现出分层、模块化、集约化的特点,并强调数据安全和标准规范。 智…...

UE5从入门到精通之多人游戏编程常用函数
文章目录 前言一、权限与身份判断函数1. 服务器/客户端判断2. 网络角色判断二、网络同步与复制函数1. 变量同步2. RPC调用三、连接与会话管理函数1. 玩家连接控制2. 网络模式判断四、实用工具函数前言 UE5给我们提供了非常强大的多人网路系统,让我们可以很方便的开发多人游戏…...

Nacos注册中心实战:Java项目中的服务发现与管理
Nacos注册中心实战:Java项目中的服务发现与管理 前言 随着微服务架构的广泛应用,服务的高效注册与动态发现成为分布式系统的基础设施建设重点。Nacos 作为一款易用且功能强大的注册中心和配置中心,为 Java 项目提供了灵活的服务治理能力。本…...

开源项目管理利器OpenProject:从零构建高效团队协作平台
开源项目管理利器OpenProject:从零构建高效团队协作平台 【免费下载链接】openproject OpenProject is the leading open source project management software. 项目地址: https://gitcode.com/GitHub_Trending/op/openproject 在当今快节奏的工作环境中&…...

Fan Control完整教程:Windows风扇智能控制终极指南
Fan Control完整教程:Windows风扇智能控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

Figma中文汉化插件终极指南:3分钟告别英文界面困扰
Figma中文汉化插件终极指南:3分钟告别英文界面困扰 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?作为一名中文设计师ÿ…...

Unlock Music:3分钟解锁加密音乐,让付费歌曲真正属于你
Unlock Music:3分钟解锁加密音乐,让付费歌曲真正属于你 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目…...

Visual C++ Redistributable AIO:Windows系统DLL缺失问题的终极解决方案
Visual C Redistributable AIO:Windows系统DLL缺失问题的终极解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 当您在Windows系统上安装或运行…...

深度实战指南:如何利用ExDark数据集构建完整的低光照视觉AI解决方案
深度实战指南:如何利用ExDark数据集构建完整的低光照视觉AI解决方案 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very low-…...
)
告别QML资源路径噩梦:手把手教你用Prefix和别名管理图片资源(附避坑指南)
告别QML资源路径噩梦:手把手教你用Prefix和别名管理图片资源(附避坑指南) 在Qt Quick的UI开发中,资源路径管理往往是开发者最容易忽视却又最常踩坑的环节。想象一下这样的场景:你的QML文件中散落着各种source: "…...

OBS StreamFX插件完全指南:如何用免费插件打造专业直播画面
OBS StreamFX插件完全指南:如何用免费插件打造专业直播画面 【免费下载链接】obs-StreamFX StreamFX is a plugin for OBS Studio which adds many new effects, filters, sources, transitions and encoders! Be it 3D Transform, Blur, complex Masking, or even …...
)
2026奇点大会AI审核白皮书核心算法首度公开(含敏感图像识别F1值提升47.3%的工程密钥)
第一章:2026奇点智能技术大会:AI内容审核 2026奇点智能技术大会(https://ml-summit.org) 多模态审核引擎的实时推理架构 本届大会首次公开部署的“Sentinel-XL”审核系统,采用动态图分割策略,在视频流中实现帧级语义对齐与跨模态…...