【Python模块】——pymysql
pymysql是python操作mysql的标准库,可以通过pip install快速导入pymysql包操作数据库
使用pymysql操作mysql
简单demo
import pymysql
connect = pymysql.connect(host="localhost",port=3306,user="root",password="root",database="my_database",# charset="utf8mb4"
)
cursor = connect.cursor()# 查询语句1
sql = "select * from user where name = %(name)s"
ret = cursor.execute(sql, {"name": "ls"})
# 查询语句2
sql = "select * from user where name = %s"
ret = cursor.execute(sql, "ls")
print(ret)result = cursor.fetchall()
print("result", result)cursor.close()
connect.close()
自定义SqlHelper
import pymysqlclass MySQLClient(object):def __init__(self, **kwargs):self.conn = pymysql.connect(**kwargs)self.cursor = self.conn.cursor()def query(self, sql, *args):try:rowcount = self.cursor.execute(sql, *args)return rowcountexcept Exception as e:raise edef update(self, sql, *args):self.cursor.execute(sql, *args)self.conn.commit()def insert(self, sql, *args):self.cursor.execute(sql, *args)self.conn.commit()def fetch_one(self, sql, *args):self.query(sql, *args)result = self.cursor.fetchone()return resultdef fetch_all(self, sql, *args):self.query(sql, *args)result = self.cursor.fetchone()return resultdef close(self):self.cursor.close()self.conn.close()config = {"host": "localhost","port": 3306,"user": "root","password": "root","database": "my_database",
}mysql_client = MySQLClient(**config)
sql = "select * from user where name=%s"
ret = mysql_client.fetch_one(sql, "ls")
print(ret)# mysql_client.close()借助DButils创建数据库连接池
DButils模块可以通过创建数据库连接池,提升数据库操作性能;
实现思路:
- 定义SqlHelper类
- 通过
__init__方法定义pool=PoolDB(**kwargs),_local=threading.local()- 定义
__enter__获取connection与cursor和__exit__关闭connection与cursor,可支持with 上下文操作- 为了保证每次获取的connection与cursor不会将之前的覆盖掉,引入threading.local进行保存;self._local = {thread_id: {“stack”: [(connection, cursor)]}}
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
from dbutils.pooled_db import PooledDB
from threading import localclass SqlHelper(object):def __init__(self):self.pool = PooledDB(creator=pymysql, # 使用链接数据库的模块maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数mincached=1, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建# maxcached=5, # 链接池中最多闲置的链接,0和None不限制blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制setsession=[], # 开始会话前执行的命令列表host='localhost',port=3306,user='root',password='root',database='my_database',charset='utf8')self._local = local()def open(self):connection = self.pool.connection()cursor = connection.cursor()return connection, cursordef close(self, cursor, conn):cursor.close()conn.close()def __enter__(self):conn, cursor = self.open()rv = getattr(self._local, "stack", None)if not rv:self._local.stack = [(conn, cursor)]else:self._local.stack.append((conn, cursor))return cursordef __exit__(self, exc_type, exc_val, exc_tb):rv = getattr(self._local, "stack", None)if not rv:# del self._local.stackreturnelif len(rv) == 1:conn, cursor = rv[-1]# del self._local.stackreturnelse:conn, cursor = rv.pop()cursor.close()conn.close()def fetchone(self, sql, *args):conn, cursor = self.open(self)try:rowcount = cursor.execute(sql, *args)ret = cursor.fetchone()return retexcept Exception as e:raisedef fetchall(self, sql, *args):conn, cursor = self.open(self)try:rowcount = cursor.execute(sql, *args)ret = cursor.fetchall()return retexcept Exception as e:raisedb = SqlHelper()sql = "select * from user"
with db as c1:ret = c1.execute(sql)print(ret)with db as c2:ret = c2.execute(sql)print(ret)使用DButils的另一种写法
使用这种写法,每次都实例化SqlHelper,保证每次获取的connection和cursor不被覆盖
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
1. 定义全局变量POOL=pooledDB(**kwargs)
2. 每次用到db就实例化一次
"""
import pymysql
from dbutils.pooled_db import PooledDB
from threading import localpool = PooledDB(creator=pymysql, # 使用链接数据库的模块maxconnections=0, # 连接池允许的最大连接数,0和None表示不限制连接数mincached=1, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建# maxcached=5, # 链接池中最多闲置的链接,0和None不限制blocking=False, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制setsession=[], # 开始会话前执行的命令列表host='localhost',port=3306,user='root',password='root',database='my_database',charset='utf8')class SqlHelper(object):def __init__(self):self.conn = Noneself.cursor = Nonedef open(self):self.connection = pool.connection()self.cursor = self.connection.cursor()return self.connection, self.cursordef close(self):self.cursor.close()self.conn.close()def __enter__(self):self.conn, self.cursor = self.open()return self.cursordef __exit__(self, exc_type, exc_val, exc_tb):self.close()db = SqlHelper()sql = "select * from user"
with db as c1:ret = c1.execute(sql)print("c1.cursor: ", db.cursor)print(ret)with db as c2:ret = c2.execute(sql)print("c2.cursor: ", db.cursor) # 一个实例对象是可以多次调用enter方法的,但db.cursor发生了改变,即上一次的连接丢了print(ret)print(type(c1), type(c2))print(c1 is c2) # falseprint("c1.cursor: ", db.cursor) # c2.cursor将c1.cursor覆盖了相关文章:

【Python模块】——pymysql
pymysql是python操作mysql的标准库,可以通过pip install快速导入pymysql包操作数据库 使用pymysql操作mysql 简单demo import pymysql connect pymysql.connect(host"localhost",port3306,user"root",password"root",database&quo…...

【我的Android进阶之旅】Android Studio SDK Update Site 国内的腾讯云镜像配置指南
一、腾讯云的镜像 https://mirrors.cloud.tencent.com/AndroidSDK/ 二、 打开 Android Studio的SDK Manager 路径:Tools–>SDK Manager 在右侧找到 SDK Update Sites 列表,添加如下链接,像下面一样,一个一个添加 将下面几个链接都加上去 https:...

springboot实现多文件上传
springboot实现多文件上传 代码 package com.sh.system.controller;import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.util.StringUtils; import org.springframework.web.bind.annotation.PostMap…...

Webpack打包优化
在使用 Webpack 打包项目时,随着项目规模的扩大,构建时间和打包产物的体积可能会逐渐增加。为了提高构建性能和减小打包产物的体积,可以采取以下几种 Webpack 打包优化 的方法。 1. 使用 mode 配置 Webpack 通过 mode 配置来指定构建模式。…...

浅谈HTTP及HTTPS协议
1.什么是HTTP? HTTP全称是超文本传输协议,是一种基于TCP协议的应用非常广泛的应用层协议。 1.1常见应用场景 一.浏览器与服务器之间的交互。 二.手机和服务器之间通信。 三。多个服务器之间的通信。 2.HTTP请求详解 2.1请求报文格式 我们首先看一下…...
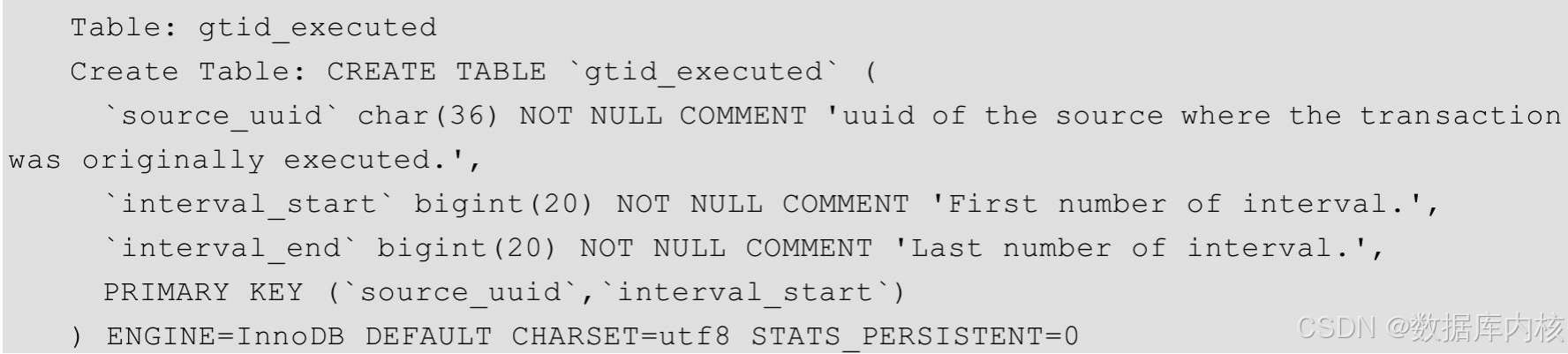
GTID的基本概念
1.1 GTID的基本概念 1.1.1 GTID的作用 GTID的全称为Global Transaction Identifier,是MySQL的一个强大的特性。MySQL会为每一个DML/DDL操作都增加一个唯一标记,叫作GTID(每个事务一个GTID)。这个标记在整个复制环境中都是唯一的…...

.NET Core MVC IHttpActionResult 设置Headers
最近碰到调用我的方法要求返回一个代码值,但是要求是不放在返回实体里,而是放在返回的Headers上 本来返回我是直接用 return Json(res) 这种封装的方法特别简单,但是没有发现设置headers的地方 查询过之后不得已换了个返回 //原来方式 //…...

数据结构与算法面试专题——桶排序
引入 桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。 桶排序…...
)
深度学习奠基作 AlexNet 论文阅读笔记(2025.2.25)
文章目录 训练数据集数据预处理神经网络模型模型训练正则化技术模型性能其他补充 训练数据集 模型主要使用2010年和2012年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)提供的 ImageNet 的子集进行训练,这些子集包含120万张图像。最终ÿ…...

MongoDB 数据库简介
MongoDB 数据库简介 引言 随着互联网技术的飞速发展,数据已经成为企业的重要资产。为了高效地管理和处理这些数据,数据库技术应运而生。MongoDB作为一种流行的NoSQL数据库,因其灵活的数据模型和高效的数据处理能力,受到了广泛的关注。本文将为您详细介绍MongoDB的基本概念…...

Transformer LLaMA
一、Transformer Transformer:一种基于自注意力机制的神经网络结构,通过并行计算和多层特征抽取,有效解决了长序列依赖问题,实现了在自然语言处理等领域的突破。 Transformer 架构摆脱了RNNs,完全依靠 Attention的优…...

【DeepSeek开源:会带来多大的影响】
DeepSeek 开源,震撼登场对云计算行业的冲击 巨头云厂商的新机遇 DeepSeek 开源后,为云计算行业带来了巨大的变革,尤其是为巨头云厂商创造了新的发展机遇。以阿里云为例,它作为云计算行业的领军者,与 DeepSeek 的合作…...

Redis7——基础篇(七)
前言:此篇文章系本人学习过程中记录下来的笔记,里面难免会有不少欠缺的地方,诚心期待大家多多给予指教。 基础篇: Redis(一)Redis(二)Redis(三)Redis&#x…...

边缘计算:通俗易懂的全方位解析
1. 什么是边缘计算? 边缘计算(Edge Computing)是一种数据处理方式,它将计算任务从云端或数据中心下放到更靠近数据源(边缘)的设备上。 通俗理解: 想象你住在一个偏远的村庄,而最近…...
)
Flink 中的滚动策略(Rolling Policy)
在 Apache Flink 中,滚动策略(Rolling Policy)是针对日志(或数据流)文件输出的一种管理策略,它决定了在日志文件的大小、时间或其他条件满足特定标准时,如何“滚动”生成新的日志文件。滚动策略…...

GPU和FPGA的区别
GPU(Graphics Processing Unit,图形处理器)和 FPGA(Field-Programmable Gate Array,现场可编程门阵列)不是同一种硬件。 我的理解是,虽然都可以用于并行计算,但是GPU是纯计算的硬件…...

网易云音乐分布式KV存储实践与演进
随着网易云音乐业务的快速发展,推荐和搜索场景对分布式KV存储的需求日益增长。本文将深入探讨网易云音乐在分布式KV存储方面的实践和演进,分析其技术选型、架构设计以及未来发展方向。 一、业务背景 网易云音乐的业务场景对分布式KV存储提出了高并发、…...

WordPress平台如何接入Deepseek,有效提升网站流量
深夜改代码到崩溃?《2024全球CMS生态报告》揭露:78%的WordPress站长因API对接复杂,错失AI内容红利。本文实测「零代码接入Deepseek」的保姆级方案,配合147SEO的智能发布系统,让你用3个步骤实现日均50篇EEAT合规内容自动…...

【嵌入式】STM32内部NOR Flash磨损平衡与掉电保护总结
1. NOR Flash与NAND Flash 先deepseek看结论: 特性Nor FlashNAND Flash读取速度快(支持随机访问,直接执行代码)较慢(需按页顺序读取)写入/擦除速度慢(擦除需5秒,写入需逐字节操作&…...

什么是磁盘阵列(RAID)?如何提高磁盘阵列的性能
什么是磁盘阵列 磁盘阵列(RAID)是一种将多个独立的硬盘组合成一个逻辑存储单元的技术,旨在提高数据存储的性能、容量、可靠性和冗余性。磁盘阵列通过将数据分割成多个区段并分别存储在不同的硬盘上,利用个别磁盘提供数据加…...
的动画性能优化点)
Android 13手势导航卡顿?深入剖析Launcher3最近任务(Recents)的动画性能优化点
Android 13手势导航卡顿?深入剖析Launcher3最近任务(Recents)的动画性能优化点 在Android 13中,手势导航已经成为主流交互方式,但不少开发者反馈在Launcher3的最近任务(Recents)界面会出现动画卡…...

AI前沿思想、AI理想、AI的妄言、AI极致观测文明
一、前言本文来自全世界的信息整理,本人对Ai内容进行记录和学习 ,如有异议和争论,请留言更正,不涉及现实相关事实。本文观点仅供参考。如有雷同,不回应。二、AI文明级变革观点1.旨在记录那些冲破常规的、甚至略显疯狂的…...

别再死磕NeRF了!从体素到点云,聊聊2024年三维重建的5种主流技术选型与实战避坑
别再死磕NeRF了!从体素到点云,聊聊2024年三维重建的5种主流技术选型与实战避坑 当你在深夜盯着屏幕,反复调整NeRF的视角采样参数却依然无法解决场景边缘模糊问题时;当项目Deadline临近,而体素模型的内存占用已经让显卡…...

VCS覆盖率进阶:用功能覆盖率精准验证复杂SoC设计,提升验证效率
VCS覆盖率进阶:用功能覆盖率精准验证复杂SoC设计,提升验证效率 在当今SoC设计复杂度呈指数级增长的背景下,传统的代码覆盖率已难以满足验证完备性需求。当RTL代码量突破千万行量级时,仅靠行覆盖率和分支覆盖率就像用渔网捕鱼——看…...

鲁班猫MIPI屏幕配置与触摸校准全攻略:从1080P切换到横屏显示的完整流程
1. 鲁班猫开发板与MIPI屏幕初体验 第一次拿到鲁班猫开发板时,我像大多数嵌入式开发者一样兴奋。这块基于RK3566芯片的小板子虽然体积不大,但性能足够强大,特别适合用来做各种嵌入式项目。不过当我准备连接MIPI屏幕时,发现默认配置…...

人工智能入门:基于Phi-4-mini-reasoning理解大模型推理的基本原理
人工智能入门:基于Phi-4-mini-reasoning理解大模型推理的基本原理 1. 从零开始认识大模型推理 你可能已经听说过ChatGPT这样的AI聊天机器人,它们能够像人类一样回答问题、写文章甚至解决数学题。这背后就是大语言模型的"推理"能力在发挥作用…...

Macleod Stack案例:长波通滤波器的设计与优化
1. 长波通滤波器的基础概念 长波通滤波器(Long Wave Pass Filter)是光学薄膜设计中常见的器件类型,它的核心功能是允许长波长的光通过,同时阻挡短波长的光。这种滤波器在光谱分析、成像系统、激光技术等领域有着广泛应用。举个生活…...

海思Hi3516DV500/HI3519DV500开发实战:从SDK编译到多媒体例程验证
1. 环境准备:搭建Hi3516DV500/HI3519DV500开发环境 拿到海思SDK后,第一件事就是搭建开发环境。我建议使用Ubuntu 18.04或20.04系统,这是官方推荐的环境。安装完系统后,需要配置一些基础工具链: sudo apt-get update su…...

课程论文不用赶!虎贲等考 AI:快速出稿、格式规范、低分变高分,期末周救星
对每一位大学生来说,期中、期末的“课程论文暴击”,远比考试更让人崩溃。一门课一篇,多则四五篇, deadlines扎堆而来,既要应付日常上课、复习,还要挤时间写论文,很多同学陷入“熬夜赶稿、东拼西…...

传统物流专员效率瓶颈明显,AI物流调度师正在替代
路线规划、车辆调度、在途跟踪、异常处理……传统物流专员的大量工作时间被这些重复性、高耗时的事务占据。随着运力成本上升和时效要求提高,人工调度的效率瓶颈日益突出:经验依赖强、响应速度慢、难以同时处理多变量优化。与此同时,“AI物流…...