mmdetection框架下使用yolov3训练Seaships数据集
之前复现的yolov3算法采用的是传统的coco数据集,这里我需要在新的数据集上跑,也就是船舶检测方向的SeaShips数据集,这里给出教程。
Seaships论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8438999
一、数据集下载
可以去官网下载或者直接点击链接下载:
Seaships官网:https://github.com/jiaming-wang/SeaShips
下载链接:http://www.lmars.whu.edu.cn/prof_web/shaozhenfeng/datasets/SeaShips(7000).zip
Seaships原数据集有3万+张图像,但给出的数据集一共只有7000张,应该是经过筛选后的高质量图像。

这是论文给出的数据集中各类型的船只图像数量。

这是论文《AnenhancedCNN-enabledlearningmethodforpromotingshipdetectionin maritimesurveillance system》采用Seaships数据集进行实验的图像数量,一共是7000张。
下载完后的数据集文件夹结构应该是这样的:

一共是三个文件夹,JPEGImages里面保存的是7000张图像文件

ImageSets保存的是四个txt文件

里面分别是四种集的图像编号,如test.txt文件内容如下(部分):

Annotations里面存放的是7000张图像的标注文件:

二、数据集格式转换
YOLO系列算法采用的是coco数据集,coco数据集的标注文件格式如下:

我们可以使用下面的代码直接将Seaships数据集转换成coco数据集文件夹架构的文件:
import os
import cv2
import json
import shutil
import xml.etree.ElementTree as ET
from tqdm import tqdm# Seaships 数据集的类别
SEASHIPS_CLASSES = ('ship', 'ore carrier', 'bulk cargo carrier', 'general cargo ship', 'container ship', 'fishing boat'
)# 将类别名称映射为 COCO 格式的 category_id
label_ids = {name: i + 1 for i, name in enumerate(SEASHIPS_CLASSES)}def parse_xml(xml_path):"""解析 XML 文件,提取标注信息。"""tree = ET.parse(xml_path)root = tree.getroot()objects = []for obj in root.findall('object'):# 解析类别名称name = obj.find('name').textif name not in label_ids:print(f"警告: 未知类别 '{name}',跳过该对象。")continue# 解析 difficult 标签difficult_tag = obj.find('difficult')difficult = int(difficult_tag.text) if difficult_tag is not None else 0# 解析边界框bnd_box = obj.find('bndbox')if bnd_box is not None:bbox = [int(bnd_box.find('xmin').text),int(bnd_box.find('ymin').text),int(bnd_box.find('xmax').text),int(bnd_box.find('ymax').text)]else:print(f"警告: 在文件 {xml_path} 中未找到 <bndbox> 标签,跳过该对象。")continue# 添加到对象列表objects.append({'name': name,'label_id': label_ids[name],'difficult': difficult,'bbox': bbox})return objectsdef load_split_files(split_dir):"""加载划分文件(train.txt, val.txt, test.txt)。"""split_files = {}for split_name in ['train', 'val', 'test']:split_path = os.path.join(split_dir, f'{split_name}.txt')if os.path.exists(split_path):with open(split_path, 'r') as f:split_files[split_name] = [line.strip() for line in f.readlines()]else:print(f"警告: 未找到 {split_name}.txt 文件,跳过该划分。")split_files[split_name] = []return split_filesdef convert_to_coco(image_dir, xml_dir, split_dir, output_dir):"""将 Seaships 数据集转换为 COCO 格式,并根据划分文件划分数据集。"""# 创建输出目录os.makedirs(os.path.join(output_dir, 'annotations'), exist_ok=True)os.makedirs(os.path.join(output_dir, 'train'), exist_ok=True)os.makedirs(os.path.join(output_dir, 'val'), exist_ok=True)os.makedirs(os.path.join(output_dir, 'test'), exist_ok=True)# 加载划分文件split_files = load_split_files(split_dir)# 定义 COCO 格式的基本结构def create_coco_structure():return {"info": {"description": "Seaships Dataset","version": "1.0","year": 2023,"contributor": "Your Name","date_created": "2023-10-01"},"licenses": [],"images": [],"annotations": [],"categories": [{"id": i + 1, "name": name, "supercategory": "none"}for i, name in enumerate(SEASHIPS_CLASSES)]}# 处理每个数据集for split_name, file_names in split_files.items():coco_data = create_coco_structure()annotation_id = 1for file_name in tqdm(file_names, desc=f"处理 {split_name} 数据集"):xml_file = os.path.join(xml_dir, f'{file_name}.xml')image_name = f'{file_name}.jpg'image_path = os.path.join(image_dir, image_name)# 检查图像文件和 XML 文件是否存在if not os.path.exists(image_path):print(f"警告: 图像文件 {image_name} 不存在,跳过该标注文件。")continueif not os.path.exists(xml_file):print(f"警告: 标注文件 {xml_file} 不存在,跳过该图像文件。")continue# 读取图像尺寸image = cv2.imread(image_path)height, width, _ = image.shape# 添加图像信息image_id = len(coco_data['images']) + 1coco_data['images'].append({"id": image_id,"file_name": image_name,"width": width,"height": height})# 解析 XML 文件objects = parse_xml(xml_file)for obj in objects:xmin, ymin, xmax, ymax = obj['bbox']bbox = [xmin, ymin, xmax - xmin, ymax - ymin] # COCO 格式的 bbox 是 [x, y, width, height]area = (xmax - xmin) * (ymax - ymin)coco_data['annotations'].append({"id": annotation_id,"image_id": image_id,"category_id": obj['label_id'],"bbox": bbox,"area": area,"iscrowd": 0,"difficult": obj['difficult']})annotation_id += 1# 复制图像文件到对应的文件夹shutil.copy(image_path, os.path.join(output_dir, split_name, image_name))# 保存 COCO 格式的标注文件with open(os.path.join(output_dir, 'annotations', f'instances_{split_name}.json'), 'w') as f:json.dump(coco_data, f, indent=4)print(f"转换完成,结果已保存到 {output_dir}")# 设置路径
image_dir = "your path to images" # 图像文件目录
xml_dir = "your path to annotations" # XML 标注文件目录
split_dir = "your path to txt directory" # 划分文件目录(包含 train.txt, val.txt, test.txt)
output_dir = "your path to output directory" # 输出的 COCO 格式文件夹# 执行转换
convert_to_coco(image_dir, xml_dir, split_dir, output_dir)将代码保存为Seaships_to_coco.py文件。
运行以下代码进行转换:
python seaships_to_coco.py运行完成以后生成Seaships_coco文件夹,下面包含和coco数据集相同格式的文件:

这样我们就得到了coco格式的Seaships数据集了。
三、修改配置文件
3.1 修改coco.py
将classes修改为Seaships数据集的类:

Seaships类如下六种:
'ship', 'ore carrier', 'bulk cargo carrier', 'general cargo ship', 'container ship', 'fishing boat'3.2 修改class_names.py
同样将coco_class修改为seaships的类别:

3.3 修改需要运行的配置的文件
比如我跑的这个py文件,需要把里面所有的路径都修改成自己coco格式的seaships数据集。

把所有coco的路径都改成自己seaships数据集的路径,包括测试集、训练集等。
完整代码如下:
auto_scale_lr = dict(base_batch_size=64, enable=False)
backend_args = None
data_preprocessor = dict(bgr_to_rgb=True,mean=[0,0,0,],pad_size_divisor=32,std=[255.0,255.0,255.0,],type='DetDataPreprocessor')
data_root = 'data/SeaShips_coco/'
dataset_type = 'CocoDataset'
default_hooks = dict(checkpoint=dict(interval=7, type='CheckpointHook'),logger=dict(interval=50, type='LoggerHook'),param_scheduler=dict(type='ParamSchedulerHook'),sampler_seed=dict(type='DistSamplerSeedHook'),timer=dict(type='IterTimerHook'),visualization=dict(type='DetVisualizationHook'))
default_scope = 'mmdet'
env_cfg = dict(cudnn_benchmark=False,dist_cfg=dict(backend='nccl'),mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
input_size = (320,320,
)
launcher = 'none'
load_from = None
log_level = 'INFO'
log_processor = dict(by_epoch=True, type='LogProcessor', window_size=50)
model = dict(backbone=dict(depth=53,init_cfg=dict(checkpoint='open-mmlab://darknet53', type='Pretrained'),out_indices=(3,4,5,),type='Darknet'),bbox_head=dict(anchor_generator=dict(base_sizes=[[(116,90,),(156,198,),(373,326,),],[(30,61,),(62,45,),(59,119,),],[(10,13,),(16,30,),(33,23,),],],strides=[32,16,8,],type='YOLOAnchorGenerator'),bbox_coder=dict(type='YOLOBBoxCoder'),featmap_strides=[32,16,8,],in_channels=[512,256,128,],loss_cls=dict(loss_weight=1.0,reduction='sum',type='CrossEntropyLoss',use_sigmoid=True),loss_conf=dict(loss_weight=1.0,reduction='sum',type='CrossEntropyLoss',use_sigmoid=True),loss_wh=dict(loss_weight=2.0, reduction='sum', type='MSELoss'),loss_xy=dict(loss_weight=2.0,reduction='sum',type='CrossEntropyLoss',use_sigmoid=True),num_classes=80,out_channels=[1024,512,256,],type='YOLOV3Head'),data_preprocessor=dict(bgr_to_rgb=True,mean=[0,0,0,],pad_size_divisor=32,std=[255.0,255.0,255.0,],type='DetDataPreprocessor'),neck=dict(in_channels=[1024,512,256,],num_scales=3,out_channels=[512,256,128,],type='YOLOV3Neck'),test_cfg=dict(conf_thr=0.005,max_per_img=100,min_bbox_size=0,nms=dict(iou_threshold=0.45, type='nms'),nms_pre=1000,score_thr=0.05),train_cfg=dict(assigner=dict(min_pos_iou=0,neg_iou_thr=0.5,pos_iou_thr=0.5,type='GridAssigner')),type='YOLOV3')
optim_wrapper = dict(clip_grad=dict(max_norm=35, norm_type=2),optimizer=dict(lr=0.001, momentum=0.9, type='SGD', weight_decay=0.0005),type='OptimWrapper')
param_scheduler = [dict(begin=0, by_epoch=False, end=2000, start_factor=0.1, type='LinearLR'),dict(by_epoch=True, gamma=0.1, milestones=[218,246,], type='MultiStepLR'),
]
resume = False
test_cfg = dict(type='TestLoop')
test_dataloader = dict(batch_size=1,dataset=dict(ann_file='annotations/instances_test.json',backend_args=None,data_prefix=dict(img='test/'),data_root='data/SeaShips_coco/',pipeline=[dict(backend_args=None, type='LoadImageFromFile'),dict(keep_ratio=True, scale=(320,320,), type='Resize'),dict(type='LoadAnnotations', with_bbox=True),dict(meta_keys=('img_id','img_path','ori_shape','img_shape','scale_factor',),type='PackDetInputs'),],test_mode=True,type='CocoDataset'),drop_last=False,num_workers=2,persistent_workers=True,sampler=dict(shuffle=False, type='DefaultSampler'))
test_evaluator = dict(ann_file='data/SeaShips_coco/annotations/instances_test.json',backend_args=None,metric='bbox',type='CocoMetric')
test_pipeline = [dict(backend_args=None, type='LoadImageFromFile'),dict(keep_ratio=True, scale=(320,320,), type='Resize'),dict(type='LoadAnnotations', with_bbox=True),dict(meta_keys=('img_id','img_path','ori_shape','img_shape','scale_factor',),type='PackDetInputs'),
]
train_cfg = dict(max_epochs=273, type='EpochBasedTrainLoop', val_interval=7)
train_dataloader = dict(batch_sampler=dict(type='AspectRatioBatchSampler'),batch_size=8,dataset=dict(ann_file='annotations/instances_train.json',backend_args=None,data_prefix=dict(img='train/'),data_root='data/SeaShips_coco/',filter_cfg=dict(filter_empty_gt=True, min_size=32),pipeline=[dict(backend_args=None, type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(mean=[0,0,0,],ratio_range=(1,2,),to_rgb=True,type='Expand'),dict(min_crop_size=0.3,min_ious=(0.4,0.5,0.6,0.7,0.8,0.9,),type='MinIoURandomCrop'),dict(keep_ratio=True, scale=(320,320,), type='Resize'),dict(prob=0.5, type='RandomFlip'),dict(type='PhotoMetricDistortion'),dict(type='PackDetInputs'),],type='CocoDataset'),num_workers=4,persistent_workers=True,sampler=dict(shuffle=True, type='DefaultSampler'))
train_pipeline = [dict(backend_args=None, type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(mean=[0,0,0,], ratio_range=(1,2,), to_rgb=True, type='Expand'),dict(min_crop_size=0.3,min_ious=(0.4,0.5,0.6,0.7,0.8,0.9,),type='MinIoURandomCrop'),dict(keep_ratio=True, scale=(320,320,), type='Resize'),dict(prob=0.5, type='RandomFlip'),dict(type='PhotoMetricDistortion'),dict(type='PackDetInputs'),
]
val_cfg = dict(type='ValLoop')
val_dataloader = dict(batch_size=1,dataset=dict(ann_file='annotations/instances_val.json',backend_args=None,data_prefix=dict(img='val/'),data_root='data/SeaShips_coco/',pipeline=[dict(backend_args=None, type='LoadImageFromFile'),dict(keep_ratio=True, scale=(320,320,), type='Resize'),dict(type='LoadAnnotations', with_bbox=True),dict(meta_keys=('img_id','img_path','ori_shape','img_shape','scale_factor',),type='PackDetInputs'),],test_mode=True,type='CocoDataset'),drop_last=False,num_workers=2,persistent_workers=True,sampler=dict(shuffle=False, type='DefaultSampler'))
val_evaluator = dict(ann_file='data/SeaShips_coco/annotations/instances_val.json',backend_args=None,metric='bbox',type='CocoMetric')
vis_backends = [dict(type='LocalVisBackend'),
]
visualizer = dict(name='visualizer',type='DetLocalVisualizer',vis_backends=[dict(type='LocalVisBackend'),])
work_dir = '/home/21021110287/wxz/mmdetection/work_dirs/yolo_seaships'
路径里面包含seaships的就是我自己修改过后的,大家在用的时候记得改成自己的路径即可。将该文件保存为 yolov3_seaships.py。
运行以下代码开始训练算法(验证集上跑):
python <the path to train.py> <the path to yolov3_seaships.py> --work-dir <the path to your output dirctory>第一个路径是train.py文件的路径 第二个是刚刚保存的运行配置文件的路径,最后一个路径是自定义的输出日志保存结果的路径,如果不设置则会自动生成work_dir文件夹保存结果,命令如下:
python <the path to train.py> <the path to yolov3_seaships.py>如果需要在测试集上跑的话还需要添加检查点文件路径:
python <the path to your test.py> <the path to yolov3_seaships.py> <the path to your pth file> --work-dir <the path to the output dirctory>四、运行结果
运行上述命令后 我们的算法就开始跑起来了:

最终运行结果的日志文件如下:

五、Faster-RCNN
如果还想在faster-rcnn或者ssd上运行,直接选择configs文件夹下不同的配置文件修改运行命令即可
faster-rcnn可能会出现service not available的错误,则需要把运行配置文件中加载与训练模型的代码注释掉,否则没有预训练模型无法运行:

如果不想注释掉就可以按照下面的方法去下载预训练模型(即权重文件):
在python环境下输入下面命令下载模型即可:

之后找到模型文件(.pth文件),复制路径,添加到加载预训练模型的那行代码中”checkpoint=“的后面即可重新运行,这样会发现运行速度远超未加载权重的时候。
相关文章:
mmdetection框架下使用yolov3训练Seaships数据集
之前复现的yolov3算法采用的是传统的coco数据集,这里我需要在新的数据集上跑,也就是船舶检测方向的SeaShips数据集,这里给出教程。 Seaships论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber8438999 一、…...
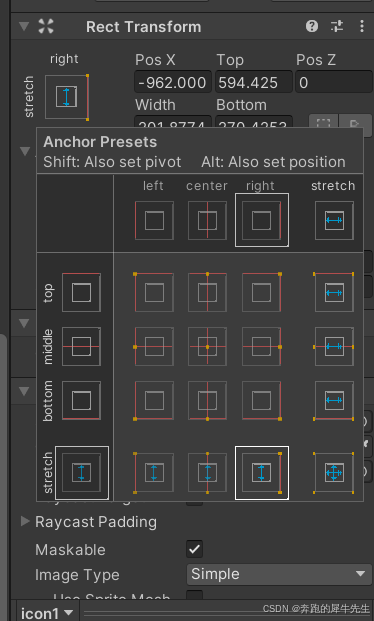
unity学习52:UI的最基础组件 rect transform,锚点anchor,支点/轴心点 pivot
目录 1 image 图像:最简单的UI 1.1 图像的基本属性 1.2 rect transform 1.3 image的component: 精灵 → 图片 1.4 修改颜色color 1.5 修改材质 1.6 raycast target 1.7 maskable 可遮罩 1.8 imageType 1.9 native size 原生大小 2 rect transform 2.1 …...

STM32MP15-FSMP1A单片机移植Linux系统platform总线驱动
之前在该单片机下移植的Linux驱动是学习过程中,对Linux内核驱动的引导学习,接下来才是比较正常的驱动开发。 在Linux内核中,对于驱动的处理,一般会通过总线进行设备信息和设备驱动的匹配,来达到自动检测外设连接系统以…...
)
Java 常见的面试题(设计模式)
一、说一下你熟悉的设计模式? **设计模式:**是一套被反复使用的代码设计经验的总结(情境中一个问题经过证实的一个解决方案)。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使人们可以更加简…...

机器学习3-聚类
1 聚类解决的问题 知识发现,发现事物之间的潜在关系异常值检测特征提取 数据压缩的例子新闻自动分组、用户分群、图像分割、像素压缩等等 2 与监督学习比较 监督学习是需要给定X、Y,X为特征,Y为标签,选择模型,学习&a…...

html中的css
css (cascading style sheets,串联样式表,也叫层叠样式表) css规范一般约定: 1.存放CSS样式文件的目录一般命名为style或css。 2.在项目初期,会把不同类别的样式放于不同的CSS文件,是为了CSS编…...

36. Spring Boot 2.1.3.RELEASE 中实现监控信息可视化并添加邮件报警功能
1. 创建 Spring Boot Admin Server 项目 1.1 添加依赖 在 pom.xml 中添加 Spring Boot Admin Server 和邮件相关依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-w…...

Linux: 已占用接口
Linux: 已占用接口 1. netstat(适用于旧系统)1.1 书中对该命令的介绍 2. ss(适用于新系统,替代 netstat)3. lsof(查看详细进程信息)4. fuser(快速查找占用端口的进程)5. …...
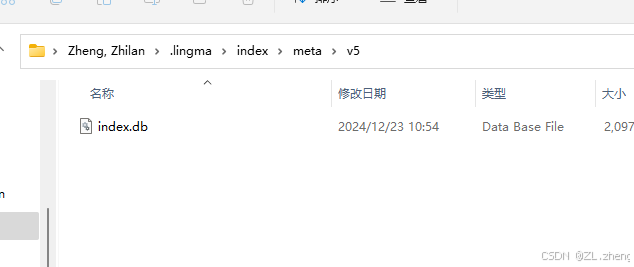
Vscode的通义灵码占用空间过大问题【.lingma】
C盘空间发现没装几个软件但是空间占用太离谱了, 最后排查发现是一个.lingma的文件夹问题,这个文件夹用了我居然差不多一百G的空间, 点进去。删除掉ai训练时产生的dbc文件就好了, windowsI 打开系统设置,搜索存储&#…...

鸿蒙Next如何自定义标签页
前言 项目需求是展示标签,标签的个数不定,一行展示不行就自行换行。但是,使用鸿蒙原生的 Grid 后发现特别的难看。然后就想着自定义控件。找了官方文档,发现2个重要的实现方法,但是,官方的demo中讲的很少&…...
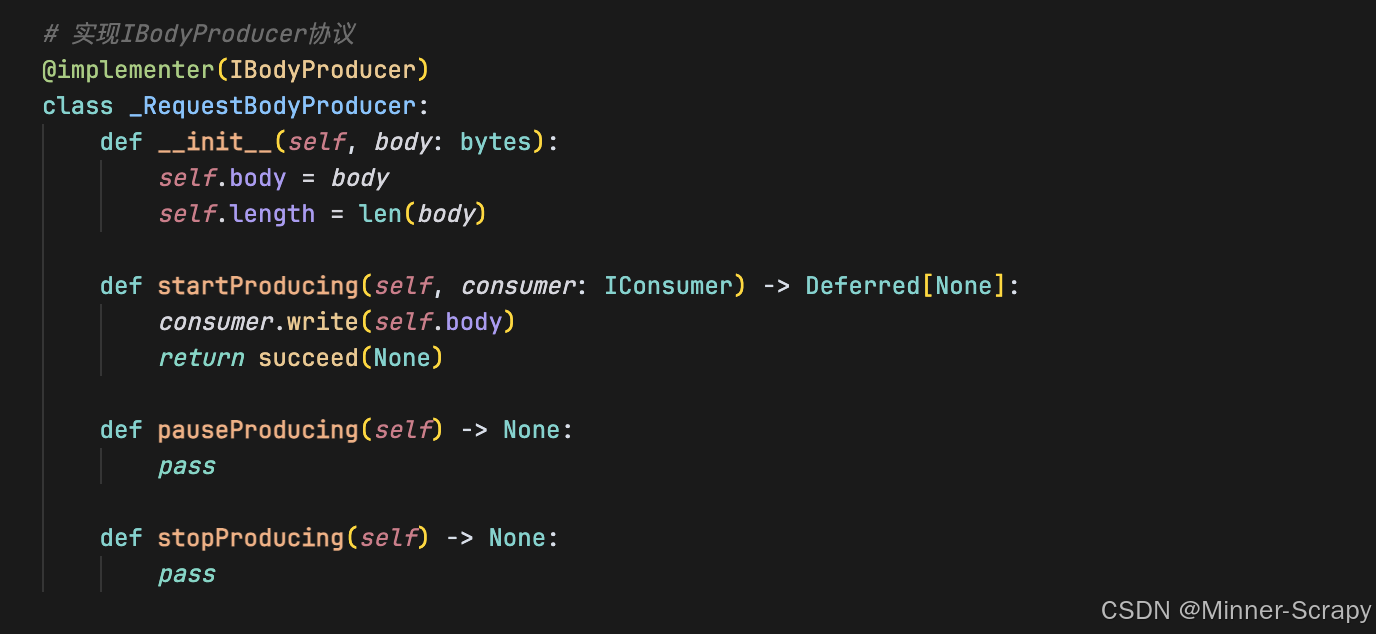
知识拓展:Python 接口实现方式对比:Protocol vs @implementer
Python 接口实现方式对比:Protocol vs implementer 1. 两种接口实现方式 1.1 Python Protocol(结构化子类型) from typing import Protocolclass DownloadHandlerProtocol(Protocol):def download_request(self, request: Request, spider:…...

开源程序wordpress在海外品牌推广中的重要作用
WordPress作为全球最流行的开源内容管理系统(CMS),在全球网站搭建中占据超过40%的市场份额。其强大的功能、灵活性和易用性使其成为企业进行海外品牌推广的首选平台。以下是WordPress在海外品牌推广中的重要性分析: 1. 多语言支持与本地化 WordPress通…...
】爬虫“反水”:助力数字版权保护的逆向之旅)
【Python爬虫(89)】爬虫“反水”:助力数字版权保护的逆向之旅
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...
)
k8s面试题总结(五)
1.考虑一种情况,即公司希望通过维持最低成本来提高其效率和技术运营速度。您认为公司将如何实现这一目标? 公司可以通过构建 CI/CD 管道来实现 DevOps 方法,但是这里可能出现的一个问题是配置可能需要一段时间才能启动并运行。 因此&#x…...

文章精读篇——用于遥感小样本语义分割的可学习Prompt
题目:Learnable Prompt for Few-Shot Semantic Segmentation in Remote Sensing Domain 会议:CVPR 2024 Workshop 论文:10.48550/arXiv.2404.10307 相关竞赛:https://codalab.lisn.upsaclay.fr/competitions/17568 年份&#…...

Spring Boot2.0之十 使用自定义注解、Json序列化器实现自动转换字典类型字段
前言 项目中经常需要后端将字典类型字段值的中文名称返回给前端。通过sql中关联字典表或者自定义函数不仅影响性能还不能使用mybatisplus自带的查询方法,所以推荐使用自定义注解、Json序列化器,Spring的缓存功能实现自动转换字典类型字段。以下实现Spri…...

从电子管到量子计算:计算机技术的未来趋势
计算机发展的历史 自古以来人类就在不断地发明和改进计算工具,从结绳计数到算盘,计算尺,手摇计算机,直到1946年第一台电子计算机诞生,虽然电子计算机至今虽然只有短短的半个多世纪,但取得了惊人的发展吗,已经经历了五代的变革。计算机的发展和电子技术的发展密切相关,…...

将CUBE或3DL LUT转换为PNG图像
概述 在大部分情况下,LUT 文件通常为 CUBE 或 3DL 格式。但是我们在 OpenGL Shader 中使用的LUT,通常是图像格式的 LUT 文件。下面,我将教大家如何将这些文件转换为 PNG 图像格式。 条形LUT在线转换(不是8x8网络)&am…...

python文件的基本操作,文件读写
1.文件 1.1文件就是存储在某种长期存储设备上的一段数据 1.2文件操作 打开文件-->读写文件-->关闭文件 注意:可以只打开和关闭文件不进行任何操作 1.3文件对象的方法 1.open():创建一个file对象,默认以只读模式打开 2.read(n):n表示从文件中…...

华为认证考试证书下载步骤(纸质+电子版)
华为考试证书可以通过官方渠道下载相应的电子证书,部分高级认证如HCIE还支持申请纸质证书。 一、华为电子版证书申请步骤如下: ①访问华为培训与认证网站 打开浏览器,登录华为培训与认证官方网站 ②登录个人账号 在网站首页,点…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧
终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...