【GO】学习笔记
目录
学习链接
开发环境
开发工具
GVM - GO多版本部署
GOPATH 与 go.mod
go常用命令
环境初始化
编译与运行
GDB -- GNU 调试器
基本语法与字符类型
关键字与标识符
格式化占位符
基本语法
初始值&零值&默认值
变量声明与赋值
_ 下划线的用法
字符类型
const 常量
字符串
类型转换与判断
指针
值类型 和 引用类型
复杂数据类型
数组 :一个由固定长度的特定类型元素组成的序列
切片(Slice) : 动态序列
链表(list): 没有元素类型的限制
集合(Map)
结构体(struct): 接近 有顺序的python字典
结构体嵌入
接口(interface)
流程控制
条件 - if else
条件 - switch case
循环 - for
学习链接
- 官方网站:当然是最权威的啦
- Go语言中文网:查询模块使用的中文文档
- Go编程语言:基础语法与规范
- Go语言圣经:入门推荐看这个
- 【尚硅谷】Golang入门到实战教程-bilibili:喜欢跟着视频学习的可以看这个,比如我。
开发环境
开发工具
IDE:goland
版本管理:gvm、go get
go主要版本:go1.16.X、go1.22.X
文档工具:zeal
GVM - GO多版本部署
[root@tserver121 ~]# yum install bison
[root@tserver121 go]# bash < <(curl -s -S -L https://raw.githubusercontent.com/moovweb/gvm/master/binscripts/gvm-installer)
Cloning from https://github.com/moovweb/gvm.git to /root/.gvm
Installed GVM v1.0.22Please restart your terminal session or to get started right away run`source /root/.gvm/scripts/gvm` #可以写到.bash_profile 对普通用户非常有用#相关目录
├── /scripts/ #相关功能脚本
├── /gos/ #go版本数据目录
└── /environments/ #各个版本的环境配置目录#使用
gvm list #当前已安装版本
gvm listall #查找版本#努力安装到最新版本
#由于 Go 1.5 使用了自举(用 Go 编译 Go),如果在系统环境完全没有 Go 命令的情况下,直接使用 gvm install go 会报错。所以,你必须先安装 Go 1.4。
gvm install go1.4 -B #-B 表示只安装二进制包。
gvm use go1.4
gvm install go1.16.2
gvm install go1.22.2
#can't load package: package ./cmd/dist: found packages build.go (main) and notgo120.go (building_Go_requires_Go_1_20_6_or_later) in /root/.gvm/gos/go1.22.2/src/cmd/dist
gvm use go1.16.2
gvm install go1.17.13
gvm use go1.17.13
gvm install go1.20.6
gvm use go1.20.6
gvm install go1.22.2
gvm use go1.22.2 --default #设置默认版本#下载太慢怎么办:https://cloud.tencent.com/developer/article/2403153 实际我测试的机器下载速度还可以GOPATH 与 go.mod
//只是感觉感觉会用上的两个命令
gvm pkgset: 管理Go包。
gvm linkthis: 将此目录链接到 GOPATH 中。//关于 GOROOT 与 GOPATH 可以通过 go env 查看当前环境参数
GOROOT: Go的安装目录
GOPATH: 我们的工作空间,保存go项目代码和第三方依赖包 //Go 1.11 及以上版本推荐使用 Go Modules,而不再强制要求依赖 GOPATH 结构。( go.mod )
GO111MODULE = auto(默认值)Go 会根据当前的工作目录判断是否启用 Go Modules。如果你在 GOPATH 目录内,Go 会使用 GOPATH 模式来管理依赖。如果你在 GOPATH 目录外并且有 go.mod 文件,Go 会自动启用模块模式。go常用命令
go version #查看版本
go env #查看环境变量
go run xxx.go #运行
go build #编译 go build -v -x -work xxx.go //指定文件 xxx.go -race #用来启用竞态检测的命令选项
go test -v #运行测试 go mod init #初始化
go mod tidy #清理和整理
go clean #移除当前源码包和关联源码包里面编译生成的文件
go get #添加新依赖项, go.mod 文件将自动更新以反映新的依赖项及其版本。gofmt -d 只是检查差异,并不会修改文件本身。
gofmt -w 写入文件//go build
-v 编译时显示包名
-p n 开启并发编译,默认情况下该值为 CPU 逻辑核数
-a 强制重新构建
-n 打印编译时会用到的所有命令,但不真正执行
-x 打印编译时会用到的所有命令
-race 开启竞态检测
-o 输出文件名//go clean 清除掉编译过程中产生的一些文件
-i 清除关联的安装的包和可运行文件,也就是通过go install安装的文件;
-n 把需要执行的清除命令打印出来,但是不执行,这样就可以很容易的知道底层是如何运行的;
-r 循环的清除在 import 中引入的包;
-x 打印出来执行的详细命令,其实就是 -n 打印的执行版本;
-cache 删除所有go build命令的缓存
-testcache 删除当前包所有的测试结果//go fmt 格式化代码文件
-l 仅把那些不符合格式化规范的、需要被命令程序改写的源码文件的绝对路径打印到标准输出
-w 把改写后的内容直接写入到文件中,而不是作为结果打印到标准输出。
-s 简化文件中的代码。 去掉注释环境初始化
go mod download 下载依赖包到本地(默认为 GOPATH/pkg/mod 目录)
go mod edit 编辑 go.mod 文件 管理依赖
go mod graph 打印模块依赖图
go mod init 初始化当前文件夹,创建 go.mod 文件
go mod vendor 将依赖复制到 vendor 目录下
go mod verify 校验依赖
go mod why 解释为什么需要依赖
go mod tidy 增加缺少的包,删除无用的包 清理和整理 go.mod 、go.sum文件1. 初始化项目(如果没有 go.mod 文件)go test -v
问题go: go.mod file not found in current directory or any parent directory; see 'go help modules'
执行[root@t33 src]# go mod init bilibili //生成go.mod 文件 管理项目的依赖项,并在$GOPATH/下生成pkg/mod/cache/lock文件 ,//另外go.sum 文件,充当一个校验和文件记录模块及其对应版本的加密哈希值(校验和)[root@t33 src]# cat go.mod module bilibiligo 1.22.2关于go.mod module example.com/bilibili:定义了当前项目的模块路径。go 1.22.2:指定了当前项目所需的最低 Go 版本。require 块下列出了项目依赖的模块及其版本要求。编译与运行
//编译
[root@t33 src]# go build
[root@t33 src]# ls -l
total 2084
-rwxr-xr-x 1 root root 2120162 Feb 10 18:35 bilibili // 编译后的可执行文件
-rw-r--r-- 1 root root 27 Feb 10 18:30 go.mod
-rw-r--r-- 1 root root 5952 Feb 6 19:22 main.go//运行
go run xxx.go //直接运行脚本文件
./bilibili //运行编译后的二进制文件GDB -- GNU 调试器
#debug 调试器 编译后的二进制文件 感觉是需要的
devel #https://github.com/derekparker/delve
GDB #文档https://blog.csdn.net/qq_30614345/article/details/131345027r:run,执行程序n:next,下一步,不进入函数s:step,下一步,会进入函数b:breakponit,设置断点l:list,查看源码c:continue,继续执行到下一断点bt:backtrace,查看当前调用栈p:print,打印查看变量q:quit,退出 GDBwhatis:查看对象类型info breakpoints:查看所有的断点info locals:查看局部变量info args:查看函数的参数值及要返回的变量值info frame:堆栈帧信息基本语法与字符类型
关键字与标识符
Go语言的词法元素包括 5 种,分别是标识符(identifier)、关键字(keyword)、操作符(operator)、分隔符(delimiter)、字面量(literal)关键字: 一共有 25个 不能够作标识符使用。break default func interface selectcase defer go map structchan else goto package switchconst fallthrough if range typecontinue for import return var标识符:Go语言对各种变量、方法、函数等命名时使用的字符序列 //就是定义的名称特殊的标识符 //可以理解为 已经被定义过了 所以不要定义一样的了内建常量: true false iota nil内建类型: int int8 int16 int32 int64uint uint8 uint16 uint32 uint64 uintptrfloat32 float64 complex128 complex64bool byte rune string error内建函数: make len cap new append copy close deletecomplex real imagpanic recover操作符算术运算符:+, -, *, /, %关系运算符:==, !=, <, >, <=, >=逻辑运算符:&&, ||, !赋值运算符:=, +=, -=, *=, /=, %= //先运算后赋值位运算符:&, |, ^, <<, >>其他操作符:&, *, ++, --, <-逻辑运算:与或非 (A && B) (A || B) !(A && B)位运算: (A & B) (A | B) (A ^ B) 原码、反码、补码二进制的最高位是符号位: 0表示正数,1表示负数 -1【1000 0001】正数的原码,反码,补码都一样,负数的反码=它的原码符号位不变,其它位取反(0->1,1->0) -1【1111 1110】负数的补码=它的反码+1 -1【1111 1111】在计算机运算的时候,都是以补码的方式来运算的.(A << 2) (A >> 2) 分隔符分号(;):用于分隔语句 //Go 中每个语句一般由换行符结束,但在某些情况下也会使用分号。 逗号(,):用于分隔函数参数、变量声明等。句点(.):用于访问结构体成员或调用方法。括号(()):用于表达式的分组、函数参数等。大括号({}):用于代码块的包围(如函数体、控制结构体等)。中括号([]):用于声明数组、切片等。双引号(""):用于表示字符串字面量。反引号(``):用于表示原生字符串字面量。字面量直接表示它们所代表的值,而不需要经过计算或解释。字面量通常用于初始化变量、常量或传递参数等情况。
字面量可以是各种数据类型的值,包括整数、浮点数、布尔值、字符串、字符、数组、映射等。字符串字面量:"hello", "Go language"结构体字面量布尔字面量:true, false命名规则-常见约定规则 变量名、函数名、常量名: 驼峰法 stuName/xxxYyyyZzzz, 而不是优先下划线分隔//【重点标记】首字母大写为共有的,小写的就私有的 格式化占位符
%v:用于打印变量的自然格式。 // 这个比较厉害,学习的时候用这个会比较多。如果打印的是结构体,会递归打印其字段;如果是指针,则打印指针所指向的值;如果是接口,则打印接口的动态类型和动态值;如果是数组,则打印数组的值;如果是切片,则打印切片的长度和容量;如果是通道,则打印通道的地址;如果是 map,则打印 map 的键值对;如果是 nil,则打印 <nil>。%T:用于打印值的类型。
%d:用于打印有符号整数(十进制)。
%b:用于打印二进制表示的整数。
%o:用于打印八进制表示的整数。
%x:用于打印十六进制表示的整数,使用小写字母。
%X:用于打印十六进制表示的整数,使用大写字母。
%f:用于打印浮点数(小数)。
%e:用于打印科学计数法表示的浮点数。
%s:用于打印字符串。
%p:用于打印指针的值,以十六进制形式显示。
%c:用于打印字符。
%U:用于打印 Unicode 字符的格式,如 U+1234。
%q:用于打印格式化输出的占位符// 打印自己想要的结果,有时候可以用来做字符转换fmt.Sprintf
// 常用的是:%v %T %d %s %p
func main() {var i int=011fmt.Printf("%v, %T, %d, %s, %p, \n", i, i, i, i, i)//9, int, 9, %!s(int=9), %!p(int=9),
}基本语法
包含:包声明 & 引入包 函数 & 变量 & 语句 & 表达式 & 注释,下面是一个简单的例子。
package main //包声明 函数内部的名字则必须先声明之后才能使用import ("fmt" //引入包
)// 主要的组成部分: 函数 & 变量 & 语句 & 表达式 & 注释
// 函数
func expression() {a := 10b := 5sum := a + b // 算术表达式fmt.Println("Sum:", sum)
}
// main函数
func main() {//单行注释/* 多行注释体验与python不一样的地方写实例 是为了 ctrl + cgoland ctrl + 左键 追踪源代码go对我初学过程中 中英文切换输入 不太友好: := , //需要秉持着怀疑态度看待此文档,毕竟缺乏大量的实操,踩坑太少的缘故*/var str string = `多行字符串 使用反引号这是一个简单的程序`fmt.Printf("%v \n", str); fmt.Println("多个语句写在同一行,它们则必须使用分号(;)")//空格通常用于分隔标识符、关键字、运算符和表达式,为了美观也需要保持一定的格式与缩进expression() //函数调用
}初始值&零值&默认值
//go语言中不存在未初始化的变量数值类型变量对应的零值是0,布尔类型变量对应的零值是false,字符串类型对应的零值是空字符串,接口或引用类型(包括slice、指针、map、chan和函数)变量对应的零值是nil。数组或结构体等聚合类型对应的零值是每个元素或字段都是对应该类型的零值。nil 标识符是不能比较的不同类型的 nil 是不能比较的两个相同类型的 map、slice 和 function 类型的 nil 值不能比较
nil 不是关键字或保留字
nil 没有默认类型 #fmt.Printf("%T", nil)
不同类型 nil 的指针是一样的变量声明与赋值
变量声明一般语法 //变量没有声明会报错, 声明了没使用也会报错(全局变量除外)。var 变量名字 类型 = 表达式 var str2 string = "123456" //这是声明并赋值,可以简化,简化的既是常用的//省略类型 将根据初始化表达式来推导变量的类型var i, j, k int // int, int, intvar ff, ss = 2.3, "four" // float64, string//省略表达式var str stringvar b int // 没有初始化就为零值 var c bool // bool 零值为 false//(简短形式) 变量的类型根据表达式来自动推导v_name := value // := 声明变量, var v_name 声明过了就会报错i, j := 0, 1f, err := os.Open(name) //函数的返回值赋值语句可以更新一个变量的值x = 1 // 命名变量的赋值*p = true // 通过指针间接赋值person.name = "bob" // 结构体字段赋值count[x] = count[x] * scale // 数组、slice或map的元素赋值支持 *=, i++, i--_ 下划线的用法
import (_ "database/sql/driver" // 导入包仅用于初始化驱动,不直接使用包中的符号
)//_ 也用作空白标识符,它允许您忽略不需要的值。常见的使用场景包括:
// 忽略错误返回值/第二个返回值
result, _ := someFunction()// 在 range 循环中忽略键/值
for _, value := range someSlice
for value, _ := range someSlice 字符类型
数字: int*(有符号整型)uint*(无符号整型) uintptr(指针类型)rune == int32-Unicode 字符 []byte("") //byte是 uint8 的别名表示原始的二进制数据 byte 0-255
浮点数:float* , 推荐常用float64
布尔型: true, false
字符与字符串型: 字符串是一种值类型,且值不可变,任何对字符串进行的修改,都会生成一个新的字符串,而不会改变原来的字符串字符串它是由字节组成的。单个字符用byte类型 []byte("") 字符串用"" 和``反引号不转换字符串, 字符用''//如果我们希望输出对应字符,需要使用格式化输出var c1 int = '北' // 这里是单引号('')var c2 = []byte("a,as,sd,f,g, 北") //中文用byte 类型就会 overflow 溢出 fmt. Printf(" c1=%c c1对应码值=%d \n", c1, c1) //当我们直接输出byte值,就是输出了的对应的字符的码值fmt. Printf(" c2=%c c2对应码值=%d \n", c2, c2) 符合数据类型:指针 数组 结构体 ...等等const 常量
//常量表达式的值在编译期计算,而不是在运行期显式类型定义: const b string = "abc"隐式类型定义: const b = "abc"const b = iota //iota 特殊常量 行索引const (a = iota //0 ota将会被置为0,然后在每一个有常量声明的行加一b //1c //2d = "ha" //独立值,iota += 1e //"ha" iota += 1f = 100 //iota +=1g //100 iota +=1h = iota //7,恢复计数i //8)const (_ = 1 << (10 * iota) 1024的幂KiB // 1024MiB // 1048576GiB // 1073741824)字符串
//一个字符串是一个不可改变的字节序列,基于原来的字符串操作是生成一个新字符串。s := "left foot"t := ss += ", right foot"fmt.Println(s) // "left foot, right foot"fmt.Println(t) // "left foot" t依然是包含原先的字符串值。//字符串是不可修改的,因此尝试修改字符串内部数据的操作也是被禁止的:s[0] = 'L' // compile error: cannot assign to s[0]//字符串是以字节序列来存储的 底层是一个byte数组myString := "hello, 世界"//228, 184, 150 对应字符 世(UTF-8 编码的 3 字节表示)//231, 149, 140 对应字符 界(UTF-8 编码的 3 字节表示)//截断fmt.Println(myString[0], myString[7], myString[10]) //104 228 231 输出的是编码值fmt.Println(myString[:5]) // "hello"fmt.Println(myString[7:]) // "世界"fmt.Println(myString[:]) // "hello, 世界"fmt.Printf("%v", len("世界")) //6//Byte切片var myBytes = []byte("h,e,ll,o, 世,界")fmt.Printf("%c", myBytes) //打印字符fmt.Printf("%v", myBytes) //打印asill//遍历, 直接使用 for len的话 中文会乱码 go统一采用utf-8 编码 中文占3个字节for i := 0; i < len([]rune(myString)); i ++ {fmt.Printf("%c, ", []rune(myString)[i])}for i := 0; i < len(myString); i ++ {fmt.Printf("%c, ", myString[i])}//标准库中常用的:bytes、strings、strconv和unicode包strings包提供了许多如字符串的查询、替换、比较、截断、拆分和合并等功能。strconv包提供了布尔型、整型数、浮点数和对应字符串的相互转换。unicode包提供了IsDigit、IsLetter、IsUpper和IsLower等类似功能//长度fmt.Printf("%v", len("asded")) //查找字符串ba := strings.Contains("asded", "as")fmt.Printf("%v", ba) //打印asill//统计出现次数cont := strings.Count("asded", "as")fmt.Printf("%v", cont) //打印asillstrUpLow := " Golang hello "fmt.Printf("%v\n", strings.ToLower(strUpLow)) //大小写转换fmt.Printf("%v\n", strings.ToUpper(strUpLow)) //大小写转换fmt.Printf("%q\n", strings.Trim(strUpLow, " ")) //去指定字符串fmt.Printf("%q\n", strings.TrimSpace(strUpLow)) //去空格fmt.Printf("%v\n", strings.HasPrefix(strUpLow, " ")) //以什么开头fmt.Printf("%v\n", strings.HasSuffix(strUpLow, " ")) //以什么结尾类型转换与判断
//基本数据类型转换var inta int = 10233var floata float64 = float64(inta) //type_name(expression) type_name 为类型,expression 为表达式。//字符串和数字的转换// 数字 --> 字符var inta int = 10233var str stringstr = fmt.Sprintf("%v", floata)fmt.Printf("str type: %T str=%q", str, str) //str type: string str="10233" 注意这个%q 与 "10233" 这个引号 是默认加的strconv_str = strconv.FormatInt(int64(floata), 8) //type: string strconv_str="23771"strconv_str = strconv.FormatFloat(floata, 'f', 2, 64) //type: string strconv_str="10233.00"strconv_str = strconv.Itoa(inta) //strconv_str type: string strconv_str="10233"// 字符 --> 数字var str2 string = "123456"strconv_num, _ := strconv.ParseInt(str2, 10, 64) //strconv_num type: int64 strconv_num=123456strconv_num, _ = strconv.ParseFloat(str2, 64) //strconv_num type: float64 strconv_num=10233str_num, _ := strconv.Atoi("str2") //str_num type: int str_num=123456//类型判断unicode.IsLetter('A') //判断是否为字母:unicode.IsDigit('1') //判断是否为数字:unicode.IsSpace(' ') //判断是否为空白符号://断言str, ok := i.(string) #string是要转换成的类型。无论 T 是什么类型,如果 x 是 nil 接口值,类型断言都会失败。switch a.(type) {case int:fmt.Println("the type of a is int")case string:fmt.Println("the type of a is string")指针
// * 取值符 & 取地址符
//值类型 都有对应的指针类型 格式为 *数据类型var ip *int /* 指向整型*/var fp *float32 /* 指向浮点型 */var pptr **int /* 指针的指针 */var mun1 int = 1var ptr1 *int = &mun1pptr = &ptr1fmt.Printf("类型=%T,值=%v\n", mun1, mun1) //类型=int,值=1fmt.Printf("类型=%T,值=%v\n", &mun1, &mun1) //类型=*int,值=0xc00008a080 mun1的地址fmt.Printf("类型=%T,值=%v\n", ptr1, ptr1) //类型=*int,值=0xc00008a080 和&mun1 结一致说明ptr1 存放的mun1地址fmt.Printf("类型=%T,值=%v\n", *ptr1, *ptr1) //类型=int,值=1 通过去地址符将 ptr1存放地址指向的值 取出来fmt.Printf("类型=%T,值=%v\n", *pptr, *pptr) //类型=*int,值=0xc00008a080 等同于ptr1fmt.Printf("类型=%T,值=%v\n", **pptr, **pptr) //类型=int,值=1
值类型 和 引用类型
- 值类型: 数字,浮点数,bool, string、数组和 结构体struct 等基本的数据类型
- 引用类型:指针、slice切片、map,管道chan、interface 等
- 区别:引用类型变量存储的是一个地址,这个地址对应的空间才真正存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC来回收
复杂数据类型
数组 :一个由固定长度的特定类型元素组成的序列
//数组的地址 就是第一个元素的地址 ,数字的元素的地址是连续的
//很少直接使用数组 一般使用Slice(切片)比较多,它是可以增长和收缩的动态序列
//[3]int和[4]int是两种不同的数组类型
//如果一个数组的元素类型是可以相互比较的,那么数组类型也是可以相互比较的//赋值var arrayName [size]dataType = [size]dataType{int1, int2, int2} //一般语法//四种初始化数组的方式var numArrel [3]int = [3]int{1, 2, 3}var numArre2 = []int{5, 6, 7}var numArre3 = [...]int{8, 9, 10} //这里的[...] 是规定的写法 表示长度是根据初始化值的个数来计算var numArre4 = [...]int{1: 800, 4: 900, 2:9} // 指定位置赋值//可以省略表达式var arrayName [10]int //初始值为0var arrayName [10][10]int{} //多维数组//推导模式numbers := [5]int{1, 2, 3, 4, 5} //初始化元素numbers := [5]float32{1:2.0,3:7.0} //指定下标来初始化元素numbers := [...]int{1, 2, 3, 4, 5} //数组长度不确定, ...是固定写法var hens [6]float64hens[0] = 3.01 //[3.01 0 0 0 0 0]//数组的地址 就是第一个元素的地址 ,数字的元素的地址是连续的 ,切片不是&hens, &hens[0] //hens 的地址0xc00000c360, 第一个元素的地址0xc00000c360//遍历for index, vlue := range hens {fmt.Printf("hens 下标%v, 对应的值%v", index, vlue)fmt.Println()}切片(Slice) : 动态序列
//虽然它是可以增长和收缩的动态序列序列中,但每个元素都有相同的类型
//slice一个引用类型
//slice从底层来说,一个轻量级的struct结构体
type slice struct{ptr *[2]intlen intcap int
}//赋值 int 和 string类型 的切片会比较常见var mySlice []string //未指定大小的数组来定义切片var mySlice1 []int = []int{1,2,3}var mySlice2 []int = []int{1: 800, 4: 900, 2:9} //[0 800 9 0 900]//make([]type, length, capacity) 使用 make() 函数来创建切片,也可以指定容量,其中 capacity 为可选参数var mySlice3 []int = make([]int, 3,9) var numArre4 = [...]int{8, 9, 10}mySlice4 := numArre4[1:2] //通过数组截取 获得切片//访问s := Slice[startIndex:endIndex] s := Slice[startIndex:] s := Slice[:endIndex]//string底层是一个byte数组,因此string也可以进行切片处理strString := "hello@bilibili"slice5 := strString[6:] //bilibili//遍历 和数组一样for index, vlue := range mySlice2 {fmt.Printf("mySlice2 下标%v, 对应的值%v", index, vlue)fmt.Println()}支持的函数len() 获取长度cap() 计算容量-最大长度 切片在自动扩容时,容量的扩展规律是按容量的 2 倍数进行扩充append() 追加 #返回新切片的特性copy() 拷贝//cap()cap(make([]int, 3,9)) //9cap([]int{-3, -2, -1, 0, 1, 2, 3}) //7//append() mySlice1 = []int{1,2,3} //[1 2 3]mySlice2 = []int{1: 800, 4: 900} // [800 0 0 900]a := append(mySlice1, 100,200,5,) // 同时添加多个元素 //...是固定写法 表示将切片的元素逐一添加到目标切片,而不是整体加进去 会涉及到二维切片了a = append([]int{0}, mySlice1...) // 追加一个切片 [0 1 2 3]a = append([]int{0}, mySlice2) //...是固定写法 cannot use mySlice2 (type []int) as type int in appenda = append([]int{-3,-2,-1}, a...) // [-3 -2 -1 0 1 2 3] cap =8 a = append(a[:2], append([]int{100,99,98}, a[2:]...)...) // 在第2个位置插入切片 [-3 -2 100 99 98 -1 0 1 2 3]//copy(dst, src []T) int dst: 目标切片 src: 源切片 返回值: 返回实际复制的元素个数a = a[1:] // 删除前1个元素 [-2 100 99 98 -1 0 1 2 3]copy(a, a[1:]) // 返回值: 8 [100 99 98 -1 0 1 2 3 3] 重合的被覆盖,为重合的保持原值a = a[:copy(a, a[1:])] // 删除开头1个元素 [99 98 -1 0 1 2 3 3] 这种方法等于a = a[:8] a = a[:len(a)-1] // 删除尾部1个元素 [99 98 -1 0 1 2 3]a = append(a[:2], a[2+1:]...) // 删除中间三号位的1个元素 [99 98 0 1 2 3]a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素链表(list): 没有元素类型的限制
//container/list包实现了双向链表
//链表是一种非连续的存储容器,由多个节点组成,节点通过一些变量记录彼此之间的关系,链表有多种实现方法,如单链表、双链表等。
//链表与切片和 map 不同的是,列表并没有具体元素类型的限制
赋值//var l list.Listl := list.New()// 尾部添加l.PushBack("canon") // canon// 头部添加l.PushFront(67) // 67 ==> canon // 尾部添加后保存元素句柄element := l.PushBack("fist") // 67 ==> canon ==> fist//返回值会提供一个 *list.Element ,这个结构记录着列表元素的值以及与其他节点之间的关系等信息,从列表中删除元素时,需要用到这个结构进行快速删除。// 在fist之后添加highl.InsertAfter("high", element) // 67 ==> canon ==> fist ==> high // 在fist之前添加noonl.InsertBefore("noon", element) //67 ==> canon ==> noon ==> fist ==> high// 移除l.Remove(element) // 67 ==> canon ==> noon ==> high// 遍历for i := l.Front(); i != nil; i = i.Next() { //遍历时只要元素不为空就可以继续进行,每一次遍历都会调用元素的 Next() 函数,fmt.Println(i.Value)}单链表
type Node struct {Data interface{} //interface{} 可以理解为可以放任意值Next *Node
} // Data 用来存放结点中的有用数据,Next 是指针类型的成员,它指向 Node struct 类型数据,也就是下一个结点的数据类型。双向链表
type Node struct {Date interface{}Next *Node Preview *Node
}集合(Map)
//map就是一个哈希表的引用集合,
// key必须相同的类型,value必须相同的类型 所以感觉使用结构体的会比较多
// key类型:bool、数字、string、指针、channel. 还可以是只包含前面几个类型的接口,结构体,数组
// key必须是支持==比较运算符的数据类型,通常为int、string,但slice、map、function 不可以,因为这几个没法用=来判断// 赋值 -四种方式//map := make(map[KeyType]ValueType, initialCapacity) #initialCapacity 是可选的参数,用于指定 Map 的初始容量var myMap map[string]stringmyMap = make(map[string]string, 10) //需要make分配数据空间之后才能使用 myCitpMap := make(map[string]string, 12)var myPeoMap map[string]int = map[string]int{"apple": 1,"banana": 2,"orange": 3,}m := map[string]int{"apple": 1,"banana": 2,"orange": 3,}m := make(map[string]int) // 创建一个空的 Mapm := make(map[string]int, 10) // 创建一个初始容量为 10 的 Map// value 是个map 有点像python的字典了 myStuMap := make(map[string]map[string]string, 12)myStuMap["key1"] = make(map[string]string, 12) //这里value 是个map ,需要将value make一次myStuMap["key1"]["col"] = "col1"myStuMap["key1"]["row"] = "row1"//获取v1 := m["apple"] // 获取键值对v2, ok := m["pear"] // 如果键不存在,ok 的值为 false,v2 的值为该类型的零值len := len(m) // 获取 Map 的长度// 删除delete(m, "banana") // 删除键值对//清空 map 的唯一办法就是重新 make 一个新的 map// 遍历 Mapfor k, v := range m {fmt.Printf("key=%s, value=%d\n", k, v)}//切片-mapmySliceMap := make([]map[string]string, 2) // [map[] map[]]mySliceMap[0] = make(map[string]string, 2) //需要make一次mySliceMap[1] = make(map[string]string, 2) //需要make一次 // 切片-动态增加mySliceMap = append(mySliceMap, make(map[string]string, 2)) //[map[] map[] map[]]//结构体-maptype Stus struct {Name stringAge intAddress string}mySliceMap1 := make(map[string]Stus, 2)stu2 :=Stus{"tom", 18, "zheli"} // {"Name": "tom", "Age": 18, "Address":"zheli"}mySliceMap1["key1"] = stu2fmt.Println(mySliceMap1) //map[key1:{tom 18 zheli}]fmt.Println(mySliceMap1["key1"].Name) //获得Name的值tom //可以了解一下
//map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。
//Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Mapvar scene sync.Map// 将键值对保存到sync.Mapscene.Store("greece", 97)scene.Store("london", 100)// 从sync.Map中根据键取值fmt.Println(scene.Load("london"))// 根据键删除对应的键值对scene.Delete("london")// 遍历所有sync.Map中的键值对scene.Range(func(k, v interface{}) bool {fmt.Println("iterate:", k, v)return true})结构体(struct): 接近 有顺序的python字典
//结构体是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。
//结构体中,非空白字段名必须是唯一的。//type 定义新的类型 type TypeName ExistingType
type Employee struct {} // 将Employee定义为结构体//字段的顺序 很重要
// 一个正常简单的结构体
type Stus struct {Name stringAge intAddress string
}type Person struct {Name string `json:"name"` //tag 反射Age int `json:"age"`Address string
}type T struct {u float32Microsec uint64 "field 1" // 注释x, y int //相同类型_ float32 // _ 填充 不打算使用该字段A *[]int // 整数切片的指针F func() //函数 Data interface{} //接口 int // 匿名段名*string // 匿名段名Employee // 匿名段名 自定义类型Name string `json:"name"` //tag 反射使用 后面在讲。Age intColor string
}//实例化// 结构体的定义只是一种内存布局的描述,只有当结构体实例化时,才会真正地分配内存// 创建指针类型的结构体ins := new(T)// 取结构体的地址实例化var Person6 *Person = &Person{} insw := &T{} //语法 就是这样的语法 不要奇怪//正常的的创建结构体var cat1 Tinsws := T{}//赋值Person3 := Person{"myname",1, "海上"} //推导模式直接赋值 这样的方式值而且按顺序写完全 不够方便 //通过点操作符赋值与访问cat1.Name = "cat1"cat1.Age = 1cat1.Age += 1cat1.string = "age1" //指针类型的也支持点操作符Person6.Name = "Person6" //是(*Person6).Age = 12 简写 (*Person6).Age = 12 //这样写也需要看的懂fmt.Println(*Person6) //{Person6 12 }//转换var a Stusvar b Persona = Stus(b) //两个结构体 是不同类型, 转换:结构体需要完全一样才能强制转换//反射机制
//struct的每个字段上,可以写上一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化。jsonPerson3, _ :=json.Marshal(Person3) //Name string `json:"name"`fmt.Println(jsonPerson3) // {"name":"myname","age":1,"Address":"海上"} Address 没加tag 所以是大写的fmt.Println(string(jsonPerson3)) //string//实例化一个匿名结构体msg := &struct { // 定义部分id intdata string}{ // 值初始化部分1024,"hello",}fmt.Println(*msg) //指针类型 结构体嵌入
//结构体嵌入 带有父子关系的结构体的构造和初始化 ----继承
//https://c.biancheng.net/view/68.htmltype Point struct {X int
}//Go语言导出规则决定:以大写字母开头的,那么该成员就是导出的
type Circle struct {Center Point // 大写字段开头 能导出 包外部能访问该字段radius int // 小写字段开头 不能导出 包外部不能访问该字段,当然可以通过 工厂模式 解决结构体首字母是小写的问题
}type Square struct {Point //匿名段名Side intTags string
}type Colors struct {Circle //匿名段名Square //匿名段名color intTags float32
}type Wheel struct {Circle CircleSpokes int
}func main() {//var w popcount.Wheel// struct 分开写 是为了相同的属性独立出来,逻辑更简单var w Wheelvar c Colorsw.Circle.Center.X = 8 //需要全路径访问fmt.Println(w.Circle.Center.X)c.X = 9 //匿名嵌入的特性,不需要给出完整的路径c.Square.Point.X = 7 //当然也可以全路径访问fmt.Println(c.X) //7fmt.Println(c.Point.X ) //7 c.Point.X == c.Xfmt.Println(c.Center.X ) //0 c.Center.X != c.X 这和 加载顺序有关系 匿名调用简单了 但涉及到字段冲突//结构体方法按照你显式调用它们的顺序执行。//嵌套结构体的字段会在父结构体字段之前初始化。//字段会按照声明的顺序被初始化,先是默认值,再覆盖传入的值。 c.X 值为7 不是9fmt.Printf("%T", c.Tags) //float32 c.Tags 为 float32 类型fmt.Printf("%T", c.Square.Tags) //stringfmt.Println()fmt.Printf("%#v\n", c)//if c.Point.X == c.X { //找到尾节点// fmt.Println("true" )//}//可以不通过点方式赋值,但是路径需要写完成,不能省略匿名成员//dict := Wheel{Circle{Point{8}, 5}, 20} //不能缺少字段dict1 := Colors{ //这种方式 字段顺序可以打乱 但是更复杂Circle: Circle{Center: Point{X: 9},radius: 5, // 逗号不能省略 为了保持规范是不是不习惯了},Square:Square{Point:Point{X:7}, //匿名段名Tags:"big",Side:1, // 逗号不能省略},Tags: 11.21,color: 48932,// 逗号不能省略}fmt.Printf("%#v\n", dict) //可以看看这么打印和直接%v 有什么不一样fmt.Printf("%v\n", dict1)
}接口(interface)
//go的核心功能,这里先简单的介绍下,体验体验,后面单独讲
//接口不包含方法的实现,只是定义了方法的名称、参数和返回类型。是一种抽象类型,定义了一组方法的集合,实现了多态性。//定义
type AInterg interface { //格式//method1(参数列表) 返回值列表//method2(参数列表) 返回值列表Start()
}//接口本身不能创建实例
//定义一个int, 一般举例都用结构体,但是只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型。
type integer int //integer 现在还与 AInterg 无关var myi integer = 10 //myi 赋值integer自定义数据类型 值为10//给integer 绑定个方法 方法后面再说 可以使用点操作符调用 myi.Start()
func (i integer) Start() {fmt.Println("(i integer) Say() ", i * i)
}myi.Start() //可以直接调用 这里和interface没联系//当一个类型实现了接口中的所有方法时,它就实现了该接口。不需要显式声明某个类型实现了某个接口。
//实现接口 就需要实现接口申明的所有方法 再次强调var new4 AInterg = myi // 接口与 myi 就绑定了,AInterg 的方法需要全部实现new4.Start()//过程觉得太麻烦了
//优点就是解耦,接口的实现是隐式的,不需要声明myi是否实现了接口//空接口 interface{} //空接口是没有任何方法签名的接口,所有类型都默认实现了空接口,索引可以传入任何值,//在函数传入时特别有用func reflectTest1(b interface{}) {} // b可以任意数据类型变量var allChan interface{} // 可以任意数据类型变量allChan = 1allChan = "int"// 类型断言、嵌入 后面再讲流程控制
条件 - if else
if condition1 {// do something
} else if condition2 {// do something else
}else {// catch-all or default
}// 特殊写法: if 表达式之前添加一个执行语句,再根据变量值进行判断
// 返回值的作用范围被限制在 if、else 语句组合中
if err := Connect(); err != nil {fmt.Println(err)return
}
//变量的作用范围越小,所造成的问题可能性越小条件 - switch case
//不需要通过 break 语句跳出当前 case 代码块以避免执行到下一行
// 数据类型需要保持一致。
var a = "hello"
switch a { //如果 switch 没有表达式,则对 true 进行匹配
case "hello": fmt.Println("hello")
case "mum", "daddy": //多个值fmt.Println(2)
default: //只能有一个 default fmt.Println(0)
}switch {case a == "hello": //条件fmt.Println("hello")fallthrough //接着执行下一个 case 不用判断case a != "world":fmt.Println("world")default: //只能有一个 defaultfmt.Println(0)
}
循环 - for
//Go语言中的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构//无限循环 for true
//条件表达式可以被忽略,忽略条件表达式后默认形成无限循环。
var i int
for ; ; i++ { //变量最好在此处for循环中被声明,循环结束不会被销毁,可以当做循环次数使用if i > 10 {break}
}
fmt.Println(i) // i==11//支持 continue 和 break 来控制循环,但是它提供了一个更高级的 break,可以选择中断哪一个循环
rand.Seed(time.Now().UnixNano()) // 设置随机种子,以确保每次运行时都生成不同的随机数序列
OLoop:for j := 0; j < 100; j++ {jint := rand.Intn(10)TLoop:for i := 0; i < 100; i++ {iint := rand.Intn(10)if jint + iint == 4 {fmt.Println("continue OLoop", j, i, jint, iint, jint + iint)continue OLoop //以结束当前循环,开始下一次的循环迭代过程}if jint + iint == 5 {fmt.Println("OLoop", j, i, jint, iint, jint + iint)break OLoop //退出OLoop循环}if jint + iint == 7 {fmt.Println("TLoop", j, i, jint, iint, jint + iint)break TLoop //退出TLoop循环}}
}//goto 退出多层循环 不推荐使用,提升代码理解难度for j := 0; j < 5; j++ {for i := 0; i < 10; i++ {if i > 5 {goto breakHere // 跳转到标签}fmt.Println(i)}}
breakHere:fmt.Println("done")for range 可以遍历数组、切片、字符串、map 及通道(channel),一般形式为:
for key, val := range coll {...
}相关文章:

【GO】学习笔记
目录 学习链接 开发环境 开发工具 GVM - GO多版本部署 GOPATH 与 go.mod go常用命令 环境初始化 编译与运行 GDB -- GNU 调试器 基本语法与字符类型 关键字与标识符 格式化占位符 基本语法 初始值&零值&默认值 变量声明与赋值 _ 下划线的用法 字…...

【TypeScript】ts在vue中的使用
目录 一、Vue 3 TypeScript 1. 项目创建与配置 项目创建 关键配置文件 2.完整项目结构示例 3. 组件 Props 类型定义 4. 响应式数据与 Ref 5. Composition 函数复用 二、组件开发 1.组合式API(Composition API) 2.选项式API(Options…...

2025前端框架最新组件解析与实战技巧:Vue与React的革新之路
作者:飞天大河豚 引言 2025年的前端开发领域,Vue与React依然是开发者最青睐的框架。随着Vue 3的全面普及和React 18的持续优化,两大框架在组件化开发、性能优化、工程化支持等方面均有显著突破。本文将从最新组件特性、使用场景和编码技巧三…...

Elasticsearch 的分布式架构原理:通俗易懂版
Elasticsearch 的分布式架构原理:通俗易懂版 Lucene 和 Elasticsearch 的前世今生 Lucene 是一个功能强大的搜索库,提供了高效的全文检索能力。然而,直接基于 Lucene 开发非常复杂,即使是简单的功能也需要编写大量的 Java 代码&…...

【DeepSeek】【GPT-Academic】:DeepSeek集成到GPT-Academic(官方+第三方)
目录 1 官方deepseek 1.1 拉取学术GPT项目 1.2 安装依赖 1.3 修改配置文件中的DEEPSEEK_API_KEY 2 第三方API 2.1 修改DEEPSEEK_API_KEY 2.2 修改CUSTOM_API_KEY_PATTERM 2.3 地址重定向 2.4 修改模型参数 2.5 成功调用 2.6 尝试添加一个deepseek-r1参数 3 使用千帆…...

2.部署kafka:9092
官方文档:http://kafka.apache.org/documentation.html (虽然kafka中集成了zookeeper,但还是建议使用独立的zk集群) Kafka3台集群搭建环境: 操作系统: centos7 防火墙:全关 3台zookeeper集群内的机器,1台logstash 软件版本: …...

学习路之PHP --TP6异步执行功能 (无需安装任何框架)
学习路之PHP --异步执行功能 (无需安装任何框架) 简介一、工具类二、调用三、异步任务的操作四、效果: 简介 执行异步任务是一种很常见的需求,如批量发邮箱,短信等等执行耗时任务时,需要程序异步执行&…...

Uniapp 小程序复制、粘贴功能实现
在开发 Uniapp 小程序的过程中,复制和粘贴功能是非常实用且常见的交互需求。今天,我就来和大家详细分享如何在 Uniapp 中实现这两个功能。 复制功能:uni.setClipboardData方法 goResult() {uni.setClipboardData({data: this.copyContent, /…...

seacmsv9注入管理员账号密码+orderby+limit
一、seacmsv9 SQL注入漏洞 查看源码 <?php session_start(); require_once("include/common.php"); //前置跳转start $cs$_SERVER["REQUEST_URI"]; if($GLOBALS[cfg_mskin]3 AND $GLOBALS[isMobile]1){header("location:$cfg_mhost$cs");}…...

多通道数据采集和信号生成的模块化仪器如何重构飞机电子可靠性测试体系?
飞机的核心电子系统包括发电与配电系统,飞机内部所有设备和系统之间的内部数据通信系统,以及用于外部通信的射频设备。其他所有航空电子元件都依赖这些关键总线进行电力传输或数据通信。在本文中,我们将了解模块化仪器(无论是PCIe…...
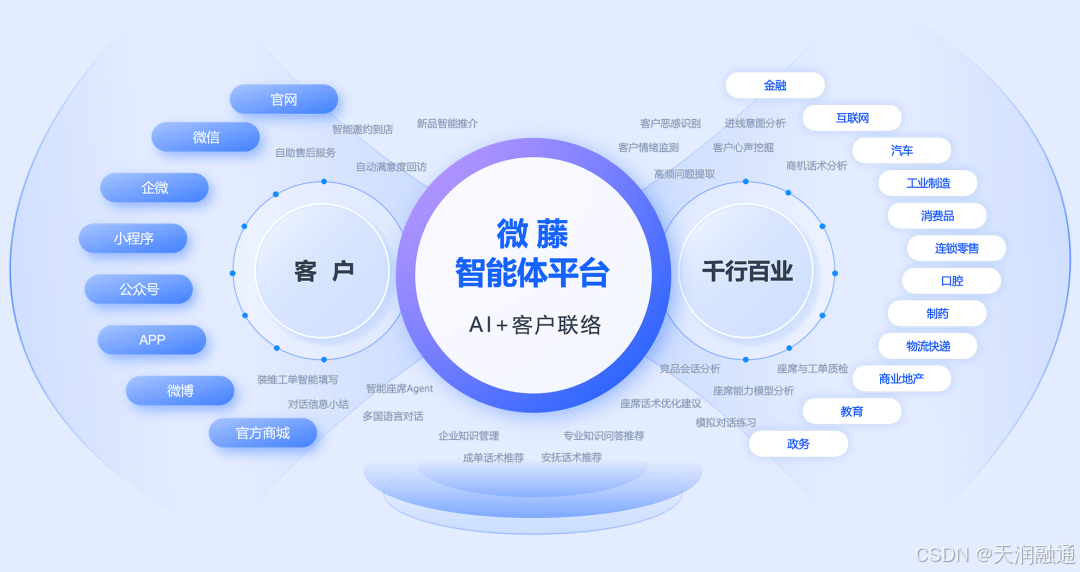
天润融通分析DeepSeek如何一键完成从PR接入,到真正的业务接入
DeepSeek出圈之后,市场上很快掀起了一波DeepSeek接入潮。 在客户服务领域,许多企业见识到DeepSeek的超强能力后,也迅速接入DeepSeek并获得了不错的效果。 比如在客户接待服务场景,有企业将DeepSeek应用到智能问答助手࿰…...

免费PDF工具
Smallpdf.com - A Free Solution to all your PDF Problems Smallpdf - the platform that makes it super easy to convert and edit all your PDF files. Solving all your PDF problems in one place - and yes, free. https://smallpdf.com/#rappSmallpdf.com-解决您所有PD…...

PyTorch 源码学习:GPU 内存管理之它山之石——TensorFlow BFC 算法
TensorFlow 和 PyTorch 都是常用的深度学习框架,各自有一套独特但又相似的 GPU 内存管理机制(BFC 算法)。它山之石可以攻玉。了解 TensorFlow 的 BFC 算法有助于学习 PyTorch 管理 GPU 内存的精妙之处。本文重点关注 TensorFlow BFC 算法的核…...

【学写LibreCAD】1 LibreCAD主程序
一、源码 头文件: #ifndef MAIN_H #define MAIN_H#include<QStringList>#define STR(x) #x #define XSTR(x) STR(x)/*** brief handleArgs* param argc cli argument counter from main()* param argv cli arguments from main()* param argClean a list…...

Android Studio超级详细讲解下载、安装配置教程(建议收藏)
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有…...

CDN与群联云防护的技术差异在哪?
CDN(内容分发网络)与群联云防护是两种常用于提升网站性能和安全的解决方案,但两者的核心目标和技术实现存在显著差异。本文将从防御机制、技术架构、适用场景和代码实现等方面详细对比两者的区别,并提供可直接运行的代码示例。 一…...

故障诊断 | Matlab实现基于DBO-BP-Bagging多特征分类预测/故障诊断
故障诊断 | Matlab实现基于DBO-BP-Bagging多特征分类预测/故障诊断 目录 故障诊断 | Matlab实现基于DBO-BP-Bagging多特征分类预测/故障诊断分类效果基本介绍模型描述DBO-BP-Bagging蜣螂算法优化多特征分类预测一、引言1.1、研究背景和意义1.2、研究现状1.3、研究目的与方法 二…...

Linux-SaltStack配置
文章目录 SaltStack配置 🏡作者主页:点击! 🤖Linux专栏:点击! ⏰️创作时间:2025年02月24日20点51分 SaltStack配置 SaltStack 中既支持SSH协议也支持我们的一个客户端 #获取公钥(…...

内网渗透测试-Vulnerable Docker靶场
靶场来源: Vulnerable Docker: 1 ~ VulnHub 描述:Down By The Docker 有没有想过在容器中玩 docker 错误配置、权限提升等? 下载此 VM,拿出您的渗透测试帽并开始使用 我们有 2 种模式: - HARD:这需要您将 d…...

云计算如何解决延迟问题?
在云计算中,延迟(latency)指的是从请求发出到收到响应之间的时间间隔。延迟过高可能会严重影响用户体验,特别是在需要实时响应的应用中,如在线游戏、视频流、金融交易等。云计算服务如何解决延迟问题,通常依…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...