【大模型系列篇】如何解决DeepSeek-R1结构化输出问题,使用PydanticAl和DeepSeek构建结构化Agent
今日号外:🔥🔥🔥 DeepSeek开源周:炸场!DeepSeek开源FlashMLA,提升GPU效率

下面我们开始今天的主题,deepseek官方明确表示deepseek-r1目前不支持json输出/function call,可点击跳转至deepseek api查看。从deepseek-r1论文《DeepSeek-R1如何通过强化学习有效提升大型语言模型的推理能力》末尾对未来工作的展望中,我们知道deepseek团队将在deepseek-r1的通用能力上继续探索加强,包括函数调用、多轮对话、复杂角色扮演和json输出等任务上的能力。

如何解决DeepSeek-R1结构化输出问题,本文将使用PydanticAl和DeepSeek构建结构化Agent。
安装依赖
pip -q install pydantic-ai
pip -q install nest_asyncio
pip -q install devtools
pip -q install tavily-python# Jupyter环境,启用嵌套的异步事件循环
import nest_asyncio
nest_asyncio.apply()设置搜索Tavily
from tavily import TavilyClient, AsyncTavilyclient
#设置 Tavily客户端
tavily_client = AsyncTavilyClient(api_key=os.environ["TAVILY_API_KEY"])
#简单搜索
response=await tavily_client.search("介绍一下什么是deepseek R1?", max_results=3)
print(response['results'])设置DeepSeek模型
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIModel# DeepSeekV3
deepseek_chat_model = OpenAIModel('deepseek-chat',base_url='https://api.deepseek.com',api_key=os.environ["DEEPSEEK_API_KEY"],)# DeepSeekR1
deepseek_reasoner_model = OpenAIModel('deepseek-reasoner',base_url='https://api.deepseek.com',api_key=os.environ["DEEPSEEK_API_KEY"],)DeepSeekV3模型
首先我们来尝试使用DeepSeekV3模型来完成function call和json格式化输出问题。
from _future import annotations as annotationsimport asyncio
import os
from dataclasses import dataclass
from typing import Anyfrom devtools import debug
from httpx import AsyncClient
import datetime
from pydantic_ai import Agent, ModelRetry, RunContext
from pydantic import BaseModel, Field@dataclass
class SearchDataclass:max_results: inttodays_date:str@dataclass
class ResearchDependencies:todays_date: strclass ResearchResult(BaseModel):research_title:str=Field(description='这是一个顶级Markdown标题,涵盖查询和答案的主题,并以#作为前缀')research_main:str=Field(description='这是一个主要部分,提供查询和研究的答案')research_bullets:str=Field(description='这是一组要点,用于总结查询的答案')## 创建代理
search_agent = Agent(deepseek_chat_model,deps_type=ResearchDependencies,result_type=ResearchResult,system_prompt="你是一个乐于助人的研究助手,并且是研究方面的专家。如果你收到一个问题,你需要写出强有力的关键词来进行总共3-5次搜索(每次都有一个query_number),然后结合结果")@search_agent.tool #Tavily
async def get_search(search_data:RunContext[SearchDataclass],query: str,query_number: int) -> dict[str,Any]"""获取关键词查询的搜索结果。Args:query:要搜索的关键词。"""print(f"Search query {query_number}:{query}")max_results = search_data.deps.max_resultsresults = await tavily_client.get_search_context(query=query, max_results=max_results)return results## 设置依赖项
# 获取当前日期
current_date=datetime.date.today()
# 将日期转换为字符串
date_string = current_date.strftime("%Y-%m-%d")
deps = SearchDataclass(max_results=3, todays_date=date_string)result = await search_agent.run('你能给我用中文详细分析一下 DeepSeekR1模型吗', deps=deps)print(result.data.research_title)
print(result.data.research_main)
print(result.data.research_bullets) DeepSeek-R1模型
class LifeMeaningStructuredResult(BaseModel):life_meaning_title:str = Field(description='这是一个顶级的Markdown标题,涵盖查询的主题和答案,以#开头')life_meaning_main: str = Field(description='这是提供查询和问题答案的主要部分')life_meaning_bullets: str= Field(description='这是一组总结查询答案的要点')##创建代理
reasoner_agent = Agent(deepseek_reasoner_model,deps_type=ResearchDependencies,result_type=LifeMeaningStructuredResult,system_prompt='你是一个有帮助且智慧的推理助手,你擅长思考 如果你被问到一个问题,你会仔细思考,然后回复一个标题、你的思考过程、一组要点总结和一个最终答案')result = await reasoner_agent.run('什么是人工智能?')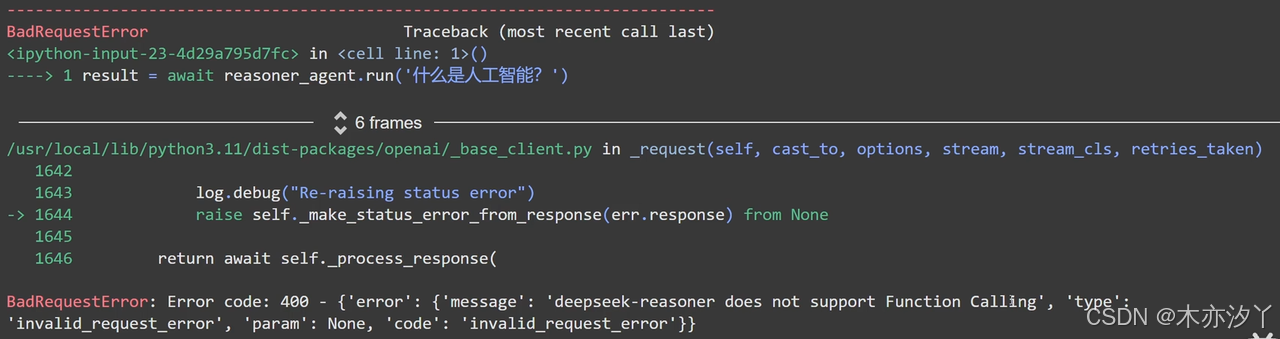
和官方文档描述一致,不支持Function Calling。
方法一、设置第二个LLM帮忙解析并输出
from pydantic_ai import Agentclass LifeMeaningStructuredResult(BaseModel):title:str=Field(description='这是一个顶级的Markdown标题,涵盖查询的主题和答案,以#开头')answer:str=Field(description='这是提供查询和问题答案的主要部分'bullets:str=Field(description='这是一组总结查询答案的要点')thinking:str=Field(description='这是一个字符串,涵盖答案背后的思考过程')##创建代理
reasoner_agent = Agent(deepseek_reasoner_model,# deps_type=ResearchDependencies,# result_type=LifeMeaningStructuredResult,system_prompt='你是一个有帮助且智慧的推理助手,你擅长思考 如果你被问到一个问题,你会仔细思考,然后回复一个标题、你的思考过程、一组要点总结和一个最终答案')result = await reasoner_agent.run('什么是人工智能')from pydantic_ai.models.openai import OpenAIModel
ollama_model = OpenAIModel(model_name='qwen2.5:32b', base_url='http://localhost:11434/v1') formatting_agent = Agent(ollama_model,result_type=LifeMeaningStructuredResult,system_prompt='你是一个有帮助的格式化助手,你从不发表自己的意见你只是接收给定的输入,并将其转换为结构化结果以返回,')structured_results = await formatting_agent.run(result.data)
print(structured_results.data.title)
print(structured_results.data.answer)
print(structured_results.data.bullets)
print(structured_results.data.thinking)方法二、把推理模型当成一个tool
ORCHESTRATOR_PROMPT="""你是一个协调系统,在专用工具之间间进行协调以产生全面的响应。请遵循以下确切顺序,不要跳过:
一旦你有了搜索信息,总是返回到推理模型进行综合1.关键词生成输入:用户查询工具:推理引擎操作:生成3-5个搜索关键词/短语输出格式:{关键词,查询ID}列表2.搜索执行输入:来自步骤1的关键词工具:搜索工具操作:使用每个关键词执行并行搜索输出格式:{查询ID,搜索结果[]}列表3.综合输入:- 原始用户查询- 所有搜索结果工具:推理引擎操作:分析和综合信息,如果你需要更多信息,请要求进行更多搜索输出格式:结构化报告,包含:- 主要发现- 支持证据- 可信度4.响应格式化输入:综合报告操作:格式化为用户友好的响应,包含:- 清晰的章节- 引用- 相关指标输出:最终格式化的响应每个步骤都需要验证:
-验证工具输出是否与预期格式匹配
-记录任何失败的步骤以便重试
-保持信息来源的可追溯性
"""@dataclass
class TaskData:task: str@dataclass
class SearchDataclass:max_results: intclass ReportStructuredResult(BaseModel):title:str=Field(description='这是一个顶级的Markdoown标题,涵盖查询的主题和答案,以#开头')answer:str=Field(description='这是提供查询和问题答案的主要部分')bullets:str=Field(description='这是一组总结查询答案的要点')thinking:str=Field(description='这是一个字符串,涵盖答案背后的思考过程')from pydantic_ai.models.openai import OpenAIModel
ollama_model = OpenAIModel(model_name='qwen2.5:32b', base_url='http://localhost:11434/v1') orchestrator_agent = Agent(ollama_model,result_type=ReportStructuredResult,system_prompt=ORCHESTRATOR_PROMPT)deps = SearchDataclass(max_results=3)SYSTEM PROMPT="""你是一个有帮助且智慧的推理助手,你擅长思考
如果你被问到一个问题,你会仔细思考,然后回复一个标题、
一组要点总结和一个最终答案"""@orchestrator_agent.tool_plain
async def get_reasoning_answers(task: str) -> dict[str, Any]"""获取任何任务的强大推理答案。Args:task:用于推理的任务"""client = OpenAI(api_key=os.environ["DEEPSEEK_API_KEY"] base_url="https://api.deepseek.com")messages = [{"role": "system", "content": SYSTEM PROMPT},{"role": "user", "content": task}]response = client.chat.completions.create(model="deepseek-reasoner", messages=messages)reasoning_content = response.choices[0].message.reasoning_contentcontent = response.choices[0].message.contentformatted_response = "<thinking>" + reasoning_content + "</thinking>" + "\n\n" + contentreturn formatted_response@orchestrator_agent.tool #Tavily
async def get_search(search_data:RunContext[SearchDataclass],query: str, query_number: int) -> dict[str, Any]:"""获取关键词查询的搜索结果。Args:query:要搜索的关键词。"""print(f"Search query {query_number}: {query}")max_results = search_data.deps.max_resultsresults = await tavily_client.get_search_context(query=query, max_results=max_results)return resultsstructured_results = await orchestrator_agent.run("请用P中文为我创建一份关于DeepSeekR1-Zero模型中使用的GRPO、RL的的报告", deps=deps)print(structured_results.data.title)
print(structured_results.data.answer)
print(structured_results.data.bullets)
print(structured_results.data.thinking)
相关文章:
【大模型系列篇】如何解决DeepSeek-R1结构化输出问题,使用PydanticAl和DeepSeek构建结构化Agent
今日号外:🔥🔥🔥 DeepSeek开源周:炸场!DeepSeek开源FlashMLA,提升GPU效率 下面我们开始今天的主题,deepseek官方明确表示deepseek-r1目前不支持json输出/function call,可…...

老旧android项目编译指南(持续更)
原因 编译了很多项目,找到了一些可观的解决办法 1. android studio里面的jdk版本切换 jdk版本切换在这里,一般安卓开发需要用到4个版本的jdk,jdk8, jdk11, jdk17, jdk21新版的android stuio是默认使用高版本的jdk,所以切换版本是很有必要的 2. 命令…...

linux中安装部署Jenkins,成功构建springboot项目详细教程
参考别人配置Jenkins的git地址为https,无法连上github拉取项目,所以本章节介绍通过配置SSH地址来连github拉取项目 目录: 1、springboot项目 1.1 创建名为springcloudproject的springboot项目工程 1.2 已将工程上传到github中,g…...

AI开发利器:Anaconda
在Python开发过程中,不同的项目可能会依赖不同版本的Python以及各种不同版本的库。比如,项目A可能依赖Python 3.8和某个特定版本的numpy、TensorFlow和PyTorch,而项目B可能需要Python 3.9以及另一个版本的numpy库。如果直接在系统中安装Pytho…...

java网络编程--基于TCP协议的网络编程
Scoket介绍 利用 TCP 协议进行通信的两个应用程序是有主次之分的, 一个是服务器程序,一个是客户端程序, 两者的功能和编写方法不太一样, 其中 ServerSocket 类表示 Socket 服务器端,Socket 类表示 Socket 客户端。 服…...

PageHelper新发现
PageHelper 背景解决reasonablepageSizeZero 背景 今天发现了一个很有趣的现象,接手一个很老的项目springmvc项目、使用PageHelper分页实现常见的后端接口分页功能。但是发现当页码参数大于实际的页码数时、正常不应该返回数据,但是目前确一直返回数据不…...
)
Redis 数据结构和使用详解(带示例)
Redis 支持的主要数据结构及其对应操作命令的详细解释,结合具体使用场景和示例: 1. 字符串(String) 用途:存储文本、数值或二进制数据,适用于缓存、计数器等。 常用命令: SET key value&#x…...

深度解读 Chinese CLIP 论文:开启中文视觉对比语言预训练
目录 论文概述1.论文摘要2.论文脑图3.论文创新3.1模型构建3.2训练方法3.3数据构建3.4部署优化 4.模型架构 论文解析1. 引言2. 方法2.1数据说明2.2预训练方法2.2.1模型初始化方法2.2.2两阶段预训练方法 2.3预训练细节2.3.1模型初始化2.3.2第一阶段预训练2.3.3第二阶段预训练2.3.…...

SpringBoot 2 后端通用开发模板搭建(异常处理,请求响应)
目录 一、环境准备 二、新建项目 三、整合依赖 1、MyBatis Plus 数据库操作 2、Hutool 工具库 3、Knife4j 接口文档 4、其他依赖 四、通用基础代码 1、自定义异常 2、响应包装类 3、全局异常处理器 4、请求包装类 5、全局跨域配置 补充:设置新建类/接…...

【Oracle专栏】sqlplus显示设置+脚本常用显示命令
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.内容概述 本文主要针对oracle 运维中常用知识点进行整理,包括: 1)sqlplus模式下,为了方便查询设置相应的行宽、列宽、行数。…...

DeepSeek 助力 Vue3 开发:打造丝滑的页眉(Header)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

JVM线程分析详解
java线程状态: 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。 线程对象创建…...

【备赛】点亮LED
LED部分的原理图 led前面有锁存器,这是为了防止led会受到lcd的干扰(lcd也需要用到这些引脚)。 每次想要对led操作,就需要先打开锁存器,再执行操作,最后关闭锁存器。 这里需要注意的是,引脚配置…...

【音视频】编解码相关概念总结
NALU RTP PS流 三者总体关系 NALU在RTP中的应用:视频流的RTP传输通常将NALU作为基本的单元进行传输。每个RTP包携带一个或多个NALU,这些NALU包含了视频编码数据。RTP协议通过其头部信息(如时间戳、序列号等)帮助接收端重新排列和…...

Python爬虫(四)- Selenium 安装与使用教程
文章目录 前言一、简介及安装1. Selenium 简介2. Selenium 安装 二、Selenium 基本使用1. 导入Selenium2. 启动浏览器3. 打开网页4. 获取页面标题5. 关闭浏览器6. 完整示例代码 三、Selenium WebDriver1. 简介2. 基本操作2.1 启动浏览器2.2 关闭浏览器2.3 打开网页2.4 关闭当前…...

Node.js项目启动流程以及各个模块执行顺序详解
Node.js项目启动流程以及各个模块执行顺序的问题。首先,我需要仔细阅读并理解我搜索到的资料,从中提取关键信息,然后综合这些信息组织成一个结构化的回答。 首先,根据我搜索到的资料都详细描述了Node.js的启动流程,涉及…...

各种类型网络安全竞赛有哪些 网络安全大赛的简称
本文是对入门学习的一些概念了解和一些常规场景记录 1.CTF(capture the flag)是夺旗赛的意思。 是网络安全技术人员之间进行攻防的比赛。 起源1996年DEFCON全球黑客大会,替代之前真实攻击的技术比拼。 (DEFCON极客大会诞生1993,…...

浅谈人工智能与深度学习的应用案例研究
人工智能与深度学习的应用案例研究 人工智能(AI)与深度学习技术正以惊人的速度渗透到社会生活的各个领域,从医疗健康到艺术创作,从金融风控到城市治理,其应用案例不断突破传统边界。以下是近年来具有代表性的六大应用方向及具体案例: 一、医疗健康:精准诊断与药物研发 医…...

vue2版本elementUI的table分页实现多选逻辑
1. 需求 我们需要在表格页上实现多选要求,该表格支持分页逻辑。 2. 认识属性 表格属性 参数说明类型可选值默认值data显示的数据array——row-key行数据的 Key,用来优化 Table 的渲染;在使用 reserve-selection 功能与显示树形数据时&…...

AI数字人技术源码开发分享:革新短视频营销策略
集星幻影的AI数字人分身系统是一款融合了先进人工智能技术的综合性短视频营销解决方案。该系统整合了形象克隆、声音克隆、AI数字人分身生成、智能剪辑及文案创作等功能,旨在为用户打造虚拟人物资产并提供AI驱动的多模态交互服务。以下是该系统的主要功能概述&#…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...
从模糊到电影级景深:Midjourney + Topaz Gigapixel联调方案(含LUT预设包+PSD分层模板)
更多请点击: https://codechina.net 第一章:从模糊到电影级景深:Midjourney Topaz Gigapixel联调方案(含LUT预设包PSD分层模板) 当Midjourney生成的图像存在主体边缘柔化、背景层次缺失或分辨率不足等问题时…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...