一文了解:部署 Deepseek 各版本的硬件要求
很多朋友在咨询关于 DeepSeek 模型部署所需硬件资源的需求,最近自己实践了一部分,部分信息是通过各渠道收集整理,so 仅供参考。

言归正转,大家都知道,DeepSeek 模型的性能在很大程度上取决于它运行的硬件。我们先看一下 DeepSeek 的部分通用版本(如下图),然后再介绍一下最近火热的R1推理版本的各规格的硬件要求。最后,会给出 R1 的各主流版本的资源参考列表(文末)。
| 模型名 | 参数大小 | 文件格式 | 标签 | 公司 |
|---|---|---|---|---|
| deepseek-coder-1.3b-base | 1.3B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-1.3b-instruct | 1.3B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-33B-base | 33B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-33B-instruct | 33B | EXL2 GGUF GPTQ | functions | DeepSeek |
| deepseek-coder-5.7bmqa-base | 7B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-6.7B-base | 7B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-6.7B-instruct | 7B | GGUF GPTQ | DeepSeek | |
| deepseek-llm-67b-base | 67B | GGUF GPTQ | DeepSeek | |
| deepseek-llm-67b-chat | 67B | EXL2 GGUF GPTQ | DeepSeek | |
| deepseek-llm-7B-base | 7B | GGUF GPTQ | DeepSeek | |
| deepseek-llm-7B-chat | 7B | GGUF GPTQ | DeepSeek | |
| deepseek-coder-6.7b-instruct | 7B | EXL2 | DeepSeek |
以下是 4 位量化 DeepSeek 模型的硬件要求:
7B 参数模型
如果您追求的是 7B 模型,那么您需要从两个方面考虑硬件。首先,对于 GPTQ 版本,您需要一块至少有 6GB 显存的不错显卡。GTX 1660 或 2060、AMD 5700 XT 或 RTX 3050 或 3060 都可以很好地工作。但对于 GGML/GGUF 格式,更多的是需要足够的内存。您需要大约 4GB 的空闲内存才能顺利运行。
| 格式 | RAM需求 | VRAM需求 |
|---|---|---|
| GPTQ(GPU推理) | 6GB(加载时交换*) | 6GB |
| GGML / GGUF(CPU推理) | 4GB | 300MB |
| GPTQ和GGML / GGUF的组合(卸载) | 2GB | 2GB |
*加载模型初始所需的内存。推理时不需要。如果您的系统没有足够的内存来在启动时完全加载模型,您可以创建一个 swap 交换文件通过磁盘做为缓存来帮助加载。
30B、33B 和 34B 参数模型
如果您正在进入更大模型的领域,硬件要求会发生明显变化。GPTQ 模型受益于 RTX 3080 20GB、A4500、A5000 等显卡,大约需要 20GB 的显存。相反,GGML 格式的模型将需要您系统内存的很大一部分,接近 20GB。
| 格式 | 内存需求 | 显存需求 |
|---|---|---|
| GPTQ(GPU推理) | 32GB(加载时交换*) | 20GB |
| GGML / GGUF(CPU推理) | 20GB | 500MB |
| GPTQ和GGML / GGUF的组合(卸载) | 10GB | 4GB |
*加载模型初始所需的内存。推理时不需要。如果您的系统没有足够的内存来在启动时完全加载模型,您可以创建一个交换文件来帮助加载。
内存速度
在运行 DeepSeek AI 模型时,您需要关注内存带宽和模型大小对推理速度的影响。这些大型语言模型每次生成一个新标记(一段文本)时都需要完全加载到内存或显存中。例如,一个 4 位 7B 参数的 DeepSeek 模型大约占用 4.0GB 的内存。
假设您有 Ryzen 5 5600X 处理器和 DDR4-3200 内存,理论最大带宽为 50 GBps。在这种情况下,您可以期望每秒生成大约 9 个标记。通常,由于推理软件、延迟、系统开销和工作负载特性等几个限制因素,这种性能大约是您理论最大速度的 70%,这些因素阻止了达到峰值速度。为了达到更高的推理速度,比如每秒 16 个标记,您需要更多的带宽。例如,一个具有 DDR5-5600 的系统,大约提供 90 GBps 的带宽,就足够了。
相比之下,高端显卡如 Nvidia RTX 3090 的显存带宽接近 930 GBps。DDR5-6400 内存可以提供高达 100 GB/s 的带宽。因此,理解和优化带宽对于高效运行 DeepSeek 等模型至关重要。
CPU 要求
为了获得最佳性能,建议使用现代多核 CPU。从第 8 代起的 Intel Core i7 或从第 3 代起的 AMD Ryzen 5 都可以很好地工作。具有 6 核或 8 核的 CPU 是理想的。更高的时钟速度还可以提高提示处理速度,因此目标是 3.6GHz 或更高。
如果可用,具有 AVX、AVX2、AVX-512 等 CPU 指令集可以进一步提高性能。关键是拥有一台相对现代的消费级 CPU,具有不错的核数和时钟速度,以及通过 AVX2 进行基本向量处理(使用 llama.cpp 进行 CPU 推理所需的)。有了这些规格,CPU 应该能够处理 DeepSeek 模型的大小。
DeepSeek R1 小型、中型和大型模型配置需求
如果你正考虑在本地家用电脑或笔记本上运行新的 DeepSeek R1 AI 推理模型,你可能会想了解运行小型、中型和大型 AI DeepSeek 模型所需的硬件需求。DeepSeek R1 是一个可扩展的 AI 模型,旨在满足从轻量级任务到企业级操作的广泛应用需求。
根据你打算部署的模型大小,其硬件需求差异显著,从小型 15 亿参数版本到庞大的 6710 亿参数模型,了解这些需求对于实现最佳性能和资源效率至关重要。
关键要点:
-
DeepSeek R1 提供可扩展的 AI 模型,硬件需求根据模型大小差异显著,从 15 亿到 6710 亿参数。
-
较小的模型(15 亿)非常易于使用,仅需 CPU、8GB 内存,无需专用 GPU,而稍大一些的模型(70 亿-80 亿)从至少 8GB 显存的 GPU 中受益,性能更快。
-
中型模型(140 亿-320 亿)需要 12GB-24GB 显存的 GPU,以实现最佳性能,平衡资源需求和计算效率。
-
较大的模型(700 亿-6710 亿)需要高端硬件,包括 48GB 显存的 GPU 或多 GPU 配置(例如 20 张 Nvidia RTX 3090 或 10 张 Nvidia RTX A6000),用于企业级应用。
-
高效部署取决于将模型大小与可用资源对齐,确保可扩展性,并为大型设置规划电源、散热和硬件兼容性。
DeepSeek R1 在设计时考虑了可扩展性,提供了从轻量级任务到企业级操作的各种选项。但随着模型大小的增长,硬件需求也随之增加,了解你的系统在其中的位置是关键。
小型模型:易于使用且轻量级
DeepSeek R1 的 15 亿参数版本设计得非常易于使用,硬件需求 minimal。这使其成为拥有标准计算设置的用户的绝佳选择。要有效运行此模型,你需要:
-
不超过 10 年的 CPU
-
至少 8GB 内存
-
无需专用 GPU 或显存
这种配置非常适合那些优先考虑简单性和成本效率而非处理速度的用户。然而,如果你计划使用稍大一些的模型,如 70 亿或 80 亿版本,需求会适度增加。虽然这些模型仍然可以在仅 CPU 的系统上运行,但性能可能会较慢。为了提高速度和效率,考虑使用至少 8GB 显存的 GPU。这允许模型使用并行处理,显著提高计算时间。
中型模型:寻求平衡
对于中型模型,如 140 亿和 320 亿版本,硬件需求变得更加 substantial,反映了它们增加的计算复杂性。这些模型在性能和资源需求之间取得了平衡,使其适合拥有中等 advanced 硬件设置的用户。以下是你需要的:
-
140 亿模型: 需要至少 12GB 显存的 GPU,虽然 16GB 更推荐,以实现更平稳的运行并容纳额外的进程。
-
320 亿模型: 至少需要 24GB 显存才能实现最佳的 GPU 性能。显存较少的系统仍然可以运行模型,但工作负载将分布在 GPU、CPU 和内存之间,导致处理速度较慢。
这些中型模型非常适合需要计算能力与资源可用性之间平衡的用户。然而,与小型模型相比,它们需要更 robust 的硬件,特别是如果你旨在保持高效的处理时间。
大规模模型:高级应用的高端硬件
随着你扩展到更大的模型,如 700 亿和 6710 亿版本,硬件需求显著增加。这些模型专为 advanced 应用而设计,通常在企业或研究环境中,高端硬件是必需的。以下是这些大规模模型的需求:
-
700 亿模型: 需要 48GB 显存的 GPU 才能实现无缝运行。显存较少的系统将体验到较慢的性能,因为计算将卸载到 CPU 和内存。
-
6710 亿模型: 这个模型代表了 DeepSeek R1 可扩展性的上限,需要大约 480GB 显存。多 GPU 配置是必需的,例如:
-
20 张 Nvidia RTX 3090 GPU(每张 24GB)
-
10 张 Nvidia RTX A6000 GPU(每张 48GB)
-
这些配置通常保留给拥有 substantial 计算资源的企业级应用或研究机构。
部署这些大规模模型不仅需要高端 GPU,还需要仔细规划电源供应、散热系统和硬件兼容性。确保你的基础设施能够处理增加的负载对于保持操作效率至关重要。
高效 AI 部署的关键因素
为 DeepSeek R1 选择合适的硬件涉及将模型大小与可用资源和未来目标对齐。以下是一些关键考虑因素:
-
小型模型: 这些模型只需要标准硬件,使其能够被拥有 basic 设置的大多数用户使用。
-
中型模型: 这些模型从具有适度显存容量的 GPU 中显著受益,提高了性能并减少了处理时间。
-
大型模型: 这些模型需要高端 GPU 或多 GPU 配置,以及 robust 的电源和散热系统,以确保平稳运行。
-
可扩展性: 如果你预计将来会升级到更大的模型,确保你的硬件设置是可扩展的,并且能够容纳增加的需求。
对于多 GPU 配置,验证 GPU 之间的兼容性并确保你的系统能够处理增加的计算负载是 essential 的。此外,在规划硬件投资时,考虑与电源消耗和散热相关的长期成本。
有效部署 DeepSeek R1
DeepSeek R1 的硬件需求反映了其可扩展性和适应性,满足了 diverse 的用例需求。小型模型对于拥有标准硬件的用户来说是易于使用的,提供了简单性和成本效率。中型模型在性能和资源需求之间提供了平衡,而大型模型需要为 enterprise 或研究级应用设计的 advanced 设置。通过理解这些需求并将其与你的特定需求对齐,你可以有效地部署 DeepSeek R1,确保最佳性能和资源利用。如果只想CPU本地部署,请参考《本地使用CPU快速体验DeepSeek R1》。
下面给出各主要模型的的参考部署配置(由GPUStack社区提供):
| 模型名称 | 上下文大小 | 显存需求 | 推荐的GPU配置 |
|---|---|---|---|
| R1-Distill-Qwen-1.5B (Q4_K_M) | 32K | 2.86 GiB | RTX 4060 8GB x 1 |
| R1-Distill-Qwen-1.5B (Q8_0) | 32K | 3.47 GiB | RTX 4060 8GB x 1 |
| R1-Distill-Qwen-1.5B (FP16) | 32K | 4.82 GiB | RTX 4060 8GB x 1 |
| R1-Distill-Qwen-7B (Q4_K_M) | 32K | 7.90 GiB | RTX 4070 12GB x 1 |
| R1-Distill-Qwen-7B (Q8_0) | 32K | 10.83 GiB | RTX 4080 16GB x 1 |
| R1-Distill-Qwen-7B (FP16) | 32K | 17.01 GiB | RTX 4090 24GB x 1 |
| R1-Distill-Llama-8B (Q4_K_M) | 32K | 10.64 GiB | RTX 4080 16GB x 1 |
| R1-Distill-Llama-8B (Q8_0) | 32K | 13.77 GiB | RTX 4080 16GB x 1 |
| R1-Distill-Llama-8B (FP16) | 32K | 20.32 GiB | RTX 4090 24GB x 1 |
| R1-Distill-Qwen-14B (Q4_K_M) | 32K | 16.80 GiB | RTX 4090 24GB x 1 |
| R1-Distill-Qwen-14B (Q8_0) | 32K | 22.69 GiB | RTX 4090 24GB x 1 |
| R1-Distill-Qwen-14B (FP16) | 32K | 34.91 GiB | RTX 4090 24GB x 2 |
| R1-Distill-Qwen-32B (Q4_K_M) | 32K | 28.92 GiB | RTX 4080 16GB x 2 |
| R1-Distill-Qwen-32B (Q8_0) | 32K | 42.50 GiB | RTX 4090 24GB x 3 |
| R1-Distill-Qwen-32B (FP16) | 32K | 70.43 GiB | RTX 4090 24GB x 4 |
| R1-Distill-Llama-70B (Q4_K_M) | 32K | 53.41 GiB | RTX 4090 24GB x 5 |
| R1-Distill-Llama-70B (Q8_0) | 32K | 83.15 GiB | A100 80GB x 1 |
| R1-Distill-Llama-70B (FP16) | 32K | 143.83 GiB | A100 80GB x 2 |
| R1-671B (UD-Q1_S) | 32K | 225.27 GiB | A100 80GB x 4 |
| R1-671B (UD-Q1_M) | 32K | 251.99 GiB | A100 80GB x 4 |
| R1-671B (UD-Q2_XXS) | 32K | 277.36 GiB | A100 80GB x 5 |
| R1-671B (UD-Q2_K_XL) | 32K | 305.71 GiB | A100 80GB x 5 |
| R1-671B (Q2_K_XS) | 32K | 300.73 GiB | A100 80GB x 5 |
| R1-671B (Q2_K / Q2_K_L) | 32K | 322.14 GiB | A100 80GB x 6 |
| R1-671B (Q3_K_M) | 32K | 392.06 GiB | A100 80GB x 7 |
| R1-671B (Q4_K_M) | 32K | 471.33 GiB | A100 80GB x 8 |
| R1-671B (Q5_K_M) | 32K | 537.31 GiB | A100 80GB x 9 |
| R1-671B (Q6_K) | 32K | 607.42 GiB | A100 80GB x 11 |
| R1-671B (Q8_0) | 32K | 758.54 GiB | A100 80GB x 13 |
| R1-671B (FP8) | 32K | 805.2 GB | H200 141GB x 8 |
建议:
-
对于最佳性能: 选择一台配备高端显卡(如 NVIDIA 最新的 RTX 3090 或 RTX 4090)或双显卡配置的机器,以适应最大的模型(65B 和 70B)。具有足够内存(最低 16GB,但 64GB 最好)的系统将是最佳选择。
-
对于预算限制: 如果您的预算有限,专注于适合系统内存的 Deepseek GGML/GGUF 模型。记住,虽然您可以将一些权重卸载到系统内存中,但这会带来性能成本。
当然,实际性能将取决于几个因素,包括具体任务、模型实现和其他系统进程。
参考资料:
1.https://github.com/deepseek-ai/DeepSeek-R1
2.https://www.geeky-gadgets.com/hardware-requirements-for-deepseek-r1-ai-models/
3.https://www.hardware-corner.net/llm-database/Deepseek/
相关文章:
一文了解:部署 Deepseek 各版本的硬件要求
很多朋友在咨询关于 DeepSeek 模型部署所需硬件资源的需求,最近自己实践了一部分,部分信息是通过各渠道收集整理,so 仅供参考。 言归正转,大家都知道,DeepSeek 模型的性能在很大程度上取决于它运行的硬件。我们先看一下…...

有没有什么免费的AI工具可以帮忙做简单的ppt?
互联网各领域资料分享专区(不定期更新): Sheet 正文 1. 博思AIPPT 特点:专为中文用户设计,支持文本/文件导入生成PPT,内置海量模板和智能排版功能,涵盖商务、教育等多种场景。可一键优化布局、配色,并集成AI绘图功能(文生图/图生图)。适用场景:职场汇报、教育培训、商…...

python绘图之灰度图
灰度图(Gray Scale Image)是一种将图像中的像素值映射到灰度范围(通常是0到255)的图像表示方式。它在图像处理和计算机视觉中具有重要作用.本节学习使用python绘制灰度图 # 导入必要的库 import numpy as np import matplotlib.py…...

华为 VRP 系统简介配置SSH,TELNET远程登录
华为 VRP 系统简介&配置SSH/TELNET远程登录 1.华为 VRP 系统概述 1.1 什么是 VRP VRP(Versatile Routing Platform 华为数通设备操作系统)是华为公司数据通信产品的通用操作系统平台,从低端到核心的全系列路由器、以太网交换机、业务网…...
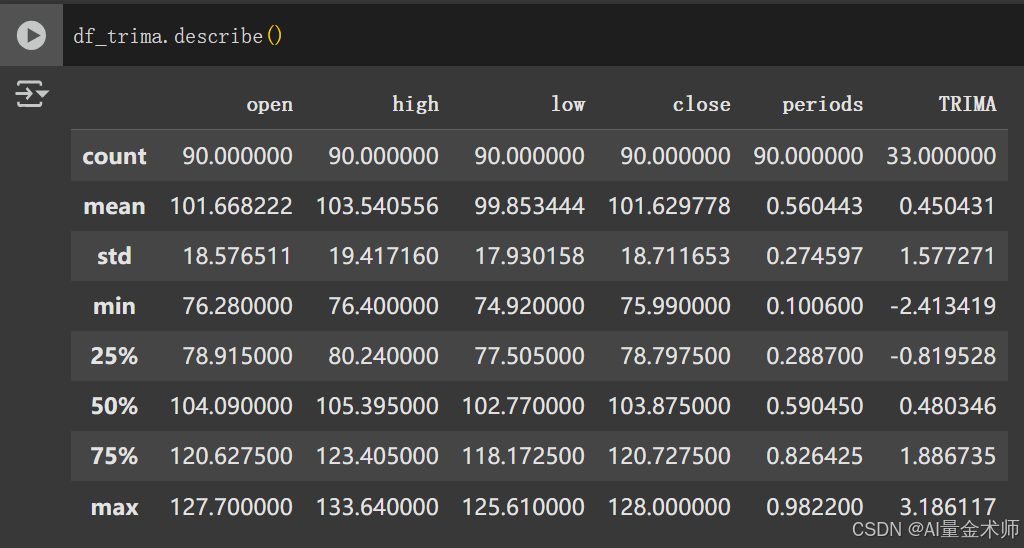
1.14 重叠因子:TRIMA三角移动平均线(Triangular Moving Average, TRIMA)概念与Python实战
目录 0. 本栏目因子汇总表1. 因子简述2. 因子计算逻辑3. 因子应用场景4. 因子优缺点5. 因子代码实现6. 因子取值范围及其含义7. 因子函数参数建议 0. 本栏目因子汇总表 【量海航行】 1. 因子简述 三角移动平均线(Triangular Moving Average, TRIMA)是一种特殊的加权移动平均…...

【tplink】校园网接路由器如何单独登录自己的账号,wan-lan和lan-lan区别
老式路由器TPLINK,接入校园网后一人登录,所有人都能通过连接此路由器上网,无法解决遂上网搜索,无果,幸而偶然看到一个帖子说要把信号源网线接入路由器lan口,开启新世界。 一、wan-lan,lan-lan区…...

PC 端连接安卓手机恢复各类数据:安装、操作步骤与实用指南
软件介绍 这款用于恢复安卓手机数据的软件,虽运行在 PC 端,却专为安卓手机数据恢复打造,使用时得用数据线把手机和电脑连接起来。它的功能相当强大,能帮你找回安卓手机里已删除的短信、联系人、通话记录、文档,还有照…...

【折线图 Line】——1
🌟 解锁数据可视化的魔法钥匙 —— pyecharts实战指南 🌟 在这个数据为王的时代,每一次点击、每一次交易、每一份报告背后都隐藏着无尽的故事与洞察。但你是否曾苦恼于如何将这些冰冷的数据转化为直观、吸引人的视觉盛宴? 🔥 欢迎来到《pyecharts图形绘制大师班》 �…...

SpringBoot 整合mongoDB并自定义连接池,实现多数据源配置
要想在同一个springboot项目中使用多个数据源,最主要是每个数据源都有自己的mongoTemplate和MongoDbFactory。mongoTemplate和MongoDbFactory是负责对数据源进行交互的并管理链接的。 spring提供了一个注解EnableMongoRepositories 用来注释在某些路径下的MongoRepo…...

TCP/IP的分层结构、各层的典型协议,以及与ISO七层模型的差别
1. TCP/IP的分层结构 TCP/IP模型是一个四层模型,主要用于网络通信的设计和实现。它的分层结构如下: (1) 应用层(Application Layer) 功能:提供应用程序之间的通信服务,处理特定的应用细节。 典型协议&am…...

FreeRTOS-中断管理
实验目的 创建一个队列及一个任务,按下按键 KEY1 触发中断,在中断服务函数里向队列里发送数据,任务则阻塞接 收队列数据。 实验代码 实验结果 这样就实现了,使用中断往队列的发送信息,用任务阻塞接收信息...

ShenNiusModularity项目源码学习(15:ShenNius.Admin.API项目分析)
ShenNius.Admin.Mvc项目是MVC模式的入口,ShenNius.Admin.Hosting项目是前后端分离模式的后台服务入口,这两个项目都依赖ShenNius.Admin.API项目,前者使用ShenniusAdminApiModule类注册服务及配置管道,而后者的webapi实现都在ShenN…...

Express + MongoDB 实现文件上传
使用 multer 中间件来处理文件上传,同时将文件的元数据存储到 MongoDB 中。 一、安装依赖 npm install multer 二、核心代码 // 定义文件模型const fileSchema new mongoose.Schema({originalname: String,mimetype: String,size: Number,path: String,});cons…...

计算机毕业设计SpringBoot+Vue.js作业管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

Odoo免费开源CRM技术实战:从商机线索关联转化为售后工单的应用
文 / 开源智造 Odoo金牌服务 Odoo:功能强大且免费开源的CRM Odoo 引入了一种高效的客户支持管理方式,即将 CRM 线索转换为服务台工单。此功能确保销售和支持团队能够无缝协作,从而提升客户满意度并缩短问题解决时间。通过整合 CRM 模块与服…...

2025年如何实现安卓、iOS、鸿蒙跨平台开发
2025年如何实现安卓、iOS、鸿蒙跨平台开发 文章目录 2025年如何实现安卓、iOS、鸿蒙跨平台开发1. 使用统一开发框架2. 华为官方工具链支持3. 代码适配策略4. 生态兼容性处理5. 性能与体验优化总结:方案选择建议 本文首发地址 https://h89.cn/archives/324.html 最新…...

萌新学 Python 之 os 模块
os 模块:主要提供程序与操作系统进行交互的接口 先导入模块:import os 1. os.listdir(),获取当前目录的文件,返回到列表中 2. os.mkdir(文件目录, mode 0o777),创建目录,777 表示读写程序 在当前目录下…...

IPoIB源码深度解析:如何基于TCP/IP协议栈实现高性能InfiniBand通信
一、IPoIB的核心设计理念 IPoIB(IP over InfiniBand)是一种在InfiniBand网络上承载IP流量的技术,其核心目标是在不修改上层应用的前提下,利用InfiniBand的高带宽和低延迟特性。与自定义协议栈不同,IPoIB通过深度集成到Linux内核TCP/IP协议栈中,将InfiniBand设备抽象为标…...

本地部署阿里万象2.1文生视频模型(Wan2.1-T2V)完全指南
在生成式AI技术爆发式发展的今天,阿里云开源的万象2.1(Wan2.1)视频生成模型,为创作者提供了从文字/图像到高清视频的一站式解决方案。本文针对消费级显卡用户,以RTX 4060 Ti 16G为例,详解本地部署全流程与性能调优方案,涵盖环境配置、多模型选择策略、显存优化技巧及实战…...

information_schema.processlist 表详解
information_schema.processlist 表(或 SHOW PROCESSLIST; 命令)用于查看 MySQL 当前所有的连接进程,帮助管理员监控数据库活动并排查性能问题。以下是该表的字段及其具体含义: 🔹 information_schema.processlist 字段…...

随机森林与Busy函数在天文光谱分类中的实战应用
1. 项目概述:当随机森林遇见宇宙光谱在射电天文学的前沿,我们每天都在与来自宇宙深处的海量数据打交道。其中,中性氢原子在21厘米波长处产生的吸收线,就像宇宙气体的“指纹”,是探测星系中冷气体分布、运动状态以及星系…...
)
ChatGPT绘画提示词生成效率革命(92%设计师不知道的5层语义嵌套法)
更多请点击: https://kaifayun.com 第一章:ChatGPT绘画提示词生成效率革命(92%设计师不知道的5层语义嵌套法) 传统提示词工程常陷于“关键词堆砌”误区,而真正高阶的生成控制源于语义结构的纵深组织。5层语义嵌套法将…...
)
手把手教你解锁影驰B360M主板隐藏的fTPM 2.0,绕过限制升级Win11(附BIOS修改避坑指南)
解锁影驰B360M主板fTPM 2.0的完整实战手册当Windows 11的升级提示弹出时,许多使用影驰B360M主板的用户发现自己的设备被系统要求拒之门外——原因很简单:主板BIOS中缺少必要的fTPM 2.0支持选项。这并非硬件不支持,而是厂商在固件层面隐藏了相…...

iOS真机动态分析CCMD5签名算法的Frida实战指南
1. 这不是“破解”,而是 iOS 应用安全分析中的一次标准算法溯源实践你打开一个金融类 App,登录后点击“提交交易”,界面上只显示“处理中…”——3 秒后,请求发出,服务端返回 success。但没人告诉你,这 3 秒…...

ARM SME指令集:矩阵运算加速与AI应用实践
1. SME指令集概述:矩阵运算的加速引擎在现代处理器架构中,SIMD(Single Instruction Multiple Data)技术早已成为性能优化的关键手段。作为ARMv9架构的重要扩展,SME(Scalable Matrix Extension)指…...
)
MacBook锁屏别慌!手把手教你用恢复模式+Apple ID重置开机密码(保姆级图文)
MacBook锁屏急救指南:3种安全解锁方案详解刚泡好的咖啡还在冒热气,手指悬在键盘上方却突然僵住——那个每天输入几十次的密码,此刻竟怎么也想不起来了。MacBook屏幕上冰冷的"密码错误"提示像一堵墙,将你与所有工作资料、…...

从背包UI到聊天框:详解Unity ScrollRect在不同游戏场景下的实战应用与优化
从背包UI到聊天框:Unity ScrollRect全场景实战指南在RPG游戏的背包界面滑动查看装备,在社交系统中翻阅聊天记录,或是横向浏览角色画廊——这些看似不同的交互背后,都依赖同一个核心组件:Unity的ScrollRect。作为UGUI体…...

别急着重装系统!记一次 Ubuntu 22.04 上 gcc 与 cpp 版本依赖冲突的排查与修复实录
从依赖地狱到编译自由:Ubuntu 22.04下gcc与cpp版本冲突的深度修复指南那天下午,当我正准备为新的C项目搭建开发环境时,终端里那行刺眼的红色错误提示让我的咖啡瞬间不香了。作为一个自诩"Linux老司机"的开发者,我没想到…...

兆赫兹X射线光子相关光谱技术原理与应用
1. 兆赫兹X射线光子相关光谱技术概述X射线光子相关光谱(XPCS)作为研究软物质动态特性的重要工具,其核心原理是通过分析相干X射线散射形成的散斑图样随时间的变化来揭示纳米尺度的动力学过程。这项技术的独特之处在于能够探测传统光学方法难以…...

差分隐私生成模型实战:从理论保障到隐私攻击与审计评估
1. 项目概述与核心挑战在医疗健康、社会科学研究以及政府统计等领域,处理包含个人敏感信息的表格数据是一项常态。这些数据是宝贵的研究资源,但其使用受到严格的隐私法规(如GDPR、HIPAA等)的约束。传统的数据脱敏或匿名化方法&…...