SpringBatch简单处理多表批量动态更新
项目需要处理一堆表,这些表数据量不是很大都有经纬度信息,但是这些表的数据没有流域信息,需要按经纬度信息计算所属流域信息。比较简单的项目,按DeepSeek提示思索完成开发,AI真好用。
阿里AI个人版本IDEA安装
IDEA中使用DeepSeek满血版的手把手教程来了!

代码实现
1、controller
/*** 批量流域处理任务*/
@Tag(name = "批量流域处理任务")
@ApiSupport(order = 2)
@RequestMapping("/job")
@RestController
public class SysBatchJobController {@AutowiredJobLauncher jobLauncher;@AutowiredJobOperator jobOperator;@Autowired@Qualifier("updateWaterCodeJob")private Job updateWaterCodeJob;// 多线程分页更新数据@GetMapping("/asyncJob")public void asyncJob() throws Exception {JobParameters jobParameters = new JobParametersBuilder().addLong("time",System.currentTimeMillis()).toJobParameters();JobExecution run = jobLauncher.run(updateWaterCodeJob, jobParameters);run.getId();}}2、批量处理表
/*** 需要批量处理的业务表信息*/
@Builder
@AllArgsConstructor
@Data
@TableName(value = "ads_t_sys_batch_update_table")
public class SysBatchUpdateTable extends BaseEntity implements Serializable {private static final long serialVersionUID = -7367871287146067724L;@TableId(type = IdType.ASSIGN_UUID)private String pkId;/*** 需要更新的表名**/@TableField(value = "table_name")private String tableName;/*** 所需更新表所在数据库ID**/@TableField(value = "data_source_id")private String dataSourceId;/*** 表对应的主键字段**/@TableField(value = "key_id")private String keyId;/*** 表对应的流域字段**/@TableField(value = "water_code_column")private String waterCodeColumn;/*** 表对应的经度字段**/@TableField(value = "lon_column")private String lonColumn;/*** 表对应的纬度字段**/@TableField(value = "lat_column")private String latColumn;public SysBatchUpdateTable() {}}3、Mapper,传递参数比较麻烦,可以考虑将参数动态整合到sql里面构造
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.bigdatacd.panorama.system.domain.po.SysBatchUpdateTable;
import org.apache.ibatis.annotations.Mapper;import java.util.List;
import java.util.Map;@Mapper
public interface UpdateTableMapper extends BaseMapper<SysBatchUpdateTable> {/*** 根据表名分页查询数据* @param tableName 表名* @return*/List<Map<String, Object>> selectUpdateTableByPage(String tableName);/*** 更新数据* @param tableName 表名* @param waterCode 流域编码* @param pkId 表主键ID*/void updateWaterCode(String tableName,String waterCode,String pkId);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bigdatacd.panorama.system.mapper.UpdateTableMapper"><!-- 动态分页查询通过#和$区别动态构造更新所需参数 --><select id="selectUpdateTableByPage" resultType="java.util.HashMap"><!--如果有分页查询就直接使用分页查询sql-->SELECT${keyId} as pkId,#{keyId} as keyId,${waterCodeColumn} as waterCode,#{waterCodeColumn} as waterCodeColumn,${lonColumn} as lon,${latColumn} as lat,#{tableName} as tableNameFROM ${tableName} a where ${waterCodeColumn} is nullORDER BY ${keyId} <!-- 确保分页顺序 -->LIMIT #{_pagesize} OFFSET #{_skiprows}</select><!-- 动态更新 --><update id="updateWaterCode">UPDATE ${tableName}SET ${waterCodeColumn} = #{waterCode}WHERE ${keyId} = #{pkId} <!-- 假设主键为id --></update>
</mapper>
4、配置文件
Springbatch:job:enabled: false #启动时不启动jobjdbc:initialize-schema: always sql:init:schema-locations: classpath:/org/springframework/batch/core/schema-mysql.sql 数据源url加个批处理参数rewriteBatchedStatements=trueurl: jdbc:mysql://localhost:3306/xxxx?autoReconnect=true&useUnicode=true&createDatabaseIfNotExist=true&characterEncoding=utf8&&serverTimezone=GMT%2b8&useSSL=false&rewriteBatchedStatements=true5、主配置类调整(按表分区)
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.batch.MyBatisPagingItemReader;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.step.skip.AlwaysSkipItemSkipPolicy;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.HashMap;
import java.util.Map;// 1. 主配置类调整(按表分区)
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate SqlSessionFactory sqlSessionFactory;/*** 主任务** @return*/@Bean("updateWaterCodeJob")public Job updateWaterCodeJob(@Qualifier("masterStep") Step masterStep) {return jobBuilderFactory.get("updateWaterCodeJob").start(masterStep).build();}@Bean("masterStep")public Step masterStep(@Qualifier("updateBatchTableData") Step updateBatchTableData,@Qualifier("multiTablePartitioner") MultiTablePartitioner multiTablePartitioner) {return stepBuilderFactory.get("masterStep").partitioner(updateBatchTableData.getName(), multiTablePartitioner) // 分区器按表名分区一个表一个分区.step(updateBatchTableData).gridSize(10) // 按表分区了 并发数一般设置为核心数.taskExecutor(taskExecutor()).listener(new BatchJobListener()).build();}// 线程池配置(核心线程数=表数量)@Bean("batchTaskExecutor")public TaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(5);executor.setMaxPoolSize(10);executor.setThreadNamePrefix("table-processor-");return executor;}/*** 处理分页数据更新步骤* @return*/@Bean("updateBatchTableData")public Step updateBatchTableData(@Qualifier("dynamicTableReader") MyBatisPagingItemReader<Map<String, Object>> myBatisPagingItemReader,@Qualifier("batchUpdateWriter") BatchUpdateWriter batchUpdateWriter,@Qualifier("tableProcessor") TableProcessor tableProcessor) {return stepBuilderFactory.get("updateBatchTableData").<Map<String, Object>, Map<String, Object>>chunk(100).reader(myBatisPagingItemReader).processor(tableProcessor).writer(batchUpdateWriter).faultTolerant().skipPolicy(new AlwaysSkipItemSkipPolicy()).build();}/*** 分页获取需要更新的表数据* @return*/@Bean@StepScopepublic MyBatisPagingItemReader<Map<String, Object>> dynamicTableReader(@Value("#{stepExecutionContext['keyId']}") String keyId, //需要更新的表ID字段@Value("#{stepExecutionContext['waterCodeColumn']}") String waterCodeColumn,// 需要更新的流域字段@Value("#{stepExecutionContext['lonColumn']}") String lonColumn,// 经度纬度字段@Value("#{stepExecutionContext['latColumn']}") String latColumn,// 经度纬度字段@Value("#{stepExecutionContext['tableName']}") String tableName // 需要更新的表名) {MyBatisPagingItemReader<Map<String, Object>> reader = new MyBatisPagingItemReader<>();reader.setSqlSessionFactory(sqlSessionFactory);reader.setQueryId("com.bigdatacd.panorama.system.mapper.UpdateTableMapper.selectUpdateTableByPage");Map<String,Object> param = new HashMap<>();param.put("keyId",keyId);param.put("waterCodeColumn",waterCodeColumn);param.put("lonColumn",lonColumn);param.put("latColumn",latColumn);param.put("tableName",tableName);reader.setParameterValues(param);reader.setPageSize(2000);return reader;}}import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemWriter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.stereotype.Component;import java.util.List;
import java.util.Map;// 批量更新Writer
@Component("batchUpdateWriter")
@StepScope
public class BatchUpdateWriter implements ItemWriter<Map<String, Object>> {@Autowiredprivate NamedParameterJdbcTemplate jdbcTemplate;@Overridepublic void write(List<? extends Map<String, Object>> items) {// 构造动态sql更新数据StringBuilder sb = new StringBuilder();sb.append("UPDATE ");sb.append((String) items.get(0).get("tableName"));sb.append(" SET ");sb.append((String) items.get(0).get("waterCodeColumn"));sb.append(" = :waterCode");sb.append(" WHERE ");sb.append((String) items.get(0).get("keyId"));sb.append(" = :pkId");jdbcTemplate.batchUpdate(sb.toString(), items.stream().map(item -> new MapSqlParameterSource().addValue("waterCode", item.get("waterCode")).addValue("tableName", item.get("tableName")).addValue("waterCodeColumn", item.get("waterCodeColumn")).addValue("keyId", item.get("keyId")).addValue("pkId", item.get("pkId"))).toArray(SqlParameterSource[]::new));}
}import javax.sql.DataSource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Component
@Slf4j
public class MultiTablePartitioner implements Partitioner {private final DataSource dataSource;public MultiTablePartitioner(DataSource dataSource) {this.dataSource = dataSource;}@Overridepublic Map<String, ExecutionContext> partition(int gridSize) {JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);String sql = "SELECT key_id as keyId,water_code_column as waterCodeColumn,lon_column as lonColumn,lat_column as latColumn,page_sql as pageSql,table_name as tableName FROM ads_t_sys_batch_update_table where deleted = 0 and data_status = '0'";List<Map<String,Object>> tables = jdbcTemplate.queryForList(sql);log.info("查询" + sql);Map<String, ExecutionContext> partitions = new HashMap<>();for (int i = 0; i < tables.size(); i++) {ExecutionContext ctx = new ExecutionContext();// 将需要传递的参数放到上下文中,用于动态批量更新的sql用ctx.putString("keyId", String.valueOf(tables.get(i).get("keyId")));ctx.putString("waterCodeColumn", String.valueOf(tables.get(i).get("waterCodeColumn")));ctx.putString("lonColumn", String.valueOf(tables.get(i).get("lonColumn")));ctx.putString("latColumn", String.valueOf(tables.get(i).get("latColumn")));//ctx.putString("pageSql", String.valueOf(tables.get(i).get("pageSql")));ctx.putString("tableName", String.valueOf(tables.get(i).get("tableName")));partitions.put("partition" + i, ctx);}return partitions;}
}import com.bigdatacd.panorama.common.utils.GeoJsonUtil;
import lombok.Builder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;import java.util.Map;// 处理数据的经纬度所在流域
@Component("tableProcessor")
@Builder
public class TableProcessor implements ItemProcessor<Map<String, Object>, Map<String, Object>> {@Overridepublic Map<String, Object> process(Map<String, Object> item) {// 处理数据经纬度查找对应的流域item.put("waterCode", GeoJsonUtil.getWaterCode(Double.parseDouble(item.get("lon").toString()), Double.parseDouble(item.get("lat").toString())));return item;}
}import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;/*** Job 监听*/
public class BatchJobListener implements JobExecutionListener {private long beingTime;private long endTime;@Overridepublic void beforeJob(JobExecution jobExecution) {beingTime = System.currentTimeMillis();System.out.println(jobExecution.getJobInstance().getJobName() + " beforeJob...... " + beingTime);}@Overridepublic void afterJob(JobExecution jobExecution) {endTime = System.currentTimeMillis();System.out.println(jobExecution.getJobInstance().getJobName() + " afterJob...... " + endTime);System.out.println(jobExecution.getJobInstance().getJobName() + "一共耗耗时:【" + (endTime - beingTime) + "】毫秒");}}6、通过经纬度计算流域工具类
import lombok.extern.slf4j.Slf4j;
import org.geotools.feature.FeatureCollection;
import org.geotools.feature.FeatureIterator;
import org.geotools.geojson.feature.FeatureJSON;
import org.geotools.geometry.jts.JTSFactoryFinder;
import org.locationtech.jts.geom.*;
import org.opengis.feature.Feature;
import org.opengis.feature.Property;import java.io.IOException;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;/*** @Description: GeoJSON工具类* @author: Mr.xulong* @date: 2023年01月09日 14:39*/
@Slf4j
public class GeoJsonUtil {/*public static void main(String[] args) {try {FeatureCollection featureCollection = getFeatureCollection("sichuanliuyu.json");double x = 106.955085;double y = 32.09546061139062;System.out.println(JSON.toJSONString(properties(x,y,featureCollection)));} catch (Exception e) {e.printStackTrace();}}*/private static String geoJsonFilePath = "sichuanliuyu.json";private GeoJsonUtil() {}/*** 获取区域数据集合** @return*/public static FeatureCollection getFeatureCollection() {// 读取 GeoJson 文件InputStream resourceAsStream = GeoJsonUtil.class.getResourceAsStream("/json/" + geoJsonFilePath);FeatureJSON featureJSON = new FeatureJSON();try {return featureJSON.readFeatureCollection(resourceAsStream);} catch (IOException e) {e.printStackTrace();}return null;}/*** 判断指定区域集合是否包含某个点* @param longitude* @param latitude* @param featureCollection* @return*/public static boolean contains(double longitude, double latitude, FeatureCollection featureCollection) {FeatureIterator features = featureCollection.features();try {while (features.hasNext()) {Feature next = features.next();if (isContains(longitude, latitude, next)) {return true;}}} finally {features.close();}return false;}/*** 判断指定区域集合是否包含某个点,如果包含,则返回所需属性* @param longitude* @param latitude* @param featureCollection* @return*/public static Map<String, Object> properties(double longitude, double latitude, FeatureCollection featureCollection) {FeatureIterator features = featureCollection.features();try {while (features.hasNext()) {Feature next = features.next();boolean contains = isContains(longitude, latitude, next);// 如果点在面内则返回所需属性if (contains) {HashMap<String, Object> properties = new HashMap<>();properties.put("waterCode", next.getProperty("FID").getValue());properties.put("waterName", next.getProperty("name").getValue());return properties;}}} finally {features.close();}return null;}/*** 判断指定区域集合是否包含某个点,如果包含,则返回所需属性* @param longitude* @param latitude* @return*/public static Map<String, Object> properties(double longitude, double latitude) {FeatureCollection featureCollection = getFeatureCollection();FeatureIterator features = featureCollection.features();try {while (features.hasNext()) {Feature next = features.next();boolean contains = isContains(longitude, latitude, next);// 如果点在面内则返回所需属性if (contains) {HashMap<String, Object> properties = new HashMap<>();properties.put("waterCode", next.getProperty("FID").getValue());properties.put("waterName", next.getProperty("name").getValue());return properties;}}} finally {features.close();}return null;}/*** 判断指定区域集合是否包含某个点,如果包含,则返回所需属性* @param longitude* @param latitude* @return*/public static String getWaterCode(double longitude, double latitude) {FeatureCollection featureCollection = getFeatureCollection();FeatureIterator features = featureCollection.features();try {while (features.hasNext()) {Feature next = features.next();boolean contains = isContains(longitude, latitude, next);// 如果点在面内则返回所需属性if (contains) {return String.valueOf(next.getProperty("FID").getValue());}}} finally {features.close();}return null;}private static boolean isContains(double longitude, double latitude, Feature feature) {// 获取边界数据Property geometry = feature.getProperty("geometry");Object value = geometry.getValue();// 创建坐标的pointGeometryFactory geometryFactory = JTSFactoryFinder.getGeometryFactory();Point point = geometryFactory.createPoint(new Coordinate(longitude, latitude));boolean contains = false;// 判断是单面还是多面if (value instanceof MultiPolygon) {MultiPolygon multiPolygon = (MultiPolygon) value;contains = multiPolygon.contains(point);} else if (value instanceof Polygon) {Polygon polygon = (Polygon) value;contains = polygon.contains(point);}return contains;}
}7、地图依赖
<geotools.version>27-SNAPSHOT</geotools.version>
<!--地图--><dependency><groupId>org.geotools</groupId><artifactId>gt-shapefile</artifactId><version>${geotools.version}</version><exclusions><exclusion><groupId>org.geotools</groupId><artifactId>gt-main</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.geotools</groupId><artifactId>gt-main</artifactId><version>${geotools.version}</version></dependency><dependency><groupId>org.geotools</groupId><artifactId>gt-geojson</artifactId><version>${geotools.version}</version></dependency><dependency><groupId>org.geotools</groupId><artifactId>gt-swing</artifactId><version>${geotools.version}</version></dependency><repositories><repository><id>osgeo</id><name>OSGeo Release Repository</name><url>https://repo.osgeo.org/repository/release/</url><snapshots><enabled>false</enabled></snapshots><releases><enabled>true</enabled></releases></repository><repository><id>osgeo-snapshot</id><name>OSGeo Snapshot Repository</name><url>https://repo.osgeo.org/repository/snapshot/</url><snapshots><enabled>true</enabled></snapshots><releases><enabled>false</enabled></releases></repository></repositories>参考git项目 springbatch: 这是一个SpringBoot开发的SpringBatch批处理示例,示例主要是将文件30W条数据使用多线程导入到t_cust_temp表,然后又将t_cust_temp表数据使用分片导入到t_cust_info表。下载即可用。
相关文章:
SpringBatch简单处理多表批量动态更新
项目需要处理一堆表,这些表数据量不是很大都有经纬度信息,但是这些表的数据没有流域信息,需要按经纬度信息计算所属流域信息。比较简单的项目,按DeepSeek提示思索完成开发,AI真好用。 阿里AI个人版本IDEA安装 IDEA中使…...

夜莺监控 - 边缘告警引擎架构详解
前言 夜莺类似 Grafana 可以接入多个数据源,查询数据源的数据做告警和展示。但是有些数据源所在的机房和中心机房之间网络链路不好,如果由 n9e 进程去周期性查询数据并判定告警,那在网络链路抖动或拥塞的时候,告警就不稳定了。所…...

18440二维差分
18440二维差分 ⭐️难度:中等 📖 📚 import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);int n scanner.nextInt();int m scanner.nextInt();int q scanne…...

安全传输,高效共享 —— 体验FileLink的跨网文件传输
在当今数字化转型的浪潮中,企业在进行跨网文件传输时面临诸多挑战,包括数据安全、传输速度和用户体验等。为了解决这些问题,FileLink应运而生,成为一款高效、安全的跨网文件传输解决方案。 一、FileLink的核心特点 1.加密技术 …...

SOME/IP 教程知识点总结
总结关于SOME/IP的教程,首先通读整个文件,理解各个部分的内容。看起来这个教程从介绍开始,讲到了为什么在车辆中使用以太网,然后详细讲解了SOME/IP的概念、序列化、消息传递、服务发现(SOME/IP-SD)、发布/订阅机制以及支持情况。 首先,我需要确认每个章节的主要知识点。…...

学习路程八 langchin核心组件 Models补充 I/O和 Redis Cache
前序 之前了解了Models,Prompt,但有些资料又把这块与输出合称为模型输入输出(Model I/O):这是与各种大语言模型进行交互的基本组件。它允许开发者管理提示(prompt),通过通用接口调…...

图书数据采集:使用Python爬虫获取书籍详细信息
文章目录 一、准备工作1.1 环境搭建1.2 确定目标网站1.3 分析目标网站二、采集豆瓣读书网站三、处理动态加载的内容四、批量抓取多本书籍信息五、反爬虫策略与应对方法六、数据存储与管理七、总结在数字化时代,图书信息的管理和获取变得尤为重要。通过编写Python爬虫,可以从各…...

【DeepSeek系列】05 DeepSeek核心算法改进点总结
文章目录 一、DeepSeek概要二、4个重要改进点2.1 多头潜在注意力2.2 混合专家模型MoE2.3 多Token预测3.4 GRPO强化学习策略 三、2个重要思考3.1 大规模强化学习3.2 蒸馏方法:小模型也可以很强大 一、DeepSeek概要 2024年~2025年初,DeepSeek …...
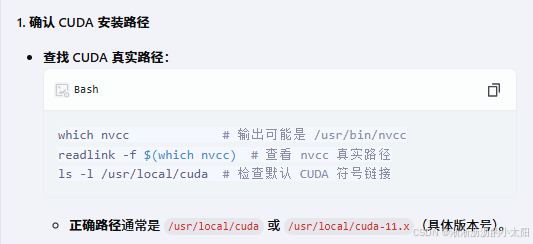
安装pointnet2-ops库
由于服务器没有连网,现在已在github中下载pointnet2_ops文件包并上传到服务器 (首先保证cuda版本和pytorch版本对应) 如何查找cuda的安装路径: 然后执行安装命令即可。...

DO-254航空标准飞行器电机控制器设计注意事项
DO-254航空标准飞行器电机控制器设计注意事项 1.核心要求1.1 设计保证等级(DAL)划分1.2生命周期管理1.3验证与确认2.电机控制器硬件设计的关键注意事项2.1需求管理与可追溯性2.2冗余与容错设计2.3验证与确认策略2.4元器件选型与管理2.5环境适应性设计2.6文档与配置管理3.应用…...

ABAP语言的动态程序
通过几个例子,由浅入深讲解 ABAP 动态编程。ABAP 动态编程主要通过 RTTS (Runtime Type Services) 来实现,包括 RTTI 和 RTTC: 运行时类型标识(RTTI) – 提供在运行时获取数据对象的类型定义的方法。运行时类型创建(R…...

开源电商项目、物联网项目、销售系统项目和社区团购项目
以下是推荐的开源电商项目、物联网项目、销售系统项目和社区团购项目,均使用Java开发,且无需付费,GitHub地址如下: ### 开源电商项目 1. **mall** GitHub地址:[https://github.com/macrozheng/mall](https://git…...

Docker教程(喂饭级!)
如果你有跨平台开发的需求,或者对每次在新机器上部署项目感到头疼,那么 Docker 是你的理想选择!Docker 通过容器化技术将应用程序与其运行环境隔离,实现快速部署和跨平台支持,极大地简化了开发和部署流程。本文详细介绍…...

HTML:自闭合标签简单介绍
1. 什么是自结束标签? 定义:自结束标签(Self-closing Tag)是指 不需要单独结束标签 的 HTML 标签,它们通过自身的语法结构闭合。语法形式: 在 HTML5 中:直接写作 <tag>,例如 …...

【和鲸社区获奖作品】内容平台数据分析报告
1.项目背景与目标 在社交和内容分享领域,某APP凭借笔记、视频等丰富的内容形式,逐渐吸引了大量用户。作为一个旨在提升用户互动和平台流量的分享平台,推荐算法成为其核心功能,通过精准推送内容,努力实现更高的点击率和…...

GitCode 助力 python-office:开启 Python 自动化办公新生态
项目仓库:https://gitcode.com/CoderWanFeng1/python-office 源于需求洞察,打造 Python 办公神器 项目作者程序员晚枫在运营拥有 14w 粉丝的 B 站账号 “Python 自动化办公社区” 时,敏锐察觉到非程序员群体对 Python 学习的强烈需求。在数字…...

超参数、网格搜索
一、超参数 超参数是在模型训练之前设置的,它们决定了训练过程的设置和模型的结构,因此被称为“超参数”。以KNN为例: 二、网格搜索 交叉验证(Cross-Validation)是在机器学习建立模型和验证模型参数时常用的方法&…...

or-tools编译命令自用备注
cmake .. -G "Visual Studio 17 2022" -A Win32 //vs2022 cmake .. -G "Visual Studio 15 2017" -A Win32 //vs2017 -DBUILD_DEPSON //联网下载 -DCMAKE_INSTALL_PREFIXinstall //带安装命令 -DCMAKE_CXX_FLAGS"/u…...
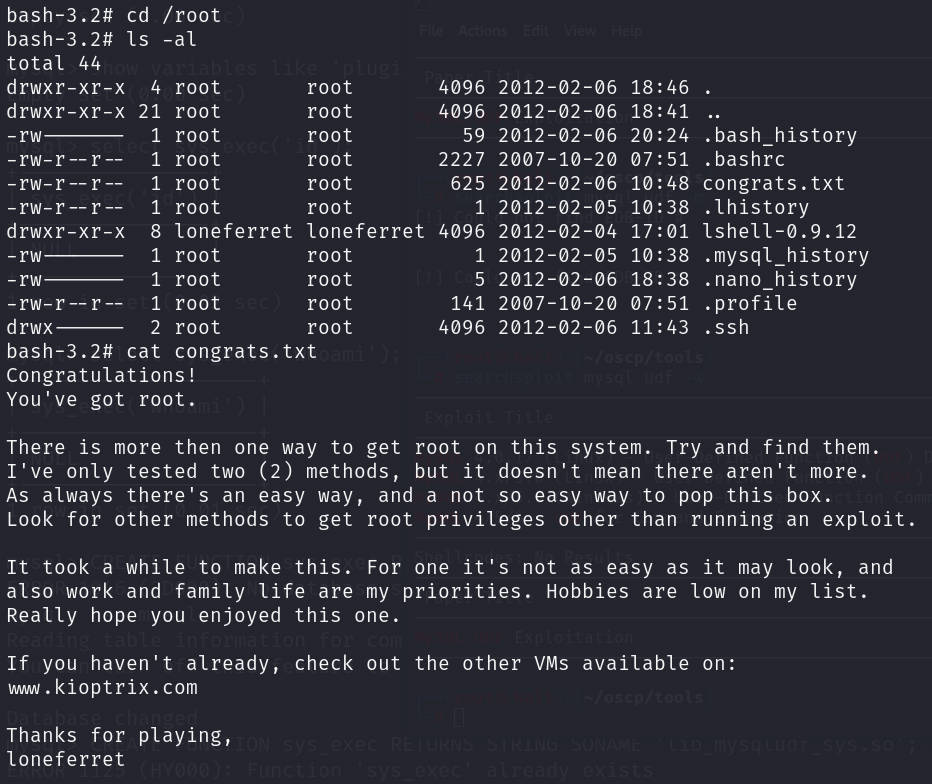
vulnhub靶场【kioptrix-4】靶机
前言 靶机:kioptrix-4,IP地址为192.168.1.75,后期IP地址为192.168.10.8 攻击:kali,IP地址为192.168.1.16,后期IP地址为192.168.10.6 都采用VMware虚拟机,网卡为桥接模式 这里的靶机…...

readline模块详解!!【Node.js】
“书到用时方恨少,事非经过不知难。” —— 陆游 目录 readline 是什么?基本用法:创建 Interface 类:核心流程: Interface 类的关键事件:line:close:pause:…...

如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析+新手教程 [特殊字符]
如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析新手教程 🚀 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client NightX Cl…...

昇腾CANN ops-nn RMSNorm:为什么 LLaMA 和 Mistral 都用它替代 LayerNorm
LayerNorm 做两件事:减均值(center)、除标准差(scale)。RMSNorm 只做一件:除 RMS。丢掉均值减法——省了 30% 计算,训练效果几乎一样。LLaMA、Mistral、Gemma 全系标配。 RMSNorm 的公式&#x…...

人机协同闭环:AI 时代邮件安全 “人在回路” 防御体系研究
摘要 2026 年,生成式 AI 全面渗透网络钓鱼攻击链,攻击从批量群发转向精准定制、从静态模板转向动态逃逸,传统纯技术防护出现显著盲区。数据显示,AI 自动化鱼叉式钓鱼点击率达 54%,攻击从投放至全面入侵的窗口压缩至秒级…...

高级内核模式硬件信息欺骗工具:深度解析Windows驱动级设备指纹伪装技术
高级内核模式硬件信息欺骗工具:深度解析Windows驱动级设备指纹伪装技术 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER EASY-HWID-SPOOFER是一款基于内核模式的硬件信息…...

【限时解析】DeepSeek 2024 Q3计费规则更新:2项重大变更将影响92%高频用户
更多请点击: https://kaifayun.com 第一章:DeepSeek计费模式分析 DeepSeek 提供的 API 服务采用按量计费(Pay-as-you-go)模式,核心计费维度为模型调用所消耗的 Token 总数,包含输入(prompt&…...

从0到99.3%上下文保真度:一位阿里云M6架构师复盘DeepSeek生产环境12类对话断裂根因与自动修复脚本
更多请点击: https://intelliparadigm.com 第一章:DeepSeek多轮对话优化的演进脉络与核心挑战 DeepSeek系列模型在多轮对话场景中的持续迭代,本质上是围绕上下文建模能力、状态一致性维持与推理效率三者协同演进的过程。早期版本依赖静态窗…...

混沌系统预测方法全景评测:从线性回归到神经ODE的实战指南
1. 项目概述:混沌系统预测的“兵器谱”与实战评测在动力系统建模和时间序列预测这个行当里混了十几年,我见过太多同行面对混沌系统时那种“既爱又恨”的复杂心情。爱的是它背后深刻的物理内涵和广泛的应用前景,从大气湍流到金融市场ÿ…...

2026中国AI应用全景图谱报告
这份《2026 中国 AI 应用全景图谱报告》由量子位智库发布,全景式呈现中国 AI 应用的生态格局、规模数据、发展趋势与标杆方案,揭示行业从工具化走向任务化、商业化与垂直深耕的关键跃迁。关注公众号:【互联互通社区】,回复【AI999…...

高性能Python多智能体建模框架:Mesa 3.0架构解析与工程实践指南
高性能Python多智能体建模框架:Mesa 3.0架构解析与工程实践指南 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.c…...

【太阳能】基于matlab PEM电解模拟了24小时太阳能绿色氢电厂(每小时太阳能发电量、氢气产量、用水量、储罐动态以及每公斤H₂的成本【含Matlab源码 15561期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...