如何理解语言模型
统计语言模型
先看语言模型,语言即自然语言,模型及我们要解决的某个任务。
-
任务一:判断哪句话出现的概率大
-
任务二:预判空缺的位置最有可能是哪个词
再看统计,统计即解决上述两个任务的解决方法。先对语句进行分词得到词序列,使用条件概率的链式法则,可以求出每一个词出现的概率,然后连乘,得出这句话的概率。对于任务二,判断每个词是空缺的概率最大。但是计算量非常大!
可以通过n元统计语言模型减少计算量。
如何计算?

平滑策略
防止出现0比0的情况如卡普拉斯平滑策略:
总的来说,就是基于数学统计的方法,来计算概率。
神经网络语言模型
即使用神经网络的方法解决任务。

NNLM的基本原理
NNLM通过神经网络来学习词序列的概率分布,基本流程如下:
-
输入层: 输入层通常由一个词汇表的向量表示。对于一个给定的词序列,NNLM首先将每个词转化为一个稀疏的one-hot编码向量,表示该词在词汇表中的位置。
-
嵌入层: 然后,将这些one-hot编码的词向量映射到一个低维的连续空间(词向量)。这个低维空间的表示能够捕捉到词与词之间的语义关系,例如“苹果”和“橙子”在某些任务中可能在词向量空间中靠得很近。
-
隐藏层: 嵌入层的输出将输入到一个神经网络的隐藏层。隐藏层通常是一个全连接层,神经网络通过非线性激活函数(如ReLU)处理输入数据。
-
输出层: 输出层会生成一个预测概率分布,表示在给定上下文(前面的词)下,当前词是每个词汇表中可能的词的概率。
-
训练过程: NNLM的训练过程通常通过最大化训练数据中每个词出现的条件概率来进行。具体来说,模型会使用梯度下降等优化方法来调整网络参数,使得给定上下文的情况下,正确词语的概率尽可能大。
这里引入了独热编码,来表示词。这是一开始的表示方法目的是让计算机“认识”单词,但这种方法有缺点,虽然减少了直接存单词,但当词汇量过大时,还是占用很大的空间。
而且还有关联度问题,现实中,词与词之间还有关联度,但是独热编码并不能很好的表示,这里词与词之间的关联度用到了余弦相似度,通过计算两个向量的夹角来判断两个向量是否有关联,不看向量的大小只看方向。为了解决这个词的“关联关系”于是就有了“词向量”这个概念。
余弦相似度(Cosine Similarity)是衡量两个向量相似度的一种常用方法,特别适用于文本分析中。它通过计算两个向量之间的夹角来判断它们的相似性,具体来说,余弦相似度是计算两个向量夹角的余弦值,余弦值越接近 1,表示两个向量越相似;越接近 0,表示两个向量越不相似。
计算公式如下:

神经网络模型的出现是为了解决平滑和计算量过大的问题。

-
tanh 是用于隐藏层的激活函数,能够捕捉输入的非线性特征,且具有对称性,将向量压缩为固定区间的值。
-
softmax是一种常用于多分类任务中的激活函数,它的作用是将输出的原始分数(logits)转换成一个概率分布。softmax的输出是一个包含所有类别的概率值,这些概率值的总和为1。
Q是一个参数,是可以学习的,c向量代表每一个单词而不是单独的独热编码,这样可以压缩维度,且可以表示关系,通过训练,Q越来越准,c向量也接代表的更准确!
词向量:用向量表示一个单词,独热编码也算词向量,但神经网络语言模型的副产品Q更佳。通过Q可以控制大小和维度,相似度也能表示!
Word Embedding是什么
Word Embedding(词嵌入)是自然语言处理(NLP)中的一种技术,它通过将单词映射到一个稠密的向量空间中,以便计算机能够更好地理解和处理文本数据。词嵌入的目标是将每个单词转换为一个固定维度的向量,这些向量能够捕捉到词与词之间的语义关系。
词袋模型(Bag of Words,简称BOW)是自然语言处理中的一种基础文本表示方法。它将文本中的每个单词视为一个独立的元素,忽略单词之间的顺序和语法结构,仅关注单词的出现与否及其频率。
有了词向量由此,现在的任务就是找到一个合适的Q!
Word2Vec模型
从这个模型的名字就能看出来,主要目的就是得到词向量,本质上也是一种神经网络模型。

Word2Vec网络架构本身就和NNLM一模一样!
两种模型架构:
-
CBOW (Continuous Bag of Words):此模型尝试通过上下文中的词来预测中心词。具体来说,CBOW 模型通过上下文窗口内的词语(即周围的词)来预测中心词。例如,在句子“我 爱 吃 苹果”中,如果“爱”和“吃”是上下文词,那么 CBOW 模型会预测中心词“苹果”。
-
Skip-gram:与 CBOW 相反,Skip-gram 模型通过给定的中心词来预测周围的上下文词。假设给定“苹果”这个中心词,Skip-gram 模型会根据它来预测“我”、“爱”和“吃”这几个上下文词。
NNLM和Word2vec的区别:NNLM目的是预测下一个词,Word2Vec是为了获得词向量。不需要使用tanh来保持预测准确性,所以少了 一层激活函数,只考虑Q矩阵的训练效果。
缺点:当有一词多意的情况 ,不能通过一个Q 准确表示出来。比如”苹果“这个词只能表示水果苹果,不能表示苹果手机的苹果。
相关文章:
如何理解语言模型
统计语言模型 先看语言模型,语言即自然语言,模型及我们要解决的某个任务。 任务一:判断哪句话出现的概率大 任务二:预判空缺的位置最有可能是哪个词 再看统计,统计即解决上述两个任务的解决方法。先对语句进行分词…...

准确-NGINX 1.26.2配置正向代理并编译安装的完整过程
NGINX 1.26.2 配置正向代理并编译安装的完整过程,使用了 ngx_http_proxy_connect_module 模块。 1. 环境准备 1.1 安装依赖 确保系统安装了以下必要的依赖: sudo yum install -y gcc gcc-c make pcre-devel zlib-devel openssl-devel1.2 下载 NGINX 源…...

企业如何将ERP和BPM项目结合提升核心竞争力
无论是实施ERP项目还是BPM项目,企业变革的根本目的的确是为了让企业变得更加强大,更具竞争力。 这就像是练武功,无论是学习少林拳还是太极拳,最终的目标都是为了强身健体,提升战斗力。 如何将ERP和BPM项目有效结合以及…...

Linux内核以太网驱动分析
1.网络接口卡接收和发送数据在Linux内核中的处理流程如下: 1. 网络接口卡(Network Interface Card, NIC) 作用:负责物理层的数据传输,将数据包从网络介质(如以太网线)读取到内存中,或…...

分布式微服务系统架构第92集:智能健康监测设备Java开发方案
加群联系作者vx:xiaoda0423 仓库地址:https://webvueblog.github.io/JavaPlusDoc/ https://1024bat.cn 嗯,用户需要为血压、血糖、尿酸和血酮测试仪编写产品描述,同时涉及Java开发。首先,我得确定他们的需求是什么。可…...

【推荐项目】023-游泳俱乐部管理系统
023 游泳俱乐部管理系统 游泳俱乐部管理系统概述 前端技术框架: 我们优雅地采用了Vue.js作为游泳俱乐部管理系统的前端基础框架。Vue.js以其轻盈、高效和易于上手的特点,为我们的用户界面带来了极致的流畅性和响应速度。通过Vue.js,我们为…...

Webpack常见配置实例
webpack实例 打包构建流程对应的常见配置 1. mode: development2. entry: ./src/index.js3. output4. module.rules5. Loader6. Plugin7. devServerwebpack.config.js webpack常见配置实例 配置详解 mode: ‘development’: 设置 Webpack 运行模式&am…...

C++核心编程之STL
STL初识:从零开始的奇幻冒险 1 STL的诞生:一场代码复用的革命 很久很久以前,在编程的世界里,开发者们每天都在重复造轮子。无论是数据结构还是算法,每个人都得从头开始写,仿佛在无尽的沙漠中寻找绿洲。直到…...

Mac mini M4安装nvm 和node
先要安装Homebrew(如果尚未安装)。在终端中输入以下命令: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 根据提示操作完成Homebrew的安装。 安装nvm。在终端中输入以下命令…...
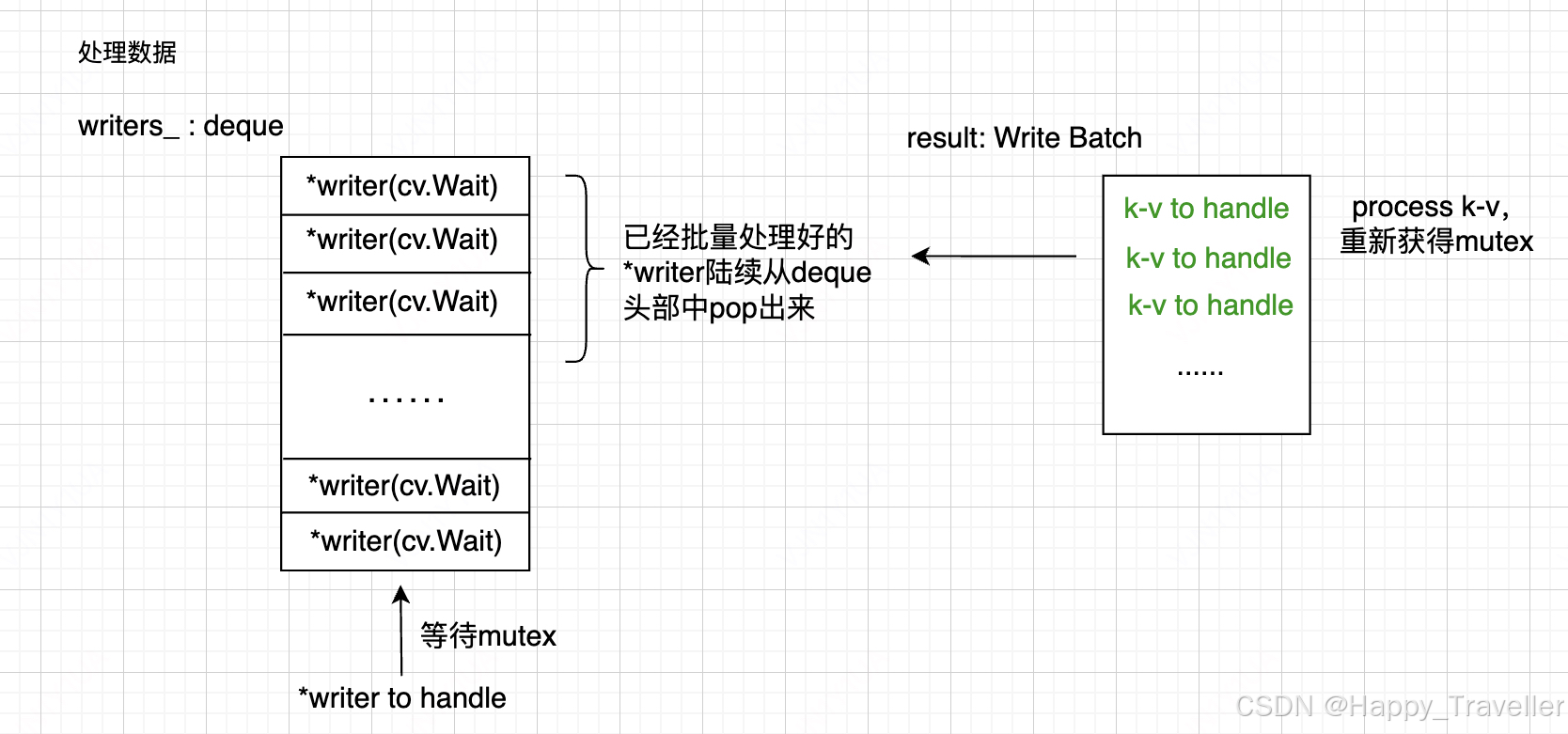
Level DB --- 写流程架构
Level DB是高效的k-v数据库,接受多线程写,既要保证多线程写临界区安全,同时又要保证写流程的尽量高效性。 写入数据 Level DB 用一个deque用来衔接生产-消费模型。一个新的kv写入请求,会先将kv封装成Writer结构体。插入之前要先…...
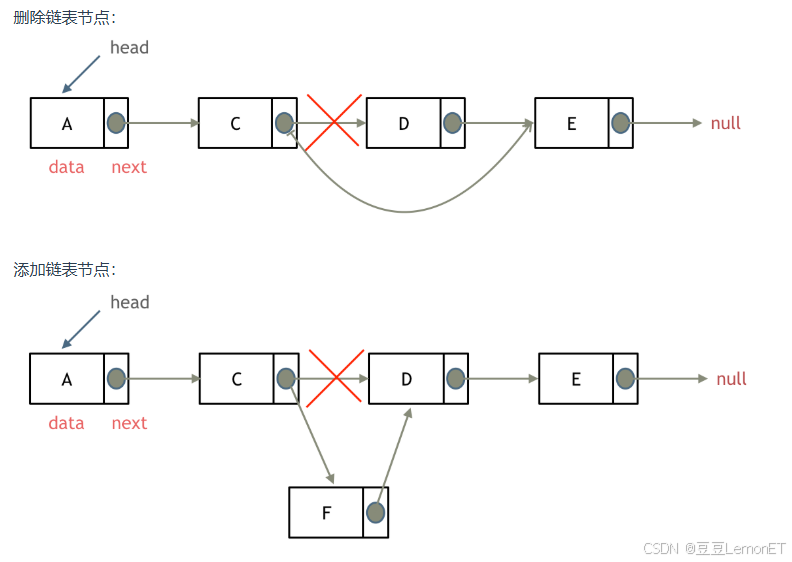
【中等】707.设计链表
题目描述 你可以选择使用单链表或者双链表,设计并实现自己的链表。 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。 如果是双向链表,则还需要属性 prev 以指示链表中的…...

深入理解Reactor Flux的生成方法
在Reactor框架中,Flux 是一个非常重要的概念,它用于表示一个可以产生多个事件的响应式流。通过 Flux 提供的多种生成方法,我们可以灵活地创建各种类型的流。本文将详细介绍 Flux.generate 方法的使用,并通过实例帮助读者更好地理解…...

next实现原理
Next.js 是一个基于 React 的 服务器端渲染(SSR) 和 静态生成(SSG) 框架,它的实现原理涉及多个关键技术点,包括 服务端渲染(SSR)、静态生成(SSG)、客户端渲染…...

LeetCode 热题 100 53. 最大子数组和
LeetCode 热题 100 | 53. 最大子数组和 大家好,今天我们来解决一道经典的算法题——最大子数组和。这道题在 LeetCode 上被标记为中等难度,要求我们找出一个具有最大和的连续子数组,并返回其最大和。下面我将详细讲解解题思路,并…...

DeepSeek 与大数据治理:AI 赋能数据管理的未来
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 在当今数字化时代,数据已成为企业和机构的重要资产,而大数据治理(Big Data Governan…...

【时时三省】(C语言基础)浮点型数据
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 浮点型数据 浮点型数据是用来表示具有小数点的实数的,为什么在C中把实数称为浮点数呢?在C语言中,实数是以指数正式存放在在储单元中的。一个实数表示为指数可以有不…...

【大模型】Ollama本地部署DeepSeek大模型:打造专属AI助手
【大模型】Ollama本地部署DeepSeek大模型:打造专属AI助手 Ollama本地部署DeepSeek大模型:打造专属AI助手一、Ollama简介二、硬件需求三、部署步骤1. 下载并安装Ollama(1)访问Ollama官网(2)安装Ollama 2. 配…...

2025.3.2机器学习笔记:PINN文献阅读
2025.3.2周报 一、文献阅读题目信息摘要Abstract创新点网络架构实验结论不足以及展望 一、文献阅读 题目信息 题目: Physics-Informed Neural Networks of the Saint-Venant Equations for Downscaling a Large-Scale River Model期刊: Water Resource…...

数据集笔记:新加坡 地铁(MRT)和轻轨(LRT)票价
数据连接 data.gov.sg 2024 年 12 月 28 日起生效的新加坡地铁票价 该数据集包含 MRT 和 LRT 票价的信息,包括: 票价类型(Fare Type):成人票、学生票、老年人票、残障人士票等。适用时间(Applicable Tim…...

如何修改安全帽/反光衣检测AI边缘计算智能分析网关V4的IP地址?
TSINGSEE青犀推出的智能分析网关V4,是一款集成了BM1684芯片的高性能AI边缘计算智能硬件。其内置的高性能8核ARM A53处理器,主频可高达2.3GHz,INT8峰值算力更是达到了惊人的17.6Tops。此外,该硬件还预装了近40种AI算法模型…...

DownKyi:解锁B站8K超高清视频下载的5个核心优势
DownKyi:解锁B站8K超高清视频下载的5个核心优势 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

RDP Wrapper实用指南:三步解决[not supported]错误的高效方法
RDP Wrapper实用指南:三步解决[not supported]错误的高效方法 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper是一款让Windows家庭版支持多用户远程桌面连接的开源工具,但许多用…...

2026 大模型企业画像梳理技术解析:混乱画像规范方法深度测评
引言随着 AI 搜索成为商业信息获取的主要渠道,大模型生成的企业画像准确性直接影响企业品牌形象和获客效果。据中国 GEO 行业协会 2026 年调研数据显示,超过 76% 的企业反映大模型生成的企业画像存在信息混乱、错误遗漏、业务不匹配等问题,其…...

AI应用开发
1.规划 2.记忆 2.工具 3.行动...

SolidWorks 2024新手避坑指南:从草图到三维实体,这5个特征操作最容易出错
SolidWorks 2024新手避坑指南:从草图到三维实体的5个关键特征操作 刚接触SolidWorks的新手工程师常常会在从二维草图转向三维实体建模的过程中踩到各种"坑"。这些错误不仅浪费时间,还可能让人对这款强大的三维设计软件产生挫败感。本文将聚焦五…...

掌握Manim数学动画引擎:从零到一的完整攻略
掌握Manim数学动画引擎:从零到一的完整攻略 【免费下载链接】manim Animation engine for explanatory math videos 项目地址: https://gitcode.com/GitHub_Trending/ma/manim Manim是一款专为数学可视化设计的强大动画引擎,能够通过编程方式创建…...

Shader Graph边缘光原理与实战:从菲涅尔效应到世界空间法线
1. 为什么边缘光不是“加个描边”那么简单——从美术需求到Shader本质的错位“给模型加个边缘光”,听起来像Unity编辑器里拖个组件、点几下鼠标就能搞定的事。我第一次接到这个需求时,美术同学在评审会上甩出一张《原神》角色截图,指着雷电将…...

你的 FlashAttention 真的在跑吗?几个简单方法确认
之前有个朋友在昇腾 NPU 上部署模型,按文档开了 --enable-flash-attn,跑起来也没报错。但他总觉得延迟不对——跟之前没开的时候差不多。他问我:怎么确认 FlashAttention 真的生效了?不会是静默降级了吧? 这个问题问得…...

第1章:AI Agent 架构与核心组件
第1章:AI Agent 架构与核心组件 1.1 从 LLM 到 AI Agent:范式转变 大型语言模型(LLM)本身只是被动响应的工具——用户输入提示,模型输出回答。而 AI Agent(人工智能代理)则赋予了模型主动思考、规划和使用工具的能力,使其能够: 自主规划:将复杂任务分解为可执行的步…...
)
Codex入门15-命令速查(实用工具:全部命令和快捷键一网打尽,打印贴墙上)
Codex入门15-命令速查(实用工具:全部命令和快捷键一网打尽,打印贴墙上) 📌 文章简介:这是一篇你一定要收藏的"字典文章"。本文把 Codex CLI 的所有交互式斜杠命令、命令行参数、键盘快捷键、环境变量整理成清晰的表格——打印出来贴墙上,随查随用。每条命令都…...