分布式日志和责任链路
目录
日志问题
责任链问题
分布式日志
GrayLog简介
部署安装
收集日志
配置Inputs
集成微服务
日志回收策略
搜索语法
搜索语法
自定义展示字段
日志统计仪表盘
创建仪表盘
链路追踪
APM
什么是APM
原理
技术选型
Skywalking简介
部署安装
微服务探针
整合到docker服务
在微服务架构体系中,微服务上线后,有两个不容忽略的问题,一是日志该怎么存储、查看,二是如何在复杂的调用链中排查问题。
日志问题
在微服务架构下,微服务被拆分成多个微小的服务,每个微小的服务都部署在不同的服务器实例上,当我们定位问题,检索日志的时候需要依次登录每台服务器进行检索。
这样是不是感觉很繁琐和效率低下?所以我们还需要一个工具来帮助集中收集、存储和搜索这些跟踪信息。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情。以前,我们通过使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
所以,需要通过分布式日志服务来帮我们解决上述问题的。
责任链问题
在微服务架构下,如何排查异常的微服务,比如:发布新版本后发现系统处理用户请求变慢了,要想解决这个问首先是要找出“慢”的环节,此时就需要对整个微服务的调用链有清晰的监控,否则是不容易找出问题的。
分布式日志
分布式日志框架服务的实现思路基本是一致的,如下:
- 日志收集器:微服务中引入日志客户端,将记录的日志发送到日志服务端的收集器,然后以某种方式存储
- 数据存储:一般使用ElasticSearch分布式存储,把收集器收集到的日志格式化,然后存储到分布式存储中
- web服务:利用ElasticSearch的统计搜索功能,实现日志查询和报表输出
比较知名的分布式日志服务包括:
- ELK:elasticsearch、Logstash、Kibana
- GrayLog
这里选择graylog实现分布式日志
业界比较知名的分布式日志服务解决方案是ELK,而我们今天要学习的是GrayLog。为什么呢?
ELK解决方案的问题:
- 不能处理多行日志,比如Mysql慢查询,Tomcat/Jetty应用的Java异常打印
- 不能保留原始日志,只能把原始日志分字段保存,这样搜索日志结果是一堆Json格式文本,无法阅读。
- 不符合正则表达式匹配的日志行,被全部丢弃。
GrayLog方案的优势:
- 一体化方案,安装方便,不像ELK有3个独立系统间的集成问题。
- 采集原始日志,并可以事后再添加字段,比如http_status_code,response_time等等。
- 自己开发采集日志的脚本,并用curl/nc发送到Graylog Server,发送格式是自定义的GELF,Flunted和Logstash都有相应的输出GELF消息的插件。自己开发带来很大的自由度。实际上只需要用inotifywait监控日志的modify事件,并把日志的新增行用curl/netcat发送到Graylog Server就可。
- 搜索结果高亮显示,就像google一样。
- 搜索语法简单,比如:
source:mongo AND reponse_time_ms:>5000,避免直接输入elasticsearch搜索json语法 - 搜索条件可以导出为elasticsearch的搜索json文本,方便直接开发调用elasticsearch rest api的搜索脚本。
GrayLog简介
GrayLog是一个轻量型的分布式日志管理平台,一个开源的日志聚合、分析、审计、展示和预警工具。在功能上来说,和 ELK类似,但又比 ELK要简单轻量许多。依靠着更加简洁,高效,部署使用简单的优势很快受到许多公司的青睐。
官网:SIEM, Log Management & API Protection
其基本框架如图:
基本思路就是每一个微服务把自己的日志发送给GrayLog然后将日志数据存入mongoDB或者es中,最后提供一个浏览器进行操作

流程如下:
- 微服务中的GrayLog客户端发送日志到GrayLog服务端
- GrayLog把日志信息格式化,存储到Elasticsearch
- 客户端通过浏览器访问GrayLog,GrayLog访问Elasticsearch
这里MongoDB是用来存储GrayLog的配置信息的,这样搭建集群时,GrayLog的各节点可以共享配置。
部署安装
我们在虚拟机中选择使用Docker来安装。需要安装的包括:
- MongoDB:用来存储GrayLog的配置信息
- Elasticsearch:用来存储日志信息
- GrayLog:GrayLog服务端
下面将通过docker的方式部署,镜像已经下载到101虚拟机中,部署脚本如下:
#部署Elasticsearch
docker run -d \
--name elasticsearch \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.17.5
#部署MongoDB(使用之前部署的服务即可)
docker run -d \
--name mongodb \
-p 27017:27017 \
--restart=always \
-v mongodb:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=sl \
-e MONGO_INITDB_ROOT_PASSWORD=123321 \
mongo:4.4
#部署
docker run \
--name graylog \
-p 9000:9000 \
-p 12201:12201/udp \
-e GRAYLOG_HTTP_EXTERNAL_URI=http://192.168.150.101:9000/ \
-e GRAYLOG_ELASTICSEARCH_HOSTS=http://192.168.150.101:9200/ \
-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai" \
-e GRAYLOG_WEB_ENDPOINT_URI="http://192.168.150.101:9000/:9000/api" \
-e GRAYLOG_PASSWORD_SECRET="somepasswordpepper" \
-e GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 \
-e GRAYLOG_MONGODB_URI=mongodb://sl:123321@192.168.150.101:27017/admin \
-d \
graylog/graylog:4.3
命令解读:
- 端口信息:
-p 9000:9000:GrayLog的http服务端口,9000-p 12201:12201/udp:GrayLog的GELF UDP协议端口,用于接收从微服务发来的日志信息
- 环境变量
-e GRAYLOG_HTTP_EXTERNAL_URI:对外开放的ip和端口信息,这里用9000端口-e GRAYLOG_ELASTICSEARCH_HOSTS:GrayLog依赖于ES,这里指定ES的地址-e GRAYLOG_WEB_ENDPOINT_URI:对外开放的API地址-e GRAYLOG_PASSWORD_SECRET:密码加密的秘钥-e GRAYLOG_ROOT_PASSWORD_SHA2:密码加密后的密文。明文是admin,账户也是admin-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai":GrayLog容器内时区-e GRAYLOG_MONGODB_URI:指定MongoDB的链接信息
graylog/graylog:4.3:使用的镜像名称,版本为4.3访问地址 http://192.168.150.101:9000/ , 如果可以看到如下界面说明启动成功。
收集日志
配置Inputs
部署完成GrayLog后,需要配置Inputs才能接收微服务发来的日志数据。
第一步,在System菜单中选择Inputs:

第二步,在页面的下拉选框中,选择GELF UDP:

然后点击Launch new input按钮:

点击save保存:

可以看到,GELF UDP Inputs 保存成功。

集成微服务
现在,GrayLog的服务端日志收集器已经准备好,我们还需要在项目中添加GrayLog的客户端,将项目日志发送到GrayLog服务中,保存到ElasticSearch。
基本步骤如下:
- 引入GrayLog客户端依赖
- 配置Logback,集成GrayLog的Appender
- 启动并测试
这里,我们以work微服务为例,其他的类似。
导入依赖:
<dependency><groupId>biz.paluch.logging</groupId><artifactId>logstash-gelf</artifactId><version>1.15.0</version>
</dependency>配置Logback,在配置文件中增加 GELF的appender:
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。-->
<!--scanPeriod: 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。-->
<!--debug: 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。-->
<configuration debug="false" scan="false" scanPeriod="60 seconds"><springProperty scope="context" name="appName" source="spring.application.name"/><!--文件名--><property name="logback.appname" value="${appName}"/><!--文件位置--><property name="logback.logdir" value="/data/logs"/><!-- 定义控制台输出 --><appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"><layout class="ch.qos.logback.classic.PatternLayout"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} - [%thread] - %-5level - %logger{50} - %msg%n</pattern></layout></appender><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>DEBUG</level></filter><File>${logback.logdir}/${logback.appname}/${logback.appname}.log</File><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><FileNamePattern>${logback.logdir}/${logback.appname}/${logback.appname}.%d{yyyy-MM-dd}.log.zip</FileNamePattern><maxHistory>90</maxHistory></rollingPolicy><encoder><charset>UTF-8</charset><pattern>%d [%thread] %-5level %logger{36} %line - %msg%n</pattern></encoder></appender><appender name="GELF" class="biz.paluch.logging.gelf.logback.GelfLogbackAppender"><!--GrayLog服务地址--><host>udp:192.168.150.101</host><!--GrayLog服务端口--><port>12201</port><version>1.1</version><!--当前服务名称--><facility>${appName}</facility><extractStackTrace>true</extractStackTrace><filterStackTrace>true</filterStackTrace><mdcProfiling>true</mdcProfiling><timestampPattern>yyyy-MM-dd HH:mm:ss,SSS</timestampPattern><maximumMessageSize>8192</maximumMessageSize></appender><!--evel:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,--><!--不能设置为INHERITED或者同义词NULL。默认是DEBUG。--><root level="INFO"><appender-ref ref="stdout"/><appender-ref ref="GELF"/></root>
</configuration>加载这个文件
logging:config: classpath:logback-spring.xml开启微服务进入打印日志便于查看数据,启动服务,点击search按钮即可看到日志数据:

日志回收策略
到此graylog的基础配置就算完成了,已经可以收到日志数据。
但是在实际工作中,服务日志会非常多,这么多的日志,如果不进行存储限制,那么不久就会占满磁盘,查询变慢等等,而且过久的历史日志对于实际工作中的有效性也会很低。
Graylog则自身集成了日志数据限制的配置,可以通过如下进行设置:

选择Default index set的Edit按钮:

GrayLog有3种日志回收限制,触发以后就会开始回收空间,删除索引:

分别是:
Index Message Count:按照日志数量统计,默认超过20000000条日志开始清理
-
- 我们测试时,设置
100000即可
- 我们测试时,设置
Index Size:按照日志大小统计,默认超过1GB开始清理Index Time:按照日志日期清理,默认日志存储1天
搜索语法
在search页面,可以完成基本的日志搜索功能:

搜索语法
搜索语法非常简单,输入关键字或指定字段进行搜索:
#不指定字段,默认从message字段查询
输入:undo
#输入两个关键字,关系为or
undo 统计
#加引号是需要完整匹配
"undo 统计"
#指定字段查询,level表示日志级别,ERROR(3)、WARNING(4)、NOTICE(5)、INFO(6)、DEBUG(7)
level: 6
#或条件
level:(6 OR 7)更多查询官网文档:Write Search Queries
自定义展示字段

效果如下:

日志统计仪表盘
GrayLog支持把日志按照自己需要的方式形成统计报表,并把许多报表组合一起,形成DashBoard(仪表盘),方便对日志统计分析。
创建仪表盘



可以设置各种指标:




最终效果:

官方给出的效果:

链路追踪
APM
什么是APM
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现
- 服务有可能布在了几千台服务器,横跨多个不同的数据中心
因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统,全称是(Application Performance Monitor,当然也有叫 Application Performance Management tools)
原理
先来看一次请求调用示例:
- 包括:前端(A),两个中间层(B和C),以及两个后端(D和E)
- 当用户发起一个请求时,首先到达前端A服务,然后分别对B服务和C服务进行RPC调用;
- B服务处理完给A做出响应,但是C服务还需要和后端的D服务和E服务交互之后再返还给A服务,最后由A服务来响应用户的请求;

如何才能实现跟踪呢?需要明白下面几个概念:
- 探针:负责在客户端程序运行时收集服务调用链路信息,发送给收集器
- 收集器:负责将数据格式化,保存到存储器
- 存储器:保存数据
- UI界面:统计并展示
探针会在链路追踪时记录每次调用的信息,Span是基本单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它;同时附加(Annotation)作为payload负载信息,用于记录性能等数据。
一个Span的基本数据结构:
type Span struct {TraceID int64 // 用于标示一次完整的请求idName string //名称ID int64 // 当前这次调用span_idParentID int64 // 上层服务的调用span_id 最上层服务parent_id为null,代表根服务rootAnnotation []Annotation // 记录性能等数据Debug bool
}一次请求的每个链路,通过spanId、parentId就能串联起来:

当然,从请求到服务器开始,服务器返回response结束,每个span存在相同的唯一标识trace_id。
技术选型
市面上的全链路监控理论模型大多都是借鉴Google Dapper论文,重点关注以下三种APM组件:
- Zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。
- Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件。
- Skywalking:国产的优秀APM组件,是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。现在是Apache的顶级项目之一。
选项就是对比各个系统的使用差异,主要对比项:
- 探针的性能
主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。 - collector的可扩展性
能够水平扩展以便支持大规模服务器集群。 - 全面的调用链路数据分析
提供代码级别的可见性以便轻松定位失败点和瓶颈。 - 对于开发透明,容易开关
添加新功能而无需修改代码,容易启用或者禁用。 - 完整的调用链应用拓扑
自动检测应用拓扑,帮助你搞清楚应用的架构
三者对比如下:
| 对比项 | zipkin | pinpoint | skywalking |
| 探针性能 | 中 | 低 | 高 |
| collector扩展性 | 高 | 中 | 高 |
| 调用链路数据分析 | 低 | 高 | 中 |
| 对开发透明性 | 中 | 高 | 高 |
| 调用链应用拓扑 | 中 | 高 | 中 |
| 社区支持 | 高 | 中 | 高 |
综上所述,使用skywalking是最佳的选择。
Skywalking简介
SkyWalking创建与2015年,提供分布式追踪功能,是一个功能完备的APM系统。
官网地址:Apache SkyWalking

主要的特征:
- 多语言探针或类库
-
- Java自动探针,追踪和监控程序时,不需要修改源码。
- 社区提供的其他多语言探针
-
-
- .NET Core
- Node.js
-
- 多种后端存储: ElasticSearch, H2
- 支持OpenTracing
-
- Java自动探针支持和OpenTracing API协同工作
- 轻量级、完善功能的后端聚合和分析
- 现代化Web UI
- 日志集成
- 应用、实例和服务的告警
官方架构图:

大致分四个部分:
- skywalking-oap-server:就是Observability Analysis Platform的服务,用来收集和处理探针发来的数据
- skywalking-UI:就是skywalking提供的Web UI 服务,图形化方式展示服务链路、拓扑图、trace、性能监控等
- agent:探针,获取服务调用的链路信息、性能信息,发送到skywalking的OAP服务
- Storage:存储,一般选择elasticsearch
因此我们安装部署也从这四个方面入手,目前elasticsearch已经安装完成,只需要部署其他3个即可。
部署安装
#oap服务,需要指定Elasticsearch以及链接信息
docker run -d \
-e TZ=Asia/Shanghai \
--name oap \
-p 12800:12800 \
-p 11800:11800 \
-e SW_STORAGE=elasticsearch \
-e SW_STORAGE_ES_CLUSTER_NODES=192.168.150.101:9200 \
apache/skywalking-oap-server:9.1.0
#部署ui,需要指定oap服务
docker run -d \
--name oap-ui \
-p 48080:8080 \
-e TZ=Asia/Shanghai \
-e SW_OAP_ADDRESS=http://192.168.150.101:12800 \
apache/skywalking-ui:9.1.0
启动成功后,访问地址http://192.168.150.101:48080/,即可查看skywalking的ui界面。

通过docker部署,需要部署两部分,分别是skywalking-oap-server和skywalking-UI。
#oap服务,需要指定Elasticsearch以及链接信息
docker run -d \
-e TZ=Asia/Shanghai \
--name oap \
-p 12800:12800 \
-p 11800:11800 \
-e SW_STORAGE=elasticsearch \
-e SW_STORAGE_ES_CLUSTER_NODES=192.168.150.101:9200 \
apache/skywalking-oap-server:9.1.0
#部署ui,需要指定oap服务
docker run -d \
--name oap-ui \
-p 48080:8080 \
-e TZ=Asia/Shanghai \
-e SW_OAP_ADDRESS=http://192.168.150.101:12800 \
apache/skywalking-ui:9.1.0
启动成功后,访问地址http://192.168.150.101:48080/,即可查看skywalking的ui界面。
微服务探针
现在,Skywalking的服务端已经启动完成,我们还需要在微服务中加入服务探针,来收集数据。

将skywalking-agent解压到非中文目录。
在微服务中设置启动参数,以work微服务为例:

输入如下内容:
-javaagent:F:\code\sl-express\docs\resources\skywalking-agent\skywalking-agent.jar
-Dskywalking.agent.service_name=ms::sl-express-ms-work
-Dskywalking.collector.backend_service=192.168.150.101:11800参数说明:
- javaagent: 将skywalking-agent以代理的方式整合到微服务中
- skywalking.agent.service_name:指定服务名称,格式:[{logic name}
- skywalking.collector.backend_service:指定oap服务,注意端口要走11800
设置完成后,重新启动work微服务,多请求几次接口,即可自oap-ui中看到数据。


查看链路:

服务关系拓扑图:

整合到docker服务
前面的测试是在本地测试,如何将SkyWalking整合到docker服务中呢?
这里以sl-express-ms-web-courier为例,其他的服务类似。
第一步,修改Dockerfile文件
#FROM openjdk:11-jdk
#修改为基于整合了skywalking的镜像,其他的不需要动
FROM apache/skywalking-java-agent:8.11.0-java11
LABEL maintainer="研究院研发组 <research@itcast.cn>"# 时区修改为东八区
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezoneWORKDIR /app
ARG JAR_FILE=target/*.jar
ADD ${JAR_FILE} app.jar
EXPOSE 8080
ENTRYPOINT ["sh","-c","java -Djava.security.egd=file:/dev/./urandom -jar $JAVA_OPTS app.jar"]第二步,在Jenkins中编辑修改配置:
名称:skywalkingServiceName 值:ms::sl-express-ms-web-courier

名称:skywalkingBackendService 值:192.168.150.101:11800

修改运行脚本,增加系统环境变量:
-e SW_AGENT_NAME=${skywalkingServiceName} -e SW_AGENT_COLLECTOR_BACKEND_SERVICES=${skywalkingBackendService}

第三步,重新部署服务:

第四步,测试接口,查看数据。


相关文章:
分布式日志和责任链路
目录 日志问题 责任链问题 分布式日志 GrayLog简介 部署安装 收集日志 配置Inputs 集成微服务 日志回收策略 搜索语法 搜索语法 自定义展示字段 日志统计仪表盘 创建仪表盘 链路追踪 APM 什么是APM 原理 技术选型 Skywalking简介 部署安装 微服务探针 整合…...

h5 IOS端渐变的兼容问题 渐变实现弧形效果
IOS端使用渐变的时候有兼容问题 以下是问题效果,图中黑色部分期望的效果应该是白色的。但是ios端是下面的样子…… 安卓pc 支持: background-image: radial-gradient(circle 40rpx at 100% 0, #f3630c 40rpx, rgb(255, 255, 255) 50%);安卓pc ios支持…...

哈希算法--猜数字游戏
1.题目要求 输入两个位数相同的数,判断对应位置的数字是否相等,返回两个数。第一个数是数字和位置完全猜对的数字个数,第二个数是数字大小猜对但位置不对的数字个数 2.逐步编程 2.1 定义函数 def g(secret,guess):sec_dic{}gue_dic{}# 定义…...

idea生成自定义Maven原型(archetype)项目工程模板
一、什么是Maven原型(Maven archetype) 引自官网的介绍如下: Maven原型插件官网地址 这里采用DeepSeek助手翻译如下: Maven 原型 什么是原型? 简而言之,原型是一个 Maven 项目模板工具包。原型被定义为一…...

Redis面试常见问题——使用场景问题
目录 Redis面试常见问题 如果发生了缓存穿透、击穿、雪崩,该如何解决? 缓存穿透 什么是布隆过滤器? 缓存击穿 缓存雪崩 双写一致性(redis做为缓存,mysql的数据如何与redis进行同步呢?) …...
)
样式和ui(待更新)
element-plus 先在项目下执行安装语句执行按需导入的命令按照官方文档修改vitest.json sass样式定制 npm -i sass -D在项目下准备定制的样式文件 styles/element/index.scss(!注意这里是.scss文件在vitest.json 修改配置文件 Components({resolvers: [ElementPlusResolver(…...

大摩闭门会:250228 学习总结报告
如果图片分辨率不足,可右键图片在新标签打开图片或者下载末尾源文件进行查看 本文只是针对视频做相应学术记录,进行学习讨论使用...

线程(Thread)
一、概念 线程:线程是一个轻量级的进程 二、线程的创建 1、线程的空间 (1)进程的空间包括:系统数据段、数据段、文本段 (2) 线程位于进程空间内部 (3) 栈区独享、与进程共享文本段、…...

AI军备竞赛2025:GPT-4.5的“情商革命”、文心4.5的开源突围与Trae的代码革命
AI军备竞赛2025:GPT-4.5的“情商革命”、文心4.5的开源突围与Trae的代码革命 ——一场重塑人类认知边界的技术战争 一、OpenAI的“感性觉醒”:GPT-4.5的颠覆与争议 1.1 从“冷面学霸”到“温柔导师”:AI的情商跃迁 当用户输入“朋友放鸽子&…...

DeepSeek + 自由职业 发现新大陆,从 0 到 1 全流程跑通商业 IP
DeepSeek 自由职业 发现新大陆,从 0 到 1 全流程跑通商业 IP 商业定位1. 商业定位分析提示词2. 私域引流策略提示词3. 变现模型计算器提示词4. 对标账号分析提示词5. 商业IP人设打造提示词6. 内容选题策略提示词7. 用户人群链分析提示词8. 内容布局与转化路径设计提…...

Java进阶——常用工具类
日常开发中,Arrays、Collections 和 Objects 是非常实用的工具类,提供了丰富的功能,从而可以更高效地处理数组、集合和对象。本文将详细介绍这三个工具类的重要知识细节。 本文目录 一、 Arrays数组转集合并行排序优化Stream 支持 二、 Colle…...

【考试大纲】高级系统架构设计师考试大纲
目录 引言一、 考试说明1.考试目标2.考试要求3.考试科目设置二、 考试范围考试科目1:系统架构设计综合知识考试科目2:系统架构设计案例分析考试科目3:系统架构设计论文引言 最新的系统架构设计师考试大纲出版于 2022 年 11 月,本考试大纲基于此版本整理。 一、 考试说明…...

上位机知识篇---四种CPU架构交叉编译
文章目录 前言一、四种 CPU 架构1. x86/x86_64指令集位宽:应用场景编译工具 2. ARM指令集位宽:应用场景编译工具 3. MIPS指令集位宽应用场景编译工具 4. RISC-V指令集位宽应用场景编译工具 二、交叉编译1. 什么是交叉编译?定义应用场景 2. 交…...

隐式转换为什么导致索引失效
SELECT * FROM users WHERE id 123;这条语句失效的原因就是id是int类型的主键,比较的时候把id从int转化为字符串来比较了,而字符串的比较规则和int的比较规则明显不同,字符串是字典序比较的,还涉及到数据的长度,那为什…...

【含文档+PPT+源码】基于过滤协同算法的旅游推荐管理系统设计与实现
项目介绍 本课程演示的是一款基于过滤协同算法的旅游推荐管理系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套…...

SpringBoot @Value 注解使用
Value 注解用于将配置文件中的属性值注入到Spring管理的Bean中。 1. 基本用法 Value 可以直接注入配置文件中的属性值。 配置文件 (application.properties 或 application.yml) 配置文件定义需要注入的数据。 consumer:username: lisiage: 23hobby: sing,read,sleepsubje…...

Spring Boot 3.x 系列【3】Spring Initializr快速创建Spring Boot项目
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot版本3.0.3 源码地址:https://gitee.com/pearl-organization/study-spring-boot3 文章目录 前言安装JDK 17创建Spring Boot 项目 方式1:网页在线生成方式2&#…...

高频 SQL 50 题(基础版)_1667. 修复表中的名字
高频 SQL 50 题(基础版)_1667. 修复表中的名字 select user_id ,concat(upper(substring(name,1,1)),lower(substring(name,2))) as name from Users order by user_id...
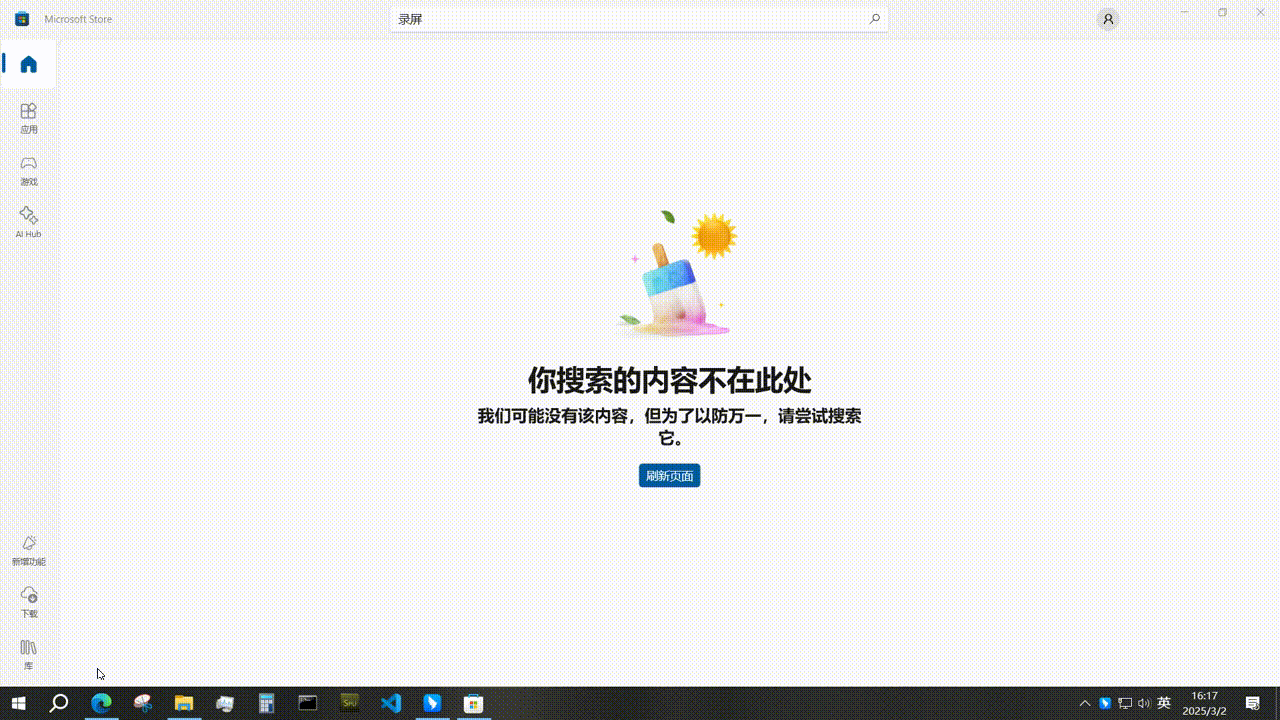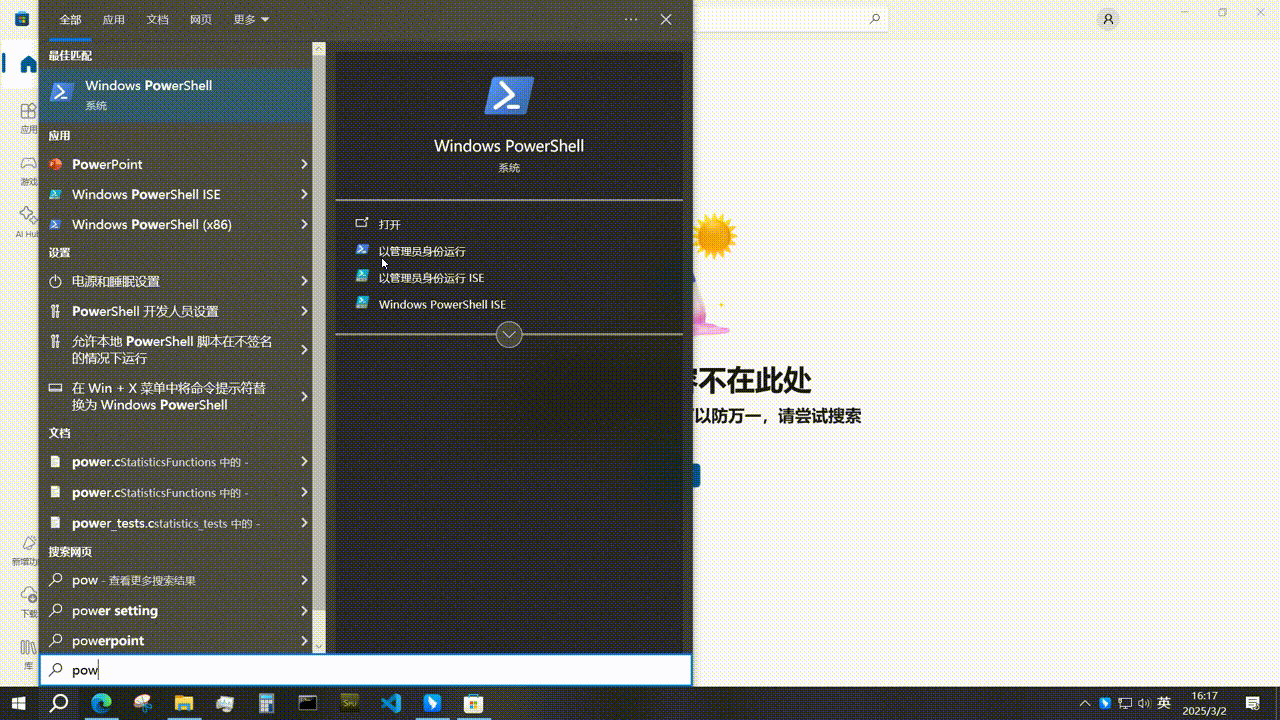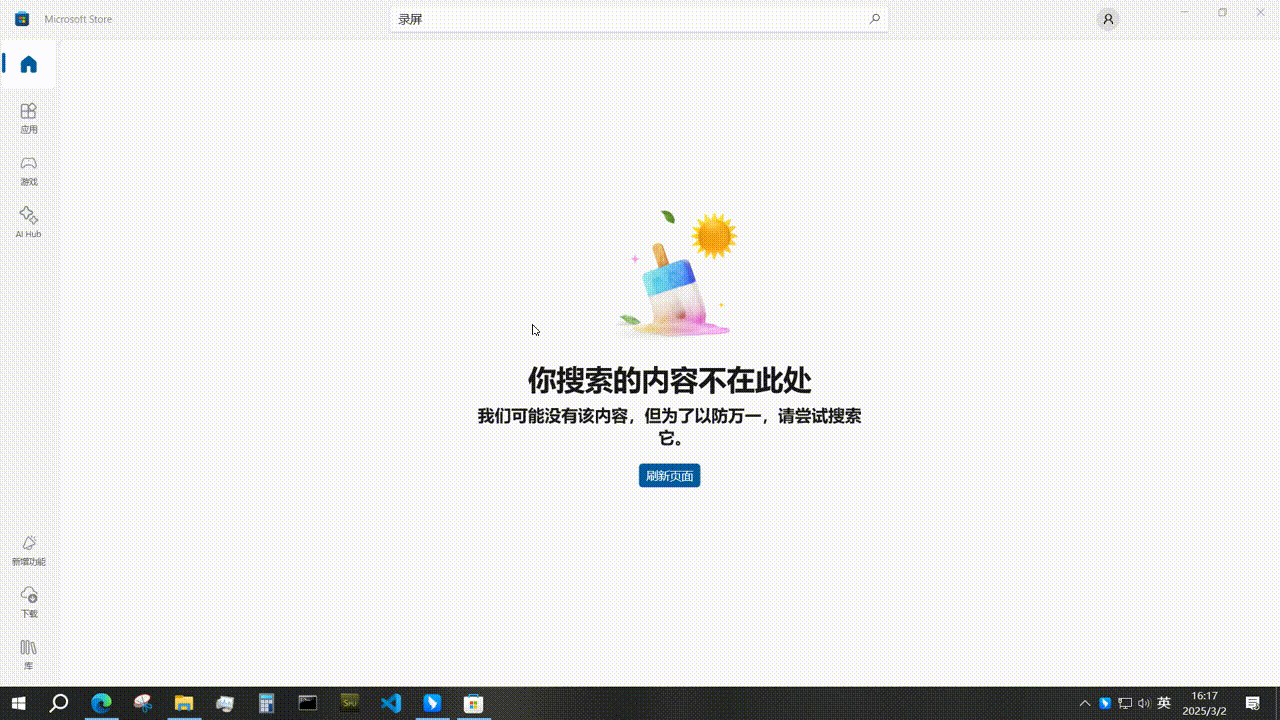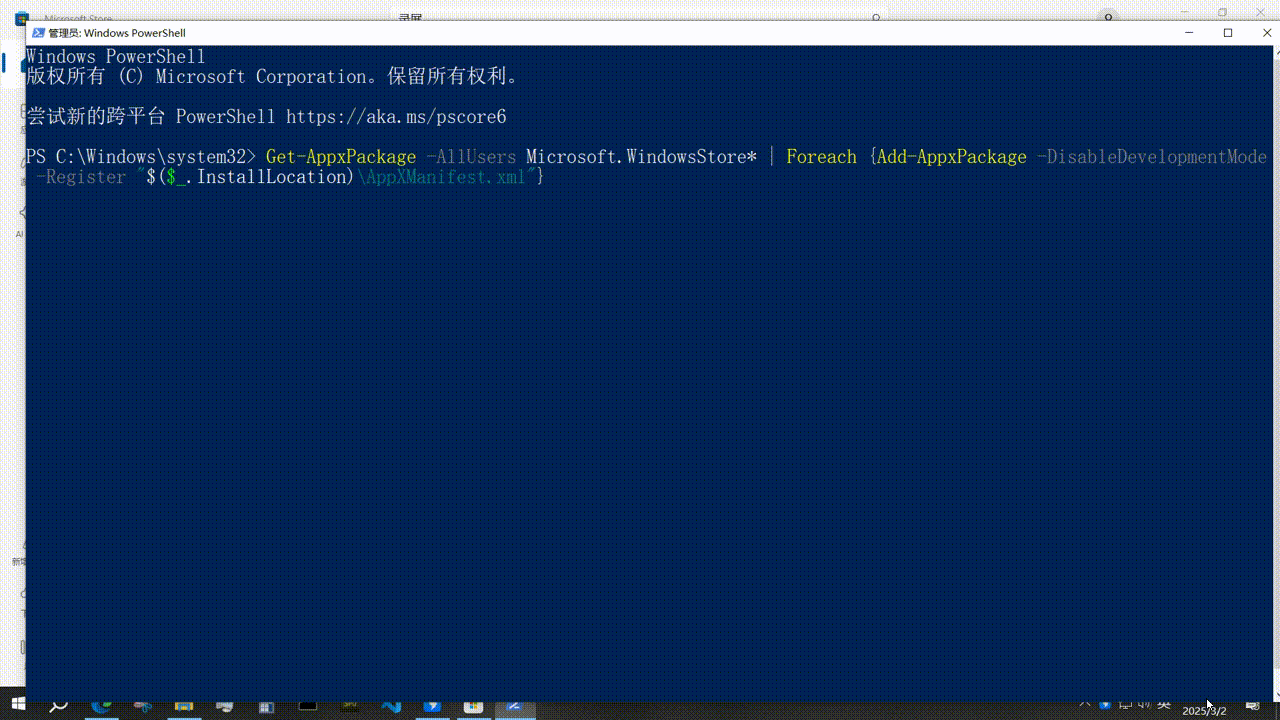
Windwos10 系统没有微软商店(Microsoft Store)怎么办?
操作方法 管理员身份打开power shell , 输入 Get-AppxPackage -AllUsers Microsoft.WindowsStore* | Foreach {Add-AppxPackage -DisableDevelopmentMode -Register “ ( ( (_.InstallLocation)\AppXManifest.xml”} 按下enter按键,就OK了...

c++同步机制
总结 多线程访问共享数据时需要加锁 多线程数据竞争 假如有一个变量shared_variable被10个线程共享,每个线程在循环中对shared_variable进行 1000 次累加操作,我们期望最终值为10000。 #include <iostream> #include <thread> #include …...

瑞萨MCU集成AI加速器:嵌入式开发者的边缘智能实战指南
1. 项目概述:当传统MCU巨头按下AI加速键最近在半导体圈里,一个消息引发了不小的讨论:瑞萨电子,这家在微控制器领域常年稳坐头把交椅的巨头,宣布要全面拥抱人工智能。你可能对这个名字有点陌生,但你的车里、…...

WarcraftHelper终极教程:5分钟搞定魔兽争霸3现代化优化
WarcraftHelper终极教程:5分钟搞定魔兽争霸3现代化优化 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》这款经典游戏在…...

用Python手把手复现NRBO优化算法:从数学公式到完整代码的保姆级教程
用Python手把手复现NRBO优化算法:从数学公式到完整代码的保姆级教程 优化算法在工程和科学计算中扮演着关键角色,而牛顿-拉弗森优化算法(NRBO)作为最新提出的智能优化方法,凭借其高效的收敛性能引起了广泛关注。本文将彻底拆解NRBO的核心机制…...

从能算到秒杀:零钱兑换与「最少硬币」的数学真相
如果说 279. 完全平方数 是在考你:👉 最少用几个平方数拼出一个数那 322. 零钱兑换 就是它的「现实版」:👉 最少用几枚硬币凑出一个金额这也是我第一次真正明白一句话:所有「最少数量」的问题,本质都是…...

【Feed 高并发架构实战】:雪花 ID + 三级缓存 + 计数旁路设计详解
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

量子机器学习噪声挑战与HPQS混合框架解析
1. 量子机器学习中的噪声挑战与HPQS解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,正在重新定义我们处理复杂模式识别问题的方式。与传统机器学习不同,QML利用量子态的叠加和纠缠特性,理论上可以在某些特定任务上实现指数级…...

蛋白质基础模型:从AlphaFold2到Chai-1的范式跃迁
1. 项目概述:一场悄然发生的蛋白质结构预测范式迁移最近在实验室跑完第7轮Chai-1的微调任务后,我盯着屏幕上跳出来的pLDDT值曲线,突然意识到:我们正在经历的不是一次工具升级,而是一场底层建模逻辑的彻底重写。标题里提…...
到底怎么选?)
别再只会用PWM调速度了!STM32驱动直流有刷电机,H桥的三种模式(单极/双极/受限)到底怎么选?
STM32驱动直流有刷电机的三种H桥模式深度解析与实战选型指南 在嵌入式电机控制领域,PWM调速早已成为基础技能,但真正决定系统性能的往往是H桥工作模式的选择。当你的电机出现异常发热、刹车响应迟缓或低速抖动时,问题很可能就出在模式选择不当…...

【文档翻译】QNX Neutrino RTOS 7.1用户手册 - 第五章 文件操作
本文翻译自BlackBerry官方提供的QNX Neutrino RTOS User’s Guide,仅供学习参考使用 第五章 文件操作 文章目录第五章 文件操作文件类型文件名和路径名绝对路径和相对路径点和点点目录没有硬盘字母以点开头的路径名扩展名路径空间映射文件名规则所有内容的存储位置…...

魔兽争霸III终极优化指南:让你的经典游戏在现代系统上焕发新生
魔兽争霸III终极优化指南:让你的经典游戏在现代系统上焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在Window…...