Python PDF文件拆分-详解
目录
使用工具
将PDF按页数拆分
将PDF的每一页拆分为单独的文件
将PDF按指定页数拆分
根据页码范围拆分PDF
根据指定内容拆分PDF
将PDF的一页拆分为多页
在日常生活中,我们常常会遇到大型的PDF文件,这些文件可能难以发送、管理和查阅。将PDF拆分成多个小文件是一个实用的解决方案,可以为我们带来多重好处。首先,拆分PDF可以提高文件的可读性,使用户更容易找到所需信息。此外,拆分后的文件更便于分享和协作,特别适用于团队项目,让不同成员能够同时处理各自负责的部分。同时,这种方法还能有效保护隐私,允许将敏感信息单独处理,从而降低数据泄露的风险。
这篇博客将探讨如何使用Python实现PDF文件拆分,主要涵盖以下几个方面的内容:
- 将PDF按页数拆分
- 将PDF的每一页拆分为单独的文件
- 将PDF按指定页数拆分
- 将PDF按页码范围拆分
- 将PDF按指定内容拆分
- 将PDF的一页拆分为多页
使用工具
要在Python中实现拆分PDF文件,可以使用Spire.PDF for Python库。该库主要用于在Python应用程序中生成和处理PDF文档,也支持将PDF转换为其他格式,例如图片,Word和Excel等。
安装 Spire.PDF
在开始之前,需要先安装 Spire.PDF 库。你可以在终端中运行以下命令进行安装:
pip install spire.pdf将PDF按页数拆分
在按页数拆分PDF文件时,你可以将PDF文档的每一页拆分为一个单独的文件,也可以将PDF文档按指定页数拆分。下面将对这两种方式逐一进行介绍。
将PDF的每一页拆分为单独的文件
Spire.PDF for Python提供了PdfDocument.Split()方法,支持将PDF文档按页拆分,生成的每个文件仅包含原始文档中的一页。具体实现步骤如下:
- 创建PdfDocument对象。
- 使用PdfDocument.LoadFromFile()方法打开PDF文档。
- 使用PdfDocument.Split()方法将PDF文档的每一页拆分为单独的PDF文档。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 创建PdfDocument对象
pdf = PdfDocument()
# 加载PDF文件
pdf.LoadFromFile("心理健康.pdf")# 将PDF文件拆分为多个PDF文件,每个文件仅包含原始PDF中的一页
pdf.Split("拆分PDF/第{0}页.pdf", 1)# 关闭PdfDocument对象
pdf.Close()

将PDF按指定页数拆分
将 PDF 文件按指定页数拆分的方法是通过创建新的 PDF 文档并将指定数量的页面插入其中来实现。具体实现步骤如下:
- 创建PdfDocument对象。
- 使用PdfDocument.LoadFromFile()方法打开PDF文档。
- 获取PDF文档的总页数。
- 使用循环按指定页数拆分PDF:
- 设置起始页和结束页。
- 创建新的PdfDocument对象。
- 使用PdfDocument.InsertPageRange()方法将当前页码范围内的页面插入到新PDF文档中。
- 使用PdfDocument.SaveToFile()方法保存生成的PDF文档。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 将PDF按指定页数拆分的方法
def split_pdf_by_page_count(input_file, page_count):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(input_file)# 计算总页数total_pages = pdf.Pages.Count# 按指定页数拆分PDFfor i in range(0, total_pages, page_count):# 创建新的PdfDocument对象new_pdf = PdfDocument()# 计算当前要插入的页码范围start_page = iend_page = min(i + page_count - 1, total_pages - 1) # 确保不超过总页数# 将当前页码范围的页面插入到新PDF中new_pdf.InsertPageRange(pdf, start_page, end_page)# 保存生成的文件new_pdf.SaveToFile("拆分PDF/" + f"{start_page + 1}-{end_page + 1}页.pdf")# 关闭新创建的PdfDocument对象new_pdf.Close()# 关闭原始PdfDocument对象pdf.Close()# 调用split_pdf_by_page_count方法将PDF文件按照每3页拆分
split_pdf_by_page_count("心理健康.pdf", 3)

根据页码范围拆分PDF
除了按页数拆分 PDF 文件外,你还可以选择将指定页码范围内的页面提取为单独的文件。该方法的实现步骤与按指定页数拆分类似,此处不再赘述。
实现代码:
from spire.pdf.common import *
from spire.pdf import *# 提取PDF中指定页码范围内的页面并保存为新文件的方法
def split_pdf_by_page_range(input_file, start_page, end_page, output_file):# 创建PdfDocument对象并加载PDF文件pdf = PdfDocument()pdf.LoadFromFile(input_file)# 创建新的PdfDocument对象new_pdf = PdfDocument()# 将指定页码范围内的页面插入到新PDF文档中new_pdf.InsertPageRange(pdf, start_page, end_page)# 保存生成的文件new_pdf.SaveToFile(output_file)# 关闭PdfDocument对象pdf.Close()new_pdf.Close()# 调用split_pdf_by_page_range方法,从PDF文件中提取第1-3页并保存为新文件
split_pdf_by_page_range("心理健康.pdf", 0, 2, "拆分PDF/指定页码范围.pdf")
根据指定内容拆分PDF
在某些情况下,你可能需要根据特定关键字或短语拆分 PDF。这种方法可以提取包含特定内容的页面,便于整理相关信息。以下代码会查找 PDF 每一页上的文本,如果找到指定关键字,则将该页面添加到新 PDF 中:
from spire.pdf.common import *
from spire.pdf import *# 提取包含特定关键字的页面到新PDF中的方法
def extract_pages_with_keyword(pdf_path, output_path, keyword):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(pdf_path)# 创建一个新的PdfDocument对象new_pdf = PdfDocument()# 遍历文档中的每一页for i in range(pdf.Pages.Count):page = pdf.Pages[i]# 创建PdfTextFinder实例finder = PdfTextFinder(page)# 定义文本查找参数finder.Options.Parameter = TextFindParameter.WholeWord# 查找特定文本results = finder.Find(keyword)# 如果找到了关键字if results:# 将当前页面添加到新文档中new_pdf.InsertPage(pdf, i)# 保存提取的结果文件new_pdf.SaveToFile(output_path)# 关闭PdfDocument对象new_pdf.Close()pdf.Close()# 调用extract_pages_with_keyword方法将PDF文件中包含特定关键字的页面保存为新文件
extract_pages_with_keyword("心理健康.pdf", "拆分PDF/含关键字页面.pdf", "问题")
将PDF的一页拆分为多页
在某些情况下,你可能需要将 PDF 文档的某一页拆分为两页或多页。在拆分时,你可以选择将该页面横向或竖向拆分。横向拆分时,拆分后的文档的每个页面的宽度等于原始宽度的1/拆分总页数;竖向拆分时,拆分后的文档的每个页面的高度等于原始高度的1/拆分总页数。
以下代码展示了如何将PDF文档的指定页面竖向或横向拆分为两页:
from spire.pdf.common import *
from spire.pdf import *# 将指定PDF页面横向或竖向拆分为多页的方法
def split_specific_pdf_page(pdf_path, output_folder, page_index, num_pages, split_direction='vertical'):# 创建PdfDocument对象pdf = PdfDocument()# 加载PDF文件pdf.LoadFromFile(pdf_path)# 获取指定页面if page_index < 0 or page_index >= pdf.Pages.Count:print("错误:指定的页面索引超出范围。")returnpage = pdf.Pages[page_index]# 创建一个新的PdfDocument对象newPdf = PdfDocument()# 移除所有页面边距newPdf.PageSettings.Margins.All = 0.0# 根据拆分方向设置新PDF的页面尺寸if split_direction == 'vertical':newPdf.PageSettings.Width = page.Size.WidthnewPdf.PageSettings.Height = page.Size.Height / float(num_pages)elif split_direction == 'horizontal':newPdf.PageSettings.Height = page.Size.HeightnewPdf.PageSettings.Width = page.Size.Width / float(num_pages)else:print("错误:无效的拆分方向,请选择'vertical'或'horizontal'。")return# 向新PDF添加一页newPage = newPdf.Pages.Add()# 设置布局格式为自动分页format = PdfTextLayout()format.Break = PdfLayoutBreakType.FitPageformat.Layout = PdfLayoutType.Paginate# 绘制内容 page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0), format)# 保存生成的文件newPdf.SaveToFile(f"{output_folder}/拆分第{page_index + 1}页.pdf")# 关闭PdfDocument对象newPdf.Close()pdf.Close()# 调用split_specific_pdf_page方法将PDF文件第1页竖向拆分为2页,0为当前页面的索引,2为拆分总页数
split_specific_pdf_page("心理健康.pdf", "拆分PDF", 0, 2, 'vertical')
# # 或者将PDF文件第1页横向拆分为2页
# split_specific_pdf_page("心理健康.pdf", "拆分PDF", 0, 2, 'horizontal') 以上就是使用Python实现拆分PDF文档的全部内容。感谢阅读!
相关文章:

Python PDF文件拆分-详解
目录 使用工具 将PDF按页数拆分 将PDF的每一页拆分为单独的文件 将PDF按指定页数拆分 根据页码范围拆分PDF 根据指定内容拆分PDF 将PDF的一页拆分为多页 在日常生活中,我们常常会遇到大型的PDF文件,这些文件可能难以发送、管理和查阅。将PDF拆分成…...

MacDroid for Mac v2.3 安卓手机文件传输助手 支持M、Intel芯片 4.7K
MacDroid 是Mac毒搜集到的一款安卓手机文件传输助手,在Mac和Android设备之间传输文件。您只需要将安卓手机使用 USB 连接到 Mac 电脑上即可将安卓设备挂载为本地磁盘,就像编辑mac磁盘上的文件一样编辑安卓设备上的文件,MacDroid支持所有 Andr…...

人大金仓国产数据库与PostgreSQL
一、简介 在前面项目中,我们使用若依前后端分离整合人大金仓,在后续开发过程中,我们经常因为各种”不适配“问题,但可以感觉得到大部分问题,将人大金仓视为postgreSQL就能去解决大部分问题。据了解,Kingba…...

阿里云 Qwen2.5-Max:超大规模 MoE 模型架构和性能评估
大家好,我是大 F,深耕AI算法十余年,互联网大厂技术岗。分享AI算法干货、技术心得。 欢迎关注《大模型理论和实战》、《DeepSeek技术解析和实战》,一起探索技术的无限可能! 一、引言 Qwen2.5-Max 是阿里云通义千问团队研发的超大规模 Mixture-of-Expert(MoE)模型,旨在通…...

C++ 标准库容器的常用成员函数
目录 C 标准库容器简介 通用成员函数 1. 大小相关 size() empty() max_size() 2. 元素访问 operator[] at(size_t n) front() back() 3. 修改容器 push_back(const T& value) pop_back() clear() insert() erase() 4. 迭代器相关 begin() end() rbegi…...

MySQL双主搭建-5.7.35
文章目录 上传并安装MySQL 5.7.35双主复制的配置实例一:172.25.0.19:实例二:172.25.0.20: 配置复制用户在实例 1 (172.25.0.19)上执行:在实例 2 (172.25.0.20)上执行&…...

Uniapp开发微信小程序插件的一些心得
一、uniapp 开发微信小程序框架搭建 1. 通过 vue-cli 创建 uni-ap // nodejs使用18以上的版本 nvm use 18.14.1 // 安装vue-cli npm install -g vue/cli4 // 选择默认模版 vue create -p dcloudio/uni-preset-vue plugindemo // 运行 uniapp2wxpack-cli npx uniapp2wxpack --…...

Vscode通过Roo Cline接入Deepseek
文章目录 背景第一步、安装插件第二步、申请API key第三步、Vscode中配置第四步、Deepseek对话 背景 在前期介绍【IDEA通过Contince接入Deepseek】步骤和流程,那如何在vscode编译器中使用deepseek,记录下来,方便备查。 第一步、安装插件 在…...

不同规模企业如何精准选择AI工具: DeepSeek、Grok 和 ChatGPT 三款主流 AI 工具深度剖析与对比
本文深入探讨了最近国内外主流的 DeepSeek、Grok 和 ChatGPT 三款主流 AI 工具的技术细节、性能表现、应用场景及局限性,并从技术能力、功能需求、成本预算、数据安全和合规以及服务与支持五个关键维度,详细分析了不同规模企业在选择 AI 工具时的考量因素…...

如何有效判断与排查Java GC问题
目录 一、GC的重要性与对性能的影响 (一)GC对性能的影响简要分析 1.GC暂停与应用停顿 2.GC吞吐量与资源利用率 3.GC对内存管理的作用:资源回收 4.GC策略与优化的选择 (二)GC的双刃剑 二、GC性能评价标准 &…...

【笔记】用大预言模型构建专家系统
最近闲庭漫步,赏一赏各个AI大语言模型芳容。也趁着时间,把倪海夏一家的天纪和人纪视频看完了,感谢倪先生和现在网络的知识分享,受益匪浅。但是发现看完,很多不错的知识都不能记录在脑子里,那用的时候岂不是…...

Android SystemUI深度定制实战:下拉状态栏集成响铃功能开关全解析
一、功能实现全景视图 目标场景:在Android 14系统级ROM定制中,为SystemUI下拉状态栏的QuickQSPanel区域新增响铃模式切换开关,实现静音/响铃快速切换功能。该功能需通过三层关键改造实现: 二、核心实现三部曲 1. 配置注入&…...

【Python】基础语法三
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解Python的函数、列表和数组。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! > 专栏选自ÿ…...
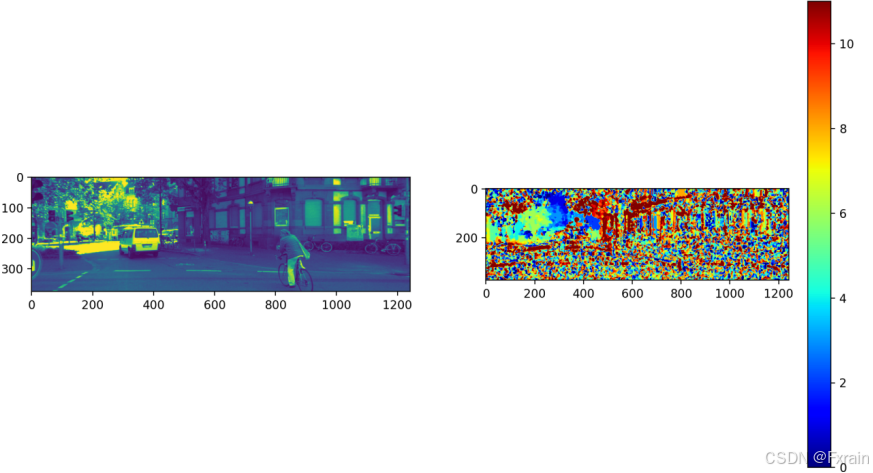
[Computer Vision]实验六:视差估计
目录 一、实验内容 二、实验过程 2.1.1 test.py文件 2.1.2 test.py文件结果与分析 2.2.1 文件代码 2.2.2 结果与分析 一、实验内容 给定左右相机图片,估算图片的视差/深度;体现极线校正(例如打印前后极线对)、同名点匹配…...

【 开发知识点 一 】 随机数生成器 /dev/urandom 和 /dev/random
文章目录 一、随机数生成器 是什么 ?二、为什么 需要 随机数生成器 ?三、随机数生成器 基本原理四、随机数生成器 三个输出接口五、随机生成器 应用1、简单应用2、项目应用一、随机数生成器 是什么 ? /dev/random 和 /dev/urandom 是 Linux 上的字符设备文件,它们是随机数…...

LabVIEW虚拟弗兰克赫兹实验仪
随着信息技术的飞速发展,虚拟仿真技术已经成为教学和研究中不可或缺的工具。开发了一种基于LabVIEW平台开发的虚拟弗兰克赫兹实验仪,该系统不仅能模拟实验操作,还能实时绘制数据图形,极大地丰富了物理实验的教学内容和方式。 …...

LLC谐振变换器恒压恒流双竞争闭环simulink仿真
1.模型简介 本仿真模型基于MATLAB/Simulink(版本MATLAB 2017Ra)软件。建议采用matlab2017 Ra及以上版本打开。(若需要其他版本可联系代为转换)针对全桥LLC拓扑,利用Matlab软件搭建模型,分别对轻载…...

TVbox蜂蜜影视:智能电视观影新选择,简洁界面与强大功能兼具
蜂蜜影视是一款基于猫影视开源项目 CatVodTVJarLoader 开发的智能电视软件,专为追求简洁与高效观影体验的用户设计。该软件从零开始编写,界面清爽,操作流畅,特别适合在智能电视上使用。其最大的亮点在于能够自动跳过失效的播放地址…...

Python 绘制迷宫游戏,自带最优解路线
1、需要安装pygame 2、上下左右移动,空格实现物体所在位置到终点的路线,会有虚线绘制。 import pygame import random import math# 迷宫单元格类 class Cell:def __init__(self, x, y):self.x xself.y yself.walls {top: True, right: True, botto…...

vue3学习-1(基础)
vue3学习-1(基础) 1. 开始API 风格选项式 API (Options API)组合式 API (Composition API) 快速创建个应用 2.基础1. 创建个应用2.模板语法3.响应式基础reactive() 的局限性[](https://cn.vuejs.org/guide/essentials/reactivity-fundamentals.html#limi…...

Java 进化之路:从 Java 8 到 Java 21 的重要新特性
Java 进化之路:从 Java 8 到 Java 21 的重要新特性 文章目录 前言(必看!!!)一、Java 8:划时代的革命 1. Lambda 表达式(史诗级更新)2. Stream API(数据操作新…...

ViGEmBus虚拟游戏控制器驱动:Windows游戏输入的革命性解决方案
ViGEmBus虚拟游戏控制器驱动:Windows游戏输入的革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 在Windows游戏世界中,…...
)
2026年实测AI论文平台榜单(安全合规版)
为解决学术写作中效率与合规两大核心痛点,以下精选8款高适配性AI论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度筛选,同时配套分场景精准选型方案与学术合…...
)
AI圈今日大事(2026-05-21)
AI圈今日大事(2026-05-21)1. 阿里云峰会:真武M890芯片 Qwen3.7-Max 双料齐发今日阿里云峰会上,阿里平头哥正式发布新一代训推一体AI芯片 真武M890:性能:相比前代真武810E提升3倍,内置144GB显存…...

java之微信机器人二次开发文档
WTAPI框架weixin ipad 协议 在微信个人号二次开发中的应用,涵盖技术架构、核心功能、开发流程及安全合规要点,为开发者提供系统化解决方案。 ⚡ 核心能力 好友管理:添加好友、删除好友、修改备注、创建标签、获取好友列表、搜索好友信息 消息…...

如何高效使用DazToBlender插件:专业3D资产迁移的完整实战指南
如何高效使用DazToBlender插件:专业3D资产迁移的完整实战指南 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender 你是否曾经为在Daz Studio和Blender之间转移3D角色而苦恼?DazToBl…...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

如何在Python中创建测试图像
原文地址:https://medium.com/itberrios6/how-to-make-a-test-image-in-python-1a6c2d41b6ab 学习如何制作测试图像 在计算机视觉和图像处理中,创建测试图像以更好地了解算法或滤波器将如何执行通常是有用的。测试图像是一个基准,可以将多种…...

QQ空间数据备份指南:三步骤永久保存你的数字青春
QQ空间数据备份指南:三步骤永久保存你的数字青春 【免费下载链接】QZoneExport QQ空间导出助手,用于备份QQ空间的说说、日志、私密日记、相册、视频、留言板、QQ好友、收藏夹、分享、最近访客为文件,便于迁移与保存 项目地址: https://gitc…...

k-Mode聚类算法原理与手写实现:专治分类数据的无监督学习利器
1. 项目概述:为什么k-Mode不是k-Means的“换皮版”,而是一把专治分类数据的手术刀你有没有遇到过这样的场景:手头有一批客户数据,字段全是“性别:男/女”、“城市:北京/上海/广州”、“会员等级:…...