提升系统效能:从流量控制到并发处理的全面解析
在当今快速发展的数字时代,无论是构建高效的网络服务、管理海量数据,还是优化系统的并发处理能力,都是技术开发者和架构师们面临的重大挑战。本文集旨在深入探讨几个关键技术领域,包括用于网络通信中的漏桶算法与令牌桶算法的原理及其应用场景,如何有效管理和查询海量数据的技术手段,以及将长链接转换为短链接并通过短信发送的实际操作流程。此外,我们还将介绍长链接与短链接之间对应关系的存储策略,以及提高系统并发能力的有效方法。通过详尽的分析与案例说明,希望能为读者提供一套全面而深入的知识体系,帮助大家更好地理解和应对这些技术挑战。无论你是软件开发人员、系统架构师,还是对相关领域感兴趣的探索者,相信本文都能为你带来有价值的见解和启示。
1.说说什么是漏桶算法
漏桶算法(Leaky Bucket Algorithm)是一种用于在网络通信中控制数据流的方式,它主要用来处理网络接口的数据传输速率。这个算法可以形象地理解为一个底部有漏洞的桶,这个桶以恒定的速率向外漏水。
漏桶算法的主要概念包括:
-
数据流入:当有数据到达时,这些数据就像水一样被倒入桶中。如果在某一时刻有大量的数据同时到达,超过桶的容量,那么超出部分的数据就会溢出,即被丢弃。
-
恒定流出率:不管进入桶中的数据量有多大,桶都以固定的速率将数据流出。这意味着即使短时间内有大量的数据输入,数据也会按照设定的最大流出速率平滑地发送出去。
-
桶的容量限制:桶有一个最大容量限制,一旦当前存储的数据量达到了这个上限,后续到达的数据将会被丢弃,直到桶中有足够的空间为止。
漏桶算法的应用场景
- 在网络通信中,用于防止突发性的大量数据对网络造成过载。
- 作为流量整形器使用,确保不同来源的数据流能够以稳定、可预测的速度发送到网络中。
和令牌桶算法的区别
与漏桶算法相对的是令牌桶算法(Token Bucket Algorithm),后者允许一定数量的突发流量,在桶内有足够的令牌时,可以一次性处理大量数据。而漏桶算法则强调的是输出流量的稳定性和平滑性。
希望这个解释能帮助您更好地理解漏桶算法的作用和工作原理。如果有更深入的问题或需要进一步的说明,请随时告诉我。
2.说说什么是令牌桶算法
令牌桶算法(Token Bucket Algorithm)是另一种用于网络流量控制和速率限制的重要机制,与漏桶算法相比,它提供了对突发流量更好的支持。下面是对令牌桶算法的详细解释:
核心概念
-
令牌生成:系统以固定的速率向桶中添加“令牌”。令牌可以被看作是一种权限,允许数据包通过网络接口发送出去。
-
数据传输:每当有一个数据包需要发送时,就需要从桶中取走一个或多个令牌(根据数据包的大小)。如果桶中有足够的令牌,数据包就可以立即发送;如果没有足够的令牌,数据包要么被缓存等待有足够的令牌,要么直接被丢弃,这取决于具体的实现。
-
桶的容量:桶有一个最大容量限制,意味着桶最多只能持有一定数量的令牌。即使系统以固定速率不断生成令牌,一旦桶满了,新的令牌就会被丢弃直到有空间为止。
应用场景
- 带宽管理:在不同的网络应用之间分配可用带宽,确保每个应用都能获得合理的网络资源。
- 速率限制:控制客户端对服务器的请求频率,防止因过高的请求率导致服务器过载。
- 处理突发流量:相比漏桶算法,令牌桶更能应对短期的数据爆发,因为它允许存储令牌并在短时间内使用这些令牌发送大量数据。
和漏桶算法的区别
虽然两者都用于流量控制,但它们的工作方式有所不同:
- 漏桶算法强调的是平滑输出流速,无论输入流如何变化,输出都是恒定的。
- 令牌桶则允许一定的灵活性,即能够处理一定程度的突发流量,只要桶内有足够的令牌。
总的来说,令牌桶算法提供了一种更加灵活的方式来进行流量控制和速率限制,特别适用于那些需要处理突发性高流量的应用场景。
3.数据库如何处理海量数据?
处理海量数据是现代数据库系统设计中的一个重要方面,随着数据量的不断增长,如何高效地存储、管理和查询这些数据成为了一个关键问题。以下是几种常见的策略和技术:
-
分区(Partitioning):将表或索引分割成更小、更易管理的部分。分区可以基于范围(如日期)、列表值(如地区代码)、哈希值或其他标准来实现。这样不仅可以提高查询性能,还能简化数据维护工作。
-
分片(Sharding):与分区类似,但通常应用于分布式数据库环境中。通过将数据水平切分并分布在多个数据库实例或服务器上,每个实例仅负责存储和处理特定子集的数据,以此来扩展数据库的容量和性能。
-
索引优化:为加速查询操作,合理设计和使用索引至关重要。这包括选择合适的索引类型(如B树、哈希索引等),以及确保索引覆盖常用的查询模式。
-
压缩技术:应用数据压缩技术可以减少存储空间需求,并且在某些情况下还能加快I/O操作的速度,因为需要读取的数据量减少了。
-
缓存机制:利用内存缓存频繁访问的数据,以减少对磁盘的直接访问次数,从而提高响应速度。例如,Redis或Memcached这样的内存数据库可以作为外部缓存层。
-
批处理和聚合:对于分析型查询,采用批处理方式预计算汇总信息,可以显著降低实时查询时的数据处理量。
-
高级存储技术:使用SSD等快速存储介质代替传统硬盘,或者采用分布式文件系统和对象存储方案,也可以有效提升海量数据的处理能力。
-
数据库调优:根据具体应用场景调整数据库配置参数,比如连接池大小、缓冲区大小等,也是提高数据库性能的有效方法之一。
-
使用大数据技术栈:当传统关系型数据库无法满足需求时,可以考虑使用Hadoop、Spark等大数据技术栈进行数据处理。
综上所述,处理海量数据涉及的技术手段多样,需要根据具体的业务需求、数据特性以及可用资源来综合考虑最适合的解决方案。
4.如何将长链接转换成短链接,并发送短信?
将长链接转换为短链接并发送短信的过程通常包括两个主要步骤:生成短链接和发送包含该短链接的短信。下面是详细的实现步骤:
生成短链接
-
选择短链接服务:首先,你需要选择一个短链接服务或自己搭建一个短链接系统。市面上有许多流行的短链接服务,如Bitly、TinyURL等,它们提供了API让你可以轻松地将长链接转换为短链接。
-
使用API生成短链接:
- 如果你选择了第三方服务,比如Bitly,你需要注册账号获取API密钥。
- 使用HTTP请求调用相应的API来生成短链接。例如,使用Bitly的API,你可以通过发送一个POST请求(附带你的API密钥和需要缩短的长链接)来获取短链接。
curl -H "Authorization: Bearer YOUR_ACCESS_TOKEN" \-H "Content-Type: application/json" \-d '{"long_url": "http://example.com/very/long/url"}' \https://api-ssl.bitly.com/v4/shorten
- 处理响应:API会返回一个JSON格式的响应,其中包含了生成的短链接。你需要解析这个响应以获取短链接。
发送短信
-
选择短信服务提供商:接下来,选择一个可靠的短信服务提供商,如Twilio、Nexmo(现Vonage)、阿里云短信服务等。这些服务商通常也提供API接口供开发者使用。
-
集成短信发送功能:
- 注册并登录到所选的服务商平台,获取必要的认证信息(如API密钥、SID等)。
- 使用服务商提供的API发送短信。你需要构造一个HTTP请求,其中包含接收者的手机号码、短信内容(这里插入之前生成的短链接)等信息。
以下是一个使用Twilio发送短信的例子:
from twilio.rest import Client# Your Twilio account SID and Auth Token
account_sid = 'your_account_sid'
auth_token = 'your_auth_token'
client = Client(account_sid, auth_token)message = client.messages.create(body="Check out this link: [SHORT_LINK]",from_='+1234567890', # your Twilio phone numberto='+0987654321' # recipient's phone number
)print(message.sid)
请确保替换上述代码中的占位符(如your_account_sid、your_auth_token、[SHORT_LINK]等)为实际值。
这样,你就完成了从长链接到短链接的转换,并通过短信发送给指定用户的过程。记得在真实的应用环境中妥善保管你的API密钥和其他敏感信息,避免泄露。
5.长链接和短链接如何互相转换?
长链接和短链接之间的转换通常涉及到使用特定的服务或工具来实现。以下是关于如何进行这两种转换的基本介绍:
长链接转短链接
将长链接转换为短链接一般需要借助第三方服务,这些服务提供了API接口,允许你通过编程方式生成短链接。
-
选择短链接服务:首先,你需要选择一个提供短链接服务的平台,如Bitly、TinyURL等。不同的服务可能有不同的功能和限制。
-
注册并获取API密钥:大多数短链接服务都需要你注册账号,并从中获取API密钥或类似的身份验证信息。
-
调用API生成短链接:
- 以Bitly为例,你可以发送HTTP请求到其API端点,并在请求中包含你的API密钥和想要缩短的长链接。
- 下面是一个简单的示例(Python代码)展示如何使用requests库与Bitly API交互来生成短链接:
import requestsurl = "https://api-ssl.bitly.com/v4/shorten"
headers = {"Authorization": "Bearer YOUR_ACCESS_TOKEN","Content-Type": "application/json"
}
data = {"long_url": "http://example.com/very/long/url"
}response = requests.post(url, headers=headers, json=data)
short_link = response.json().get("link")
print(short_link)
请确保替换YOUR_ACCESS_TOKEN为你的实际Bitly访问令牌。
短链接转回长链接
有些情况下,你也可能需要从短链接还原出原始的长链接。这同样可以通过查询短链接服务来完成,但不是所有的服务都公开支持这种操作。
-
直接访问短链接:最简单的方法是直接通过浏览器访问短链接,然后查看地址栏中的跳转目标。这种方法适用于手动操作,不适合程序化处理。
-
利用API(如果服务提供商支持):某些短链接服务可能会提供API接口用于扩展短链接。例如,Bitly就提供了这样的功能。你可以向相应的API端点发送请求,并接收返回的长链接信息。
以下是一个基于Bitly的Python示例,用于展开短链接:
import requestsurl = "https://api-ssl.bitly.com/v4/expand"
headers = {"Authorization": "Bearer YOUR_ACCESS_TOKEN","Content-Type": "application/json"
}
data = {"bitlink_id": "bit.ly/your_short_link"
}response = requests.post(url, headers=headers, json=data)
long_url = response.json().get("long_url")
print(long_url)
同样,请记得替换YOUR_ACCESS_TOKEN和bit.ly/your_short_link为实际值。
请注意,具体的操作步骤会根据所使用的短链接服务而有所不同。务必查阅相关服务的官方文档以获得最准确的信息。
6.长链接和短链接的对应关系如何存储?
长链接和短链接的对应关系存储是实现短链接服务的关键部分之一。为了有效地管理这种映射关系,通常采用数据库来存储这些信息。以下是几种常见的做法:
数据库选择
-
关系型数据库:如MySQL、PostgreSQL等,适合用于存储结构化数据。你可以创建一个表来保存长链接和短链接的映射关系。例如,在MySQL中可以这样设计表结构:
CREATE TABLE url_mapping (id BIGINT AUTO_INCREMENT PRIMARY KEY,short_url VARCHAR(255) NOT NULL UNIQUE,long_url TEXT NOT NULL,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP );这种方法简单直接,适用于大多数场景。
-
NoSQL数据库:如MongoDB、Redis等,对于某些需要高并发读写的场景可能更加合适。
- 使用MongoDB时,可以将每条记录作为一个文档存储,包含
short_url和long_url字段。 - Redis则可以用作缓存层,利用其哈希或字符串数据结构来存储映射关系,以加快访问速度。
- 使用MongoDB时,可以将每条记录作为一个文档存储,包含
存储策略
-
持久化存储:无论是使用关系型数据库还是NoSQL数据库,都需要确保数据的持久化存储,以便在系统重启后仍然能够正确地进行长链接与短链接之间的转换。
-
缓存机制:为了提高查询效率,尤其是当短链接被频繁访问时,可以在应用层面引入缓存机制(比如使用Redis)。通过缓存热门的短链接对应的长链接,减少对主数据库的直接访问压力。
关键考虑因素
- 唯一性保证:短链接需要保证全局唯一性,这通常通过数据库的唯一约束或者生成算法本身来实现。
- 扩展性和性能:随着数据量的增长,如何保持系统的高效运行是一个重要考量点。这包括但不限于数据库的选择、索引的设计、分片策略等。
- 安全性:保护存储的数据不被未授权访问,特别是涉及到用户敏感信息时尤为重要。
通过合理的设计和选择合适的工具和技术,可以有效地管理和维护长链接与短链接之间的映射关系,从而支持稳定可靠的短链接服务。
7.如何提高系统的并发能力?
提高系统的并发能力是构建高效、可扩展应用的关键。以下是一些常见且有效的策略和技术,可以帮助提升系统的并发处理能力:
1. 优化代码和算法
- 减少锁的使用:尽量减少或避免使用全局锁,考虑使用更细粒度的锁(如行级锁),或者采用无锁数据结构。
- 异步编程模型:利用异步I/O操作来提高资源利用率,尤其是在I/O密集型应用中效果显著。
- 算法优化:选择更适合并发环境的数据结构和算法,例如线程安全的集合类。
2. 负载均衡
- 硬件负载均衡器:通过硬件设备分散到多个服务器上的请求,可以有效分担单个服务器的压力。
- 软件负载均衡:如Nginx、HAProxy等,不仅能够分配流量,还可以提供健康检查等功能。
3. 缓存机制
- 本地缓存:在应用内部使用缓存存储频繁访问的数据,减少对数据库的直接查询。
- 分布式缓存:如Redis、Memcached,适合用于大规模分布式系统中的缓存层,支持高并发读写操作。
4. 数据库优化
- 索引优化:合理设计索引以加快查询速度。
- 读写分离:通过主从复制实现读写分离,减轻单一数据库实例的压力。
- 分库分表:根据业务逻辑将数据分布到不同的数据库实例或表中,降低单点负载。
5. 微服务架构
- 将大型应用程序分解为一系列小型、独立的服务,每个服务负责执行特定的功能,并可以通过独立部署和扩展来适应不同的负载需求。
6. 消息队列
- 使用消息队列(如RabbitMQ、Kafka)解耦生产者与消费者,平滑突发流量,允许异步处理任务,从而增强系统的弹性。
7. 水平扩展
- 增加更多的服务器节点而不是升级现有硬件(垂直扩展)。这通常涉及到分布式系统的设计原则,确保系统能够在多个节点之间平衡工作负荷。
8. 性能监控与调优
- 实施全面的性能监控,及时发现瓶颈并进行针对性优化。
- 利用APM(Application Performance Management)工具帮助分析应用性能,识别慢查询和潜在问题。
采取上述措施时,应基于具体的应用场景和需求来进行评估和实施。每种方法都有其适用范围和局限性,因此可能需要组合多种策略来达到最佳效果。
相关文章:

提升系统效能:从流量控制到并发处理的全面解析
在当今快速发展的数字时代,无论是构建高效的网络服务、管理海量数据,还是优化系统的并发处理能力,都是技术开发者和架构师们面临的重大挑战。本文集旨在深入探讨几个关键技术领域,包括用于网络通信中的漏桶算法与令牌桶算法的原理…...

计算机毕业设计SpringBoot+Vue.js贸易行业CRM系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

从头开始学SpringBoot—02ssmp整合及案例
《从头开始学SpringBoot》系列——第二篇 内容包括: 1)SpringBoot实现ssmp整合 2)SpringBoot整合ssmp的案例 目录 1.整合SSMP 1.1整合JUnit 1.2整合Mybatis 1.2.1导入对应的starter 1.2.2配置相关信息 1.2.3dao(或是mapper&…...

0301 leetcode - 1502.判断是否能形成等差数列、 682.棒球比赛、657.机器人能否返回原点
1502.判断是否能形成等差数列 题目 给你一个数字数组 arr 。 如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数列就称为 等差数列 。 如果可以重新排列数组形成等差数列,请返回 true ;否则,返回 false…...
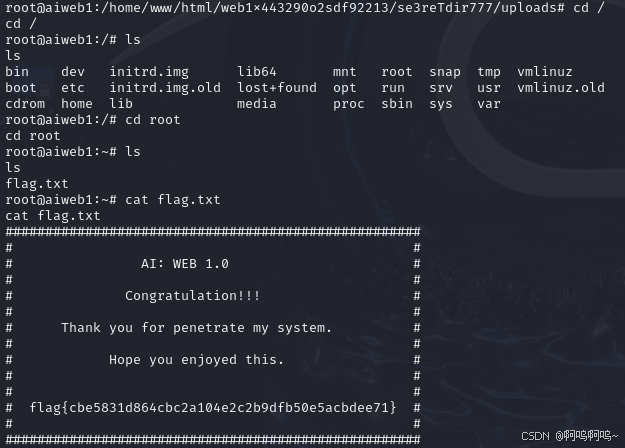
Vulnhub靶机——AI-WEB-1
目录 一、实验环境 1.1 攻击机Kali 1.2 靶机下载 二、站点信息收集 2.1 IP扫描 2.2 端口扫描 2.3 目录扫描 三、漏洞利用 3.1 SQL注入 3.2 文件上传 四、权限提升 4.1 nc反弹连接 4.2 切换用户 一、实验环境 1.1 攻击机Kali 在虚拟机中安装Kali系统并作为攻击机 1.2 靶机下载 (…...

无人系统:未来科技的智能化代表
无人系统(Unmanned Systems)是指在不依赖人类直接干预的情况下,通过自主或远程控制方式完成任务的系统。随着科技的不断进步,特别是在人工智能、机器人学、传感技术、通信技术等领域的突破,无人系统在各行各业中得到了…...

在Docker中部署DataKit最佳实践
本文主要介绍如何在 Docker 中安装 DataKit。 配置和启动 DataKit 容器 登陆观测云平台,点击「集成」 -「DataKit」 - 「Docker」,然后拷贝第二步的启动命令,启动参数按实际情况配置。 拷贝启动命令: sudo docker run \--hostn…...

进程的状态 ─── linux第11课
目录 编辑 补充知识: 1.并行和并发 分时操作系统(Time-Sharing Systems) 实时操作系统(Real-Time Systems) 进程的状态(操作系统层面) 编辑 运行状态 阻塞状态 状态总结: 挂起状态 linux下的进程状态 补充知识: …...

MySQL数据库基本概念
目录 什么是数据库 从软件角度出发 从网络角度出发 MySQL数据库的client端和sever端进程 mysql的client端进程连接sever端进程 mysql配置文件 MySql存储引擎 MySQL的sql语句的分类 数据库 库的操作 创建数据库 不同校验规则对查询的数据的影响 不区分大小写 区…...

什么是 jQuery
一、jQuery 基础入门 (一)什么是 jQuery jQuery 本质上是一个快速、小巧且功能丰富的 JavaScript 库。它将 JavaScript 中常用的功能代码进行了封装,为开发者提供了一套简洁、高效的 API,涵盖了 HTML 文档遍历与操作、事件处理、…...

Redis Desktop Manager(Redis可视化工具)安装及使用详细教程
一、安装包下载 直接从官网下载,官网下载链接地址:Downloads - Redis 二、安装步骤 2.1说明 Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也也被称作Redis可视化工具。 支持命令控制台操作,以及常用&…...

[KEIL]单片机技巧 01
1、查看外设寄存器的值 配合对应的芯片开发手册以查看寄存器及其每一位的意义,可以解决90%以上的单纯的片内外设bug,学会如何通过寄存器的值来排外设上的蛊是嵌入式开发从小白到入门的重要一步,一定要善于使用这个工具,而不是外设…...

云原生监控篇——全链路可观测性与AIOps实战
引言:监控即生命线 2023年某全球支付平台因一次未被捕获的数据库连接泄漏,导致每小时损失120万美元。而另一家社交巨头通过实时异常检测系统,在30秒内自动隔离了大规模DDoS攻击。这两个案例揭示了云原生时代的核心生存法则——监控不是可选项…...

C# 13与.NET 9革新及工业开发应用
摘要 微软推出的C# 13与.NET 9以“高效且智能”为导向,具备扩展类型、半自动属性、锁对象优化等十大革新。本文深入剖析新特性于工业级开发的应用场景,包含性能优化策略、AI集成方案以及EF Core实战技巧,为开发者提供从理论到实践的完整指引…...

Linux系统之DHCP网络协议
目录 一、DHCP概述 二、DHCP部署实操 2.1、安装DHCP软件 2.2、拷贝配置文件 2.3、配置文件详解 2.4、重启软件服务 2.5、新开一台服务器,查看dhcp地址获取 一、DHCP概述 DHCP(Dynamic Host Configuration Protocol)是一种应用层网络协…...

【Linux】【网络】不同子网下的客户端和服务器通信其它方式
【Linux】【网络】不同子网下的客户端和服务器通信其它方式 那么,在 NAT 环境下,应该如何让内网设备做为服务器,使内网设备被外部连接? 1 多拨 部分运营商,支持在多个设备上,通过 PPPoE 登录同一个宽带账…...

【C++/数据结构】栈
零.导言 栈是一种数据结构,在后续的学习中可能经常使用,因此我们今天就来学习如何实现栈,以更好地使用它。 一.栈的实现 栈的形式如下: #include<iostream> #include<cassert>using namespace std;typedef int Stack…...

Qt 对象树详解:从原理到运用
1. 什么是对象树? 对象树是一种基于父子关系的对象管理机制。在 Qt 中,所有继承自 QObject 的类都可以参与到对象树中。 当一个对象被设置为另一个对象的父对象时,子对象会被添加到父对象的内部列表中,形成一种树状结构。 Qt 提…...

【软路由】ImmortalWrt 编译指南:从入门到精通
对于喜欢折腾路由器,追求极致性能和定制化的玩家来说,OpenWrt 无疑是一个理想的选择。而在众多 OpenWrt 衍生版本中,ImmortalWrt 以其更活跃的社区、更激进的特性更新和对新硬件的支持而备受关注。 本文将带你深入了解 ImmortalWrt࿰…...

【智能音频新风尚】智能音频眼镜+FPC,打造极致听觉享受!【新立电子】
智能音频眼镜,作为一款将时尚元素与前沿科技精妙融合的智能设备,这种将音频技术与眼镜形态完美结合的可穿戴设备,不仅解放了用户的双手,更为人们提供了一种全新的音频交互体验。新立电子FPC在智能音频眼镜中的应用,为音…...
)
手把手教你用高云FPGA的Video Frame Buffer IP搞定OV7725摄像头到HDMI显示(附源码)
高云FPGA视频处理实战:OV7725摄像头数据缓存与HDMI输出全解析 在嵌入式视觉系统开发中,FPGA因其并行处理能力和低延迟特性,成为实时视频处理的理想选择。高云FPGA作为国产芯片的代表,其Video Frame Buffer等硬核IP为开发者提供了高…...

微信小程序二维码生成实战指南:weapp-qrcode高效解决方案
微信小程序二维码生成实战指南:weapp-qrcode高效解决方案 【免费下载链接】weapp-qrcode 微信小程序快速生成二维码,支持回调函数返回二维码临时文件 项目地址: https://gitcode.com/gh_mirrors/weap/weapp-qrcode 在微信小程序开发中,…...

CANN/asc-devkit同步通知API文档
asc_sync_notify 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcod…...

机器学习论文有效阅读:三层穿透法定位技术杠杆点
1. 这不是“读论文”,而是“拆解模型生长的土壤”你有没有过这种体验:打开一篇顶会论文,标题写着《Neural Architecture Search with Reinforcement Learning》,摘要读得热血沸腾,结果翻到Methodology部分,…...

容器编排:Kubernetes高级调度策略
容器编排:Kubernetes高级调度策略 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊Kubernetes高级调度策略这个重要话题。作为一个全栈开发者,Kubernetes已经成为容器编排的标准。今天就来分享一下Kubernetes的高级调…...
)
大模型时代,软件开发行业的新玩法(2026 深度复盘)
摘要 2026 年,大模型已从 “辅助工具” 进化为软件开发的核心生产引擎,彻底重构需求、设计、编码、测试、运维全链路逻辑。传统 “人写代码” 的模式被颠覆,人机共生、AI 主导执行、人类决策审核成为行业新常态。本文结合最新行业实践、数据案…...

java springboot-vue社区资源共享系统 社区活动报名系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述技术栈核心功能模块系统架构设计部署方案扩展性设计项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目概述…...
)
农业信息智能化种植系统(10079)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

JWT密钥轮换缺陷与零停机热修复实战指南
1. 这不是一次普通升级,而是一次密钥信任体系的临界点崩塌Seedance2.0 v2.0.3发布不到72小时,我在给客户做例行安全巡检时,发现一个反直觉的现象:所有新签发的JWT令牌在旧版本客户端(v2.0.2)上验证失败&…...

Wireshark深度解析:HTTP/1.1协议层隐写与pcapng元数据取证
1. 这不是一次普通的数据包分析,而是一场“协议层藏宝游戏”Wireshark实战:解密http1.pcapng中的隐藏flag——光看标题,你可能以为这只是又一篇教你怎么点开Filter框、输http然后截图的入门教程。但实际操作中,我连续三次在http1.…...