【大厂AI实践】清华:清华古典诗歌自动生成系统“九歌”的算法
【大厂AI实践】清华:清华古典诗歌自动生成系统“九歌”的算法
🌟 嗨,你好,我是 青松 !
🌈 自小刺头深草里,而今渐觉出蓬蒿。
文章目录
- **01 自动作诗缘起**
- **1. 诗歌自动写作**
- **02 九歌的模型算法**
- **1. 任务描述与研究框架**
- **2. 针对提升文学表现力的五个层面的算法研究**
- **03 九歌系统介绍**
- **04 自动作诗与知识图谱**
导读:本文将介绍清华大学THUNLP实验自研的具有文学表现力的中文古典诗歌自动生成系统“九歌”的算法,主要包括以下几方面内容:
- 自动作诗缘起
- 九歌的模型算法
- 九歌系统介绍
- 自动作诗与知识图谱
01 自动作诗缘起
1. 诗歌自动写作
① 何为诗歌自动写作

诗歌自动写作,是用户给定某种形式的输入,比如关键词、语句段落、图片等,由生成模型依据输入生成一首完整的诗歌,所生成的诗歌,既要满足一定的形式要求,比如长度、平仄,又要满足一定的语义要求,比如语句通顺,连贯一致等。
② 诗歌自动写作的研究价值
- 初心:探索机器智能

这个问题具有非常丰富的研究价值,而我们做它的初心是探索机器智能。人工智能之父Alan Turing就曾对人工智能写诗有过描述和设想。在史称图灵-杰斐逊辩论的讨论和1950年其关于图灵测试的论文中都有所体现。图灵认为人工智能是有可能写出有韵律的诗歌并且能对诗中的格律意象有一定的理解。

人工智能的经典任务是围棋,它考验的是逻辑推理能力,而诗歌自动创作考验的是创造能力。假设整个汉字集中有约一万个字,那么所有可能的七律的数量,远大于围棋棋盘可能的盘面数和宇宙中所有的原子数。我国著名的科幻小说家刘慈欣在短篇小说《诗云》一书中构想了一个高级智能文明,能够把所有诗歌的可能情况全部生成并保存下来,但没有办法去找出其中真正有价值的好诗歌。如何从海量可能性中的把前人没有创作过的、具有文学价值的诗歌给寻找或生成出来,就很具有挑战性。
- 研究方面

这个任务也利于我们去研究人类的智能。根据多元智能理论,语言智能是人类智能的重要组成部分,而诗歌,尤其是中文古典诗歌,是一种非常特殊的语言形式,具有多种优点,是研究可计算性创造力的非常好的切入点。把这两者结合在一起,利于我们未来构建真正的类人AI。
- 应用方面

除了研究价值之外,这个研究方向也在诸多领域有着丰富的应用场景和商业价值,所以在开发九歌系统之前市面也有非常多的写诗软件。而社会各界人士,包括国内外的一些作家、诗人、大学教授,也对机器写诗有了越来越正面的评价。
02 九歌的模型算法
接下来介绍整个系统里面到底用了什么样的算法,做了什么样的模型。
1. 任务描述与研究框架

诗歌生成,我们可以广义地将其定义成篇章级文学性文本的条件生成任务。

为了更好的提高生成诗歌的质量,我们去关注中文古典诗歌的文学表现力,因为诗歌是个文学体裁,可能不同于评论和商品描述,需要更多地注意可读性和文学性。所以我们拆解了文学表现力的两个层面,一是文本质量,这是表现力的基础。二是审美特征,这是诗歌作为文学体裁区别于其他文本的最大特色。
文学质量方面,我们关注连贯性、扣题性。审美特征方面,我们关注新颖性、风格化、情感化。对于所有的方面,我们都做了逐一的系统化研究,也都发了不同的paper,并对这些技术做了工程化的实现,最终集成了我们的九歌系统。可以看到这几个点和诗歌的广义描述是一一对应的,连贯性对应篇章性,扣题性对应条件生成,审美特征对应文学性。
2. 针对提升文学表现力的五个层面的算法研究
① 连贯性

由于人类创作的写诗的句子之间都是有紧密衔接和自然过渡的,而且这些句子作为整体,其主题意境有较好的一致性。而机器生成的诗作,可能会存在前后主题不一致,比如这首春风,前两句写了一个非常和煦的初春晚冬景色,后两句变为描写边塞的怀古的非常消极的感慨,中间不存在任何过渡,连贯性并不好。
- 问题原因探究

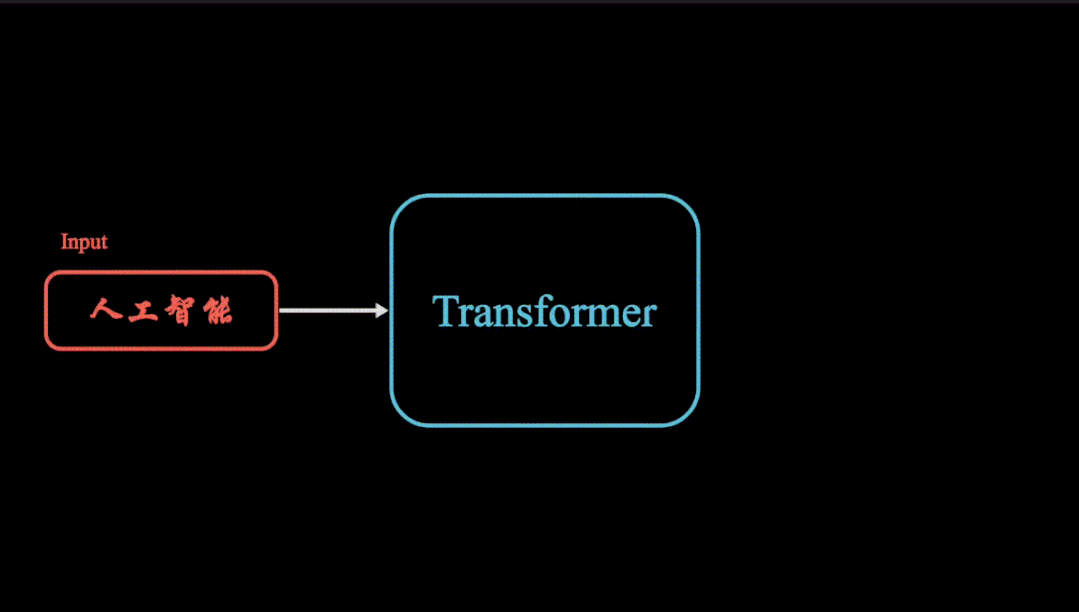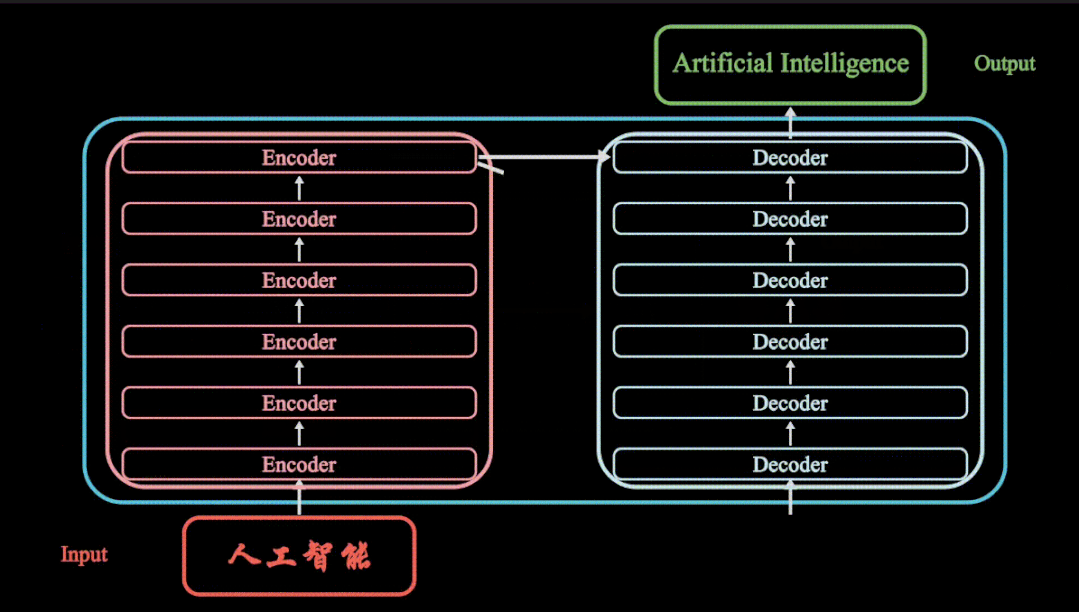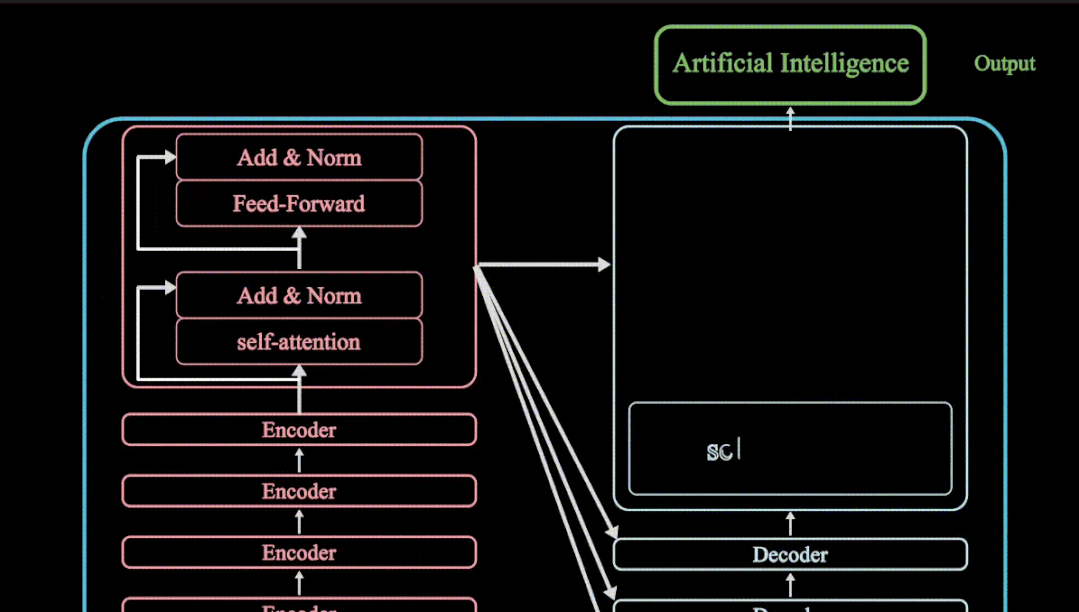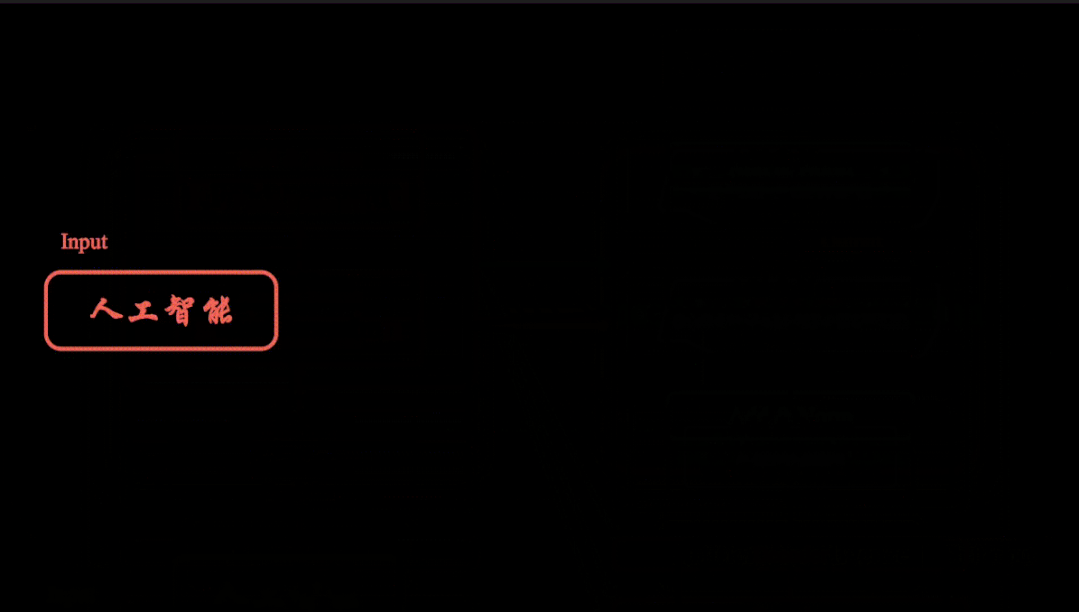
之所以出现这个问题,主要是之前诗歌生成的方法对于上文的利用方式不恰当而造成的。之前使用了单一历史(上文)向量方法,它存在三种问题如图所示。另外一种被使用的方法是拼接完整上文语句,但我们发现如果模型的容纳能力(capacity)不够,对于长的输入序列会出现明显的性能下降。
- 解决思路之显著性线索模型

为了解决这个问题,我们首先提出了一个显著性线索模型(Salient Clue Model),这个模型的灵感来源于《文心雕龙·章句》的“意脉”一词。

为了实现这一点,我们提出显著性线索模型,设计思路是在一首诗的生成过程中,对每一诗句丢弃其中没有实际语义的部分,比如虚词,并使用上文中具有显著语义的局部内容来代替完整上文,形成显著性线索以引导下文生成。
因为我们使用局部上文来替代完整上文,所以可以避免过多的约束。同时应用显著上文帮助我们减少干扰,增强关联。而使用动态构建整个线索骨架而非预先指定线索的方式,可以增加创造性和灵活性。

这一模型的核心在于如何计算每个字的显著性,我们应用了两部分信息。一部分是基于整个语料库静态计算出来的TF-IDF值,作为全局显著性。另外在生成过程中,两个句子之间的attention矩阵,作为动态局部显著性。比如我们可以把这个attention矩阵按列加和,就可以得到输入端每个字的局部显著性,之后我们提出了显著性选择算法,进一步过滤掉里面不是那么显著的词,再整合到全局显著性中做加权,最后就可以把鸿雁这个关键意象挑选出来。

我们采用自动评测和人工评测相结合的方式进行诗歌评测,自动评测采用BLEU,人工评测会找一些专家依据不同的指标按一到五分打分,通过对绝句的实验可以表明诗歌的连贯性和整体质量提升最为明显,如图所示。

在实例中可以看出,模型能对关键意象进行选择,来引导诗歌最后一句生成高度相关的落叶这一意象。
- 进一步优化之工作记忆模型

这个做法存在的问题是,在每个句子中挑选多少个显著的字,这是一个人为指定的超参数。如果挑多了会造成冗余,少了又会漏掉一些关键信息。我们其实更倾向于要一种更加灵活动态的方法去自动决定每句中有多少个关键的显著的内容需要保留,而不需要人工指定。对于这一点,我们参考了心理语言学中关于上下文连贯性的描述,它认为只要我们能够把内容和存在于working memory中的语义连在一起,就能够实现连贯性。working memory是人类大脑中存在的一个具有有限容纳能力的结构,用来存储临时的信息,可以用来处理后面的决策等。我们模拟这个working memory,提出了工作记忆模型。

这个模型有不同的记忆模块,首先有一个历史记忆模块(History Memory M1),类似于前面讲的显著性线索模型,也是从每个生成的句子中挑那些最显著的token写进去。但区别在于,这些模块是动态更新擦除的,在生成过程中如果填满了,会自动选择比较老的,比较不相关的给覆盖掉,以此我们能维护相互独立、有限、多个记忆槽,既能提供足够的容纳能力去维护部分远距离信息,又不会无限的膨胀。

还有一个局部记忆模块(Local Memory M2),用来存储上一句生成的诗句,充当一种完整近距离上文信息,以此来促进对仗句等强语义关联内容的生成。

在做记忆模块读取的时候,所有不同模块会统一读取,模型就可以自动决定要关注近距离的还是远距离的不同的信息,从而维护了整首诗在意境上的关联性。
② 扣题性

另外一个文本质量的层面是扣题性,因为诗歌生成是一种条件生成任务,我们希望输入的内容都可以在生成的诗歌中得到完整的体现来提升用户体验。传统诗歌生成会存在遗漏部分输入信息的现象,这主要是由于对于关键词的应用方式不恰当而造成的。
传统有两种方法来应用关键词,一种是多个关键词压缩入单一主题向量,用以引导生成,(向量中)关键词混杂会导致关键词包含率下降。另一种是关键词逐句插入,这种方式的弊端在于当输入关键词数小于句子数时,需要应用关键词扩展机制,而且生成的诗歌过分依赖于用户输入的关键词词序导致了诗歌生成不够灵活。
- 解决思路之主题记忆模块与主题追踪机制

我们做的工作,是在工作记忆模型中加入了一个新的模块,主题记忆模块(Topic Memory M3),它会显式且独立地存储每一个主题词。因为这些关键词是显式存储读取的,关键词不会混杂,关键词的包含率就会上升。同时独立存储读取,意味不存在相互之间词序上的依赖,这让生成诗歌的主题表达的形式和顺序都更加灵活。
同时我们还设计了一个主题追踪机制(Topic Trace),在生成过程中用更加显式的方式来记录每个主题表达与否,以此来提高其覆盖率。

通过对于绝句的测试,平均来说我们能做到输入关键词83%都能在诗歌中生成出来,远超之前的几个baseline model。
- 用户输入为语句/段落时出现的新问题

除了关键词之外,用户还倾向于输入一个完整的语句或者段落来表示主题。如何去处理呢?在工程化上的pipeline就是先做中文分词,之后做关键词抽取,再把抽取得到的多个关键词输入模型生成。但这个pipeline中分词和抽取都有误差,而且肯定会有信息损失,这会导致我们无法生成目标诗句。
我们发现现代文和古诗文的词表有78%的重合,两者可以看成同一种语言上面的两种不同的风格。我们提出的解决方案是:文本风格转换——把用户的输入直接转换为古典诗句,以此最大程度的保留用户提供的主题信息。
- 解决方案之实例支撑的风格转换模型

文本风格转换之前有两种不同的范式,这两者在内容保存度和风格转换准确率上各有千秋,我们的做法是结合两种方法来取长补短。

首先我们提出了基于attention的Seq2Seq结构以此来完整地保留用户输入的词级别的源端信息,同时我们使用隐空间风格表示来构造更具有区分度和表达能力的风格信号,最后将两者结合在一起,从而实现了转化之后用户输入的语义的内容保留度以及转化后诗歌风格准确度的更好的平衡。我们推导了新的数学形式,首先使用一组风格实例,例如使用100个诗句这个小的集合来代表古诗这种风格,也就是该特定风格的经验分布。基于此推导出了新的转化形式,这和我们的模型结构是一一对应的。

我们的核心是风格编码器,而问题在于如何从这组风格实例中抽取一个足够灵活和有表征能力的风格表示信号。这个过程是在隐空间进行,使用生成式流模型,我们会构造一个更加复杂的风格隐空间然后从里面去做sample。另外对于这种古诗和现代汉语的转化,我们是有一部少量的翻译标注数据的,所以为了有效利用这些数据,我们进一步推出了一个半监督的训练损失如图所示。
我们在优化该损失的时候是在同时做三件事情,首先是在最大化由我们的现代汉语文本和风格实例所生成目标风格诗句的概率的下界。同时在最小化这个概率的负值的上界,向两边逼近它。最后在对齐有无标注数据时的古诗的分布,以此在最终生成时学到更加符合真实的诗歌空间的风格表示。
③ 新颖性

除了文本质量之外,诗歌作为一种文学性文本,它最大的特点就是审美特征,首先是新颖性。因为用户希望读到新颖有趣的诗歌,而不是重复乏味无聊而且被人写过的诗作。对于新颖性我们最低的要求是,对于用户不同的主题词输入,模型能够生成有差异性和新颖的诗歌。
由于我们一般使用MLE极大似然估计来做模型的优化,这导致了上面所述要求很难实现。具体来说就是一个Token级别交叉熵损失。这种损失是倾向于记忆并生成高频模式,比如高频n-grams、停用词。同时这种损失函数的评价指标在评价粒度和评价指标上都与人类的评价不匹配。
- 解决思路之互强化学习

为了解决这个问题我们提出使用强化学习,我们对人类评价诗歌的每一个指标都做了量化的近似和建模,用这些来作为一个评分性的rewarder,用强化学习去激励模型在训练过程中去生成在这些指标上能得到更高得分的诗作。

进一步我们提出了互强化学习,因为写作学习对于人来说是一种群体性的任务,交流非常重要,有必要允许训练过程中生成器之间有一定的交流和借鉴。因此我们在训练过程中,同时训练两个不同的生成器来模拟学生,打分器来模拟老师,生成器不仅从老师那获取梯度反馈信号,同时相互之间也会有一定的信息交互。为了实现这种交互我们提出了一种算法,可以在整个强化学习的策略空间搜索时沿着不同的两条路径来搜索,既能加快搜索速度,又能避免某个生成器陷入局部最优点。
④ 风格化

另外一个特点,审美特征是风格化。我们知道人类在同一个主题下是有能力创作出完全不同风格的诗歌的,所以我们想让模型也实现风格的控制。我们要做的是把没有风格区分度的整个诗歌空间p(x)做解耦合到不同的风格依赖的风格上子空间上,这样就可以选择对应风格的空间,从中生成我们想要风格的诗歌。但我们只有很少的标注数据,所以想要无监督地去实现这一目标。我们没有办法去构建条件概率分布,也就是没有办法构建生成诗歌与输入的风格label之间的关联关系。
- 解决思路之无监督学习与利用正则项添加关联性

解决方案是用一个正则项去强加这个关系。具体来说,就是最大化风格分布和诗歌分布之间的互信息,强行把这种依赖给加上。互信息是衡量两个变量之间的依赖程度的。加上之后,改变风格标签y,生成的诗歌x就会跟着改变,以此实现了风格的控制。

我们得出了这样的损失函数,由两部分组成,一部分是风格无关的似然项,它能够确保我们生成的诗歌是比较通畅的,和上文关联性比较好。另外一个是风格的正则项,用来给输入的风格标签和输出的诗歌的文本空间强加一个关联性,以此来实现控制。
⑤ 情感化

最后一个审美特征是情感化,抒情是人类诗歌创作最主要的目的之一。我们想让生成模型也做到情感的控制。人类写诗的情感表达有两大特点,首先是对于同一个主题人们能写出两种不同的情感。其次一首诗歌内部每一句的情感并不完全相同,具有一定的变化转折规律。
- 解决思路之提出新拆解式

模型思路:针对文学文本我们提出了一个全新的拆解式,来描述我们的生成模型是怎么生成一首诗歌的。首先我们的user给指定一个主题词w,也可以指定一个情感标签y,若其不指定,我们也可以自动的去预测一个y。y和w共同构成了我们的一个隐空间,这三部分共同用于生成我们的诗歌。
- 针对全诗情感采用半监督循环训练

当我们要控制整首诗的整体情感时,如果有标注数据,比较简单。我们会按标准的流程去推导出它的ELBO下界来直接优化。区别在于我们天然的自带了一个分类器,这个分类器会依据我们的主题词自动地预测一个最合适的情感标签。没有label的时候,我们把情感y看成另外一个隐变量,又可以推出它的另外一项,也进行优化。这当中的第二个分类器可以用来为每个无标注的诗歌预测一个适合的情感。我们把两者结合在一起。在整个训练过程中,用那些有标注的数据去训练模型和分类器,分类器反过来为那些无标注的数据预测一个合适的标签,不断循环交替迭代,以此来实现半监督的训练。
- 针对每句情感采用交叉时间序列进行训练

如果我们想要控制每一句的情感,我们考虑每个诗句xi和这个诗句的句子级别的情感yi,无label的情况下,推出的式子中有一个期望,将其用蒙特卡罗采样,会产生一个时间序列的拆解,有一个序列的采样。在这个过程中同时学两个不同的序列:一个是每个句子的情感构成,另外一个是每个诗句si的内容的顺序,我们是在同时对两者进行建模和学习。
另外,虽然九歌算法诞生的时间比较早,但以上算法均可以移植到最新的模块上。
03 九歌系统介绍

以上所有的工作都做了工程化的实现,并整合到了中文古典诗歌在线生成系统——九歌中,在线系统网址(http://jiuge.thunlp.org/),大家可以到网站上体验九歌系统的功能。九歌系统累计为用户创作诗歌超过2500万首,用户遍布全球,也为万里之外漂泊的祖国游子提供了一点小小的慰藉,这也是我们做文化与AI相结合的初衷之一。整个项目获得了一系列奖项,系统及其创作的诗作在《机智过人》第一季和《朗读者》节目、人工智能教育大会等场合进行过展示,成果被多家媒体广泛报道,有一定的社会影响,并与学堂在线、腾讯相册管家进行合作。
04 自动作诗与知识图谱

我们也有用到一部分知识图谱的知识,我们构建了概率关联式的知识图谱——文脉,爬取维基百科中所有entity的链接,计算出一个带边权的链接的网络,如图所示,并将这个知识图谱map到了古诗文上,最后得到在所有古诗文中出现的这样一个带边权的图谱,所有权重会用词云的方式体现出来。
在线演示:https://williamlwclwc.github.io/KG-Demo/
开源下载:https://github.com/THUNLP-AIPoet/ParCKG
除了常规的关键词扩展和转换以帮助机器理解词语外,我们还对其有一系列的未来展望:
- 常识驱动的用户输入理解

人可以用古典的语言去描述现代的“飞机”一词,因为人有常识。而目前的绝大多数模型无法做到这一点,图谱的应用会帮助改善这一情况。
- 引入语言学与文学知识的诗歌生成

知识可以用来帮助实现将典故知识输入模型来促进诗歌生成,或者使用各种修辞来促使模型更好地生成更有寓意的诗歌。
- 结合时空及历史知识的诗歌生成

古人作诗常常是登高望景,所见即所得,所以诗歌中常含有地理空间的因素以及历史知识的融入。
- AI与人类的关系之我见
现在我们用人类几百年来沉淀下来的作品来指导AI学习,但随着技术的发展,AI会创作出更好的诗歌,以此激励人类创作者创作出新的诗歌,反过来进一步提升AI,形成良性循环。创作上,机器与人不是非此即彼、相互取代,而是相互促进共同学习和进步的,这也是九歌系统研发的初衷之一。希望未来我们能够一起在这个方向上做更多更有意思的探索和尝试。谢谢各位!
分享嘉宾:矣晓沅博士 微软亚洲研究院 研究员
相关文章:
【大厂AI实践】清华:清华古典诗歌自动生成系统“九歌”的算法
【大厂AI实践】清华:清华古典诗歌自动生成系统“九歌”的算法 🌟 嗨,你好,我是 青松 ! 🌈 自小刺头深草里,而今渐觉出蓬蒿。 文章目录 **01 自动作诗缘起****1. 诗歌自动写作** **02 九歌的模型…...

JS基础之函数
函数使用 函数名命名规范 和变量命名基本一致> 尽量小驼峰式命名法 前缀应该为动词 命名建议:常用动词约定 动词含义can判断是否可执行某个动作has判断是否含义某个值is判断是否为某个值get获取某个值set设置某个值load加载某些数据 有返回值的函数 细节: 在函数体中使用…...
基于java SSM springboot学生信息管理系统设计和实现
基于java SSM springboot学生信息管理系统设计和实现 🍅 作者主页 网顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系统 …...

【MongoDB】在Windows11下安装与使用
官网下载链接:Download MongoDB Community Server 官方参考文档:https://www.mongodb.com/zh-cn/docs/manual/tutorial/install-mongodb-on-windows/#std-label-install-mdb-community-windows 选择custom类型,其他默认 注意,此选…...

HTML在网页开发中的应用与重要性
## 摘要 HTML(HyperText Markup Language)是网页开发的基础语言之一,它定义了网页的结构和内容。随着互联网的快速发展,HTML不断演进,从HTML4到HTML5,其功能和特性得到了极大的增强。本文将探讨HTML在网页…...

深度学习-140-RAG技术之Agentic Chunking分块技术的实现细节和完备实现
文章目录 1 类AgenticChunker1.1 add_propositions添加命题列表1.2 add_proposition添加单个命题1.3 add_proposition_to_chunk命题添加到块中1.4 _update_chunk_summary更新块摘要1.5 _update_chunk_title更新块主题1.6 _get_new_chunk_summary获取新块摘要1.7 _get_new_chunk…...

全面中耕机与行间中耕机的作用及区别
全面中耕机与行间中耕机的作用及区别 一、作用对比 全面中耕机 核心作用:主要用于整地前的土壤准备和休闲地管理,包括播前整地、土壤改良、化肥与化学药剂的混合等,为大面积种植创造均匀的种床环境。 附加功能:通过深耕ÿ…...

CSS—显示模式display、定位position、元素溢出overflow、float浮动
目录 1.显示模式display 2.定位position 3.元素溢出overflow 4.float浮动 1.显示模式display 显示模式常见元素特点块级元素div标签、h1-h6、p、form、header、footer、section、ul、li、ol、dl、dt独占一行,默认垂直布局,没有设置宽高时宽度继承父级…...

Linux调试器gdb和cgdb的使用【Ubuntu】
文章目录 一、样例代码二、预备三、常见使用1、cgdb调试操作2、gdb调试操作 四、常见技巧1、 **安装cgdb:**2、watch3、set var确定问题原因4、条件断点 一、样例代码 // mycmd.c #include <stdio.h>int Sum(int s, int e) {int result 0;for(int i s; i < e; i){r…...

清华大学DeepSeek详细使用教程共6版免费下载
「清华北大-Deepseek使用手册」 链接:https://pan.quark.cn/s/98782f7d61dc 「清华大学Deepseek整理) 1-6版本链接:https://pan.quark.cn/s/72194e32428a AI学术工具公测链接:https://pan.baidu.com/s/104w_uBB2F42Da0qnk78_ew …...
使用黑森林实验室发布的Flux.1 文生图模型进行 UI 创作以及 PS 操作
我们前期介绍了黑森林实验室发布的 Flux.1 文生图大模型,其模型是一个扩散模型。扩散模型通过迭代细化噪声图像来生成最终图像。这种去噪过程使扩散模型能够创建更连贯、更逼真的图像,因为扩散是一个多步骤过程,这与 GAN(生成对抗…...

React Native 0.78新特性
此版本在 React Native 中发布了 React 19,以及其他相关功能,例如对 Android Vector drawables 的原生支持以及对 iOS 的更好的 Brownfield 集成。 亮点 React 19 React 19 现在可在 React Native 上使用!React 19 需要更新您的应用,因为我们从 React 18 引入了一些更改…...
@RequestMapping、@RestController、@RequestParam)
11.24 SpringMVC(1)@RequestMapping、@RestController、@RequestParam
一.RequestMapping("/user")//HTTP 请求方法既支持get也支持post,可表示为类路径与方法路径 二.RequestMapping(value "/m7", method {RequestMethod.POST, RequestMethod.GET}) value这个参数指定了请求的 URL 路径。method 参数指定了允许…...

webstorm的Live Edit插件配合chrome扩展程序JetBrains IDE Support实现实时预览html效果
前言 我们平时在前端网页修改好代码要点击刷新再去看修改的效果,这样比较麻烦,那么很多软件都提供了实时预览的功能,我们一边编辑代码一边可以看到效果。下面说的是webstorm。 1 Live Edit 首先我们需要在webstorm的settings里安装插件Live …...

ROS环境搭建
ROS首次搭建环境 注:以下内容都是在已经安装好ros的情况下如何搭建workplace 一、创建工作空间二、创建ROS包三、注意 注:以下内容都是在已经安装好ros的情况下如何搭建workplace 如果没有安装好,建议鱼香ros一步到位:鱼香ROS 我也是装了好久…...

Cherry Studio + 火山引擎 构建个人AI智能知识库
🍉在信息化时代,个人知识库的构建对于提高工作效率、知识管理和信息提取尤为重要。尤其是当这些知识库能结合人工智能来智能化地整理、分类和管理数据时,效果更为显著。我最近尝试通过 Cherry Studio 和 火山引擎 来搭建个人智能知识库&#…...

Spring Boot 与 MyBatis 版本兼容性
初接触Spring Boot,本次使用Spring Boot版本为3.4.3,mybatis的起步依赖版本为3.0.0,在启动时报错,报错代码如下 org.springframework.beans.factory.BeanDefinitionStoreException: Invalid bean definition with name userMapper…...

《 C++ 点滴漫谈: 二十九 》风格 vs. C++ 风格:类型转换的对决与取舍
摘要 类型转换是 C 编程中的重要机制,用于在不同数据类型之间进行安全高效的转换。本博客系统介绍了 C 提供的四种类型转换运算符(static_cast、dynamic_cast、const_cast 和 reinterpret_cast)的用法及适用场景,分析了它们相较于…...

AI预测福彩3D新模型百十个定位预测+胆码预测+杀和尾+杀和值2025年3月3日第11弹
前面由于工作原因停更了很长时间,停更期间很多彩友一直私信我何时恢复发布每日预测,目前手头上的项目已经基本收尾,接下来恢复发布。当然,也有很多朋友一直咨询3D超级助手开发的进度,在这里统一回复下。 由于本人既精…...

ArcGIS Pro高级应用:高效生成TIN地形模型
一、引言 在地理信息科学与遥感技术的快速发展背景下,数字高程模型(DEM)已成为地形表达与分析的关键工具。 三角网(TIN)作为DEM的一种重要形式,因其能够精准描绘复杂地形特征而广受青睐。 ArcGIS Pro为用…...

snnTorch NIR导出功能详解:实现跨框架模型转换
snnTorch NIR导出功能详解:实现跨框架模型转换 【免费下载链接】snntorch Deep and online learning with spiking neural networks in Python 项目地址: https://gitcode.com/gh_mirrors/sn/snntorch snnTorch是一个基于Python的脉冲神经网络(SN…...

5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南
5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐…...
)
别再只用TabBar了!用Qt QML的Repeater和ListView打造更灵活的侧边栏导航(附完整源码)
超越TabBar:用QML的Repeater与ListView构建动态导航系统 当标准导航控件无法满足现代应用界面需求时,Qt Quick的模型-视图架构提供了更强大的解决方案。本文将深入探讨如何利用Repeater和ListView构建高度可定制的侧边栏导航系统,通过对比分析…...

OpenRPA完全指南:免费开源的企业级RPA自动化终极方案
OpenRPA完全指南:免费开源的企业级RPA自动化终极方案 【免费下载链接】openrpa Free Open Source Enterprise Grade RPA 项目地址: https://gitcode.com/gh_mirrors/op/openrpa OpenRPA是一款免费开源的企业级RPA(机器人流程自动化)软…...

Servlet 容器与过滤器 超详细讲解
目录 一、Servlet 容器(Servlet Container) 1. 是什么? 2. 核心作用(必须掌握) 3. Servlet 生命周期(容器全权控制) 4. 工作流程(HTTP 请求完整链路) 5. 总结一句话 二、过滤器(Filter) 1. 是什么? 2. 核心特点 3. 过滤器能做什么?(高频场景) 4. 过滤…...

Pure Live完整指南:3分钟掌握跨平台纯净直播聚合工具
Pure Live完整指南:3分钟掌握跨平台纯净直播聚合工具 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 在当今数字娱乐时代,直播已成为人们日常娱乐的重…...
)
从荆楚方言保护到AIGC商业化:ElevenLabs湖北话语音项目落地的4类合规红线(含广电总局最新AI语音备案实操清单)
更多请点击: https://intelliparadigm.com 第一章:从荆楚方言保护到AIGC商业化:ElevenLabs湖北话语音项目的战略定位 湖北话作为荆楚文化的重要语音载体,长期面临传承断层、语料稀缺与数字表达缺位等挑战。ElevenLabs湖北话语音项…...

Windhawk终极指南:免费开源Windows定制工具完整教程
Windhawk终极指南:免费开源Windows定制工具完整教程 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否厌倦了Windows系统千篇一律的界面…...

如何快速掌握UESave:3个高效编辑游戏存档的秘诀
如何快速掌握UESave:3个高效编辑游戏存档的秘诀 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave 你是否曾因游戏存档损坏而失去珍贵的游戏进度?是…...

论文的重复率是什么?
论文重复率,说直白一点,就是你的论文内容和数据库里已有内容的文字相似比例。但这里有个很多人会误解的点:重复率 ≠ 抄袭率。查重系统本质上是在做“文本比对”,不是在判断你的主观意图。比如你自己写了一句:“随着数…...