MySQL SQL 优化专题
MySQL SQL 优化专题
1. 插入数据优化
-- 普通插入(不推荐)
INSERT INTO tb_user VALUES(1,'tom');
INSERT INTO tb_user VALUES(2,'cat');
INSERT INTO tb_user VALUES(3,'jerry');-- 优化方案1:批量插入(推荐,不建议超过1000条,500-1000较为合适)
INSERT INTO tb_user VALUES(1,'tom'), (2,'cat'), (3,'jerry');-- 优化方案2:手动事务提交(适用于大数据量)
start transaction;
INSERT INTO tb_user VALUES(1,'tom');
INSERT INTO tb_user VALUES(2,'cat');
commit;-- 优化方案3:主键顺序插入(减少页分裂)
-- 有序ID:1,2,3,4...
-- 无序ID:3,1,4,2...-- 优化方案4:LOAD命令(百万级数据)
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
-- 语法:LOAD DATA LOCAL INFILE '文件路径' INTO TABLE 表名;
load data local infile '/root/sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n' ;
原理说明:
- 批量插入减少事务提交次数
- 顺序插入可减少页分裂概率
- LOAD指令比INSERT快约20倍
2. 主键优化
(1)数据组织方式:
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表 (index organized table IOT)。
- InnoDB采用B+树索引,数据存储在叶子节点
- 页分裂(离散插入导致)和页合并(删除数据后触发)
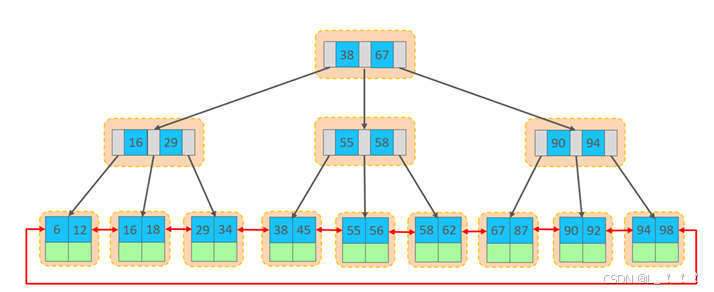
行数据,都是存储在聚集索引的叶子节点上的。InnoDB的逻辑结构图:
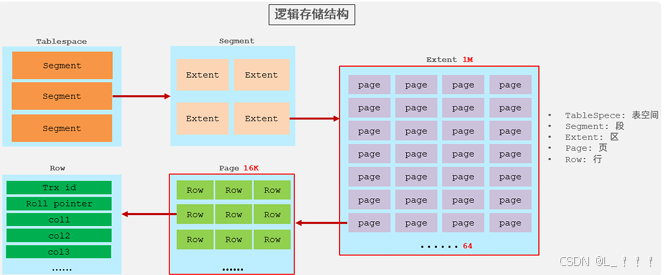
在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。 那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储 到下一个页中,页与页之间会通过指针连接。
**(2). 页分裂 **
页可以为空,也可以填充一半,也可以填充100%。每个页至少包含了2行数据(只有一行数据就等于退化成链表了)(如果一行数据过大,会行溢出),根据主键排列。
A. 主键顺序插入效果
①. 从磁盘中申请页, 主键顺序插入
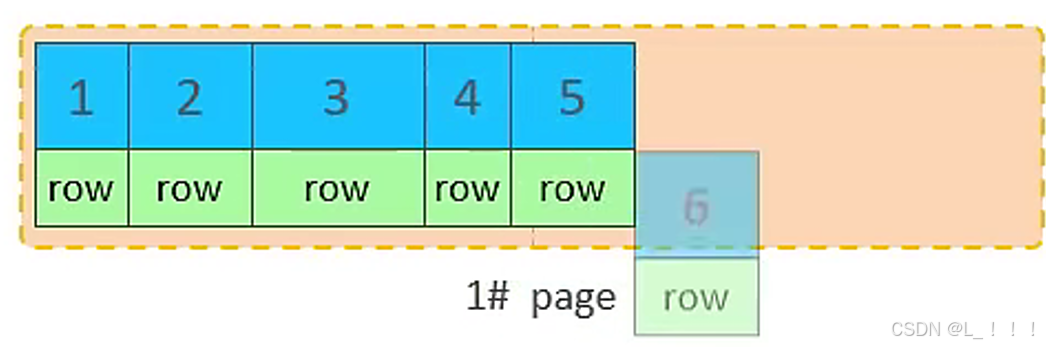
②. 第一个页没有满,继续往第一页插入
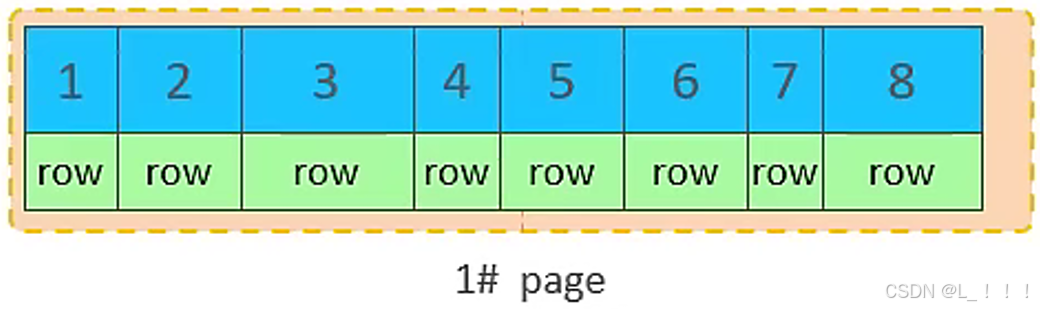
③. 当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接

④. 当第二页写满了,再往第三页写入

B. 主键乱序插入效果
①. 加入1#,2#页都已经写满了,存放了如图所示的数据

②. 此时再插入id为50的记录,我们来看看会发生什么现象 ?
会再次开启一个页,写入新的页中吗?
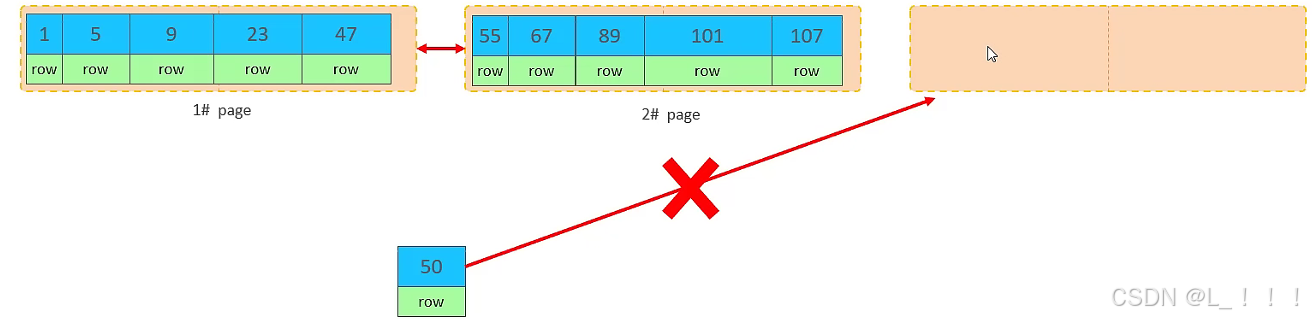
不会。因为,索引结构的叶子节点是有顺序的。按照顺序,应该存储在47之后。
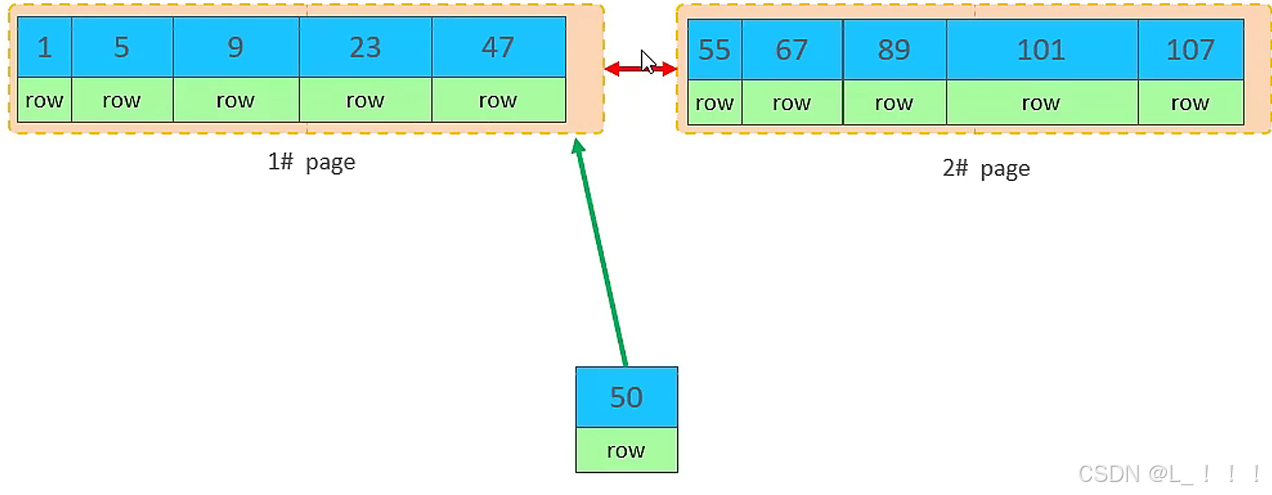
但是47所在的1#页,已经写满了,存储不了50对应的数据了。 那么此时会开辟一个新的页 3#。

但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。
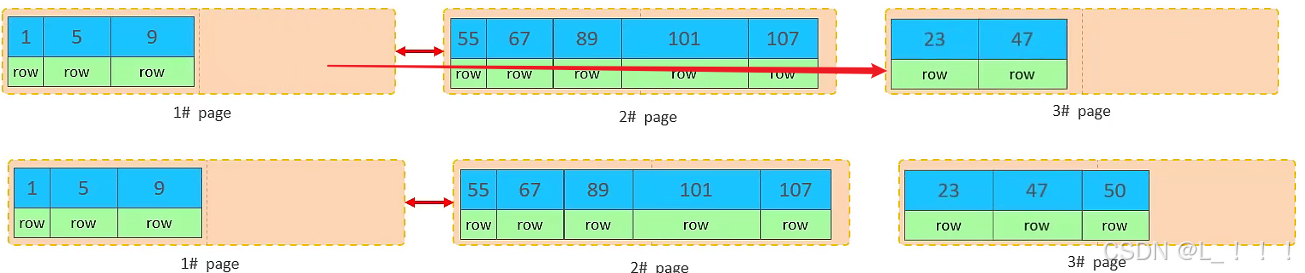
移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个 页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针。(连接过程类似双向链表的插入过程)

上述的这种现象,称之为 “页分裂”,是比较耗费性能的操作。
3). 页合并
目前表中已有数据的索引结构(叶子节点)如下:

当我们对已有数据进行删除时,具体的效果如下:
当删除一行记录时,**实际上记录并没有被物理删除,只是记录被标记(flaged)**为删除并且它的空间 变得允许被其他记录声明使用。

当我们继续删除2#的数据记录

当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
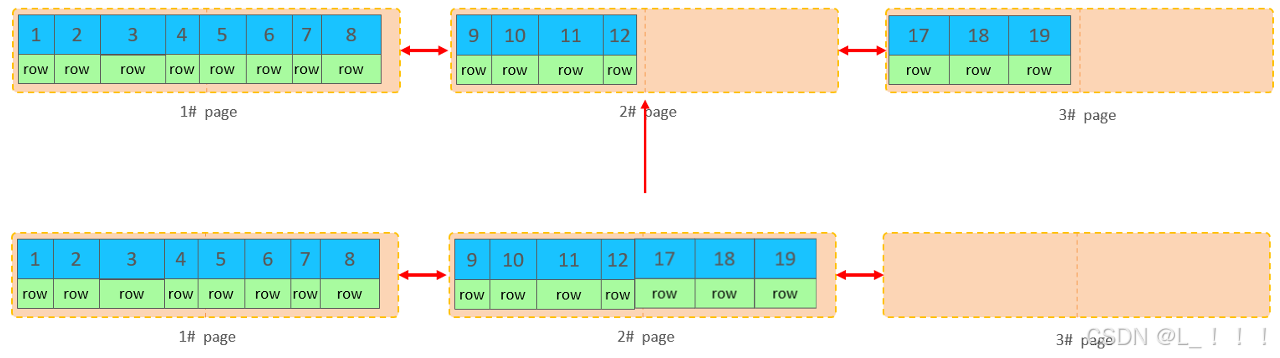
删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页

这个里面所发生的合并页的这个现象,就称之为 “页合并”。
知识小贴士: MERGE_THRESHOLD(threshold:阈值):合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
4). 主键设计原则
- 满足业务需求情况下,尽量
降低主键长度 - 插入数据时尽量选择
顺序插入,使用AUTO_INCREMENT主键 - 尽量不要使用
UUID(无序,插入可能产生页分裂现象,影响性能)或其他自然主键(如身份证号:长度比较长,检索时会浪费大量的磁盘IO时间) - 避免对主键进行
修改(修改主键还需要修改对应的索引)
3. ORDER BY 优化
MySQL的排序,有两种方式:
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要 额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序 操作时,尽量要优化为 Using index。
-- 需要优化的查询(出现Using filesort)
explain select id,age,phone from tb_user order by age ;
explain select id,age,phone from tb_user order by age, phone ;
--由于 age, phone 都没有索引,所以此时再排序时,出现Using filesort, 排序性能较低。-- 创建索引
CREATE INDEX idx_age_phone ON tb_user(age, phone);--创建索引后,根据age, phone进行升序排序
-- 优化后查询(Using index)
explain select id,age,phone from tb_user order by age, phone ;
--建立索引之后,再次进行排序查询,就由原来的Using filesort, 变为了 Using index,性能就是比较高的了。
--根据age, phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age desc , phone desc ;
--因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时
--就会出现Using filesort。
为了解决上述的问题,我们可以创建一个索引,这个联合索引中 age 升序排序,phone 倒序排序。
创建联合索引(age 升序排序,phone 倒序排序)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
优化后查询(Using index)。
升序/降序联合索引结构图示:


--根据phone,age进行升序排序,phone在前,age在后。(易错细节)
explain select id,age,phone from tb_user order by phone , age;
--排序时,也需要满足最左前缀法则,否则也会出现 filesort。因为在创建索引的时候, age是第一个
--字段,phone是第二个字段,所以排序时,也就该按照这个顺序来,否则就会出现 Using filesort。
排序类型:
- Using index:直接通过索引返回数据(性能最佳)
- Using filesort:需要将结果集加载到内存排序(需要优化)
order by优化原则:
A. 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。(where 后的连表条件只要存在即可,无所谓顺序,但order by后面的书写有顺序要求)
B. 尽量使用覆盖索引。(减少使用select * ,不用回表)
C. 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
D. 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
4. GROUP BY 优化
-- 未优化(出现Using temporary)
EXPLAIN SELECT profession, COUNT(*) FROM tb_user
GROUP BY profession;-- 创建索引后优化
CREATE INDEX idx_pro_age_sta ON tb_user(profession,age,status);
EXPLAIN SELECT profession, COUNT(*) FROM tb_user
GROUP BY profession; -- 使用索引
优化方法:
A. 在分组操作时,可以通过索引来提高效率。
B. 分组操作时,索引的使用也是满足最左前缀法则的。
5. LIMIT 优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
我们一起来看看执行limit分页查询耗时对比:

通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。 因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要MySQL排序前2000010 记 录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
(因为叶子排序是双链表,要依次遍历,越向后时间越长。)
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
explain select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;
-- 低效写法(耗时随偏移量增加)
SELECT * FROM tb_sku LIMIT 9000000,10;-- 优化方案:记录上次查询的最大ID
SELECT * FROM tb_sku WHERE id > 9000000 LIMIT 10;-- 子查询优化(需覆盖索引)
SELECT * FROM tb_sku t,
(SELECT id FROM tb_sku ORDER BY id LIMIT 9000000,10) a
WHERE t.id = a.id;
优化原理:
- 避免全表扫描,使用索引覆盖
- 使用ID分段查询替代大偏移量
6. COUNT 优化
select count(*) from tb_user ;
我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数 。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:
自己计数(可以借助于redis这样的数 据库进行,但是如果是带条件的count又比较麻烦了)。
count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
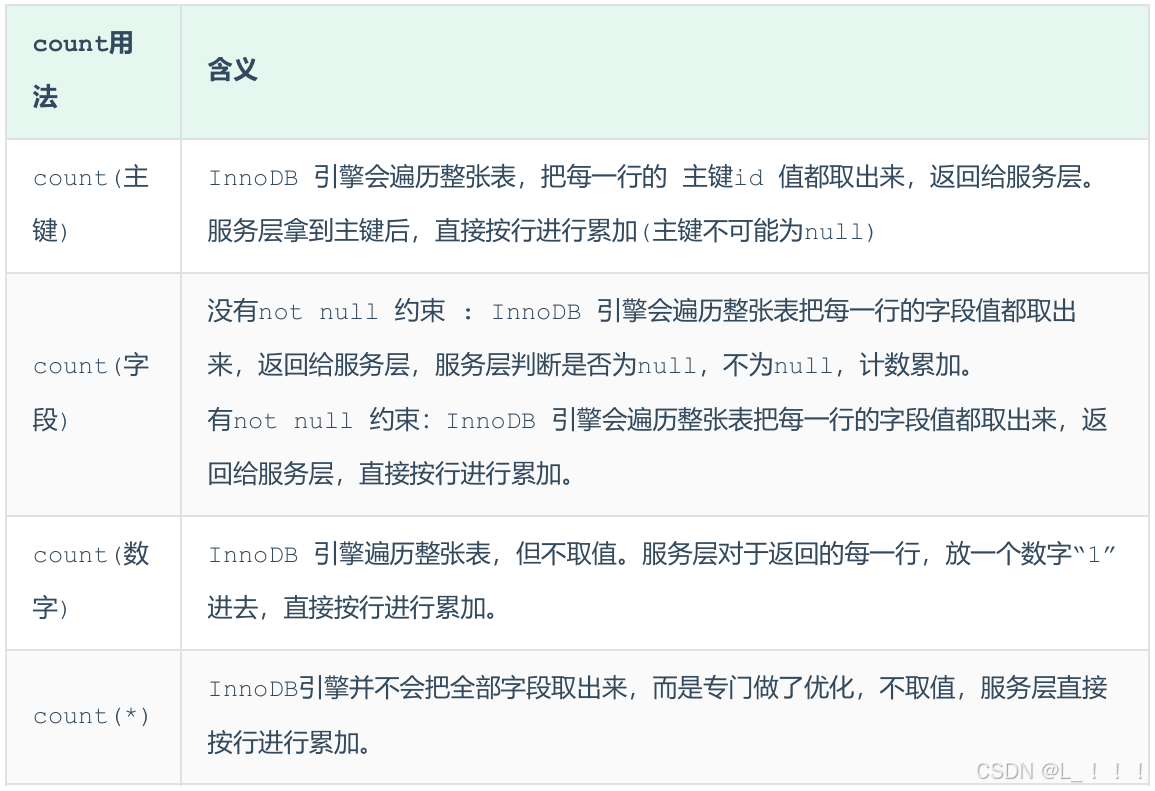
--按照效率排序的话,所以尽量使用count(*),因为专门做了优化。
count(字段)(需要做判断是否为空)< count(主键 id) < count(1) ≈ count(*)-- 统计有效数据条数
SELECT COUNT(1) FROM tb_user; -- 推荐写法
SELECT COUNT(*) FROM tb_user; -- 官方优化写法
不同COUNT区别:
- COUNT(字段):统计不为NULL的记录数
- COUNT(主键):遍历主键索引
- COUNT(1):不取值直接累加1
- COUNT(*):MySQL优化过的特殊计数器
7. UPDATE 优化
回忆:InnoDB的三大特性:事务,外键,行级锁
start transaction; 或者是begin来开启事务;
我们主要需要注意一下update语句执行时的注意事项。
update course set name = 'javaEE' where id = 1 ;
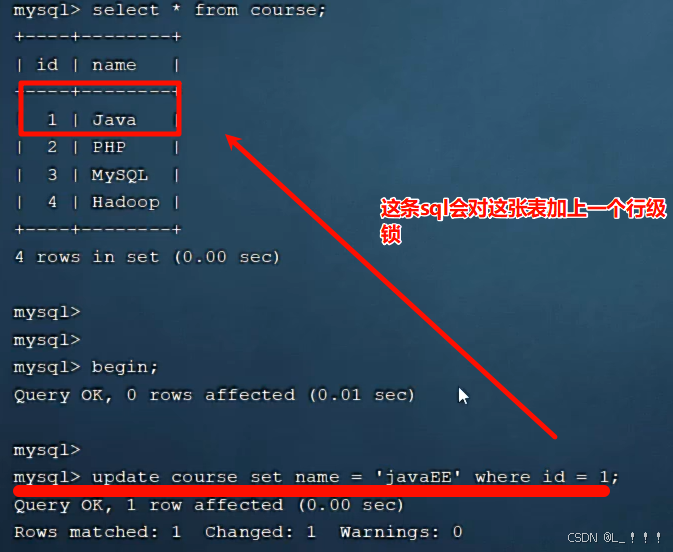
当我们在执行更新的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update course set name = 'SpringBoot' where name = 'PHP' ;

name这个字段没有索引,此时加的就不再是行锁了,而是表锁。一旦锁表了,我们的并发性能就会降低!!!
当我们开启多个事务,在执行上述的SQL时,我们发现行锁升级为了表锁。 导致该update语句的性能大大降低。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁 升级为表锁 。
-- 使用索引字段更新(行级锁)
UPDATE tb_user SET name = 'zhangsan' WHERE id = 1;-- 无索引更新(表级锁,需要避免!)
UPDATE tb_user SET name = 'lisi' WHERE name = 'wangwu';
优化重点:
- 更新条件必须
走索引,避免行锁升级为表锁 - 事务要及时提交,减少锁持有时间
总结
| 优化类型 | 核心方法 | 典型案例 |
|---|---|---|
| 插入优化 | 批量插入+手动事务提交+主键顺序插入 | 万级数据使用LOAD DATA |
| 主键优化 | 自增主键+避免修改+尽量短 | UUID导致页分裂问题 |
| ORDER BY | 尽量建立覆盖索引+避免filesort | 多字段排序注意索引顺序 |
| GROUP BY | 利用索引减少临时表(多字段分组满足最左前缀法则) | 分组字段建立联合索引 |
| LIMIT | 覆盖索引+子查询(使用ID分段替代大偏移量) | 百万级分页优化方案 |
| COUNT | 优先使用COUNT(*)或COUNT(1) | 统计全表数据时避免COUNT(字段) |
| UPDATE | WHERE条件必须走索引 | 无索引更新导致表锁问题 |
通过以上优化手段,通常可以使MySQL查询性能提升1-3个数量级,特别是在大数据量场景下效果尤为显著。实际优化中需要结合EXPLAIN执行计划进行分析,针对性优化关键瓶颈点。
相关文章:
MySQL SQL 优化专题
MySQL SQL 优化专题 1. 插入数据优化 -- 普通插入(不推荐) INSERT INTO tb_user VALUES(1,tom); INSERT INTO tb_user VALUES(2,cat); INSERT INTO tb_user VALUES(3,jerry);-- 优化方案1:批量插入(推荐,不建议超过1…...

Mac上安装Pycharm
说明:仅供参考,是自己的安装流程,以免以后自己想不起来来看看的笔记 官网地址:https://www.jetbrains.com/pycharm/ 1、点击Download,跳转到下一个页面 2、MAC,选择Mac OS,在Pycharm Professio…...

flask框架基础入门学习教程
文章目录 前言1. 环境搭建1.1Python安装1.2选择Python开发环境1.3 创建虚拟环境(可选但推荐)1.4 安装 Flask 2. 第一个 Flask 应用3. 路由和视图函数3.1 基本路由3.2 动态路由3.3 路由参数类型 4. 请求和响应4.1 获取请求数据4.2 响应对象 5. 模板渲染6.…...

Qt显示一个hello world
一、显示思路 思路一:通过图形化方式,界面上创建出一个控件显示。 思路二:通过编写C代码在界面上创建控件显示。 二、思路一实现 点开 Froms 的 widget.ui,拖拽 label 控件,显示 hello world 即可。 qmake 基于 .…...

MySQL快速搭建主从复制
一、基于位点的主从复制部署流程 确定主库Binlog是否开启修改主从server_id主库导出数据从库导入数据确定主库备份时的位点在从库配置主库信息查看复制状态并测试数据是否同步 二、准备阶段(主库和从库配置都需要修改) 1、确定主库Binlog是否开启 2、修改主从se…...
力扣-动态规划-674 最长连续递增序列
思路 dp数组定义:以i为结尾的最长连续递增序列递推公式: if(nums[i-1] < nums[i]) dp[i] dp[i-1] 1; dp数组初始化:都为1遍历顺序:顺序时间复杂度: 代码 class Solution { public:int findLengthOfLCIS(v…...

在笔记本电脑上用DeepSeek搭建个人知识库
最近DeepSeek爆火,试用DeepSeek的企业和个人越来越多。最常见的应用场景就是知识库和知识问答。所以本人也试用了一下,在笔记本电脑上部署DeepSeek并使用开源工具搭建一套知识库,实现完全在本地环境下使用本地文档搭建个人知识库。操作过程共…...
leetcode 94. 二叉树的中序遍历
题目如下 做了那么多道难题,给自己放放松。通过代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int …...

YOLOv12:目标检测新时代的破局者
目录 一、YOLOv12 横空出世二、YOLOv12 的性能飞跃2.1 多规模优势2.2 对比超越 三、技术创新与原理剖析3.1 区域注意力模块(Area Attention,A2)3.2 残差高效层聚合网络(R-ELAN)3.3 架构优化细节 四、实验验证与结果分析…...

基于OFDR的层压陆相页岩油储层中非对称裂缝群传播的分布式光纤监测
关键词:OFDR、分布式光纤传感、裂缝传播 一. 概述 四川盆地凉高山组优质页岩油储层存在复杂的垂直重叠岩性,大陆页岩油储层存在发育层理,薄层和天然裂缝,对水平井多级压裂技术的裂缝网络形态控制和监测构成挑战。本研究提出了一…...

Linux虚拟机网络配置-桥接网络配置
简介 本文档旨在指导用户如何在虚拟环境中配置Linux系统的桥接网络,以实现虚拟机与物理主机以及外部网络的直接通信。桥接网络允许虚拟机如同一台独立的物理机一样直接连接到物理网络,从而可以被分配一个独立的IP地址,并能够与网络中的其他设…...

软开经验总结
文章目录 软开经验总结一、二次开发时候操作步骤二、logger的作用!!!三、git使用 软开经验总结 一、二次开发时候操作步骤 改 SDK 和 language level改 maven 配置改数据库 注意Mysql 版本 差别是否过大!!࿰…...

关于虚拟环境中遇到的bug
conda和cmd介绍 介绍 Conda 概述: Conda是一个开源包管理系统和环境管理系统,尤其适用于Python和R语言的开发环境。它允许用户创建独立的虚拟环境,方便地管理依赖包和软件版本。 特点: 环境管理:可以创建、导入、导…...

C 语言在微软平台:经典与创新的交融
在编程语言的璀璨星空中,C 语言犹如一颗耀眼的恒星,散发着永恒的光芒。当这颗恒星与微软强大的平台相互辉映时,更是碰撞出了绚丽多彩的火花,构建起了一个充满无限可能的编程世界。 C 语言与微软平台的深厚渊源 C 语言诞生于 20 …...

大数据测试中,数据仓库表类型有哪些?
本文我们一起了解一下数据仓库测试的对象,直白一点讲就是一张表,这张表分为以下几种类型: 全量表:没有分区的表,数据全量更新或者增量合并,我们通常理解就是把这些数据放到了一个文件夹里面。这样会有什么…...

基于开源库编写MQTT通讯
目录 1. MQTT是什么?2. 开发交互UI3. 服务器核心代码4. 客户端核心代码5. 消息订阅与发布6. 通讯测试7. MQTT与PLC通讯最后. 核心总结 1. MQTT是什么? MQTT(Message Queuing Terlemetry Transport)消息队列遥测协议;是…...

Kafka Connect连接器的全生命周期:
以下是基于Vue和PySide2的两种图形化界面设计方案,用于管理Kafka Connect连接器的全生命周期: 方案一:Vue3 Web管理平台 技术栈 - 前端:Vue3 + Element Plus + ECharts - 通信:Axios + WebSocket - 安全:JWT + HTTPS - 打包:Vite + Docker核心功能模块 <!-- 连接器…...

磁盘空间不足|如何安全清理以释放磁盘空间(开源+节流)
背景: 最近往数据库里存的东西有点多,磁盘不够用 查看磁盘使用情况 df -h /dev/sda5(根目录 /) 已使用 92% 咱们来开源节流 目录 背景: 一、开源 二、节流 1.查找 大于 500MB 的文件: 1. Snap 缓存…...

DeepSeek vs Grok vs ChatGPT:大模型三强争霸,谁将引领AI未来?
DeepSeek vs. Grok vs. ChatGPT:大模型三强争霸,谁将引领AI未来? 在人工智能领域,生成式模型的竞争已进入白热化阶段。DeepSeek、Grok和ChatGPT作为三大代表性工具,凭借独特的技术路径和应用优势,正在重塑…...

2025国家护网HVV高频面试题总结来了04(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 一、HVV行动面试题分类 根据面试题的内容,我们将其分为以下几类: 漏洞利用与攻击技术 …...

IPBan:企业级服务器安全防护解决方案的架构设计与实现
IPBan:企业级服务器安全防护解决方案的架构设计与实现 【免费下载链接】IPBan Since 2011, IPBan is the worlds most trusted, free security software to block hackers and botnets. With both Windows and Linux support, IPBan has your dedicated or cloud se…...

【独家首发】ElevenLabs未公开的粤语语音增强技巧:3个隐藏prompt指令+2个音频后处理脚本
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广东话语音合成的技术边界与本地化挑战 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力广受关注,但粤语(广东话)尚未被官方列为正式…...

在Taotoken模型广场根据任务需求与预算快速选型实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求与预算快速选型实践 面对众多大模型,如何为自己的项目选择一个既满足需求又符合预算的…...

6.6k Star 这个内网穿透神器,一行命令开通公网域名,前后端联调神器!
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事中…...

Windows音频设备切换神器:AudioSwitch让你的音频管理效率提升300%
Windows音频设备切换神器:AudioSwitch让你的音频管理效率提升300% 【免费下载链接】AudioSwitch Switch between default audio input or output change volume 项目地址: https://gitcode.com/gh_mirrors/au/AudioSwitch 还在为Windows系统下繁琐的音频设备…...

图片去水印软件哪个好用?2026免费工具对比测评|电脑手机全覆盖
去水印已经成为日常生活中的高频需求。无论是保存心仪的社交媒体内容、优化电商产品图片,还是整理个人素材库,一张带着平台水印的图片往往无法直接使用。但面对市面上琳琅满目的去水印方案,很多人都有同样的疑问:到底哪款软件最实…...

Beyond Compare 5密钥生成终极指南:3分钟完成软件激活的完整解决方案
Beyond Compare 5密钥生成终极指南:3分钟完成软件激活的完整解决方案 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否正在为Beyond Compare 5的"评估模式错误"而烦恼…...

Word文档怎么导出为图片?Word如何高效转换图片?2026实测转换方法
在日常工作中,我们经常需要将Word文档转换为图片格式。无论是为了方便分享、创建演示内容,还是为了保护文档格式,将Word导出为图片都是一个常见的需求。本文将详细介绍Word文档导出为图片的多种方法,帮助你根据不同场景选择最适合…...

tars 环境安装及开发部署
参考:https://tarscloud.github.io/TarsDocs/installation/source-windows.html 安装环境 安装nodejs、vs(已安装了vs2022)、cmake(已安装,版本是3.30.0)、git(已安装,版本是2.45.2)、Mysql 下载并安装nodejs https://nodejs.org/en/ 版本是22.15.0 添加到环…...

从SE到Dual-Attention:手把手教你为YOLOv8或ResNet模型‘加装’注意力模块提升指标
从SE到Dual-Attention:手把手教你为YOLOv8或ResNet模型‘加装’注意力模块提升指标 在计算机视觉领域,注意力机制已成为提升模型性能的"秘密武器"。不同于完全重构网络架构,注意力模块的魅力在于其即插即用的特性——就像为汽车加装…...