【AI深度学习基础】Pandas完全指南入门篇:数据处理的瑞士军刀 (含完整代码)
📚 Pandas 系列文章导航
- 入门篇 🌱
- 进阶篇 🚀
- 终极篇 🌌
📌 一、引言
在大数据与 AI 驱动的时代,数据预处理和分析是深度学习与机器学习的基石。Pandas 作为 Python 生态中最强大的数据处理库,以其灵活的数据结构(如 DataFrame 和 Series)和丰富的功能(数据清洗、转换、聚合等),成为数据科学家和工程师的核心工具。
Pandas 以 Series(一维标签数组)和 DataFrame(二维表格)为核心数据结构,提供高效的数据处理能力,涵盖数据清洗(缺失值处理、去重)、筛选(loc/iloc)、聚合(groupby)、合并(merge/concat)及时间序列分析(日期解析、重采样)等关键功能。其优势在于:
- 矢量化运算:避免循环,提升性能。
- 内存优化:
category类型减少内存占用。 - 无缝集成生态:与 NumPy、Matplotlib 等库无缝集成。
Pandas数据处理全流程:
入门需掌握基础 API(如 read_csv、describe),并通过实战(如电商分析、时序预测)深化理解。官方文档与《Python for Data Analysis》是经典学习资源,适合快速处理结构化数据并赋能 AI 工程。
🛠️ 二、安装指南
1. 前置条件
- Python 版本要求:Pandas 建议 Python 3.8 及以上版本。
- 推荐环境:使用虚拟环境(如
venv或conda)隔离项目依赖。
2. 安装方法
2.1 使用 pip 安装(通用方式)
# 基础安装(仅 Pandas)
pip install pandas# 国内镜像加速(解决下载慢问题)
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 使用 Anaconda 安装(推荐数据科学用户)
# 通过 conda 安装(自动处理依赖)
conda install pandas# 或指定版本
conda install pandas=2.2.0
2.3 源码安装(高级用户)
git clone https://github.com/pandas-dev/pandas.git
cd pandas
python setup.py install
3. 验证安装
import pandas as pd
print(pd.__version__) # 输出版本号(如 2.2.0)
4. 常见问题解决
- 依赖冲突:使用
pip install --upgrade pandas升级至最新版本。 - 权限问题:在命令前添加
sudo(Linux/macOS)或以管理员身份运行终端(Windows)。 - 缺少依赖库:安装完整数据科学生态(推荐):
pip install pandas numpy matplotlib scikit-learn
5. 环境配置建议
- IDE 支持:在 Pycharm 或 VS Code 中运行代码更高效。
- 文档速查:本地查看文档(终端输入
python -m pandas或访问 官网文档)。
📊 三、知识详解
1. 核心数据结构
1.1 Series
- 一维带标签数组,支持任意数据类型,索引机制允许快速定位数据(如
pd.Series([10,20], index=['a','b']))。 - 常用于存储时间序列、数值序列或分类数据。
1.2 DataFrame
- 二维表格型结构,由多个 Series 组成,支持异构数据类型(如数字、字符串、日期并存)。
- 提供类似 SQL 的操作接口(筛选、合并、分组聚合),适合处理 Excel 表格或数据库查询结果。
核心数据结构关系
2. 核心功能与优势
2.1 数据处理能力
- 数据清洗:通过
dropna()删除缺失值、fillna()填充、drop_duplicates()去重,快速修复脏数据。 - 数据操作:
- 筛选:
loc(标签索引)、iloc(位置索引)、query()(SQL 式条件过滤)。 - 合并:
merge()实现表连接、concat()轴向拼接。 - 分组聚合:
groupby()结合agg()计算多维度统计量(如均值、总和)。
- 筛选:
2.2 时间序列处理
- 内置时间解析(
pd.to_datetime())、重采样(resample())、滚动窗口计算,适用于金融分析或物联网数据。
2.3 可视化与集成
- 与 Matplotlib 无缝衔接,直接通过
df.plot()生成柱状图、折线图等。 - 兼容 NumPy、Scikit-learn 等库,支持数据预处理到模型训练的全流程。
2.4 性能优化
- 向量化运算:底层基于 C 语言加速,避免 Python 循环的低效问题(如
df * 2比循环快千倍)。 - 内存优化:使用
category类型减少字符串存储空间,eval()提升表达式计算效率。
💡 四、工程实践
1. 数据结构基石:Series 与 DataFrame
(1)代码示例
# 创建 Series
import pandas as pd
price_series = pd.Series([9.9, 15.8, 4.5], name="商品价格", index=["苹果", "牛奶", "面包"])# 创建 DataFrame
product_df = pd.DataFrame({"品类": ["水果", "乳制品", "烘焙"],"库存量": [50, 20, 35],"单价": [9.9, 15.8, 4.5]
}, index=["苹果", "牛奶", "面包"])
(2)核心要点
- Series 本质:带标签的一维数组,索引与值一一对应。
- DataFrame 核心:二维表格结构,可视为多个 Series 的列集合。
- 索引对齐特性是 Pandas 高效运算的基础逻辑。
(3)避坑指南
⚠️ 避免直接修改 df.values 数组,这会破坏索引对齐机制。
⚠️ 创建 DataFrame 时,字典值的长度必须一致,否则会触发 ValueError。
2. 数据加载与初步探索
(1)代码示例
# 从 CSV 读取数据(自动识别日期)
sales_data = pd.read_csv("sales.csv", parse_dates=["order_date"])# 数据预览技巧
print(sales_data.head(3)) # 查看前三行
print(sales_data.describe()) # 数值列统计摘要
print(sales_data.dtypes) # 查看列数据类型
(2)核心要点
- 支持 CSV/Excel/SQL 等 15+ 数据源读取。
parse_dates参数可将字符串自动转为 datetime 类型。head()+describe()组合快速掌握数据分布特征。
(3)避坑指南
⚠️ 读取 Excel 时需额外安装 openpyxl 库:pip install openpyxl。
⚠️ 大数据文件使用 chunksize 分块读取:
for chunk in pd.read_csv("big_data.csv", chunksize=10000):process(chunk)
3. 数据清洗黄金法则
(1)代码示例
# 处理缺失值
sales_clean = sales_data.dropna(subset=["price"]) # 删除 price 列缺失行
sales_data["price"].fillna(sales_data["price"].median(), inplace=True)# IQR 法处理异常值
Q1 = sales_data["sales"].quantile(0.25)
Q3 = sales_data["sales"].quantile(0.75)
sales_data = sales_data[~((sales_data["sales"] < (Q1-1.5*(Q3-Q1))) | (sales_data["sales"] > (Q3+1.5*(Q3-Q1))))]
(2)核心要点
- 缺失值处理三板斧:删除 (
dropna)、填充 (fillna)、插值 (interpolate)。 - 异常值检测推荐使用 IQR(四分位距法)或 3σ 原则。
- 数据转换时优先使用
inplace=True减少内存占用。
(3)避坑指南
⚠️ fillna(method="ffill") 向前填充时,需先按时间排序避免逻辑错误。
⚠️ 删除缺失值前务必检查 df.isna().sum(),避免误删有效数据。
4. 数据聚合与分组魔法
(1)经典代码示例
# 单维度聚合
category_sales = sales_data.groupby("category")["sales"].sum()# 多维度高级聚合
sales_stats = sales_data.groupby(["region", "year"]).agg(total_sales=("sales", "sum"),avg_price=("price", "mean"),max_quantity=("quantity", "max")
)
(2)核心要点
groupby本质是 “拆分-应用-合并” 三阶段操作。- 聚合函数推荐具名聚合(
agg+ 元组)提升可读性。 - 搭配
pd.cut进行分箱分析可挖掘深层规律。
(3)避坑指南
⚠️ 分组键包含 NaN 时会自动创建名为 NaN 的组,建议提前处理。
⚠️ 避免在分组后直接修改数据,应使用 transform 或 apply。
5. 数据合并高阶技巧
(1)代码示例
# 横向拼接(列扩展)
combined = pd.concat([df1, df2], axis=1)# 数据库风格连接
merged_data = pd.merge(orders, customers, how="left", left_on="customer_id", right_on="id")# 索引对齐合并
joined_df = df1.join(df2, how="inner")
(2)核心要点
concat适合简单堆叠,merge适合键关联合并。- 合并前务必检查键列唯一性:
df.duplicated().sum()。 - 多表连接推荐使用
pd.merge(ordered=True)保持顺序。 - 数据合并方法选择:
(3)避坑指南
⚠️ 多对多连接会产生笛卡尔积,导致数据量爆炸式增长。
⚠️ 合并后出现大量 NaN 值时,检查连接键的数据类型是否一致。
6. 效率优化锦囊
- 类型转换:将字符串列转为
category类型可降内存 80%。df["gender"] = df["gender"].astype("category") - 矢量化运算:用
df["col1"] + df["col2"]替代循环。 - 查询优化:大数据集使用
df.query("price > 100")比布尔索引更快。
🌟 五、总结说明
Pandas 的核心价值在于将复杂的数据操作简化为高效、可读的代码。通过本文,读者可掌握:
- 核心数据结构:Series 和 DataFrame 的使用方法。
- 数据处理能力:清洗、筛选、聚合、合并等关键操作。
- 性能优化技巧:类型转换、矢量化运算、查询优化。
- 实战应用:结合真实数据集进行实战演练。
🚀 六、结语
本章完成了 Pandas 入门知识的核心讲解。下篇将深入探讨进阶主题,包括高级数据处理技巧、性能调优、以及在深度学习中的应用。敬请期待!
相关文章:
)
【AI深度学习基础】Pandas完全指南入门篇:数据处理的瑞士军刀 (含完整代码)
📚 Pandas 系列文章导航 入门篇 🌱进阶篇 🚀终极篇 🌌 📌 一、引言 在大数据与 AI 驱动的时代,数据预处理和分析是深度学习与机器学习的基石。Pandas 作为 Python 生态中最强大的数据处理库,以…...

关于opencv中solvepnp中UPNP与DLS与EPNP的参数
The methods SOLVEPNP_DLS and SOLVEPNP_UPNP cannot be used as the current implementations are unstable and sometimes give completely wrong results. If you pass one of these two flags, SOLVEPNP_EPNP method will be used instead.、 由于当前的实现不稳定&#x…...

金融项目实战
测试流程 测试流程 功能测试流程 功能测试流程 需求评审制定测试计划编写测试用例和评审用例执行缺陷管理测试报告 接口测试流程 接口测试流程 需求评审制定测试计划分析api文档编写测试用例搭建测试环境编写脚本执行脚本缺陷管理测试报告 测试步骤 测试步骤 需求评审 需求评…...

大模型小白入门
【课前篇】大模型从0到1指南 【基础篇】大模型的演变与概念 大模型的演变 人工智能:人工智能是一个广泛涉及计算机科学、数据分析、统计学、机器工程、语言学、神 经科学、哲学和心理学等多个学科的领域。 机器学习:机器学习可以分为监督学习&…...

从零到一:快速上手 Poetry——Python 项目管理的利器
在 Python 项目开发中,包管理、依赖管理和虚拟环境的创建一直是开发者们经常面对的难题。传统上,开发者通常会使用 pip、virtualenv 或者 conda 来处理这些问题。然而,随着 Python 项目复杂度的增加,传统工具往往显得力不从心&…...

【量化科普】Beta,贝塔系数
【量化科普】Beta,贝塔系数 🚀量化软件开通 🚀量化实战教程 在量化投资领域,Beta(贝塔系数)是一个衡量投资组合或股票相对于整个市场波动性的指标。它反映了资产收益与市场收益之间的相关性,…...

C++----异常
一、C 语言传统的错误处理方式 在 C 语言中,处理错误主要有两种传统方式,每种方式都有其特点和局限性。 1. 终止程序 原理:使用类似assert这样的断言机制,当程序运行到某个条件不满足时,直接终止程序的执行。示例代…...

合理规划时间,从容应对水利水电安全员考试
合理规划时间,从容应对水利水电安全员考试 在忙碌的工作与生活节奏中备考水利水电安全员考试,合理规划时间是实现高效备考的核心。科学的时间管理能让你充分利用每一分每一秒,稳步迈向考试成功。 制定详细的学习计划是第一步。依据考试时间…...
 Windows 11使用SetSuspendState睡眠命令但是进入的是休眠)
(解决) Windows 11使用SetSuspendState睡眠命令但是进入的是休眠
Windows 11 24H2 goes into hibernation mode instead of sleep mode. How can I create a sleep mode shortcut file? 25年3月4号 Win11 23H2 起因 使用网上说的睡眠命令创建bat双击后,电脑风扇会运行一段时间后再停止(应该是在保存进程到硬盘&#…...

Spring Boot 接口 JSON 序列化优化:忽略 Null 值的九种解决方案详解
一、针对特定接口null的处理: 方法一:使用 JsonInclude 注解 1.1 类级别:在接口返回的 DTO 类或字段 上添加 JsonInclude 注解,强制忽略 null 值: 类级别:所有字段为 null 时不返回 JsonInclude(Js…...

计算机毕业设计Python+DeepSeek-R1大模型考研院校推荐系统 考研分数线预测 考研推荐系统 考研(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

一、Prometheus架构
Prometheus 云原生十二要素是一套最佳实践和规范,旨在帮助开发人员更好地构建云原生应用 这十二个要素分别是: 单一职责独立部署无状态声明式API服务发现容错处理自适应算法自动化运维响应式编程通信协议服务注册与发现数据持久化一、Prometheus 是什么 Prometheus 是一个…...

火山引擎 DeepSeek R1 API 使用小白教程
一、火山引擎 DeepSeek R1 API 申请 首先需要三个要素: 1)API Key 2)API 地址 3)模型ID 1、首先打开火山引擎的 DeepSeek R1 模型页面 地址:账号登录-火山引擎 2、在页面右下角,找到【推理】按钮&#…...

react+vite+pnpm+ts基础项目搭建
1. 项目初始化 pnpm create vitelatest my-react-app --template react-ts cd my-react-app pnpm install2. 核心依赖安装 # 基础依赖 pnpm add react-router-dom tanstack/react-query zustand axios# UI 组件库 (任选其一) pnpm add mui/material emotion/react emotion/st…...

ArcGIS Pro 经纬网添加全解析:从布局到样式优化
在地理信息系统的广阔领域中,地图的精确性与直观性对于数据的呈现和分析起着至关重要的作用。 经纬网,作为地图上不可或缺的元素之一,能够为用户提供准确的地理坐标参考,帮助用户快速定位和理解地理空间数据的分布。 本文将深入…...

新闻研究导刊杂志社《新闻研究导刊》编辑部2024年第23期目录
研究论文 媒介智能化环境下新闻传播面临的风险及应对策略研究 冶玉娜; AI赋能地方政务新媒体智能化转型策略研究——以佛山政务新媒体为例 温秀妍; 新闻传播在社交媒体影响下的流变与发展展望 李晋; 县级融媒体中心生产优质短视频的路径探索 陈政清; 数字游…...
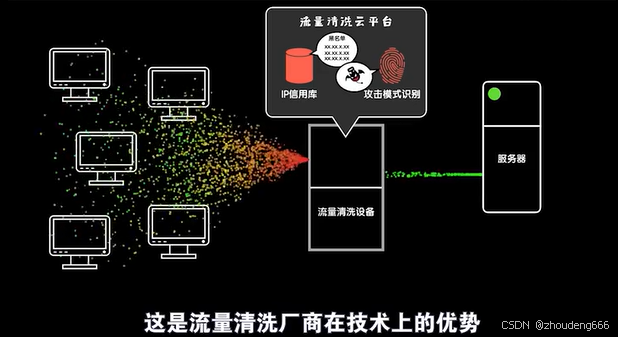
DDoS攻击的介绍和防治
一.DDoS攻击是什么 DDoS攻击:dos是服务器拒绝提供服务的意思,最前面的D是分布式的意思,所以说这个大概可以理解为分布式的机器攻击服务器,占用服务器资源,使得服务器拒绝提供服务的一种攻击手段,虽然原理简…...

UDP透传程序
UDP透传程序 本脚本用于在 设备 A 和 设备 B 之间建立 UDP 数据转发桥梁,适用于 A 和 B 设备无法直接通信的情况。 流程: A --> 电脑 (中继) --> B B --> 电脑 (中继) --> A 需要修改参数: B_IP “192.168.1.123” # 设备 B 的…...

深度学习pytorch之简单方法自定义9种卷积即插即用
本文详细解析了 PyTorch 中 torch.nn.Conv2d 的核心参数,通过代码示例演示了如何利用这一基础函数实现多种卷积操作。涵盖的卷积类型包括:标准卷积、逐点卷积(1x1 卷积)、非对称卷积(长宽不等的卷积核)、空…...

TMS320F28P550SJ9学习笔记2:Sysconfig 配置与点亮LED
今日学习使用Sysconfig 对引脚进行配置,并点亮开发板上的LED4 与LED5 我的单片机开发板平台是 LAUNCHXL_F28P55x 我是在上文描述的驱动库C2000ware官方例程example的工程基础之上进行添加功能的 该例程路径如下:D:\C2000Ware_5_04_00_00\driverlib\f28p…...

Webhook测试工具终极对决:开源自建与云端托管的决策指南
Webhook测试工具终极对决:开源自建与云端托管的决策指南 【免费下载链接】webhook.site ⚓️ Easily test HTTP webhooks with this handy tool that displays requests instantly. 项目地址: https://gitcode.com/gh_mirrors/we/webhook.site 在当今API驱动…...

赛事直播预告|高含金量智能车竞赛,邀你逐梦无人驾驶赛道!
简 介: 第二十一届全国大学生智能汽车竞赛创意组"智慧城市Robotaxi挑战赛"即将启动。作为教育部认可的A类国家级学科竞赛,赛事聚焦纯视觉无人驾驶技术,依托百度多模态能力与边缘AI算力,考验参赛者的视觉、语言、执行融合…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan集成详细攻略
2026年京东云OpenClaw/Hermes Agent配置Token Plan集成详细攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

【Perplexity环境新闻搜索实战指南】:20年老炮亲授3大避坑法则与实时情报提纯术
更多请点击: https://intelliparadigm.com 第一章:Perplexity环境新闻搜索实战指南导论 Perplexity 是一款以实时、可信与上下文感知为设计核心的 AI 搜索工具,其底层融合了多源新闻 API、语义检索模型及动态引用验证机制,特别适…...

STM32MP25x嵌入式Linux平台:集成XFCE、VNC、TSN的工业边缘计算解决方案
1. 项目概述:一个面向工业边缘的“瑞士军刀”级嵌入式平台最近,我们团队基于STM32MP25x系列核心板,成功构建并发布了一套完整的Debian系统镜像。这个项目的目标非常明确:打造一个开箱即用、功能全面、且能无缝覆盖从传统工业控制到…...

YOLOv5实战解析——激活函数的选择与调优
1. 激活函数在YOLOv5中的核心作用 第一次接触YOLOv5时,我被它的检测精度惊艳到了。但真正让我困惑的是:为什么同样的网络结构,换个激活函数效果就天差地别?后来在调试一个工业质检项目时,我才彻底明白激活函数的重要性…...

AUTOSAR Ea模块深度剖析:从原理到实战的EEPROM抽象层配置与优化
1. 项目概述:为什么我们需要深入理解Ea模块?在AUTOSAR的软件架构里,NVRAM管理器(NvM)负责非易失性数据的抽象管理,而Ea(EEPROM Abstraction,EEPROM抽象)模块,…...

别再硬算方程了!用Zemax的‘傻瓜式’方法搞定三片摄影物镜设计
颠覆传统:用Zemax高效设计三片摄影物镜的实战指南 在光学设计领域,三片摄影物镜一直被视为经典案例,它既包含了基础光学原理的精髓,又能满足实际摄影需求。然而,传统设计流程中繁琐的方程求解和反复试错让许多工程师望…...
)
保姆级教程:用Python+OpenCV高效切割Potsdam语义分割数据集(附完整代码)
PythonOpenCV实战:Potsdam语义分割数据集高效切割全流程解析 第一次接触Potsdam数据集时,面对那些6000x6000像素的巨幅航拍图像,我的GPU在训练时直接报显存不足的错误。这让我意识到,高分辨率图像的切割预处理不是可选项…...

告别Minecraft模组英文界面:MASA全家桶汉化包完全指南
告别Minecraft模组英文界面:MASA全家桶汉化包完全指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经在Minecraft中面对满屏的英文模组界面感到困惑?…...