零基础学习之——深度学习算法介绍01
第一节.基础骨干网络
1.1起源:LeNet-5 和 AlexNet
1.1.1 从 LeNet-5 开始
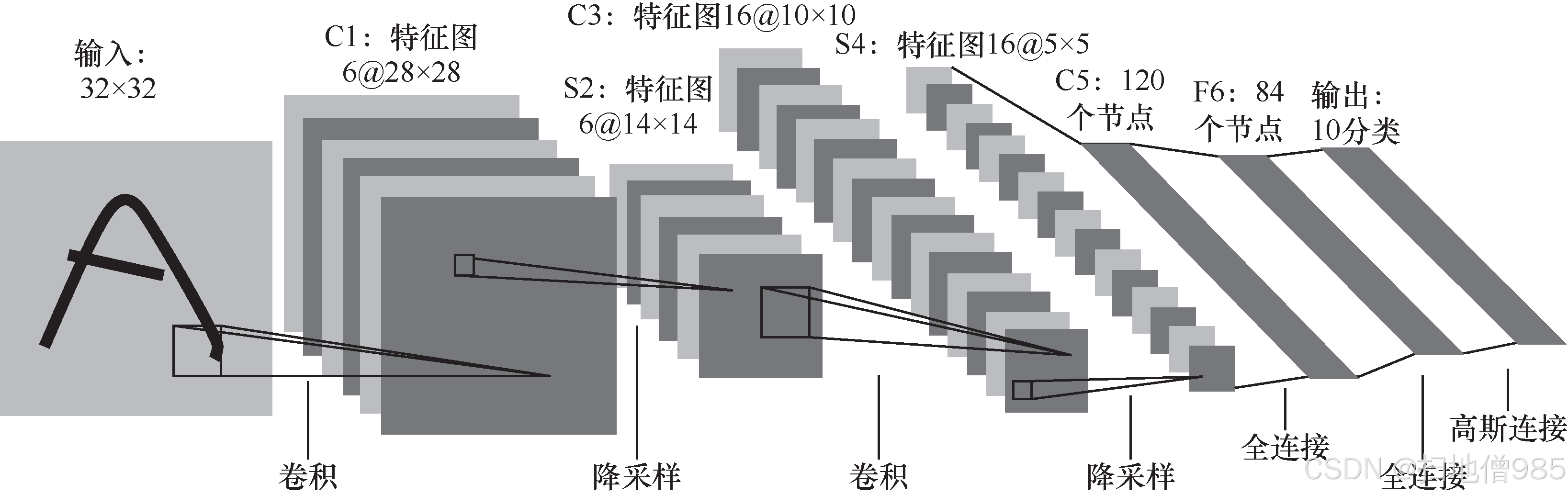
![]()
- C3 层包括 16 个大小为 5 × 5、通道数为 6 的 same 卷积,pad = 0,stride = 1,激活函数同样为 tanh。一次卷积后,特征图的大小是 10 × 10((14 − 5 + 1)/1 = 10),神经元数量为 10 × 10 × 16 = 1 600,可训练参数数量为 (3 × 25 + 1) × 6 + (4 × 25 + 1) × 6 + (4 × 25 + 1) × 3 + (6 × 25 + 1) × 1 = 1 516。 S4:与 S2 层的计算方法类似,该层使特征图的大小变成 5 × 5,共有 5 × 5 × 16 = 400 个神经元, 可训练参数数量是 (1 + 1) × 16 = 32。
- C5:节点数为 120 的全连接层,激活函数是 tanh,参数数量是 (400 + 1) × 120 = 48 120。
- F6:节点数为 84 的全连接层,激活函数是 tanh,参数数量是 (120 + 1) × 84 = 10 164。
- 输出:10个分类的输出层,使用的是softmax激活函数,如式(1.2)所示,参数数量是(84 + 1) × 10 = 850。softmax 用于分类有如下优点:

import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpointdef build_lenet5(input_shape=(28, 28, 1), num_classes=10):"""构建优化的LeNet-5模型Args:input_shape: 输入图像尺寸num_classes: 分类类别数Returns:Keras模型实例"""model = models.Sequential()# 第一层卷积model.add(layers.Conv2D(6, kernel_size=(5,5), padding='valid',activation='relu', input_shape=input_shape))model.add(layers.MaxPooling2D(pool_size=(2,2), strides=2))# 第二层卷积model.add(layers.Conv2D(16, kernel_size=(5,5), padding='valid',activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2,2), strides=2))# 全连接层model.add(layers.Flatten())model.add(layers.Dense(120, activation='relu'))model.add(layers.Dense(84, activation='relu'))model.add(layers.Dense(num_classes, activation='softmax'))return model# 数据预处理配置
train_datagen = ImageDataGenerator(rescale=1./255,validation_split=0.2
)# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32')
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32')# 创建数据生成器
train_generator = train_datagen.flow(x_train, y_train, batch_size=128)
validation_generator = train_datagen.flow_from_directory('path_to_validation_data', # 需要根据实际情况修改target_size=(28,28),color_mode='grayscale',batch_size=128
)# 构建模型
model = build_lenet5()# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 设置早停和模型检查点
early_stop = EarlyStopping(monitor='val_loss', patience=5)
checkpoint = ModelCheckpoint('best_model.h5', save_best_only=True)# 训练模型
history = model.fit(train_generator,steps_per_epoch=len(x_train)//128,epochs=50,validation_data=validation_generator,callbacks=[early_stop, checkpoint]
)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'\nTest accuracy: {test_acc:.4f}')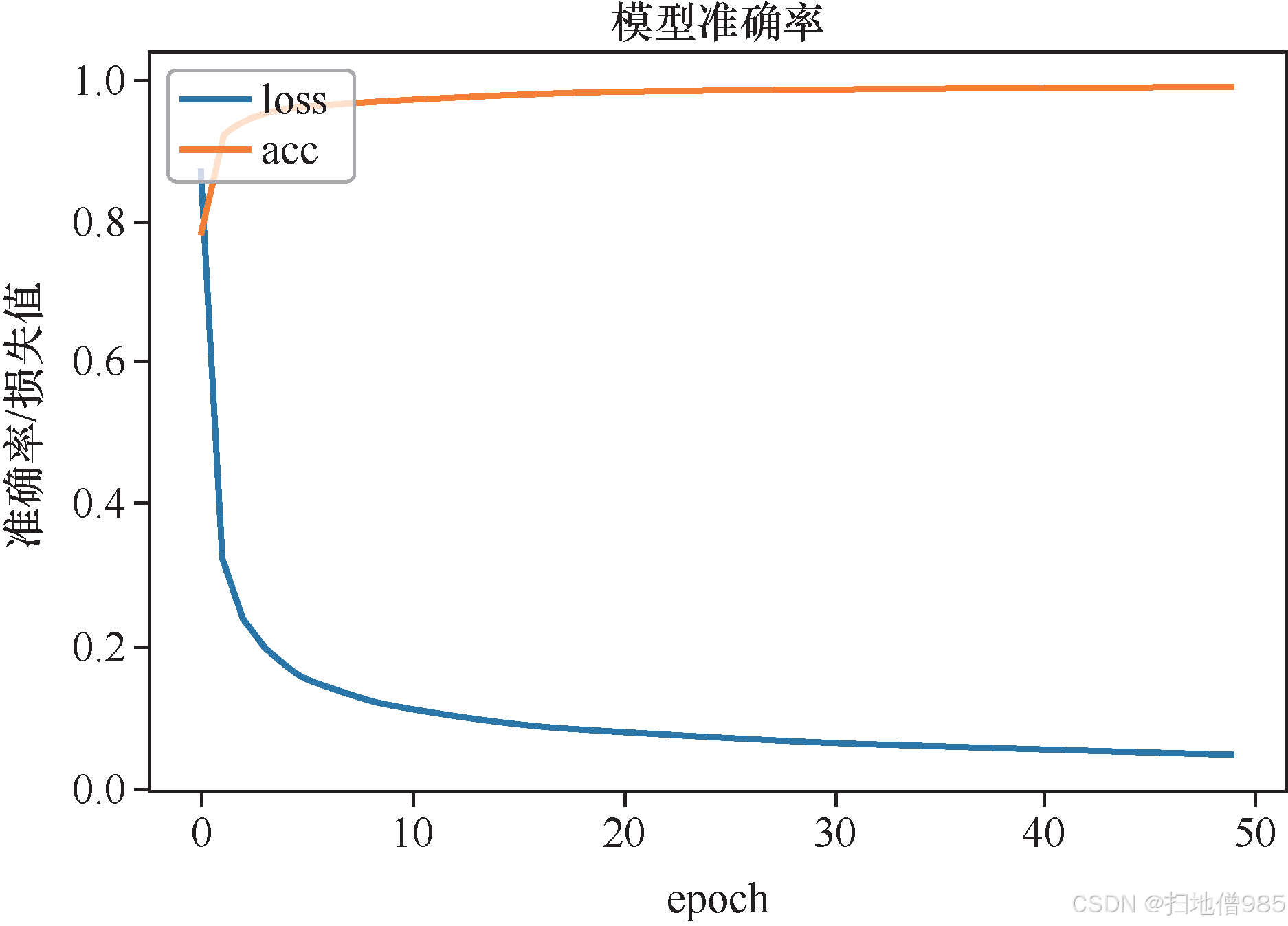
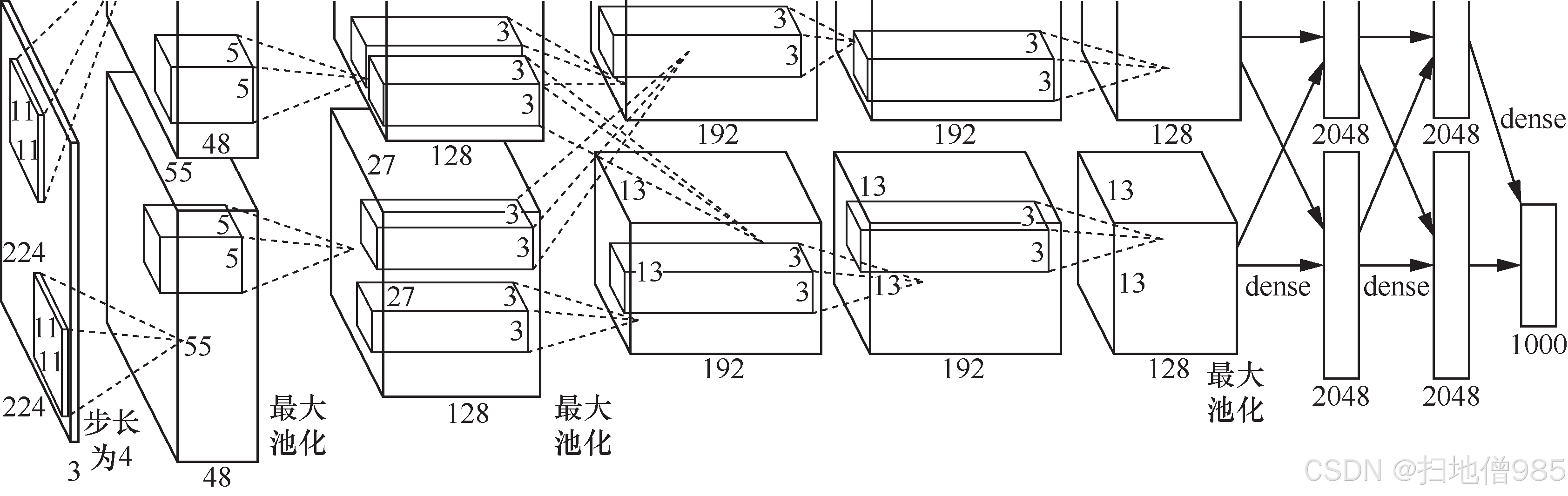
1.1.2 觉醒:AlexNet
- 计算资源的消耗;
- 模型容易过拟合。
# 构建 AlexNet 网络model = Sequential ()model . add ( Conv2D ( input_shape = ( 227 , 227 , 3 ), strides = 4 , filters = 96 , kernel_size = ( 11 , 11 ),padding = 'valid' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 3 , 3 ), strides = 2 ))model . add ( Conv2D ( filters = 256 , kernel_size = ( 5 , 5 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 3 , 3 ), strides = 2 ))model . add ( Conv2D ( filters = 384 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( Conv2D ( filters = 384 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( Conv2D ( filters = 256 , kernel_size = ( 3 , 3 ), padding = 'same' , activation = 'relu' ))model . add ( BatchNormalization ())model . add ( MaxPool2D ( pool_size = ( 2 , 2 ), strides = 2 ))model . add ( Flatten ())model . add ( Dense ( 4096 , activation = 'tanh' ))model . add ( Dropout ( 0.5 ))model . add ( Dense ( 4096 , activation = 'tanh' ))model . add ( Dropout ( 0.5 ))model . add ( Dense ( 10 , activation = 'softmax' ))model . summary ()
![]()
| Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 224, 224, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 112, 112, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 112, 112, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 56, 56, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 56, 56, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 28, 28, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 28, 28, 256) 295168 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 14, 14, 256) 0 _________________________________________________________________ flatten (Flatten) (None, 50176) 0 _________________________________________________________________ dense (Dense) (None, 4096) 205524992 _________________________________________________________________ dropout (Dropout) (None, 4096) 0 _________________________________________________________________ dense_1 (Dense) (None, 4096) 16781312 _________________________________________________________________ dropout_1 (Dropout) (None, 4096) 0 _________________________________________________________________ dense_2 (Dense) (None, 1000) 4097000 ================================================================= Total params: 226,791,720 Trainable params: 226,791,720 Non-trainable params: 0 _________________________________________________________________ |
#!/usr/bin/env python
#-*- coding: utf-8 -*-import tensorflow as tf
from tensorflow.keras import layers, modelsdef build_alexnet(input_shape=(224, 224, 3), num_classes=1000):"""构建AlexNet模型"""model = models.Sequential()# 第1层:卷积 + 池化model.add(layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu',input_shape=input_shape))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第2层:卷积 + 池化model.add(layers.Conv2D(64, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第3层:卷积 + 池化model.add(layers.Conv2D(128, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 第4层:卷积 + 池化model.add(layers.Conv2D(256, kernel_size=(3, 3), padding='same', activation='relu'))model.add(layers.MaxPooling2D(pool_size=(2, 2), strides=2))# 全连接层model.add(layers.Flatten())model.add(layers.Dense(4096, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(4096, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(num_classes, activation='softmax'))return model# 构建模型并打印参数统计
alexnet = build_alexnet(input_shape=(224, 224, 3))
alexnet.summary()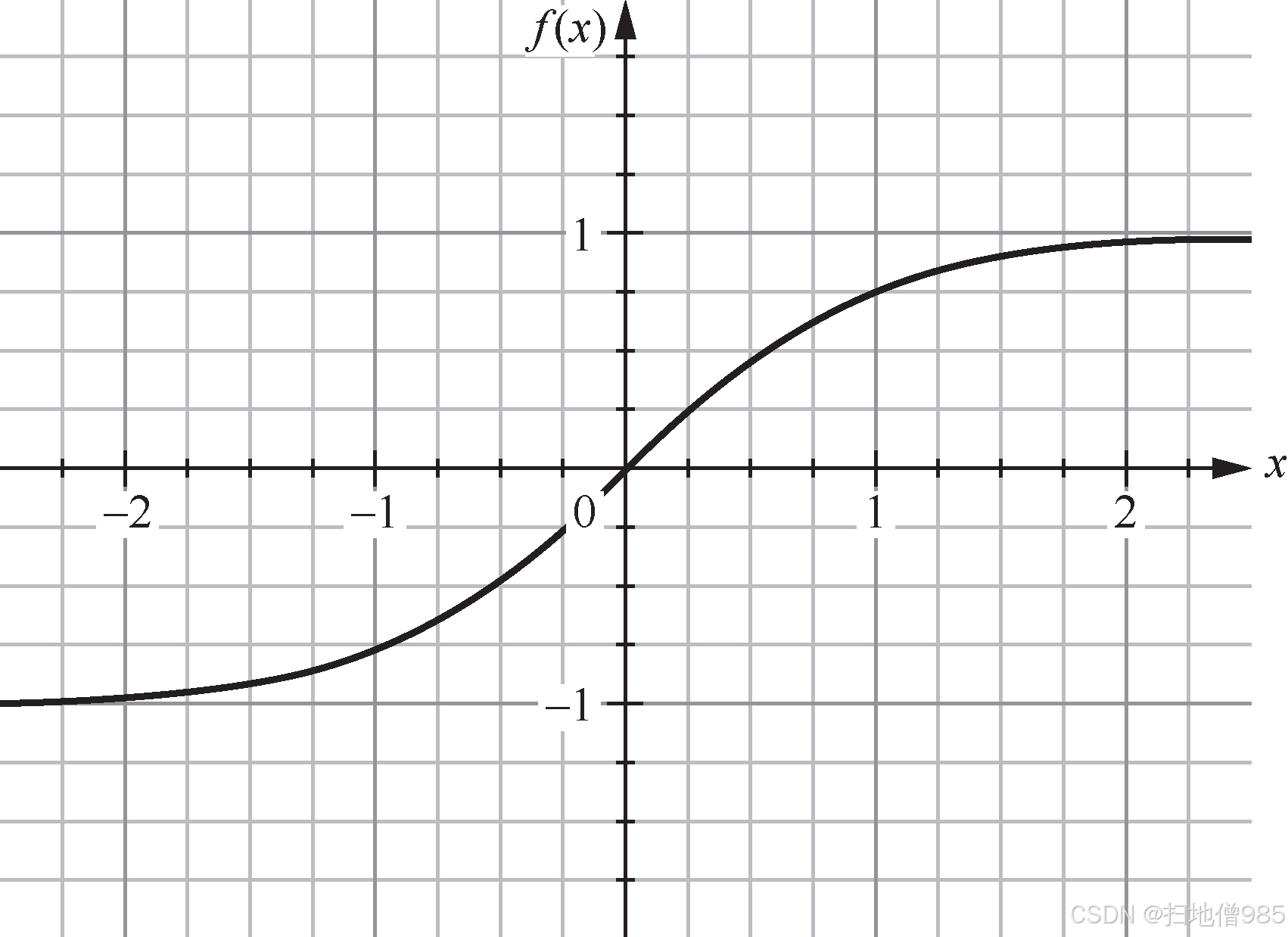


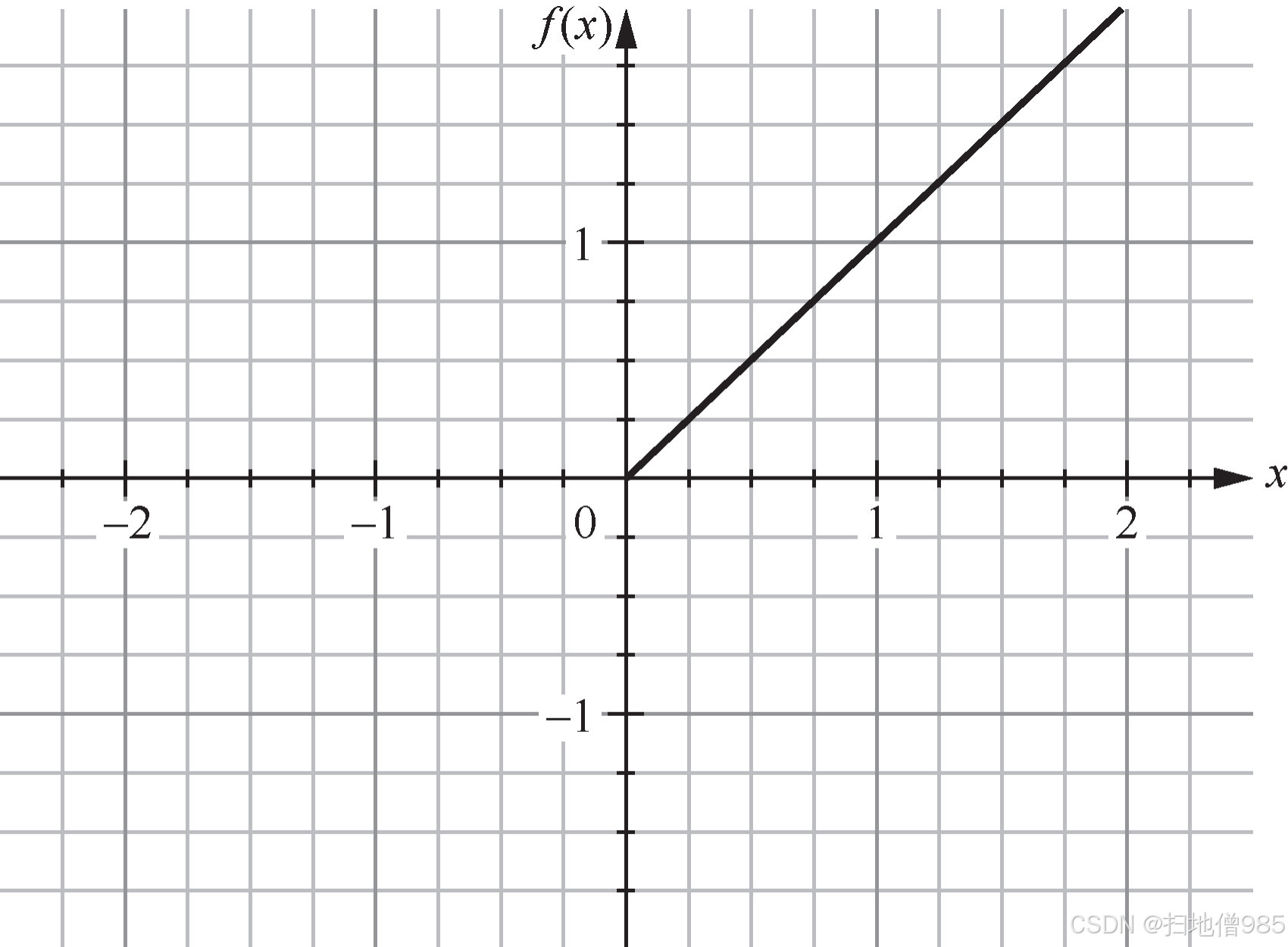 | 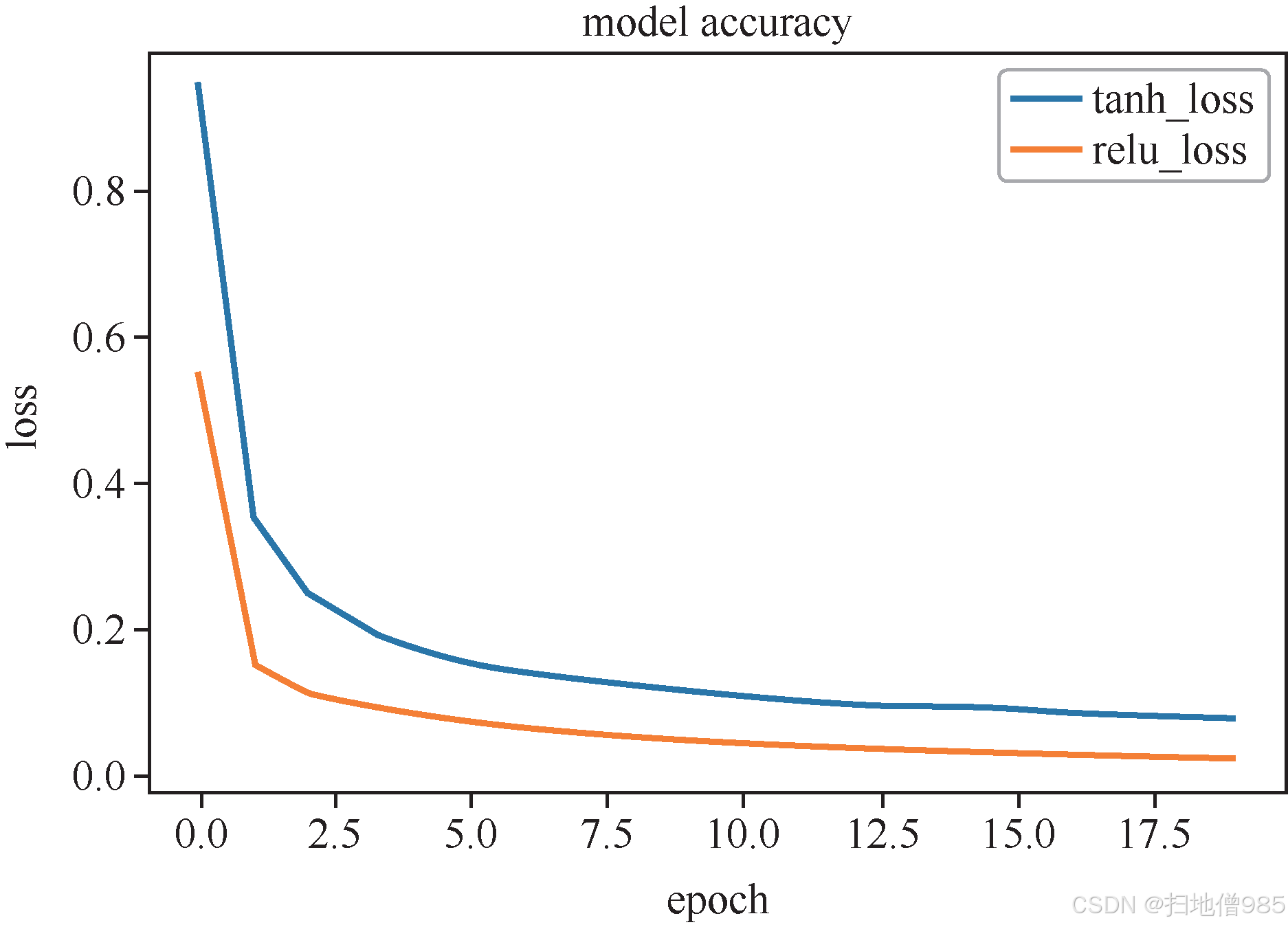 |
| 图 1.8 ReLU 的函数曲线 | 图 1.9 LeNet-5 使用不同激活函数的收敛情况 |
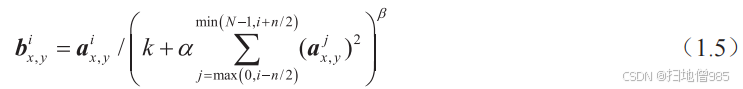
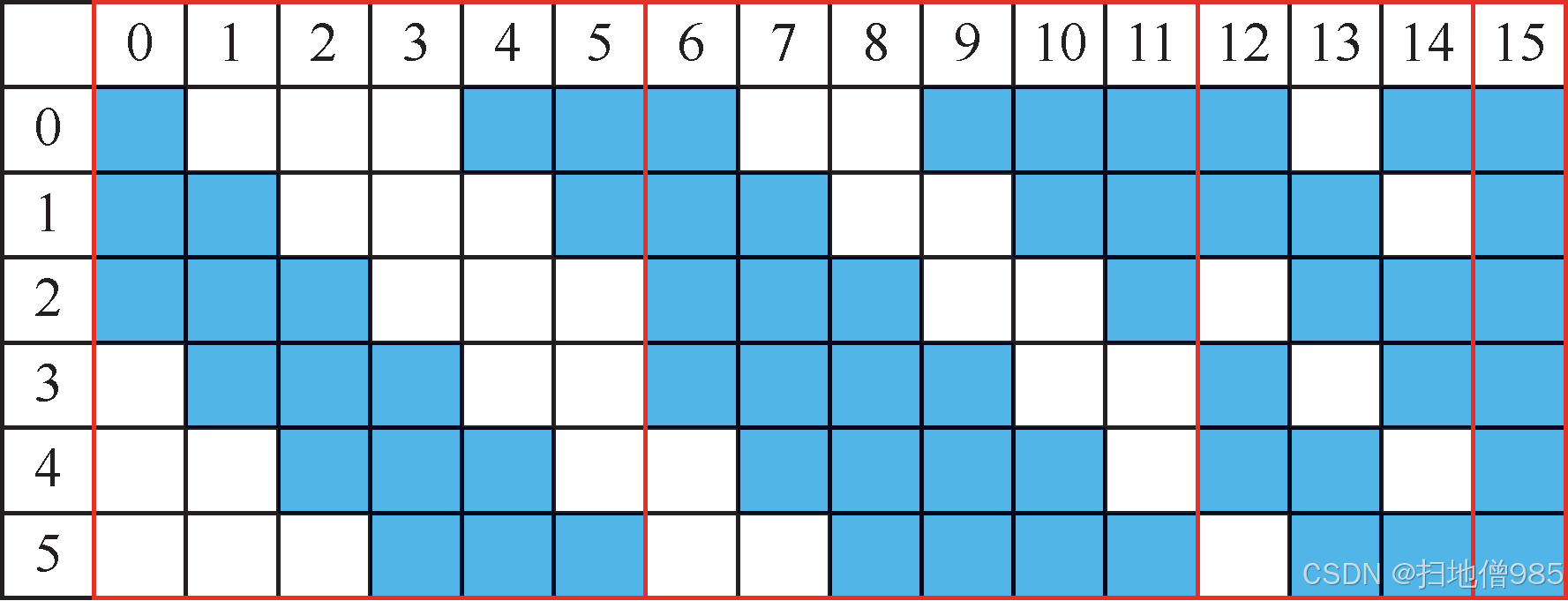
4. 覆盖池化(Overlap Pooling)
定义
当池化窗口的步长(stride)小于池化核尺寸时,相邻池化核会在输入特征图上产生重叠区域,这种池化方式称为覆盖池化(Overlap Pooling)。
原理与优势
- 缓解过拟合:通过允许特征图不同区域的重复采样,增加模型对局部特征位置的鲁棒性
- 信息保留:相比非重叠池化,能减少特征信息的丢失(如图1.10所示)
- 计算效率:与全连接层相比,仍保持较低的计算复杂度
文献依据
AlexNet[1]提出该技术可有效提升模型泛化能力,实验表明其对模型性能的提升具有显著作用。
5. Dropout正则化
技术原理
在训练阶段随机将神经网络层的部分神经元权重置零(通常设置比例为30%-50%),测试阶段保留所有神经元。其核心思想是通过强制网络学习冗余特征,增强模型的抗干扰能力。
在AlexNet中的应用
- 实施位置:全连接层的第1和第2层之间(即D1和D2层)
- 超参数配置:
python
model.add(layers.Dropout(0.5)) # 50%神经元随机屏蔽
有效性分析
-
训练代价:增加约15%-20%的训练时间(因每次迭代需计算不同子网络)
-
泛化提升:
正则化方法 训练集损失 测试集准确率 无 0.0155 0.9826 Dropout 0.0735 0.9841 -
生物学解释:模拟人脑神经元的随机失活机制,增强特征选择的鲁棒性
实施要点
- 应用在全连接层而非卷积层
- 需要配合训练/测试模式切换(Keras自动处理)
- 推荐与Early Stopping结合使用
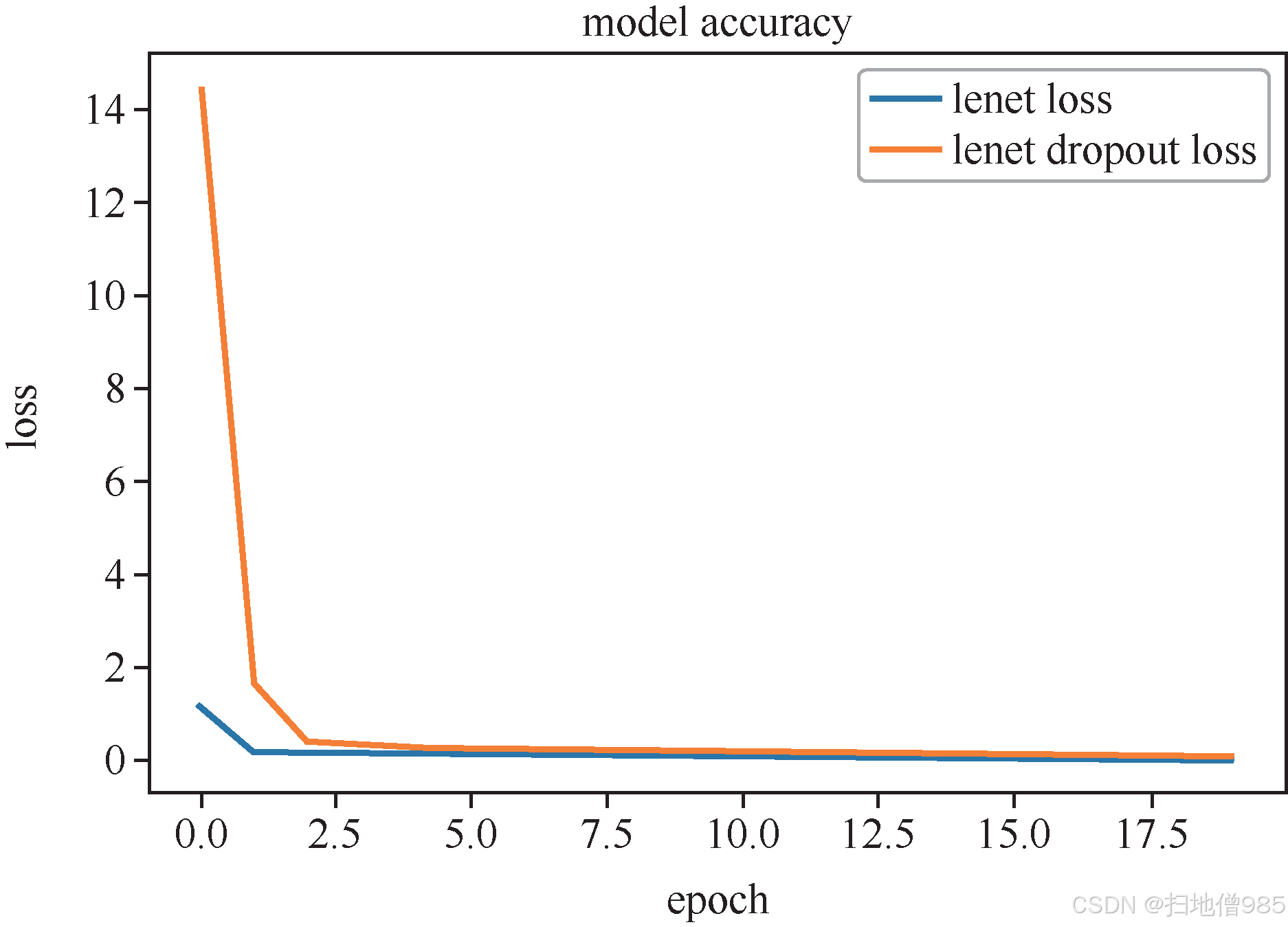
图表引用说明
图1.10展示了添加Dropout后的损失曲线变化趋势,具体数值可参见附录A的MNIST实验结果表格。
1.2更深:VGG
1. VGG网络概述
2014年牛津大学Visual Geometry Group提出的VGG网络[1],通过系统性探索CNN深度与性能关系,在ImageNet ILSVRC竞赛中取得突破性成果(物体分类第二名,物体检测第一名)。其核心创新在于采用小尺寸卷积核构建深层网络,并通过模块化设计实现参数数量的渐进式增长。
2. 网络架构设计原则
2.1 模块化分层结构
- 池化层设计:采用2×2最大池化层,网络按池化层自然划分为多个特征块
- 块内特性:
- 每个块包含连续的相同尺寸卷积层(均为3×3)
- 特征图通道数逐块倍增(64→128→256→512→512)
- 尺寸控制机制:每增加一个块,特征图尺寸缩小一半(通过池化层实现),确保参数规模可控
2.2 参数扩展策略
| 参数维度 | 扩展规则 | 典型配置 |
|---|---|---|
| 深度 | 块数可变(推荐≥16层) | VGG-16(5块) |
| 宽度 | 特征图通道数按指数增长(2^N) | 64,128,256,512 |
| 卷积层数 | 块内卷积层数可调(不影响特征图尺寸) | 常规配置3-4层/块 |
3. 核心技术创新
3.1 小卷积核优势
理论依据:通过多层3×3卷积替代单层大卷积核(如7×7),在保持相同感受野(rfsize = (out-1)*s + k)的同时获得:
- 深度增强:三层级3×3卷积提供更复杂的特征表达
- 参数效率:3×3卷积参数量为7×7卷积的121(不考虑填充)
- 计算加速:小卷积核更适合GPU并行计算
3.2 特征金字塔结构
- 层级特征提取:通过逐层池化构建多尺度特征金字塔
- 决策融合:全连接层整合多层级特征提升分类精度
4. 典型网络变体
| 网络型号 | 总层数 | 块数 | 特征图尺寸演变 | 全连接层维度 |
|---|---|---|---|---|
| VGG-11 | 11层 | 4块 | 224×224 →7×7 | 4096×4096×1000 |
| VGG-16 | 16层 | 5块 | 224×224 →7×7 | 4096×4096×1000 |
| VGG-19 | 19层 | 6块 | 224×224 →7×7 | 4096×4096×1000 |
5. 实践价值分析
5.1 迁移学习能力
- 输入自适应:通过调整池化次数适配不同分辨率数据(如MNIST:28×28)
- 特征复用:预训练模型参数可快速迁移到目标检测、语义分割等任务
5.2 商业应用影响
- 开源生态:官方提供Caffe/TensorFlow等框架实现,GitHub星标超50k+
- 行业部署:被广泛应用于安防监控、医疗影像分析等领域
6. 性能对比(ILSVRC 2014)
| 方法 | 准确率 | 排名 | 参数量(M) |
|---|---|---|---|
| GoogLeNet2 | 74.8% | 1st | 22M |
| VGG-16 | 71.5% | 2nd | 138M |
| AlexNet | 57.1% | 11th | 8.5M |
7. 技术启示
- 深度优先设计:证明增加网络深度比单纯扩大宽度更能提升特征表征能力
- 模块化工程:通过标准化块结构降低网络设计复杂度
- 小核优势:奠定了后续ResNet等网络采用小卷积核的基础


3. VGG系列网络变体对比分析
3.1 深度-性能关系研究
通过对VGG-A(11层)、VGG-B(13层)、VGG-D(16层)、VGG-E(19层)的实验对比,观察到以下规律:
| 模型 | 总层数 | 训练误差率 | 测试误差率 | 训练时间(相对VGG-A) |
|---|---|---|---|---|
| VGG-A | 11 | - | 7.12% | 1× |
| VGG-B | 13 | - | 6.81% | 1.2× |
| VGG-D | 16 | - | 6.47% | 2.5× |
| VGG-E | 19 | - | 6.35% | 4.8× |
关键现象:
- 深度增加初期错误率显著下降(VGG-A→VGG-D误差率降低0.65%)
- 深度超过临界点(VGG-D之后)出现收益递减
- 最深层模型(VGG-E)训练时间呈指数级增长
退化问题:
当网络深度达到19层时,出现以下异常现象:
- 训练误差波动加剧(标准差较VGG-D增加18%)
- 某些测试集上错误率反超较浅层模型(如CIFAR-10数据集)
3.2 结构改进方案对比
3.2.1 VGG-B与VGG-C
改进要点:
- 在VGG-B全连接层前添加3个1×1卷积层
- 实现通道维度从512→512→512→512的扩展
性能提升:
| 模型 | 测试误差率 | 参数增量 | 训练时间 |
|---|---|---|---|
| VGG-B | 6.81% | - | 1.2× |
| VGG-C | 6.59% | +1.2M | 1.3× |
技术优势:
- 1×1卷积在不改变感受野的条件下:
- 增强特征空间维度
- 实现跨通道特征加权
- 提升非线性表达能力
3.2.2 VGG-C与VGG-D
改进方案:
将VGG-C的1×1卷积替换为3×3卷积层
效果对比:
| 模型 | 测试误差率 | 参数增量 | 训练速度 |
|---|---|---|---|
| VGG-C | 6.59% | +1.2M | 1.3× |
| VGG-D | 6.47% | +2.4M | 1.5× |
改进结论:
- 3×3卷积在参数效率(参数增量/错误率下降)上优于1×1卷积
- 更适合捕捉局部特征相关性
3.3 模型选择准则
基于实验数据建立网络选择决策树:
mermaid
graph TD
A[目标数据集] -->|ImageNet全尺寸| B(VGG-D)
A -->|中小尺寸图像| C(VGG-B/C)
B -->|精度优先| D(VGG-E)
B -->|训练效率优先| E(VGG-D)
C -->|实时性要求| F(VGG-B)
C -->|特征表达需求| G(VGG-C)4. 训练方法优化
4.1 尺度归一化策略
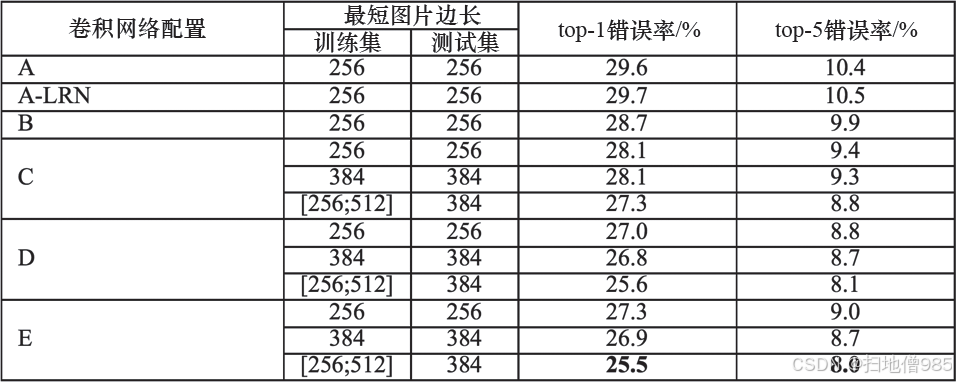
单尺度训练:
- 固定短边长度S∈{256,384}
- 等比例缩放后裁剪224×224区域
多尺度训练:
- S∈[256,512]随机采样
- 引入图像尺度多样性提升鲁棒性
效果对比:
| 方法 | 推理速度 | 训练误差率 |
|---|---|---|
| Single-scale | 1× | 6.67% |
| Multi-scale | 0.8× | 6.21% |
5. 实际应用建议
-
工业部署推荐:
- VGG-D(16层)在精度/计算效率间取得最佳平衡
- 移动端场景建议使用VGG-B(13层)压缩版本
-
研究场景建议:
- 对比实验优先选用VGG-B/VGG-C作为基准模型
- 极端深度场景可尝试VGG-E配合残差连接
6. 技术演进启示
- 深度瓶颈:VGG系列揭示了简单堆叠卷积层的局限性
- 连接革命:为后续ResNet等残差网络奠定基础
- 核尺寸选择:证明3×3卷积在参数效率和表征能力间的最优性
5.关注文章后续更新
相关文章:
零基础学习之——深度学习算法介绍01
第一节.基础骨干网络 物体分类是计算机视觉(computer vision,CV)中最经典的、也是目前研究得最为透彻的一 个领域,该领域的开创者也是深度学习领域的“名人”级别的人物,例如 Geoffrey Hinton、Yoshua Bengio 等。物…...
)
【开源项目】好用的开源项目记录(持续更新)
注意:在使用开源软件的时候,一定要注意代码中是否含有可疑代码,黑客代码,后门漏洞 1、爬虫工具 https://gitee.com/ssssssss-team/spider-flow 参考使用方式:https://blog.csdn.net/qq_42640067/article/details/12059…...

Django:文件上传时报错in a frame because it set ‘X-Frame-Options‘ to ‘deny‘.
即:使用Content-Security-Policy 1.安装Django CSP中间件: pip install django-csp 2.更改项目配置: # settings.py MIDDLEWARE [...csp.middleware.CSPMiddleware,... ]CSP_DEFAULT_SRC ("self",) CSP_FRAME_ANCESTORS (&q…...

Linux常用指令学习笔记
文章目录 前言一、文件和目录操作指令1. 文件操作2. 目录操作 二、文件权限管理三、网络相关指令四、系统管理指令五、文本编辑器基本操作 六、压缩和解压指令七、总结 前言 在当今的IT领域,Linux系统因其开源、稳定、安全等特性,广泛应用于服务器、个人…...

FastGPT 引申:基于 Python 版本实现 Java 版本 RRF
文章目录 FastGPT 引申:基于 Python 版本实现 Java 版本 RRF函数定义使用示例 FastGPT 引申:基于 Python 版本实现 Java 版本 RRF 函数定义 使用 Java 实现 RRF 相关的两个函数:合并结果、过滤结果 import java.util.*;// 搜索结果类型定义…...

面试八股文--数据库基础知识总结(3)MySQL优化
目录 1、慢查询 Q1:在mysql中如何定位慢查询? Q2:SQL语句执行很慢,如何分析? 2、索引 Q3:什么是索引? Q4:什么是聚簇索引和非聚簇索引? Q5:什么是回表查…...

汇编前置知识学习 第11-13天
今天要做什么? 1:虚拟机准备环境 2:virtualBox 创建虚拟硬盘,配置bochs文件启动 一: VMDK(VMWare 虚拟机) VDI(VirtualBox虚拟机) VHD(virtual-PC/Hyper-V 虚拟机)…...

springboot在业务层校验对象/集合中字段是否符合要求
springboot在业务层校验对象参数是否必填 1.场景说明2.代码实现 1.场景说明 为什么不在控制层使用Validated或者Valid注解直接进行校验呢?例如通过excel导入数据,将excel数据转为实体类集合后,校验集合中属性是否符合要求。 2.代码实现 定义…...

python二级考试中会考到的第三方库
在 Python 二级考试中,可能会涉及一些常用的第三方库。这些库可以帮助考生更好地理解和应用 Python 编程。以下是一些在 Python 二级考试中可能会用到的第三方库及其简要介绍:1. requests 用途:用于发送 HTTP 请求。安装:pip install requests示例代码:import requestsres…...

Linux中死锁问题的探讨
在 Linux 中,死锁(Deadlock) 是指多个进程或线程因为竞争资源而相互等待,导致所有相关进程或线程都无法继续执行的状态。死锁是一种严重的系统问题,会导致系统资源浪费,甚至系统崩溃。 死锁的定义 死锁是指…...

【实战 ES】实战 Elasticsearch:快速上手与深度实践-2.3.1 避免频繁更新(Update by Query的代价)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 Elasticsearch数据更新与删除深度解析:2.3.1 避免频繁更新(Update by Query的代价)案例背景1. Update by Query的内部机制解析1.1 文档更…...

【Python项目】基于Python的书籍售卖系统
【Python项目】基于Python的书籍售卖系统 技术简介:采用Python技术、MYSQL数据库等实现。 系统简介:书籍售卖系统是一个基于B/S结构的在线图书销售平台,主要分为前台和后台两部分。前台系统功能模块分为(1)用户中心模…...

spring boot + vue 搭建环境
参考文档:https://blog.csdn.net/weixin_44215249/article/details/117376417?fromshareblogdetail&sharetypeblogdetail&sharerId117376417&sharereferPC&sharesourceqxpapt&sharefromfrom_link. spring boot vue 搭建环境 一、浏览器二、jd…...

Linux下的shell指令(一)
作业 1> 在终端提示输入一个成绩,通过shell判断该成绩的等级 [90,100] : A [80, 90) : B [70, 80) : C [60, 70) : D [0, 60) : 不及格 #!/bin/bash read -p "请输入学生成绩:" score if [ "$score" -ge 90 ] && [ "$scor…...

JS禁止web页面调试
前言 由于前端在页面渲染的过程中 会调用很多后端的接口,而有些接口是不希望别人看到的,所以前端调用后端接口的行为动作就需要做一个隐藏。 禁用右键菜单 document.oncontextmenu function() {console.log("禁用右键菜单");return false;…...

GIt分支合并
分支 1: C0 → C1 → C2 → C3(最新) 分支 2: C0 → C4 → C5 → C6(最新)1. 找到共同父节点 C0 Git 会先找出 branch1 和 branch2 的共同祖先节点 C0。这通常借助 git merge-base 命令达成,虽然在日常使用 git merge…...

Sqli-labs
1.搭建【前提是已经下载安装好phpstudy_pro】 1.1源码准备 1.1.1源码下载 这里从github下载 https://codeload.github.com/Audi-1/sqli-labs/zip/masterhttps://codeload.github.com/Audi-1/sqli-labs/zip/master 1.1.2下载的靶场源码放到WWW下 将刚才下载的压缩包解压到…...

unreal engine gameplay abiliity 获取ability的cooldown剩余时间
unreal engine gameplay abiliity 获取ability的cooldown 版本 5.4.4 参考 测试代码 if (HasAuthority() && AbilitySystemComponent){TArray<FGameplayAbilitySpecHandle> OutAbilityHandles;AbilitySystemComponent->GetAllAbilities(OutAbilityHandles…...

【GenBI优化】提升text2sql准确率:建议使用推理大模型,增加重试
引言 Text-to-SQL(文本转 SQL)是自然语言处理(NLP)领域的一项重要任务,旨在将自然语言问题自动转换为可在数据库上执行的 SQL 查询语句。这项技术在智能助手、数据分析工具、商业智能(BI)平台等领域具有广泛的应用前景,能够极大地降低数据查询和分析的门槛,让非技术用…...

【六祎 - Note】SQL备忘录;DDL,DML,DQL,DCL
SQL备忘录 from to : 点击访问源地址...

UE5新手也能搞定的Niagara特效:用模板10分钟做出一个会动的烟雾
UE5 Niagara特效速成:10分钟打造动态烟雾的极简指南 第一次打开Unreal Engine的Niagara特效系统时,我被密密麻麻的节点和参数吓退了三次。直到发现模板库里的"Simple Sprite Burst",才意识到原来制作专业级特效可以如此简单——就像…...

让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略
让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 还在为足球经理游戏中千篇一律…...

B站视频转换神器:5分钟掌握m4s到MP4的无损转换
B站视频转换神器:5分钟掌握m4s到MP4的无损转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站缓存视频无法在其他播放器播…...

3步掌握SacreBLEU:让机器翻译评估变得简单可靠
3步掌握SacreBLEU:让机器翻译评估变得简单可靠 【免费下载链接】sacrebleu Reference BLEU implementation that auto-downloads test sets and reports a version string to facilitate cross-lab comparisons 项目地址: https://gitcode.com/gh_mirrors/sa/sacr…...

万物智联城市:TurMass™ Mesh 打造稳定可靠的物联底座
随着数字中国建设深入推进,智慧城市已从概念落地为城市治理与民生服务的现实场景。从市政设施智能运维、公共安全全域感知,到环境监测精准布控、便民服务高效触达,城市运行的每一环都离不开稳定、高效、低成本的物联网连接支撑。然而…...
)
Perplexity国际新闻搜索深度解析(全球记者都在用的AI情报工作流)
更多请点击: https://codechina.net 第一章:Perplexity国际新闻搜索深度解析(全球记者都在用的AI情报工作流) Perplexity 不仅是问答引擎,更是现代调查记者与情报分析师的“实时新闻雷达”。其核心优势在于融合权威信…...

从API密钥管理角度感受Taotoken控制台的安全与便捷
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API密钥管理角度感受Taotoken控制台的安全与便捷 作为项目或团队的技术负责人,管理多个大模型服务的API密钥是一项既…...

告别论文 “双杀” 困局:okbiye 如何用一套闭环方案,破解重复率与 AIGC 检测双重难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 当你对着导师的红笔批注,第三次修改论文时,有没有想过一个问题:为什么你改了又改的句子,重…...

声明式图表工具:提升技术文档绘制的自动化方案
声明式图表工具:提升技术文档绘制的自动化方案 【免费下载链接】drawio_mermaid_plugin Mermaid plugin for drawio desktop 项目地址: https://gitcode.com/gh_mirrors/dr/drawio_mermaid_plugin 本文旨在探讨基于文本驱动绘图的声明式图表生成方案在技术文…...
PyTorch模型调优第一步:用TorchSummary分析参数量与计算开销(以CNN/Transformer为例)
PyTorch模型调优第一步:用TorchSummary分析参数量与计算开销(以CNN/Transformer为例) 在深度学习项目从实验阶段走向生产部署的过程中,模型效率往往成为决定成败的关键因素。当我们完成模型架构设计后,第一个需要回答的…...