Java进阶:Zookeeper相关笔记
概要总结:
●Zookeeper是一个开源的分布式协调服务,需要下载并部署在服务器上(使用cmd启动,windows与linux都可用)。
●zookeeper一般用来实现诸如数据订阅/发布、负载均衡、命名服务、集群管理、分布式锁和分布式队列等功能。
●有多台服务器,每台服务器上部署一个zookeeper,在每个zookeeper中要创建myid文件,标注自己的id,然后在配置文件zoo.cfg中写好其它zookeeper的ip与通信端口,这些zookeeper之间就可以通信了。
●搭建zookeeper集群,一般是2n+1,防止投票选举时出问题。
●可以在zookeeper中创建节点、子节点,节点上可以保存数据;例如节点上保存数据库连接信息,供集群中的多个机器使用。
●可以使用cmd操作zookeeper。
●windows下操作zookeeper的命令(zkCli -server 127.0.0.1:2182)https://blog.csdn.net/zhangphil/article/details/100010629
●使用java操作zookeeper时,需要导入jar包,然后可以调用方法建立连接、创建节点、存取节点内容、删除节点、注册节点监听器等。
●使用java创建zookeeper连接对象时,可以同时连接多个zookeeper,就可以同时操作多个zookeeper了。(new方法中直接传入多个zookeeper的ip即可)
●在zookeeper集群中,如果只连接了其中一个zookeeper,进行了节点的创建/删除/修改数据,那么这个操作会自动同步到集群中的其它zookeeper上。(前提是正确搭建了zookeeper集群,就是zoo.cfg与myid文件配置正确)。如下图,在2181上创建了一个节点后,2182的再次查询,也会发现节点增加了。

●常用的jar包有org.apache.zookeeper、zkclient、curator等。
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency><dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.2</version>
</dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.12.0</version>
</dependency>
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>2.12.0</version>
</dependency>
注意要使用curator的节点监听器如NodeCache、PathChildrenCache等,需要导入上方的jar包:curator-recipes。
===========================================
笔记正文:
分布式服务治理、分布式协调服务Zookeeper深入
Zookeeper简介
Zookeeper最为主要的使用场景,是作为分布式系统的分布式协同服务。
分布式系统的协调工作就是通过某种方式,让每个节点的信息能够同步和共享。这依赖于服务进程之间的通信。通信方式有两种:
●通过网络进行信息共享。
●通过共享存储。
Zookeeper对分布式系统的协调,使用的是第二种方式,共享存储。其实共享存,分布式应用也需要和存储进行网络通信。
Zookeeper相当于SVN,存储了任务的分配、完成情况等共享信息。每个分布式应用的节点就是组员,订阅这些共享信息;
Zookeeper安排任务,节点得知任务分配,完成后将完成情况存储到Zookeeper。
可以说是把SVN与邮件系统合二为一,以Zookeeper代替。
大多数分布式系统中出现的问题,都源于信息共享出了问题。Zookeeper解决协同问题的关键,就是在于保证分布式系统信息的一致性。
-----------------------------
Zookeeper基本概念:
Zookeeper是一个开源的分布式协调服务,设计目标是将那些复杂的且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一些简单的接口提供给用户使用。Zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据订阅/发布、负载均衡、命名服务、集群管理、分布式锁和分布式队列等功能。
--------------------------------------------
角色:
在Zookeeper中,使用了Leader、Follower、Observer三种角色。
客户端发送读写请求,follower与leader都有可能收到;
Leader服务器为客户端提供读写服务;
Follower可以处理客户端发来的读请求。
也可以将客户端发来的写请求转发给leader;
leader接收到follower转发来的写请求后,会把写请求转换成带有各种状态的事务,并把该事务进行广播(发送proposal);
所有接收到proposal的follower就要进行投票,给leader返回ACK,包含是否可以执行的信息;
如果大部分的ACK表示可以执行,那么leader就会把事务提交请求发送给follower;
follower收到事务提交请求后,就会把事务操作记录到日志中,真正完成写操作;
最后,由接收到客户端请求的follower响应,写请求成功。
如果follower有很多时,投票会引起性能瓶颈;
所以出现了Observer:
Observer与follower在功能上相似,能接收读写请求;
不同的是,observer不进行投票,只作为投票结果的听众。
因此,observer可以减轻投票压力;并且在不影响写操作的情况下保证服务性能。
------------------------------
会话:
Session指客户端会话,一个客户端连接是指客户端和服务端之间建立的一个TCP长连接。
通过这个链接,客户端能够心跳检测与服务器保持有效的会话,也能够向服务器发送请求并接受响应,还能够通过该链接接受服务器的通知。
Zookeeper对外的服务器端口默认为2181。
------------------------
节点:指构成集群的机器,也称为机器节点。
数据节点Znode:指数据模型中的数据单元。
Zookeeper将所有数据存储在内存中,数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个Znode,例如/app/path1.每个ZNode上都会保存自己的数据内容,同时还会保存一系列属性信息。
----------------
版本:
对于每个Znode,Zookeeper都会为其维护一个叫做Stat的数据结构,Stat记录了这个ZNode的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前Znode字节点的版本)、aversion(当前Znode的ACL版本)。
--------------------------
Watcher(事件监听器):
Zookeeper允许用户在指定节点上注册Watcher,当特定事件触发的时候,zookeeper服务端会将事件通知到感兴趣的客户端,该机制是Zookeeper实现分布式协调服务的重要特性。
----------------------
ACL:
zookeeper采用ACL(Access Control Lists)策略来进行权限控制,其中定义了五种权限:
Create:创建子节点的权限。
Read:获取节点数据和子节点列表的权限。
Write:更新节点数据的权限。
Delete:删除子节点的权限。
Admin:设置节点的ACL权限。
其中,Create与Delete这两种权限都是针对子节点的权限控制。
--------------------------
zookeeper的leader选举:https://www.cnblogs.com/leesf456/p/6107600.html
================================
Zookeeper的安装方式有三种:
单机模式:Zookeeper只运行在一台服务器上,适合测试环境。
集群模式:zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个"集合体"
伪集群模式:就是在一台服务器上运行多个Zookeeper实例,更适合测试。
-------------------------
单机模式搭建:
以linux为例。
1.下载稳定版本的zookeeper:http://zookeeper.apache.org/releases.html
2.将下载好的zookeeper压缩包放入linux中(linux虚拟机)
3.解压zookeeper压缩包
4.在zookeeper目录下创建一个data文件夹
cd zookeeper-3.4.14
mkdir data
5.把zookeeper的conf目录下面的zoo_sample.cfg文件重命名为zoo.cfg
mv zoo_sample.cfg zoo.cfg
6.修改zookeeper配置文件zoo.cfg,将dataDir修改为data文件夹,用来保存快照文件与日志。
dataDir=/root/zookeeper-3.4.14/data
*还可以配置一个dataLogDir,单独把事务日志输出到另一个文件夹。
7.进入bin目录,输入命令启动zookeeper
./zkServer.sh start
8.关闭服务使用以下命令
./zkServer.sh.stop
---------------------------------
伪集群模式搭建:
注意事项:
一台机器上部署了3个Server,也就是说单台机器上运行多个Zookeeper实例。这种情况下,必须保证每个配置文档的各个端口号不能冲突,除clientPort不同之外,dataDir也不同。另外,还要在dataDir所对应的目录中创建myid文件来指定对应的Zookeeper服务器实例。
步骤:
1.将zookeeper解压三份,zookeeper-01,zookeeper-02,zookeeper-03
2.分别在三个zookeeper文件夹下创建data与log文件夹,用来存放快照文件与日志文件。
3.把每个zookeeper的conf目录下面的zoo_sample.cfg文件重命名为zoo.cfg
mv zoo_sample.cfg zoo.cfg
4.配置每一个zookeeper的dataDir、dataLogDir与clientPort(zoo.cfg里),注意clientPort不能相同。
5.注意每个zoo.cfg中的dataDir与dataLogDir的内容要修改为不同的。
配置集群:
1.在每个zookeeper的data目录下创建一个myid文件,内容分别是1、2、3。这个文件的作用就是记录每个服务器的ID。
touch myid
2.在每一个zookeeper的zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。将下面这三行放到zoo.cfg末尾即可。
server.1=10.200.30.4:2881:3881
server.2=10.200.30.4:2882:3882
server.3=10.200.30.4:2883:3883
#server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
#这三个server目前都在10.200.30.4上;123分别对应myid文件中的内容(整个文件就一个数字);注意服务器之间通信端口与投票端口之间也不能相同。
之后就可以启动这三个zookeeper。
可以在bin目录下使用./zkServer.sh status查看每个zookeeper状态,可以发现有一个是leader,其余的是follower
================================
Zookeeper系统模型
Zookeeper数据模型Znode:
在zookeeper中,数据信息被保存在一个个数据节点上,这些节点被称为znode。znode是zookeeper中最小数据单位,在znode下面又可以再挂znode,这样一层层下去就形成了一个层次化命名空间znode树(znode tree),它采用了类似文件系统的层级树状结构进行管理。
开发人员可以向这个节点写入数据,也可以在这个节点下面创建子节点。
Znode的类型,3类:
持久性节点(Persistent):创建后一直存在,直到手动删除。
临时性节点(Ephemeral):生命周期与客户端会话绑在一起,客户端会话结束,节点就会被删除。与持久性节点不同,临时节点不能创建子节点。
顺序性节点(Sequential):这个节点可以分两类:
持久顺序节点:顺序是指在创建节点的时候,会在节点名后加一个数字后缀,表示其顺序;其余特性与持久节点相同。
临时顺序节点:就是有顺序的临时节点,创建时会在名字后面加数字后缀。
事务ID:zookeeper中,对于每一个事务请求,都会分配一个全局唯一的事务ID,用ZXID表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序。
ZNode的状态信息
cZxid就是create ZXID,表示节点被创建时的事务ID。
ctime就是create Time,表示节点创建时间。
mZxid表示Modified ZXID,表示节点最后一次被修改时的事务ID。
mtime就是Modified Time,表示节点最后一次被修改的时间。
pZxid表示该节点的子节点列表最后一次被修改时的事务ID。只有子节点列表变更才会更新pZxid,子节点内容变更不会更新。
cversion表示子节点的版本号。
dataVersion表示内容版本号。
aclVersion表示acl版本。
ephemeralOwner表示创建该临时节点时的会话sessionID,如果是持久性节点那么值为0.
dataLength表示数据长度。
numChildren表示直系子节点数。
------------------------------
Watcher-数据变更通知
Zookeeper使用watcher机制实现分布式数据的发布/订阅功能
zookeeper允许客户端向服务端注册一个watcher监听,当服务端的一些指定事件触发了这个watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
-------------------
ACL-保障数据的安全
为了保障系统中数据的安全,避免因误操作所带来的数据随意变更而导致的数据库异常。
ACL:Access Controll List
可以从三个方面理解ACL机制:权限模式(Scheme)、授权对象(ID)、权限(Permission),通常使用"scheme🆔permission"来标识一个有效的ACL信息。
权限模式Scheme:
权限模式用来确定权限验证过程中使用的检验策略,有四种模式:
IP:IP模式就是通过IP地址来进行权限控制。
Digest:是最常用的权限控制模式,使用"username:password"形式的权限标识来进行权限配置,便于区分不同应用来进行权限控制。
World:是一种最开放的权限控制模式,几乎没有任何作用,数据节点的访问权限对所有用户开放。也可以看做一种特殊的Digest模式,它只有一个权限标识,即"world:anyone"。
Super:也是一种特殊的Digest模式,超级用户可以对任意Zookeeper上的数据节点进行任何操作。
授权对象:ID
授权对象指的是权限赋予的用户或一个指定实体,例如IP地址或是机器等。
权限:
指通过权限检查后可以被允许执行的操作。有五大类:
Create©:数据节点的创建权限,允许授权对象在该数据节点下创建子节点。
Delete(D):子节点的删除权限,允许授权对象删除该数据节点的子节点。
Read®:数据节点的读取权限,允许授权对象访问该数据节点并读取数据内容或子节点列表等。
Write(W):数据节点的更新权限,允许授权对象对该数据节点进行更新操作。
Admin(A):数据节点的管理权限,允许授权对象对该数据节点进行ACL相关的设置操作。
-----------------------------
Zookeeper命令行操作
借助客户端来对zookeeper的数据节点进行操作
首先,进入到zookeeper的bin目录之后,通过zkClient进入zookeeper客户端命令行
#连接本地的zookeeper服务器
./zkcli.sh
#连接指定的服务器
./zkcli.sh -server
创建节点
create [-s][-e] path data ac1
其中,-s或-e分别指定节点特性,顺序或临时节点,若不指定,则创建持久节点;path是节点路径,用/分割;data是当前节点存储的内容;acl用来进行权限控制。
例如:
创建顺序节点:
create -s /zk-test 123
创建临时节点:
create -e /zk-temp 123
创建持久节点:
create /zk-permanent 123
之后,可以使用【ls /】命令查看节点信息。
永久节点会一直存在,临时节点当client退出后就会消失。
--------------------------------
读取节点
ls path
其中,path表示节点路径,可以显示当前节点路径下子节点的列表
get path
其中,path表示节点路径,可以显示当前节点详细信息
-------------------------
更新节点
set path data [version]
其中,data就是要更新的新内容,version表示数据版本(可选参数)。
删除节点
delete path [version]
如果节点存在子节点,那么就无法删除该节点;需要先删除子节点,再删除根节点。
------------------------------------------
zookeeper的api使用
zookeeper的api共包含五个包,分别为:
(1)org.apache.zookeeper
(2)org.apache.zookeeper.data
(3)org.apache.zookeeper.server
(4)org.apache.zookeeper.server.quorum
(5)org.apache.zookeeper.server.upgrade
其中org.apache.zookeeper,包含zookeeper类,是编程时最常用的类文件。这个类是zookeeper客户端的主要类文件。
客户端需要创建一个zookeeper实例,与zookeeper服务器建立连接;zookeeper系统会给本次连接会话分配一个ID值,并且客户端会周期性的向服务器发送心跳来维持会话连接。只要连接有效,客户端就可以使用zookeeper的api进行操作。
1.导入依赖
org.apache.zookeeper
zookeeper
3.4.14
2.与服务器建立会话
public class CreateSession implements Watcher {
//允许等待一个线程
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throw IOException{
//连接地址,session超时时间,watcher监听器
Zookeeper zk = new Zookeeper(“127.0.0.1:2181”,5000,new CreateSession());
//Connecting ,此时并没有完全建立好链接
System.out.println(zk.getState());
//使用计数工具类:CountDownLatch让线程等待,不让main方法结束,让线程处于等待阻塞
countDownLatch.await();
System.out.println(“客户端与服务器的会话建立完成”);
}
//回调方法,处理来自服务器端的watcher通知;服务器建立连接成功后会发送事件通知,之后这个方法会被(客户端)调用
public void process(WatchedEvent watchedEvent){
// SyncConnected
if(watchedEvent.getState() == Event.KeeperState.SyncConnected){
//解除主程序在CountDownLatch上的等待阻塞
countDownLatch.countDown();
}
}
}
-------------------------------------
使用API创建节点
//使用同步方法创建节点,操作简单
private static void createNoteSync(){
/**
path:节点创建的路径
data[]:节点创建要保存的数据,是byte类型的。
acl:节点创建的权限信息(4种类型):
ANYONE_ID_UNSAFE,表示任何人;
AUTH_IDS,此ID仅可用于设置ACL,它将被客户机验证的ID替换。
OPEN_ACL_UNSAFE,这是一个完全开放的ACL(常用)。
CREATOR_ALL_ACL,此ACL授予创建者身份验证ID的所有权限。
createMode:创建节点的类型(4种类型):
PERSISTENT:持久节点
PERSISTENT_SEQUENTIAL:持久顺序节点
EPHEMERAL:临时节点
EPHEMERAL_SEQUENTIAL:临时顺序节点
*/
//这个返回结果就是节点的path,如果是顺序节点的话,path就有编号了
String node_persistent = zookeeper.create(“/persistent”,“持久节点内容”.getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(“创建的持久节点”+node_persistent);
}
注意,创建节点的方法需要移动到process中执行,并且main方法中要改为使用Thread.sleep()
---------------------------------------
使用API获取节点数据
//获取节点数据
public void getNoteData(){
/**
path:获取数据的路径
watch:是否开启监听
stat:节点状态信息;如果为null,表示获取最新版本的数据
*/
byte[] data = zookeeper.getData(“/persistent”,false,null);
System.out.println(new String(data));
}
//获取某个节点的字节点列表方法
public static void getChildrens(){
/**
path:路径
watch:是否要启动监听;如果为true,当子节点列表发生变化,会触发监听
*/
List list = zookeeper.getChildren(“/persistent”,true);
System.out.println(list);
}
这个方法中,watch的参数为true,所以当子节点列表发生变化时,服务器会通知客户端,客户端的public void process(WatchedEvent watchedEvent){}方法就会被执行。
需要注意,通知是一次性的,需要反复注册监听。
现在修改一下process,如下:
public void process(WatchedEvent watchedEvent){
//如果是子节点改变的事件
if(watchedEvent.getType() == Event.EventType.NodeChildrenChanged){
//重新获取子节点列表,并重新注册监听
List children = zookeeper.getChildren(“/persistent”, true);
}
}
个人对回调机制watcher的理解:客户端向服务器注册watcher后,服务器在触发相应事件时,会给客户端返回消息,并告诉客户端哪个watcher被触发了,然后由客户端实际执行watcher中的方法。注意客户端并没有将watcher对象发给服务器,并且回调时最终是由客户端执行的。
watcher详细讲解:
https://blog.csdn.net/ThreeAspects/article/details/103558797
-----------------------------------
使用API更新节点:
//更新数据节点内容的方法
private void updateNoteSync(){
/**
path:路径
data:要修改的内容 byte[]
version:为-1时,表示对最新版本的数据进行修改
*/
//获取修改前的值
byte[] data = zookeeper.getData(“/persistent”,false,null);
System.out.println(new String(data));
//修改这个节点的值,返回状态信息对象
Stat stat = zookeeper.setData(“/persistent”,“新的值”.getBytes(),-1);
}
-----------------------------------
使用API删除节点:
String path = “/persistent/c1”;
boolean watch = false;
Stat isExists = zookeeper.exists(path,watch);//判断节点是否存在
if(isExists != null){
zookeeper.delete(path,version);//删除节点
}
---------------------------------
zookeeper开源客户端
ZkClient:是github上一个开源的zookeeper客户端,在zookeeper原生API接口之上进行了包装,是一个更易使用的zookeeper客户端。同时,ZkClient在内部还实现了诸如Session超时重连、watcher反复注册等功能。
可以使用ZkClient进行创建会话、创建节点、读取数据、更新数据、删除节点等。
ZkClient依赖:
在pom.xml文件中添加如下内容
com.10ltec
zkclient
0.2
ZkClient创建会话:
创建一个ZkClient的实例就可以完成连接、完成会话的创建
ZkClient zkClient = new ZkClient(“127.0.0.1:2181”);
---------------------------
ZkClientc创建和删除节点:
ZkClient提供了递归创建节点的接口,
//看方法名,这个方法可以创建持久节点
//第二个参数是createParents,如果为true,就会递归创建节点
//创建了父节点zkclient,以及子节点c1
zkClient.createPersistent(“/zkclient/c1”,true);
删除节点,也可以递归:
//recursive是递归的意思
String path = “/zkclient/c1”;
String path2 = “/zkclient/c1/c11”;
//创建了三个节点,zkclient,c1,c11
zkClient.createPersistent(path2,true);
//删除了2个节点,c1,c11
zkClient.deleteRecursive(path);
-----------------------
//获取子节点列表
List children = zkClient.getChildren(“/zkclient”);
//注册监听事件,即使节点目前不存在,也可以注册。
zkClient.subscribeChildChanges(“/zkclient-new”,new IZkChildListener(){
//s:parentPath
//list:变化后的子节点列表
public void handleChildChange(String s,List list)throws Exception{
System.out.println(s + “的子节点发生变化:” + list);
}
});
//测试
zkClient.createPersistent(“/zkclient-new”);
============================
Curator
Curator是Netflix公司开源的一套Zookeeper客户端框架,和ZKClient一样,Curator解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连,反复注册Watcher和NodeExistsException异常等。支持fluent风格。
fluent风格:
set方法返回this,便于执行多个set方法。
有build()方法,可以创建该类的对象,可以做成单例。
Curator可以递归创建节点(创建子节点时、如果父节点存在则正常创建子节点;如果父节点不存在,则先创建父节点、再创建子节点),防止创建子节点时、父节点不存在、报错NoNodeException.
Curator也可以递归删除节点(删除该节点及以下的子节点)
=========================================
Zookeeper应用场景
zookeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,可以使用它来进行分布式数据的发布与订阅。
数据发布/订阅
发布者将数据发布到zookeeper的一个或一系列节点上,供订阅者进行数据订阅,达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。
发布/订阅系统一般有两种设计模式:
推(Push)模式:服务端主动将数据更新发送给所有订阅的客户端。
拉(Pull)模式:客户端主动发起请求来获取最新数据。
zookeeper采用的是推拉相结合的方式:客户端向服务器端注册自己需要关注的节点,一旦节点的数据发生变更,那么服务端就会向客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据。
数据发布订阅应用场景,共享数据库配置信息:
配置节点
使用zookeeper时,首先可以在zookeeper上选取一个数据节点,存储配置信息,例如数据库链接信息等。
配置获取
集群中的每台机器在启动初始化阶段,首先会从上面提到的zookeeper配置节点上读取数据库信息。同时,客户端也应该在配置节点上注册监听数据变更的watcher,一旦配置信息变更,所有订阅的客户端都能获取到数据变更通知。
配置变更
如果需要变更配置信息,只要修改配置节点上的配置信息即可,zookeeper会通知其余节点,并且客户端也能通过监听收到变更信息。
---------------------------
命名服务
命名服务(Name Service)也是分布式系统中比较常见的一类场景,是分布式系统最基本的公共服务之一。
例如,借助zookeeper生成全局唯一ID(可以改造为数据库全局唯一ID):
1.客户端使用create()接口创建一个顺序节点,例如创建"job-"节点。
2.zookeeper在创建顺序节点时,节点名会按顺序生成,例如创建"job-“节点,实际生成的节点名是"job-0000000001”,“job-0000000002”;create()接口返回的是完整的节点名。
3.客户端拿到返回值后,进行拼接,就可以作为全局唯一ID使用了。
---------------------------
集群管理:
在日常开发和运维中,经常有如下需求:
1.如何快速的统计出当前生产环境下一共有多少台机器
2.如何快速获取到机器上下线的情况
3.如何实时监控集群中每台主机的运行时状态
zookeeper的两大特性:
1.客户端如果对zookeeper的数据节点注册watcher监听,那么当该数据节点的内容或是其子节点列表发生变更时,zookeeper服务器就会向订阅的客户端发送变更通知。
2.对在zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么该临时节点也会被自动删除。
利用这两大特性,可以实现集群机器存活监控系统,若监控系统在/clusterServers节点上注册一个watcher监听,那么凡是进行动态添加机器的操作,就会在/clusterServers节点下创建一个临时节点:/clusterServers/[Hostname],这样,监控系统就能够实时监测机器的变动情况。
zookeeper可以用于分布式日志收集系统。
分布式日志收集系统的主要工作:收集分布在不同机器上的系统日志。
日志源机器:产生日志、需要被收集日志的机器。
收集器机器:用于收集日志的机器。
通常,一个收集器机器,对应一组(多个)日志源机器。
对于大规模的分布式日志收集系统场景,通常需要解决两个问题:
1.变化的日志源机器
2.变化的收集器机器
这两个问题可以归结为如何快速、合理、动态地为每个收集器分配对应的日志源机器。
使用zookeeper实现分布式日志收集系统:
1.注册收集器机器(给每个收集器机器创建对应的节点)
2.任务分发(将日志源机器列表分别写到收集器机器节点上去)
3.状态汇报(收集器机器在自己的节点下创建一个子节点,定时把自己的状态记录到子节点上,可以用来判断该收集器机器是否存活)
4.动态分配(如果收集器机器挂掉或扩容,则需要调整,重新分配日志源机器;可以使用全局动态分配或局部动态分配)
全局动态分配:对所有日志源机器重新分组,重新分给收集器机器。
局部动态分配:将部分日志源机器分配给负载小的收集器机器。
注意事项:
1.需要选择持久节点来标识收集器机器,增加子节点用来记录收集器状态。(如果使用临时节点标识收集器机器,当收集器机器挂掉后,记录在节点上的日志源机器列表也会被清除)
2.如果采用watcher机制,那么通知的消息量的网络开销非常大;需要采用日志系统主动轮询收集器节点的策略,这样可以节省网络流量,但是存在一定的延时。
--------------------------
Master选举
在分布式系统中,master用来协调集群中其它系统单元,具有对分布式系统状态变更的决定权。例如,在一些读写分离场景中,客户端的写请求往往是由Master来处理的;而另一些场景中,master则常常负责处理一些复杂的逻辑,并将结果同步给集群中其它系统单元。
----------------------------------
zookeeper可以实现分布式锁。
分布式锁是控制分布式系统之间通过访问共享资源的一种方式。
排他锁:又称为写锁或独占锁。
zookeeper可以实现排他锁。
共享锁,又称为读锁,如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其它事务也只能对这个数据对象加共享锁————直到该数据对象上的所有共享锁都被释放。
zookeeper可以实现读锁。
zookeeper实现读写锁整体流程(通过临时节点实现):
1.获取锁,创建"/shared_lock"临时节点,创建"/shared_lock/host1-请求类型-序号"节点。
例如,读锁是"/shared_lock/host1-read-001",写锁是"/shared_lock/host1-write-001"
2.客户端收到读请求或写请求,获取"/shared_lock"的子节点列表
3.如果是写请求,判断自己是否是序号最小的,如果是,占用锁,完成写操作,之后释放锁。
4.如果是写请求,判断自己是否是序号最小的,如果不是,就对比自己小的序号节点注册watcher监听;满足条件后(比自己序号小的节点都不存在后),就能够获取并占用锁,完成写操作,之后释放锁。
5.如果是读请求,判断,如果没有比自己序号小的子节点、或者所有比自己序号小的子节点都是读请求,就能够获取并占用锁,完成读操作,之后释放锁。
6.如果是读请求,判断无法获得锁,就对比自己小的节点注册watcher,直到满足条件后,占用锁,完成读操作,之后释放锁。
总结:获取子节点列表,子节点列表名称包含当前操作,或读或写,有序号;
写操作需要自己是序号最小的时才能获取锁,完成写操作,释放锁;如果不满足条件,就对比自己小的节点注册watcher监听,直到满足条件。
读操作需要自己是序号最小的或者比自己序号小的子节点都是读操作时才能获取锁,完成读操作,释放锁;如果不满足条件,也是通过watcher机制监听,直到满足条件。
--------------------------------
zookeeper可以实现分布式队列。
1.FIFO先入先出
(1)zookeeper创建/queue_fifo节点及有序子节点。
(2)获取该子节点列表,确定自己的节点序号在所有子节点的顺序。
(3)如果自己的序号不是最小,那就需要等待,同时向比自己序号小的最后一个节点注册watcher监听。
(4)接收到watcher通知后,重复步骤2.
2.Barrier:分布式屏障
含义:一个队列中的元素必须都集聚后才能统一进行安排,否则一直等待。
这些往往出现在大规模分布式并行计算的应用场景上:最终的合并计算需要基于很多并行计算的子结果来进行。
zookeeper大致实现思想如下:
1.开始时,zookeeper先创建一个/queue_barrier节点,然后将这个节点的数据内容赋值为一个数字n代表barrier的值,例如当n=10表示只有当/queue_barrier的子节点个数达到10时,才打开barrier。
2.通过调用getData接口获取/queue_barrier节点的数据内容:10.
3.获取子节点,同时注册对子节点变更的watcher监听。
4.如果子节点个数不到10个,就继续等待;直到到达10个。
--------------------------------------
zookeeper实现算法:
zookeeper没有完全采用paxos算法,而是使用了ZAB协议作为其数据一致性的核心算法。
ZAB协议:Zookeeper Atomic Broadcast,zookeeper原子消息广播协议。
ZAB协议的核心是定义了对于那些会改变Zookeeper服务器数据状态的事务请求的处理方式。
ZAB协议包含两种基本的模式:崩溃恢复和消息广播。
相关文章:
Java进阶:Zookeeper相关笔记
概要总结: ●Zookeeper是一个开源的分布式协调服务,需要下载并部署在服务器上(使用cmd启动,windows与linux都可用)。 ●zookeeper一般用来实现诸如数据订阅/发布、负载均衡、命名服务、集群管理、分布式锁和分布式队列等功能。 ●有多台服…...

QT-绘画事件
实现颜色的随时调整,追加橡皮擦功能 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QColor> #include <QPoint> #include <QVector> #include <QMouseEvent> #include <QPainter> #include <Q…...

鸿蒙NEXT开发-端云一体化开发
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下 如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识 目录 端云一体化开发基本概念 传统架构 端云一…...

大模型——股票分析AI工具开发教程
大模型——股票分析AI工具开发教程 在本教程中,我们将利用Google Gemini 2.0 Flash模型创建一个简单但有效的股票分析器。 你是否曾被大量的股票市场数据所淹没?希望有一个私人助理来筛选噪音并为您提供清晰、可操作的见解?好吧,你可以自己构建一个,而且由于 Python 的强…...

nexus 实现https 私有镜像搭建
1、安装nexus 1.1 安装JDK17 rpm -ivh jdk-17.0.13_linux-x64_bin.rpm 1.2 下载安装包解压到指定目录 tar zxvf nexus-3.77.2-02-unix.tar.gz -C /usr/local 2、运行nexus 默认8081端口 cd /usr/local/nexus-3.77.2-02 && bin/nexus start 3、配置nexus私有docker 镜…...

颈椎X光数据集(cervical spine X-ray dataset)
颈椎X光数据集(cervical spine X-ray dataset) 一.颈椎X光(1248张原始图像,无处理,jpg格式) 二.颈椎X光(1000张原始图像,无处理,jpg格式) 此数据…...

(动态规划 完全背包 零钱兑换)leetcode 322
本题为完全背包 与01背包的区别是 物品可以任意取 而01背包只能取一次 这就导致了状态转移方程的不同 1.当放不下:的时候 转移方程是一样的 取0到i-1 物品,背包容量为j的最优值 else 2.放得下:就是取 0到i-1 物品,背包容量为j的最优值和 “0到i的[j-w[i]]v…...

【AI大模型】DeepSeek + Kimi 高效制作PPT实战详解
目录 一、前言 二、传统 PPT 制作问题 2.1 传统方式制作 PPT 2.2 AI 大模型辅助制作 PPT 2.3 适用场景对比分析 2.4 最佳实践与推荐 三、DeepSeek Kimi 高效制作PPT操作实践 3.1 Kimi 简介 3.2 DeepSeek Kimi 制作PPT优势 3.2.1 DeepSeek 优势 3.2.2 Kimi 制作PPT优…...

Pytorch的一小步,昇腾芯片的一大步
Pytorch的一小步,昇腾芯片的一大步 相信在AI圈的人多多少少都看到了最近的信息:PyTorch最新2.1版本宣布支持华为昇腾芯片! 1、 发生了什么事儿? 在2023年10月4日PyTorch 2.1版本的发布博客上,PyTorch介绍的beta版本…...
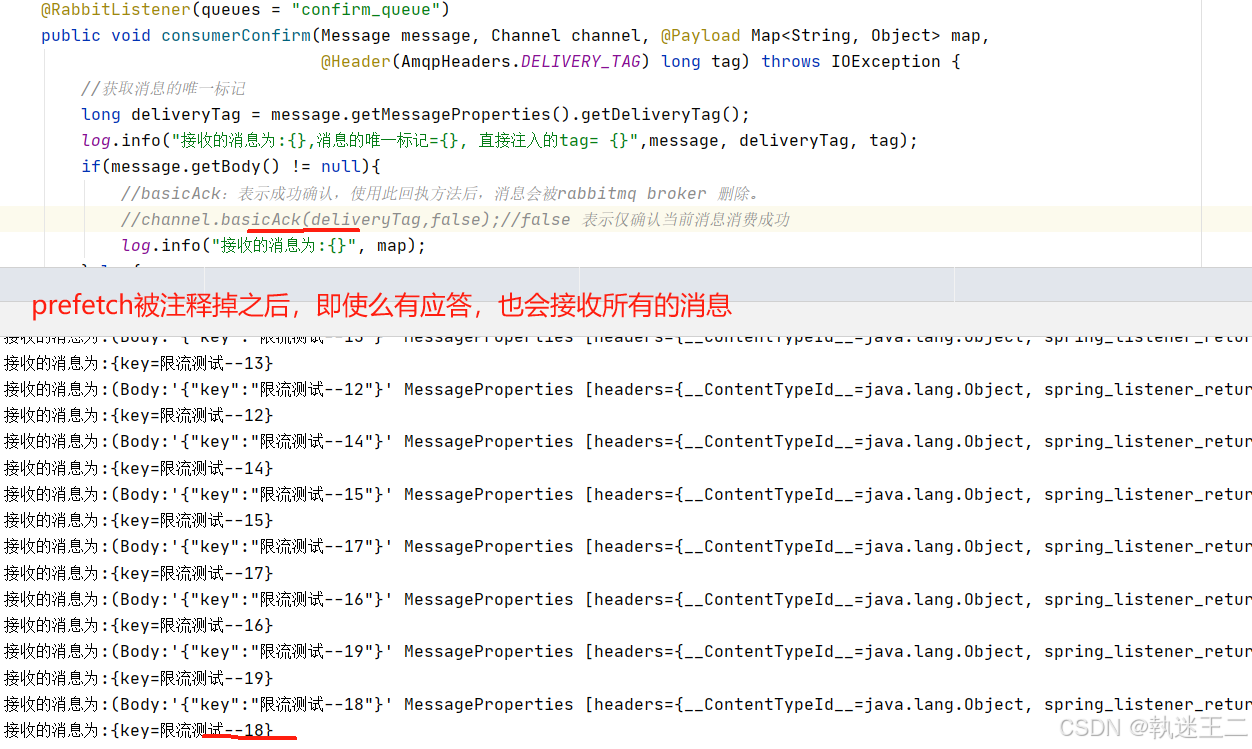
rabbitmq-amqp事务消息+消费失败重试机制+prefetch限流
1. 安装和配置 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency><dependency> <groupId>com.fasterxml.jackson.core</groupId> <arti…...

【HarmonyOS Next】自定义Tabs
背景 项目中Tabs的使用可以说是特别的频繁,但是官方提供的Tabs使用起来,存在tab选项卡切换动画滞后的问题。 原始动画无法满足产品的UI需求,因此,这篇文章将实现下面页面滑动,tab选项卡实时滑动的动画效果。 实现逻…...

Sass 模块化革命:深入解析 @use 语法,打造高效 CSS 架构
文章目录 前言use 用法1. 模块化与命名空间2. use 中 as 语法的使用3. as * 语法的使用4. 私有成员的访问5. use 中with默认值6. use 导入问题总结下一篇预告: 前言 在上一篇中,我们深入探讨了 Sass 中 import 语法的局限性,正是因为这些问题…...
)
【渗透测试】反弹 Shell 技术详解(一)
反弹 Shell 技术详解 一、前置知识 反弹 shell(Reverse Shell)是一种技术,攻击者利用它可以在远程主机上获得一个交互式的命令行接口。通常情况下,反弹 shell 会将标准输入(stdin)、标准输出(…...

python:pymunk + pygame 模拟六边形中小球弹跳运动
向 chat.deepseek.com 提问:编写 python 程序,用 pymunk, 有一个正六边形,围绕中心点缓慢旋转,六边形内有一个小球,六边形的6条边作为墙壁,小球受重力和摩擦力、弹力影响,模拟小球弹跳运动&…...
)
Windows 图形显示驱动开发-WDDM 3.2-本机 GPU 围栏对象(二)
GPU 和 CPU 之间的同步 CPU 必须执行 MonitoredValue 的更新,并读取 CurrentValue,以确保不会丢失正在进行的信号中断通知。 当向系统中添加新的 CPU 等待程序时,或者如果现有的 CPU 等待程序失效时,OS 必须修改受监视的值。OS …...
》在c#中的应用及理解)
23种设计模式之《模板方法模式(Template Method)》在c#中的应用及理解
程序设计中的主要设计模式通常分为三大类,共23种: 1. 创建型模式(Creational Patterns) 单例模式(Singleton):确保一个类只有一个实例,并提供全局访问点。 工厂方法模式࿰…...

DEV-C++ 为什么不能调试?(正确解决方案)
为了备战pat考试,专门下载了DEV C,然后懵圈的发现,怎么无法调试(╯□)╯︵ ┻━┻ 然后整了半天,终于在网上找到相应的解决方案!!!-> Dev C 5.11 调试初始设置 <- 一共四步…...
)
【C++设计模式】第五篇:原型模式(Prototype)
注意:复现代码时,确保 VS2022 使用 C17/20 标准以支持现代特性。 克隆对象的效率革命 1. 模式定义与用途 核心思想 原型模式:通过复制现有对象(原型)来创建新对象,而非通过new构造。关键用…...

深入 Vue.js 组件开发:从基础到实践
深入 Vue.js 组件开发:从基础到实践 Vue.js 作为一款卓越的前端框架,其组件化开发模式为构建高效、可维护的用户界面提供了强大支持。在这篇博客中,我们将深入探讨 Vue.js 组件开发的各个方面,从基础概念到高级技巧,助…...

maven导入spring框架
在eclipse导入maven项目, 在pom.xml文件中加入以下内容 junit junit 3.8.1 test org.springframework spring-core ${org.springframework.version} org.springframework spring-beans ${org.springframework.version} org.springframework spring-context ${org.s…...

linux service和systemctl命令、systemd
文章目录service命令(老版本)systemctl命令(推荐)systemdsystemd示例-Hello Worldsystemd语法如何查看service对应的脚本service命令(老版本) 都是服务控制相关的命令,差别不大,之前用service,现在一般用systemctl。 service命令例子&#…...

【免费下载】 探索三维世界的利器:Qt+OpenGL三维地形显示项目
探索三维世界的利器:QtOpenGL三维地形显示项目 项目介绍 在数字化的时代,三维地形显示技术已经成为地理信息系统(GIS)、游戏开发、虚拟现实等领域不可或缺的一部分。QtOpenGL三维地形显示项目 是一个开源的、跨平台的三维地形显示…...

SAP EWM实战:从产品到处理单位,两种库存转移操作保姆级教程
SAP EWM库存转移实战指南:产品与处理单位的精准操作 在仓库管理的日常工作中,库存转移是最基础却最容易出错的环节之一。特别是对于刚接触SAP EWM系统的管理员来说,面对不同形态的物料——散件产品和带包装的处理单位(HU),往往会产…...
)
告别“人工智障”:用LangChain和GPT-4打造你的第一个AI智能体(附保姆级代码)
从零构建智能体:LangChain与GPT-4实战指南 在咖啡厅角落,一位开发者正对着屏幕皱眉——她刚读完一篇关于AI代理的学术论文,满篇理论却找不到一行可执行的代码。这场景你是否熟悉?本文将用完全不同的方式,带你用LangCha…...

LLaMA论文里没细说的三个“小”改进:RMSNorm、SwiGLU和RoPE到底强在哪?
LLaMA模型三大底层优化技术解析:RMSNorm、SwiGLU与RoPE的设计哲学 当大多数人关注大语言模型的参数量级时,LLaMA团队却在微观架构层面做了一系列精妙改进。这些看似微小的技术选择,实则是支撑模型高效运行的关键支柱。本文将带您深入LLaMA的&…...

JiYuTrainer高效实用指南:3步解锁极域电子教室控制,恢复电脑操作自由
JiYuTrainer高效实用指南:3步解锁极域电子教室控制,恢复电脑操作自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为课堂上被老师全屏控制电脑而烦…...

Utools插件分离功能详解:像浏览器开标签页一样,同时运行多个效率工具
Utools插件分离功能实战:打造多窗口并行工作流的高效引擎 在数字工作时代,效率工具的价值早已超越了单一功能的实现,而在于如何无缝融入复杂的工作场景。对于开发者、内容创作者和知识工作者而言,真正的痛点往往不在于缺少工具&am…...

Vue3代码编辑器终极指南:5分钟学会vue-codemirror专业集成
Vue3代码编辑器终极指南:5分钟学会vue-codemirror专业集成 【免费下载链接】vue-codemirror codemirror code editor component for vuejs 项目地址: https://gitcode.com/gh_mirrors/vu/vue-codemirror 你是否曾经在Vue3项目中苦苦寻找一个既专业又易用的代…...

Nodejs后端服务接入Taotoken实现AI功能的具体配置步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务接入 Taotoken 实现 AI 功能的具体配置步骤 对于 Node.js 开发者而言,将大模型能力集成到后端服务中&…...

用LoRA微调LLaMA2时,你的显存和参数到底省在哪了?一个公式讲明白
LoRA微调LLaMA2的显存优化原理与工程实践指南 当开发者尝试在消费级显卡上微调大语言模型时,显存限制往往成为首要障碍。以LLaMA2-7B为例,全量微调需要约120GB显存,远超RTX 3090等主流显卡的24GB容量。低秩适配(LoRA)技…...