尚硅谷爬虫note14
一、scrapy
scrapy:为爬取网站数据是,提取结构性数据而编写的应用框架
1. 安装
pip install scrapy
或者,国内源安装
pip install scrapy -i https://pypi.douban.com/simple
2. 报错
报错1)building ‘twisted.test.raiser’ extension
原因:缺少twisted库
解决:下载twisted库:
a)cp是python版本
b)amd是操作系统版本
安装twisted库:
使用:pip install 拖入twisted路径
twisted库安装完成后,再安装scrapy库
报错2)提示python -m pip install --upgrade pid
解决:运行python -m pip install --upgrade pid
报错3)win32错误
解决:pip install pypiwin32
仍然报错)
解决:安装Aanacoda工具
二、创建scrapy项目
1)创建scrapy项目
在终端中创建项目:
scrapy startproject 项目名
![]()
2)创建爬虫文件
在spiders文件夹中创建爬虫文件
a)切入spiders目录下:
cd 项目名\项目名\spiders
![]()
b) 在spiders文件夹中创建爬虫文件
scrapy genspider 文件名 要爬取的网页

一般情况下,要爬取的网页之前:不需要添加http协议
否则start-urls中的路径不成立

原因:start_urls的值是根据allowed_domains进行修改的,如果添加了http协议,allowed_domains的值需要用户手动修改
import scrapyclass Demo001Spider(scrapy.Spider):# 爬虫的名字:用于运行爬虫时,使用的值name = "demo001"# 允许访问的域名allowed_domains = ["www.baidu.com"]# 起始url地址:指的是第一次要访问的域名# start_urls是在allowed_domains之前添加1个http:// 在allowed_domains之后添加1个/start_urls = ["http://www.baidu.com"]
#执行了 start_urls之后执行的方法 方法中的response就是返回的对象 相当于1)response = urllib.requests.urlopen() 2)response = requests.get()def parse(self, response):pass
3)运行爬虫文件
scrapy crawl 爬虫的名字
![]()
做了反扒————
解决:注释掉君子协议:项目下的setting.py文件中的robots.txt协议
注释掉:ROBOTSTXT_OBEY = True

三、scrapy项目结构
项目名
项目名
spider文件夹 (存储爬虫文件)
init
自定义的爬虫文件 (核心功能文件)
init
items (定义数据结构的地方)(爬取的数据包含哪些)
middleware (中间件)(代理)
pipelines (管道)(处理下载的数据)
settings (配置文件)
四、response的属性和方法
3)4)5)常用
1)response.text
获取响应的字符串
2)response.body
获取响应的二进制数据
3)response.xpath
直接使用xpath方法解析response中的内容
4)response.extract()
提取selector对象中的data属性值
5)response.extract_first()
提取selector对象的第一个数据
五、scrapy工作原理
1). 引擎向spiders要url
2). 引擎将要爬取的url给调度器
3). 调度器将url生成请求对象,放入指定的队列
4). 从队列中出队一个请求
5). 引擎将请求交给下载器进行处理
6).下载器发送请求,向互联网请求数据
7). 下载器将数据返回给引擎
8). 引擎将数据再次给到spiders
9).spiders通过xpath解析数据
10). spiders将数据,或者url,给到引擎
11). 引擎判断该数据,是数据,还是url
a)是数据,交给管道处理
b)还是url,交给调度器处理

六、scrapy shell
scrapy终端
测试xpath和css表达式
免去了每次修改后,运行spiders的麻烦
使用:
终端中直接执行:
scrapy shell 域名
安装ipython(高亮,补全)
pip install ipython
七、懒加载中的src
有data-original,src用data-original替代
替换前:src = // ul[ @ id = "component_59"] / li // img / @ src
替换后:src = // ul[ @ id = "component_59"] / li // img / @ data-original
当当网练习中的第一张图片是none
原因:没有data-original
#有data-original,src用data-original替代src = li.xpath('.//img/@data-original').extract_first()# 第一张图片和其他图片标签不一样,第一张图片的src是可以使用的 其他图片的地址是data-originalif src:src = srcelse:#用srcsrc = li.xpath('.//img/@src').extract_first()当当网:
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
from urllib import responseimport scrapyclass DemoDdwItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# pass#图片# src = // ul[ @ id = "component_59"] / li // img / @ srcsrc = scrapy.Field()#名字# alt = // ul[ @ id = "component_59"] / li // img / @ altname = scrapy.Field()#价格# price = //ul[@id = "component_59"]/li//p[@class = "price"]/span[1]/text()price = scrapy.Field()# src、name、price都有共同的li标签# 所有的selector对象,都可以再次调用xpath方法li_list = response.xpath('//ul[@id = "component_59"]/li')for li in li_list:#.extract()提取数据#有data-original,src用data-original替代src = li.xpath('.//img/@data-original').extract_first()# 第一张图片和其他图片标签不一样,第一张图片的src是可以使用的 其他图片的地址是data-originalif src:src = srcelse:#用srcsrc = li.xpath('.//img/@src').extract_first()alt = li.xpath('.//img/@alt').extract_first()price = li1.xpath('.//p[@class = "price"]/span[1]/text()').extract_first()print(src,name,price)
相关文章:
尚硅谷爬虫note14
一、scrapy scrapy:为爬取网站数据是,提取结构性数据而编写的应用框架 1. 安装 pip install scrapy 或者,国内源安装 pip install scrapy -i https://pypi.douban.com/simple 2. 报错 报错1)building ‘twisted.te…...

1438. 绝对差不超过限制的最长连续子数组
目录 一、题目二、思路2.1 解题思路2.2 代码尝试2.3 疑难问题2.4 代码复盘 三、解法四、收获4.1 心得4.2 举一反三 一、题目 二、思路 2.1 解题思路 滑动窗口 2.2 代码尝试 class Solution { public:int longestSubarray(vector<int>& nums, int limit) {int cou…...

ZCC5090EA适用于TYPE-C接口,集成30V OVP功能, 最大1.5A充电电流,带NTC及使能功能,双节锂电升压充电芯片替代CS5090EA
概要: ZCC5090EA是一款5V输入,最大1.5A充电电流,支 持双 节 锂 电 池 串 联 应 用 的 升 压 充 电 管 理 I C 。ZCC5090EA集成功率MOS,采用异步开关架构, 使其在应用时仅需极少的外围器件,可有效减少整体 …...
)
Dify 开源大语言模型应用开发平台使用(二)
文章目录 说明Dify 使用报告1. 应用创建——专业的锂电池相关知识解答1.1 平台简介1.2 创建应用 2. 知识库、工作流、变量、节点与编排节点详解2.1 知识库管理2.2 工作流配置2.3 变量管理2.4 节点与编排节点 3. 测试和调试3.1 单元测试3.2 日志与监控3.3 实时调试3.4 性能测试 …...
【LangFuse】数据集与测试
1. 在线标注 2. 上传已有数据集 import json# 调整数据格式 {"input":{...},"expected_output":"label"} data [] with open(my_annotations.jsonl, r, encodingutf-8) as fp:for line in fp:example json.loads(line.strip())item {"i…...

【Python】如何解决Jupyter Notebook修改外部模块后必须重启内核的问题?
“为什么我修改了Python模块的代码,Jupyter Notebook却看不到变化?” 一、问题现象:令人抓狂的开发体验 假设你正在开发一个图像处理项目,项目结构如下: project/ ├── utils/ │ └── image_processor.py └…...

Redis 篇
一、数据结构 二、持久化方式 Redis 提供了两种主要的持久化方式,分别是 RDB(Redis Database)和 AOF(Append Only File),此外,还可以同时使用这两种方式以增强数据安全性,以下为你…...

React + TypeScript 实战指南:用类型守护你的组件
TypeScript 为 React 开发带来了强大的类型安全保障,这里解析常见的一些TS写法: 一、组件基础类型 1. 函数组件定义 // 显式声明 Props 类型并标注返回值 interface WelcomeProps {name: string;age?: number; // 可选属性 }const Welcome: React.FC…...

从零开始:Linux环境下如何制作静态库与动态库
个人主页:chian-ocean 文章专栏-Linux 前言 动静态库是编程中两种主要的库类型,它们用于帮助开发者复用已有的代码,而不需要每次都从头开始编写。它们的主要区别在于链接和加载的时机、方式以及使用场景 库 库就是一些已经写好并且经过测试…...

【智能体Agent】ReAct智能体的实现思路和关键技术
基于ReAct(Reasoning Acting)框架的自主智能体 import re from typing import List, Tuplefrom langchain_community.chat_message_histories.in_memory import ChatMessageHistory from langchain_core.language_models.chat_models import BaseChatM…...

Java进阶:Zookeeper相关笔记
概要总结: ●Zookeeper是一个开源的分布式协调服务,需要下载并部署在服务器上(使用cmd启动,windows与linux都可用)。 ●zookeeper一般用来实现诸如数据订阅/发布、负载均衡、命名服务、集群管理、分布式锁和分布式队列等功能。 ●有多台服…...

QT-绘画事件
实现颜色的随时调整,追加橡皮擦功能 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QColor> #include <QPoint> #include <QVector> #include <QMouseEvent> #include <QPainter> #include <Q…...

鸿蒙NEXT开发-端云一体化开发
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下 如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识 目录 端云一体化开发基本概念 传统架构 端云一…...

大模型——股票分析AI工具开发教程
大模型——股票分析AI工具开发教程 在本教程中,我们将利用Google Gemini 2.0 Flash模型创建一个简单但有效的股票分析器。 你是否曾被大量的股票市场数据所淹没?希望有一个私人助理来筛选噪音并为您提供清晰、可操作的见解?好吧,你可以自己构建一个,而且由于 Python 的强…...

nexus 实现https 私有镜像搭建
1、安装nexus 1.1 安装JDK17 rpm -ivh jdk-17.0.13_linux-x64_bin.rpm 1.2 下载安装包解压到指定目录 tar zxvf nexus-3.77.2-02-unix.tar.gz -C /usr/local 2、运行nexus 默认8081端口 cd /usr/local/nexus-3.77.2-02 && bin/nexus start 3、配置nexus私有docker 镜…...

颈椎X光数据集(cervical spine X-ray dataset)
颈椎X光数据集(cervical spine X-ray dataset) 一.颈椎X光(1248张原始图像,无处理,jpg格式) 二.颈椎X光(1000张原始图像,无处理,jpg格式) 此数据…...

(动态规划 完全背包 零钱兑换)leetcode 322
本题为完全背包 与01背包的区别是 物品可以任意取 而01背包只能取一次 这就导致了状态转移方程的不同 1.当放不下:的时候 转移方程是一样的 取0到i-1 物品,背包容量为j的最优值 else 2.放得下:就是取 0到i-1 物品,背包容量为j的最优值和 “0到i的[j-w[i]]v…...

【AI大模型】DeepSeek + Kimi 高效制作PPT实战详解
目录 一、前言 二、传统 PPT 制作问题 2.1 传统方式制作 PPT 2.2 AI 大模型辅助制作 PPT 2.3 适用场景对比分析 2.4 最佳实践与推荐 三、DeepSeek Kimi 高效制作PPT操作实践 3.1 Kimi 简介 3.2 DeepSeek Kimi 制作PPT优势 3.2.1 DeepSeek 优势 3.2.2 Kimi 制作PPT优…...

Pytorch的一小步,昇腾芯片的一大步
Pytorch的一小步,昇腾芯片的一大步 相信在AI圈的人多多少少都看到了最近的信息:PyTorch最新2.1版本宣布支持华为昇腾芯片! 1、 发生了什么事儿? 在2023年10月4日PyTorch 2.1版本的发布博客上,PyTorch介绍的beta版本…...
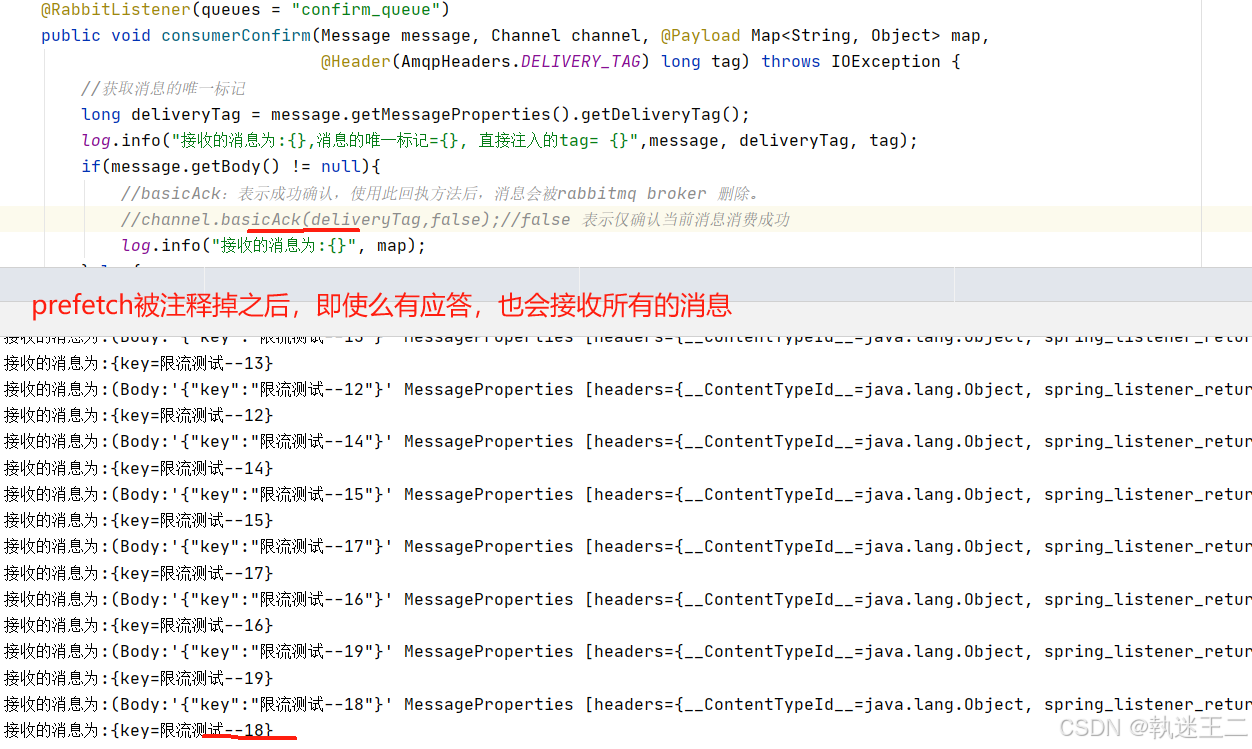
rabbitmq-amqp事务消息+消费失败重试机制+prefetch限流
1. 安装和配置 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency><dependency> <groupId>com.fasterxml.jackson.core</groupId> <arti…...

通过Taotoken审计日志功能追踪与分析API调用情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志功能追踪与分析API调用情况 对于使用大模型API进行开发的项目团队而言,清晰、透明地掌握API调用情…...

【亲测免费】 Zynq平台网络芯片RTL8211FD配置资源推荐
Zynq平台网络芯片RTL8211FD配置资源推荐 【下载地址】Zynq使用网络芯片RTL8211FD资源文件 本仓库提供了一个用于Zynq平台使用网络芯片RTL8211FD的资源文件。由于Xilinx的源代码默认不支持RTL8211FD,本资源文件中的程序可以替代Xilinx的默认配置,使得Zynq…...

GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析
GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 在游…...

为什么选择nxdumptool:Switch游戏备份的完全指南
为什么选择nxdumptool:Switch游戏备份的完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxdum…...
的3D视觉原理与应用)
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头(如Intel Realsense)的3D视觉原理与应用
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头的3D视觉原理与应用 当你第一次看到RGB-D摄像头生成的彩色点云在屏幕上旋转时,那种将现实世界数字化的震撼感令人难忘。但真正让这种设备发挥价值的,是理解它如何将光信号转化为三维坐标的完整技术…...

告别假进度条!UE5蓝图实战:用自定义AssetManager实现真实关卡加载进度
UE5蓝图实战:打造真实关卡加载进度系统 在虚幻引擎5(UE5)游戏开发中,流畅的关卡加载体验对玩家沉浸感至关重要。许多开发者会遇到"假进度条"问题——进度条看似在动,实则与真实加载进度无关。本文将手把手教…...

SharpCompress实战:一个方法搞定C#里ZIP压缩打包,附赠RAR/7Z解压和TAR.GZ创建教程
C#压缩解压全能手册:用SharpCompress玩转ZIP/RAR/7Z/TAR.GZ 在开发日志管理系统、文件上传模块或数据备份工具时,文件压缩解压功能就像空气一样不可或缺。但面对ZIP、RAR、7Z、TAR.GZ这些格式各异的压缩包,不少开发者都会陷入API选择的困境。…...

三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密
三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为找不到三星官方固件而烦恼吗&am…...
)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解+方程双解法)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解方程双解法) 在电子工程实践中,工程师们常常会遇到一种令人头疼的"黑盒子"——那些内部结构不明、数据手册不全的电路模块。面对这样的未知网络ÿ…...

终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效
终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...