【自学笔记】Hadoop基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Hadoop基础知识点总览
- 1. Hadoop简介
- 2. Hadoop生态系统
- 3. HDFS(Hadoop Distributed File System)
- HDFS基本命令
- 4. MapReduce
- WordCount示例(Java)
- 5. YARN(Yet Another Resource Negotiator)
- 6. 其他组件简介
- 总结
Hadoop基础知识点总览
1. Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它能利用集群的威力进行高速运算和存储。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
2. Hadoop生态系统
Hadoop生态系统包含了多个组件,其中最重要的是HDFS(Hadoop Distributed File System)和MapReduce。其他重要的组件还包括YARN(Yet Another Resource Negotiator)、Hive、HBase、Zookeeper、Sqoop、Flume等。
3. HDFS(Hadoop Distributed File System)
HDFS是Hadoop的分布式文件系统,具有高容错性的特点,并且设计用来部署在低廉的硬件上。它提供高吞吐量的数据访问,适合那些有着超大数据集的应用程序。
HDFS基本命令
以下是一些HDFS的基本命令示例:
# 启动HDFS
start-dfs.sh# 查看HDFS上的文件列表
hdfs dfs -ls /# 在HDFS上创建一个目录
hdfs dfs -mkdir /user/hadoop/data# 将本地文件上传到HDFS
hdfs dfs -put localfile.txt /user/hadoop/data/# 从HDFS下载文件到本地
hdfs dfs -get /user/hadoop/data/localfile.txt ./# 删除HDFS上的文件
hdfs dfs -rm /user/hadoop/data/localfile.txt
4. MapReduce
MapReduce是一种编程模型和处理大量数据的框架。它基于一个“Map(映射)”函数,用来把一组键值对映射成另一组键值对,以及一个“Reduce(归约)”函数,用来保证所有映射的键值对中的每一个中间键值对都恰好被归约一次。
WordCount示例(Java)
以下是一个简单的WordCount程序的Map和Reduce函数示例:
// Mapper类
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {private final static LongWritable one = new LongWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split("\\s+");for (String str : words) {word.set(str);context.write(word, one);}}
}// Reducer类
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {long sum = 0;for (LongWritable val : values) {sum += val.get();}context.write(key, new LongWritable(sum));}
}// 主类
public class WordCount {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(WordCountMapper.class);job.setCombinerClass(WordCountReducer.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
5. YARN(Yet Another Resource Negotiator)
YARN是Hadoop的资源管理器,负责为应用程序分配系统资源。它将资源管理功能和应用程序调度/监控功能分开,使得Hadoop能够运行更多种类的应用程序。
6. 其他组件简介
- Hive:一个数据仓库软件,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
- HBase:一个分布式的、可扩展的大数据存储系统,支持对大数据的随机、实时读写访问。
- Zookeeper:一个为分布式应用提供一致性服务的开源项目,它主要是用来解决分布式环境中数据一致性的问题。
希望这个示例对你有所帮助!你可以根据自己的需要添加更多的内容或代码块。如果你有任何其他问题或需要进一步的帮助,请随时提问。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,自学记录Hadoop基础知识点总览。
相关文章:

【自学笔记】Hadoop基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Hadoop基础知识点总览1. Hadoop简介2. Hadoop生态系统3. HDFS(Hadoop Distributed File System)HDFS基本命令 4. MapReduceWordCount示例&am…...

【Linux】使用问题汇总
#1 ssh连接的时候报Key exchange failed 原因:服务端版本高,抛弃了一些不安全的交换密钥算法,且客户端版本比较旧,不支持安全性较高的密钥交换算法。 解决方案: 如果是内网应用,安全要求不这么高…...

(二 十 二)趣学设计模式 之 备忘录模式!
目录 一、 啥是备忘录模式?二、 为什么要用备忘录模式?三、 备忘录模式的实现方式四、 备忘录模式的优缺点五、 备忘录模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,…...

交叉编译openssl及curl
操作环境:Ubuntu20.04 IDE工具:Clion2020.2 curl下载地址:https://curl.se/download/ openssl下载地址:https://openssl-library.org/source/old/index.html 直接交叉编译curl会报错找不到openssl,所以需要先交叉编…...
:IP)
【每日八股】计算机网络篇(三):IP
目录 DNS 查询服务器的基本流程DNS 采用 TCP 还是 UDP,为什么?默认使用 UDP 的原因需要使用 TCP 的场景?总结 DNS 劫持是什么?解决办法?浏览器输入一个 URL 到显示器显示的过程?URL 解析TCP 连接HTTP 请求页…...

Gartner:数据安全平台DSP提升数据流转及使用安全
2025 年 1 月 7 日,Gartner 发布“China Context:Market Guide for Data Security Platforms”(《数据安全平台市场指南——中国篇》,以下简称指南),报告主要聚焦中国数据安全平台(Data Securit…...

从vue源码解析Vue.set()和this.$set()
前言 最近死磕了一段时间vue源码,想想觉得还是要输出点东西,我们先来从Vue提供的Vue.set()和this.$set()这两个api看看它内部是怎么实现的。 Vue.set()和this.$set()应用的场景 平时做项目的时候难免不会对 数组或者对象 进行这样的骚操作操作ÿ…...

深入浅出:UniApp 从入门到精通全指南
https://juejin.cn/post/7440119937644101684 uni-app官网 uniapp安卓离线打包流程_uniapp离线打包-CSDN博客 本文是关于 UniApp 从入门到精通的全指南,涵盖基础入门(环境搭建、创建项目、项目结构、编写运行)、核心概念与进阶知识&#x…...

DeepSeek未来发展趋势:开创智能时代的新风口
DeepSeek未来发展趋势:开创智能时代的新风口 随着人工智能(AI)、深度学习(DL)和大数据的飞速发展,众多创新型技术已经逐渐走向成熟,而DeepSeek作为这一领域的新兴力量,正逐步吸引越…...
阻塞队列的实现(线程案例)
一.什么是阻塞队列? 1.如果对于一个满的队列,还要把元素入队列,此时这个队列就会阻塞等待,一直阻塞到这个队列不满为止,从而把这个元素入队列! 2.如果对于一个空的队列,还要从队列拿出元素&…...

http status是什么?常见的http状态码指的是什么意思?
HTTP 状态码 HTTP 状态码(HTTP Status Code)是服务器在响应客户端请求时返回的一个三位数字代码,用于表示请求的处理结果。HTTP 状态码是 HTTP 协议的一部分,帮助客户端(如浏览器或应用程序)了解请求是否成…...
react组件分离,降低耦合
分离前 分离后...

【AI】AI白日梦+ChatGPT 三分钟生成爆款短视频
引言 随着人工智能(AI)技术的快速发展,AI在各个领域都展现出了强大的应用潜力。其中,自然语言处理技术的进步使得智能对话系统得以实现,而ChatGPT作为其中的代表之一,具有自动生成文本的能力,为…...
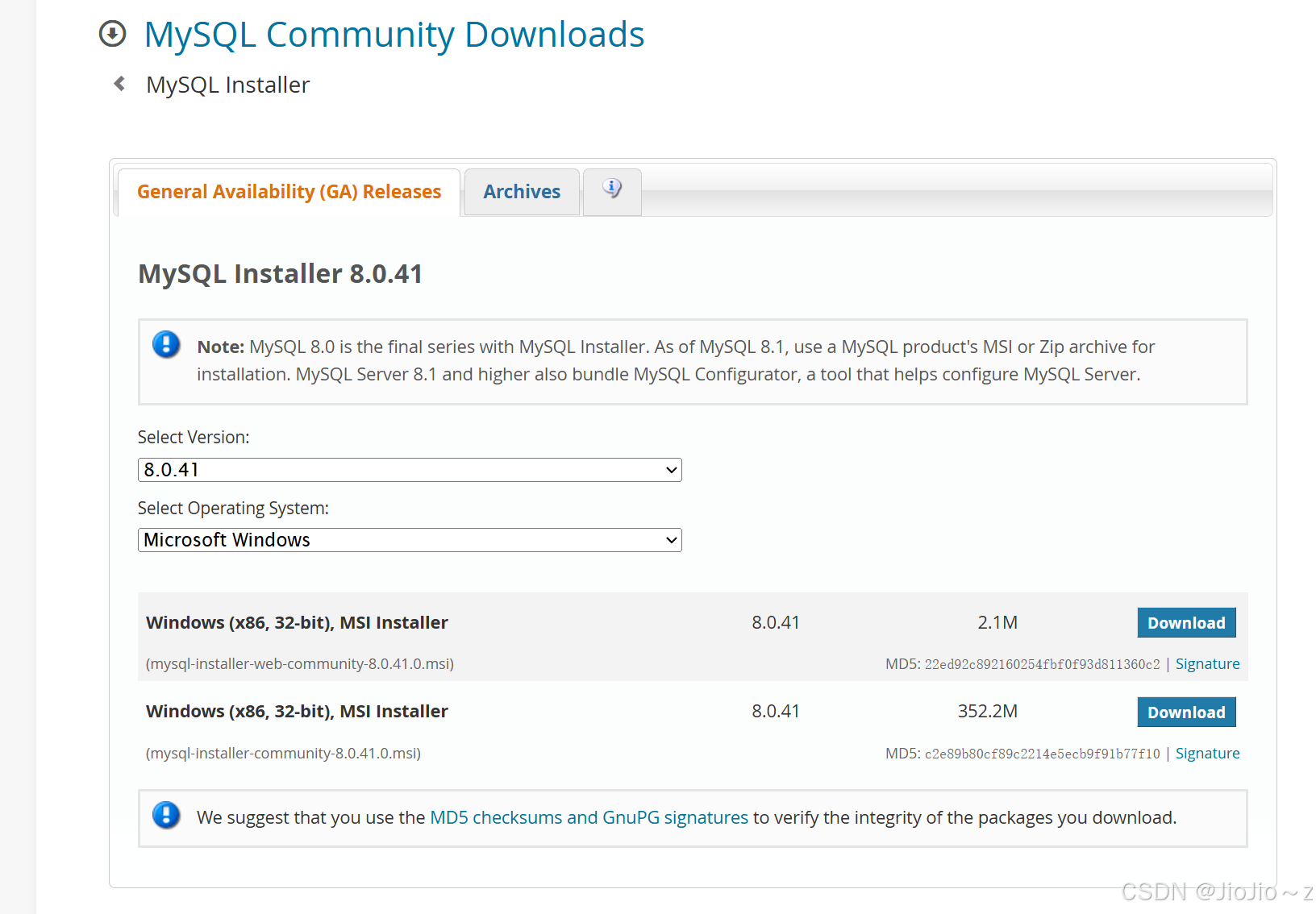
MYSQL的安装教程
mysql安装分为:普通安装和压缩包安装 压缩包安装很多会存在安装失败的情况,所以我这里就用了普通安装 一、官网下载安装包 www.mysql.com 点击DOWNLOADS: 进入社区版本下载: 点击最下面一行进行下载: 选择第二个离…...

深入解析 C# 中的泛型:概念、用法与最佳实践
C# 中的 泛型(Generics) 是一种强大的编程特性,允许开发者在不预先指定具体数据类型的情况下编写代码。通过泛型,C# 能够让我们编写更灵活、可重用、类型安全且性能优良的代码。泛型广泛应用于类、方法、接口、委托、集合等多个方…...

NUMA架构介绍
NUMA 架构详解 NUMA(Non-Uniform Memory Access,非统一内存访问) 是一种多处理器系统的内存设计架构,旨在解决多处理器系统中内存访问延迟不一致的问题。与传统的 UMA(Uniform Memory Access,统一内存访问…...

数据安全VS创作自由:ChatGPT与国产AI工具隐私管理对比——论文党程序员必看的避坑指南
文章目录 数据安全VS创作自由:ChatGPT与国产AI工具隐私管理对比——论文党程序员必看的避坑指南ChatGPTKimi腾讯元宝DeepSeek 数据安全VS创作自由:ChatGPT与国产AI工具隐私管理对比——论文党程序员必看的避坑指南 产品隐私设置操作路径隐私协议ChatGPT…...

python爬虫:python中使用多进程、多线程和协程对比和采集实践
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 1. 多进程爬虫1.1 python多进程样例1.2 实现多进程爬虫2. 多线程爬虫2.1 python多线程样例2.2 实现多线程爬虫3. 协程爬虫3.1 python协程样例3.2 实现协程爬虫在网络爬虫中,为了提高抓取效率,常常需要使用多进程、多线…...

《OpenCV》—— dlib库
文章目录 dlib库是什么?OpenCV库与dlib库对比dlib库安装dlib——人脸应用实例——人脸检测dlib——人脸应用实例——人脸关键点定位dlib——人脸应用实例——人脸轮廓绘制 dlib库是什么? OpenCV库与dlib库对比 dlib库安装 dlib——人脸应用实例——人脸检…...

Linux搜索---find
find搜索 find 命令的核心功能是在指定的目录路径下,递归地搜索文件和目录,并且可以根据多种条件对搜索结果进行筛选,还能对符合条件的文件和目录执行特定操作。 一、基础语法结构 find [起始目录] [匹配条件] [执行操作] # 基本示例 find…...

CAXA 中心线
位置命令属性自由(方式)1、触发命令;2、属性如下;3、点击对象;(例如这里点击圆弧)4、输入定位点,或移动鼠标;5、点击确定中心线大小;指定延长线长度ÿ…...

数学科研效率提升300%,NotebookLM辅助建模全流程解析,含独家提示词矩阵与误差校验协议
更多请点击: https://intelliparadigm.com 第一章:NotebookLM数学研究辅助的范式革命 传统数学研究长期依赖纸笔推演、孤立文献查阅与手工公式验证,而NotebookLM通过其独特的“语义锚点双文档协同推理”机制,重构了从问题建模到定…...

长期使用Taotoken Token Plan套餐的成本控制体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本控制体会 1. 从按需计费到套餐订阅的转变 在开始使用Taotoken平台时,我和团队…...

简单认识显卡
学习视频来自B站(从零开始认识显卡):https://www.bilibili.com/video/BV1xE421j7Uv 这是你最近在玩的电脑游戏,形态各异的建筑、细节丰富的车辆,一切都很真实,它们的本质其实是一个个不同位置的点ÿ…...

从 API 密钥管理角度看 Taotoken 控制台提供的安全与便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从 API 密钥管理角度看 Taotoken 控制台提供的安全与便捷性 1. 引言:集中管理的起点 在开发涉及大模型的应用时&#…...

C#上位机与三菱PLC通信实战:从零构建GX Works3仿真平台
1. 为什么需要搭建GX Works3仿真平台 第一次接触三菱PLC开发的朋友们,可能都有这样的困惑:手头没有实体PLC设备,怎么测试自己写的控制程序?买一台FX5U PLC动辄几千元,对个人开发者来说成本太高。这时候仿真平台就成了最…...

哔哩下载姬完整指南:三步快速掌握B站视频批量下载技巧
哔哩下载姬完整指南:三步快速掌握B站视频批量下载技巧 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...

RK3588 ARM开发板KVM虚拟机搭建与性能优化实战指南
1. 项目概述:为什么要在RK3588上折腾虚拟机?最近几年,国产芯片的势头越来越猛,尤其是在嵌入式和高性能计算领域。RK3588这颗芯片,作为瑞芯微的旗舰级SoC,凭借其8核CPU(4xA76 4xA55)…...

魔兽世界宏编辑器终极指南:5分钟掌握GSE高级宏编译工具
魔兽世界宏编辑器终极指南:5分钟掌握GSE高级宏编译工具 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compi…...

APK Installer终极指南:Windows平台Android应用部署完全手册
APK Installer终极指南:Windows平台Android应用部署完全手册 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用生态日益融合的今天,开…...