马尔科夫不等式和切比雪夫不等式
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
统计概率的利剑:掌握这两大不等式,让机器学习模型风险评估更有保障!

1️⃣ 马尔科夫不等式:概率上界的基石 🏗️
🔍 核心思想
对于非负随机变量 X ≥ 0 X \geq 0 X≥0,其取值超过某阈值 a ( a > 0 ) a\ (a > 0) a (a>0) 的概率上界可通过数学期望估计。马尔科夫不等式提供了一种分布无关的概率上界估计方法。
📝 数学形式
P ( X ≥ a ) ≤ E ( X ) a P(X \geq a) \leq \frac{E(X)}{a} P(X≥a)≤aE(X)
🧩 直观理解
想象一个班级的学生成绩(非负),平均分80分。有多少学生可能得到160分以上?马尔科夫告诉我们:最多50%,因为 80 160 = 0.5 \frac{80}{160} = 0.5 16080=0.5。
🔄 推导过程
由于 X ≥ 0 X \geq 0 X≥0,期望 E ( X ) = ∫ 0 ∞ x f ( x ) d x E(X) = \int_0^\infty x f(x) dx E(X)=∫0∞xf(x)dx。将积分拆分:
E ( X ) = ∫ 0 a x f ( x ) d x + ∫ a ∞ x f ( x ) d x ≥ ∫ a ∞ x f ( x ) d x ≥ a ∫ a ∞ f ( x ) d x = a ⋅ P ( X ≥ a ) E(X) = \int_0^a x f(x) dx + \int_a^\infty x f(x) dx \geq \int_a^\infty x f(x) dx \geq a \int_a^\infty f(x) dx = a \cdot P(X \geq a) E(X)=∫0axf(x)dx+∫a∞xf(x)dx≥∫a∞xf(x)dx≥a∫a∞f(x)dx=a⋅P(X≥a)
两边同除 a a a 即得不等式。
💡 机器学习应用
- 异常检测:估计特征值超过阈值的异常概率上界
- 过拟合风险评估:当损失函数视为随机变量时,评估超过某阈值的概率
- 资源分配预测:如预估GPU内存使用峰值概率
- 梯度下降收敛性:评估随机梯度下降中梯度爆炸的概率上界
📈 实例:模型训练资源规划
假设深度学习训练任务的内存需求 X X X 平均为8GB,估计内存需求超过16GB的概率上界:
P ( X ≥ 16 G B ) ≤ 8 G B 16 G B = 0.5 P(X \geq 16GB) \leq \frac{8GB}{16GB} = 0.5 P(X≥16GB)≤16GB8GB=0.5
因此,如果我们为服务器配置16GB内存,理论上至少50%的训练任务可以顺利完成。
2️⃣ 切比雪夫不等式:方差的力量 💪
🔍 核心思想
切比雪夫不等式利用方差量化随机变量偏离均值的程度,提供比马尔科夫更精确的概率界限,是机器学习中量化不确定性的强大工具。
📝 数学形式
P ( ∣ X − E ( X ) ∣ ≥ ϵ ) ≤ D ( X ) ϵ 2 P\left(|X - E(X)| \geq \epsilon\right) \leq \frac{D(X)}{\epsilon^2} P(∣X−E(X)∣≥ϵ)≤ϵ2D(X)
等价形式:
P ( ∣ X − E ( X ) ∣ < ϵ ) ≥ 1 − D ( X ) ϵ 2 P\left(|X - E(X)| < \epsilon\right) \geq 1 - \frac{D(X)}{\epsilon^2} P(∣X−E(X)∣<ϵ)≥1−ϵ2D(X)
🧩 直观理解
如果模型预测误差的方差为4,那么预测偏离真实值超过10个单位的概率不会超过 4 1 0 2 = 0.04 \frac{4}{10^2} = 0.04 1024=0.04,即4%。
🔄 推导过程
对随机变量 Y = ( X − μ ) 2 Y = (X - \mu)^2 Y=(X−μ)2 应用马尔科夫不等式。已知 E ( Y ) = D ( X ) E(Y) = D(X) E(Y)=D(X),则:
P ( Y ≥ ϵ 2 ) ≤ E ( Y ) ϵ 2 = D ( X ) ϵ 2 P(Y \geq \epsilon^2) \leq \frac{E(Y)}{\epsilon^2} = \frac{D(X)}{\epsilon^2} P(Y≥ϵ2)≤ϵ2E(Y)=ϵ2D(X)
注意到 ( X − μ ) 2 ≥ ϵ 2 ⇔ ∣ X − μ ∣ ≥ ϵ (X - \mu)^2 \geq \epsilon^2 \Leftrightarrow |X - \mu| \geq \epsilon (X−μ)2≥ϵ2⇔∣X−μ∣≥ϵ,即得原式。
💡 机器学习应用
- 模型预测置信区间:根据验证误差方差估计预测偏离的概率范围
- 特征重要性评估:评估特征值偏离均值的稳定性
- 模型鲁棒性分析:量化模型对输入扰动的敏感度
- 早停策略设计:基于验证损失偏离平均值的概率设计早停阈值
💻 实现示例
import numpy as np
import matplotlib.pyplot as plt# 生成随机数据
np.random.seed(42)
data = np.random.normal(100, 15, 1000) # 均值100,标准差15的正态分布# 计算实际值
mean = np.mean(data)
var = np.var(data)
epsilon = 30# 切比雪夫不等式计算
chebyshev_bound = var / (epsilon**2)
actual_prob = np.mean(np.abs(data - mean) >= epsilon)print(f"数据均值: {mean:.2f}")
print(f"数据方差: {var:.2f}")
print(f"切比雪夫界限: P(|X - μ| ≥ {epsilon}) ≤ {chebyshev_bound:.4f}")
print(f"实际概率: P(|X - μ| ≥ {epsilon}) = {actual_prob:.4f}")# 对比图
plt.figure(figsize=(10, 6))
plt.hist(data, bins=50, alpha=0.7, density=True, label='数据分布')
plt.axvline(mean, color='r', linestyle='--', label=f'均值: {mean:.2f}')
plt.axvline(mean + epsilon, color='g', linestyle='--', label=f'均值 + {epsilon}')
plt.axvline(mean - epsilon, color='g', linestyle='--', label=f'均值 - {epsilon}')
plt.title('切比雪夫不等式实例演示')
plt.legend()
plt.show()
📊 实例:推荐系统的准确性评估
某推荐系统的点击率预测模型在验证集上的预测误差方差为0.04。使用切比雪夫不等式,可估计预测偏离真实值超过0.3的概率上界:
P ( ∣ X − μ ∣ ≥ 0.3 ) ≤ 0.04 0. 3 2 ≈ 0.44 P(|X - \mu| \geq 0.3) \leq \frac{0.04}{0.3^2} \approx 0.44 P(∣X−μ∣≥0.3)≤0.320.04≈0.44
这提示我们模型的准确性还有提升空间,44%的预测可能有较大偏差。
3️⃣ 马尔科夫与切比雪夫不等式对比 🔍
| 对比项 | 马尔科夫不等式 | 切比雪夫不等式 |
|---|---|---|
| 适用条件 | X ≥ 0 X \geq 0 X≥0,仅需均值已知 | 需已知均值和方差 |
| 数学基础 | 通过期望拆分积分 | 基于变量 ( X − μ ) 2 (X - \mu)^2 (X−μ)2的马尔科夫扩展 |
| 估计特点 | 单边界( X ≥ a X \geq a X≥a) | 双侧界( ∣ X − μ ∣ ≥ ϵ \vert X - \mu \vert \geq \epsilon ∣X−μ∣≥ϵ) |
| 界限精度 | 较松散 | 更严格(利用方差信息) |
| ML中典型应用 | 梯度爆炸检测 资源使用预测 | 预测置信区间 模型收敛性分析 |
4️⃣ 机器学习中的实际应用 🤖
🔬 批量归一化(Batch Normalization)原理解释
切比雪夫不等式帮助解释为什么批量归一化能提高模型训练稳定性。通过标准化每层输出,使方差保持恒定,根据切比雪夫不等式,可以更好地控制激活值偏离均值的概率,减少梯度消失/爆炸问题。
🎯 SGD优化器学习率调节
随机梯度下降中,每批次梯度可视为随机变量。应用马尔科夫不等式,可以估计梯度超过阈值的概率上界,帮助动态调整学习率。
🛡️ 异常检测阈值设定
在无监督异常检测中,若特征 X X X的均值为 μ \mu μ,方差为 σ 2 \sigma^2 σ2,根据切比雪夫不等式,设置阈值 T = μ + k σ T = \mu + k\sigma T=μ+kσ,则异常比例不超过 1 k 2 \frac{1}{k^2} k21,提供了阈值选择的理论依据。
5️⃣ 与其他概率界的关系与扩展 🌐
🔗 霍夫丁不等式(Hoeffding’s Inequality)
切比雪夫的一个重要扩展,提供了有界随机变量和的更紧概率界限,是PAC学习理论和VC维分析的基础。
形式:若 X 1 , X 2 , . . . , X n X_1, X_2, ..., X_n X1,X2,...,Xn是独立随机变量且 a i ≤ X i ≤ b i a_i \leq X_i \leq b_i ai≤Xi≤bi,则:
P ( ∣ 1 n ∑ i = 1 n X i − E [ 1 n ∑ i = 1 n X i ] ∣ ≥ ϵ ) ≤ 2 e − 2 n 2 ϵ 2 ∑ i = 1 n ( b i − a i ) 2 P\left(|\frac{1}{n}\sum_{i=1}^n X_i - E[\frac{1}{n}\sum_{i=1}^n X_i]| \geq \epsilon\right) \leq 2e^{-\frac{2n^2\epsilon^2}{\sum_{i=1}^n (b_i-a_i)^2}} P(∣n1∑i=1nXi−E[n1∑i=1nXi]∣≥ϵ)≤2e−∑i=1n(bi−ai)22n2ϵ2
🔄 集中不等式(Concentration Inequalities)
马尔科夫和切比雪夫不等式是最基础的集中不等式,在高维统计和机器学习中,更广泛应用的有:
- 次高斯分布的概率界
- 矩阵浓缩不等式,用于随机矩阵分析
- 经验风险最小化的泛化误差界
6️⃣ 代码实践:模型鲁棒性评估工具 🛠️
def estimate_robustness(model, test_data, test_labels, epsilon=0.1):"""使用切比雪夫不等式估计模型对输入扰动的鲁棒性Args:model: 训练好的模型test_data: 测试数据test_labels: 测试标签epsilon: 输入扰动幅度Returns:robustness_score: 模型鲁棒性分数 (0-1,越高越好)"""# 计算原始预测original_preds = model.predict(test_data)original_acc = np.mean(np.argmax(original_preds, axis=1) == test_labels)# 生成扰动数据perturbed_data = test_data + np.random.normal(0, epsilon, test_data.shape)perturbed_preds = model.predict(perturbed_data)# 计算预测变化的方差pred_diff = np.abs(original_preds - perturbed_preds)pred_var = np.var(pred_diff)# 使用切比雪夫不等式估计稳定性delta = 0.1 # 允许的预测变化阈值stability_prob_lower = 1 - (pred_var / (delta**2))stability_prob_lower = max(0, min(1, stability_prob_lower)) # 限制范围[0,1]print(f"模型原始准确率: {original_acc:.4f}")print(f"预测变化方差: {pred_var:.6f}")print(f"稳定性下界(切比雪夫): {stability_prob_lower:.4f}")return stability_prob_lower
7️⃣ 总结与进阶方向 📚
📌 要点总结
- 马尔科夫不等式:通过均值提供单侧概率上界,适用于非负随机变量
- 切比雪夫不等式:通过方差提供双侧概率界,更精确但要求更多信息
- 机器学习应用:从模型训练、评估到部署,这些不等式提供了理论基础
- 实践价值:即使在不知道确切分布的情况下也能得到有用的概率界限
🚀 进阶方向
-
探索更精确的界限:学习柴丁-霍夫丁不等式(Chernoff-Hoeffding bounds),它在大多数情况下提供比切比雪夫更紧的概率界
-
指数型马尔科夫不等式:研究基于矩生成函数的指数马尔科夫不等式,形式为 P ( X ≥ a ) ≤ E [ e t X ] e t a P(X \geq a) \leq \frac{E[e^{tX}]}{e^{ta}} P(X≥a)≤etaE[etX],它是许多更强不等式的基础
-
次高斯(Sub-Gaussian)与次指数(Sub-Exponential)随机变量:这些特殊类型的随机变量具有更好的尾部概率界限,在高维统计和机器学习理论中广泛应用
-
经验风险最小化(ERM)理论:了解如何使用集中不等式推导学习算法的泛化误差界
8️⃣ 机器学习算法中的应用实例 🧠
🤖 梯度下降的收敛性分析
随机梯度下降(SGD)中,单次梯度可视为随机变量。若其方差有界,通过切比雪夫不等式可估计:
P ( ∣ ∣ ∇ f ( x t ) − E [ ∇ f ( x t ) ] ∣ ∣ ≥ ϵ ) ≤ σ 2 ϵ 2 P\left(||\nabla f(x_t) - \mathbb{E}[\nabla f(x_t)]|| \geq \epsilon\right) \leq \frac{\sigma^2}{\epsilon^2} P(∣∣∇f(xt)−E[∇f(xt)]∣∣≥ϵ)≤ϵ2σ2
这解释了为什么:
- 小批量(mini-batch)SGD比单样本SGD更稳定
- 梯度裁剪(gradient clipping)能提高训练稳定性
- 学习率衰减策略有助于收敛
📋 特征选择与降维
在特征选择中,可使用切比雪夫不等式评估特征缺失对模型性能的影响。若特征 X i X_i Xi 的信息增益方差为 σ i 2 \sigma_i^2 σi2,则可以估计删除该特征后模型性能下降超过阈值 δ \delta δ 的概率。
def feature_stability_score(feature_importances, n_bootstrap=100):"""使用切比雪夫不等式评估特征重要性的稳定性"""importances = []for _ in range(n_bootstrap):# 假设有bootstrap重采样的特征重要性数据bootstrap_idx = np.random.choice(len(feature_importances), len(feature_importances), replace=True)importances.append(feature_importances[bootstrap_idx])# 计算每个特征重要性的方差variances = np.var(importances, axis=0)# 使用切比雪夫不等式估计稳定性epsilon = 0.05 # 允许的波动stability_scores = 1 - (variances / (epsilon**2))stability_scores = np.clip(stability_scores, 0, 1) # 限制在[0,1]范围return stability_scores
🎯 异常检测与离群点识别
在基于密度的异常检测中,马尔科夫不等式提供了一个重要思路:如果数据点 x x x 的密度估计值 p ( x ) p(x) p(x) 满足 p ( x ) < τ E [ p ( X ) ] p(x) < \frac{\tau}{E[p(X)]} p(x)<E[p(X)]τ,则 x x x 可能是异常值。这是局部异常因子(LOF)等算法的理论基础之一。
9️⃣ 常见问题与解答 ❓
Q1: 这些不等式在深度学习中有什么应用?
A: 在深度学习中,这些不等式帮助:
- 分析网络权重初始化策略的合理性
- 证明Dropout等正则化技术的有效性
- 设计自适应学习率优化器(如AdaGrad)
- 分析批量归一化(Batch Normalization)等技术的收敛性质
- 评估模型对对抗样本的鲁棒性
Q2: 为什么切比雪夫不等式在实际中常被认为界限过松?
A: 切比雪夫不等式适用于任何具有有限方差的分布,这种通用性导致界限较为保守。对于特定分布(如高斯分布),可以得到更紧的界限。例如,对于高斯分布,3-sigma规则表明偏离均值超过3个标准差的概率约为0.003,而切比雪夫仅给出 1 / 9 ≈ 0.111 1/9 \approx 0.111 1/9≈0.111 的上界。
Q3: 如何使用这些不等式设计早停策略?
A: 设模型在验证集上的损失为随机变量 L L L,其移动平均为 μ t \mu_t μt,移动方差为 σ t 2 \sigma_t^2 σt2。使用切比雪夫不等式,可估计损失低于当前最佳值的概率上界。若该概率小于阈值(如0.05),则可能已接近最优,可以考虑早停。
🔟 经典应用:PAC学习理论 🎓
PAC(Probably Approximately Correct)学习理论是机器学习的理论基础,而集中不等式(特别是霍夫丁不等式,切比雪夫不等式的一个扩展)在其中扮演核心角色。
对于样本量为 m m m 的训练集,经验风险为 R ^ ( h ) \hat{R}(h) R^(h),真实风险为 R ( h ) R(h) R(h),霍夫丁不等式给出:
P ( ∣ R ( h ) − R ^ ( h ) ∣ ≥ ϵ ) ≤ 2 e − 2 m ϵ 2 P(|R(h) - \hat{R}(h)| \geq \epsilon) \leq 2e^{-2m\epsilon^2} P(∣R(h)−R^(h)∣≥ϵ)≤2e−2mϵ2
这意味着当样本量 m ≥ 1 2 ϵ 2 ln 2 δ m \geq \frac{1}{2\epsilon^2}\ln\frac{2}{\delta} m≥2ϵ21lnδ2 时,我们有 1 − δ 1-\delta 1−δ 的置信度认为经验风险与真实风险的差不超过 ϵ \epsilon ϵ。这直接导出了PAC学习的样本复杂度界限。
def calculate_pac_sample_size(epsilon, delta):"""计算PAC学习理论下需要的最小样本量Args:epsilon: 允许的经验风险与真实风险之间的误差delta: 允许的失败概率Returns:m: 所需最小样本数"""m = np.ceil((1 / (2 * (epsilon**2))) * np.log(2 / delta))return int(m)# 示例:如果想要95%的置信度,误差不超过0.1
sample_size = calculate_pac_sample_size(0.1, 0.05)
print(f"为获得95%置信度,误差不超过0.1,需要至少{sample_size}个样本")
💭 结语
马尔科夫和切比雪夫不等式是机器学习数学基础中的璀璨明珠。它们不仅提供了理论保证,更在实际算法设计和模型评估中发挥着不可替代的作用。掌握这些工具,我们能够:
- 对模型性能做出可靠估计,即便不知道准确的数据分布
- 设计具有理论保证的算法
- 更好地理解现有算法的优缺点
- 建立对模型可靠性的信心
在机器学习日益成为关键技术的今天,深入理解这些基础概念不仅是理论探索,更是实践应用的坚实基石。希望这篇文章能帮助你在机器学习的数学迷宫中找到前进的方向!
💡 思考练习: 试着用马尔科夫不等式估计你的模型在极端情况下可能达到的最差性能,然后思考如何通过降低相应指标的方差来提高这个下限。记住,真正的工程师不仅追求平均性能,更要保证最坏情况下的可靠性!
如果你对这个系列感兴趣,可以关注我的「机器学习数学通关指南」专栏,我们将继续探索概率论、线性代数、优化理论等领域在机器学习中的精彩应用!
相关文章:
马尔科夫不等式和切比雪夫不等式
前言 本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《机器学习数学通关指南》 正文 统计概率的利剑:掌…...

护照阅读器在汽车客运站流程中的应用
在汽车客运站的日常运营里,如何高效服务旅客、保障出行安全是工作重点。护照阅读器作为精准身份识别的得力工具,在客运站的多个关键流程,如自助购票、柜台购票、安检以及行李托运中,发挥着不可小觑的作用,有力地提升了…...

CentOS 7 安装Nginx-1.26.3
无论安装啥工具、首先认准了就是官网。Nginx Nginx官网下载安装包 Windows下载: http://nginx.org/download/nginx-1.26.3.zipLinxu下载 wget http://nginx.org/download/nginx-1.26.3.tar.gzLinux安装Nginx-1.26.3 安装之前先安装Nginx依赖包、自行选择 yum -y i…...

Unity 使用NGUI制作无限滑动列表
原理: 复用几个子物体,通过子物体的循环移动实现,如下图 在第一个子物体滑动到超出一定数值时,使其放到最下方 --------------------------------------------------------------》 然后不停的循环往复,向下滑动也是这…...

linux中断调用流程(arm)
文章目录 ARM架构下Linux中断处理全流程解析:从硬件触发到驱动调用 ⚡**一、中断触发与硬件层响应** 🔌**1. 设备触发中断** 📡 **二、CPU阶段:异常入口与上下文处理** 🖥️**1. 异常模式切换** 🔄**2. 跳转…...

基于Matlab的多目标粒子群优化
在复杂系统的设计、决策与优化问题中,常常需要同时兼顾多个相互冲突的目标,多目标粒子群优化(MOPSO)算法应运而生,作为群体智能优化算法家族中的重要成员,它为解决此类棘手难题提供了高效且富有创新性的解决…...

【网络安全】——协议逆向与频繁序列提取:从流量中解码未知协议
目录 引言 一、为什么要结合频繁序列提取? 二、四步融合分析法 步骤1:原始流量采集与预处理 步骤2:多粒度序列模式挖掘 层1:单包内字节级频繁项 层2:跨数据包的行为序列 步骤3:关键字段定位与结构假…...

CSS 中等比例缩放的演变:从传统技巧到 aspect-ratio 属性
CSS 中等比例缩放的演变:从传统技巧到 aspect-ratio 属性 在响应式网页设计和多设备兼容成为主流的今天,如何实现元素的等比例缩放成为前端开发中一个重要的课题。无论是图片、视频还是其他容器,都常常需要保持固定的宽高比,以便…...

系统架构设计师—计算机基础篇—进度管理
文章目录 基本概念进程的特征进程的状态前趋图 进程的通信进程的互斥做题方法 进程的同步PV操作做题方法 基本概念 进程的特征 进程通常由程序、数据集合、进程控制块PCB组成。 PCB是一种数据结构,是进程存在的唯一标识。 组织方式说明线性方式把所有PCB组织在一…...

初始提示词(Prompting)
理解LLM架构 在自然语言处理领域,LLM(Large Memory Language Model,大型记忆语言模型)架构代表了最前沿的技术。它结合了存储和检索外部知识的能力以及大规模语言模型的强大实力。 LLM架构由外部记忆模块、注意力机制和语…...

Ollama+AnythingLLM安装
一、文件准备 1. 安装包获取 从联网设备下载: AnythingLLMDesktopInstaller.exe(官网离线安装包) deepseek-r1-1.5b.gguf(1.5B 参数模型文件) 2. 传输介质 使用 U 盘或移动硬盘拷贝以下文件至离线设…...

docker拉取失败
备份原始配置文件 sudo cp /etc/docker/daemon.json /etc/docker/daemon.json.bak 清理或修复 daemon.json 文件 sudo nano /etc/docker/daemon.json 删除 文件中的所有内容,确保文件为空。 cv下面这个文件内容 { "registry-mirrors": [ &…...

PHP之Cookie和Session
在你有别的编程语言的基础下,你想学习PHP,可能要了解的一些关于cookie和session的信息。 Cookie 参数信息 setcookie(name,value,expire, path, domain); name : Cookie的名称。 value : Cookie的值。 expire : Cookie的过期时间,可以是一…...

【万字长文】基于大模型的数据合成(增强)及标注
写在前面 由于合成数据目前是一个热门的研究方向,越来越多的研究者开始通过大模型合成数据来丰富训练集,为了能够从一个系统的角度去理解这个方向和目前的研究方法便写了这篇播客,希望能对这个领域感兴趣的同学有帮助! 欢迎点赞&…...

CES Asia 2025增设未来办公教育板块,科技变革再掀高潮
作为亚洲消费电子领域一年一度的行业盛会,CES Asia 2025(第七届亚洲消费电子技术贸易展)即将盛大启幕。今年展会规模再度升级,预计将吸引超过500家全球展商参展,专业观众人数有望突破10万。除了聚焦人工智能、物联网、…...

Python详细安装教程——Python及PyCharm超详细安装教程:新手小白也能轻松搞定!(最新版)
Python作为一门简单易学、功能强大的编程语言,近年来在数据分析、人工智能、Web开发等领域广受欢迎。而PyCharm作为一款专业的Python集成开发环境(IDE),提供了强大的代码编辑、调试和项目管理功能,是Python开发者的得力…...

游戏引擎学习第137天
演示资产系统中的一个 bug 我们留下了个问题,你现在可以看到,移动时它没有选择正确的资产。我们知道问题的原因,就在之前我就预见到这个问题会出现。问题是我们的标签系统没有处理周期性边界的匹配问题。当处理像角度这种周期性的标签时&…...

RAGflow升级出错,把服务器灌满了
使用自动化更新命令,从16升级到17,结果发现出现了大问题,不断下载,一直无法下载完毕。 df -h 直接把服务器搞满了。哈哈哈哈~。查看一下: sudo du -sh /var/lib/docker确认是docker里面安装的ragflow有问题。所以&am…...
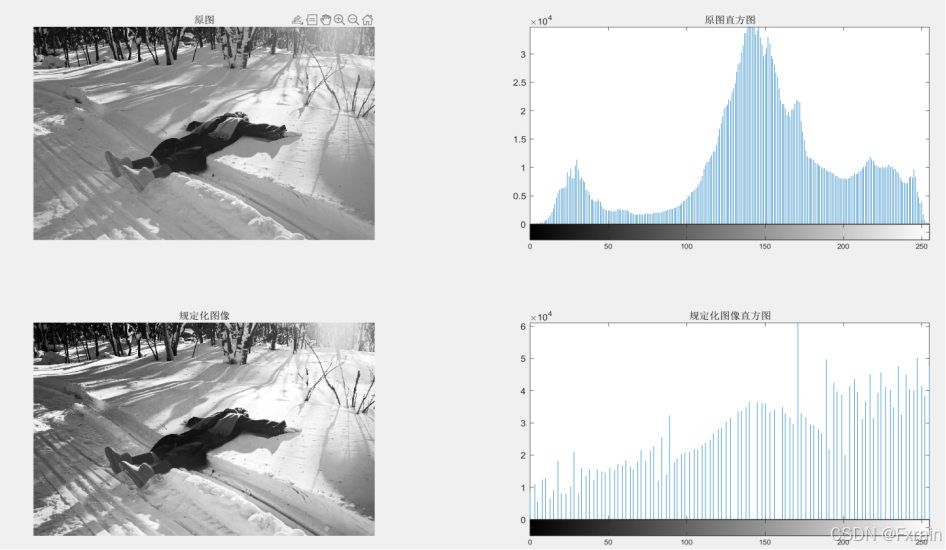
[数字图像处理]直方图规定化
这里分别使用基于像素手动计算、调用工具箱函数两种方法实现直方图规定化 1.基于像素进行直方图规定化 (1)读取了原始图像和期望图像,并将它们转换为灰度图像 (2)计算原始图像和期望图像的像素概率分布直方图P(i)和…...

OpenMCU(一):STM32F407 FreeRTOS移植
概述 本文主要描述了STM32F407移植FreeRTOS的简要步骤。移植描述过程中,忽略了Keil软件的部分使用技巧。默认读者熟练使用Keil软件。本文的描述是基于OpenMCU_FreeRTOS这个工程,该工程已经下载放好了移植stm32f407 FreeRTOS的所有文件 OpenMCU_FreeRTOS工…...
)
告别卡顿!在Windows上用VirtualBox+Ubuntu 20.04搭建涂鸦Wi-Fi SoC开发环境(保姆级避坑指南)
告别卡顿!在Windows上用VirtualBoxUbuntu 20.04搭建涂鸦Wi-Fi SoC开发环境(保姆级避坑指南) 嵌入式开发环境搭建往往是工程师面临的第一个挑战。当你在Windows系统上尝试运行Linux虚拟机进行涂鸦Wi-Fi SoC开发时,可能会遇到各种性…...

语音克隆从入门到商用变现,手把手教你在TikTok/播客/AI助手部署高保真克隆声,今天就能上线
更多请点击: https://kaifayun.com 第一章:语音克隆技术演进与ElevenLabs核心能力解析 语音克隆技术已从早期基于拼接的单元选择(Unit Selection)和统计参数合成(HMM-based TTS),跨越深度学习驱…...

如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析
如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你…...

命令行AI工具gemini-cli:无缝集成Gemini大模型提升终端效率
1. 项目概述:一个与AI对话的命令行工具 如果你和我一样,大部分工作时间都泡在终端里,那么 eliben/gemini-cli 这个项目可能会让你眼前一亮。简单来说,它是一个让你能在命令行里直接与 Google 的 Gemini 大模型对话的工具。你不…...

OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级
OpenCore Legacy Patcher技术揭秘:4步实现老旧Mac硬件兼容性修复与系统升级 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在苹果生态系统中&…...

HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合
HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的游戏体验而烦恼…...

5分钟免费搭建PUBG终极雷达系统:实现战场全透视的完整指南
5分钟免费搭建PUBG终极雷达系统:实现战场全透视的完整指南 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-ma…...

专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案
专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案 【免费下载链接】glogg A fast, advanced log explorer. 项目地址: https://gitcode.com/gh_mirrors/gl/glogg 在当今的分布式系统和微服务架构中,日志分析已成为系统运维、故障排…...

如何用MGit在Android手机上轻松管理Git仓库:完整指南
如何用MGit在Android手机上轻松管理Git仓库:完整指南 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 你是否曾经希望在Android手机上也能像在电脑上一样轻松管理Git仓库?MGit就是为你量身打…...

逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数
逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数 在逆向分析领域,MFC程序因其复杂的消息映射机制和封装层次,常常让分析者感到无从下手。特别是当我们需要分析某个特定窗口消息(如按钮点击、菜单选择)的处…...