课程3. 分批训练与数据规范、标准化
课程3. 分批训练与数据规范、标准化
- 理论
- 神经网络的梯度优化
- 反向传播算法
- 批量训练
- 网络输入的规范化
- BatchNorm
- 验证样本
- 实践
- 加载数据集
- 网络构建
- 训练神经网络
课程计划:
1.理论:
批量训练;
输入数据的规范化;
批量标准化(batchnorm); ——验证样品;
2.练习:
在 PyTorch 上使用神经网络进行 MNIST 数字图像分类。
理论
神经网络的梯度优化
我们已经知道,神经网络是使用基于梯度下降的反向传播算法进行训练的。其本质是通过计算损失 L L L对网络参数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L的偏导数来持续改变神经网络参数的值。
我们来回忆一下神经网络训练算法的思路是什么样的:
假设我们有一个神经网络 F F F,一个由 n n n 个元素组成的数据集 { X i , Y i } i = 0 n \{X_i, Y_i\}_{i=0}^n {Xi,Yi}i=0n,以及一个损失函数 l o s s loss loss。然后我们的任务就是找到这样的神经网络权重值,使得数据集所有元素的损失函数 l o s s loss loss的平均值很小:
L = ∑ i = 1 n l o s s ( y i , y ^ i ) n → m i n L = \frac{∑^{n}_{i=1} loss(y_i, \widehat{y}_i)}{n} \to min L=n∑i=1nloss(yi,y i)→min
这里 y i y_i yi是数据集中第i个元素的正确答案, y ^ i \widehat{y}_i y i是神经网络对数据集中第 i i i个元素的答案。
梯度下降算法利用以下思想来帮助找到最佳权重:
- 偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 的符号表示权重 w i w_i wi 应该向哪个方向移动,以使损失值 L L L 变小;
- 偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 的模越大, w i w_i wi 的值距离最优值越远;
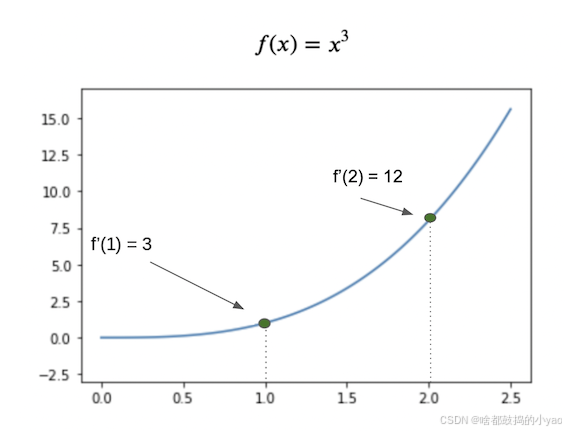
神经网络的梯度优化算法如下所示:
- 用随机值初始化所有网络权重 W i W_i Wi和 b i b_i bi。我们选择梯度下降步长 α \alpha α 的值
- 直到满足停止标准为止,执行以下操作:
- 利用参数 W i W_i Wi和 b i b_i bi的当前值计算 L L L的值;
- 我们计算偏导数 ∂ L ∂ W i \frac{\partial L}{\partial W_i} ∂Wi∂L、 ∂ L ∂ b i \frac{\partial L}{\partial b_i} ∂bi∂L的值;
- 更新网络参数值:
W i = W i − α ∂ L ∂ W i , b i = b i − α ∂ L ∂ b i W_i = W_i - \alpha \frac{\partial L}{\partial W_i}, \ \ b_i = b_i - \alpha \frac{\partial L}{\partial b_i} Wi=Wi−α∂Wi∂L, bi=bi−α∂bi∂L
停止标准可能有所不同。最合乎逻辑和最普遍的说法是:当每次迭代(或从一个时代到另一个时代)的损失变化幅度变小时,我们就停止。此外,我们还监控过度训练:如果开始过度训练,我们就会停止算法。
反向传播算法
从之前的讲座中大家可以知道,在标准梯度下降的基础上,人们已经发明了大量的修改方法,其中当今最流行、最有效的修改方法就是ADAM(Adaptive Gradients with Momentum)算法。对于每一种可能的梯度方法,都会出现一个问题:如何根据深度神经网络的参数有效地计算损失函数的梯度。问题是这样的:为了对神经网络的所有权重进行自动微分,需要计算最终函数的值,计算次数与我们计算梯度的参数数量成线性比例。对于深度神经网络来说,这个值可以达到数十亿、数千亿。有必要简化这一过程,并学会在比使用标准数值方法计算导数更短的时间内计算模型所有参数的导数。为此,有一个众所周知的算法叫做反向传播。
反向传播算法是一种将复杂函数的微分法则应用于神经网络层层逐次计算梯度的问题的方法。
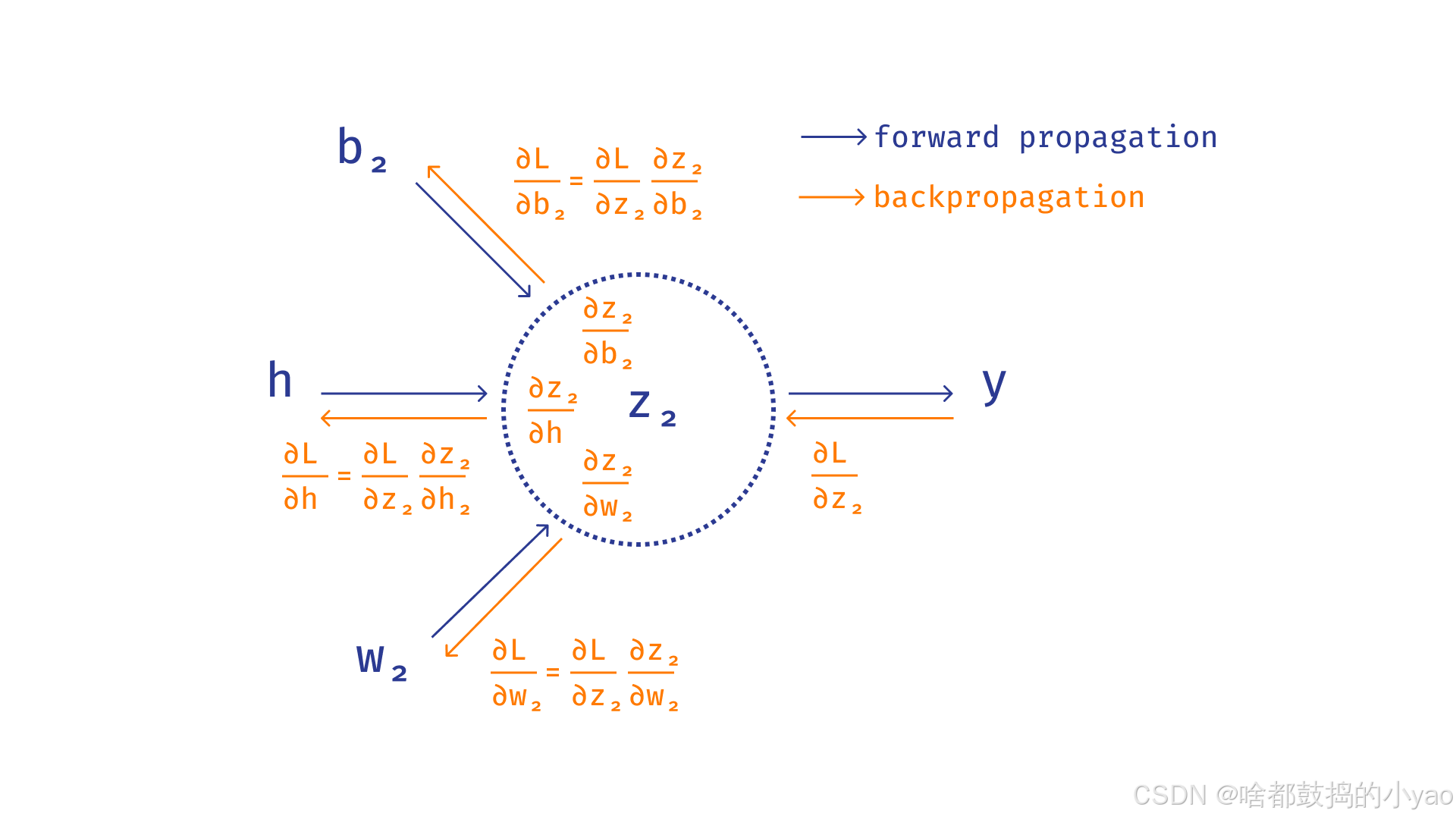
为了方便起见,我们引入以下符号和术语:
- 我们将原始张量 X X X 在神经网络处理过程中的连续变换称为信号。
- 对于每个完全连接的层,经过线性变换处理但尚未输入到激活函数的信号值将被称为预激活,并用 z z z 表示
- 经过激活函数变换后,该层的输出将被称为层 a a a的激活
- 令 Q Q Q 表示要最小化的函数, L L L 表示层内线性变换的应用
层间信号转换由以下公式确定:
z i + 1 = L i ( a i ) = L i ( f i ( z i ) ) z_{i+1} = L_i(a_i) = L_i(f_i(z_i)) zi+1=Li(ai)=Li(fi(zi))
其中 L i L_i Li 是定义第 i 层的线性变换(即,在基本情况下,只是乘以某个矩阵), f i f_i fi 是第 i 层的激活函数。反向传播算法提出将损失函数Q关于第i层参数的导数展开如下:
∂ Q ∂ ω i = ∂ Q ∂ z i + 1 ∂ z i + 1 ∂ ω i = ∂ Q ∂ z i + 1 ∂ z i + 1 ∂ z i ∂ z i ∂ ω i \frac{∂ Q}{∂ ω_i} = \frac{∂ Q}{∂ z_{i+1}}\frac{∂ z_{i+1}}{∂ ω_i} = \frac{∂ Q}{∂ z_{i+1}}\frac{∂ z_{i+1}}{∂ z_i}\frac{∂ z_{i}}{∂ \omega_i} ∂ωi∂Q=∂zi+1∂Q∂ωi∂zi+1=∂zi+1∂Q∂zi∂zi+1∂ωi∂zi
该公式应这样理解:此处的索引表示相应名称所指的层的编号。这里 ω i ω_i ωi是第i层的任意参数,也就是说,这个公式对于定义第i个线性层的矩阵 W i W_i Wi的任何元素都成立。
此外,该公式中以下结论也成立:
(1)对于最后一层,计算关于参数和预激活的导数并不困难。它们的数量相当多,并且不会花费太多时间。在标准分类和回归问题中,最后一层只包含一个神经元。
(2)如果我们知道对第i+1层预激活的导数,那么根据最后一个公式,我们不难计算出对第i层参数的导数。事实上: ∂ z i + 1 ∂ z i \frac{∂ z_{i+1}}{∂ z_i} ∂zi∂zi+1 很容易表示,因为 z i + 1 = W i + 1 ⋅ f i ( z i ) z_{i+1} = W_{i+1}⋅f_i(z_i) zi+1=Wi+1⋅fi(zi),其中我们知道矩阵 W i W_i Wi 和函数 f i f_i fi。我们还可以计算导数 ∂ z i ∂ ω i \frac{∂ z_{i}}{∂ \omega_i} ∂ωi∂zi,因为 ω i \omega_i ωi 是矩阵 W i W_i Wi 的一个分量,且 z i = W i ⋅ a i − 1 z_i = W_i \cdot a_{i-1} zi=Wi⋅ai−1
(3)因此,我们可以从最后一层的导数开始,一步步回到第一层,重新计算所有的导数
批量训练
现在让我们想象一下我们有一个大型数据集。例如,1,000,000 个元素。对于这样的数据集,上述算法的每次迭代都会花费非常长的时间,因为每次迭代都需要计算神经网络的输出值以及所有数据元素的损失 L L L!
此外,还可能出现第二个问题:大型数据集可能不适合放入 GPU 内存。那么我们基本上就无法在算法中迈出一步。
解决方案是这样的:让我们在每个步骤中针对部分数据集元素计算损失 L L L 和偏导数的值,而不是一次性针对所有数据集元素计算损失 L L L 和偏导数的值。例如,对于 100 个元素。那么算法将如下所示:
神经网络的梯度优化算法如下所示:
- 用随机值初始化所有网络权重 W i W_i Wi和 b i b_i bi。我们选择梯度下降步长 α \alpha α 的值
- 直到满足停止标准为止,执行以下操作:
- 我们将数据分成批,每批有 k k k个元素。对于每个 batch 我们执行以下操作:
- 我们根据当前第 j j j 个批次的元素,用参数 W i W_i Wi 和 b i b_i bi 的当前值计算 L j L^j Lj 的值;
- 我们计算偏导数 ∂ L j ∂ W i \frac{\partial L^j}{\partial W_i} ∂Wi∂Lj、 ∂ L j ∂ b i \frac{\partial L^j}{\partial b_i} ∂bi∂Lj的值;
- 更新网络参数值:
W i = W i − α ∂ L j ∂ W i , b i = b i − α ∂ L j ∂ b i W_i = W_i - \alpha \frac{\partial L^j}{\partial W_i}, \ \ b_i = b_i - \alpha \frac{\partial L^j}{\partial b_i} Wi=Wi−α∂Wi∂Lj, bi=bi−α∂bi∂Lj
- 我们将数据分成批,每批有 k k k个元素。对于每个 batch 我们执行以下操作:
该算法称为小批量梯度下降或随机梯度下降(SGD)。
这种算法的每次迭代都比通常的梯度下降的每次迭代快得多,在梯度下降中我们每次都会计算数据集所有元素的 L L L 值。但随机梯度下降所需的总迭代次数较高。
为了理解其含义,让我们考虑批量大小等于一的极端情况。也就是说,在梯度下降的每次迭代中,我们仅根据数据集的一个元素来计算表达式 L L L 的值和偏导数。这意味着在算法的每一步我们都会改变网络权重,以便网络开始针对当前元素 y i y_i yi 产生最佳答案。但是这种权重变化的方向并不一定与导致数据集所有元素的网络性能提高的方向完全一致。
事实证明,每一步的随机梯度下降都会使参数值朝着略微偏离理想的方向移动。
具体如下:
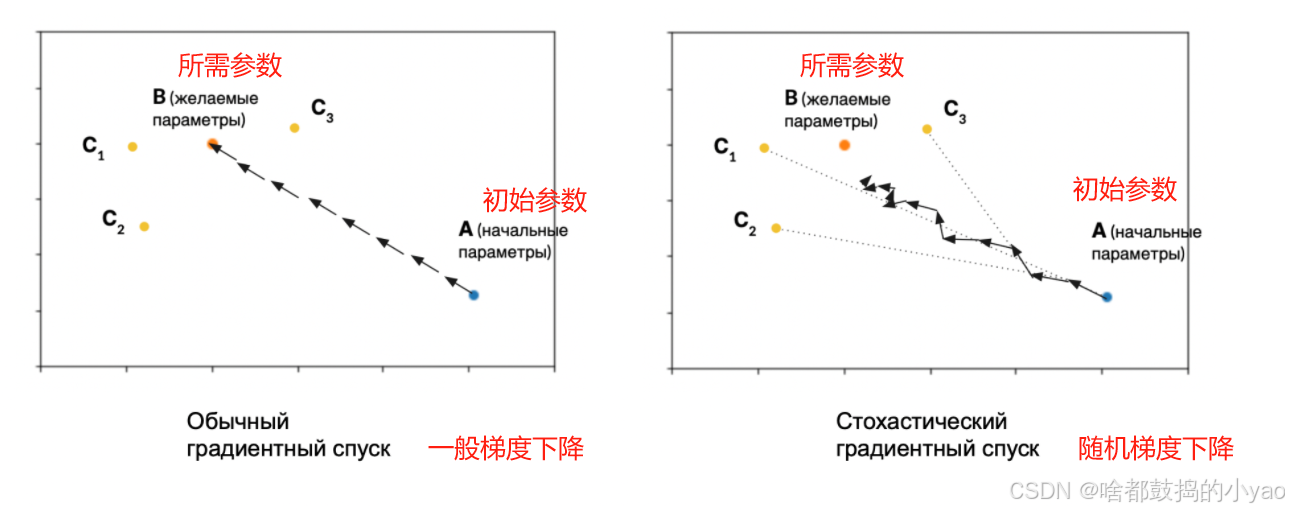
这里 D i D_i Di是第 i i i个batch上的损失值最小的网络参数值向量。平均而言, D i D_i Di比 C i C_i Ci更接近 B B B。因此,小批量的梯度下降所需的迭代次数将比批量大小为 1 时更少。
事实证明,我们需要在算法一次迭代的执行速度和所需的迭代次数之间进行权衡。实际上,批量大小通常被认为是 GPU 允许的最大值。
网络输入的规范化
对于神经网络,在将输入数据输入网络之前对其进行规范化是很有用的。规范化是将所有输入特征的分布带到同一尺度的过程。
例如,假设我们有一项任务,是根据客户信息确定信用评分。让信息包括客户的年龄。此特征的值变化为[18, 80],即在相当大的范围内,它的绝对值可能相当大。这使得梯度下降算法的效率降低,需要更多的迭代来训练网络,还会导致网络中梯度爆炸等其他问题。您可以通过“附加”部分中的链接了解为什么会发生这种情况。
最常见的规范化方法是标准化。这减少到了平均值 0 和方差 1。
假设我们有一个特征 F F F,以及它在数据集中的值 { x i f } \{x_i^f\} {xif}。那么每个元素的属性值变化如下:
x i f − μ f σ f \frac{x_i^f-\mu_f}{\sigma_f} σfxif−μf
,其中 μ f \mu_f μf是数据集中特征 F F F的平均值, σ f \sigma_f σf是数据集中特征 F F F的标准差。经过这样的标准化之后,数据集的特征的平均值将为0,标准差将为1。
特征的规范化可以说明如下。假设数据集中有两个特征。我们将数据集的元素可视化为平面上的点。
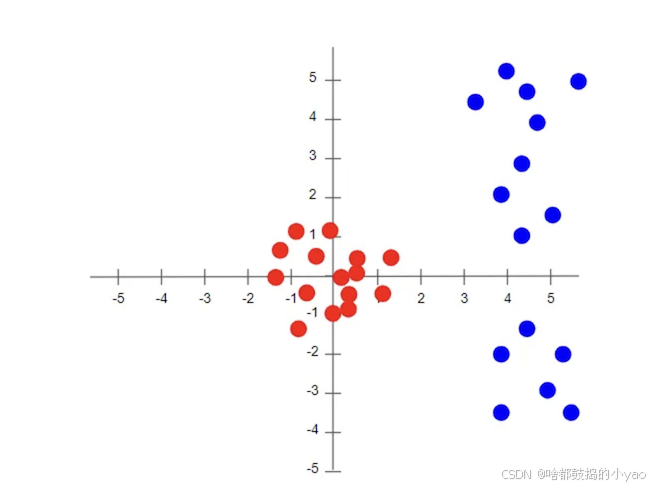
这里的蓝点表示标准化之前的数据集元素,红点表示标准化之后的数据集元素。
BatchNorm
现在我们来讨论网络的一个新的层——批量标准化。 这一层有助于使网络训练更稳定、更快。此外,具有批量规范层的神经网络通常比没有批量规范的相同网络更好地学习任务。
让我们看一下具有多层的神经网络。请注意,该神经网络的 2-3 层可以被视为一个单独的、较小的神经网络。该神经网络的输入数据是网络第一层的输出。
我们已经知道,为了更好地训练神经网络,输入数据需要规范化。事实证明,规范化每个中间层的输出也有助于更好的网络训练。 BatchNorm 是执行此标准化的层。
但是还有第二个原因来规范中间层的输出。这是神经网络内部协变量转移的影响。 BatchNorm 最初是为了消除这种影响而设计的。
什么是内部协变量转移:让我们看一下具有几层的神经网络。在训练过程中,各层一起学习。并且网络在训练时每一层都必须适应前一层产生的值。但是在网络训练的时候,网络每一层输出的数值的分布是会发生变化的。并且算法每次迭代时每个隐藏层都必须适应前一层输出的新分布。正因为如此,网络学习得比较慢。同时,在每次训练迭代中,权重可能会发生相当大的变化,这可能会引发其他问题,例如梯度爆炸。
规范化神经网络层的输出将有助于解决这个问题。
那么我们如何实现层输出的规范化呢?最简单的想法是在将每一层的输出进一步输入到网络之前对其进行严格的规范化,就像我们规范化输入数据一样。假设,也将所有层输出的平均值降低为 0,方差降低为 1。
但是为什么不给神经网络更多的自由并让它自己决定如何最好地规范化每一层的输出呢?
这就是 BatchNorm 背后的想法。 BatchNorm 是一个可训练层,它使用可训练参数对网络输出进行规范化。
BatchNorm层应用在网络层之后,其工作原理如下:
- 我们按批次计算网络层输出的平均值 μ B \mu_B μB和标准差 σ B \sigma_B σB。也就是说,我们有层 { x i } i = 1 b \{x_i\}_{i=1}^b {xi}i=1b 的 b b b 个输出,其中 b b b 是批量大小。然后:
μ B = ∑ i = 1 b x i b \mu_B = \frac{\sum_{i=1}^b x_i}{b} μB=b∑i=1bxi
σ B 2 = ∑ i = 1 b ( x i − μ B ) 2 b \sigma^2_B = \frac{\sum_{i=1}^b (x_i - \mu_B)^2}{b} σB2=b∑i=1b(xi−μB)2
-
规范化层输出:
x i ^ = x i − μ B σ B \widehat{x_i} = \frac{x_i - \mu_B}{\sigma_B} xi =σBxi−μB -
计算更新后的层输出为
y i = γ x i ^ + β y_i = \gamma\widehat{x_i} + \beta yi=γxi +β
,其中 γ \gamma γ和 β \beta β是训练参数。
所以这个想法是这样的:我们对每个神经元的输出进行标准化,使得其输出的平均值是 0,方差是 1。然后我们将每个神经元的输出乘以可训练值 γ \gamma γ 并添加可训练值 β \beta β。也就是说,我们改变神经元输出的平均值及其方差。但同时,我们使得该层的所有神经元的平均输出值和方差相同。
每层的可学习平均值和方差使得神经网络能够为特定任务选择最方便的层值标准化。
在实践中,BatchNorm 几乎用于所有神经网络,尤其是深度神经网络。当我们讨论流行的网络架构时我们会再次看到这一点。
验证样本
为了在训练过程中跟踪网络的当前质量,训练样本通常分为两部分:训练和验证。训练部分用于训练网络,验证部分用于在每 n 次训练迭代之后(例如,每个 epoch 之后)检查网络的质量。
测试样品不能作为验证样品。因此测试样本存在过度拟合的风险。
验证样本的主要功能:
-
在训练过程中监控模型的质量。这对于跟踪训练模型时可能出现的问题非常重要:过度拟合、梯度爆炸或衰减、模型参数的不良分布或“滚动”到简单的答案。根据验证样本的结果,通常会从训练期间保存的集合中选择最终模型。需要注意的是,在大型神经网络的情况下,使用验证样本时不能排除可能的随机性因素:即使是训练不佳的模型有时也能在验证样本上显示出良好的结果。这类似于多重假设检验的效果,需要进行校正(如果我们测试同一模型的许多不同版本,即使是随机的,在某个时候我们也会找到一个在验证集上提供高质量的版本)。这种影响可以被视为验证样本的一种过度训练。因此,验证样本和测试样本必须彼此不同。
-
一些超参数的选择。对于训练许多模型来说,以最佳方式选择超参数非常重要。但这无法在训练样本上完成,因为无法排除模型的过度拟合(即,所选的超参数与优化参数的组合本身是好的,而不是针对特定的训练样本)。在测试样本上执行此操作也是不可能的,因为我们可以对其进行重新训练,并且它不再是测试样本。为了这些目的,有必要使用验证样本。
实践
在本部分中,我们将使用 PyTorch 上的全连接神经网络解决将图像分类为 10 个类的问题。

import numpy as np
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
%matplotlib inline# PyTorch 库模块
import torch
from torchvision import datasets, transforms
加载数据集
MNIST数据集是标准数据集之一,位于PyTorch框架的数据集模块中。下载并加载到内存中非常简单:
train_data = datasets.MNIST(root="./mnist_data", train=True, download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST(root="./mnist_data", train=False, download=True, transform=transforms.ToTensor())

这里:
- root — 下载数据集的文件夹路径;
- train — 如果为 True,则下载样本的训练部分;如果为 False — 则下载测试部分;
- download — 如果数据集尚未在磁盘上,则为 True。如果已经下载,可以设置download=False;
- transform — 加载时对数据集元素应用哪些转换;
- transforms.ToTensor() 将所有图像转换为“张量”类型。
train_data
接下来,您需要向数据集的两个部分添加数据加载器。数据加载器是一种协调将数据集分成批次的结构。我们将在网络训练代码中使用它。
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=False)
这里:
- batch_size — 批次大小;
- shuffle — 如果您需要在每个时期之前将数据集分成批次之前进行打乱,则为 True,否则为 False。对于训练集,shuffle=True 应该始终为真!
网络构建
我们将建立一个完全连接的神经网络来解决将图像分为 10 类的问题。要做到这一点,您需要了解如何将图像输入到神经网络的输入。
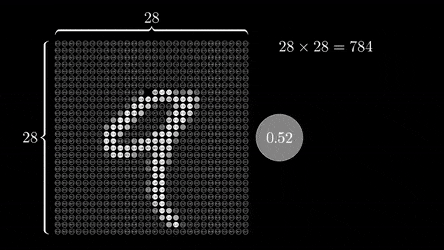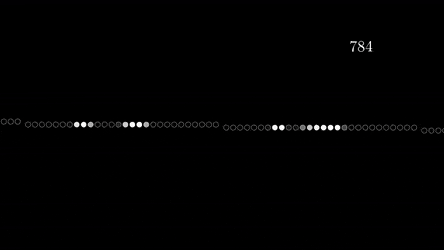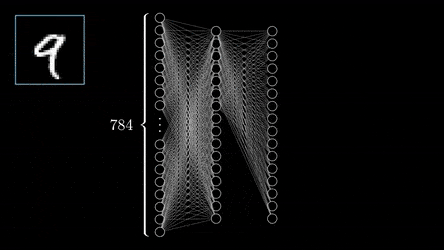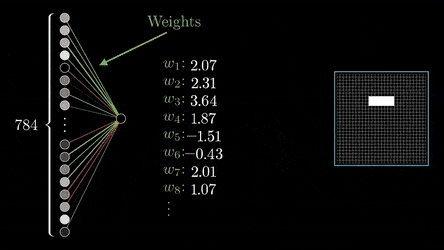
事实上,这很容易做到。每张黑白图片都是一个二维数字矩阵。在我们的数据集中,图像的分辨率为 28x28,因此 MNIST 的每个图像都表示为 28x28 的数字矩阵。
为了将图像输入神经网络,我们将二维矩阵拉伸为一维向量。我们将矩阵的所有行连接成一个大小为 28*28 = 784 的长向量。结果是每张图片将由一个大小为 784 的向量表示。该向量可以被视为图片特征的向量。
那么,在解决 MNIST 图像分类问题的神经网络中,输入层应该正好有 784 个神经元。输出为 - 10,因为我们的问题中有 10 个类。中间层的数量以及每个中间层的神经元的数量可以是任意的。
让我们建立一个神经网络:
# 定义神经网络层的模块
import torch.nn as nn
# 定义神经网络层激活的模块
import torch.nn.functional as F
class SimpleNet(nn.Module):def __init__(self):super().__init__()self.flatten = torch.nn.Flatten()self.fc_in = nn.Linear(28*28, 256)self.fc_out = nn.Linear(256, 10)def forward(self, x):# 前向传递网络# 将输入对象从图像转换为矢量x = self.flatten(x)# 乘以第 1 层的权重矩阵并应用激活函数x = F.relu(self.fc_in(x))# 乘以第 2 层权重矩阵并应用激活函数x = self.fc_out(x)return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
输出:device(type=‘cuda’)
model = SimpleNet().to(device)
训练神经网络
让我们声明损失函数和优化器:
# 损失函数
loss_fn = torch.nn.CrossEntropyLoss()# 优化器
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
最后,我们来编写模型训练函数:
def train(model, loss_fn, optimizer, n_epoch=6):model.train(True)# 网络训练周期for epoch in tqdm(range(n_epoch)):for i, batch in enumerate(tqdm(train_loader)):# 这就是我们获得当前一批图片和对它们的回应的方式X_batch, y_batch = batch# 前向传递(接收一批图像的网络响应)logits = model(X_batch.to(device))# 根据网络给出的答案和批次的正确答案计算损失loss = loss_fn(logits, y_batch.to(device))# 每 50 次迭代我们将显示当前批次的损失if i % 50 == 0:print(loss.item())optimizer.zero_grad() # 我们重置优化器梯度的值loss.backward() # 反向传播(梯度计算)optimizer.step() # 更新网络权重return model
我们训练模型:
model = train(model, loss_fn, optimizer, n_epoch=2)
太好了,模型已经训练好了。让我们在测试样本上测试一下它的质量。为此,我们编写了评估函数:
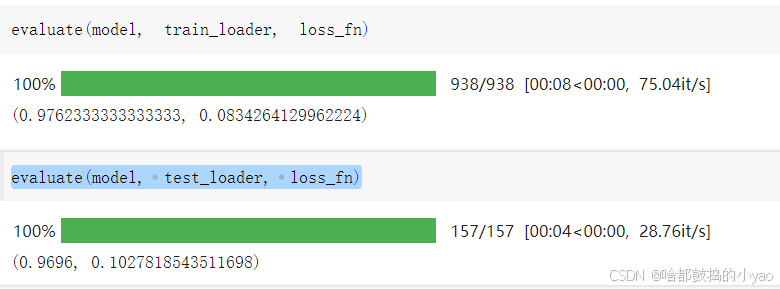
from sklearn.metrics import accuracy_scoredef evaluate(model, dataloader, loss_fn):model.eval()y_pred_list = []y_true_list = []losses = []# 让我们看一下数据加载器批次for i, batch in enumerate(tqdm(dataloader)):# 这就是我们得到当前批次的方法X_batch, y_batch = batch# 关闭任何梯度的计算with torch.no_grad():# 我们收到该批次的网络响应logits = model(X_batch.to(device))# 我们计算批次上的损失函数值loss = loss_fn(logits, y_batch.to(device))loss = loss.item()# 将当前批次的损失保存到数组中losses.append(loss)# 对于我们理解的批次中的每个元素,# 网络将它分配到 0 到 9 中的哪个类别y_pred = torch.argmax(logits, dim=1)# 我们将当前批次的正确答案保存到数组中# 以及对当前批次的网络响应y_pred_list.extend(y_pred.cpu().numpy())y_true_list.extend(y_batch.numpy())# 我们计算网络响应和正确答案之间的准确率accuracy = accuracy_score(y_pred_list, y_true_list)return accuracy, np.mean(losses)
让我们检查一下模型对训练和测试样本的预测质量:
evaluate(model, train_loader, loss_fn)
evaluate(model, test_loader, loss_fn)
我们将训练数据分为 train 和 val:
# 我们将把 80% 的图片纳入训练样本
train_size = int(len(train_data) * 0.8)
# 验证 - 剩余 20%
val_size = len(train_data) - train_sizetrain_data, val_data = torch.utils.data.random_split(train_data, [train_size, val_size])train_data, val_data, test_data
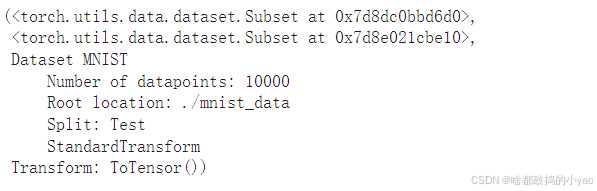
让我们为更新的数据集声明数据加载器:
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
val_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=False)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=False)
让我们添加一些网络训练代码:在每个时期之后插入对训练和验证样本的损失和准确性的检查:
def train(model, loss_fn, optimizer, n_epoch=6):model.train(True)data = {'acc_train': [],'loss_train': [],'acc_val': [],'loss_val': []}# 网络训练周期for epoch in tqdm(range(n_epoch)):for i, batch in enumerate(tqdm(train_loader)):# 这就是我们获得当前一批图片和对它们的回应的方式X_batch, y_batch = batch# 前向传递(接收一批图像的网络响应)logits = model(X_batch.to(device))# 根据网络给出的答案和批次的正确答案计算损失loss = loss_fn(logits, y_batch.to(device))optimizer.zero_grad() # 我们重置优化器梯度的值loss.backward() # 反向传播(梯度计算)optimizer.step() # 更新网络权重# 时代终结,模型验证print('On epoch end', epoch)acc_train_epoch, loss_train_epoch = evaluate(model, train_loader, loss_fn)print('Train acc:', acc_train_epoch, 'Train loss:', loss_train_epoch)acc_val_epoch, loss_val_epoch = evaluate(model, val_loader, loss_fn)print('Val acc:', acc_val_epoch, 'Val loss:', loss_val_epoch)data['acc_train'].append(acc_train_epoch)data['loss_train'].append(loss_train_epoch)data['acc_val'].append(acc_val_epoch)data['loss_val'].append(loss_val_epoch)return model, data
让我们再次创建一个具有随机权重的模型,为其声明一个损失函数和一个优化器:
model = SimpleNet().to(device)# 损失函数
loss_fn = torch.nn.CrossEntropyLoss()# 优化器
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
我们训练模型:
model, data = train(model, loss_fn, optimizer, n_epoch=3)
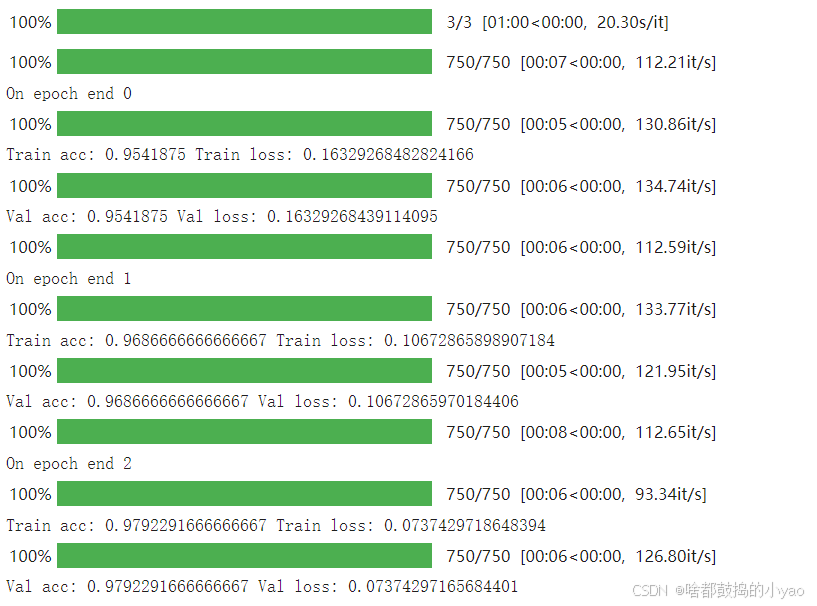
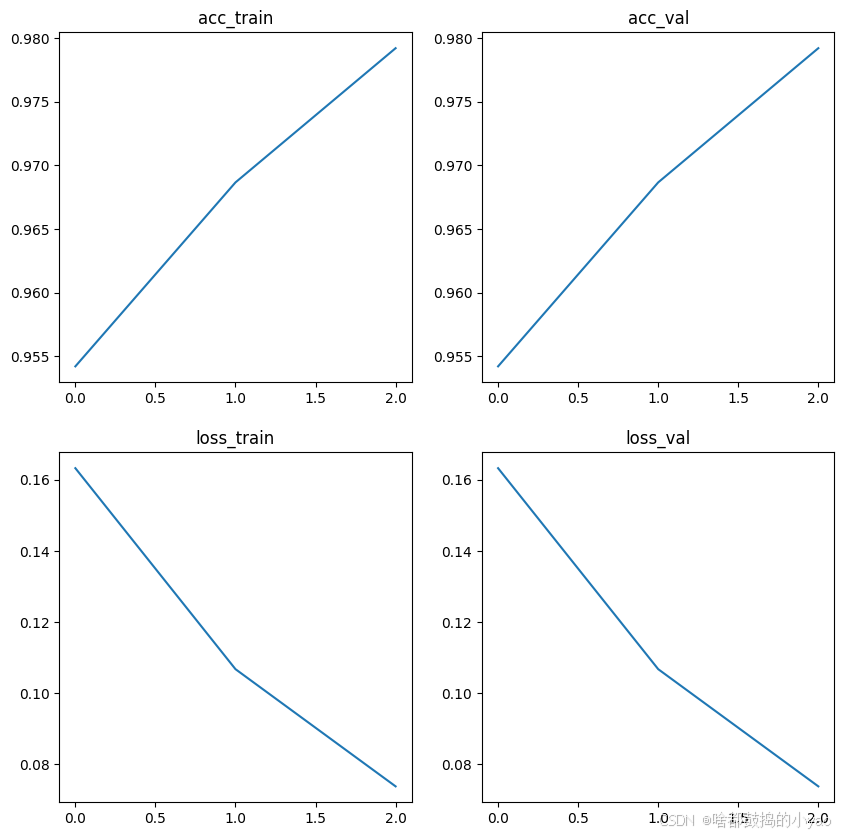
让我们直观地看一下各个时期损失和准确度的变化图:
_, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))ox = list(range(3))axes[0][0].plot(ox, data['acc_train'])
axes[0][0].title.set_text('acc_train')axes[0][1].plot(ox, data['acc_val'])
axes[0][1].title.set_text('acc_val')axes[1][0].plot(ox, data['loss_train'])
axes[1][0].title.set_text('loss_train')axes[1][1].plot(ox, data['loss_val'])
axes[1][1].title.set_text('loss_val')plt.show()
相关文章:
课程3. 分批训练与数据规范、标准化
课程3. 分批训练与数据规范、标准化 理论神经网络的梯度优化反向传播算法 批量训练网络输入的规范化BatchNorm 验证样本实践加载数据集网络构建训练神经网络 课程计划: 1.理论: 批量训练; 输入数据的规范化; 批量标准化ÿ…...

《机器学习数学基础》补充资料:过渡矩阵和坐标变换推导
尽管《机器学习数学基础》这本书,耗费了比较长的时间和精力,怎奈学识有限,错误难免。因此,除了在专门的网页( 勘误和修订 )中发布勘误和修订内容之外,对于重大错误,我还会以专题的形…...

linux指令学习--sudo apt-get install vim
1. 命令分解 部分含义sudo以管理员权限运行命令(需要输入用户密码)。apt-getUbuntu 的包管理工具,用于安装、更新、卸载软件包。installapt-get 的子命令,表示安装软件包。vim要安装的软件包名称(Vim 文本编辑器&…...

类和对象—多态—案例2—制作饮品
案例描述: 制作饮品的大致流程为:煮水-冲泡-倒入杯中-加入辅料 利用多态技术实现本案例,提供抽象制作产品基类,提供子类制作咖啡和茶叶 思路解析: 1. 定义抽象基类 - 创建 AbstractDrinking 抽象类,该类…...

嵌入式产品级-超小尺寸游戏机(从0到1 硬件-软件-外壳)
Ultra-small size gaming console。 超小尺寸游戏机-Pico This embedded product is mainly based on miniaturization, followed by his game functions are also very complete, for all kinds of games can be played, and there will be relevant illustrations in the fo…...

计算机毕业设计Python+Django+Vue3微博数据舆情分析平台 微博用户画像系统 微博舆情可视化(源码+ 文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

前端开发10大框架深度解析
摘要 在现代前端开发中,框架的选择对项目的成功至关重要。本文旨在为开发者提供一份全面的前端框架指南,涵盖 React、Vue.js、Angular、Svelte、Ember.js、Preact、Backbone.js、Next.js、Nuxt.js 和 Gatsby。我们将从 简介、优缺点、适用场景 以及 实际…...

Mybatis 的关联映射(一对一,一对多,多对多)
前言 在前面我们已经了解了,mybatis 的基本用法,动态SQL,学会使用mybatis 来操作数据库。但这些主要操作还是针对 单表实现的。在实际的开发中,对数据库的操作,常常涉及多张表。 因此本篇博客的目标:通过my…...

深度解码!清华大学第六弹《AIGC发展研究3.0版》
在Grok3与GPT-4.5相继发布之际,《AIGC发展研究3.0版》的重磅报告——这份长达200页的行业圣经,不仅预测了2025年AI技术爆发点,更将「天人合一」的东方智慧融入AI伦理建构,堪称数字时代的《道德经》。 文档:清华大学第…...

/dev/console文件详解
/dev/console概览 /dev/console 是 Linux 系统中的一个特殊设备文件,通常用于与系统的控制台进行交互。它的作用和特点如下: 1. 作用 init 进程(PID 1)和某些系统服务在启动时会使用 /dev/console 进行日志输出,以确…...

ProfibusDP主站转ModbusTCP网关如何进行数据互换
ProfibusDP主站转ModbusTCP网关如何进行数据互换 在现代工业自动化领域,通信协议的多样性和复杂性不断增加。Profibus DP作为一种经典的现场总线标准,广泛应用于工业控制网络中;而Modbus TCP作为基于以太网的通信协议,因其简单易…...

springboot3 WebClient
1 介绍 在 Spring 5 之前,如果我们想要调用其他系统提供的 HTTP 服务,通常可以使用 Spring 提供的 RestTemplate 来访问,不过由于 RestTemplate 是 Spring 3 中引入的同步阻塞式 HTTP 客户端,因此存在一定性能瓶颈。根据 Spring 官…...

牛客周赛 Round 83
A.和猫猫一起起舞! 思路:遇到‘U’和‘D’,输出‘R’或者‘L’;遇到‘R’和‘L’,输出‘U’或者‘D’.(这题比较简单) AC代码: void solve() {int n, m, k;char ch;cin >> ch;if (ch U || ch D)…...

硬通货用Deekseek做一个Vue.js组件开发的教程
安装 Node.js 与 Vue CLI npm install -g vue/cli vue create my-vue-project cd my-vue-project npm run serve 通过 Vue CLI 可快速生成项目骨架,默认配置适合新手快速上手 目录结构 src/ ├── components/ # 存放组件文件 │ └── …...

Windows权限维持之利用安全描述符隐藏服务后门进行权限维持(八)
我们先打开cs的服务端 然后我们打开客户端 我们点击连接 然后弹出这个界面 然后我们新建一个监听器 然后我们生成一个beacon 然后把这个复制到目标主机 然后我们双击 运行 然后cs这边就上线了 然后我们把进程结束掉 然后我们再把他删除掉 然后我们创建服务 将后门程序注册…...

Ubuntu20.04双系统安装及软件安装(七):Anaconda3
Ubuntu20.04双系统安装及软件安装(七):Anaconda3 打开Anaconda官网,在右侧处填写邮箱(要真实有效!),然后Submit。会出现如图示的Success界面。 进入填写的邮箱,有一封Ana…...

【极光 Orbit•STC8A-8H】02. STC8 单片机工程模板创建
【极光 Orbit•STC8A-8H】02. STC8 单片机工程模板创建 七绝单片机 小小芯片大乾坤, 集成世界在其中。 初学虽感千重难, 实践方知奥妙通。 今天的讲法和过去不同,直接来一个多文件模块化的工程模板创建,万事开头难,…...

Spring Boot WebFlux 中 WebSocket 生命周期解析
Spring Boot WebFlux 中的 WebSocket 提供了一种高效、异步的方式来处理客户端与服务器之间的双向通信。WebSocket 连接的生命周期包括连接建立、消息传输、连接关闭以及资源清理等过程。此外,为了确保 WebSocket 连接的稳定性和可靠性,我们可以加入重试…...

PostgreSQL中的事务隔离
1. 事务隔离的概念 在数据库管理系统中,事务隔离是一项重要的功能,它能确保在并发访问数据库时事务之间能够独立运行,不会相互干扰。数据库系统通常支持不同级别的事务隔离,用来满足不同应用程序之间的需求。 2. 事务隔离的种类…...

基于Rye的Django项目通过Pyinstaller用Github工作流简单打包
前言 Rye的介绍和安装 Ryehttps://rye.astral.sh/Rye 完整使用教程_安装rye-CSDN博客https://blog.csdn.net/zhenndbc/article/details/144544692 正文 项目建立 配置好环境后 新建文件夹 新建文件夹,进入项目 初始化 rye init下载依赖 rye syncpycharm 打…...

数字孪生交互推演方法
数字孪生交互推演方法(Digital Twin Interactive Deduction Methodology)是用户为中心交互系统工程(UCI-SE)在研发设计、变型设计以及生产预测环节的最高技术形态 。它改变了传统数字孪生“只能看、不能动”的静态看板僵局&#x…...

终极指南:如何用NoFences桌面分区工具提升3倍工作效率
终极指南:如何用NoFences桌面分区工具提升3倍工作效率 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上杂乱无章的图标?每天…...

HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合
HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的游戏体验而烦恼…...

Minimax算法在技能学习中的应用:构建抗风险技术成长路径
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫justl9169/minimax-skills。光看名字,你可能会联想到“最小化-最大化”算法,也就是博弈论里那个经典的Minimax。没错,这个项目的核心灵感确实来源于此,但…...
前,这5个NDR和约束设置没做好,后期时序肯定崩)
ICC II时钟树综合(CTS)前,这5个NDR和约束设置没做好,后期时序肯定崩
ICC II时钟树综合前的5个致命陷阱:NDR与约束设置实战指南 时钟树综合(CTS)是数字后端设计中最关键的阶段之一,而90%的后期时序问题往往源于CTS前的配置疏漏。本文将深入剖析五个最容易被忽视却影响深远的设置环节,结合…...

终极指南:如何使用FlicFlac快速完成Windows音频格式转换
终极指南:如何使用FlicFlac快速完成Windows音频格式转换 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在Windows平台上处理音频文件时&…...

STM32 SPI协议深度解析:从硬件连接到时序模式与实战配置
1. SPI协议:从硬件连接到时序模式的深度解析 搞嵌入式开发,尤其是用STM32这类MCU,SPI(Serial Peripheral Interface)总线是绕不开的一道坎。它不像I2C那样需要上拉电阻和复杂的地址协议,也不像UART那样需要…...

3分钟掌握Joy-Con Toolkit:让你的Switch手柄焕然一新的终极指南
3分钟掌握Joy-Con Toolkit:让你的Switch手柄焕然一新的终极指南 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 还在为单调的Joy-Con手柄配色而烦恼吗?Joy-Con Toolkit为你带来了一键改变…...

终极免费桌面分区工具:NoFences让你的Windows桌面告别杂乱
终极免费桌面分区工具:NoFences让你的Windows桌面告别杂乱 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗࿱…...

终极指南:5步掌握番茄小说下载器的完整使用方案
终极指南:5步掌握番茄小说下载器的完整使用方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,我们常常面临一个共同的问题࿱…...