Pandas的数据转换函数
Pandas的数据转换函数:map, apply, applymap
| 参数 | 描述 |
| map | 只用于Series,实现每个值->值的映射 |
| apply | 用于Series实现每个值的处理,用于DataFrame实现某个轴的Series的处理 |
| applymap | 只能用于DataFrame, 用于处理该DataFrame的每个元素 |
1. map用于Series值的转换
- 将股票代码英文转换成中文名字
- Series.map(dict) or Series.map(function)均可
import pandas as pd
file_path = r'C:\TELCEL_MEXICO_BOT\A\互联网公司股票.xlsx'
stocks = pd.read_excel(file_path)print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00print(stocks['公司'].unique())
['BIDU' 'BABA' 'IQ' 'JD']## 公司股票代码到中文的映射,注意这是小写
dict_company_names = {'bidu':'百度','baba':'阿里巴巴','iq':'爱奇艺','jd':'京东'}
## 方法1: Series.map(dict)
stocks['公司中文'] = stocks['公司'].str.lower().map(dict_company_names)
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅 公司中文
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02 百度
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01 百度
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01 百度
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02 阿里巴巴
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00 阿里巴巴
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01 阿里巴巴
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02 爱奇艺
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01 爱奇艺
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01 爱奇艺
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03 京东
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00 京东
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00 京东## 方法2:Series.map(function), function的参数是Series的每个元素的值
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00dict_company_names = {'bidu':'百度','baba':'阿里巴巴','iq':'爱奇艺','jd':'京东'}
stocks['公司中文2'] = stocks['公司'].map(lambda x:dict_company_names[x.lower()])
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅 公司中文2
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02 百度
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01 百度
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01 百度
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02 阿里巴巴
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00 阿里巴巴
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01 阿里巴巴
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02 爱奇艺
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01 爱奇艺
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01 爱奇艺
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03 京东
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00 京东
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00 京东2. apply用于Series和DataFrame的转换
- Series.apply(function), 函数的参数是每个值
- DataFrame.apply(function),函数的参数是Series
import pandas as pd
import numpy as np
file_path = r'C:\TELCEL_MEXICO_BOT\A\互联网公司股票.xlsx'
stocks = pd.read_excel(file_path)
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00dict_company_names = {'bidu':'百度','baba':'阿里巴巴','iq':'爱奇艺','jd':'京东'}## Series.apply(function)stocks['公司中文3'] = stocks['公司'].apply(lambda x:dict_company_names[x.lower()] )
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅 公司中文3
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02 百度
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01 百度
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01 百度
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02 阿里巴巴
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00 阿里巴巴
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01 阿里巴巴
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02 爱奇艺
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01 爱奇艺
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01 爱奇艺
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03 京东
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00 京东
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00 京东## DataFrame.apply(function)stocks['公司中文4'] = stocks.apply(lambda x:dict_company_names[x['公司'].lower()], axis=1)
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅 公司中文4
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02 百度
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01 百度
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01 百度
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02 阿里巴巴
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00 阿里巴巴
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01 阿里巴巴
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02 爱奇艺
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01 爱奇艺
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01 爱奇艺
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03 京东
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00 京东
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00 京东## 注意在这个代码中
1. apply 是在stocks这个DataFrame上调用
2. lambda x 的 x是一个Series,因为指定了axis=1,所以Series的key是列名,可以用x['公司']获取3. applymap用于DataFrame所有值的转换
import pandas as pdfile_path = r'C:\TELCEL_MEXICO_BOT\A\互联网公司股票.xlsx'
stocks = pd.read_excel(file_path)
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅
0 2019-10-03 BIDU 104.32 102.35 104.73 101.15 2.24 0.02
1 2019-10-02 BIDU 102.62 100.85 103.24 99.50 2.69 0.01
2 2019-10-01 BIDU 102.00 102.80 103.26 101.00 1.78 -0.01
3 2019-10-03 BABA 1169.48 166.65 170.18 165.00 10.39 0.02
4 2019-10-02 BABA 165.77 162.82 166.88 161.90 11.60 0.00
5 2019-10-01 BABA 165.15 168.01 168.23 163.64 14.19 -0.01
6 2019-10-03 IQ 16.06 15.71 16.38 15.32 10.08 0.02
7 2019-10-02 IQ 15.72 15.85 15.87 15.12 8.10 -0.01
8 2019-10-01 IQ 15.92 16.14 16.22 15.50 11.65 -0.01
9 2019-10-03 JD 128.80 28.11 28.97 27.82 8.77 -0.03
10 2019-10-02 JD 128.06 28.00 28.22 27.53 9.53 0.00
11 2019-10-01 JD 28.19 28.22 28.57 27.97 10.64 0.00sub_df = stocks[['收盘', '开盘','高', '低', '交易量']]
print(sub_df)收盘 开盘 高 低 交易量
0 104.32 102.35 104.73 101.15 2.24
1 102.62 100.85 103.24 99.50 2.69
2 102.00 102.80 103.26 101.00 1.78
3 1169.48 166.65 170.18 165.00 10.39
4 165.77 162.82 166.88 161.90 11.60
5 165.15 168.01 168.23 163.64 14.19
6 16.06 15.71 16.38 15.32 10.08
7 15.72 15.85 15.87 15.12 8.10
8 15.92 16.14 16.22 15.50 11.65
9 128.80 28.11 28.97 27.82 8.77
10 128.06 28.00 28.22 27.53 9.53
11 28.19 28.22 28.57 27.97 10.64## 将这些数据取整数,应用于所有元素
print(sub_df.applymap(lambda x:int(x)))收盘 开盘 高 低 交易量
0 104 102 104 101 2
1 102 100 103 99 2
2 102 102 103 101 1
3 1169 166 170 165 10
4 165 162 166 161 11
5 165 168 168 163 14
6 16 15 16 15 10
7 15 15 15 15 8
8 15 16 16 15 11
9 128 28 28 27 8
10 128 28 28 27 9
11 28 28 28 27 10## 直接修改原df的这几列stocks.loc[:,['收盘', '开盘','高', '低', '交易量']] = sub_df.applymap(lambda x:int(x))
print(stocks)日期 公司 收盘 开盘 高 低 交易量 涨跌幅
0 2019-10-03 BIDU 104 102 104 101 2 0.02
1 2019-10-02 BIDU 102 100 103 99 2 0.01
2 2019-10-01 BIDU 102 102 103 101 1 -0.01
3 2019-10-03 BABA 1169 166 170 165 10 0.02
4 2019-10-02 BABA 165 162 166 161 11 0.00
5 2019-10-01 BABA 165 168 168 163 14 -0.01
6 2019-10-03 IQ 16 15 16 15 10 0.02
7 2019-10-02 IQ 15 15 15 15 8 -0.01
8 2019-10-01 IQ 15 16 16 15 11 -0.01
9 2019-10-03 JD 128 28 28 27 8 -0.03
10 2019-10-02 JD 128 28 28 27 9 0.00
11 2019-10-01 JD 28 28 28 27 10 0.00
相关文章:

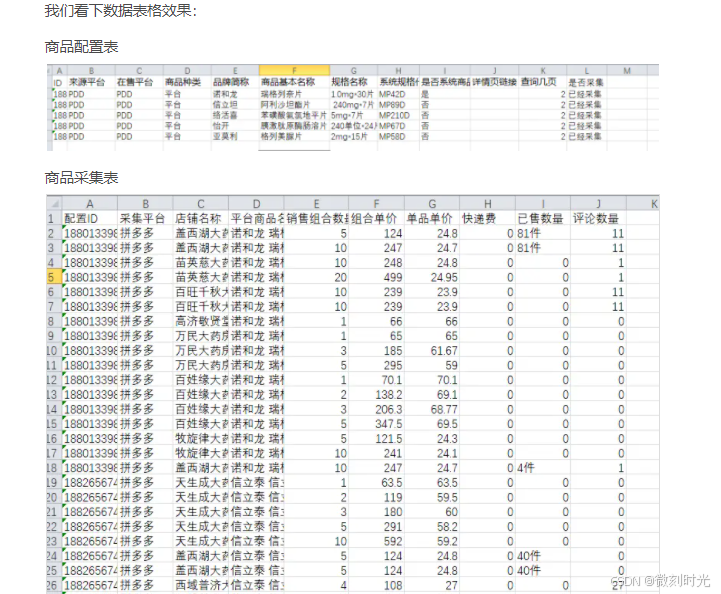
Pandas的数据转换函数
Pandas的数据转换函数:map, apply, applymap 参数描述map只用于Series,实现每个值->值的映射apply用于Series实现每个值的处理,用于DataFrame实现某个轴的Series的处理applymap只能用于DataFrame, 用于处理该DataFrame的每个元素 1. map用于Series值…...
影刀 RPA 实战开发阶段总结
目录 1. 影刀 RPA 官方教程的重要性 1.1系统全面的知识体系 1.2 权威准确的技术指导 1.3 贴合实际的案例教学 1.4高效的学习方法引导 2. 官方视频教程与实战 2.1 官方视频教程:奠定坚实基础 2.2 实战:拓展应用视野 3. 往期实战博文导航 3.1 初级…...

Linux系统上安装kafka
目录 1. 安装Java环境 2. 下载和解压Kafka 3. 配置Kafka 4. 启动ZooKeeper和Kafka 5. 测试Kafka 6. 停止服务 7.常见问题 1. 安装Java环境 Kafka依赖Java运行环境(JDK 8或更高版本): # 安装OpenJDK(推荐) yum…...
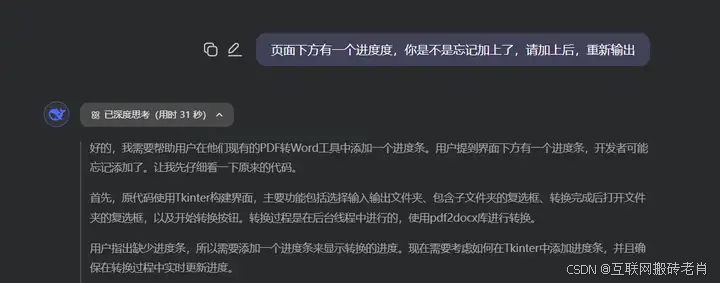
DeepSeek如何快速开发PDF转Word软件
一、引言 如今,在线工具的普及让PDF转Word成为了一个常见需求,常见的PDF转Word工具有收费的WPS,免费的有PDFGear,以及在线工具SmallPDF、iLovePDF、24PDF等。然而,大多数免费在线转换工具存在严重隐私风险——文件需上…...

虚拟机 | Ubuntu图形化系统: open-vm-tools安装失败以及实现文件拖放
系列文章目录 虚拟机 | Ubuntu 安装流程以及界面太小问题解决 文章目录 系列文章目录虚拟机 | Ubuntu 安装流程以及界面太小问题解决 前言一、VMware Tools 和 open-vm-tools 是什么1、VMware Tools2、open-vm-tools 二、推荐使用open-vm-tools(简单)1、…...
-主从同步由于主键问题引发的故障)
Mysql-经典故障案例(1)-主从同步由于主键问题引发的故障
故障报错 Could not execute Write_rows event on table test.users; Duplicate entry 3 for key PRIMARY, Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the events master log mysql-bin.000031, end_log_pos 3297这是由于从库存在与主库相同主键值,…...

Linux下学【MySQL】中如何实现:多表查询(配sql+实操图+案例巩固 通俗易懂版~)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章是MySQL篇中,非常实用性的篇章,相信在实际工作中对于表的查询,很多时候会涉及多表的查询,在多表查询…...
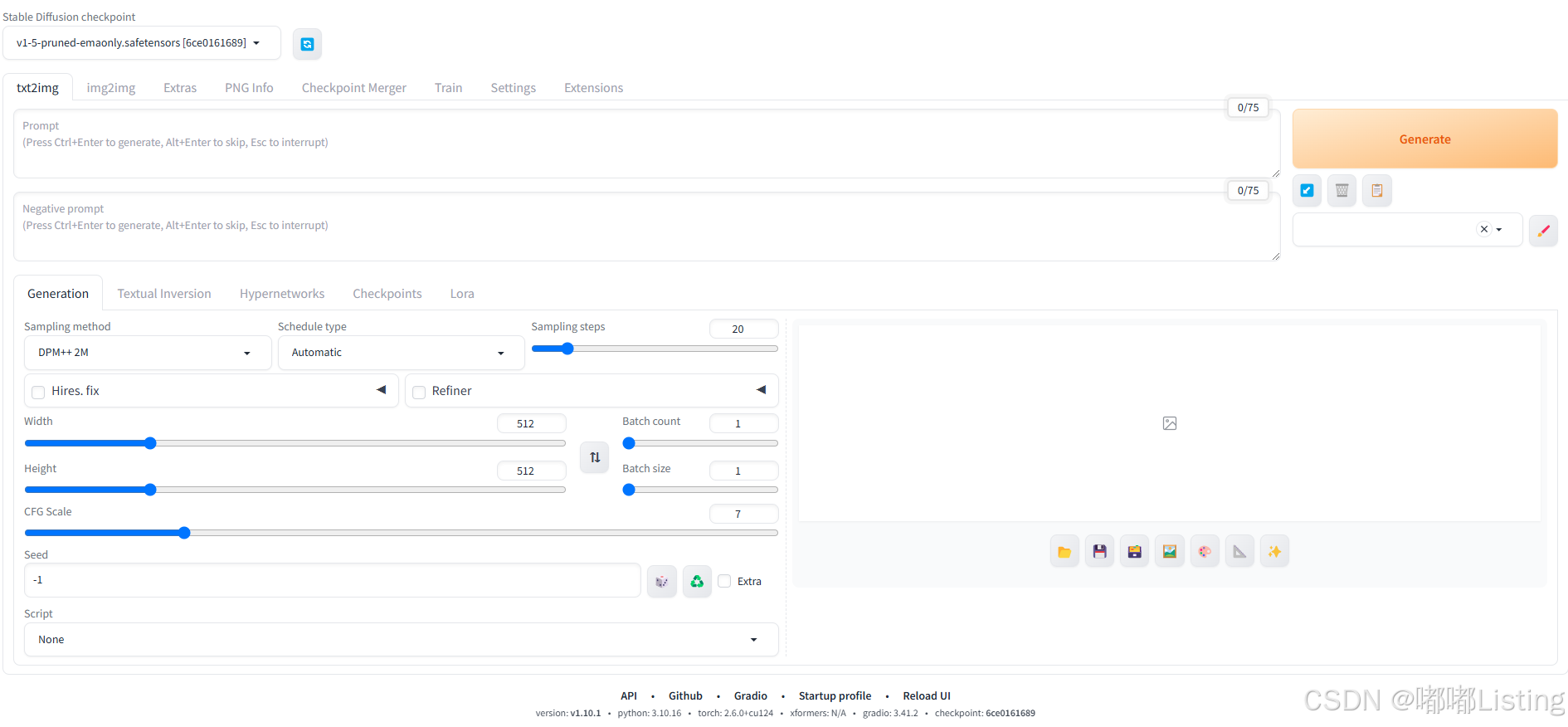
ubuntu局域网部署stable-diffusion-webui记录
需要局域网访问,如下设置: 过程记录查看源码: 查看源码,原来修改参数:--server-name 故启动: ./webui.sh --server-name0.0.0.0 安装下载记录: 快速下载可设置: export HF_ENDPOI…...

最基于底层的运算符——位运算符
位运算符是直接对二进制位(bit)进行操作的运算符,它们在底层开发、算法优化和特定场景(如位掩码、数据压缩)中非常高效。以下是常见位运算符的详解、使用技巧及注意事项: 一、六大核心位运算符 1. 按位与&…...

代码随想录算法训练营第三十二天 | 509. 斐波那契数 70. 爬楼梯 746. 使用最小花费爬楼梯
509. 斐波那契数 力扣题目链接(opens new window) 斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n -…...
)
3-9 WPS JS宏单元格复制、重定位应用(拆分单表到多表)
************************************************************************************************************** 点击进入 -我要自学网-国内领先的专业视频教程学习网站 *******************************************************************************************…...

C++ 中前置 `++` 与后置 `++` 运算符重载
C 中前置 与后置 运算符重载的设计原理与使用规范 1. 为什么后置 返回对象而不是引用? 原因: 后置 需要返回自增前的旧值,但旧值在运算后已被修改。为了保存旧值,必须在函数内部创建一个临时对象(拷贝原对象的状态…...
)
Scala:case class(通俗易懂版)
1. case class 是什么? 想象你要做一个表格,比如学生信息表,每一行需要填:姓名、年龄、成绩。 在代码里,这种“表格的一行”就是一个数据对象,case class 就是帮你快速创建这种“表格行”的工具。 普通方…...

Vue、React、原生小程序的写法对比差异
以下是从 变量、方法、路由、状态管理、父子传值 等多个维度对 Vue、React、原生小程序 的对比表格: 技术对比表格 功能/技术Vue (Options/Composition API)React (Hooks)原生微信小程序变量定义data() { return { count: 0 } }(Options API)const count = ref(0)(Composition…...

【AIGC系列】6:HunyuanVideo视频生成模型部署和代码分析
AIGC系列博文: 【AIGC系列】1:自编码器(AutoEncoder, AE) 【AIGC系列】2:DALLE 2模型介绍(内含扩散模型介绍) 【AIGC系列】3:Stable Diffusion模型原理介绍 【AIGC系列】4࿱…...

java 初学知识点总结
自己总结着玩 1.基本框架 public class HelloWorld{ public static void main(String[] args){ }//类名用大写字母开头 } 2.输入: (1)Scanner:可读取各种类型,字符串相当于cin>>; Scanner anew Scanner(System.in); Scan…...

Android MVC、MVP、MVVM三种架构的介绍和使用。
写在前面:现在随便出去面试Android APP相关的工作,面试官基本上都会提问APP架构相关的问题,用Java、kotlin写APP的话,其实就三种架构MVC、MVP、MVVM,MVC和MVP高度相似,区别不大,MVVM则不同&…...

AI视频领域的DeepSeek—阿里万相2.1图生视频
让我们一同深入探索万相 2.1 ,本文不仅介绍其文生图和文生视频的使用秘籍,还将手把手教你如何利用它实现图生视频。 如下为生成的视频效果(我录制的GIF动图) 如下为输入的图片 目录 1.阿里巴巴全面开源旗下视频生成模型万相2.1模…...

IDEA 2024.1.7 Java EE 无框架配置servlet
1、创建一个目录(文件夹)lib来放置我们的库 2、将tomcat目录下的lib文件夹中的servlet-api.jar文件复制到刚创建的lib文件夹下。 3、把刚才复制到lib下的servlet-api.jar添加为库 4、在src下新建一个package:com.demo,然后创…...

STM32---FreeRTOS中断管理试验
一、实验 实验目的:学会使用FreeRTOS的中断管理 创建两个定时器,一个优先级为4,另一个优先级为6;注意:系统所管理的优先级范围 :5~15 现象:两个定时器每1s,打印一段字符串&#x…...

你的Mac数字管家:Pearcleaner如何让macOS保持“梨子般“的清新体验?
你的Mac数字管家:Pearcleaner如何让macOS保持"梨子般"的清新体验? 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾…...

告别网络瓶颈:手把手教你用K8s RDMA Device Plugin和SR-IOV CNI搭建超低延迟通信栈
云原生时代的超高速通信:基于K8s RDMA与SR-IOV的实战架构设计 当分布式AI训练任务因为网络延迟导致GPU利用率不足50%,当金融高频交易系统因TCP协议栈开销错过最佳套利窗口,传统网络架构已成为性能瓶颈的罪魁祸首。本文将揭示如何通过RDMA&…...

揭秘qmc-decoder:三步解锁QQ音乐加密音频的终极指南
揭秘qmc-decoder:三步解锁QQ音乐加密音频的终极指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了心爱的QQ音乐歌曲,却发现只能在…...

Chrome扩展开发实战:打造浏览器侧边栏ChatGPT助手
1. 项目概述:一个让ChatGPT常驻浏览器侧边栏的利器如果你和我一样,每天的工作和学习都离不开浏览器,并且频繁地与ChatGPT对话来获取灵感、润色文案或者调试代码,那么你肯定对在无数个标签页之间来回切换感到厌烦。每次都要打开一个…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

基于Groq LPU与React技术栈构建极速AI聊天应用实战
1. 项目概述:当极速推理遇上聊天应用最近在折腾AI应用开发的朋友,估计都绕不开一个词:推理速度。模型能力再强,如果生成一句话要等上十几秒,用户体验就无从谈起。正是在这种背景下,我注意到了unclecode/gro…...

Kubernetes原生自动化部署工具Keel:实现容器镜像自动更新的最后一公里
1. 项目概述:什么是Keel,以及它解决了什么问题如果你和我一样,在团队里负责过一段时间的应用部署和更新,那你一定对“发布日”的紧张感深有体会。开发那边代码一提交,这边就得开始手动拉取镜像、更新Kubernetes的Deplo…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...