【Azure 架构师学习笔记】- Azure Databricks (15) --Delta Lake 和Data Lake
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Databricks】系列。
接上文 【Azure 架构师学习笔记】- Azure Databricks (14) – 搭建Medallion Architecture part 2
前言
ADB 除了UC 这个概念之外,前面【Azure 架构师学习笔记】- Azure Databricks (12) – Medallion Architecture简介中也提到了lakehouse, 那么现在再深入一下了解ADB 的lakehouse。同时看看Data Lake和Delta Lake之间的区别与联系。
Data Lake是一个中央存储库,存储和处理原始数据。
Delta Lake则是一个开源的,针对数据存储的“表结构”。对比起Data Lake, 它通过支持ACID,架构演变,数据版本控制等多个特性来提升数据存储中的各种能力。
Data Lake 是一个通用术语,描述了数据存储方法。
Delta Lake 是一种特定的开源技术。数据使用delta lake技术存储在delta 表中。使数据更加安全和高性能。这种技术通常就跟lakehouse架构相关联。
在Delta lake中,如果你的data lake包含了非表格数据, 那么还要把它们存进表中。
Data lake
数据湖是把数据环境类比成一个湖(中央存储),有多条河流(数据流)流入到湖中。这些数据流最终都流到同一个地方,无需严格的预定义结构。它的出现主要是应对数据仓库这种需要预定义架构的存储模式。数据仓库对特定的查询进行了性能优化,意味着以牺牲灵活性为代价提高速度。另外由于不同的供应商有专用数据存储格式,意味着你可能会被供应商“绑架”。
相比数据仓库, 数据湖针对灵活性进行优化,对数据存储没有格式要求,同时也支持不需要复杂昂贵的预处理的数据分析。

数据沼泽
数据湖提供了灵活度和相对低廉的存储价格,各方异构数据都可以简单直接地存储到单一位置。但是当数据不停增长,这样的灵活就可能带来问题,比如文件的版本跟踪,数据架构,数据恢复等。
这种情况将会使得数据湖,退化成数据沼泽。导致下游应用的“数据源”变得不准确或者需要花费大量成本进行清洗才能使用。
Delta Lake
Delta lake 可以运行在已有的data lake 基础架构之上。它把数据以parquet文件格式存储在后台。
从磁盘上看Delta Lake的文件存储将会试一下结构,有文件夹,包含了事务日志,数据的变更记录,delta 表的分区。
your_delta_table/ <-- this is the top-level table directory
_delta_log <-- this is the transaction log which tracks00.json all the changes to your data01.json…n.json
file1.parquet <-- these are your Delta table partitions,
file2.parquet ordered for maximum query performance
…
fileN.parquet
Delta Lake 相对于 Data Lake的优势
- ACID: 跟数据库的ACID 类似, 想象一下当你使用集群向Data Lake写入数据,如果此时集群中途崩溃了,数据文件会以损坏或者只有部分存储到datalake上。你需要手动识别并清理这些残缺文件然后重跑。但是对于Delta lake, 则会把整个写操作回退,而不写入到存储上。
- 性能:Parquet格式文件,在很多大数据应用上都远比其他类型的格式快得多,因为其具有一些如压缩,列存储等特点。同时Delta Lake对其进行了一些改进,使其更加适合lakehouse。
- 文件搜索:在data lake中读取数据需要先列出所有的文件,非常耗时,特别是云环境这种使用Key-value 存储的文件系统。KV 存储在范围扫描过程中速度远不如其他系统,它更适合精确查找。Delta Lake 则通过预先把路径存储到Parquet的事务日志中,减少全量扫描的开销从而加快文件搜索。
- 元数据:在Data Lake的parquet 文件存储每个文件关于列的元数据, 这些元数据包含每个行组内列的最大,最小值,每一次查询范围数据都不得不遍历所有文件。在Delta Lake中,对parquet进行了改进把这些元数据独立存储在单个事务日志文件中,减少扫描的范围和数量。
- 架构演变:由于输入的数据总是在变,你不能总是知道最后数据集的架构,或某种原因你需要增减列。在Delta lake中通过write.option(“mergeSchema”,“true”)的方式来实现即可。
除此之外,还有包括版本控制等优点,就不一一列举。
小结
下一文将介绍一下DataBricks在Delta方面的知识。
相关文章:
【Azure 架构师学习笔记】- Azure Databricks (15) --Delta Lake 和Data Lake
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (14) – 搭建Medallion Architecture part 2 前言 ADB 除了UC 这个概念之外,前面【Azure 架构师学习笔记】- Azure Databricks (1…...

WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中
WPF高级 | WPF 应用程序部署与发布:确保顺利交付到用户手中 一、前言二、部署与发布基础概念2.1 部署的定义与目的2.2 发布的方式与渠道2.3 部署与发布的关键要素 三、WPF 应用程序打包3.1 使用 Visual Studio 自带的打包工具3.2 使用第三方打包工具 四、发布到不同…...

在 IntelliJ IDEA(2024) 中创建 JAR 包步骤
下是在 IntelliJ IDEA 中创建 JAR 包的详细的步骤: 1. 选择File -> Project Structure->Artifacts, (1)点击➕新建,如下图所示: (2)选择JAR->Empty (3)输入jar包名称,确定输出路径 (4&#…...

【C++】5.4.3 范围for语句
范围for语句基本形式: for(声明变量:序列容器) {循环执行语句; } 其中,“序列容器”是指花括号括起来的初始值列表、数组、vector或者string等类型的对象,主要特点是拥有能返回迭代器的 begin() 和 end() 成员; “声明变量”是一个类似声明…...

达梦数据库备份
达梦数据库联机在线备份操作指南 一、基础条件与准备 开启归档模式: 联机备份必须处于归档模式下,否则无法执行。需通过disql工具执行以下操作: alter database mount; alter database ARCHIVELOG; 例子: [dmdbaserver ~]$ cd /op…...

Linux系统基于ARM平台的LVGL移植
软硬件介绍:Ubuntu 20.04 ARM 和(Cortex-A53架构)开发板 基本原理 LVGL图形库是支持使用Linux系统的Framebuffer帧缓冲设备实现的,如果想要实现在ARM开发板上运行LVGL图形库,那么就需要把LVGL图形库提供的关于帧缓冲设…...

C++ 二叉搜索树代码
C 二叉搜索树代码 #include <iostream> using namespace std;template<typename T> struct TreeNode{T val;TreeNode *left;TreeNode *right;TreeNode():val(0), left(NULL), right(NULL){}TreeNode(T x):val(x), left(NULL), right(NULL){} };template<typena…...
DeepSeek+知识库+鸿蒙,助力鸿蒙高效开发
不知道你们发现没有,就是鸿蒙开发官网,文档也太多太多了,对于新手来说确实头疼,开发者大多是极客,程序的目的是让世界更高效!看文档,挺头疼的,毕竟都是理科生。 遇到问题不要慌&…...
蓝桥杯牛客1-10重点(自用)
1 import mathdef lcm(a,b):return a * b // math.gcd(a, b) # math.gcd(a, b)最小公倍数 a,b map(int,input().split()) # a int(input()) # 只读取一个整数 # print(a) print(lcm(a,b)) 2 import os import sysdef fly(lists,n):count 0flag Falsefor i in range(1,n…...

Kafka - 高吞吐量的七项核心设计解析
文章目录 概述一、顺序磁盘I/O (分区顺序追加)1.1 存储架构设计1.2 性能对比实验1.3 存储优化策略 二、零拷贝技术:颠覆传统的数据传输革命2.1 传统模式痛点2.2 Kafka优化方案 三、页缓存机制:操作系统的隐藏加速器3.1 实现原理3.2 优势对比 四、日志索引…...
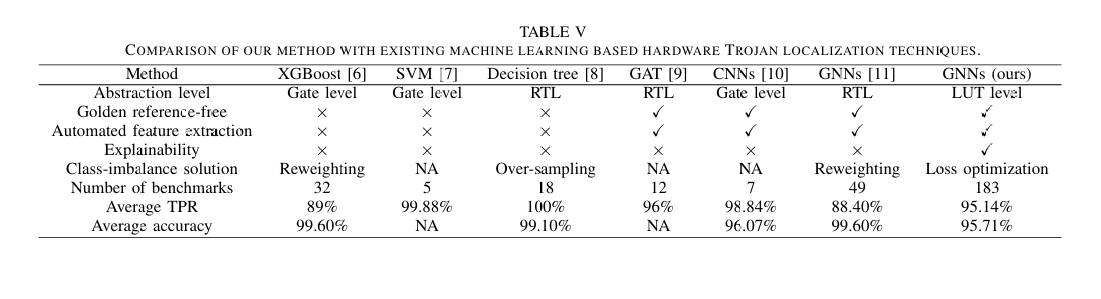
Towards Precise and Explainable Hardware Trojan Localization at LUT Level
文章 《Towards Precise and Explainable Hardware Trojan Localization at LUT Level》 TCAD’2025 《LUT层次的精细可解释木马定位》 期刊介绍 《IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems》(TCAD)是集成电路…...

Python实现鼠标点击获取窗口进程信息
最近遇到挺无解的一个问题:电脑上莫名其妙出现一个白色小方块,点击没有反应,关也关不掉,想知道它和哪个软件有关还是显卡出了问题,也找不到思路,就想着要不获取一下它的进程号看看。 于是写了一个Python脚本…...

Mac安装jdk教程
在Mac上安装JDK(Java Development Kit)的步骤如下: 一、下载JDK安装包 访问Oracle官网: 打开浏览器,访问Oracle JDK下载页面。 选择JDK版本: 根据你的开发需求选择合适的JDK版本。例如,JDK 11…...

【HeadFirst系列之HeadFirst设计模式】第14天之与设计模式相处:真实世界中的设计模式
与设计模式相处:真实世界中的设计模式 设计模式是软件开发中的经典解决方案,它们帮助我们解决常见的设计问题,并提高代码的可维护性和可扩展性。在《Head First设计模式》一书中,作者通过生动的案例和通俗的语言,深入…...

JDBC 完全指南:掌握 Java 数据库交互的核心技术
JDBC 完全指南:掌握 Java 数据库交互的核心技术 一、JDBC 是什么?为什么它如此重要? JDBC(Java Database Connectivity)是 Java 语言中用于连接和操作关系型数据库的标准 API。它允许开发者通过统一的接口访问不同的数…...

Vue父子组件传递笔记
Vue父子组件传递笔记 props 父组件向子组件进行传值 (1)在父组件APP.vue <template><div> <!-- 给子组件Child.vue传递以msg的信号,传递的信息内容为messages --><Child :msg"messages"></Child>…...

文件上传漏洞与phpcms漏洞安全分析
目录 1. 文件上传漏洞简介 2. 文件上传漏洞的危害 3. 文件上传漏洞的触发条件 1. 文件必须能被服务器解析执行 2. 上传目录必须支持代码执行 3. 需要能访问上传的文件 4. 例外情况:非脚本文件也可能被执行 4. 常见的攻击手法 4.1 直接上传恶意文件 4.2 文件…...

【deepseek】辅助思考生物学问题:ICImapping构建遗传图谱gap较大
基于ICImapping构建遗传图谱的常见问题与解答 问题一:染色体两端标记间遗传距离gap较大 答疑一 标记密度不足(如芯片设计时分布不均)重组概率低基因组结构变异软件算法限制 Deepseek的解释 #### 1. **染色体末端的重组率较低** - **现象*…...

linux磁盘非lvm分区
linux磁盘非lvm分区 类似于windows划分C盘、D盘,并且不需要多个磁盘空间合一 图形化直接分区 通过gparted 这个提供直观的图形化分区,类似windows的磁盘管理工具 下载方式: 乌班图/debian系列: sudo apt install gparted红帽…...

Windows下sql server2012安装流程
准备工作 确认系统要求:确保 Windows 系统为 Windows 7 或更高版本,且为 64 位操作系统,CPU 在 2GHz 以上,内存 4GB 或更高。 下载安装包:从微软官方网站或其他可靠渠道下载 SQL Server 2012 安装包。 关闭相关软件&am…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

从零构建Go Web框架:解析the0极简框架的设计原理与实现
1. 项目概述:一个极简主义Web框架的诞生在Web开发的世界里,我们常常面临一个选择:是拥抱功能齐全但略显臃肿的“巨无霸”框架,还是追求极致轻量与灵活的自定义方案?对于许多追求性能、热爱掌控感,或是需要构…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...