Mybatis缓存机制(一级缓存和二级缓存)
前言
为什么要学习Mybatis 缓存机制?
学习Mybatis 缓存机制,可以有效解决 数据库的压力,提高数据库的性能。
例如:你要 对tb_user 表 ,查询 所有用户的信息,并且多次查询所有用户信息。我们知道第一次查询表信息流程是 ,执行 sql 查询语句,找到存储在数据库的目标数据【在硬盘】,最后得到这些数据。那如果第二次查询,我们依旧如此,这般循环往复,如果是存储很多数据的数据库,这样一次查询,耗时是很长的,且会数据库的性能。
思考,当 第一次得到查询数据或者进行其他的操作后,能否把最终的数据临时存储在一个地方。当第二次执行相同的sql 语句时,传递相同的参数,可以直接从这地方获得,不再需要从 数据库进行二次查询。这样不仅节省了时间,还提高了性能。-------Mybatis 缓存机制 的功能
Mybatis一级缓存
一级缓存的功能
一级缓存会将第一次执行SQL语句后查询到的结果存储在缓存中。这些数据会被暂存,以便后续的查询操作可以直接从缓存中读取,而无需再次访问数据库。
- 一级缓存 是SqlSession 级别的缓存。如果同一个SqlSession 对象 多次执行完全相同的sql 语句,在第一次执行完成后, Mybatis 会将查询结果写入一级缓存中,此后如果程序没有执行插入,更新,删除操作,当第二次执行相同的查询语句,Mybatis 会直接 读取一级缓存中的数据,而不用再去数据库查询,从而提高数据库的查询效率。
例子
从 数据表 tb_book 中多次 查询 di=1 的图书信息,使用 一级缓存 。

注意:学习 一级缓存的核心 不仅仅理解 一级缓存是临时存储场所,而且始终与数据库存储的数据保持同步------这里具体表现为数据的一致性
数据一致性的真正含义
数据一致性是指在缓存机制中,缓存中的数据与数据库中的数据始终保持一致。具体来说,这意味着:
-
读取操作:当从缓存中读取数据时,缓存中的数据必须是最新的,与数据库中的数据完全一致。
-
写入操作:当数据库中的数据发生变化时(例如通过
INSERT、UPDATE、DELETE操作),缓存中的数据必须及时更新或失效,以避免读取到过时的数据。
验证 数据的一致性
1 当执行相同的sql 语句时,获得相同的结果
2 存储在 一级缓存的数据,在数据库中也要存在,并且不会轻易被改变
demo(案例:验证 数据的一致性)
目的: 查询 id=1 时,图书信息
项目准备
tb_book 表 和与之对应的 实体类 Book 类
- tb_book 表

- 实体类 Book 类

添加 需要的依赖
- mybatis 框架固定的依赖 + log4j 日志依赖 通过控制台直观看到整个过程
<dependencies><!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.6</version></dependency><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.16</version></dependency><!-- https://mvnrepository.com/artifact/log4j/log4j --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency></dependencies>和log4j 日志依赖配套的log4j.properties 配置文件
# Set root logger level
log4j.rootLogger=DEBUG, stdout# Set the log output format
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%nBookMapper 接口方法
// 根据id查询图书public Book queryBookById(int id);// 更新图书public int updateBook(Book book);正文
BookMapper.xml 映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="fs.mapper.BookMapper">
<!-- 根据id 查询 图书信息--><select id="queryBookById" parameterType="int" resultType="fs.entity.Book">select * from tb_book where id = #{id}</select>
<!-- 根据id 修改--><update id="updateBook" parameterType="fs.entity.Book">update tb_book set price = #{price},author = #{author},bookName = #{bookName} where id = #{id}</update>
</mapper>BookTest 测试类
1 两次查询 id=1 时,图书信息
// 第一次执行Book book = sqlSession.selectOne("queryBookById", 1);System.out.println(book);// 第二次执行 sqlSession.selectOne("queryBookById", 1);Book book1 = sqlSession.selectOne("queryBookById", 1);System.out.println(book1);运行截图

发现
通过运行截图和 代码发现,之后使用同样的sql 语句和传递相同的参数,会从一级缓存中直接获得,不再经过数据库。
2 查询id=1 和第二次 id=2 图书信息
BookTest 测试类

运行截图

发现
即使第二次执行相同的sql 语句,如果传递不同的参数,不能从一级缓存中获得目标结果,只能通过数据库查询
3 第一次执行 id=1 的查询 图书信息 ,第二次执行 修改 id=1 的图书名,第三次查询id=1图书信息
BookTest 测试类
// 第一次执行Book book = sqlSession.selectOne("queryBookById", 1);System.out.println(book);// 第二次更新int update = sqlSession.update("updateBook", new Book(1, "author", "Html基础","67"));sqlSession.commit();// 第二次执行 sqlSession.selectOne("queryBookById", 1);Book book1 = sqlSession.selectOne("queryBookById", 1);System.out.println(book1);sqlSession.close();运行截图

最后我们发现:
一级缓存实质上是在内存开辟一个空间来存储数据的。
一级缓存不需要,我们手动创建或者设置的
Mybatis二级缓存
为什么要学习 Mybatis二级缓存?
学完一级缓存后,发现 在相同的Mapper 映射文件中使用相同的SQL语句,如果sqlSession不同,则两个sqlSession查询数据时,会查询数据两次,这样会降低数据库的查询效率。因此为了解决这个问题 使用 Mybatis二级缓存
Mybatis二级缓存 的优点
二级缓存 是一个跨多个
SqlSession的共享缓存机制,它的作用范围比一级缓存更广泛。二级缓存可以显著提高系统的性能,因为它允许在多个会话之间共享缓存数据,从而减少对数据库的重复查询。
二级缓存的工作原理
查询流程:
当执行查询操作时,MyBatis 首先检查一级缓存。
如果一级缓存中没有找到数据,则检查二级缓存。
如果二级缓存中也没有找到数据,则查询数据库,并将结果存入二级缓存。
更新流程:
当执行数据更新操作(如
INSERT、UPDATE、DELETE)时,MyBatis 会清空相关的一级缓存和二级缓存,以确保数据一致性。
手动打开二级缓存的步骤
1 在主配置文件 mybatis-config .xml 开启二级 缓存的全局配置
<settings>
<!-- 开启日志--><setting name="logImpl" value="LOG4J"/>
<!-- 开启二级缓存--><setting name="cacheEnabled" value="true"/>
</settings>
2 在 Mapper XML 文件中,使用 <cache> 标签配置二级缓存。

二级缓存一般是默认状态,可以实现的功能如下
1 映射文件所有的select 语句将会被缓存
2 映射文件中的所有的insert,update,delete 都会被刷新缓存
3 缓存会使用LRU算法回收
4 没有刷新间隔
5 缓存是可读可写的,但不被共享
以上是默认状态的特性,如果需要调整,可通过cache 元素的属性来实现
配置参数说明:
eviction:缓存回收策略。可选值包括:
FIFO(先进先出)
LRU(最近最少使用)
SOFT(软引用)
WEAK(弱引用)
flushInterval:缓存刷新间隔(毫秒)。默认值为不刷新。
size:缓存的最大存储对象数量。
readOnly:是否只读。如果设置为true,则缓存中的数据被认为是只读的,可以提高性能,但不允许修改。
3 . 实体类实现 Serializable

4 BookTest测试类中 两次查询 id=1 的图书信息
package fs.Test;import fs.entity.Book;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;import java.io.IOException;
import java.io.InputStream;public class BookTest {public static void main(String[] args) throws IOException {InputStream resource = Resources.getResourceAsStream("mybatis-confif.xml");SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resource);SqlSession sqlSession = build.openSession();SqlSession sqlSession1 = build.openSession();// 第一次执行Book book = sqlSession.selectOne("queryBookById", 3);System.out.println(book);sqlSession.close();// 第二次执行Book book1 = sqlSession1.selectOne("queryBookById", 3);System.out.println(book1);sqlSession1.close();}
}
运行截图

补充
- 缓存命中率
缓存命中率的计算公式
缓存命中率通常通过以下公式计算: 缓存命中率=总查询次数缓存命中次数
缓存命中次数:从缓存中成功获取到数据的次数。
总查询次数:所有查询操作的次数,包括从缓存中获取数据和从数据库中查询数据的次数。
示例
假设你进行了 10 次查询操作:
3 次查询直接从缓存中获取到了数据(缓存命中)。
7 次查询需要从数据库中查询数据(缓存未命中)。
那么缓存命中率为: 缓存命中率=103=0.3 或 30%
MyBatis 中的缓存命中率
在 MyBatis 的日志中,你可以看到类似以下的输出:
DEBUG BookMapper:60 - Cache Hit Ratio [fs.mapper.BookMapper]: 0.0这表示当前的缓存命中率为 0.0,即尚未有缓存命中。
为什么缓存命中率是 0.0?
缓存尚未生效:
如果是第一次查询,缓存尚未填充,因此命中率为 0。
如果二级缓存未正确配置(如实体类未实现
Serializable接口,或<cache>标签未正确设置),缓存可能不会生效。查询条件不匹配:
缓存基于查询语句和参数进行匹配。如果查询语句或参数不同,即使使用了缓存,也可能无法命中。
缓存被清空:
如果在两次查询之间执行了数据更新操作(如
INSERT、UPDATE、DELETE),二级缓存可能会被清空,导致命中率为 0。
相关文章:
Mybatis缓存机制(一级缓存和二级缓存)
前言 为什么要学习Mybatis 缓存机制? 学习Mybatis 缓存机制,可以有效解决 数据库的压力,提高数据库的性能。 例如:你要 对tb_user 表 ,查询 所有用户的信息,并且多次查询所有用户信息。我们知道第一次查询表信息流…...

设计模式--单例模式
一、单例模式代码实现 public class DatabaseConnection {// 1. 私有静态实例变量private static DatabaseConnection instance;// 2. 私有构造函数,防止外部直接创建实例private DatabaseConnection() {// 初始化数据库连接System.out.println("Database con…...

ubuntu22.04本地部署OpenWebUI
一、简介 Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器,如 Ollama 和 OpenAI 兼容的 API,并内置了 RAG 推理引擎,使其成为强大的 AI 部署解决方案。 二、安装 方法 …...
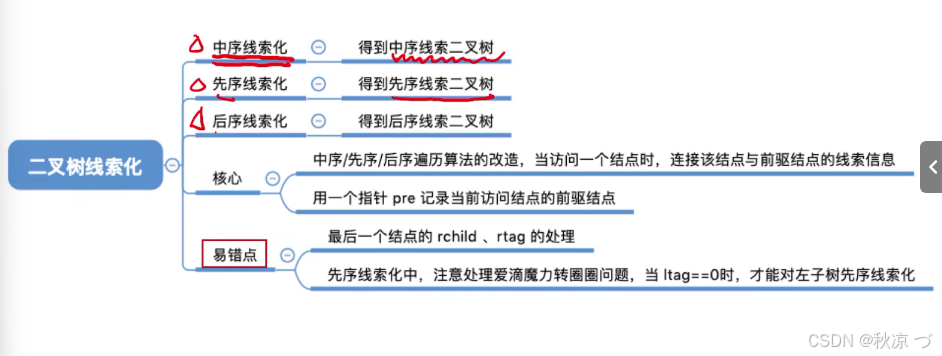
2025-3-7二叉树的线索化
一、中序线索化 代码其实就是和中序遍历相似,增加了两个标志位 ltag rtag。 完整的代码: 二、先序线索化: 三、后序线索化: 总结:其核心其实还是遍历算法的改造。 并且注意处理最后一个被访问的节点。...

以商业思维框架为帆,驭创业浪潮前行
创业者踏入商海,如同航海家奔赴未知海域,需有清晰的思维罗盘指引方向。图中“为什么—用什么—怎么做—何人做—投入产出”的商业框架,正是创业者破解商业谜题的密钥,从需求洞察到落地执行,为创业之路铺就逻辑基石。 …...

海思Hi3516DV300交叉编译opencv
OpenCV是一个开源的跨平台计算机视觉库,支持C、Python等多种语言,适用于图像处理、目标检测、机器学习等任务。其核心由C编写,高效轻量,提供实时视觉处理功能,广泛应用于工业自动化、医疗影像等领域。 1 环境准备 1…...
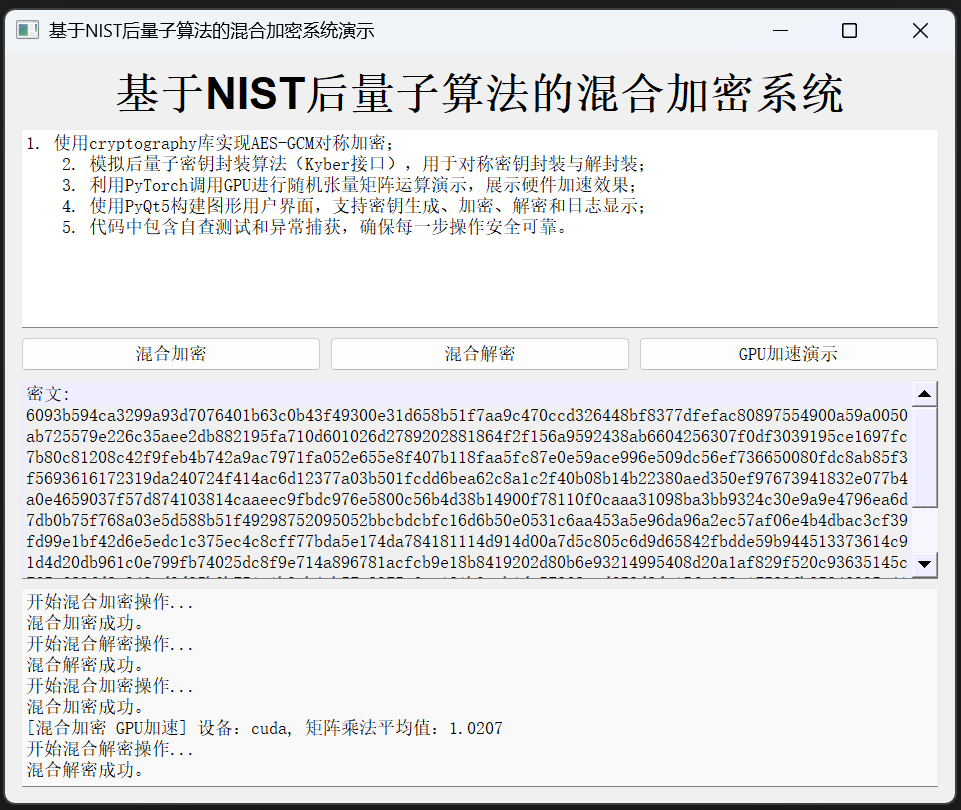
基于NIST后量子算法的混合加密系统
目录 基于NIST后量子算法的混合加密系统一、前言二、后量子密码学概述2.1 后量子密码学的背景2.2 NIST候选后量子算法 三、混合加密系统的设计原理3.1 混合加密的基本思想3.2 数学公式与证明3.3 混合加密系统的优势 四、工程实现与优化策略4.1 算法层面优化4.2 工程实现优化 五…...

uni-app 开发ios 使用testFlight 进行分发测试
一、生成ipa 首先你要生成一个ipa包,怎么生成这个包,可以在uniapp打包安卓和iOS包 二、上传到分发平台 在这里我使用的是Transporter ,当然你也可以看下其他分发平台 在mac电脑app store中下载Transporter,双击打开, 点击添加,将打包好的ipa文件放上去,注意打包的时…...
Node.js入门笔记2---下载安装Node.js
Node.js入门笔记2 Node.js下载并安装的步骤1.Node.js 环境的安装2. 区分 LTS 版本和 Current 版本的不同3.项目node管理版本工具4.Node.js 包管理工具5.MSI与ZIP文件格式的主要区别6. 选择好上面的内容,点击下载mis7. 环境配置 Node.js下载并安装的步骤 1.Node.js …...

基于微信小程序的超市购物系统+论文源码调试讲解
4 系统设计 超市购物系统的设计方案比如功能框架的设计,比如数据库的设计的好坏也就决定了该系统在开发层面是否高效,以及在系统维护层面是否容易维护和升级,因为在系统实现阶段是需要考虑用户的所有需求,要是在设计阶段没有经过…...

OpenCV视频解码实战指南
硬核解析OpenCV视频处理底层原理,从零实现高效视频解码流水线!附赠FFmpeg调优参数和异常帧处理方案,建议收藏备用。 📺 视频解码核心原理 视频容器 vs 编码格式 类型常见格式特点容器格式MP4/MKV/AVI/MOV存储封装格式࿰…...

Python的那些事第四十三篇:功能强大的测试框架pytest
pytest:功能强大的测试框架 摘要 本文旨在深入探讨 pytest 这一功能强大的测试框架。pytest 具有简单易用、功能丰富等特点,支持分布式测试、自动化测试用例发现等功能。本文将从 pytest 的基本概念、主要功能、使用方法等多个方面进行详细阐述,并通过具体的代码示例和表格…...
--前端性能优化(下))
工程化与框架系列(23)--前端性能优化(下)
前端性能优化(用户体验) 🎨 引言 用户体验(UX)性能优化是前端性能优化的重要组成部分。本文将探讨如何通过优化用户体验相关的性能指标,提升用户对应用的满意度,包括感知性能、交互响应、视觉…...

使用 Elasticsearch 进行集成测试初始化数据时的注意事项
作者:来自 Elastic piotrprz 在创建应该使用 Elasticsearch 进行搜索、数据聚合或 BM25/vector/search 的软件时,创建至少少量的集成测试至关重要。虽然 “模拟索引” 看起来很诱人,因为测试甚至可以在几分之一秒内运行,但它们实际…...

自然语言模型(NLP)介绍
一、自然语言模型概述 自然语言模型(NLP)通过模拟人类语言理解和生成能力,已成为人工智能领域的核心技术。近年来,以DeepSeek、GPT-4、Claude等为代表的模型在技术突破和应用场景上展现出显著优势。例如,DeepSeek通过…...

解决:Word 保存文档失败,重启电脑后,Word 在试图打开文件时遇到错误
杀千刀的微软,设计的 Word 是个几把,用 LaTex 写完公式,然后保存,卡的飞起 我看文档卡了很久,就关闭文档,然后 TMD 脑抽了重启电脑 重启之后,文档打不开了,显示 杀千刀的ÿ…...

Android进程间通信方式之AIDL
Android 进程间通信(IPC)有多种方式,其中 AIDL(Android Interface Definition Language) 是最常用的一种,特别适用于 客户端-服务端(Client-Server)模型,当多个应用或进程…...

基于MD5分块哈希的前端图片重复检测方案
一、需求背景 在Web应用中处理用户图片上传时,我们需要解决两个核心问题: 避免重复文件占用存储空间 提升上传效率减少带宽消耗 传统方案直接上传后校验,存在以下缺陷: 重复文件仍然消耗上传时间 服务器重复校验增加计算压力…...

【每日学点HarmonyOS Next知识】Web Header更新、状态变量嵌套问题、自定义弹窗、stack圆角、Flex换行问题
【每日学点HarmonyOS Next知识】Web Header更新、状态变量嵌套问题、自定义弹窗、stack圆角、Flex换行问题 1、HarmonyOS 有关webview Header无法更新的问题? 业务A页面 打开 webivew B页面,第一次打开带了header请求,然后退出webview B页面…...

胜软科技冲刺北交所一年多转港股:由盈转亏,毛利率大幅下滑
《港湾商业观察》施子夫 近期,山东胜软科技股份有限公司(以下简称,胜软科技)递表港交所获受理,独家保荐机构为广发证券(香港)。 在赴港上市之前,胜软科技还曾谋求过A股上市&#x…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

第07章 FastMCP 把检索封装成 Agent 工具
第07章 FastMCP 把检索封装成 Agent 工具 工单知识库已经能在 Python 进程内被普通函数调用,但要让外部 Agent、Web 后端或其他语言的客户端使用这份能力,函数级别的接口不够:缺少协议、缺少描述、缺少跨进程通讯。MCP(Model Cont…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

基于Rust的网页正文提取工具web-reader:从原理到自动化实践
1. 项目概述:一个为现代阅读场景而生的开源利器最近在折腾个人知识库和稍后读工具链,发现市面上的网页内容抓取工具要么太重,要么太“脏”——抓下来的内容常常带着一堆广告、导航栏,甚至还有烦人的弹窗代码。直到我遇到了Cat-tj/…...

ElevenLabs希伯来文语音合成:从API调用失败到99.2%自然度达标的7步生产级优化流程
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs希伯来文语音合成:从API调用失败到99.2%自然度达标的7步生产级优化流程 ElevenLabs 官方虽未明确标注希伯来语(he-IL)为“fully supported”,但…...
)
紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案)
更多请点击: https://intelliparadigm.com 第一章:紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案) MidJourney v6.1 引入的 --style raw 参数并非简单降低美学修饰,而是…...