如何在语言模型的参数中封装知识?——以T5模型为例
【摘要】
这篇论文探讨了大型语言模型在无需外部知识的情况下,能否通过预训练来存储和检索知识以回答开放领域的问题。作者通过微调预训练模型来回答问题,而这些模型在训练时并未提供任何额外的知识或上下文。这种方法随着模型规模的增加而表现出良好的扩展性,并在某些任务上达到了与使用外部知识源的开放领域系统相当的性能。
论文的主要贡献包括:
- 研究了大语言模型在开放领域问答任务上的表现,特别是这些模型是否能够存储和检索足够的知识以回答问题。
- 通过使用预训练的T5模型进行实验,展示了模型规模与知识存储能力之间的关系。
- 探讨了模型参数中存储知识的能力,以及这种能力是否能随着模型复杂性的增加而增加。
- 分享了代码和训练好的模型,以便其他研究人员能够复制实验结果。
实验展示了在不同规模的预训练模型上进行微调的结果,发现较大的模型在开放领域问答任务上表现更好。此外,使用“显著短语掩码”(SSM)预训练目标可以显著提高模型的性能。尽管模型能够回答复杂的问题,但它们在处理多义或上下文依赖性更强的问题时表现不如使用外部知识源的方法。
论文还通过对人进行的评估,发现模型在某些情况下可能会错过正确答案,这可能是由于答案的细微差别、缺失的正确答案或者需要特定上下文的问题。作者还讨论了未来工作的方向,包括更有效的语言模型设计、解释性模型以及需要推理能力的复杂任务。
总的来说,这篇论文展示了大语言模型在开放领域知识存储和检索方面的能力,并提出了未来研究的方向。
【数据来源】
本文的主要数据来源包括以下几个方面:
-
预训练数据:主要使用了C4数据集,这是一个包含大量非结构化网页内容的大规模多样化数据集。此外,还尝试了在英语维基百科上进行预训练,使用与T5相同的目标(无监督“片段替换”)进行进一步训练,但结果未见明显改善。
-
实验数据集:
- Natural Questions:一个来自网络查询的问题数据集,每个问题都可以被标注为不可回答、简短答案或二元答案。问题验证集可以被多次标注,有些问题有多个答案。
- WebQuestions:一个从网络查询中提取的问题数据集,匹配到免费基(FreeBase)中的相应条目。
- TriviaQA:一个来自问答竞赛网站的问题集合,每个问题都附有包含答案的网页和维基百科搜索结果。
-
模型预训练和微调:使用了T5系列模型的不同版本,包括T5-Base、T5-Large、T5-3B和T5-11B,以及T5.1.1系列模型,通过调整模型大小来测试其性能。
-
评估方法:在验证集上进行模型评估,使用精确匹配(Exact Match)作为评估指标。对于无法回答的问题,从验证集中移除并重新计算模型的准确率。
-
附加实验:
- 进一步预训练:尝试在维基百科上进行进一步预训练,使用片段替换和显著片段掩蔽等技术。
- 多种任务微调:尝试同时对多种问答任务进行微调,但发现效果并不明显提升。
- 随机采样答案:在开放域Natural Questions中,仅对第一个标注的答案进行训练,实验结果显示随机采样答案对性能无显著影响。
综上所述,本文利用预训练的大型语言模型在不提供外部知识的情况下,对开放域问答任务进行微调,并通过不同规模的模型测试其性能,验证了模型在回答开放域问题时的能力。
【模型架构】
该论文主要研究了预训练的语言模型在不利用外部知识的情况下回答开放域问题的能力。论文提出了一个名为T5的模型架构,并通过实验展示了模型大小对性能的影响。以下是模型架构的总结:
-
模型架构(T5):
- T5是一个基于Transformer的模型,被训练用于填充文本中缺失的部分(用
<M>表示)。 - T5在大规模未结构化文本数据上进行预训练,学习如何在没有外部知识的情况下回答问题。
- 通过调整模型大小(从Base到11B),研究模型性能随参数数量增加的变化。
- T5是一个基于Transformer的模型,被训练用于填充文本中缺失的部分(用
-
预训练过程:
- T5模型首先在C4数据集上进行多任务预训练,包括未监督的“片段填充”任务、监督翻译、摘要、分类和阅读理解任务。
- 为评估不同大小模型的表现,进行了Base(2.2亿参数)、Large(7.7亿参数)、3B(3亿参数)和11B(11亿参数)版本的实验。
- 使用Salient Span Masking (SSM)技术进一步预训练,特别针对包含实体或日期的片段进行掩码,以增强模型在世界知识方面的理解能力。
-
微调过程:
- 通过在不同数据集(如Natural Questions、WebQuestions和TriviaQA)上的微调来评估模型性能。
- 使用AdaFactor优化器,设置学习率为0.001,使用10%的dropout率和196,608个token的批量大小。
- 对于WebQuestions,由于数据较小,调整了批量大小和dropout率。
-
实验结果:
- 随着模型参数量的增加,T5模型在开放域问题上的表现逐渐提高,尤其是在11B和11B + SSM模型上表现最佳。
- 使用SSM进行额外预训练显著提高了性能,特别是在WebQuestions和TriviaQA上取得了最先进的结果。
-
结论:
- 大型预训练语言模型可以在没有外部知识的情况下取得竞争性的开放域问答性能。
- 这表明设计问答系统时可以采用不同的方法,模型越大,存储的知识越多,回答问题的能力越强。
- 需要更高效的模型设计,并进一步研究如何确保模型在预训练过程中获得特定知识以及如何更新或删除预训练模型中的知识。
总结来说,该模型架构通过预训练和微调过程展示了语言模型在开放域问答任务中的潜力,特别是通过增加模型规模来提升性能。
【创新点】
该论文的创新点主要包括:
-
大型语言模型的知识存储能力:研究表明,通过预训练的大规模语言模型可以在不依赖外部知识库的情况下,回答开放领域的问答任务,表现出色。这表明这些模型能够隐式地存储和检索大量的知识。
-
参数规模的扩展性:实验表明,随着模型规模的增加,其知识检索能力也随之增强。最强大的模型(约110亿参数)在多个开放领域问答任务中表现出最佳效果。
-
知识存储的不可解释性:与需要从外部知识库检索信息的模型不同,这些大型语言模型是通过预训练将知识存储在其参数中,这种存储方式是不可解释的。当模型不确定时,它会生成看起来合理但实际上是虚构的答案。
-
开放领域问题回答的新方法:这为设计问答系统提供了一种新的方法,即模型无需访问外部知识库即可回答问题。这种方法在资源受限的环境中可能过于昂贵,因此需要开发更高效的模型。
-
增强的鲁棒性:通过使用极大似然估计目标进行模型训练,虽然可以预训练模型学习特定的事实,但无法保证模型总是学习到所需的知识,这使得难以确保模型在预训练过程中获得特定知识。
-
改进的数据集和评估方法:引入了新的数据集(如Natural Questions)和评估方法,以更准确地评估模型在开放领域问答任务中的表现。通过手动评估,发现当前评估方法可能低估了封闭式问答系统的性能。
这些创新点展示了大型语言模型在开放领域问答任务上的潜力,以及这种方法在未来研究中的应用前景。
【应用场景】
论文《How Much Knowledge Can You Pack Into the Parameters of a Language Model?》探讨了语言模型在没有外部知识的情况下,通过预训练来存储和检索知识的有效性。具体应用场景如下:
1. 应用场景概述
- 开放域问答(Open-domain Question Answering,简称ODQA):模型在没有外部知识源的情况下,直接从其参数中检索知识以回答自然语言查询。
- 零样本提问:模型能够在没有任何上下文信息的情况下回答问题,就像学生在闭卷考试中需要独立回忆和应用已学知识。
2. 主要技术及其应用场景
- T5模型:T5是一种预训练的文本到文本变换器模型,用于生成自然语言文本。在本研究中,T5被用来预训练以填充文档中的缺失文本跨度(denoted by ),并通过微调来回答问题。
- 预训练和微调(Pre-training and Fine-tuning):模型首先在大规模的未标记文本上进行预训练,学习到一定的知识库,然后通过微调来解决特定任务,如开放域问答。
- 参数掩码预训练(Salient Span Masking Pre-training):通过掩码关键实体或日期等关键短语,进一步增强模型在开放域问答任务上的表现。
3. 应用场景的具体描述
- 自然问题(Natural Questions):模型被用来回答从网络查询中提取的问题,这些问题可能没有明确的答案,模型需要从其内部存储的知识中提取信息。
- 维基百科问答(TriviaQA):模型从维基百科文章中获取信息,回答与维基百科相关的开放域问答问题。
- 网络问题(WebQuestions):模型从网页查询中提取信息,回答与网站内容相关的开放域问答问题。
4. 实验和结果
- 数据集:研究使用了多个开放域问答数据集,包括自然问题、维基百科问题和TrivaQA。
- 模型大小的影响:模型大小的增加提高了其在开放域问答任务上的性能,尤其是在使用大量参数的模型上表现更佳。
- 参数掩码预训练的效果:使用参数掩码预训练的方法显著提高了模型在开放域问答任务上的表现。
- 闭卷问答:模型在没有外部知识的情况下表现良好,类似于学生在闭卷考试中需要独立回忆和应用已学知识。
5. 结论
- 知识存储与检索:大型语言模型可以通过预训练隐式地存储大量知识,而无需外部知识源。
- 未来工作方向:研究指出未来工作的几个方向,包括更高效的语言模型设计、更具解释性的模型以及更复杂推理能力的评估。
- 人类评估:研究还通过人类评估验证了模型在闭卷问答任务上的表现,揭示了模型在某些情况下仍存在局限性。
这些应用展示了大型语言模型在开放域问答任务中的潜力,同时也指出了未来研究的方向。
【未来展望】
技术未来展望:How Much Knowledge Can You Pack Into the Parameters of a Language Model?
摘要
近年来,预训练的神经语言模型在未标记文本上训练后,能够隐式地存储和检索知识,使用自然语言查询。本文通过微调预训练模型来回答问题,而无需任何外部上下文或知识,来测量这一方法的实际使用价值。结果显示,该方法随着模型规模的增加而扩展,并在回答问题时与从外部知识源显式检索答案的开放式系统竞争。为了促进可重现性和未来工作,我们发布了代码和训练模型。本文研究了大型语言模型通过预训练存储和检索知识的能力。
1. 引言
大型、深度神经语言模型在未经标记文本上预训练后,在下游自然语言处理(NLP)任务上表现出极高的性能。有趣的是,这些模型在预训练后还能内化一种隐式的“知识库”。这在两个方面具有潜在用处:1) 知识是通过预训练在大量未标记文本数据上积累的,这些数据在网络上广泛可用;2) 可以使用自然语言查询检索信息,因为这些预训练的语言模型在自然语言理解任务上表现出色。
本文通过微调模型来回答问题,而不需要任何外部知识或上下文,来评估语言模型在开放式领域问答任务上的能力。这种方法要求模型解析自然语言查询,并在其参数中“查找”信息。以往关于“语言模型作为知识库”的工作通常通过合成任务来理解模型中存储的信息范围或评估推理能力。本文采用不同的方法,通过评估语言模型在开放式领域问答任务上的能力,来研究模型规模对知识检索能力的影响。
2. 背景
问答任务
训练模型以选择或输出给定问题的正确答案的任务称为“问答”。最流行的变体是为模型提供一些包含答案的“上下文”(例如,从维基百科文章中获取的段落)以及问题。模型可以被训练以指示包含答案的上下文段落,或者直接输出答案文本。这种格式可以被视为阅读一些文本并回答关于它的问题,因此被称为“阅读理解”。
更困难的变体是“开放式领域问答”,模型可以被问到任意上下文无关的问题(例如,知名事实或历史细节)。通常假设模型在回答问题时可以访问外部知识库(例如,结构化的知识库或未结构化的文本库),但不会给模型提供关于答案出现的具体位置的信息。阅读理解可以被视为一种简化版本的开放式领域问答,模型可以提供“Oracle”上下文来回答问题。开放式领域问答系统可以被视为类似开放书考试,可以找到并在外部知识源中使用信息。
3. 实验
数据集
本文考虑了以下开放式领域问答数据集:
- Natural Questions:包含从网络查询中提取的问题及其对应的维基百科文章。
- WebQuestions:从网络查询匹配到FreeBase中的对应条目。
- TriviaQA:来自问答网站的问题集合,每个问题配有网页搜索结果,可能包含答案。
本文仅使用每个数据集的问题,而不考虑为每个问题提供的匹配文档。对于WebQuestions和TriviaQA,遵循标准评估程序,将预测答案与标准答案进行比较。对于Natural Questions,使用两种评估方法:一种是标准的“开放式领域”版本,模型仅需生成一个归一化答案;另一种是标准的多答案版本,用于阅读理解系统。
训练
本文使用Raffel等人提供的预训练模型——“Text-to-Text Transfer Transformer”(T5)。T5模型在包含未监督“跨度破坏”任务的多任务混合数据集(C4)上进行了预训练,还包括翻译、总结、分类和阅读理解等任务。T5模型在预训练过程中接触到了问答数据集,因此报告了“T5.1.1”检查点的性能。对于T5模型的微调,遵循Raffel等人(2019)的方法,使用AdaFactor优化器,设置常数学习率为0.001,10%的dropout率和196,608个令牌的批量大小。对于WebQuestions,由于其规模较小,将批量大小减半,dropout率加倍。对于T5.1.1检查点,使用相同的程序,但所有三个数据集的dropout率设置为5%。
4. 结论
本文展示了大型语言模型通过预训练在未标记文本上,能够在没有外部知识的情况下,达到开放式领域问答基准的竞争力结果。这表明设计问答系统的不同方法,引发了未来工作的多个方向:1) 我们仅用最大的模型(约110亿参数)获得了最先进的结果。这种模型规模在资源受限的环境中可能过于昂贵,需要更高效的语言模型。2) “开放式领域”模型通常在回答问题时会提供关于访问了哪些信息的指示。这可以提供有用的可解释性。相比之下,我们的模型以不可解释的方式分布在参数中存储知识,并在不确定时生成看起来真实的答案。3) 用于训练模型的最大似然目标不能保证模型会学习到特定的事实。这使得确保模型在预训练过程中获得特定知识变得困难,并且无法明确更新或从预训练模型中删除知识。4) 本文使用的任务主要测量“琐碎”型知识。因此,我们对需要推理能力(如DROP)的问答任务感兴趣。
未来展望
随着模型规模的增加,语言模型能够存储和检索更多知识的能力得到了验证。虽然目前的模型在开放式问答任务上表现良好,但未来的研究可以探索如何更高效地训练和使用这些模型。此外,如何理解和改进模型的推理能力也是未来研究的重点。未来的工作可以进一步研究如何在更复杂的数据集上应用这些模型,以及如何使这些模型更好地适应不同的应用需求。未来的研究还可以探索如何通过更好的训练策略和模型架构来提高模型的性能。
总之,本文的工作展示了大型语言模型在开放式领域问答任务上的潜力,为进一步的研究和应用奠定了基础。未来的研究将继续探索如何更好地利用这些模型的能力,以应对更复杂和多样的任务。
【附录】
为了实现论文中提到的关键技术,我们可以使用T5模型来填充文档中的缺失部分。以下是一个简化的伪代码实现,用于说明如何训练和微调T5模型来完成开放域问答任务。
伪代码实现
# 1. 准备数据集
# - 选择开放域问题回答数据集,如Natural Questions, WebQuestions, TriviaQA
# - 对数据集进行预处理,提取问题和答案# 2. 加载预训练的T5模型
model = T5.load_pretrained_model("t5-base") # 可以选择不同大小的T5模型# 3. 配置训练参数
# - 学习率
learning_rate = 0.001
# - 优化器
optimizer = Adam(learning_rate=learning_rate)
# - 预处理和后处理函数
preprocess_fn = lambda text: text.replace("<M>", "[MASK]") # 替换缺失部分
postprocess_fn = lambda text: text.replace("[MASK]", "<M>") # 恢复缺失部分
# - 批量大小
batch_size = 196608 # 以词为单位# 4. 训练模型
for epoch in range(epochs):for batch in DataLoader(dataset, batch_size=batch_size, shuffle=True):# 4.1 前向传播outputs = model(batch, return_dict=True)loss = outputs.loss# 4.2 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 4.3 后处理和验证if epoch % validation_interval == 0:# 验证模型在验证集上的性能validate(model, validation_dataset, preprocess_fn, postprocess_fn)
详细说明
-
数据集准备:
- 选择开放域问题回答数据集,如Natural Questions, WebQuestions, TriviaQA。
- 对数据集进行预处理,提取问题和答案。对于每个问题,需要将其转换为可以输入T5模型的形式,例如,将缺失部分用
<M>标记。
-
加载预训练的T5模型:
- 使用
T5类加载预训练的T5模型。可以选择不同大小的模型,如T5-base,T5-large,T5-3B等。
- 使用
-
配置训练参数:
- 设置学习率、优化器、预处理和后处理函数。预处理函数将
<M>替换为[MASK],后处理函数将[MASK]替换回<M>。
- 设置学习率、优化器、预处理和后处理函数。预处理函数将
-
训练模型:
- 通过迭代训练数据集来训练模型。
- 在每个epoch结束后,使用验证集验证模型性能。
代码实现
以下是一个使用Hugging Face transformers库实现的简化代码示例:
from transformers import T5ForConditionalGeneration, T5Tokenizer, AdamW
from torch.utils.data import DataLoader
from torch.optim import AdamW# 1. 加载预训练的T5模型
model = T5ForConditionalGeneration.from_pretrained('t5-base')
tokenizer = T5Tokenizer.from_pretrained('t5-base')# 2. 配置训练参数
learning_rate = 0.001
optimizer = AdamW(model.parameters(), lr=learning_rate)# 3. 准备数据集
def preprocess_example(example):question = example['question']answer = example['answer']input_text = f"fill {question} with {answer}"input_ids = tokenizer.encode(input_text, return_tensors='pt')target_text = f"answer: {answer}"target_ids = tokenizer.encode(target_text, return_tensors='pt')return input_ids, target_idsdataset = [...] # 假设已经准备好数据集
data_loader = DataLoader(dataset, batch_size=16, shuffle=True)# 4. 训练模型
epochs = 10
for epoch in range(epochs):for batch in data_loader:input_ids, target_ids = batchoutputs = model(input_ids=input_ids, labels=target_ids)loss = outputs.lossoptimizer.zero_grad()loss.backward()optimizer.step()if epoch % 100 == 0:print(f"Epoch {epoch}, Loss: {loss.item()}")# 5. 评估模型
def evaluate(model, data_loader):model.eval()total_loss = 0for batch in data_loader:input_ids, target_ids = batchwith torch.no_grad():outputs = model(input_ids=input_ids, labels=target_ids)loss = outputs.losstotal_loss += loss.item()avg_loss = total_loss / len(data_loader)print(f"Validation Loss: {avg_loss}")model.train()evaluate(model, validation_loader)
这个代码示例展示了如何使用Hugging Face的transformers库来训练和评估T5模型,以完成开放域问答任务。实际使用中可能需要根据具体需求调整数据预处理和模型配置。
【OpenSpace】
开放性讨论:语言模型能够存储多少知识?
背景
近年来,预训练的语言模型在无监督环境下,通过对大量未标注文本进行训练,展现出强大的性能。特别是经过微调后的语言模型在下游自然语言处理任务(NLP)中取得了显著成果。然而,最近的研究发现,这些模型在预训练过程中还能够内部化一种隐式的“知识库”,并且可以在不依赖外部知识库的情况下回答问题。这种现象引发了对语言模型作为知识库能力的深入研究。
思考问题
-
模型大小与知识存储量的关系:
- 研究表明,模型的参数量越大,其内部化知识的能力越强。例如,T5模型从Base到11B参数版本,性能随着参数量的增加而逐步提升。
- 这是因为大规模模型能够更好地捕捉和存储大量的语言模式和信息。因此,模型的参数量可以作为衡量其知识存储能力的一个指标。
-
闭卷问答(Closed-Book QA)与开放问答(Open-Book QA):
- 闭卷问答是指模型在回答问题时不能访问任何外部知识,必须依靠其内部化的知识来回答问题。这种设置可以更真实地评估模型的内部知识存储能力。
- 开放问答模型则可以访问外部知识库,这为它们提供了更多的信息来源,但同时也降低了评估的难度。因此,闭卷问答提供了一种更为严格的评估标准。
-
知识存储的隐秘性:
- 语言模型内部化知识的方式通常是隐秘的,模型在回答问题时会根据其内部的知识库生成答案。这不同于传统的知识存储方式,模型不需要显式地存储知识,而是通过训练过程中学习到的模式来推断和生成答案。
- 这种隐秘性使得评估模型的知识存储能力更加困难,需要设计特定的任务和评估标准来衡量模型的性能。
-
知识存储的深度和广度:
- 研究表明,模型能够存储大量的知识,但这些知识的深度和广度仍有待进一步探究。例如,模型在回答封闭领域的问题时可能表现良好,但在处理更复杂、需要推理能力的问题时可能表现不佳。
- 这种现象提示我们,语言模型内部化知识的过程可能涉及复杂的模式学习和推理机制,需要进一步研究来揭示其背后的机制。
-
未来研究方向:
- 需要进一步研究如何提高模型的知识存储能力,包括设计更有效的预训练任务、探索新的知识表示方法等。
- 同时,需要设计更复杂的评估任务来全面评估模型的知识存储和推理能力,包括那些需要多层次推理和背景理解的任务。
结论
语言模型在预训练过程中能够隐式地存储大量知识,并在闭卷问答任务中表现出强大的能力。这为自然语言处理领域提供了一种新的知识表示和存储方式。未来的研究将进一步探索这一现象背后的机制,并设计更为复杂的评估任务来全面评估模型的能力。
以上讨论为开放性问题,旨在引发更多的思考和探讨。如果您有具体的问题或观点,欢迎进一步交流!
相关文章:

如何在语言模型的参数中封装知识?——以T5模型为例
【摘要】 这篇论文探讨了大型语言模型在无需外部知识的情况下,能否通过预训练来存储和检索知识以回答开放领域的问题。作者通过微调预训练模型来回答问题,而这些模型在训练时并未提供任何额外的知识或上下文。这种方法随着模型规模的增加而表现出良好的…...

面试java做了一道逻辑题,人麻了
题目:给你一个5升水壶,一个6升水壶,去池塘中取水,如何保证最后取出的水是3升? 思考了很久终于想出来了,这里用X5代表5升的桶,X6代表6升的桶: ① 6升桶装满,X50ÿ…...

数据仓库为什么要分层
数据仓库分层架构是数据仓库设计中的一个重要概念,其主要目的是为了更好地组织和管理数据,提高数据仓库的可维护性、可扩展性和性能。分层架构将数据仓库划分为多个层次,每个层次都有其特定的职责和功能。以下是数据仓库分层的主要原因和好处…...

【Python运维】实现高效的自动化备份与恢复:Python脚本从入门到实践
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在信息化时代,数据备份和恢复的有效性对企业和个人来说至关重要。本文将带领读者深入了解如何使用Python编写自动化备份与恢复脚本,确保重…...

RLock类详细介绍、应用场景和示例代码
概述 org.redisson.api.RLock 是 Redisson 提供的 分布式可重入锁(类似 ReentrantLock),基于 Redis 实现,常用于 分布式环境 下的 并发控制。 1. RLock 详解 🔹 特点 基于 Redis 实现,支持 集群环境。可…...

bash: uwsgi: 未找到命令
针对你提出的“bash: uwsgi: command not found”问题,以下是一些可能的解决方案,请按照步骤逐一排查: 1、检查uwsgi命令是否正确: 确保你输入的命令是uwsgi,而不是uWSGI或其他变体。 2、确认uwsgi是否已安装&…...

基于数据挖掘的疾病数据可视化分析与预测系统
【大数据】基于数据挖掘的疾病数据可视化分析与预测系统(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 📌 技术核爆点:✔️ Python全栈开发Flask高能框架 ✔️ 爬虫技术…...

rv1106g2摄像头wlan0固定mac地址
wq9001无线网卡的mac地址是一个随机地址,在每次启动后,都会变更,使得dhcp分配的地址不同。要想有固定的mac地址,要做以下操作。 在文件uckfox-pico/sysdrv/drv_ko/wifi/insmod_wifi.sh添加函数wlan0_init wlan0_init() {wlan0add…...

企业日常工作中常用的 Linux 操作系统命令整理
Linux 操作系统命令整理 在企业级运维、开发和日常工作中,Linux 命令是绕不开的核心技能。不论是日志排查、进程管理,还是高效运维优化,掌握这些命令都能让你事半功倍!本篇文章整理了自己在日常工作中积累最常用的 Linux 命令&am…...

AutoGen学习笔记系列(六)Tutorial - Termination
这篇文章瞄准的是AutoGen框架官方教程中的 Tutorial 章节中的 Termination 小节,主要介绍了更细粒度上图如何终止Team组内轮询的过程。 官网链接:https://microsoft.github.io/autogen/stable/user-guide/agentchat-user-guide/tutorial/termination.ht…...

用IdleHandler来性能优化及原理源码分析
背景: 经常在做一些app冷启动速度优化等性能优化工作时候,经常可能会发现有时候需要引入一些第三方sdk,或者库,这些库一般会要求我们在onCreate中进行初始化等,但是onCreate属于生命周期的回调方法,如果on…...

git忽略特定文件或者文件夹
如果想让 Git 忽略指定目录,不进行更新或提交,可以使用 .gitignore 文件进行配置。 🛠 方法:使用 .gitignore 忽略目录 1️⃣ 在仓库根目录创建 .gitignore 文件 如果你的项目目录下还没有 .gitignore 文件,可以新建…...

STM32使用无源蜂鸣器
1.1 介绍: 有源蜂鸣器:内部自带振荡源,将正负极接上直流电压即可持续发声,频率固定 无源蜂鸣器:内部不带振荡源,需要控制器提供振荡脉冲才可发声,调整提供振荡脉冲的频率,可发出不同…...

VMware 安装部署RHEL9
目录 目标一:创建名为RHEL9_node2的虚拟机 1.环境搭建:VMware 2.下载RHEL9的ISO镜像(官网可获取) 3.打开VMware,新建虚拟机 3.1 自定义安装 3.2 默认操纵至下一步操作到稍后安装系统 3.3选择操作系统为linux以及…...

智能机器人学习机WT3000A AI芯片方案-自然语音交互 打造沉浸式学习体验
一、概述 当AI浪潮席卷全球,教育领域也未能幸免。AI学习机,这个打着“个性化学习”、“精准提分”旗号的新兴产品,正以惊人的速度占领市场。从一线城市到偏远乡镇,从学龄前儿童到高考备考生,AI学习机的广告铺天盖地&am…...

阿里推出全新推理模型(因果语言模型),仅1/20参数媲美DeepSeek R1
阿里Qwen 团队正式发布了他们最新的研究成果——QwQ-32B大语言模型!这款模型不仅名字萌萌哒(QwQ),实力更是不容小觑!😎 QwQ-32B 已在 Hugging Face 和 ModelScope 开源,采用了 Apache 2.0 开源协议。大家可通过 Qwen C…...
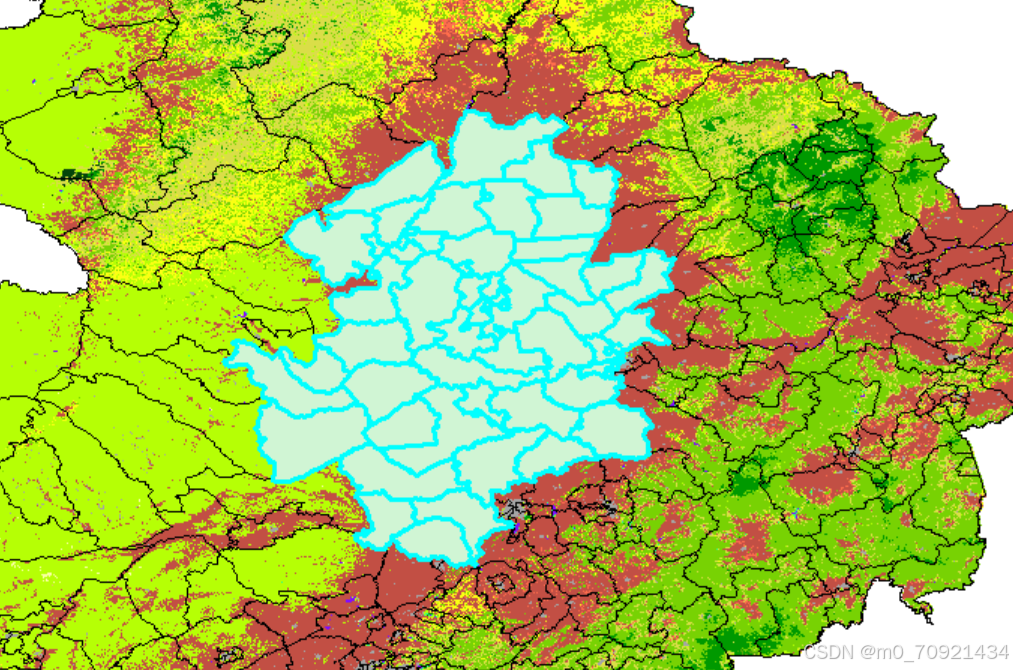
20250307学习记录
大家早上好呀,今天早上七点四十就起床了 第一部分,修改一下任务 完成 第二部分,整理MODIS数据 2023-5-30-GEE-土地覆盖处理_mcd12q1.061-CSDN博客 看完这个博客,我有了大致的思路 编写代码转换为tiff,并且将不同…...

设计模式-创建型模式详解
这里写目录标题 一、基本概念二、单例模式1. 模式特点2. 适用场景3. 实现方法4. 经典示例 三、简单工厂模式1. 模式特点2. 经典示例 四、工厂方法模式五、抽象工厂模式1. 适用场景2. 经典示例 六、建造者模式1. 模式特点2. 一般流程3. 适用场景4. 经典示例 七、原型模式 一、基…...

【蓝桥杯】每天一题,理解逻辑(2/90)【LeetCode 复写零】
闲话系列:每日一题,秃头有我,Hello!!!!!,我是IF‘Maxue,欢迎大佬们来参观我写的蓝桥杯系列,我好久没有更新博客了,因为up猪我寒假用自己的劳动换了…...

米尔基于STM32MP25x核心板Debian系统发布,赋能工业设备
一、系统概述 MYD-LD25X搭载的Debian系统包含以太网、WIFI/BT、USB、RS485、RS232、CAN、AUDIO、HDMI显示和摄像头等功能,同时也集成了XFCE轻量化桌面、VNC远程操控、SWITCH网络交换和TSN时间敏感网络功能,为工业设备赋予“超强算力实时响应极简运维”的…...

FPGA异构计算与模块化SoM:赋能边缘智能与工业应用实战
1. 项目概述:一次行业深度交流的契机最近,我作为Enclustra团队的一员,有幸受邀参加了今年的嵌入式计算大会。这不仅仅是一次简单的行业聚会,更是一个观察技术风向、碰撞思想火花、探寻合作机会的绝佳窗口。对于所有深耕于嵌入式系…...

靠谱的微晶电热板机构
在实验设备领域,微晶电热板是一款重要的工具,选择靠谱的机构至关重要。微晶电热板的重要性微晶电热板在环境监测、食品安全、农产品检测等分析实验室中应用广泛。它能够为样品前处理提供稳定的加热环境,保障实验结果的准确性。行业报告显示&a…...

ISE FPGA开发全流程实战:从代码到比特流的经典设计指南
1. 项目概述与核心价值如果你正准备踏入FPGA开发的大门,或者已经用了一段时间的Vivado,想看看业界另一个主流工具ISE(Integrated Software Environment)到底怎么玩,那这个系列的内容就是为你准备的。ISE是Xilinx&#…...

学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南
学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南 同一段文字,不同平台检测AI率相差20%以上。这不是玄学,有原因可解释。 关于高校AIGC检测标准差异解读,理解了背后逻辑,很多「奇怪现…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...

宇视摄像机室外安装防腐说明
摄像机室外安装防腐说明一、开篇介绍防腐能力是户外摄像机长期稳定运行的关键。设备金属外壳一旦腐蚀,易引发起雾、进水、性能下降,严重时会导致整机损坏。宇视户外产品均按对应环境防护标准设计,可根据现场腐蚀等级选择适配产品。本文为工程…...

终极CH55xduino指南:5分钟构建低成本USB微控制器项目
终极CH55xduino指南:5分钟构建低成本USB微控制器项目 【免费下载链接】ch55xduino An Arduino-like programming API for the CH55X 项目地址: https://gitcode.com/gh_mirrors/ch/ch55xduino CH55xduino为CH55X系列低成本MCS51 USB微控制器提供了完整的Ardu…...

别再傻傻分不清了!一张图看懂CRT、PEM、PFX、P7B证书格式的区别与应用场景
数字证书格式全解析:CRT、PEM、PFX、P7B的核心差异与实战选择 当你第一次在服务器上配置SSL证书时,面对CRT、PEM、PFX、P7B这些后缀名,是不是感觉像在解密码?上周我帮一个创业团队迁移服务器,他们的CTO拿着五个不同格式…...
详情页开发避坑指南:路由配置与参数传递详解)
告别弹窗!若依框架(Ruoyi)详情页开发避坑指南:路由配置与参数传递详解
若依框架详情页开发实战:从路由配置到参数传递的深度解析 在若依框架的实际开发中,详情页的实现往往成为开发者遇到的"拦路虎"。明明按照文档操作,却频繁遭遇页面空白、参数丢失或控制台报错等问题。本文将深入剖析若依框架中前端路…...

texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜
texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜 【免费下载链接】texgen.js JavaScript Texture Generator 项目地址: https://gitcode.com/gh_mirrors/te/texgen.js texgen.js 是一个功能强大的JavaScript纹理生成器库,它让开发者能够通…...